Dataproc イメージ バージョン 1.5 と 2.0 で利用可能な Dataproc Ranger Cloud Storage プラグインは、各 Dataproc クラスタ VM で認証サービスを有効にします。認証サービスは、Cloud Storage コネクタからのリクエストを Ranger ポリシーに対して評価し、リクエストが許可されている場合は、クラスタのVM サービス アカウントに対してアクセス トークンを返します。
Ranger Cloud Storage プラグインは認証に Kerberos を使用し、委任トークンの Cloud Storage コネクタ サポートと統合される。委任トークンは、クラスタ マスターノード上の MySQL データベースに保存されます。データベースのルートパスワードは、Dataproc クラスタを作成するときにクラスタ プロパティで指定します。
始める前に
プロジェクトの Dataproc VM サービス アカウントでサービス アカウント トークン作成者ロールとIAM ロールの管理者ロールを付与します。
Ranger Cloud Storage プラグインをインストールする
ローカル ターミナル ウィンドウまたは Cloud Shell で次のコマンドを実行して、Dataproc クラスタを作成するときに Ranger Cloud Storage プラグインをインストールします。
環境変数を設定する
export CLUSTER_NAME=new-cluster-name \ export REGION=region \ export KERBEROS_KMS_KEY_URI=Kerberos-KMS-key-URI \ export KERBEROS_PASSWORD_URI=Kerberos-password-URI \ export RANGER_ADMIN_PASSWORD_KMS_KEY_URI=Ranger-admin-password-KMS-key-URI \ export RANGER_ADMIN_PASSWORD_GCS_URI=Ranger-admin-password-GCS-URI \ export RANGER_GCS_PLUGIN_MYSQL_KMS_KEY_URI=MySQL-root-password-KMS-key-URI \ export RANGER_GCS_PLUGIN_MYSQL_PASSWORD_URI=MySQL-root-password-GCS-URI
注:
- CLUSTER_NAME: 新しいクラスタの名前。
- REGION: クラスタが作成されるリージョン(例:
us-west1)。 - KERBEROS_KMS_KEY_URI、KERBEROS_PASSWORD_URI: Kerberos ルート プリンシパルのパスワードを設定するをご覧ください。
- RANGER_ADMIN_PASSWORD_KMS_KEY_URI、RANGER_ADMIN_PASSWORD_GCS_URI: Ranger 管理者パスワードを設定するをご覧ください。
- RANGER_GCS_PLUGIN_MYSQL_KMS_KEY_URI、RANGER_GCS_PLUGIN_MYSQL_PASSWORD_URI: Ranger 管理者パスワードの設定と同じ手順で MySQL パスワードを設定します。
Dataproc クラスタを作成する
次のコマンドを実行して Dataproc クラスタを作成し、クラスタに Ranger Cloud Storage プラグインをインストールします。
gcloud dataproc clusters create ${CLUSTER_NAME} \
--region=${REGION} \
--scopes cloud-platform \
--enable-component-gateway \
--optional-components=SOLR,RANGER \
--kerberos-kms-key=${KERBEROS_KMS_KEY_URI} \
--kerberos-root-principal-password-uri=${KERBEROS_PASSWORD_URI} \
--properties="dataproc:ranger.gcs.plugin.enable=true, \
dataproc:ranger.kms.key.uri=${RANGER_ADMIN_PASSWORD_KMS_KEY_URI}, \
dataproc:ranger.admin.password.uri=${RANGER_ADMIN_PASSWORD_GCS_URI}, \
dataproc:ranger.gcs.plugin.mysql.kms.key.uri=${RANGER_GCS_PLUGIN_MYSQL_KMS_KEY_URI}, \
dataproc:ranger.gcs.plugin.mysql.password.uri=${RANGER_GCS_PLUGIN_MYSQL_PASSWORD_URI}"
注:
- 1.5 イメージ バージョン: 1.5 イメージ バージョンのクラスタを作成する場合(バージョンの選択を参照)、
--metadata=GCS_CONNECTOR_VERSION="2.2.6" or higherフラグを追加して必要なコネクタ バージョンをインストールします。
Ranger Cloud Storage プラグインのインストールを確認する
クラスタの作成が完了すると、Ranger 管理者ウェブ インターフェースに「gcs-dataproc」という名前の GCS サービスタイプが表示されます。
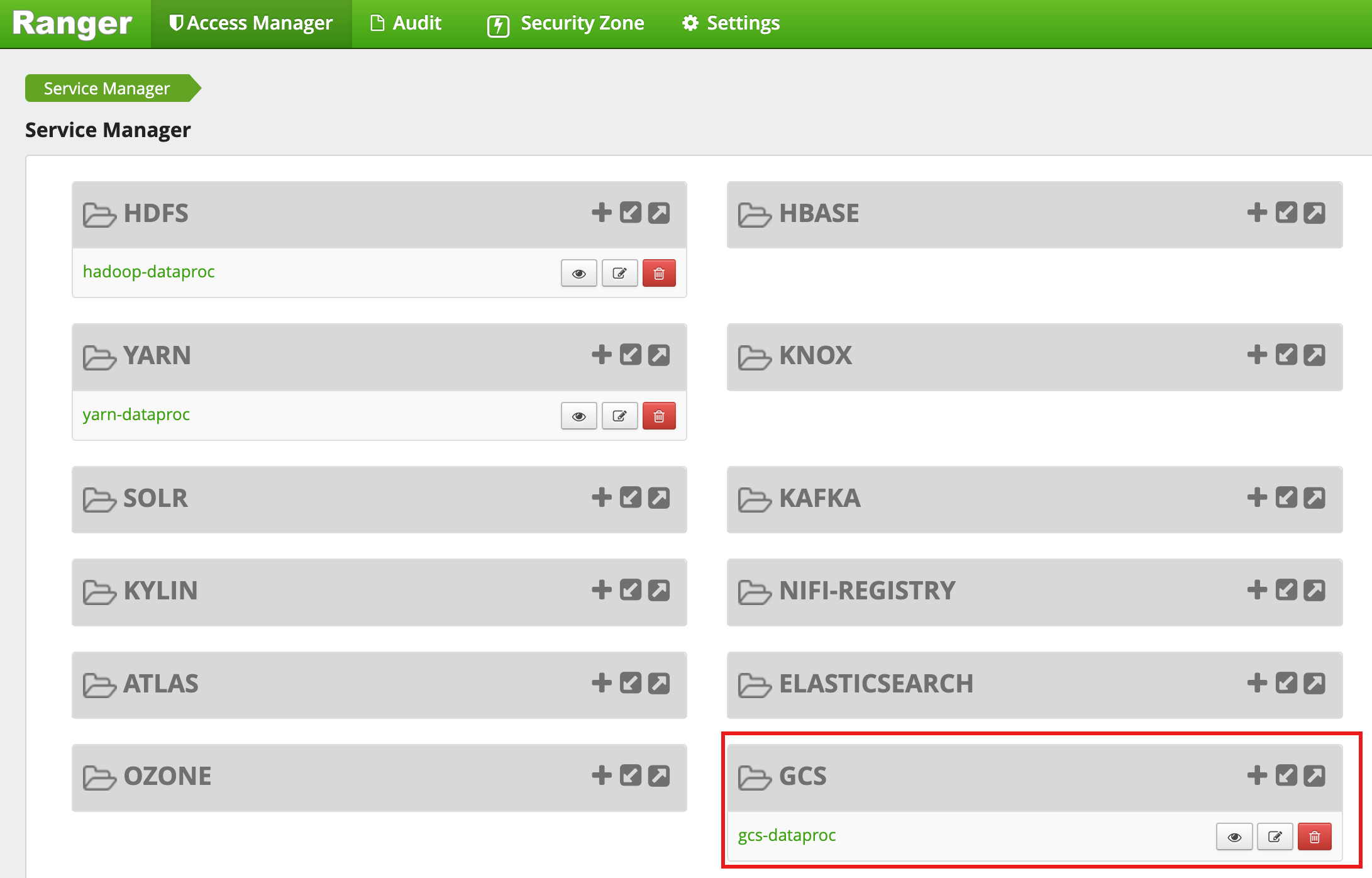
Ranger Cloud Storage プラグインのデフォルト ポリシー
デフォルトの gcs-dataproc サービスには、次のポリシーがあります。
Dataproc クラスタのステージング バケットと一時バケットへの読み取りと書き込みを行うためのポリシー
all - bucket, object-pathポリシー。これにより、すべてのユーザーがすべてのオブジェクトのメタデータにアクセスできるようになります。このアクセス権は、Cloud Storage コネクタが HCFS(Hadoop 共通ファイルシステム)のオペレーションを実行できるようにするために必要です。
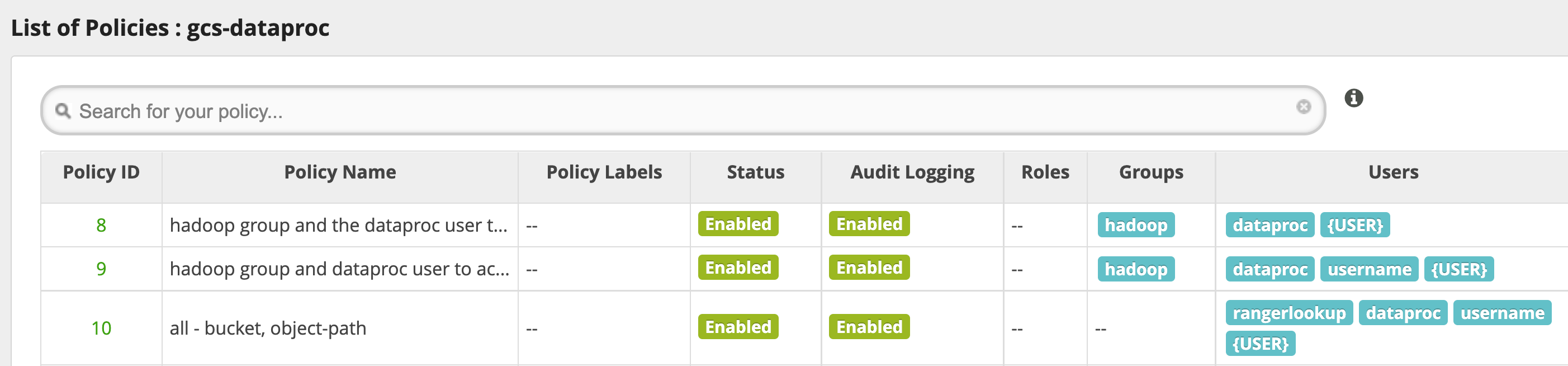
使い方のヒント
バケット フォルダへのアプリのアクセス
Cloud Storage バケットに中間ファイルを作成するアプリに対応するには、Cloud Storage バケットパスにModify Objects、List Objects、Delete Objects 権限を付与し、次に recursive モードを指定して、指定したパスのサブパスに権限を拡張できます。
保護手段
プラグインの技術的保護手段の回避を防ぐには:
VM サービス アカウントの権限を Cloud Storage バケット内のリソースに付与します。これらのリソースへのアクセス権は、範囲を限定したアクセス トークンで付与できます(Cloud Storage の IAM 権限を参照)。また、バケット リソースへのユーザーによるアクセス権を削除して、ユーザーがバケットに直接アクセスするのを妨げます。
クラスタ VM で
sudoとその他のルートアクセス手段(sudoerファイルの更新を含む)を無効にして、なりすましや、認証と認可の変更を防ぎます。詳しくは、sudoユーザー権限を追加または削除するための Linux の手順をご覧ください。iptableを使用して、クラスタ VM から Cloud Storage への直接アクセス リクエストをブロックします。たとえば、VM メタデータ サーバーへのアクセスをブロックして、VM サービス アカウントの認証情報や Cloud Storage へのアクセスの承認に使用するアクセス トークンへのアクセスを防止できます(block_vm_metadata_server.sh、iptableルールを使用して VM メタデータ サーバーへのアクセスをブロックする初期化スクリプトをご覧ください)。
Spark、Hive on MapReduce、Hive on Tez のジョブ
機密性の高いユーザー認証の詳細を保護し、鍵配布センター(KDC)の負荷を軽減するため、Spark ドライバは Kerberos 認証情報をエグゼキュータに配布しません。代わりに、Spark ドライバは Ranger Cloud Storage プラグインから委任トークンを取得し、委任トークンをエグゼキュータに配布します。エグゼキュータは、委任トークンを使用して Ranger Cloud Storage プラグインで認証を行い、Cloud Storage へのアクセスを許可する Google アクセス トークンと交換します。
Hive-on-MapReduce ジョブと Hive-on-Tez ジョブも、トークンを使用して Cloud Storage にアクセスします。次のジョブタイプを送信するときに、指定された Cloud Storage バケットにアクセスするためのトークンを取得するには、次のプロパティを使用します。
Spark ジョブ:
--conf spark.yarn.access.hadoopFileSystems=gs://bucket-name,gs://bucket-name,...
Hive-on-MapReduce ジョブ:
--hiveconf "mapreduce.job.hdfs-servers=gs://bucket-name,gs://bucket-name,..."
Hive-on-Tez ジョブ:
--hiveconf "tez.job.fs-servers=gs://bucket-name,gs://bucket-name,..."
Spark ジョブのシナリオ
Ranger Cloud Storage プラグインがインストールされている Dataproc クラスタ VM のターミナル ウィンドウから実行すると、Spark ワードカウント ジョブが失敗します。
spark-submit \
--conf spark.yarn.access.hadoopFileSystems=gs://${FILE_BUCKET} \
--class org.apache.spark.examples.JavaWordCount \
/usr/lib/spark/examples/jars/spark-examples.jar \
gs://bucket-name/wordcount.txt
注:
- FILE_BUCKET: Spark アクセス用の Cloud Storage バケット。
エラー出力:
Caused by: com.google.gcs.ranger.client.shaded.io.grpc.StatusRuntimeException: PERMISSION_DENIED: Access denied by Ranger policy: User: '<USER>', Bucket: '<dataproc_temp_bucket>', Object Path: 'a97127cf-f543-40c3-9851-32f172acc53b/spark-job-history/', Action: 'LIST_OBJECTS'
注:
- Kerberos 対応環境では、
spark.yarn.access.hadoopFileSystems=gs://${FILE_BUCKET}が必要です。
エラー出力:
Caused by: java.lang.RuntimeException: Failed creating a SPNEGO token. Make sure that you have run `kinit` and that your Kerberos configuration is correct. See the full Kerberos error message: No valid credentials provided (Mechanism level: No valid credentials provided)
ポリシーは、Ranger 管理者ウェブ インターフェースのアクセス マネージャーを使用して編集され、List Objects とその他の temp バケット権限を持つユーザのリストに username を追加します。
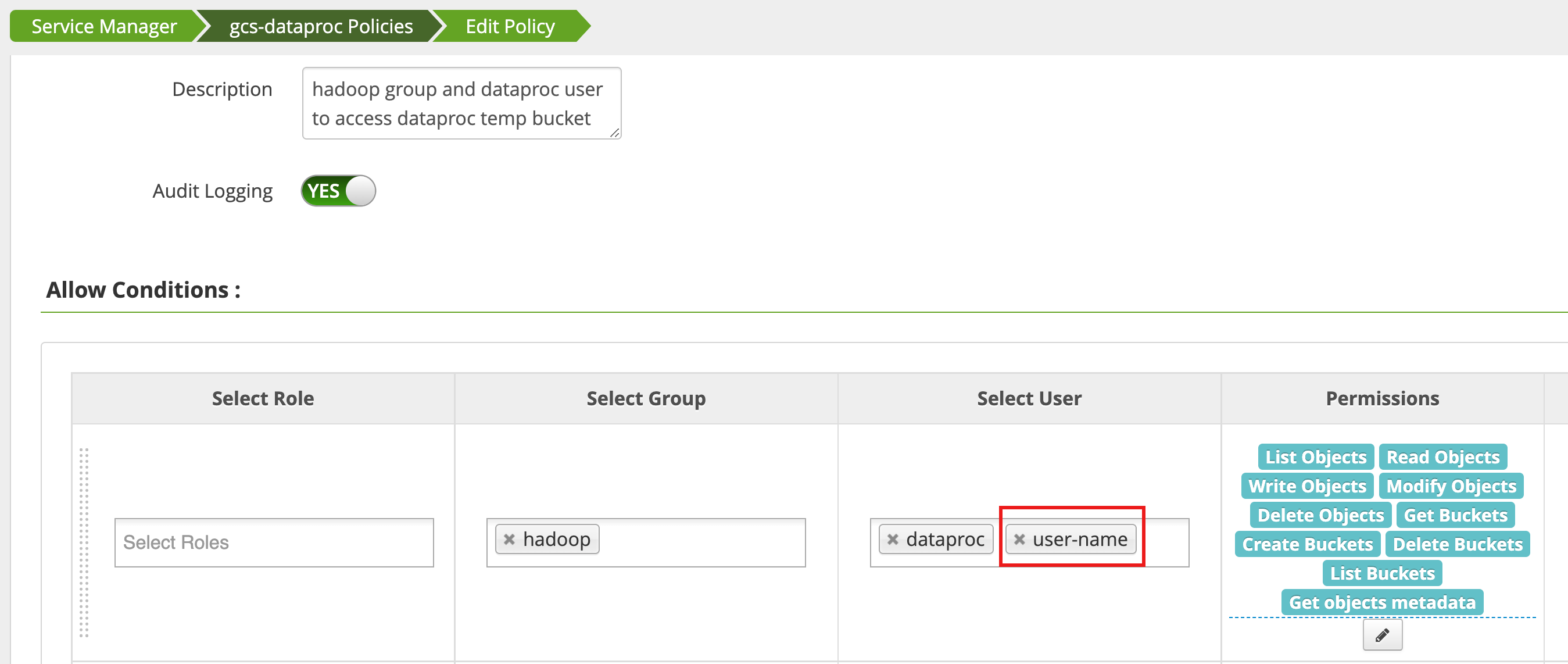
ジョブを実行すると、新しいエラーが発生します。
エラー出力:
com.google.gcs.ranger.client.shaded.io.grpc.StatusRuntimeException: PERMISSION_DENIED: Access denied by Ranger policy: User: <USER>, Bucket: '<file-bucket>', Object Path: 'wordcount.txt', Action: 'READ_OBJECTS'
wordcount.text Cloud Storage パスに対する読み取りアクセスをユーザーに付与するためのポリシーが追加されます。
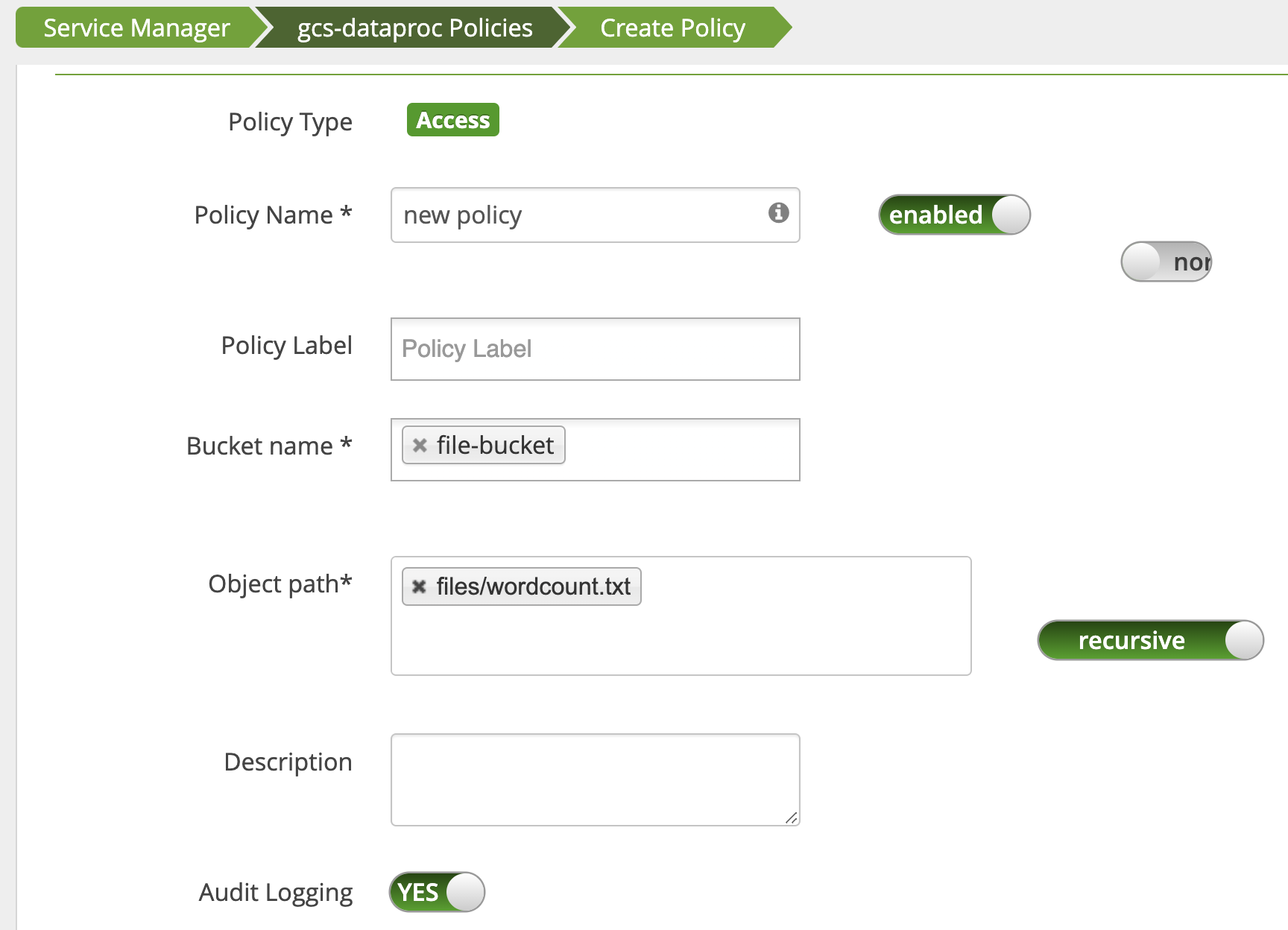
ジョブが実行され、正常に完了します。
INFO com.google.cloud.hadoop.fs.gcs.auth.GcsDelegationTokens: Using delegation token RangerGCSAuthorizationServerSessionToken owner=<USER>, renewer=yarn, realUser=, issueDate=1654116824281, maxDate=0, sequenceNumber=0, masterKeyId=0 this: 1 is: 1 a: 1 text: 1 file: 1 22/06/01 20:54:13 INFO org.sparkproject.jetty.server.AbstractConnector: Stopped