Esta página fornece informações para ajudar a monitorizar e depurar tarefas do Dataproc e compreender as mensagens de erro das tarefas do Dataproc.
Monitorização e depuração de tarefas
Use a Google Cloud CLI, a API REST Dataproc e a Google Cloud consola para analisar e depurar tarefas do Dataproc.
CLI gcloud
Para examinar o estado de uma tarefa em execução:
gcloud dataproc jobs describe job-id \ --region=region
Para ver a saída do controlador de tarefas, consulte o artigo Ver saída da tarefa.
API REST
Chame jobs.get para examinar os campos JobStatus.State, JobStatus.Substate, JobStatus.details e YarnApplication.
Consola
Para ver a saída do controlador de tarefas, consulte o artigo Ver saída da tarefa.
Para ver o registo do agente do Dataproc em Registo, selecione Cluster do Dataproc → Nome do cluster → UUID do cluster no seletor de clusters do Explorador de registos.
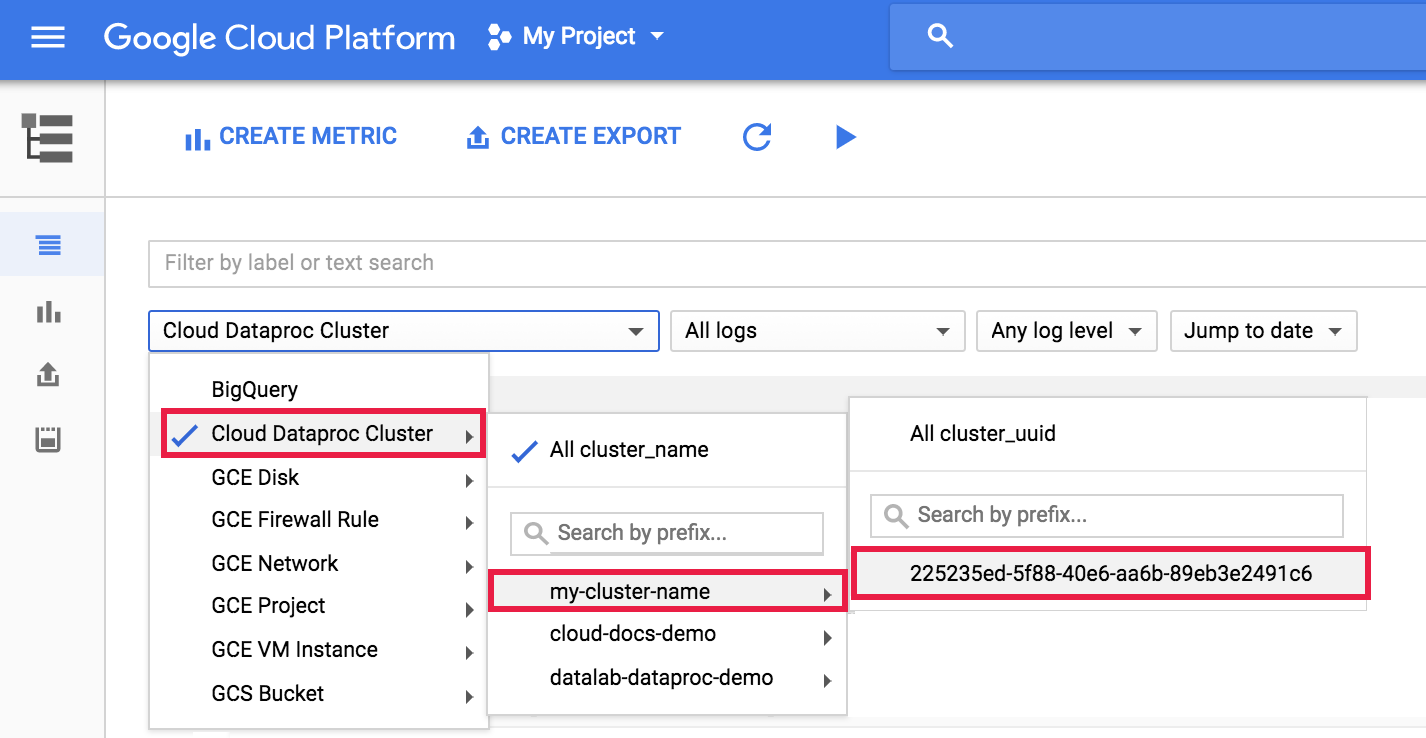
Em seguida, use o seletor de registos para selecionar os registos google.dataproc.agent.

Veja registos de tarefas em Registos
Se uma tarefa falhar, pode aceder aos registos de tarefas no Logging.
Determinar quem enviou uma tarefa
Procurar os detalhes de uma tarefa mostra quem enviou essa tarefa no campo submittedBy. Por exemplo, este resultado do trabalho mostra que user@domain enviou o trabalho de exemplo para um cluster.
... placement: clusterName: cluster-name clusterUuid: cluster-uuid reference: jobId: job-uuid projectId: project status: state: DONE stateStartTime: '2018-11-01T00:53:37.599Z' statusHistory: - state: PENDING stateStartTime: '2018-11-01T00:33:41.387Z' - state: SETUP_DONE stateStartTime: '2018-11-01T00:33:41.765Z' - details: Agent reported job success state: RUNNING stateStartTime: '2018-11-01T00:33:42.146Z' submittedBy: user@domain
Mensagens de erro
A tarefa não foi adquirida
Isto indica que o agente do Dataproc no nó principal não conseguiu adquirir a tarefa do plano de controlo. Isto acontece frequentemente devido a problemas de rede ou de memória insuficiente (OOM). Se a tarefa tiver sido executada com êxito anteriormente e não tiver alterado as definições de configuração de rede, a causa mais provável é a falta de memória, muitas vezes o resultado do envio de muitas tarefas em execução em simultâneo ou tarefas cujos controladores consomem uma quantidade significativa de memória (por exemplo, tarefas que carregam grandes conjuntos de dados na memória).
Não foi encontrado nenhum agente nos nós principais que esteja ativo
Isto indica que o agente do Dataproc no nó principal não está ativo e não pode aceitar novas tarefas. Isto acontece frequentemente devido a problemas de rede ou de memória insuficiente (OOM), ou se a VM do nó principal não estiver em bom estado. Se a tarefa tiver sido executada com êxito anteriormente e não tiver alterado as definições de configuração de rede, a causa mais provável é a falta de memória, que resulta frequentemente do envio de muitas tarefas em execução em simultâneo ou de tarefas cujos controladores consomem uma quantidade significativa de memória (tarefas que carregam grandes conjuntos de dados na memória).
Para ajudar a resolver o problema, pode experimentar as seguintes ações:
- Reinicie a tarefa.
- Ligue através de SSH ao nó principal do cluster, e, em seguida, determine que tarefa ou outro recurso está a usar mais memória.
Se não conseguir iniciar sessão no nó principal, pode verificar os registos da porta série (consola).

Gere um pacote de diagnóstico, que contém o syslog e outros dados.
A tarefa não foi encontrada.
Este erro indica que o cluster foi eliminado enquanto uma tarefa estava em execução. Pode realizar as seguintes ações para identificar o principal que realizou a eliminação e confirmar que a eliminação do cluster ocorreu quando um trabalho estava em execução:
Veja os registos de auditoria do Dataproc para identificar o principal que realizou a operação de eliminação.
Use o registo ou a CLI gcloud para verificar se o último estado conhecido da aplicação YARN era RUNNING:
- Use o seguinte filtro no Registo:
resource.type="cloud_dataproc_cluster" resource.labels.cluster_name="CLUSTER_NAME" resource.labels.cluster_uuid="CLUSTER_UUID" "YARN_APPLICATION_ID State change from"
- Execute
gcloud dataproc jobs describe job-id --region=REGIONe, em seguida, verifiqueyarnApplications: > STATEno resultado.
Se o principal que eliminou o cluster for a conta de serviço do agente de serviço do Dataproc, verifique se o cluster foi configurado com uma duração de eliminação automática inferior à duração da tarefa.
Para evitar erros Task not found, use a automatização para garantir que os clusters não são eliminados antes de todas as tarefas em execução estarem concluídas.
Não existe espaço no dispositivo
O Dataproc escreve dados HDFS e temporários no disco. Esta mensagem de erro indica que o cluster foi criado com espaço em disco insuficiente. Para analisar e evitar este erro:
Verifique o tamanho do disco principal do cluster indicado no separador Configuração na página Detalhes do cluster na Google Cloud consola. O tamanho mínimo recomendado do disco é de
1000 GBpara clusters que usam o tipo de máquinan1-standard-4e de2 TBpara clusters que usam o tipo de máquinan1-standard-32.Se o tamanho do disco do cluster for inferior ao tamanho recomendado, recrie o cluster com, pelo menos, o tamanho do disco recomendado.
Se o tamanho do disco for o tamanho recomendado ou superior, use o SSH para se ligar à VM principal e, em seguida, execute
df -hna VM principal para verificar a utilização do disco e determinar se é necessário espaço em disco adicional.