Vous pouvez activer des composants supplémentaires tels que Flink lorsque vous créez un cluster Dataproc à l'aide de la fonctionnalité Composants facultatifs. Cette page vous explique comment créer un cluster Dataproc avec le composant facultatif Apache Flink activé (un cluster Flink), puis comment exécuter des jobs Flink sur le cluster.
Vous pouvez utiliser votre cluster Flink pour :
Exécutez des jobs Flink à l'aide de la ressource Dataproc
Jobsdepuis la console Google Cloud , la Google Cloud CLI ou l'API Dataproc.Exécutez des jobs Flink à l'aide de la CLI
flinksur le nœud maître du cluster Flink.Exécuter Flink sur un cluster kerberisé
Créer un cluster Dataproc Flink
Vous pouvez utiliser la console Google Cloud , la Google Cloud CLI ou l'API Dataproc pour créer un cluster Dataproc sur lequel le composant Flink est activé.
Recommandation : Utilisez un cluster de VM standard à un nœud maître avec le composant Flink. Les clusters Dataproc en mode haute disponibilité (avec trois VM maîtres) ne sont pas compatibles avec le mode haute disponibilité Flink.
Console
Pour créer un cluster Dataproc Flink à l'aide de la console Google Cloud , procédez comme suit :
Ouvrez la page Dataproc Créer un cluster Dataproc sur Compute Engine.
- Le panneau Configurer un cluster est sélectionné.
- Dans la section Gestion des versions, confirmez ou modifiez le type et la version de l'image. La version de l'image du cluster détermine la version du composant Flink installé sur le cluster.
- La version de l'image doit être 1.5 ou ultérieure pour activer le composant Flink sur le cluster (consultez Versions Dataproc compatibles pour afficher la liste des versions de composant incluses dans chaque version d'image Dataproc).
- La version de l'image doit être [TBD] ou ultérieure pour exécuter des jobs Flink avec l'API Jobs Dataproc (voir Exécuter des jobs Flink Dataproc).
- Dans la section Composants :
- Sous Passerelle des composants, sélectionnez Activer la passerelle des composants. Vous devez activer la passerelle des composants pour activer le lien de la passerelle des composants vers l'interface utilisateur du serveur d'historique Flink. L'activation de la passerelle des composants permet également d'accéder à l'interface Web du gestionnaire de tâches Flink exécutée sur le cluster Flink.
- Sous Composants facultatifs, sélectionnez Flink et les autres composants facultatifs à activer sur votre cluster.
- Dans la section Gestion des versions, confirmez ou modifiez le type et la version de l'image. La version de l'image du cluster détermine la version du composant Flink installé sur le cluster.
Cliquez sur le panneau Personnaliser le cluster (facultatif).
Dans la section Propriétés du cluster, cliquez sur Ajouter des propriétés pour chaque propriété de cluster facultative à ajouter à votre cluster. Vous pouvez ajouter des propriétés avec le préfixe
flinkpour configurer les propriétés Flink dans/etc/flink/conf/flink-conf.yaml, qui serviront de valeurs par défaut pour les applications Flink que vous exécutez sur le cluster.Exemples :
- Définissez
flink:historyserver.archive.fs.dirpour spécifier l'emplacement Cloud Storage dans lequel écrire les fichiers d'historique des tâches Flink (cet emplacement sera utilisé par le serveur d'historique Flink exécuté sur le cluster Flink). - Définissez les emplacements de tâches Flink avec
flink:taskmanager.numberOfTaskSlots=n.
- Définissez
Dans la section Métadonnées de cluster personnalisées, cliquez sur Ajouter des métadonnées pour ajouter des métadonnées facultatives. Par exemple, ajoutez
flink-start-yarn-sessiontruepour exécuter le démon Flink YARN (/usr/bin/flink-yarn-daemon) en arrière-plan sur le nœud maître du cluster afin de démarrer une session Flink YARN (voir Mode session Flink).
Si vous utilisez une version d'image Dataproc 2.0 ou antérieure, cliquez sur le panneau Gérer la sécurité (facultatif), puis, sous Accès au projet, sélectionnez
Enables the cloud-platform scope for this cluster. Le champ d'applicationcloud-platformest activé par défaut lorsque vous créez un cluster qui utilise la version 2.1 ou ultérieure de l'image Dataproc.
- Le panneau Configurer un cluster est sélectionné.
Cliquez sur Créer pour créer le cluster.
gcloud
Pour créer un cluster Dataproc Flink à l'aide de la gcloud CLI, exécutez la commande gcloud dataproc clusters create en local dans une fenêtre de terminal ou dans Cloud Shell :
gcloud dataproc clusters create CLUSTER_NAME \ --region=REGION \ --image-version=DATAPROC_IMAGE_VERSION \ --optional-components=FLINK \ --enable-component-gateway \ --properties=PROPERTIES ... other flags
Remarques :
- CLUSTER_NAME : spécifiez le nom du cluster.
- REGION : spécifiez une région Compute Engine dans laquelle le cluster sera situé.
DATAPROC_IMAGE_VERSION : vous pouvez spécifier la version de l'image à utiliser sur le cluster. La version de l'image du cluster détermine la version du composant Flink installé sur le cluster.
La version de l'image doit être 1.5 ou ultérieure pour activer le composant Flink sur le cluster. (Consultez Versions Dataproc compatibles pour afficher la liste des versions de composant incluses dans chaque version d'image Dataproc.)
La version de l'image doit être [TBD] ou ultérieure pour exécuter des jobs Flink avec l'API Dataproc Jobs (consultez Exécuter des jobs Flink Dataproc).
--optional-components: vous devez spécifier le composantFLINKpour exécuter les jobs Flink et le service Web Flink HistoryServer sur le cluster.--enable-component-gateway: vous devez activer la passerelle des composants pour activer le lien de la passerelle des composants vers l'interface utilisateur du serveur d'historique Flink. L'activation de la passerelle des composants permet également d'accéder à l'interface Web du gestionnaire de tâches Flink exécutée sur le cluster Flink.PROPERTIES. Vous pouvez également spécifier une ou plusieurs propriétés de cluster.
Lorsque vous créez des clusters Dataproc avec les versions d'image
2.0.67+ et2.1.15+, vous pouvez utiliser l'indicateur--propertiespour configurer les propriétés Flink dans/etc/flink/conf/flink-conf.yaml, qui serviront de valeurs par défaut pour les applications Flink que vous exécutez sur le cluster.Vous pouvez définir
flink:historyserver.archive.fs.dirpour spécifier l'emplacement Cloud Storage dans lequel écrire les fichiers d'historique des tâches Flink (cet emplacement sera utilisé par le serveur d'historique Flink exécuté sur le cluster Flink).Exemple pour plusieurs établissements :
--properties=flink:historyserver.archive.fs.dir=gs://my-bucket/my-flink-cluster/completed-jobs,flink:taskmanager.numberOfTaskSlots=2Autres options :
- Vous pouvez ajouter l'option facultative
--metadata flink-start-yarn-session=truepour exécuter le démon Flink YARN (/usr/bin/flink-yarn-daemon) en arrière-plan sur le nœud maître du cluster afin de démarrer une session Flink YARN (voir Mode session Flink).
- Vous pouvez ajouter l'option facultative
Lorsque vous utilisez des versions d'image 2.0 ou antérieures, vous pouvez ajouter l'indicateur
--scopes=https://www.googleapis.com/auth/cloud-platformpour activer l'accès aux API Google Cloud par votre cluster (voir Bonnes pratiques concernant les autorisations). Le champ d'applicationcloud-platformest activé par défaut lorsque vous créez un cluster qui utilise la version 2.1 ou ultérieure de l'image Dataproc.
API
Pour créer un cluster Dataproc Flink à l'aide de l'API Dataproc, envoyez une requête clusters.create comme suit :
Remarques :
Définissez SoftwareConfig.Component sur
FLINK.Vous pouvez éventuellement définir
SoftwareConfig.imageVersionpour spécifier la version de l'image à utiliser sur le cluster. La version de l'image du cluster détermine la version du composant Flink installé sur le cluster.La version de l'image doit être 1.5 ou ultérieure pour activer le composant Flink sur le cluster. (Consultez Versions Dataproc compatibles pour afficher la liste des versions de composant incluses dans chaque version d'image Dataproc.)
La version de l'image doit être [TBD] ou ultérieure pour exécuter des jobs Flink avec l'API Dataproc Jobs (consultez Exécuter des jobs Flink Dataproc).
Définissez EndpointConfig.enableHttpPortAccess sur
truepour activer le lien de la passerelle des composants vers l'interface utilisateur du serveur d'historique Flink. L'activation de la passerelle des composants permet également d'accéder à l'interface Web du gestionnaire de tâches Flink exécutée sur le cluster Flink.Vous pouvez éventuellement définir
SoftwareConfig.propertiespour spécifier une ou plusieurs propriétés de cluster.- Vous pouvez spécifier des propriétés Flink qui serviront de valeurs par défaut pour les applications Flink que vous exécutez sur le cluster. Par exemple, vous pouvez définir
flink:historyserver.archive.fs.dirpour spécifier l'emplacement Cloud Storage dans lequel écrire les fichiers d'historique des jobs Flink (cet emplacement sera utilisé par le serveur d'historique Flink exécuté sur le cluster Flink).
- Vous pouvez spécifier des propriétés Flink qui serviront de valeurs par défaut pour les applications Flink que vous exécutez sur le cluster. Par exemple, vous pouvez définir
Vous pouvez éventuellement définir les options suivantes :
GceClusterConfig.metadata. Par exemple, pour spécifierflink-start-yarn-sessiontrueafin d'exécuter le démon Flink YARN (/usr/bin/flink-yarn-daemon) en arrière-plan sur le nœud maître du cluster pour démarrer une session Flink YARN (voir Mode session Flink).- Définissez GceClusterConfig.serviceAccountScopes sur
https://www.googleapis.com/auth/cloud-platform(champ d'applicationcloud-platform) lorsque vous utilisez des versions d'image 2.0 ou antérieures pour permettre à votre cluster d'accéder aux API Google Cloud(consultez Bonnes pratiques concernant les champs d'application). Le champ d'applicationcloud-platformest activé par défaut lorsque vous créez un cluster qui utilise la version 2.1 ou ultérieure de l'image Dataproc.
Après avoir créé un cluster Flink
- Utilisez le lien
Flink History Serverdans la passerelle des composants pour afficher le serveur d'historique Flink exécuté sur le cluster Flink. - Utilisez
YARN ResourceManager linkdans la passerelle de composants pour afficher l'interface Web du gestionnaire de tâches Flink exécutée sur le cluster Flink . - Créez un serveur d'historique persistant Dataproc pour afficher les fichiers d'historique des tâches Flink écrits par des clusters Flink existants et supprimés.
Exécuter des jobs Flink à l'aide de la ressource Dataproc Jobs
Vous pouvez exécuter des jobs Flink à l'aide de la ressource Jobs Dataproc depuis la consoleGoogle Cloud , Google Cloud CLI ou l'API Dataproc.
Console
Pour envoyer un exemple de job Flink WordCount depuis la console :
Ouvrez la page Dataproc Envoyer une tâche dans la consoleGoogle Cloud de votre navigateur.
Renseignez les champs de la page Submit a job (Envoyer une tâche) :
- Sélectionnez le nom du cluster dans la liste des clusters.
- Définissez le champ Job type (Type de tâche) sur
Flink. - Définissez le champ Main class or jar (Classe principale ou fichier JAR) sur
org.apache.flink.examples.java.wordcount.WordCount. - Définissez Fichiers JAR sur
file:///usr/lib/flink/examples/batch/WordCount.jar.file:///désigne un fichier situé sur le cluster. Dataproc a installéWordCount.jarlors de la création du cluster Flink.- Ce champ accepte également un chemin d'accès à Cloud Storage (
gs://BUCKET/JARFILE) ou un chemin d'accès au système de fichiers distribué Hadoop (HDFS, Hadoop Distributed File System) (hdfs://PATH_TO_JAR).
Cliquez sur Envoyer.
- Les résultats du pilote de tâches s'affichent sur la page Informations sur la tâche.
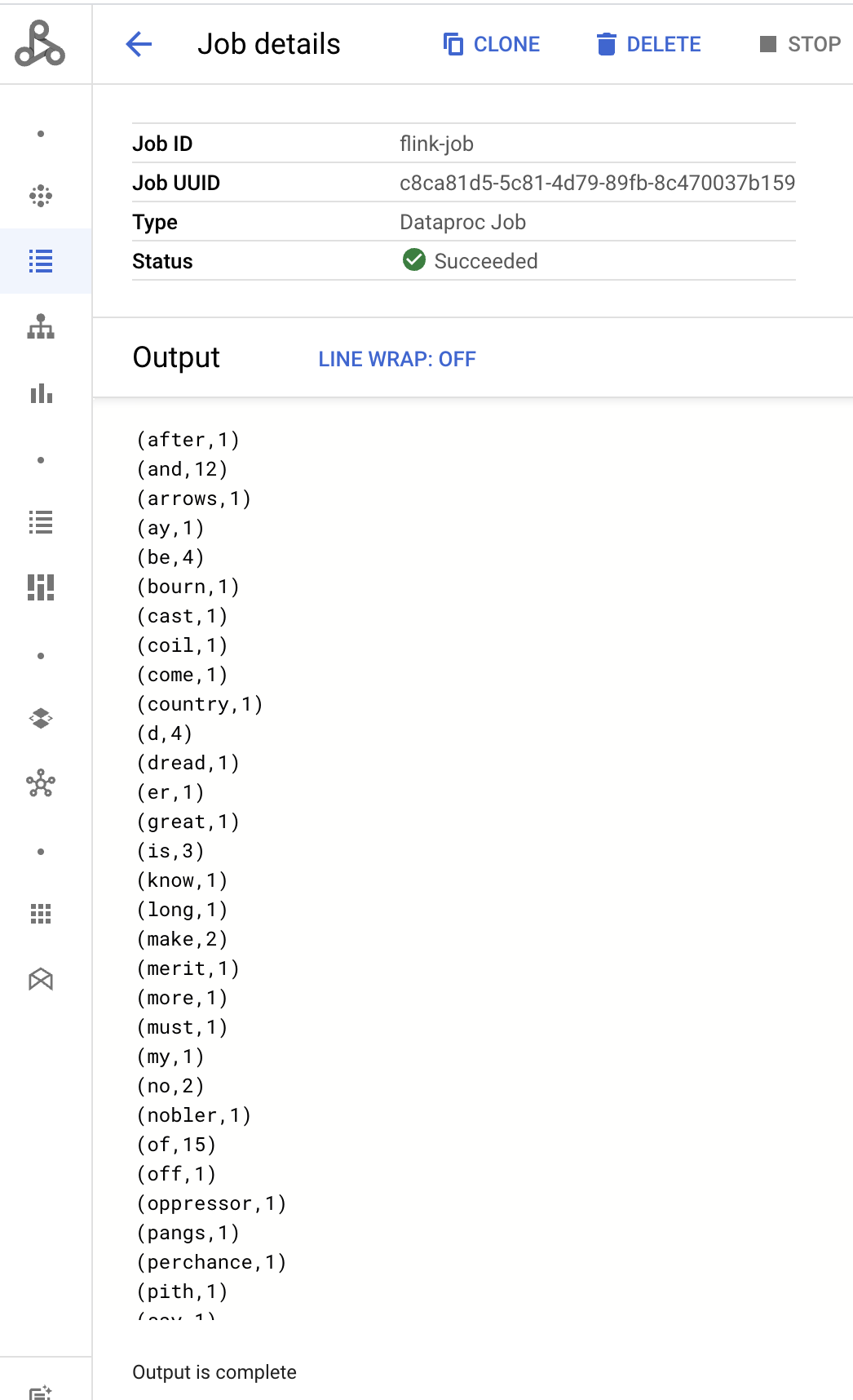
- Les jobs Flink sont listés sur la page Jobs de Dataproc dans la console Google Cloud .
- Cliquez sur Arrêter ou Supprimer sur la page Tâches ou Informations sur la tâche pour arrêter ou supprimer une tâche.
gcloud
Pour envoyer un job Flink à un cluster Dataproc Flink, exécutez la commande gcloud dataproc jobs submit de la CLI gcloud en local dans une fenêtre de terminal ou dans Cloud Shell.
gcloud dataproc jobs submit flink \ --cluster=CLUSTER_NAME \ --region=REGION \ --class=MAIN_CLASS \ --jar=JAR_FILE \ -- JOB_ARGS
Remarques :
- CLUSTER_NAME : spécifiez le nom du cluster Dataproc Flink auquel envoyer le job.
- REGION : spécifiez une région Compute Engine dans laquelle se trouve le cluster.
- MAIN_CLASS : spécifiez la classe
mainde votre application Flink, par exemple :org.apache.flink.examples.java.wordcount.WordCount
- JAR_FILE : spécifiez le fichier jar de l'application Flink. Vous pouvez spécifier les éléments suivants :
- Fichier JAR installé sur le cluster, à l'aide du préfixe
file:/// :file:///usr/lib/flink/examples/streaming/TopSpeedWindowing.jarfile:///usr/lib/flink/examples/batch/WordCount.jar
- Fichier jar dans Cloud Storage :
gs://BUCKET/JARFILE - Fichier JAR dans HDFS :
hdfs://PATH_TO_JAR
- Fichier JAR installé sur le cluster, à l'aide du préfixe
JOB_ARGS : vous pouvez ajouter des arguments de job après le double tiret (
--).Une fois la tâche envoyée, le résultat du pilote de tâches s'affiche dans le terminal local ou Cloud Shell.
Program execution finished Job with JobID 829d48df4ebef2817f4000dfba126e0f has finished. Job Runtime: 13610 ms ... (after,1) (and,12) (arrows,1) (ay,1) (be,4) (bourn,1) (cast,1) (coil,1) (come,1)
REST
Cette section explique comment envoyer une tâche Flink à un cluster Dataproc Flink à l'aide de l'API Dataproc jobs.submit.
Avant d'utiliser les données de requête, effectuez les remplacements suivants :
- PROJECT_ID : Google Cloud ID du projet
- REGION : région du cluster
- CLUSTER_NAME : spécifiez le nom du cluster Dataproc Flink auquel envoyer le job.
Méthode HTTP et URL :
POST https://dataproc.googleapis.com/v1/projects/PROJECT_ID/regions/REGION/jobs:submit
Corps JSON de la requête :
{
"job": {
"placement": {
"clusterName": "CLUSTER_NAME"
},
"flinkJob": {
"mainClass": "org.apache.flink.examples.java.wordcount.WordCount",
"jarFileUris": [
"file:///usr/lib/flink/examples/batch/WordCount.jar"
]
}
}
}
Pour envoyer votre requête, développez l'une des options suivantes :
Vous devriez recevoir une réponse JSON de ce type :
{
"reference": {
"projectId": "PROJECT_ID",
"jobId": "JOB_ID"
},
"placement": {
"clusterName": "CLUSTER_NAME",
"clusterUuid": "CLUSTER_UUID"
},
"flinkJob": {
"mainClass": "org.apache.flink.examples.java.wordcount.WordCount",
"args": [
"1000"
],
"jarFileUris": [
"file:///usr/lib/flink/examples/batch/WordCount.jar"
]
},
"status": {
"state": "PENDING",
"stateStartTime": "2020-10-07T20:16:21.759Z"
},
"jobUuid": "JOB_UUID"
}
- Les jobs Flink sont listés sur la page Jobs de Dataproc dans la console Google Cloud .
- Vous pouvez cliquer sur Arrêter ou Supprimer sur la page Tâches ou Informations sur la tâche de la console Google Cloud pour arrêter ou supprimer une tâche.
Exécuter des jobs Flink à l'aide de la CLI flink
Au lieu d'exécuter des tâches Flink à l'aide de la ressource Dataproc Jobs, vous pouvez exécuter des tâches Flink sur le nœud maître de votre cluster Flink à l'aide de la CLI flink.
Les sections suivantes décrivent différentes façons d'exécuter un job de CLI flink sur votre cluster Dataproc Flink.
Connectez-vous en SSH au nœud maître : utilisez l'utilitaire SSH pour ouvrir une fenêtre de terminal sur la VM maître du cluster.
Définissez le chemin de classe : initialisez le chemin de classe Hadoop à partir de la fenêtre de terminal SSH sur la VM maîtresse du cluster Flink :
export HADOOP_CLASSPATH=$(hadoop classpath)Exécuter des jobs Flink : vous pouvez exécuter des jobs Flink dans différents modes de déploiement sur YARN : mode application, mode par job et mode session.
Mode Application : le mode Application Flink est compatible avec la version 2.0 et les versions ultérieures de l'image Dataproc. Dans ce mode, la méthode
main()du job est exécutée sur le gestionnaire de jobs YARN. Le cluster s'arrête une fois le job terminé.Exemple d'envoi de tâche :
flink run-application \ -t yarn-application \ -Djobmanager.memory.process.size=1024m \ -Dtaskmanager.memory.process.size=2048m \ -Djobmanager.heap.mb=820 \ -Dtaskmanager.heap.mb=1640 \ -Dtaskmanager.numberOfTaskSlots=2 \ -Dparallelism.default=4 \ /usr/lib/flink/examples/batch/WordCount.jarRépertorier les jobs en cours d'exécution :
./bin/flink list -t yarn-application -Dyarn.application.id=application_XXXX_YYAnnuler une tâche en cours d'exécution :
./bin/flink cancel -t yarn-application -Dyarn.application.id=application_XXXX_YY <jobId>Mode par job : ce mode Flink exécute la méthode
main()du job côté client.Exemple d'envoi de tâche :
flink run \ -m yarn-cluster \ -p 4 \ -ys 2 \ -yjm 1024m \ -ytm 2048m \ /usr/lib/flink/examples/batch/WordCount.jarMode session : démarrez une session Flink YARN de longue durée, puis envoyez une ou plusieurs tâches à la session.
Démarrer une session : vous pouvez démarrer une session Flink de l'une des manières suivantes :
Créez un cluster Flink en ajoutant l'option
--metadata flink-start-yarn-session=trueà la commandegcloud dataproc clusters create(consultez Créer un cluster Dataproc Flink). Lorsque cet indicateur est activé, une fois le cluster créé, Dataproc exécute/usr/bin/flink-yarn-daemonpour démarrer une session Flink sur le cluster.L'ID d'application YARN de la session est enregistré dans
/tmp/.yarn-properties-${USER}. Vous pouvez lister l'ID avec la commandeyarn application -list.Exécutez le script Flink
yarn-session.sh, qui est préinstallé sur la VM maître du cluster, avec des paramètres personnalisés :Exemple avec des paramètres personnalisés :
/usr/lib/flink/bin/yarn-session.sh \ -s 1 \ -jm 1024m \ -tm 2048m \ -nm flink-dataproc \ --detachedExécutez le script wrapper Flink
/usr/bin/flink-yarn-daemonavec les paramètres par défaut :. /usr/bin/flink-yarn-daemon
Envoyer un job à une session : exécutez la commande suivante pour envoyer un job Flink à la session.
flink run -m <var>FLINK_MASTER_URL</var>/usr/lib/flink/examples/batch/WordCount.jar- FLINK_MASTER_URL : URL, y compris l'hôte et le port, de la VM maître Flink sur laquelle les jobs sont exécutés.
Supprimez
http:// prefixde l'URL. Cette URL est indiquée dans le résultat de la commande lorsque vous démarrez une session Flink. Vous pouvez exécuter la commande suivante pour lister cette URL dans le champTracking-URL:
yarn application -list -appId=<yarn-app-id> | sed 's#http://##' ```- FLINK_MASTER_URL : URL, y compris l'hôte et le port, de la VM maître Flink sur laquelle les jobs sont exécutés.
Supprimez
Lister les jobs dans une session : pour lister les jobs Flink dans une session, procédez de l'une des manières suivantes :
Exécutez
flink listsans arguments. La commande recherche l'ID d'application YARN de la session dans/tmp/.yarn-properties-${USER}.Obtenez l'ID d'application YARN de la session à partir de
/tmp/.yarn-properties-${USER}ou du résultat deyarn application -list, puis exécutez<code>flink list -yid YARN_APPLICATION_ID.Exécutez
flink list -m FLINK_MASTER_URL.
Arrêter une session : pour arrêter la session, obtenez l'ID d'application YARN de la session à partir de
/tmp/.yarn-properties-${USER}ou du résultat deyarn application -list, puis exécutez l'une des commandes suivantes :echo "stop" | /usr/lib/flink/bin/yarn-session.sh -id YARN_APPLICATION_IDyarn application -kill YARN_APPLICATION_ID
Exécuter des jobs Apache Beam sur Flink
Vous pouvez exécuter des tâches Apache Beam sur Dataproc à l'aide de la commande FlinkRunner.
Vous pouvez exécuter des tâches Beam sur Flink de différentes manières:
- Tâches Java Beam
- Tâches portables Beam
Tâches Java Beam
Empaquetez vos tâches Beam dans un fichier JAR. Fournissez le fichier JAR groupé avec les dépendances nécessaires à l'exécution de la tâche.
L'exemple suivant exécute une tâche Java Beam à partir du nœud maître du cluster Dataproc.
Créez un cluster Dataproc avec le composant Flink activé.
gcloud dataproc clusters create CLUSTER_NAME \ --optional-components=FLINK \ --image-version=DATAPROC_IMAGE_VERSION \ --region=REGION \ --enable-component-gateway \ --scopes=https://www.googleapis.com/auth/cloud-platform--optional-components: Flink--image-version: La version de l'image du cluster qui détermine la version Flink installée sur le cluster (par exemple, consultez les versions des composants Apache Flink répertoriées pour les quatre versions suivantes et précédentes des Versions 2.0.x de l'image).--region: région Dataproc compatible--enable-component-gateway: permet d'accéder à l'interface utilisateur du gestionnaire de tâches Flink.--scopes: activez l'accès aux API Google Cloud par votre cluster (consultez les bonnes pratiques concernant les niveaux d'accès). Le champ d'applicationcloud-platformest activé par défaut (vous n'avez pas besoin d'inclure ce paramètre d'indicateur) lorsque vous créez un cluster qui utilise la version d'image Dataproc 2.1 ou ultérieure.
Utilisez l'utilitaire SSH pour ouvrir une fenêtre de terminal sur le nœud maître du cluster Flink.
Démarrez une session YARN Flink sur le nœud maître du cluster Dataproc.
. /usr/bin/flink-yarn-daemonNotez la version de Flink sur votre cluster Dataproc.
flink --versionSur votre ordinateur local, générez l'exemple canonique de nombre de mots Beam en Java.
Choisissez une version de Beam compatible avec la version de Flink de votre cluster Dataproc. Consultez le tableau Compatibilité avec les versions de Flink qui répertorie la compatibilité des versions de Beam-Flink.
Ouvrez le fichier POM généré. Vérifiez la version de l'exécuteur Beam Flink spécifiée par le tag
<flink.artifact.name>. Si la version de l'exécuteur Beam Flink dans le nom de l'artefact Flink ne correspond pas à la version Flink de votre cluster, mettez à jour le numéro de version.mvn archetype:generate \ -DarchetypeGroupId=org.apache.beam \ -DarchetypeArtifactId=beam-sdks-java-maven-archetypes-examples \ -DarchetypeVersion=BEAM_VERSION \ -DgroupId=org.example \ -DartifactId=word-count-beam \ -Dversion="0.1" \ -Dpackage=org.apache.beam.examples \ -DinteractiveMode=falseEmpaqueter l'exemple de décompte de mots.
mvn package -Pflink-runnerImportez le fichier uber JAR empaqueté
word-count-beam-bundled-0.1.jar(~135 Mo) sur le nœud maître de votre cluster Dataproc. Vous pouvez utilisergcloud storage cppour accélérer les transferts de fichiers vers votre cluster Dataproc à partir de Cloud Storage.Sur votre terminal local, créez un bucket Cloud Storage et importez le fichier Uber JAR.
gcloud storage buckets create BUCKET_NAMEgcloud storage cp target/word-count-beam-bundled-0.1.jar gs://BUCKET_NAME/Sur le nœud maître de Dataproc, téléchargez le fichier Uber JAR.
gcloud storage cp gs://BUCKET_NAME/word-count-beam-bundled-0.1.jar .
Exécutez la tâche Java Beam sur le nœud maître du cluster Dataproc.
flink run -c org.apache.beam.examples.WordCount word-count-beam-bundled-0.1.jar \ --runner=FlinkRunner \ --output=gs://BUCKET_NAME/java-wordcount-outVérifiez que les résultats ont bien été écrits dans votre bucket Cloud Storage.
gcloud storage cat gs://BUCKET_NAME/java-wordcount-out-SHARD_IDArrêtez la session YARN Flink.
yarn application -listyarn application -kill YARN_APPLICATION_ID
Tâches Beam portables
Pour exécuter des jobs Beam écrits en Python, Go et d'autres langages compatibles, vous pouvez utiliser FlinkRunner et PortableRunner, comme décrit sur la page de l'exécuteur Flink de Beam (voir aussi Feuille de route du framework de portabilité).
L'exemple suivant exécute une tâche Beam portable en Python à partir du nœud maître du cluster Dataproc.
Créez un cluster Dataproc avec les composants Flink et Docker activés.
gcloud dataproc clusters create CLUSTER_NAME \ --optional-components=FLINK,DOCKER \ --image-version=DATAPROC_IMAGE_VERSION \ --region=REGION \ --enable-component-gateway \ --scopes=https://www.googleapis.com/auth/cloud-platformRemarques :
--optional-components: Flink et Docker.--image-version: la version de l'image du cluster, qui détermine la version Flink installée sur le cluster (par exemple, consultez les versions des composants Apache Flink répertoriées pour les quatre versions suivantes et précédentes des versions 2.0.x de l'image).--region: région Dataproc disponible--enable-component-gateway: permet d'accéder à l'interface utilisateur du gestionnaire de tâches Flink.--scopes: activez l'accès aux API Google Cloud par votre cluster (voir Bonnes pratiques concernant les niveaux d'accès). Le champ d'applicationcloud-platformest activé par défaut (vous n'avez pas besoin d'inclure ce paramètre d'indicateur) lorsque vous créez un cluster qui utilise la version d'image Dataproc 2.1 ou ultérieure.
Utilisez gcloud CLI en local ou dans Cloud Shell pour créer un bucket Cloud Storage. Vous spécifierez BUCKET_NAME lorsque vous exécuterez un exemple de programme de comptage de mots.
gcloud storage buckets create BUCKET_NAMEDans une fenêtre de terminal sur la VM du cluster, démarrez une session Flink YARN. Notez l'URL du maître Flink, c'est-à-dire l'adresse du maître Flink où les jobs sont exécutés. Vous spécifierez le FLINK_MASTER_URL lorsque vous exécuterez un exemple de programme de comptage de mots.
. /usr/bin/flink-yarn-daemonAffichez et notez la version de Flink exécutée par le cluster Dataproc. Vous spécifierez le FLINK_VERSION lorsque vous exécuterez un exemple de programme de comptage de mots.
flink --versionInstallez les bibliothèques Python nécessaires pour exécuter la tâche sur le nœud maître du cluster.
Installez une version de Beam compatible avec la version de Flink du cluster.
python -m pip install apache-beam[gcp]==BEAM_VERSIONExécutez l'exemple de comptage de mots sur le nœud maître du cluster.
python -m apache_beam.examples.wordcount \ --runner=FlinkRunner \ --flink_version=FLINK_VERSION \ --flink_master=FLINK_MASTER_URL --flink_submit_uber_jar \ --output=gs://BUCKET_NAME/python-wordcount-outRemarques :
--runner:FlinkRunner.--flink_version: FLINK_VERSION, noté précédemment.--flink_master: FLINK_MASTER_URL, noté précédemment.--flink_submit_uber_jar: utilisez le fichier Uber JAR pour exécuter le job Beam.--output: BUCKET_NAME, créé précédemment.
Vérifiez que les résultats ont bien été écrits dans votre bucket.
gcloud storage cat gs://BUCKET_NAME/python-wordcount-out-SHARD_IDArrêtez la session YARN Flink.
- Obtenez l'ID de l'application.
yarn application -list1. Insert the <var>YARN_APPLICATION_ID</var>, then stop the session.yarn application -kill
Exécuter Flink sur un cluster kerberisé
Le composant Dataproc Flink est compatible avec les clusters kerberisés. Une demande Kerberos valide est nécessaire pour envoyer et conserver une tâche Flink, ou pour démarrer un cluster Flink. Par défaut, une demande Kerberos reste valide pendant sept jours.
Accéder à l'interface utilisateur du gestionnaire de tâches Flink
L'interface Web du gestionnaire de tâches Flink est disponible lorsqu'une tâche Flink ou un cluster de session Flink est en cours d'exécution. Pour utiliser l'interface Web :
- Créez un cluster Dataproc Flink.
- Après la création du cluster, cliquez sur le lien du ResourceManager YARN de la passerelle des composants dans l'onglet "Interface Web" de la page Détails du cluster de la console Google Cloud .
- Dans l'interface utilisateur YARN Resource Manager, identifiez l'entrée de l'application de cluster Flink. En fonction de l'état d'exécution d'un job, un lien ApplicationMaster ou History (Historique) est répertorié.
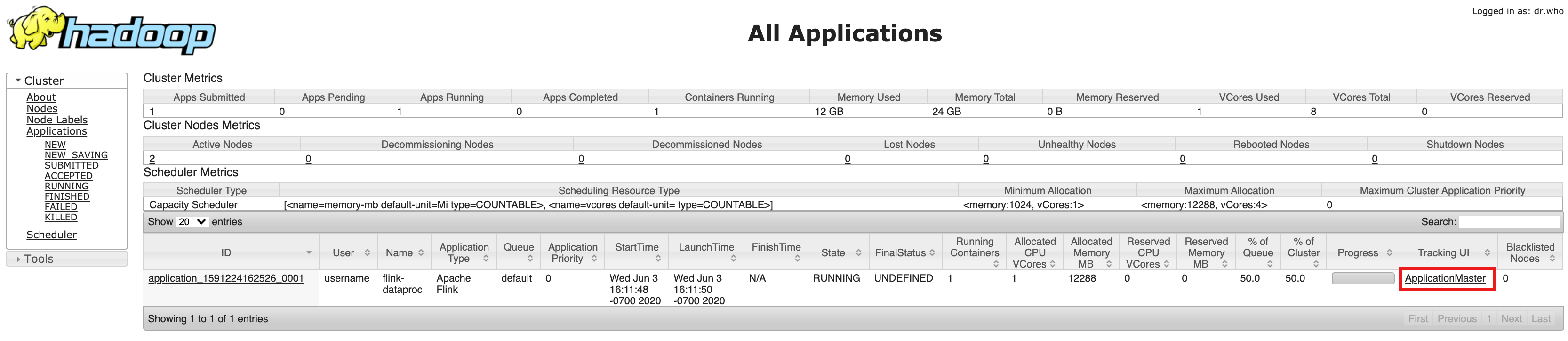
- Pour une tâche de streaming de longue durée, cliquez sur le lien ApplicationManager pour ouvrir le tableau de bord Flink. Pour une tâche terminée, cliquez sur le lien Historique pour afficher les détails de la tâche.
