Monitoring アラートを作成すると、Dataproc クラスタやジョブの指標が指定されたしきい値を超えた場合に通知を受け取れます。
アラートを作成する
Google Cloud コンソールで [アラート] ページを開きます。
[+ ポリシーを作成] をクリックして、[アラート ポリシーの作成] ページを表示します。
- [指標を選択] をクリックします。
- [リソース名または指標名でフィルタ] 入力ボックスに「dataproc」と入力して、Dataproc 指標を一覧表示します。[Cloud Dataproc] 指標の階層内を移動し、クラスタ、ジョブ、バッチ、セッションの指標を選択します。
- [適用] をクリックします。
- [次へ] をクリックして [Configure alert trigger] ページを開きます。
- アラートをトリガーするしきい値を設定します。
- [NEXT] をクリックして [Configure notifications and finalize alert] ペインを開きます。
- 通知チャンネル、ドキュメント、アラート ポリシー名を設定します。
- [次へ] をクリックして、アラート ポリシーを確認します。
- [ポリシーの作成] をクリックしてアラートを作成します。
アラートの例
このセクションでは、Dataproc サービスに送信されたジョブのサンプル アラート、および YARN アプリケーションとして実行されるジョブのアラートについて説明します。
長時間実行 Dataproc ジョブのアラート
Dataproc は、ジョブがさまざまな状態であった時間を追跡する dataproc.googleapis.com/job/state 指標を出力します。この指標は、 Google Cloud コンソールの Metrics Explorer の Cloud Dataproc ジョブ(cloud_dataproc_job)リソースで確認できます。この指標を使用して、ジョブの RUNNING 状態が実行時間のしきい値を超えたときに通知するアラートを設定できます。
ジョブ所要時間のアラートの設定
この例では、Monitoring Query Language(MQL)を使用してアラート ポリシーを作成します(MQL アラート ポリシーの作成(コンソール)をご覧ください)。
fetch cloud_dataproc_job
| metric 'dataproc.googleapis.com/job/state'
| filter metric.state == 'RUNNING'
| group_by [resource.job_id, metric.state], 1m
| condition val() == true()
次の例では、ジョブの実行時間が 30 分を超えるとアラートがトリガーされます。
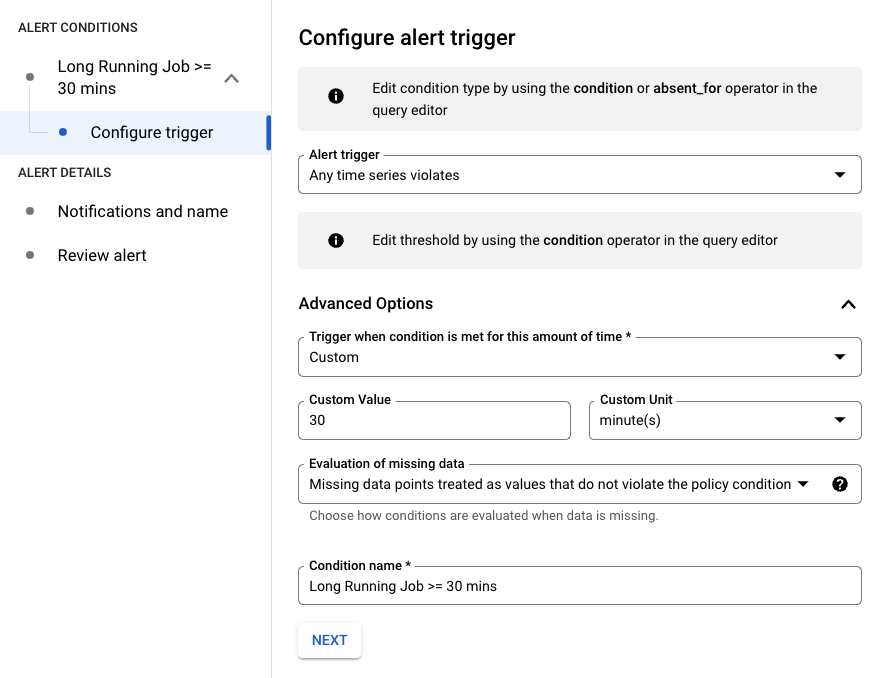
resource.job_id でフィルタしてクエリを変更し、特定のジョブに適用できます。
fetch cloud_dataproc_job
| metric 'dataproc.googleapis.com/job/state'
| filter (resource.job_id == '1234567890') && (metric.state == 'RUNNING')
| group_by [resource.job_id, metric.state], 1m
| condition val() == true()
長時間実行中 YARN アプリケーションのアラート
上記の例は、Dataproc ジョブが指定された期間よりも長く実行されたときにトリガーされるアラートを示していますが、これは、 Google Cloud コンソール、Google Cloud CLI を介して、または Dataproc jobs API への直接呼び出しによって Dataproc サービスに送信されたジョブにのみ適用されます。OSS 指標を使用して、YARN アプリケーションの実行時間をモニタリングする同様のアラートを設定することもできます。
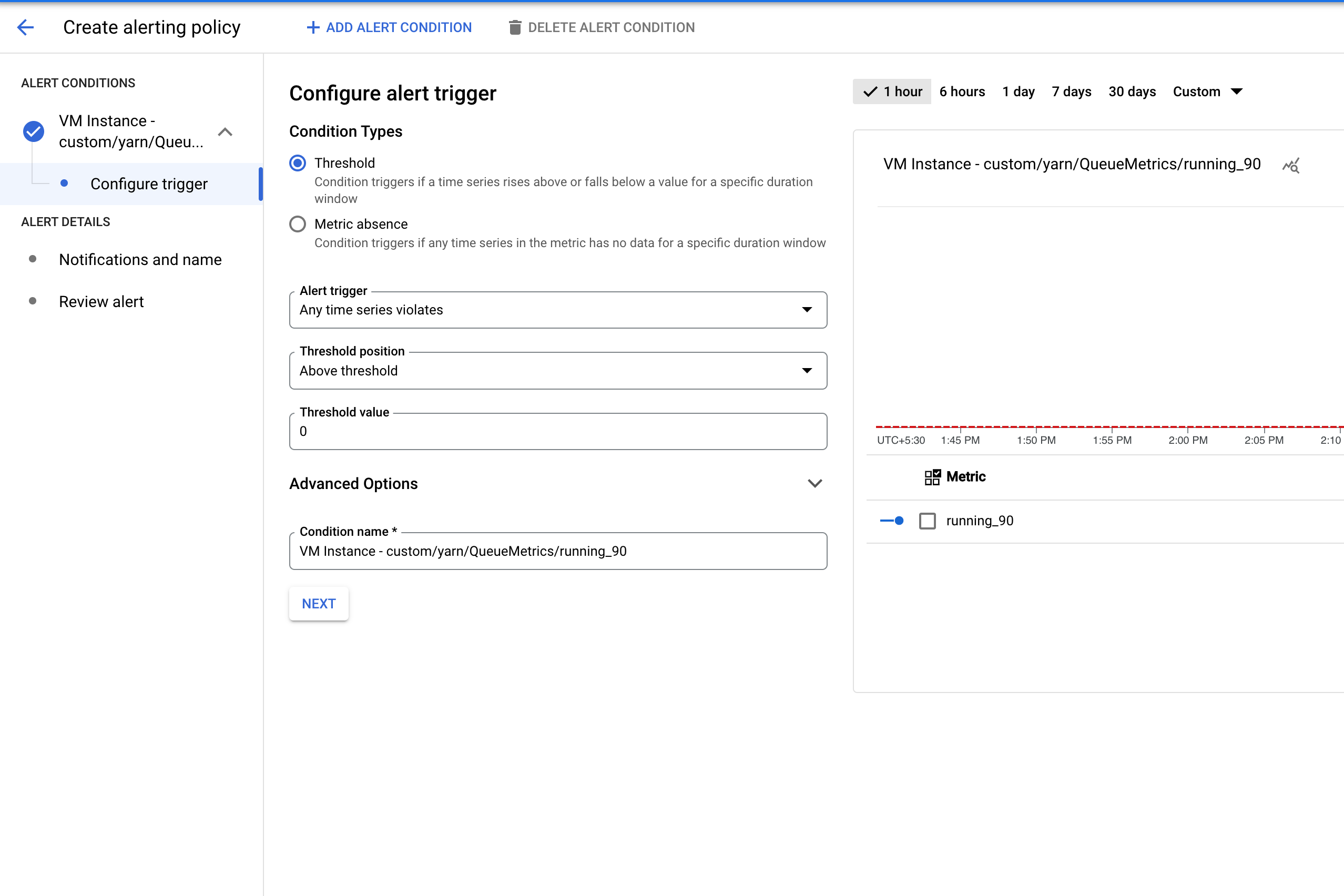
まず、背景を説明します。YARN は、実行時間の指標を複数のバケットに出力します。デフォルトでは、YARN はバケットしきい値として 60 分、300 分、1,440 分を維持し、4 つの指標(running_0、running_60、running_300、running_1440)を出力します。
running_0は、ランタイムが 0~60 分のジョブの数を記録します。running_60は、ランタイムが 60~300 分のジョブの数を記録します。running_300は、ランタイムが 300~1,440 分のジョブの数を記録します。running_1440は、ランタイムが 1,440 分を超えるジョブの数を記録します。
たとえば、72 分間実行されたジョブは running_60 に記録されますが、running_0 には記録されません。
こうしたデフォルトのバケットしきい値は、Dataproc クラスタの作成時に yarn:yarn.resourcemanager.metrics.runtime.buckets クラスタ プロパティに新しい値を渡すことで変更できます。カスタム バケットのしきい値を定義する場合は、指標のオーバーライドも定義する必要があります。たとえば、バケットのしきい値を 30 分、60 分、90 分に指定するには、gcloud dataproc clusters create コマンドに次のフラグを含める必要があります。
バケットのしきい値:
‑‑properties=yarn:yarn.resourcemanager.metrics.runtime.buckets=30,60,90指標のオーバーライド:
‑‑metric-overrides=yarn:ResourceManager:QueueMetrics:running_0, yarn:ResourceManager:QueueMetrics:running_30,yarn:ResourceManager:QueueMetrics:running_60, yarn:ResourceManager:QueueMetrics:running_90
gcloud dataproc clusters create test-cluster \ --properties ^#^yarn:yarn.resourcemanager.metrics.runtime.buckets=30,60,90 \ --metric-sources=yarn \ --metric-overrides=yarn:ResourceManager:QueueMetrics:running_0,yarn:ResourceManager:QueueMetrics:running_30,yarn:ResourceManager:QueueMetrics:running_60,yarn:ResourceManager:QueueMetrics:running_90
これらの指標は、 Google Cloud コンソールの Metrics Explorer の、[VM インスタンス](gce_instance)リソースに一覧表示されます。
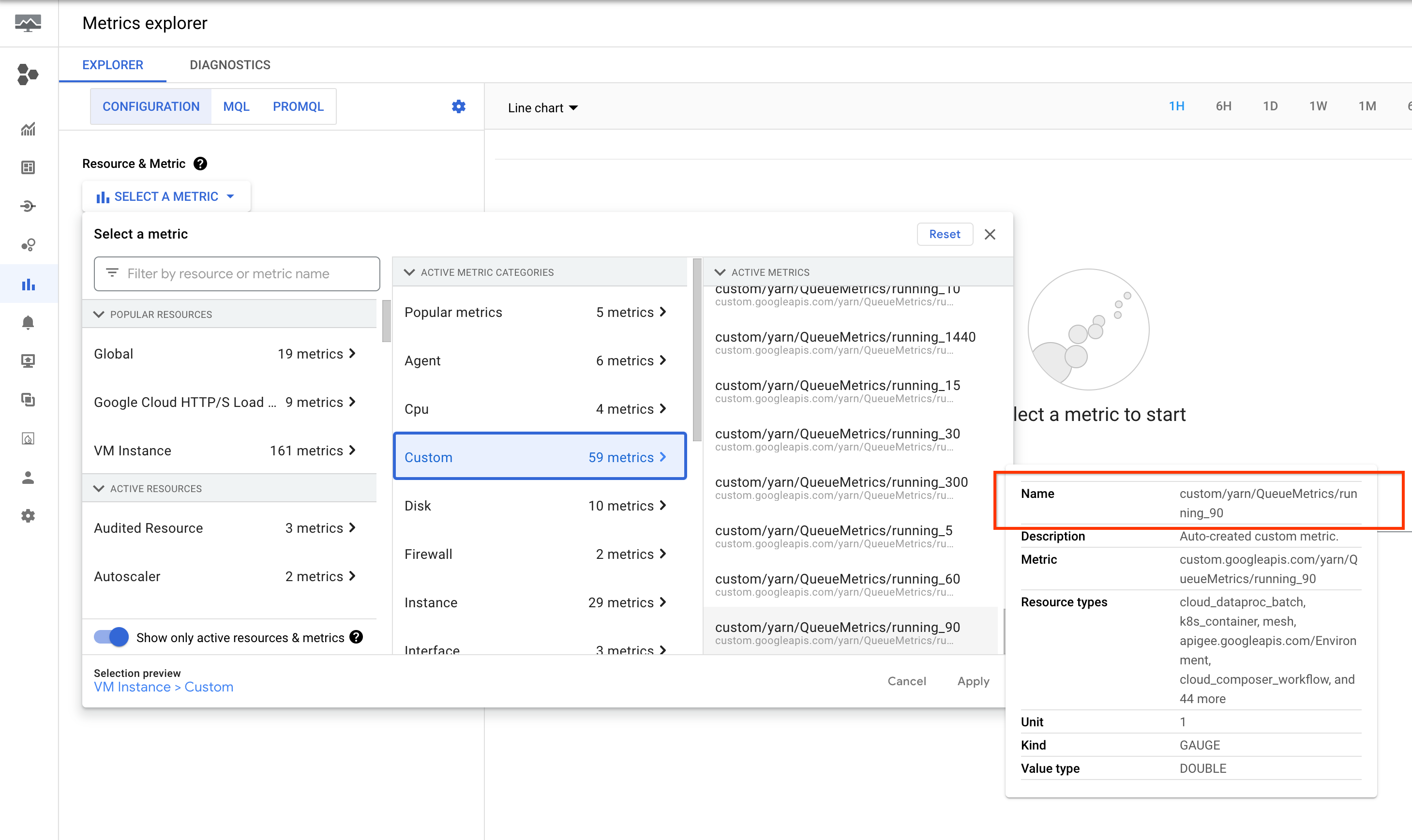
YARN アプリケーション アラートの設定
YARN 指標バケット内のアプリケーション数が指定されたしきい値を超えたときにトリガーされるアラート ポリシーを作成します。
必要に応じて、パターンに一致するクラスタに対してアラートを送信するフィルタを追加します。
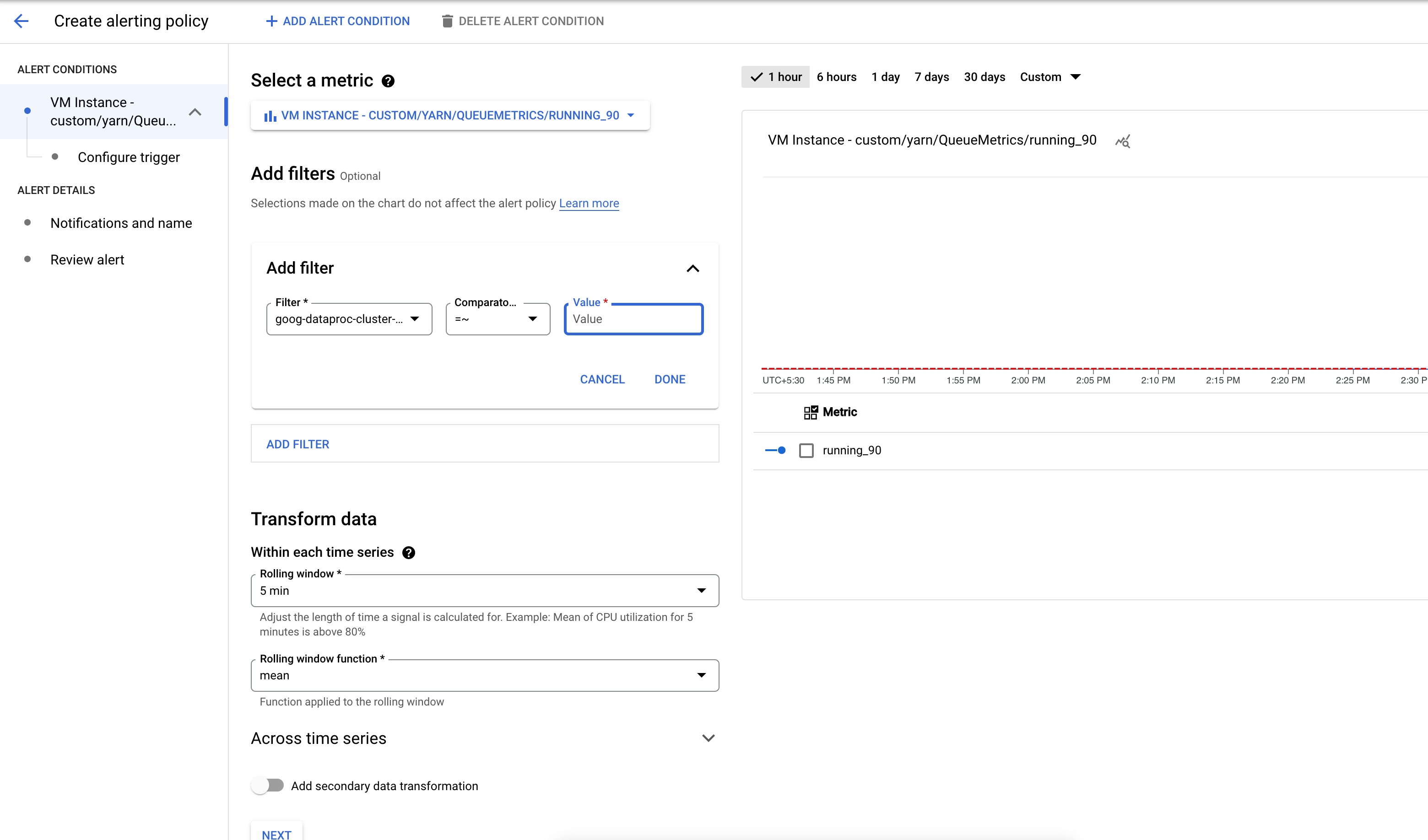
アラートをトリガーするしきい値を構成します。
Dataproc のジョブアラートに失敗しました
dataproc.googleapis.com/job/state 指標(長時間実行される Dataproc ジョブのアラートを参照)を使用して、Dataproc ジョブが失敗したときにアラートを送信することもできます。
ジョブアラートの設定に失敗しました
この例では、Monitoring Query Language(MQL)を使用してアラート ポリシーを作成します(MQL アラート ポリシーの作成(コンソール)をご覧ください)。
アラート MQL
fetch cloud_dataproc_job
| metric 'dataproc.googleapis.com/job/state'
| filter metric.state == 'ERROR'
| group_by [resource.job_id, metric.state], 1m
| condition val() == true()
アラート トリガーの構成
次の例では、プロジェクト内の Dataproc ジョブが失敗するとアラートがトリガーされます。
resource.job_id でフィルタしてクエリを変更し、特定のジョブに適用できます。
fetch cloud_dataproc_job
| metric 'dataproc.googleapis.com/job/state'
| filter (resource.job_id == '1234567890') && (metric.state == 'ERROR')
| group_by [resource.job_id, metric.state], 1m
| condition val() == true()
クラスタ キャパシティの偏差アラート
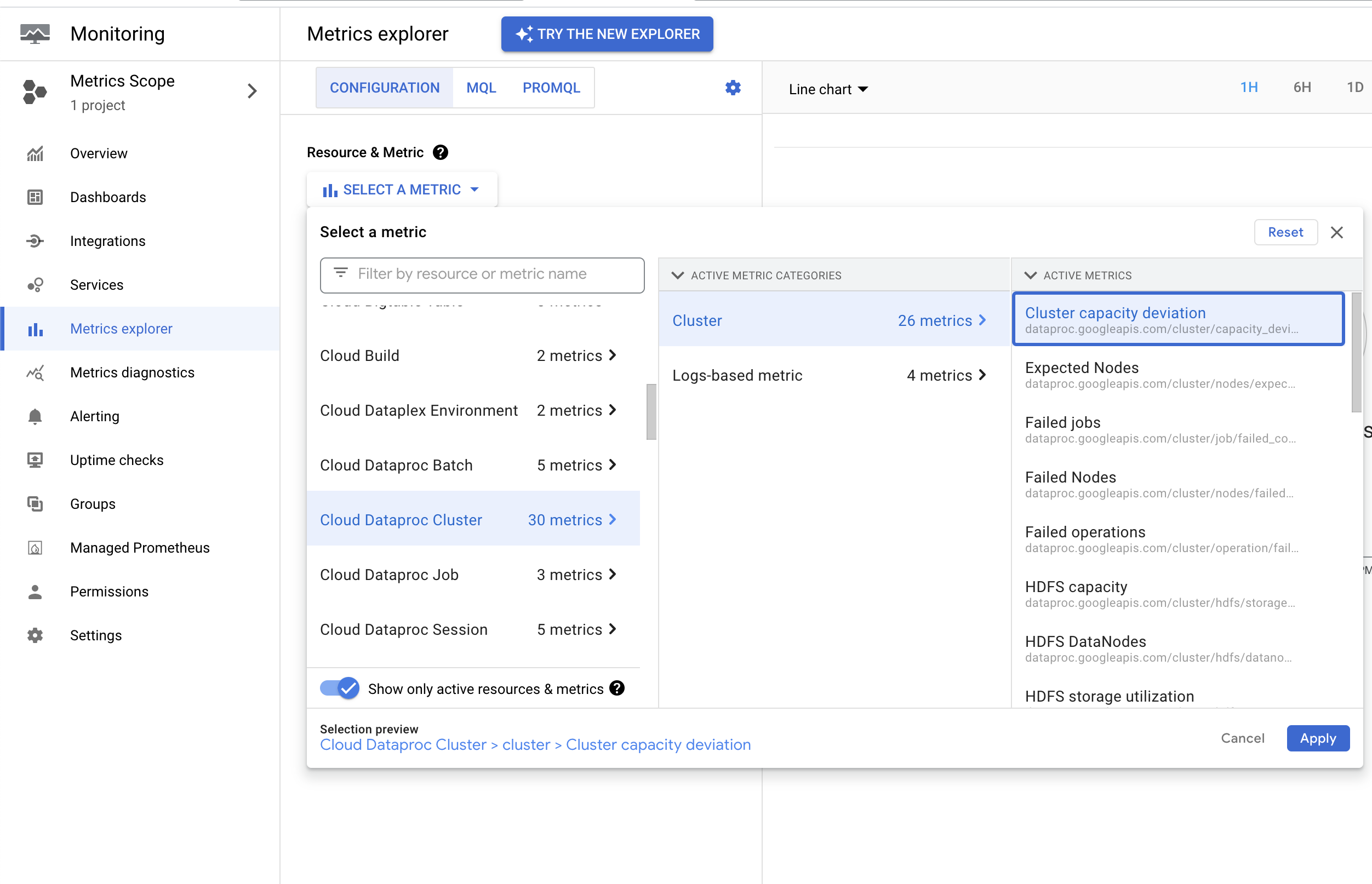
Dataproc は dataproc.googleapis.com/cluster/capacity_deviation 指標を出力します。この指標は、クラスタ内の想定ノード数とアクティブな YARN ノード数の差異を報告します。この指標は、Google Cloud コンソールの Metrics Explorer の Cloud Dataproc クラスタ リソースで確認できます。この指標を使用して、クラスタ キャパシティが指定されたしきい値の期間を超えて予想容量から逸脱したときに通知するアラートを作成できます。
次のオペレーションを行うと、capacity_deviation 指標でのクラスタノードの報告が一時的に抑えられる可能性があります。誤検出アラートを回避するには、指標アラートのしきい値を設定して、次のオペレーションを考慮します。
クラスタの作成と更新: クラスタの作成オペレーションまたは更新オペレーション中に
capacity_deviation指標は出力されません。クラスタ初期化アクション: 初期化アクションは、ノードがプロビジョニングされた後に実行されます。
セカンダリ ワーカーの更新: セカンダリ ワーカーは、更新操作の完了後に非同期的に追加されます。
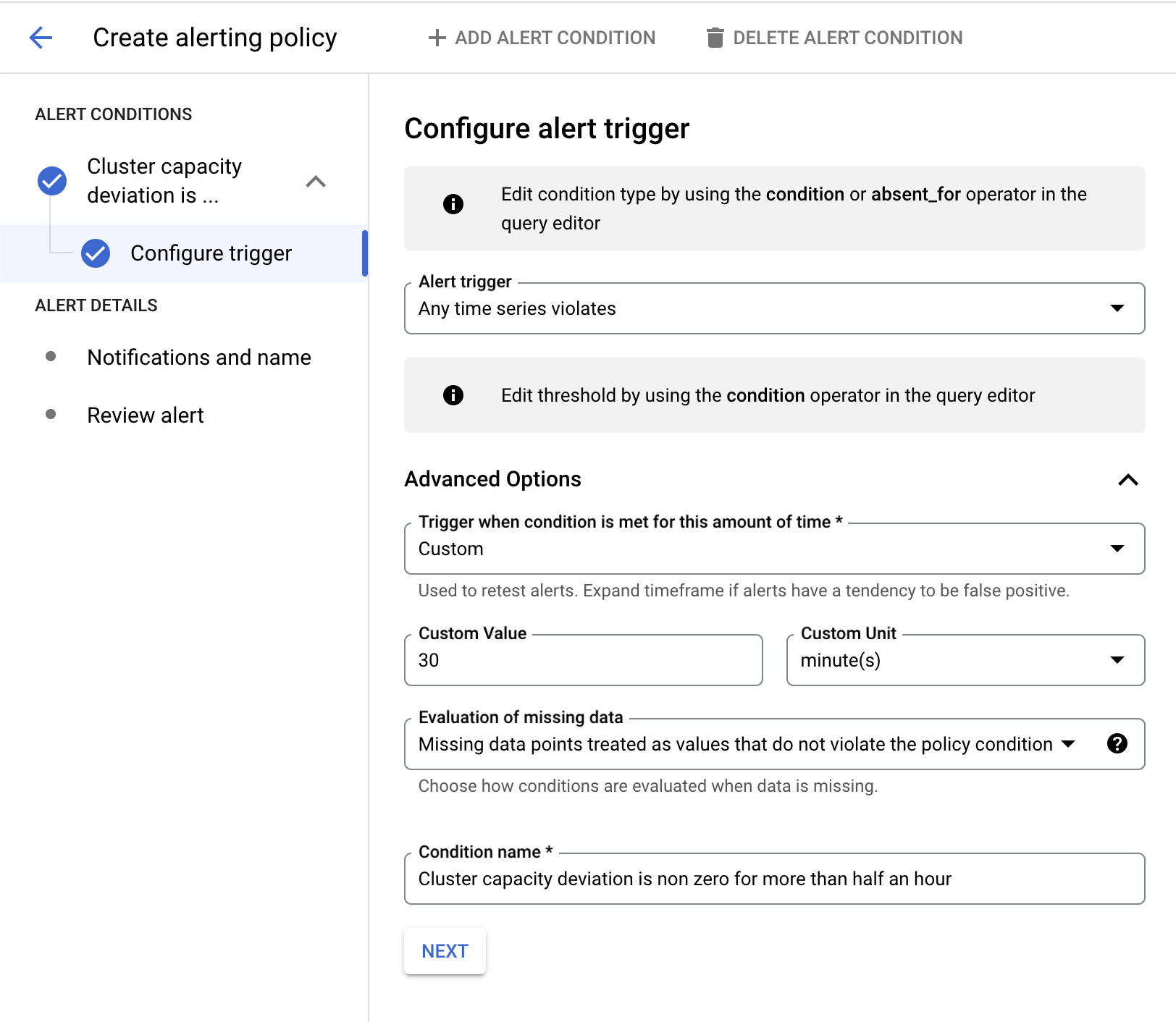
容量偏差アラートの設定
この例では、Monitoring Query Language(MQL)を使用してアラート ポリシーを作成します。
fetch cloud_dataproc_cluster
| metric 'dataproc.googleapis.com/cluster/capacity_deviation'
| every 1m
| condition val() <> 0 '1'
次の例では、クラスタ キャパシティの偏差が 30 分間ゼロでない場合にアラートがトリガーされます。
アラートを表示する
指標しきい値条件によってアラートがトリガーされると、Monitoring によってインシデントおよび対応するイベントが作成されます。インシデントは、 Google Cloud コンソールの Monitoring のアラートページから表示できます。
アラート ポリシーに通知メカニズム(メールや SMS 通知など)を定義した場合、Monitoring によってインシデントの通知が送信されます。
次のステップ
- アラートの概要を確認する。