Présentation
Le serveur d'historique persistant (PHS) Dataproc fournit des interfaces Web qui permettent d'afficher l'historique des tâches exécutées sur des clusters Dataproc actifs ou supprimés. Il est disponible dans la version d'image 1.5 de Dataproc et versions ultérieures, et s'exécute sur un cluster Dataproc à nœud unique. Il fournit des interfaces Web pour les fichiers et données suivants :
Fichiers d'historique des tâches MapReduce et Spark
Fichiers d'historique des jobs Flink (consultez Composant Flink facultatif Dataproc pour créer un cluster Dataproc permettant d'exécuter des jobs Flink)
Fichiers de données du calendrier des applications créés par YARN Timeline Service v2 et stockés dans une instance Bigtable.
Journaux d'agrégation YARN
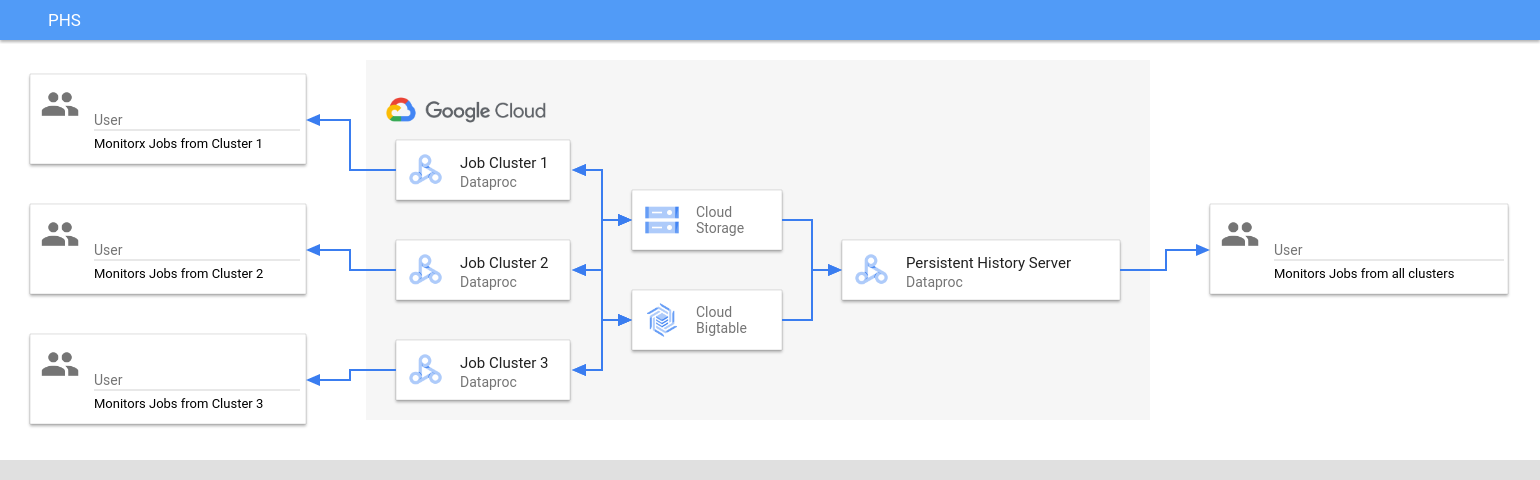
Le serveur d'historique persistant accède aux fichiers d'historique des tâches Spark et MapReduce, aux fichiers d'historique des tâches Flink et aux fichiers journaux YARN écrits dans Cloud Storage pendant la durée de vie des clusters de tâches Dataproc, et les affiche.
Limites
La version de l'image du cluster PHS et celle du ou des clusters de jobs Dataproc doivent correspondre. Par exemple, vous pouvez utiliser un cluster PHS de version 2.0 de l'image Dataproc pour afficher les fichiers d'historique des tâches exécutées sur des clusters de tâches de version 2.0 de l'image Dataproc situés dans le projet où se trouve le cluster PHS.
Un cluster PHS n'est pas compatible avec Kerberos ni avec l'authentification personnelle.
Créer un cluster Dataproc PHS
Vous pouvez exécuter la commande gcloud dataproc clusters create suivante dans un terminal local ou dans Cloud Shell avec les indicateurs et les propriétés de cluster suivants pour créer un cluster Dataproc à nœud unique du serveur d'historique persistant.
gcloud dataproc clusters create CLUSTER_NAME \ --project=PROJECT \ --region=REGION \ --single-node \ --enable-component-gateway \ --optional-components=COMPONENT \ --properties=PROPERTIES
- CLUSTER_NAME : spécifiez le nom du cluster PHS.
- PROJECT : spécifiez le projet à associer au cluster PHS. Ce projet doit être le même que celui associé au cluster qui exécute vos jobs (voir Créer un cluster de jobs Dataproc).
- REGION : spécifiez une région Compute Engine dans laquelle le cluster PHS sera situé.
--single-node: un cluster PHS est un cluster à nœud unique Dataproc.--enable-component-gateway: cette option active les interfaces Web de la passerelle des composants sur le cluster PHS.- COMPONENT : utilisez cette option pour installer un ou plusieurs composants facultatifs sur le cluster. Vous devez spécifier le composant facultatif
FLINKpour exécuter le service Web Flink HistoryServer sur le cluster PHS afin d'afficher les fichiers d'historique des tâches Flink. - PROPERTIES. Spécifiez une ou plusieurs propriétés de cluster.
Si vous le souhaitez, ajoutez l'indicateur --image-version pour spécifier la version de l'image du cluster PHS. La version de l'image PHS doit correspondre à celle des clusters de jobs Dataproc. Consultez les limites.
Remarques :
- Les exemples de valeurs de propriété de cette section utilisent un caractère générique "*" pour permettre au serveur d'historique persistant de faire correspondre plusieurs répertoires du bucket spécifié et écrits par différents clusters de tâches (mais consultez la section Considérations d'efficacité des caractères génériques).
- Des indicateurs
--propertiesdistincts sont présentés dans les exemples suivants pour faciliter la lecture. Lorsque vous utilisezgcloud dataproc clusters createpour créer un cluster Dataproc sur Compute Engine, nous vous recommandons d'utiliser un indicateur--propertiespour spécifier une liste de propriétés séparées par des virgules (voir Format des propriétés de cluster).
Propriétés :
yarn:yarn.nodemanager.remote-app-log-dir=gs://bucket-name/*/yarn-logs: ajoutez cette propriété pour spécifier l'emplacement Cloud Storage où le serveur d'historique persistant accède aux journaux YARN écrits par les clusters de tâches.spark:spark.history.fs.logDirectory=gs://bucket-name/*/spark-job-history: Ajoutez cette propriété pour activer l'historique des tâches Spark persistantes. Cette propriété spécifie l'emplacement où le serveur d'historique persistant accède aux journaux de l'historique des tâches Spark écrits par les clusters de tâches.Dans les clusters Dataproc 2.0 et versions ultérieures, les deux propriétés suivantes doivent également être définies pour activer les journaux d'historique Spark du PHS (voir Options de configuration du serveur d'historique Spark). La valeur
spark.history.custom.executor.log.urlest une valeur littérale qui contient des {{ESPACES RÉSERVÉS}} pour les variables qui seront définies par le serveur d'historique persistant. Ces variables ne sont pas définies par les utilisateurs. Transmettez la valeur de la propriété telle qu'elle est indiquée.--properties=spark:spark.history.custom.executor.log.url.applyIncompleteApplication=false
--properties=spark:spark.history.custom.executor.log.url={{YARN_LOG_SERVER_URL}}/{{NM_HOST}}:{{NM_PORT}}/{{CONTAINER_ID}}/{{CONTAINER_ID}}/{{USER}}/{{FILE_NAME}}mapred:mapreduce.jobhistory.read-only.dir-pattern=gs://bucket-name/*/mapreduce-job-history/done: Ajoutez cette propriété pour activer l'historique des tâches MapReduce persistantes. Cette propriété spécifie l'emplacement Cloud Storage où le serveur d'historique persistant accède aux journaux de l'historique des tâches MapReduce écrits par les clusters de tâches.dataproc:yarn.atsv2.bigtable.instance=projects/project-id/instance_id/bigtable-instance-id: Après avoir configuré le service Yarn Timeline Service v2, ajoutez cette propriété pour utiliser le cluster PHS afin d'afficher les données de chronologie dans les interfaces Web YARN Application Timeline Service V2 et Tez (consultez Interfaces Web de la passerelle de composants).flink:historyserver.archive.fs.dir=gs://bucket-name/*/flink-job-history/completed-jobs: Utilisez cette propriété pour configurer leHistoryServerFlink afin de surveiller une liste de répertoires séparés par une virgule.
Exemples de propriétés :
--properties=spark:spark.history.fs.logDirectory=gs://bucket-name/*/spark-job-history
--properties=mapred:mapreduce.jobhistory.read-only.dir-pattern=gs://bucket-name/*/mapreduce-job-history/done
--properties=flink:flink.historyserver.archive.fs.dir=gs://bucket-name/*/flink-job-history/completed-jobs
Créer un cluster de tâches Dataproc
Vous pouvez exécuter la commande suivante dans un terminal local ou dans Cloud Shell pour créer un cluster de tâches Dataproc qui exécute des tâches et écrit des fichiers d'historique des tâches dans un serveur d'historique persistant (PHS).
gcloud dataproc clusters create CLUSTER_NAME \ --project=PROJECT \ --region=REGION \ --optional-components=COMPONENT \ --enable-component-gateway \ --properties=PROPERTIES \ other args ...
- CLUSTER_NAME : spécifiez le nom du cluster de jobs.
- PROJECT : spécifiez le projet associé au cluster de jobs.
- REGION : spécifiez la région Compute Engine dans laquelle le cluster de tâches sera situé.
--enable-component-gateway: cette option active les interfaces Web de la passerelle des composants sur le cluster de tâches.- COMPONENT : utilisez cette option pour installer un ou plusieurs composants facultatifs sur le cluster. Spécifiez le composant facultatif
FLINKpour exécuter des jobs Flink sur le cluster. PROPERTIES : ajoutez une ou plusieurs des propriétés de cluster suivantes pour définir des emplacements Cloud Storage non définis par défaut et d'autres propriétés de cluster de tâches liées au serveur d'historique persistant.
Remarques :
- Les exemples de valeurs de propriété de cette section utilisent un caractère générique "*" pour permettre au serveur d'historique persistant de faire correspondre plusieurs répertoires du bucket spécifié et écrits par différents clusters de tâches (mais consultez la section Considérations d'efficacité des caractères génériques).
- Des indicateurs
--propertiesdistincts sont présentés dans les exemples suivants pour faciliter la lecture. Lorsque vous utilisezgcloud dataproc clusters createpour créer un cluster Dataproc sur Compute Engine, nous vous recommandons d'utiliser un indicateur--propertiespour spécifier une liste de propriétés séparées par des virgules (voir Format des propriétés de cluster).
Propriétés :
yarn:yarn.nodemanager.remote-app-log-dir: par défaut, les journaux YARN agrégés sont activés sur les clusters de tâches Dataproc et écrits dans le bucket temporaire du cluster. Ajoutez cette propriété pour spécifier un autre emplacement Cloud Storage où le cluster écrira les journaux d'agrégation pour que le serveur d'historique persistant puisse y accéder.--properties=yarn:yarn.nodemanager.remote-app-log-dir=gs://bucket-name/directory-name/yarn-logs
spark:spark.history.fs.logDirectoryetspark:spark.eventLog.dir: par défaut, les fichiers d'historique des tâches Spark sont enregistrés dans letemp bucketdu cluster, dans le répertoire/spark-job-history. Vous pouvez ajouter ces propriétés pour spécifier différents emplacements Cloud Storage pour ces fichiers. Si les deux propriétés sont utilisées, elles doivent pointer vers des répertoires situés dans le même bucket.--properties=spark:spark.history.fs.logDirectory=gs://bucket-name/directory-name/spark-job-history
--properties=spark:spark.eventLog.dir=gs://bucket-name/directory-name/spark-job-history
mapred:mapreduce.jobhistory.done-diretmapred:mapreduce.jobhistory.intermediate-done-dir: par défaut, les fichiers de l'historique des tâches MapReduce sont enregistrés dans letemp bucketdu cluster, dans les répertoires/mapreduce-job-history/doneet/mapreduce-job-history/intermediate-done. L'emplacementmapreduce.jobhistory.intermediate-done-dirintermédiaire est un espace de stockage temporaire. Les fichiers intermédiaires sont déplacés vers l'emplacementmapreduce.jobhistory.done-dirune fois la tâche MapReduce terminée. Vous pouvez ajouter ces propriétés pour spécifier différents emplacements Cloud Storage pour ces fichiers. Si les deux propriétés sont utilisées, elles doivent pointer vers des répertoires situés dans le même bucket.--properties=mapred:mapreduce.jobhistory.done-dir=gs://bucket-name/directory-name/mapreduce-job-history/done
--properties=mapred:mapreduce.jobhistory.intermediate-done-dir=gs://bucket-name/directory-name/mapreduce-job-history/intermediate-done
spark:spark.history.fs.gs.outputstream.type: cette propriété s'applique aux clusters de version d'image2.0et2.1qui utilisent la version2.0.xdu connecteur Cloud Storage (version par défaut du connecteur pour les clusters de version d'image2.0et2.1). Il contrôle la façon dont les jobs Spark envoient des données à Cloud Storage. Le paramètre par défaut estBASIC, qui envoie les données à Cloud Storage une fois le job terminé. Lorsque la valeur est définie surFLUSHABLE_COMPOSITE, les données sont copiées dans Cloud Storage à intervalles réguliers pendant l'exécution du job, comme défini parspark:spark.history.fs.gs.outputstream.sync.min.interval.ms.--properties=spark:spark.history.fs.gs.outputstream.type=FLUSHABLE_COMPOSITE
spark:spark.history.fs.gs.outputstream.sync.min.interval.ms: cette propriété s'applique aux clusters de version d'image2.0et2.1qui utilisent la version2.0.xdu connecteur Cloud Storage (version par défaut du connecteur pour les clusters de version d'image2.0et2.1). Il contrôle la fréquence (en millisecondes) à laquelle les données sont transférées vers Cloud Storage lorsquespark:spark.history.fs.gs.outputstream.typeest défini surFLUSHABLE_COMPOSITE. L'intervalle de temps par défaut est5000ms. La valeur de l'intervalle de temps en millisecondes peut être spécifiée avec ou sans l'ajout du suffixems.--properties=spark:spark.history.fs.gs.outputstream.sync.min.interval.ms=INTERVALms
spark:spark.history.fs.gs.outputstream.sync.min.interval: cette propriété s'applique aux clusters de version d'image2.2et ultérieures qui utilisent le connecteur Cloud Storage version3.0.x(version par défaut du connecteur pour les clusters de version d'image2.2). Elle remplace la propriétéspark:spark.history.fs.gs.outputstream.sync.min.interval.msprécédente et accepte les valeurs avec suffixe temporel, telles quems,setm. Il contrôle la fréquence à laquelle les données sont transférées vers Cloud Storage lorsquespark:spark.history.fs.gs.outputstream.typeest défini surFLUSHABLE_COMPOSITE.--properties=spark:spark.history.fs.gs.outputstream.sync.min.interval=INTERVAL
dataproc:yarn.atsv2.bigtable.instance: après avoir configuré le service Yarn Timeline Service v2, ajoutez cette propriété pour écrire les données de chronologie YARN dans l'instance Bigtable spécifiée afin de les afficher dans les interfaces Web YARN Application Timeline Service V2 et Tez du cluster PHS. Remarque : La création du cluster échouera si l'instance Bigtable n'existe pas.--properties=dataproc:yarn.atsv2.bigtable.instance=projects/project-id/instance_id/bigtable-instance-id
flink:jobhistory.archive.fs.dir: Flink JobManager archive les jobs Flink terminés en important les informations archivées sur les jobs dans un répertoire du système de fichiers. Utilisez cette propriété pour définir le répertoire d'archive dansflink-conf.yaml.--properties=flink:jobmanager.archive.fs.dir=gs://bucket-name/job-cluster-1/flink-job-history/completed-jobs
Utiliser PHS avec des charges de travail par lot Spark
Pour utiliser le serveur d'historique persistant avec les charges de travail par lot Spark de Dataproc sans serveur :
Sélectionnez ou spécifiez le cluster PHS lorsque vous envoyez une charge de travail par lot Spark.
Utiliser PHS avec Dataproc sur Google Kubernetes Engine
Pour utiliser le serveur d'historique persistant avec Dataproc sur GKE :
Sélectionnez ou spécifiez le cluster PHS lorsque vous créez un cluster virtuel Dataproc sur GKE.
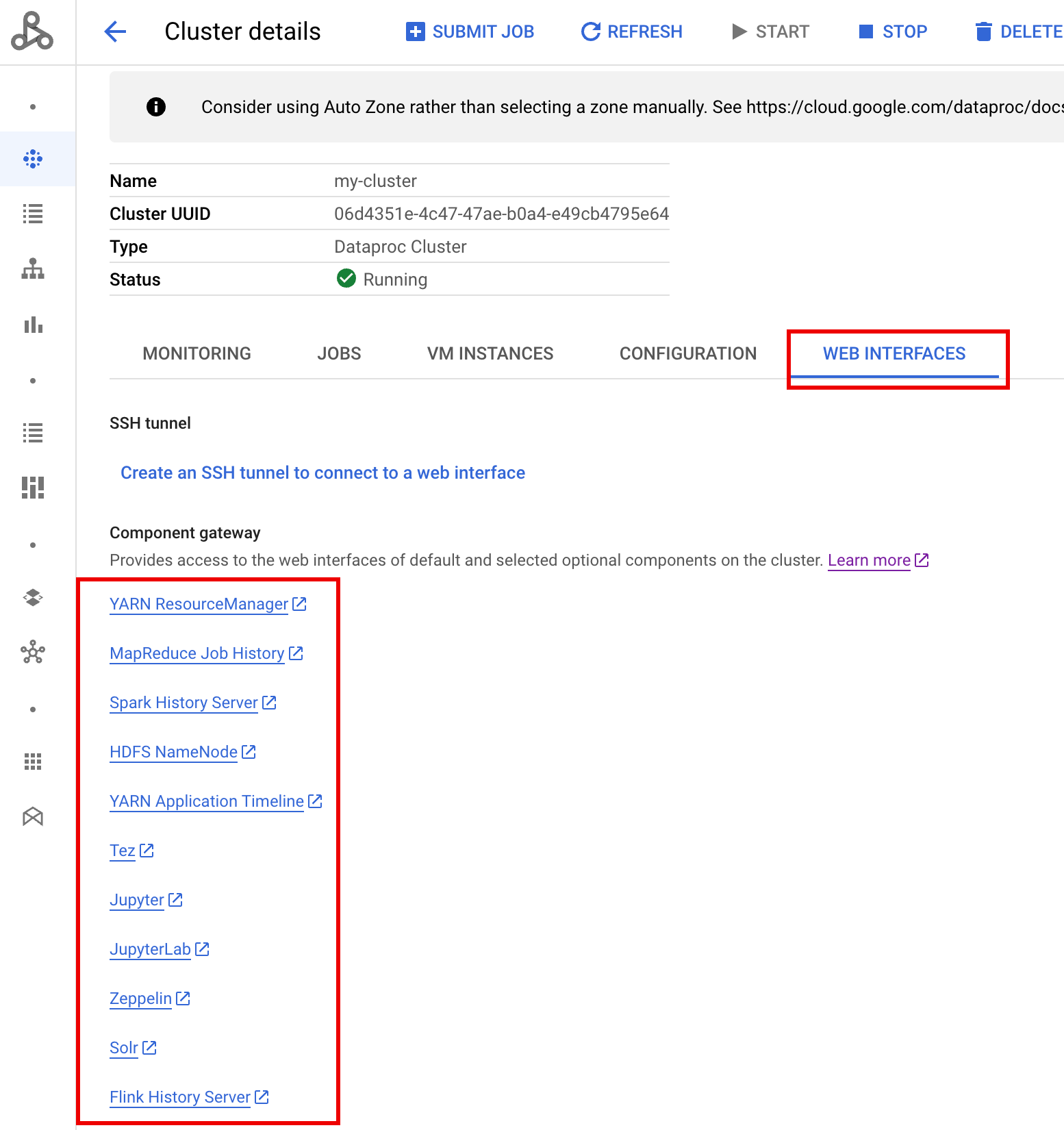
Interfaces Web de la passerelle des composants
Dans la console Google Cloud , sur la page Clusters Dataproc, cliquez sur le nom du cluster PHS pour ouvrir la page Cluster details (Détails du cluster). Dans l'onglet Interfaces Web, sélectionnez les liens de la passerelle des composants pour ouvrir les interfaces Web exécutées sur le cluster PHS.
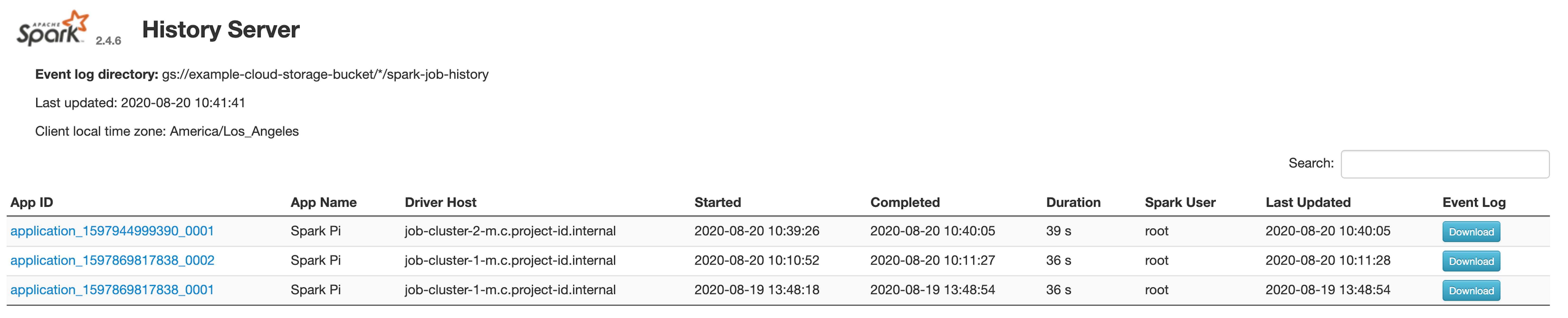
Interface Web du serveur d'historique Spark
La capture d'écran suivante montre l'interface Web du serveur d'historique Spark affichant des liens vers les tâches Spark exécutées sur les job-cluster-1 et job-cluster-2 après la configuration de spark.history.fs.logDirectory et spark:spark.eventLog.dir des clusters de tâches et des emplacements spark.history.fs.logDirectory du cluster du serveur d'historique persistant de la manière suivante :
| job-cluster-1 | gs://example-cloud-storage-bucket/job-cluster-1/spark-job-history |
| job-cluster-2 | gs://example-cloud-storage-bucket/job-cluster-2/spark-job-history |
| phs-cluster | gs://example-cloud-storage-bucket/*/spark-job-history |
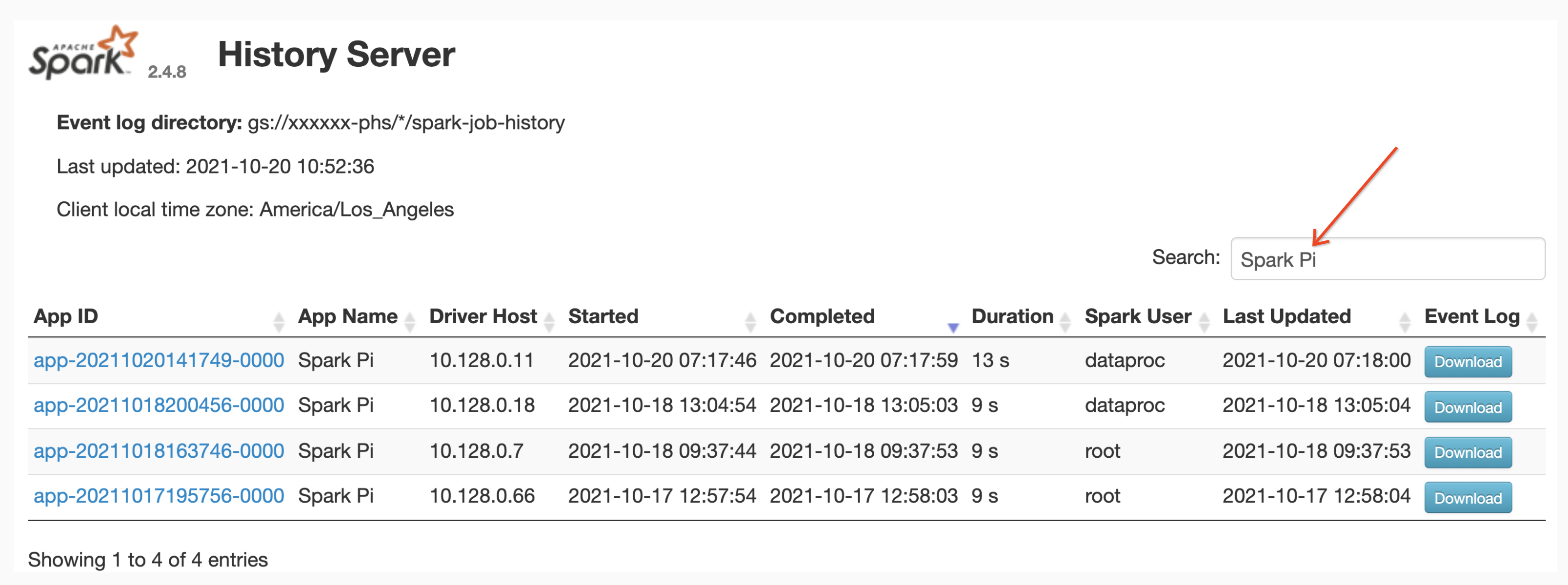
Recherche par nom d'application
Vous pouvez répertorier les tâches par nom d'application dans l'interface Web Spark History Server en saisissant un nom d'application dans le champ de recherche. Le nom de l'application peut être défini de l'une des manières suivantes (répertoriées par ordre de priorité) :
- Défini dans le code de l'application lors de la création du contexte Spark
- Défini par la propriété spark.app.name lors de l'envoi de la tâche
- Défini par Dataproc sur le nom complet de la ressource REST pour la tâche (
projects/project-id/regions/region/jobs/job-id)
Les utilisateurs peuvent saisir le nom d'une application ou d'une ressource dans le champ Rechercher pour trouver et lister les jobs.
Journaux des événements
L'interface Web du serveur d'historique Spark fournit un bouton Journal des événements sur lequel vous pouvez cliquer pour télécharger les journaux des événements Spark. Ces journaux sont utiles pour examiner le cycle de vie de l'application Spark.
Tâches Spark
Les applications Spark sont divisées en plusieurs tâches, elles-mêmes divisées en plusieurs étapes. Chaque étape peut comprendre plusieurs tâches, qui sont exécutées sur des nœuds d'exécution (nœuds de calcul).
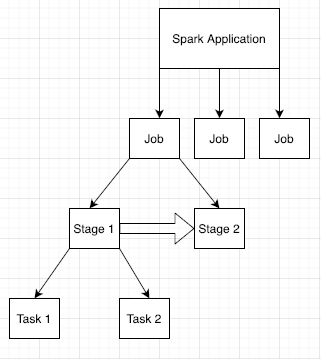
Cliquez sur un ID d'application Spark dans l'interface Web pour ouvrir la page des tâches Spark, qui fournit une chronologie des événements et un résumé des tâches au sein de l'application.
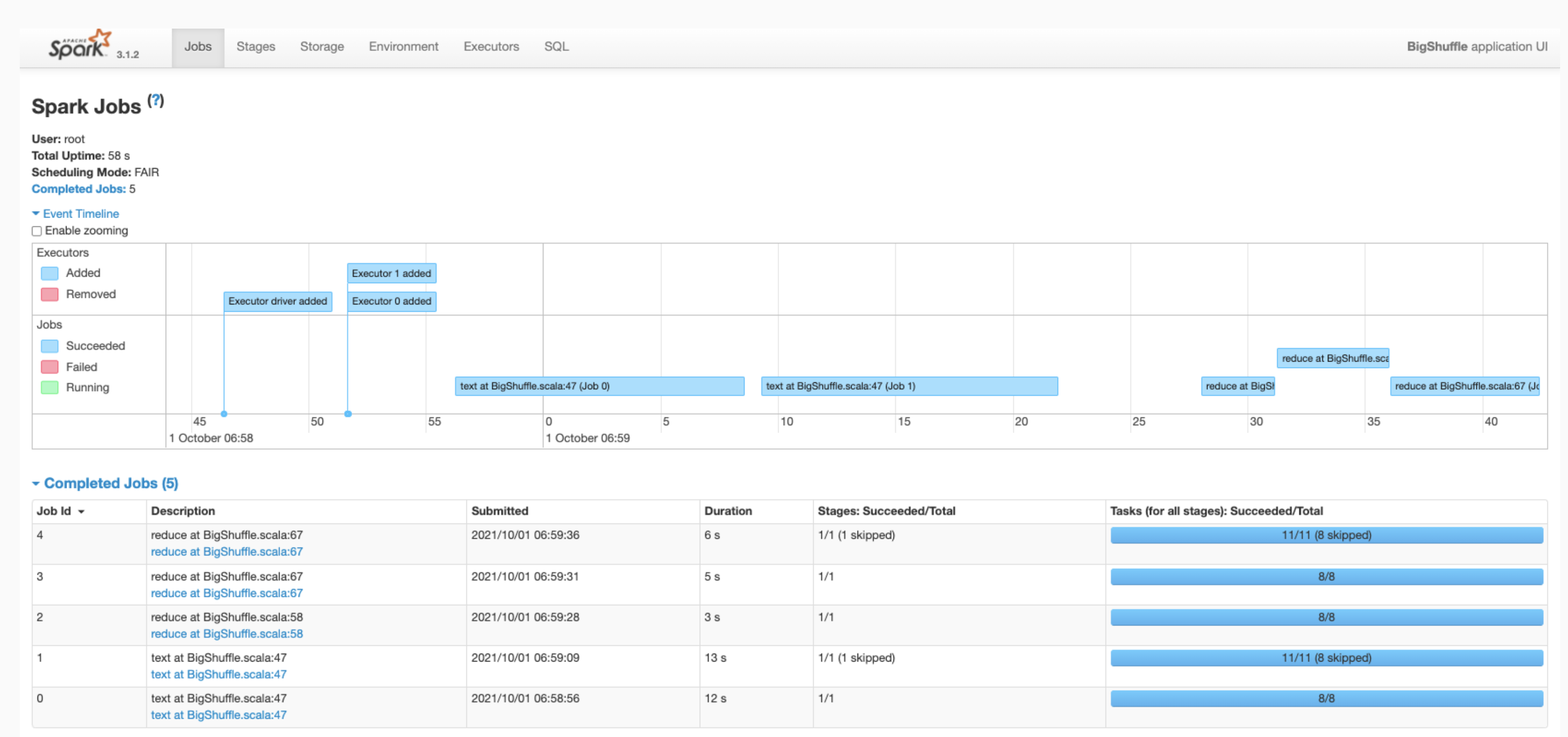
Cliquez sur une tâche pour ouvrir la page "Détails de la tâche" avec un graphe orienté acyclique et un résumé des étapes de la tâche.
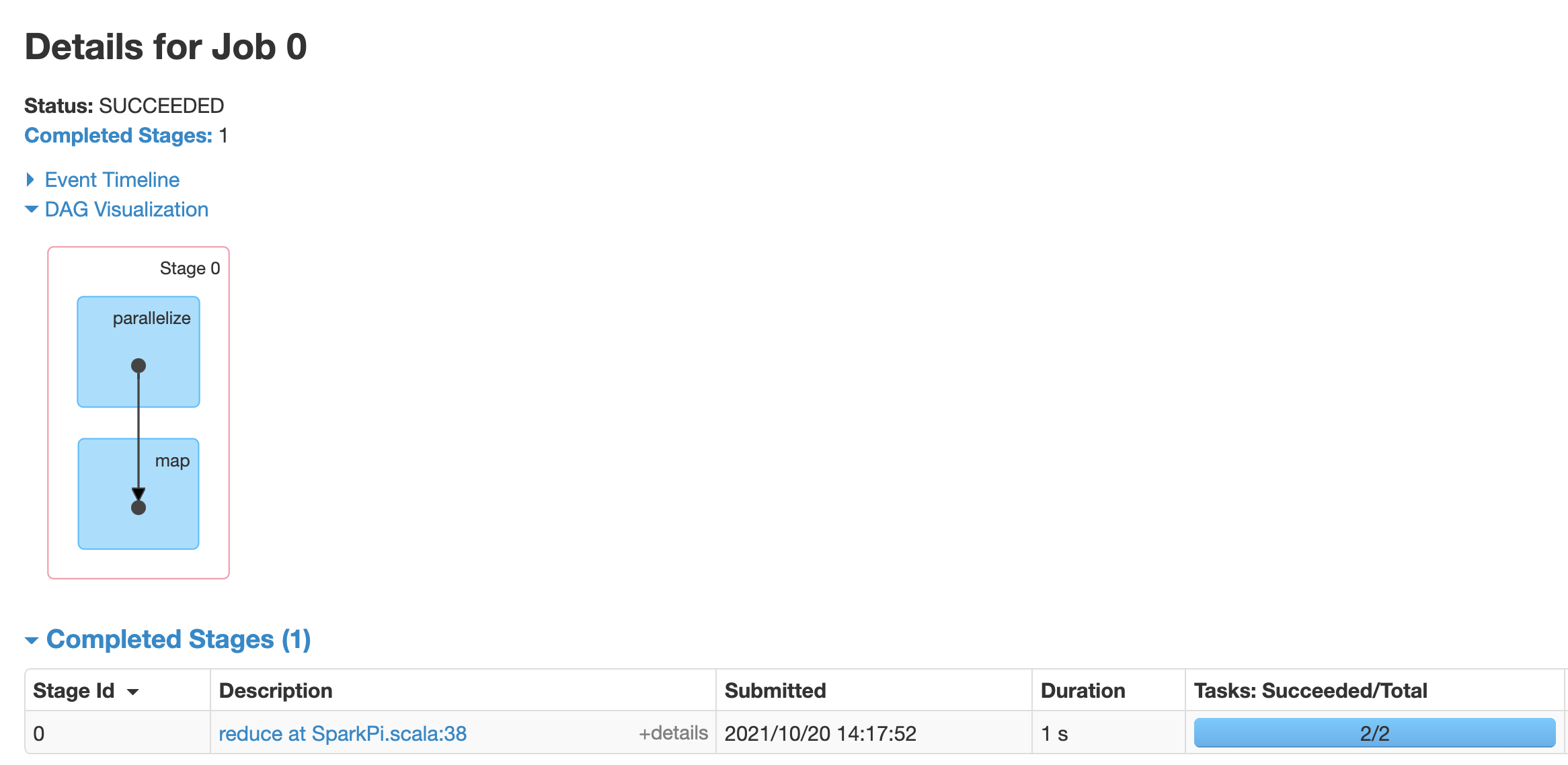
Cliquez sur une étape ou utilisez l'onglet "Étapes" pour sélectionner une étape afin d'ouvrir la page "Détails de l'étape".
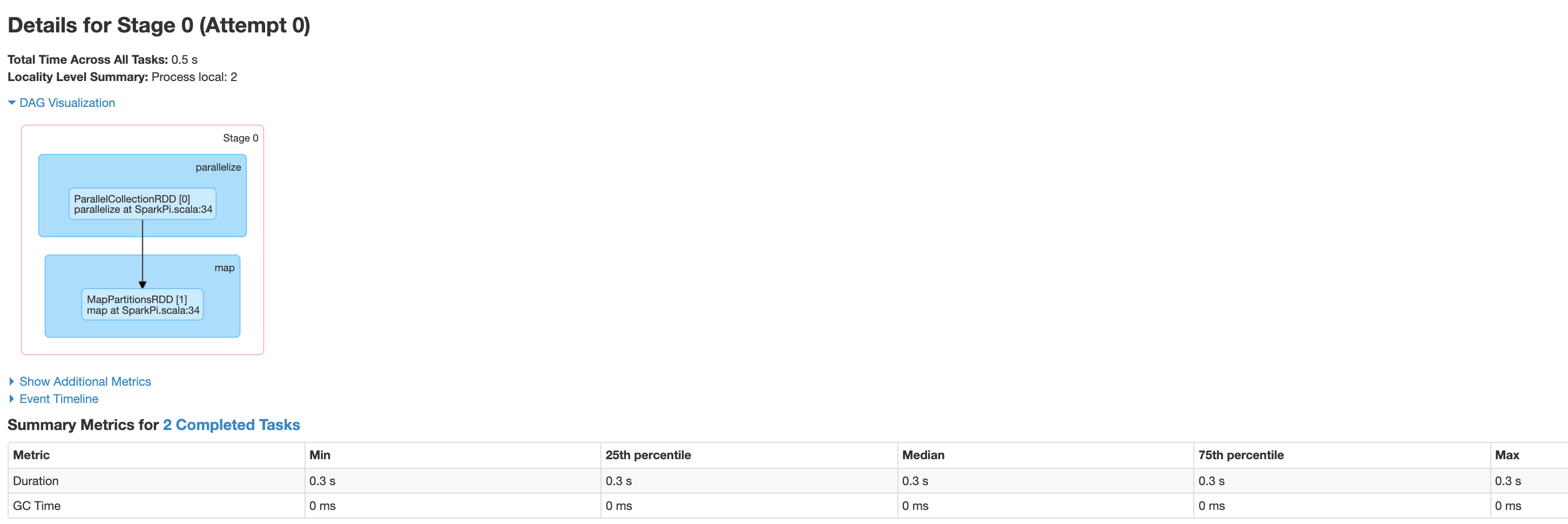
Les détails de l'étape incluent une visualisation du DAG, une chronologie des événements et des métriques pour les tâches de la phase. Vous pouvez utiliser cette page pour résoudre les problèmes liés aux tâches "étranglées", aux retards du programmeur et aux erreurs de mémoire insuffisante. Le visualiseur de DAG affiche la ligne de code à partir de laquelle la phase est dérivée, ce qui vous aide à suivre les problèmes dans le code.
Cliquez sur l'onglet "Executors" (Exécuteurs) pour en savoir plus sur le pilote et les nœuds d'exécution de l'application Spark.
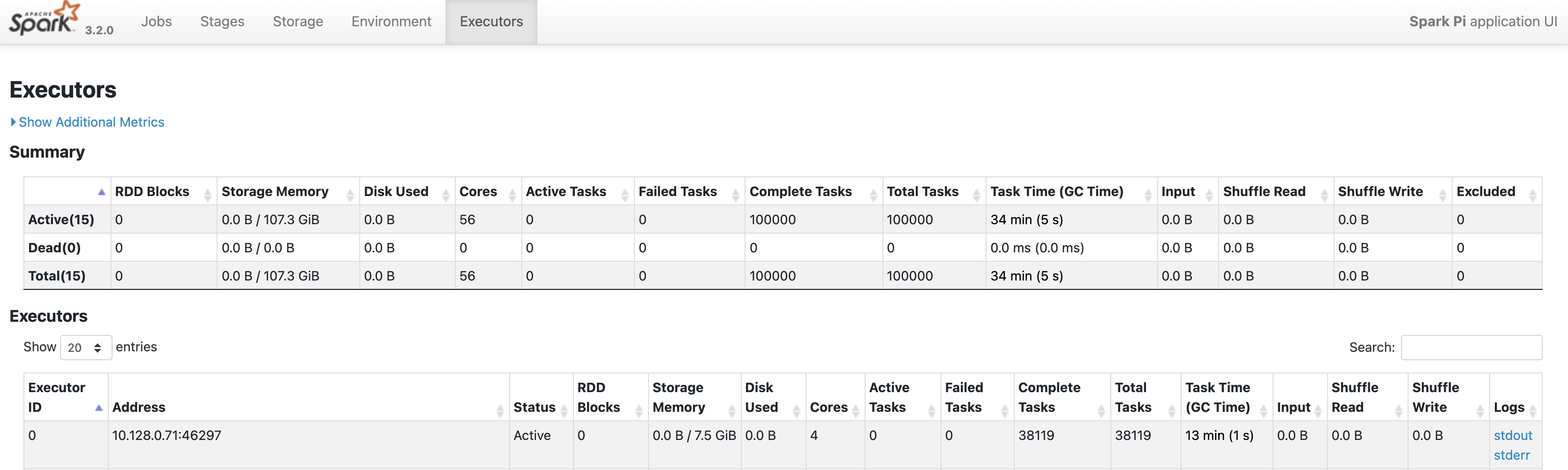
Les informations importantes de cette page incluent le nombre de cœurs et le nombre de tâches exécutées sur chaque exécuteur.
Interface Web Tez
Tez est le moteur d'exécution par défaut pour Hive et Pig sur Dataproc. L'envoi d'une tâche Hive sur un cluster de tâches Dataproc lance une application Tez.
Si vous avez configuré le service d'historique YARN v2 et défini la propriété dataproc:yarn.atsv2.bigtable.instance lorsque vous avez créé le serveur d'historique persistant et les clusters de tâches Dataproc, YARN écrit les données d'historique des tâches Hive et Pig générées dans l'instance Bigtable spécifiée pour les récupérer et les afficher dans l'interface Web Tez exécutée sur le serveur d'historique persistant.

Interface Web de la chronologie des applications YARN V2
Si vous avez configuré le service Yarn Timeline v2 et défini la propriété dataproc:yarn.atsv2.bigtable.instance lorsque vous avez créé le serveur d'historique persistant et les clusters de tâches Dataproc, YARN écrit les données de chronologie des tâches générées dans l'instance Bigtable spécifiée pour la récupération et l'affichage dans l'interface Web du service YARN Application Timeline s'exécutant sur le serveur PHS. Les jobs Dataproc sont listés dans l'onglet Activité du flux de l'interface Web.
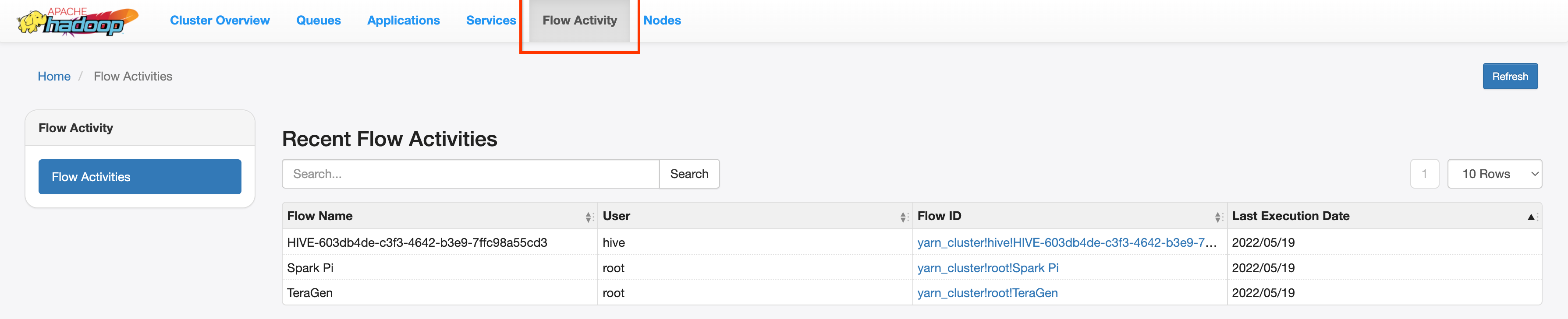
Configurer Yarn Timeline Service v2
Pour configurer Yarn Timeline Service v2, configurez une instance Bigtable et, si nécessaire, vérifiez les rôles du compte de service, comme suit :
Vérifiez les rôles du compte de service, si nécessaire. Le compte de service de VM par défaut utilisé par les VM de cluster Dataproc dispose des autorisations nécessaires pour créer et configurer l'instance Bigtable pour le service YARN Timeline. Si vous créez votre job ou votre cluster PHS avec un compte de service de VM personnalisé, le compte doit disposer du rôle Bigtable
AdministratorouBigtable User.
Schéma de table requis
La compatibilité de Dataproc PHS avec YARN Timeline Service v2 nécessite un schéma spécifique créé dans l'instance Bigtable. Dataproc crée le schéma requis lorsqu'un cluster de tâches ou un cluster PHS est créé avec la propriété dataproc:yarn.atsv2.bigtable.instance définie pour pointer vers l'instance Bigtable.
Voici le schéma d'instance Bigtable requis :
| Tables | Familles de colonnes |
|---|---|
| prod.timelineservice.application | c,i,m |
| prod.timelineservice.app_flow | m |
| prod.timelineservice.entity | c,i,m |
| prod.timelineservice.flowactivity | i |
| prod.timelineservice.flowrun | i |
| prod.timelineservice.subapplication | c,i,m |
Récupération de mémoire Bigtable
Vous pouvez configurer la récupération de mémoire Bigtable en fonction de l'âge pour les tables ATSv2 :
Installez cbt (y compris la création de
.cbrtc file).Créez la stratégie de récupération de mémoire basée sur l'âge ATSv2 :
export NUMBER_OF_DAYS = number \
cbt setgcpolicy prod.timelineservice.application c maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.application i maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.application m maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.app_flow m maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.entity c maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.entity i maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.entity m maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.flowactivity i maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.flowrun i maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.subapplication c maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.subapplication i maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.subapplication m maxage=${NUMBER_OF_DAYS}
Remarques :
NUMBER_OF_DAYS : le nombre maximal de jours est 30d.