Lorsque vous créez un cluster Dataproc, vous pouvez activer l'authentification personnelle de cluster Dataproc afin d'autoriser les charges de travail interactives du cluster à s'exécuter en toute sécurité en tant qu'identité d'utilisateur. Cela signifie que vous vous authentifiez vous-même au lieu d'utiliser un compte de service du cluster pour interagir avec d'autres ressources Google Cloud , telles que Cloud Storage.
Remarques
Lorsque vous créez un cluster avec la fonctionnalité d'authentification personnelle activée, il ne peut être utilisé que par votre identité. Les autres utilisateurs ne pourront pas exécuter de tâches ni accéder aux points de terminaison de la passerelle des composants sur le cluster.
Les clusters sur lesquels l'authentification personnelle de cluster est activée bloquent l'accès SSH et les fonctionnalités de Compute Engine telles que les scripts de démarrage sur toutes les VM du cluster.
Les clusters sur lesquels l'authentification personnelle de cluster est activée activent et configurent Kerberos sur le cluster pour permettre une communication sécurisée au sein des clusters. Cependant, toutes les identités Kerberos du cluster interagissent avec les ressources Google Clouden tant qu'utilisateur unique.
Les clusters sur lesquels l'authentification personnelle de cluster est activée ne sont pas compatibles avec les images personnalisées.
L'authentification personnelle de cluster Dataproc n'est pas compatible avec les workflows Dataproc.
L'authentification personnelle de cluster Dataproc est uniquement destinée aux tâches interactives exécutées par un seul utilisateur. Les tâches et opérations de longue durée doivent configurer et utiliser une identité de compte de service appropriée.
Les identifiants propagés sont limités par une limite d'accès aux identifiants. La limite d'accès par défaut est limitée à la lecture et à l'écriture d'objets Cloud Storage dans des buckets Cloud Storage appartenant au même projet que celui contenant le cluster. Vous pouvez définir une limite d'accès non définie par défaut lorsque vous enable_an_interactive_session.
L'authentification personnelle de cluster Dataproc utilise les attributs invité Compute Engine. Si la fonctionnalité d'attributs d'invité est désactivée, l'authentification personnelle du cluster échouera.
Objectifs
Créer un cluster Dataproc sur lequel l'authentification personnelle de cluster Dataproc est activée
Démarrer la propagation des identifiants sur le cluster
Utiliser un notebook Jupyter sur le cluster pour exécuter des tâches Spark qui s'authentifient avec vos identifiants
Avant de commencer
Créer un projet
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Dataproc API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Install the Google Cloud CLI.
-
Si vous utilisez un fournisseur d'identité (IdP) externe, vous devez d'abord vous connecter à la gcloud CLI avec votre identité fédérée.
-
Pour initialiser la gcloud CLI, exécutez la commande suivante :
gcloud init -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Dataproc API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Install the Google Cloud CLI.
-
Si vous utilisez un fournisseur d'identité (IdP) externe, vous devez d'abord vous connecter à la gcloud CLI avec votre identité fédérée.
-
Pour initialiser la gcloud CLI, exécutez la commande suivante :
gcloud init - Démarrez une session Cloud Shell.
- Exécutez la commande
gcloud auth loginpour obtenir des identifiants utilisateur valides. Recherchez l'adresse e-mail de votre compte actif dans gcloud.
gcloud auth list --filter=status=ACTIVE --format="value(account)"
créer un cluster ;
gcloud dataproc clusters create CLUSTER_NAME \ --properties=dataproc:dataproc.personal-auth.user=your-email-address \ --enable-component-gateway \ --optional-components=JUPYTER \ --region=REGION
Activez une session de propagation des identifiants pour que le cluster commence à utiliser vos identifiants personnels lorsqu'il interagit avec des ressources Google Cloud.
gcloud dataproc clusters enable-personal-auth-session \ --region=REGION \ CLUSTER_NAME
Exemple de résultat :
Injecting initial credentials into the cluster CLUSTER_NAME...done. Periodically refreshing credentials for cluster CLUSTER_NAME. This will continue running until the command is interrupted...
Exemple de limite d'accès à champ d'application limité : L'exemple suivant active une session d'authentification personnelle plus restrictive que la limite d'accès aux identifiants à champ d'application limité par défaut. Il limite l'accès au bucket de préproduction du cluster Dataproc (pour en savoir plus, consultez Réduire le champ d'application avec les limites d'accès aux identifiants ).
gcloud dataproc clusters enable-personal-auth-session \ --project=PROJECT_ID \ --region=REGION \ --access-boundary=<(echo -n "{ \ \"access_boundary\": { \ \"accessBoundaryRules\": [{ \ \"availableResource\": \"//storage.googleapis.com/projects/_/buckets/$(gcloud dataproc clusters describe --project=PROJECT_ID --region=REGION CLUSTER_NAME --format="value(config.configBucket)")\", \ \"availablePermissions\": [ \ \"inRole:roles/storage.objectViewer\", \ \"inRole:roles/storage.objectCreator\", \ \"inRole:roles/storage.objectAdmin\", \ \"inRole:roles/storage.legacyBucketReader\" \ ] \ }] \ } \ }") \ CLUSTER_NAME
Laissez la commande s'exécuter, et basculez vers un nouvel onglet ou une nouvelle session de terminal Cloud Shell. Le client actualise les identifiants pendant l'exécution de la commande.
Saisissez
Ctrl-Cpour mettre fin à la session.- Obtenez les détails du cluster.
gcloud dataproc clusters describe CLUSTER_NAME --region=REGION
L'URL de l'interface Web Jupyter est répertoriée dans les détails du cluster.
... JupyterLab: https://UUID-dot-us-central1.dataproc.googleusercontent.com/jupyter/lab/ ...
- Copiez l'URL dans votre navigateur local pour lancer l'interface utilisateur de Jupyter.
- Vérifiez que l'authentification personnelle de cluster a réussi.
- Démarrez un terminal Jupyter.
- Exécutez la commande
gcloud auth list. - Vérifiez que votre nom d'utilisateur est le seul compte actif.
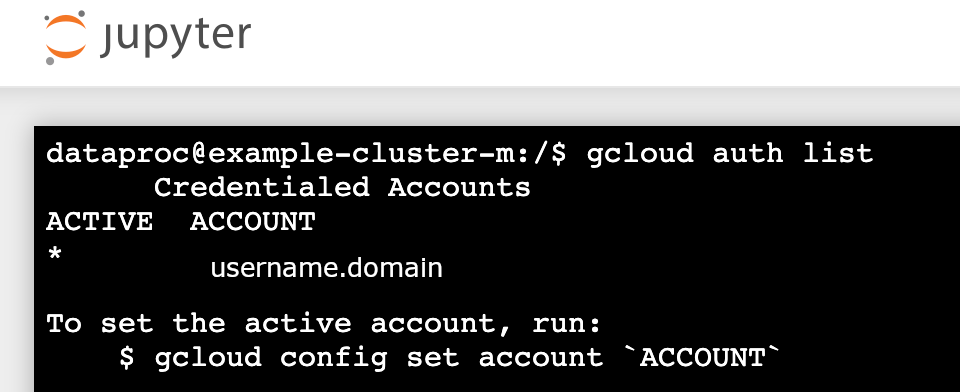
- Dans un terminal Jupyter, activez Jupyter pour vous authentifier avec Kerberos et envoyer des tâches Spark.
kinit -kt /etc/security/keytab/dataproc.service.keytab dataproc/$(hostname -f)
- Exécutez la commande
klistpour vérifier que Jupyter a obtenu un ticket TGT valide.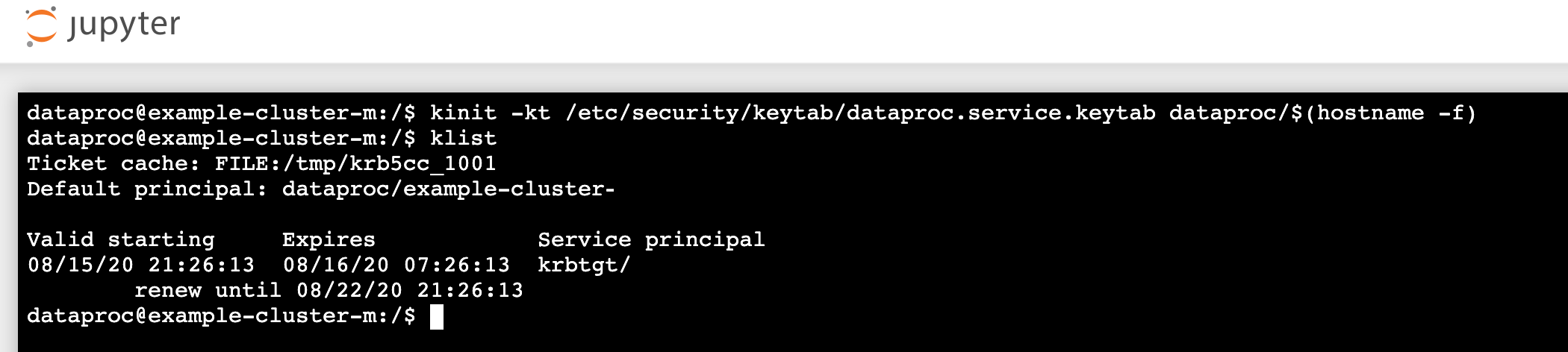
- Exécutez la commande
- Dans un terminal Jupyter, utilisez gcloud CLI pour créer un fichier
rose.txtdans un bucket Cloud Storage de votre projet.echo "A rose by any other name would smell as sweet" > /tmp/rose.txt
gcloud storage cp /tmp/rose.txt gs://bucket-name/rose.txt
- Marquez le fichier comme privé afin que seul votre compte utilisateur puisse y effectuer des opérations de lecture et d'écriture. Jupyter utilise vos identifiants personnels pour interagir avec Cloud Storage.
gcloud storage objects update gs://bucket-name/rose.txt --predefined-acl=private
- Vérifiez que vous disposez d'un accès privé.
gcloud storage objects describe gs://$BUCKET/rose.txt
acl:
- Marquez le fichier comme privé afin que seul votre compte utilisateur puisse y effectuer des opérations de lecture et d'écriture. Jupyter utilise vos identifiants personnels pour interagir avec Cloud Storage.
- email: $USER entity: user-$USER role: OWNER
- Pour lancer l'interface utilisateur de Jupyter, cliquez sur le lien Passerelle des composants Jupyter.
- Vérifiez que l'authentification personnelle de cluster a réussi.
- Démarrez un terminal Jupyter.
- Exécutez la commande
gcloud auth list. - Vérifiez que votre nom d'utilisateur est le seul compte actif.
- Dans un terminal Jupyter, activez Jupyter pour vous authentifier avec Kerberos et envoyer des tâches Spark.
kinit -kt /etc/security/keytab/dataproc.service.keytab dataproc/$(hostname -f)
- Exécutez la commande
klistpour vérifier que Jupyter a obtenu un ticket TGT valide.
- Exécutez la commande
- Dans un terminal Jupyter, utilisez gcloud CLI pour créer un fichier
rose.txtdans un bucket Cloud Storage de votre projet.echo "A rose by any other name would smell as sweet" > /tmp/rose.txt
gcloud storage cp /tmp/rose.txt gs://bucket-name/rose.txt
- Marquez le fichier comme privé afin que seul votre compte utilisateur puisse y effectuer des opérations de lecture et d'écriture. Jupyter utilise vos identifiants personnels pour interagir avec Cloud Storage.
gcloud storage objects update gs://bucket-name/rose.txt --predefined-acl=private
- Vérifiez que vous disposez d'un accès privé.
gcloud storage objects describe gs://bucket-name/rose.txt
acl:
- Marquez le fichier comme privé afin que seul votre compte utilisateur puisse y effectuer des opérations de lecture et d'écriture. Jupyter utilise vos identifiants personnels pour interagir avec Cloud Storage.
- email: $USER entity: user-$USER role: OWNER
- Accédez à un dossier, puis créez un notebook PySpark.
Exécutez une tâche simple de décompte de mots sur le fichier
rose.txtcréé ci-dessus.text_file = sc.textFile("gs://bucket-name/rose.txt") counts = text_file.flatMap(lambda line: line.split(" ")) \ .map(lambda word: (word, 1)) \ .reduceByKey(lambda a, b: a + b) print(counts.collect())rose.txtdans Cloud Storage, car il s'exécute avec vos identifiants utilisateur.Vous pouvez également consulter les journaux d'audit du bucket Cloud Storage pour vérifier que le job accède à Cloud Storage avec votre identité (pour en savoir plus, consultez Cloud Audit Logs avec Cloud Storage).
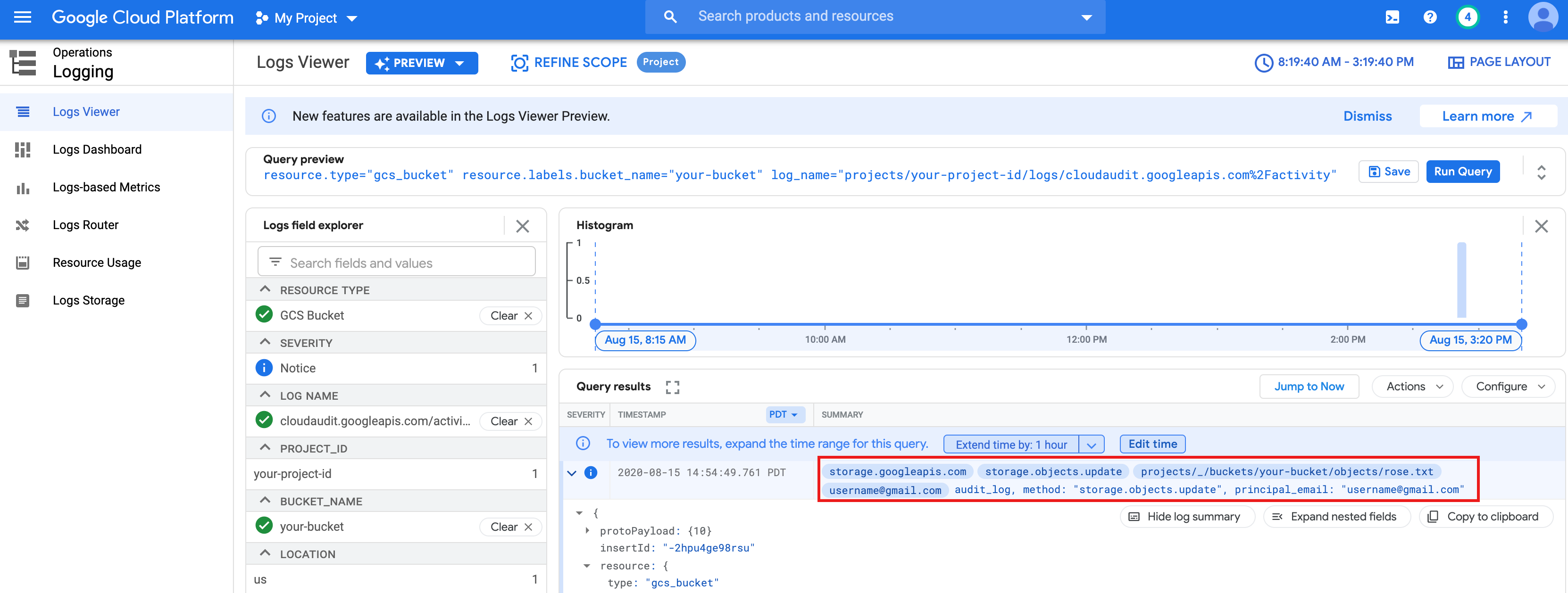
- Supprimez le cluster Dataproc.
gcloud dataproc clusters delete CLUSTER_NAME --region=REGION
Configurer l'environnement
Configurez l'environnement à partir de Cloud Shell ou d'un terminal local :