Che cos'è la scalabilità automatica
Stimare il numero "giusto" di worker (nodi) del cluster per un carico di lavoro è difficile e una singola dimensione del cluster per un'intera pipeline spesso non è l'ideale. Lo scaling del cluster avviato dall'utenterisolve parzialmente questo problema, ma richiede il monitoraggio dell'utilizzo del cluster e un intervento manuale.
L'API AutoscalingPolicies di Dataproc
offre un meccanismo per automatizzare la gestione delle risorse cluster e consente
la scalabilità automatica delle VM worker del cluster. Un Autoscaling Policy è una configurazione riutilizzabile che
descrive in che modo scalare i worker del cluster che utilizzano il criterio di scalabilità automatica. Definisce i limiti, la frequenza e l'aggressività della scalabilità per fornire un controllo dettagliato sulle risorse del cluster nel corso del suo ciclo di vita.
Quando utilizzare la scalabilità automatica
Utilizza la scalabilità automatica:
sui cluster che archiviano i dati in servizi esterni, come Cloud Storage o BigQuery
sui cluster che elaborano molti job
per scalare i cluster con un singolo job
con la modalità di flessibilità avanzata per i job batch Spark
La scalabilità automatica non è consigliata con/per:
HDFS:la scalabilità automatica non è pensata per la scalabilità di HDFS su cluster perché:
- L'utilizzo di HDFS non è un indicatore per la scalabilità automatica.
- I dati HDFS sono ospitati solo sui worker primari. Il numero di worker primari deve essere sufficiente per ospitare tutti i dati HDFS.
- Il ritiro dei DataNode HDFS può ritardare la rimozione dei worker. I nodi dati copiano i blocchi HDFS in altri nodi dati prima che un worker venga rimosso. A seconda delle dimensioni dei dati e del fattore di replica, questo processo può richiedere ore.
Etichette nodo YARN:la scalabilità automatica non supporta le etichette nodo YARN né la proprietà
dataproc:am.primary_onlya causa di YARN-9088. YARN segnala in modo errato le metriche del cluster quando vengono utilizzate le etichette dei nodi.Spark Structured Streaming:la scalabilità automatica non supporta Spark Structured Streaming (vedi Scalabilità automatica e Spark Structured Streaming).
Cluster inattivi:la scalabilità automatica non è consigliata per ridurre le dimensioni di un cluster al minimo quando è inattivo. Poiché la creazione di un nuovo cluster è veloce quanto il ridimensionamento di uno esistente, valuta la possibilità di eliminare i cluster inattivi e ricrearli. I seguenti strumenti supportano questo modello "effimero":
Utilizza i workflow Dataproc per pianificare un insieme di job su un cluster dedicato, quindi elimina il cluster al termine dei job. Per un'orchestrazione più avanzata, utilizza Cloud Composer, basato su Apache Airflow.
Per i cluster che elaborano query ad hoc o carichi di lavoro pianificati esternamente, utilizza l'eliminazione pianificata del cluster per eliminare il cluster dopo un periodo di inattività o una durata specifici oppure in un momento specifico.
Workload di dimensioni diverse: quando vengono eseguiti job piccoli e grandi su un cluster, la riduzione in scala rimozione controllata attenderà il completamento dei job di grandi dimensioni. Il risultato è che un job a lunga esecuzione ritarderà la scalabilità automatica delle risorse per i job più piccoli in esecuzione sul cluster fino al termine del job a lunga esecuzione. Per evitare questo risultato, raggruppa i job più piccoli di dimensioni simili in un cluster e isola ogni job di lunga durata in un cluster separato.
Abilita scalabilità automatica
Per abilitare la scalabilità automatica su un cluster:
Procedi in uno dei seguenti modi:
Crea un criterio di scalabilità automatica
Interfaccia a riga di comando gcloud
Puoi utilizzare il comando
gcloud dataproc autoscaling-policies import
per creare una policy di scalabilità automatica. Legge un file
YAML
locale che definisce un criterio di scalabilità automatica. Il formato e i contenuti del file
devono corrispondere agli oggetti e ai campi di configurazione definiti dall'API REST autoscalingPolicies.
L'esempio YAML seguente definisce una policy per i cluster standard Dataproc, con tutti i campi obbligatori. Fornisce anche i valori
minInstances e maxInstances per i
worker principali, il valore maxInstances per i worker secondari
(prerilasciabili) e specifica un cooldownPeriod di 4 minuti
(il valore predefinito è 2 minuti). workerConfig configura i
worker principali. In questo esempio, minInstances e
maxInstances sono impostati sullo stesso valore
per evitare di scalare i worker principali.
workerConfig:
minInstances: 10
maxInstances: 10
secondaryWorkerConfig:
maxInstances: 50
basicAlgorithm:
cooldownPeriod: 4m
yarnConfig:
scaleUpFactor: 0.05
scaleDownFactor: 1.0
gracefulDecommissionTimeout: 1h
Il seguente esempio YAML definisce un criterio per i cluster standard Dataproc, con tutti i campi obbligatori e facoltativi del criterio di scalabilità automatica.
clusterType: STANDARD
workerConfig:
minInstances: 10
maxInstances: 10
weight: 1
secondaryWorkerConfig:
minInstances: 0
maxInstances: 100
weight: 1
basicAlgorithm:
cooldownPeriod: 2m
yarnConfig:
scaleUpFactor: 0.05
scaleDownFactor: 1.0
scaleUpMinWorkerFraction: 0.0
scaleDownMinWorkerFraction: 0.0
gracefulDecommissionTimeout: 1h
Il seguente esempio YAML definisce un criterio per i cluster con scalabilità a zero.
Per i cluster con scalabilità fino a zero, non includereworkerConfig.
clusterType: ZERO_SCALE
secondaryWorkerConfig:
minInstances: 0
maxInstances: 100
weight: 1
basicAlgorithm:
cooldownPeriod: 2m
yarnConfig:
scaleUpFactor: 0.05
scaleDownFactor: 1.0
scaleUpMinWorkerFraction: 0.0
scaleDownMinWorkerFraction: 0.0
gracefulDecommissionTimeout: 1h
Esegui il seguente comando gcloud da un terminale locale o in
Cloud Shell per creare la
policy di scalabilità automatica. Fornisci un nome per il criterio. Questo nome diventerà
il id del criterio, che potrai utilizzare nei comandi gcloud successivi
per fare riferimento al criterio. Utilizza il flag --source per specificare
il percorso locale e il nome file del file YAML del criterio di scalabilità automatica da importare.
gcloud dataproc autoscaling-policies import policy-name \ --source=filepath/filename.yaml \ --region=region
API REST
Crea un criterio di scalabilità automatica definendo un AutoscalingPolicy nell'ambito di una richiesta autoscalingPolicies.create.
Console
Per creare un criterio di scalabilità automatica, seleziona CREA CRITERIO dalla pagina Criteri di scalabilità automatica di Dataproc utilizzando la console Google Cloud . Nella pagina Crea policy, puoi selezionare un riquadro di consigli per le policy per compilare i campi della policy di scalabilità automatica per un tipo di job o un obiettivo di scalabilità specifico.
Crea un cluster con scalabilità automatica
Dopo aver creato una policy di scalabilità automatica, crea un cluster che la utilizzi. Il cluster deve trovarsi nella stessa regione del criterio di scalabilità automatica.
Interfaccia a riga di comando gcloud
Esegui il seguente comando gcloud da un terminale locale o in Cloud Shell per creare un cluster di scalabilità automatica. Fornisci un nome per il cluster e utilizza
il flag --autoscaling-policy per specificare policy ID
(il nome della policy che hai specificato quando
hai creato la policy)
o la policy
resource URI (resource name)
(vedi i campi
AutoscalingPolicy id e name).
gcloud dataproc clusters create cluster-name \ --autoscaling-policy=policy id or resource URI \ --region=region
API REST
Crea un cluster con scalabilità automatica includendo un AutoscalingConfig come parte di una richiesta clusters.create.
Console
Puoi selezionare una policy di scalabilità automatica esistente da applicare a un nuovo cluster dalla sezione Policy di scalabilità automatica del pannello Configura cluster nella paginaCrea un cluster della console Google Cloud .
Abilitare la scalabilità automatica su un cluster esistente
Dopo aver creato un criterio di scalabilità automatica, puoi attivarlo su un cluster esistente nella stessa regione.
Interfaccia a riga di comando gcloud
Esegui questo comando gcloud da un terminale locale o in
Cloud Shell per abilitare un
policy di scalabilità automatica su un cluster esistente. Fornisci il nome del cluster e utilizza
il flag --autoscaling-policy per specificare policy ID
(il nome del criterio specificato quando hai
creato il criterio)
o il criterio
resource URI (resource name)
(vedi i campi
AutoscalingPolicy id e name).
gcloud dataproc clusters update cluster-name \ --autoscaling-policy=policy id or resource URI \ --region=region
API REST
Per attivare una policy di scalabilità automatica su un cluster esistente, imposta
AutoscalingConfig.policyUri
della policy in updateMask di una
richiesta clusters.patch.
Console
L'abilitazione di una policy di scalabilità automatica su un cluster esistente non è supportata nella console Google Cloud .
Utilizzo dei criteri multi-cluster
Un criterio di scalabilità automatica definisce il comportamento di scalabilità che può essere applicato a più cluster. È consigliabile applicare una policy di scalabilità automatica a più cluster quando i cluster condivideranno workload simili o eseguiranno job con pattern di utilizzo delle risorse simili.
Puoi aggiornare una policy utilizzata da più cluster. Gli aggiornamenti influenzano immediatamente il comportamento di scalabilità automatica per tutti i cluster che utilizzano le norme (vedi autoscalingPolicies.update). Se non vuoi che un aggiornamento dei criteri venga applicato a un cluster che li utilizza, disattiva la scalabilità automatica sul cluster prima di aggiornare i criteri.
Interfaccia a riga di comando gcloud
Esegui questo comando gcloud da un terminale locale o in
Cloud Shell per
disattivare la scalabilità automatica su un cluster.
gcloud dataproc clusters update cluster-name --disable-autoscaling \ --region=region
API REST
Per disattivare la scalabilità automatica su un cluster, imposta
AutoscalingConfig.policyUri
sulla stringa vuota e imposta
update_mask=config.autoscaling_config.policy_uri in una
richiesta clusters.patch.
Console
La disattivazione della scalabilità automatica su un cluster non è supportata nella console Google Cloud .
- Una policy utilizzata da uno o più cluster non può essere eliminata (vedi autoscalingPolicies.delete).
Come funziona la scalabilità automatica
La scalabilità automatica controlla le metriche Hadoop YARN del cluster al termine di ogni periodo di "raffreddamento" per determinare se scalare il cluster e, in caso affermativo, l'entità dell'aggiornamento.
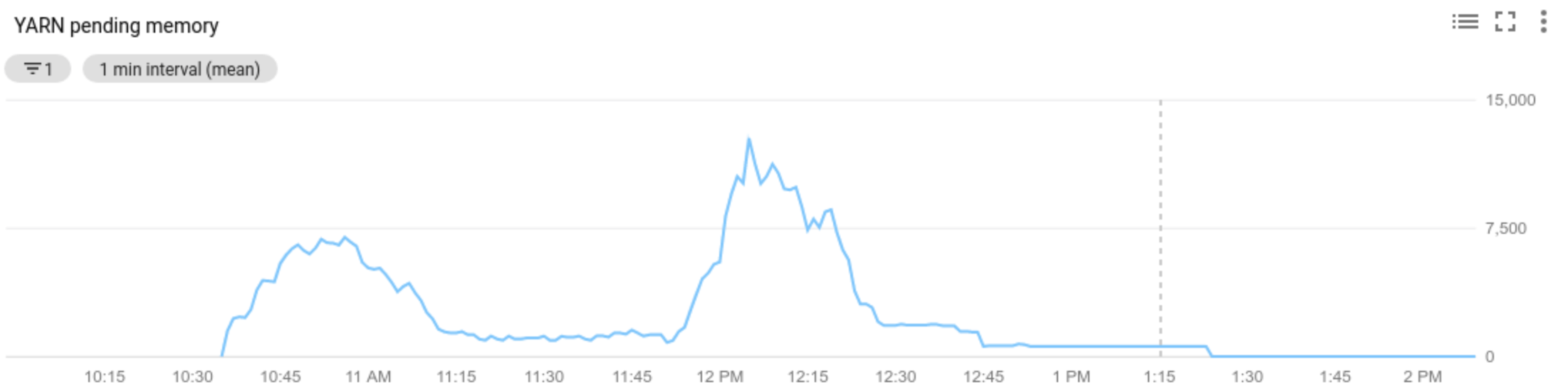
Il valore della metrica delle risorse in attesa di YARN (memoria in attesa o core in attesa) determina se aumentare o diminuire lo scale up. Un valore maggiore di
0indica che i job YARN sono in attesa di risorse e che potrebbe essere necessario aumentare lo scale up. Un valore0indica che YARN dispone di risorse sufficienti, pertanto potrebbe non essere necessario ridimensionare o apportare altre modifiche.Se la risorsa in attesa è > 0:
$estimated\_worker\_count =$
\[ \Biggl \lceil AVERAGE\ during\ cooldown\ period\Big(\frac{Pending + Available + Allocated + Reserved}{Resource\ per\ worker}\Big)\Biggr \rceil \]
Se la risorsa in attesa è 0:
$estimated\_worker\_count =$
\[ \Biggl \lceil AVERAGE\ during\ cooldown\ period\Big(\frac{Allocated + Reserved}{Resource\ per\ worker}\Big)\Biggr \rceil \]
Per impostazione predefinita, a partire dall'immagine Dataproc 2.2, lo strumento di scalabilità automatica monitora la memoria YARN e i core YARN in modo che
estimated_worker_countvenga valutato separatamente per memoria e core e venga selezionato il numero maggiore di worker risultante. Per le versioni precedenti dell'immagine, il gestore della scalabilità automatica monitora solo la memoria YARN, a meno che tu non attivi la scalabilità automatica basata sui core.$estimated\_worker\_count =$
\[ max(estimated\_worker\_count\_by\_memory,\ estimated\_worker\_count\_by\_cores) \]
\[ estimated\ \Delta worker = estimated\_worker\_count - current\_worker\_count \]
In base alla variazione stimata necessaria al numero di worker, la scalabilità automatica utilizza un
scaleUpFactoro unscaleDownFactorper calcolare la variazione effettiva del numero di worker:if estimated Δworkers > 0: actual Δworkers = ROUND_UP(estimated Δworkers * scaleUpFactor) # examples: # ROUND_UP(estimated Δworkers=5 * scaleUpFactor=0.5) = 3 # ROUND_UP(estimated Δworkers=0.8 * scaleUpFactor=0.5) = 1 else: actual Δworkers = ROUND_DOWN(estimated Δworkers * scaleDownFactor) # examples: # ROUND_DOWN(estimated Δworkers=-5 * scaleDownFactor=0.5) = -2 # ROUND_DOWN(estimated Δworkers=-0.8 * scaleDownFactor=0.5) = 0 # ROUND_DOWN(estimated Δworkers=-1.5 * scaleDownFactor=0.5) = 0
Un valore di scaleUpFactor o scaleDownFactor pari a 1,0 indica che la scalabilità automatica verrà applicata in modo che la risorsa in attesa o disponibile sia pari a 0 (utilizzo perfetto).
Una volta calcolata la modifica al numero di worker,
scaleUpMinWorkerFractionescaleDownMinWorkerFractionfungono da soglia per determinare se la scalabilità automatica aumenterà le dimensioni del cluster. Una piccola frazione indica che la scalabilità automatica deve scalare anche se ilΔworkersè piccolo. Una frazione più grande significa che il ridimensionamento deve avvenire solo quando ilΔworkersè grande.IF (Δworkers > scaleUpMinWorkerFraction * current_worker_count) then scale up
IF (abs(Δworkers) > scaleDownMinWorkerFraction * current_worker_count), THEN scale down.
Se il numero di worker da scalare è sufficientemente grande da attivare lo scaling, la scalabilità automatica utilizza i limiti
minInstancesmaxInstancesdiworkerConfigesecondaryWorkerConfigeweight(rapporto tra worker principali e secondari) per determinare come dividere il numero di worker tra i gruppi di istanza worker principali e secondari. Il risultato di questi calcoli è la modifica finale della scalabilità automatica al cluster per il periodo di scalabilità.Le richieste di riduzione della scalabilità automatica verranno annullate sui cluster creati con versioni immagine 2.0.57+, 2.1.5+ e versioni immagine successive se:
- è in corso uno scale down con un valore di timeout per la rimozione controllata diverso da zero e
il numero di worker YARN ATTIVI ("worker attivi") più la variazione del numero totale di worker consigliato dal gestore della scalabilità automatica (
Δworkers) è uguale o maggiore diDECOMMISSIONINGworker YARN ("worker ritirati"), come mostrato nella seguente formula:IF (active workers + Δworkers ≥ active workers + decommissioning workers) THEN cancel the scaledown operation
Per un esempio di annullamento della riduzione della scalabilità, consulta Quando la scalabilità automatica annulla un'operazione di riduzione della scalabilità?.
Suggerimenti per la configurazione della scalabilità automatica
Questa sezione contiene consigli per configurare la scalabilità automatica.
Evita di scalare i worker principali
I worker principali eseguono i nodi dati HDFS, mentre i worker secondari sono solo di calcolo.
L'utilizzo di worker secondari consente di scalare in modo efficiente le risorse di calcolo senza
la necessità di eseguire il provisioning dell'archiviazione, con conseguente aumento della velocità di scalabilità.
I nodi dei nomi HDFS possono presentare più race condition che causano il danneggiamento di HDFS, in modo che il ritiro rimanga bloccato a tempo indeterminato. Per
evitare questo problema, non scalare i worker principali. Ad esempio:
none
workerConfig:
minInstances: 10
maxInstances: 10
secondaryWorkerConfig:
minInstances: 0
maxInstances: 100
È necessario apportare alcune modifiche al comando di creazione del cluster:
- Imposta
--num-workers=10in modo che corrisponda alle dimensioni del gruppo di worker principale della policy di scalabilità automatica. - Imposta
--secondary-worker-type=non-preemptibleper configurare i worker secondari in modo che non siano prerilasciabili. (a meno che non siano desiderate VM preemptible). - Copia la configurazione hardware dai worker principali ai worker secondari. Ad esempio, imposta
--secondary-worker-boot-disk-size=1000GBin modo che corrisponda a--worker-boot-disk-size=1000GB.
Utilizzare la modalità di flessibilità avanzata per i job batch Spark
Utilizza la modalità di flessibilità avanzata (EFM) con la scalabilità automatica per:
consente di ridurre più rapidamente le dimensioni del cluster durante l'esecuzione dei job
impedire l'interruzione dei job in esecuzione a causa della riduzione delle dimensioni del cluster
ridurre al minimo le interruzioni dei job in esecuzione a causa del prerilascio dei worker secondari prerilasciabili
Con la modalità EFM attivata, il timeout di ritiro
controllato di una policy di scalabilità automatica deve essere impostato su 0s. La policy di scalabilità automatica deve scalare automaticamente solo i worker secondari.
Scegliere un timeout per la rimozione controllata
La scalabilità automatica supporta il ritiro controllato di YARN quando vengono rimossi nodi da un cluster. Il ritiro controllato consente alle applicazioni di completare il trasferimento dei dati tra le fasi per evitare di rallentare l'avanzamento del job. Il timeout di ritiro controllato fornito in una policy di scalabilità automatica è il limite superiore della durata durante la quale YARN attenderà le applicazioni in esecuzione (le applicazioni in esecuzione all'avvio del ritiro) prima di rimuovere i nodi.
Quando un processo non viene completato entro il periodo di timeout per rimozione controllata specificato, il
nodo di lavoro viene arrestato forzatamente, causando potenzialmente la perdita di dati o
l'interruzione del servizio. Per evitare questa possibilità, imposta il timeout per il ritiro gestito automaticamente su un valore superiore al
job più lungo che il cluster elaborerà. Ad esempio, se prevedi che il tuo job più lungo
venga eseguito per un'ora, imposta il timeout su almeno un'ora (1h).
Valuta la possibilità di eseguire la migrazione dei job che richiedono più di un'ora ai propri cluster effimeri per evitare di bloccare ilrimozione controllatao.
Impostazione scaleUpFactor
scaleUpFactor controlla l'aggressività con cui il gestore della scalabilità automatica esegue lo scale up di un cluster.
Specifica un numero compreso tra 0.0 e 1.0 per impostare il valore frazionario
della risorsa in attesa di YARN che causa l'aggiunta del nodo.
Ad esempio, se ci sono 100 container in attesa che richiedono 512 MB ciascuno, allora
ci sono 50 GB di memoria YARN in attesa. Se scaleUpFactor è 0.5, il
gestore della scalabilità automatica aggiungerà nodi sufficienti per aggiungere 25 GB di memoria YARN. Allo stesso modo, se è
0.1, il gestore della scalabilità automatica aggiungerà nodi sufficienti per 5 GB. Tieni presente che questi valori
corrispondono alla memoria YARN, non alla memoria totale disponibile fisicamente su una VM.
Un buon punto di partenza è 0.05 per i job MapReduce e Spark con allocazione dinamica abilitata. Per i job Spark con un numero fisso di executor e i job Tez, utilizza
1.0. Un valore scaleUpFactor pari a 1.0 indica che la scalabilità automatica verrà eseguita in modo che la risorsa in attesa o disponibile sia 0 (utilizzo perfetto).
Impostazione scaleDownFactor
scaleDownFactor controlla l'aggressività con cui il gestore della scalabilità automatica riduce le dimensioni di un cluster. Specifica un numero compreso tra 0.0 e 1.0 per impostare il valore frazionario
della risorsa YARN disponibile che causa la rimozione del nodo.
Lascia questo valore a 1.0 per la maggior parte dei cluster multi-job che devono scalare
frequentemente. A seguito della rimozione controllata, le operazioni di riduzione della scalabilità sono
molto più lente rispetto alle operazioni di aumento della scalabilità. L'impostazione di scaleDownFactor=1.0 imposta
un tasso di riduzione aggressivo, che riduce al minimo il numero di operazioni di riduzione
necessarie per raggiungere le dimensioni appropriate del cluster.
Per i cluster che richiedono maggiore stabilità, imposta un valore di scaleDownFactor inferiore per una
velocità di riduzione delle dimensioni più lenta.
Imposta questo valore su 0.0 per impedire la riduzione delle dimensioni del cluster, ad esempio quando
utilizzi cluster temporanei o con un singolo job.
Impostazione di scaleUpMinWorkerFraction e scaleDownMinWorkerFraction
scaleUpMinWorkerFraction e scaleDownMinWorkerFraction vengono utilizzati
con scaleUpFactor o scaleDownFactor e hanno valori
predefiniti di 0.0. Rappresentano le soglie in corrispondenza delle quali il gestore della scalabilità automatica aumenterà o fare lo scale down le dimensioni del cluster: l'aumento o la diminuzione frazionaria minima delle dimensioni del cluster necessaria per emettere richieste di scale up o scale down.
Esempi: il gestore della scalabilità automatica non invierà una richiesta di aggiornamento per aggiungere 5 worker a un cluster di 100 nodi, a meno che scaleUpMinWorkerFraction non sia inferiore o uguale a 0.05 (5%). Se impostato su 0.1, il gestore della scalabilità automatica non invierà la richiesta di scale up del cluster.
Analogamente, se scaleDownMinWorkerFraction è 0.05, il gestore della scalabilità automatica non
rimuove almeno 5 nodi.
Il valore predefinito di 0.0 indica che non è presente alcuna soglia.
L'impostazione di un valore di scaleDownMinWorkerFractionthresholds più elevato su cluster di grandi dimensioni (> 100 nodi) per evitare operazioni di scalabilità piccole e non necessarie è vivamente consigliata.
Scegliere un periodo di raffreddamento
cooldownPeriod imposta un periodo di tempo durante il quale il gestore della scalabilità automatica
non invierà richieste di modifica delle dimensioni del cluster. Puoi utilizzarlo
per limitare la frequenza delle modifiche del gestore della scalabilità automatica alle dimensioni del cluster.
Il valore minimo e predefinito di cooldownPeriod
è di due minuti. Se in una policy viene impostato un cooldownPeriod più breve, le modifiche al workload influiranno più rapidamente sulle dimensioni del cluster, ma i cluster potrebbero essere scalati inutilmente verso l'alto e verso il basso. La prassi consigliata è impostare scaleUpMinWorkerFraction e scaleDownMinWorkerFraction di un criterio su un valore diverso da zero quando si utilizza un cooldownPeriod più breve. In questo modo, il cluster viene scalato solo quando la variazione dell'utilizzo delle risorse è sufficiente a giustificare un aggiornamento del cluster.
Se il tuo workload è sensibile alle modifiche delle dimensioni del cluster, puoi aumentare il periodo di raffreddamento. Ad esempio, se esegui un job di elaborazione batch, puoi impostare il periodo di raffreddamento su 10 minuti o più. Sperimenta diversi periodi di raffreddamento per trovare il valore più adatto al tuo carico di lavoro.
Limiti del conteggio dei worker e pesi dei gruppi
Ogni gruppo di worker ha minInstances e maxInstances che configurano un limite rigido
per le dimensioni di ogni gruppo.
Ogni gruppo ha anche un parametro denominato weight che configura il bilanciamento
target tra i due gruppi. Tieni presente che questo parametro è solo un suggerimento e che, se
un gruppo raggiunge le dimensioni minime o massime, i nodi verranno aggiunti o rimossi
solo dall'altro gruppo. Pertanto, weight può quasi sempre essere lasciato al valore predefinito 1.
Utilizzare la scalabilità automatica basata sui core
Per le applicazioni che richiedono un uso intensivo della CPU, una best practice consiste nell'utilizzare lo strumento di calcolo della risorsa dominante per l'allocazione delle risorse. Questa è la configurazione YARN predefinita a partire dalla versione 2.2 dell'immagine Dataproc. Con le versioni precedenti dell'immagine, Dataproc configura YARN per utilizzare le metriche di memoria per l'allocazione delle risorse, a meno che tu non imposti la seguente proprietà quando crei un cluster per configurare YARN in modo che utilizzi il calcolatore delle risorse dominanti:
capacity-scheduler:yarn.scheduler.capacity.resource-calculator=org.apache.hadoop.yarn.util.resource.DominantResourceCalculator
Metriche e log di scalabilità automatica
Le seguenti risorse e strumenti possono aiutarti a monitorare le operazioni di scalabilità automatica e il loro effetto sul cluster e sui relativi job.
Cloud Monitoring
Utilizza Cloud Monitoring per:
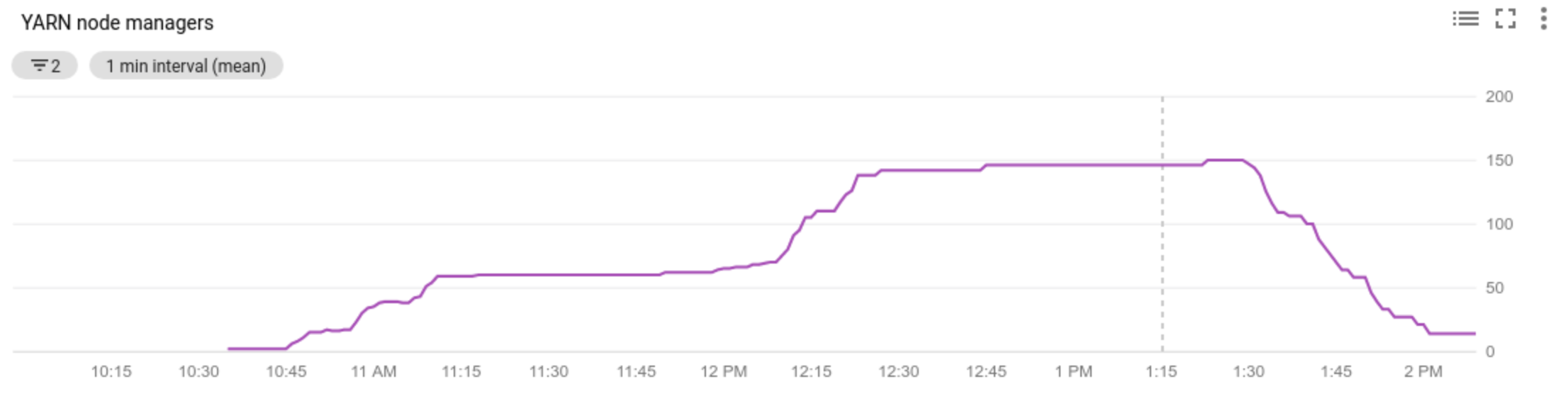
- visualizzare le metriche utilizzate dalla scalabilità automatica
- visualizzare il numero di Node Manager nel cluster
- capire perché la scalabilità automatica ha o non ha scalato il cluster
Cloud Logging
Utilizza Cloud Logging per visualizzare i log dello strumento di scalabilità automatica di Dataproc.
1) Trova i log per il tuo cluster.
2) Seleziona dataproc.googleapis.com/autoscaler.
3) Espandi i messaggi di log per visualizzare il campo status. I log sono in formato JSON, un formato leggibile dal computer.
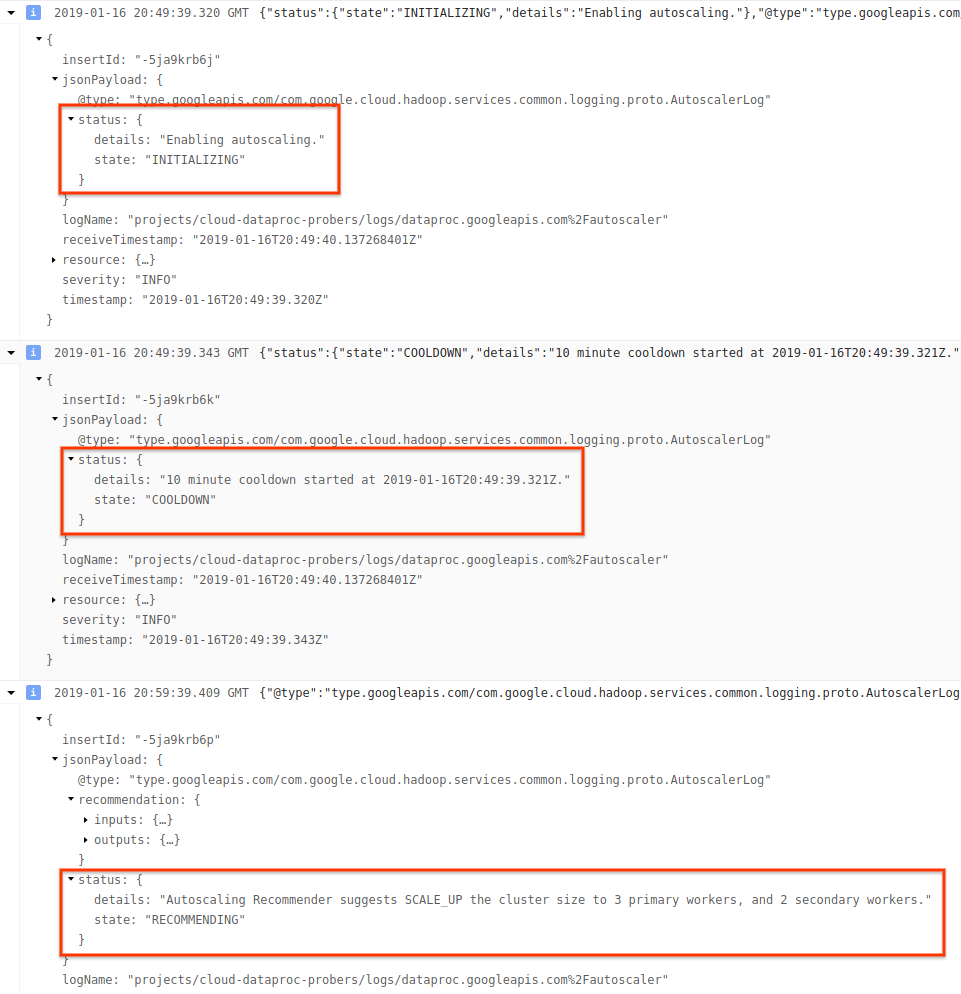
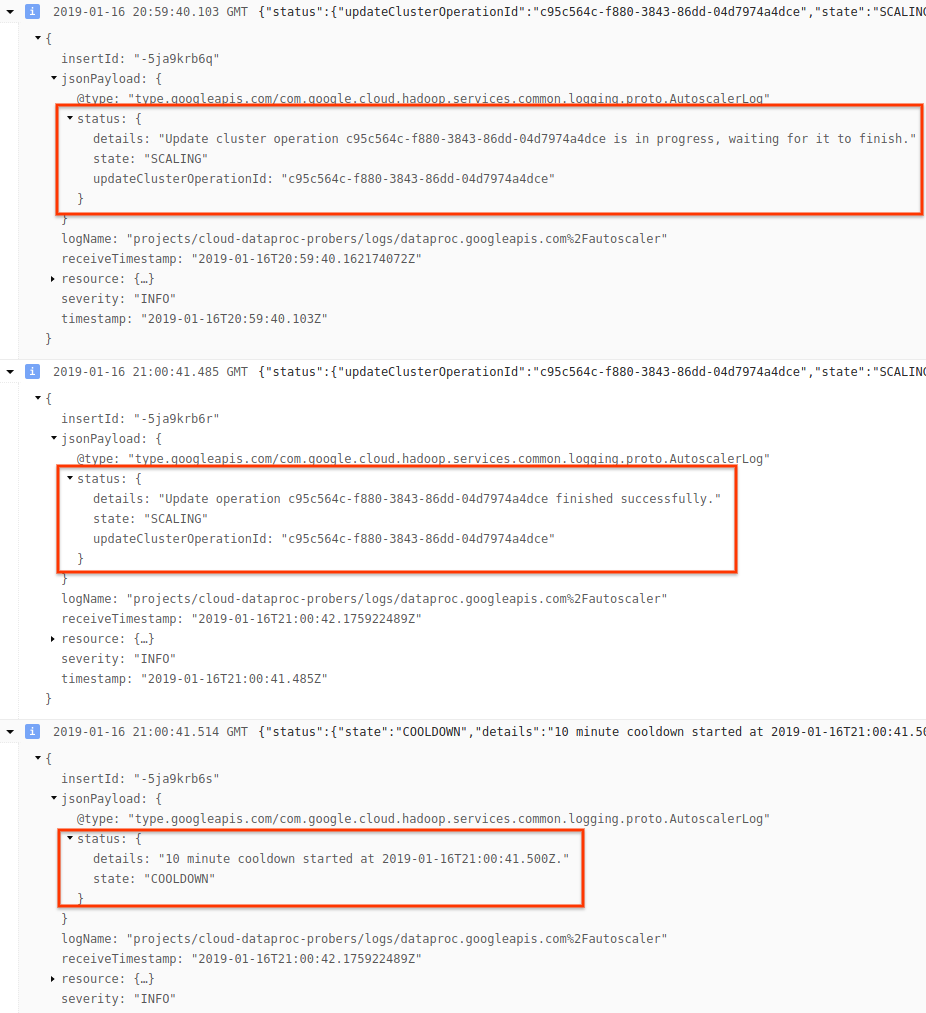
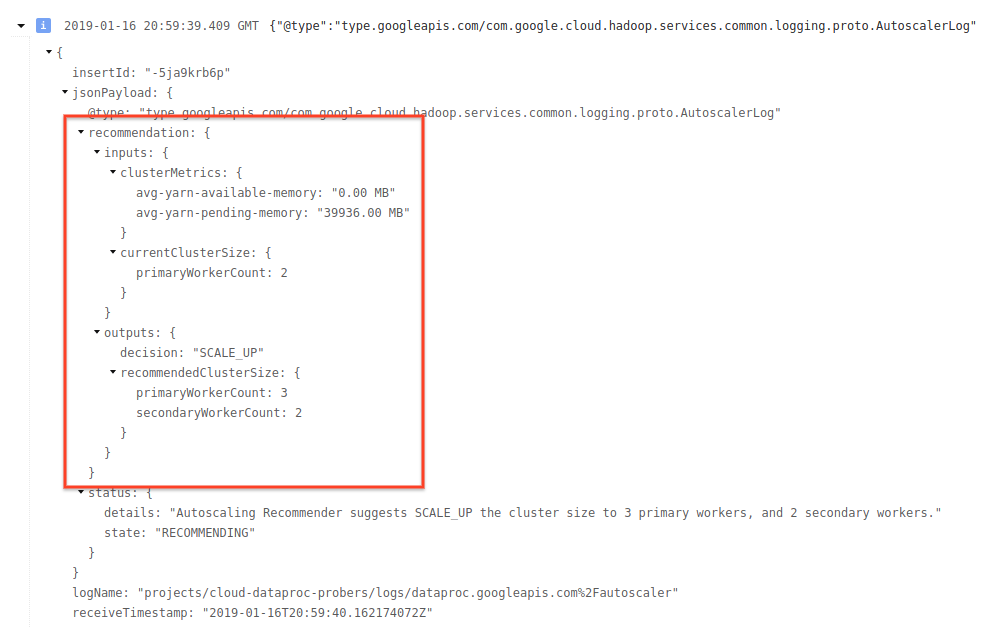
4) Espandi il messaggio di log per visualizzare i consigli di scalabilità, le metriche utilizzate per le decisioni di scalabilità, le dimensioni originali del cluster e le nuove dimensioni del cluster target.
Background: scalabilità automatica con Apache Hadoop e Apache Spark
Le sezioni seguenti descrivono in che modo la scalabilità automatica interagisce (o non interagisce) con Hadoop YARN e Hadoop MapReduce, nonché con Apache Spark, Spark Streaming e Spark Structured Streaming.
Metriche YARN Hadoop
La scalabilità automatica si basa sulle seguenti metriche YARN Hadoop:
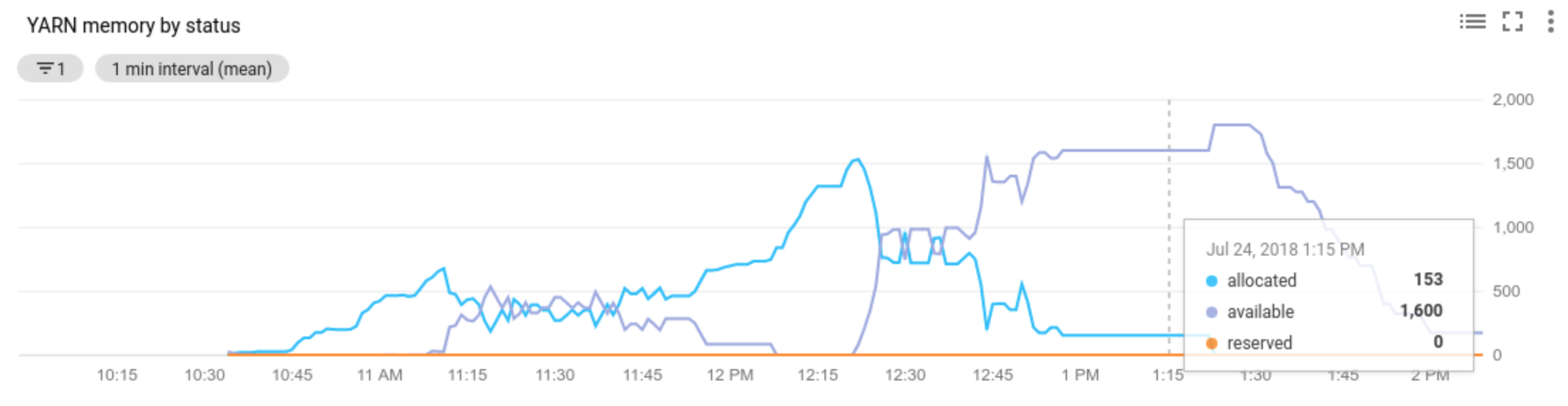
Allocated resourcesi riferisce alla risorsa YARN totale occupata dai container in esecuzione nell'intero cluster. Se ci sono 6 container in esecuzione che possono utilizzare fino a 1 unità di risorsa, le risorse allocate sono 6.Available resourceè la risorsa YARN nel cluster non utilizzata dai container allocati. Se ci sono 10 unità di risorse in tutti i gestori dei nodi e 6 di queste sono allocate, ci sono 4 risorse disponibili. Se nel cluster sono presenti risorse disponibili (non utilizzate), la scalabilità automatica potrebbe rimuovere i worker dal cluster.Pending resourceè la somma delle richieste di risorse YARN per i container in attesa. I container in attesa aspettano spazio per essere eseguiti in YARN. La risorsa in attesa è diversa da zero solo se la risorsa disponibile è zero o troppo piccola per essere allocata al successivo container. Se sono presenti contenitori in attesa, la scalabilità automatica potrebbe aggiungere worker al cluster.
Puoi visualizzare queste metriche in Cloud Monitoring. Per impostazione predefinita, la memoria YARN sarà pari a 0,8 * la memoria totale del cluster, con la memoria rimanente riservata ad altri daemon e all'utilizzo del sistema operativo, come la cache di pagine. Puoi ignorare il valore predefinito con l'impostazione di configurazione YARN "yarn.nodemanager.resource.memory-mb" (vedi Apache Hadoop YARN, HDFS, Spark e proprietà correlate).
Scalabilità automatica e Hadoop MapReduce
MapReduce esegue ogni attività di map e reduce come container YARN separato. Quando inizia un job, MapReduce invia richieste di container per ogni attività di mappatura, il che comporta un picco elevato di memoria YARN in attesa. Man mano che le attività di mapping vengono completate, la memoria in attesa diminuisce.
Quando mapreduce.job.reduce.slowstart.completedmaps sono stati completati (95% per impostazione predefinita
su Dataproc), MapReduce mette in coda le richieste di container per tutti
i reducer, il che comporta un altro picco di memoria in attesa.
A meno che le attività di mappatura e riduzione non richiedano diversi minuti o più, non
impostare un valore elevato per la scalabilità automatica scaleUpFactor. L'aggiunta di worker al cluster richiede almeno 1,5 minuti, quindi assicurati che ci sia lavoro in attesa sufficiente per utilizzare il nuovo worker per diversi minuti. Un buon punto di partenza è impostare scaleUpFactor su 0,05 (5%) o 0,1 (10%) della memoria in attesa.
Scalabilità automatica e Spark
Spark aggiunge un ulteriore livello di pianificazione a YARN. Nello specifico, l'allocazione dinamica di Spark Core effettua richieste a YARN per i container per eseguire gli executor Spark, quindi pianifica le attività Spark sui thread di questi executor. I cluster Dataproc attivano l'allocazione dinamica per impostazione predefinita, quindi gli executor vengono aggiunti e rimossi in base alle necessità.
Spark chiede sempre i container a YARN, ma senza l'allocazione dinamica, li chiede solo all'inizio del job. Con l'allocazione dinamica, rimuoverà i container o ne richiederà di nuovi, se necessario.
Spark inizia con un piccolo numero di esecutori, due sui cluster con scalabilità automatica, e
continua a raddoppiare il numero di esecutori finché non ci sono attività in attesa.
In questo modo, la memoria in attesa viene livellata (meno picchi di memoria in attesa). Ti consigliamo di impostare
scaleUpFactor della scalabilità automatica su un numero elevato, ad esempio 1,0 (100%), per i job Spark.
Disattivazione dell'allocazione dinamica di Spark
Se esegui job Spark separati che non traggono vantaggio dall'allocazione dinamica di Spark, puoi disattivarla impostando spark.dynamicAllocation.enabled=false e spark.executor.instances.
Puoi comunque utilizzare la scalabilità automatica per scalare i cluster verso l'alto e verso il basso mentre vengono eseguiti i job Spark separati.
Job Spark con dati memorizzati nella cache
Imposta spark.dynamicAllocation.cachedExecutorIdleTimeout o rimuovi dalla cache i set di dati quando non sono più necessari. Per impostazione predefinita, Spark non rimuove gli executor che hanno
dati memorizzati nella cache, il che impedisce la riduzione delle dimensioni del cluster.
Scalabilità automatica e Spark Streaming
Poiché Spark Streaming ha una propria versione di allocazione dinamica che utilizza indicatori specifici per lo streaming per aggiungere e rimuovere executor, imposta
spark.streaming.dynamicAllocation.enabled=truee disattiva l'allocazione dinamica di Spark Core impostandospark.dynamicAllocation.enabled=false.Non utilizzare il ritiro gestito automaticamente (scalabilità automatica
gracefulDecommissionTimeout) con i job Spark Streaming. Per rimuovere in sicurezza i worker con la scalabilità automatica, configura il checkpointing per la tolleranza agli errori.
In alternativa, per utilizzare Spark Streaming senza scalabilità automatica:
- Disattiva l'allocazione dinamica di Spark Core (
spark.dynamicAllocation.enabled=false) e - Imposta il numero di esecutori (
spark.executor.instances) per il tuo job. Consulta Proprietà cluster.
Scalabilità automatica e Spark Structured Streaming
La scalabilità automatica non è compatibile con Spark Structured Streaming perché Spark Structured Streaming non supporta l'allocazione dinamica (vedi SPARK-24815: Structured Streaming should support dynamic allocation).
Controllare la scalabilità automatica tramite partizionamento e parallelismo
Mentre il parallelismo viene solitamente impostato o determinato dalle risorse del cluster (ad esempio, il numero di blocchi HDFS controlla il numero di attività), con la scalabilità automatica vale il contrario: la scalabilità automatica imposta il numero di worker in base al parallelismo del job. Di seguito sono riportate le linee guida per impostare il parallelismo dei job:
- Anche se Dataproc imposta il numero predefinito di attività MapReduce reduce
in base alle dimensioni iniziali del cluster, puoi impostare
mapreduce.job.reducesper aumentare il parallelismo della fase di riduzione. - Il parallelismo di Spark SQL e DataFrame è determinato da
spark.sql.shuffle.partitions, che per impostazione predefinita è 200. - Le funzioni RDD di Spark utilizzano per impostazione predefinita
spark.default.parallelism, che viene impostato sul numero di core dei nodi worker all'avvio del job. Tuttavia, tutte le funzioni RDD che creano shuffle utilizzano un parametro per il numero di partizioni, che sostituiscespark.default.parallelism.
Devi assicurarti che i dati siano partizionati in modo uniforme. Se si verifica una distorsione significativa della chiave, una o più attività potrebbero richiedere molto più tempo rispetto alle altre, con conseguente basso utilizzo.
Impostazioni predefinite delle proprietà Spark e Hadoop di scalabilità automatica
I cluster con scalabilità automatica hanno valori predefiniti delle proprietà del cluster che aiutano a evitare l'errore del job quando i worker principali vengono rimossi o i worker secondari vengono prerilasciati. Puoi eseguire l'override di questi valori predefiniti quando crei un cluster con scalabilità automatica (vedi Proprietà del cluster).
Valori predefiniti per aumentare il numero massimo di tentativi per attività, application master e fasi:
yarn:yarn.resourcemanager.am.max-attempts=10 mapred:mapreduce.map.maxattempts=10 mapred:mapreduce.reduce.maxattempts=10 spark:spark.task.maxFailures=10 spark:spark.stage.maxConsecutiveAttempts=10
Valore predefinito per reimpostare i contatori dei tentativi (utile per i job Spark Streaming di lunga durata):
spark:spark.yarn.am.attemptFailuresValidityInterval=1h spark:spark.yarn.executor.failuresValidityInterval=1h
Impostazione predefinita per l'avvio lento di Spark allocazione dinamica del meccanismo a partire da una dimensione ridotta:
spark:spark.executor.instances=2
Domande frequenti
Questa sezione contiene domande e risposte comuni sullo scalabilità automatica.
È possibile attivare la scalabilità automatica su cluster ad alta disponibilità e cluster a nodo singolo?
La scalabilità automatica può essere abilitata sui cluster ad alta disponibilità, ma non sui cluster a nodo singolo (i cluster a nodo singolo non supportano il ridimensionamento).
È possibile ridimensionare manualmente un cluster di scalabilità automatica?
Sì. Potresti decidere di ridimensionare manualmente un cluster come misura provvisoria durante la messa a punto di un criterio di scalabilità automatica. Tuttavia, queste modifiche avranno solo un effetto temporaneo e la scalabilità automatica alla fine ridimensionerà il cluster.
Invece di ridimensionare manualmente un cluster di scalabilità automatica, valuta la possibilità di:
Aggiornamento del criterio di scalabilità automatica. Qualsiasi modifica apportata alla policy di scalabilità automatica influirà su tutti i cluster che attualmente utilizzano la policy (vedi Utilizzo delle policy multi-cluster).
Scollegamento del criterio e scalabilità manuale del cluster alla dimensione preferita.
Richiedere assistenza per Dataproc.
In che modo la scalabilità automatica di Dataproc è diversa da quella di Dataflow?
Consulta Scalabilità automatica orizzontale di Dataflow e Scalabilità automatica verticale di Dataflow Prime.
Il team di sviluppo di Dataproc può reimpostare lo stato del cluster da ERROR a RUNNING?
In generale, no. Questa operazione richiede un intervento manuale per verificare se è sicuro reimpostare lo stato del cluster e spesso un cluster non può essere reimpostato senza altri passaggi manuali, come il riavvio di HDFS NameNode.
Dataproc imposta lo stato di un cluster su ERROR quando
non riesce a determinare lo stato di un cluster dopo un'operazione non riuscita. I cluster in
ERROR non vengono scalati automaticamente. Alcune cause comuni sono:
Errori restituiti dall'API Compute Engine, spesso durante le interruzioni di Compute Engine.
HDFS entra in uno stato danneggiato a causa di bug nel ritiro di HDFS.
Errori dell'API Dataproc Control, ad esempio "Task lease expired" (Lease attività scaduto).
Elimina e ricrea i cluster il cui stato è ERROR.
Quando la scalabilità automatica annulla un'operazione di riduzione della scalabilità?
La seguente immagine è un'illustrazione che mostra quando la scalabilità automatica annulla un'operazione di scale down (vedi anche Come funziona la scalabilità automatica).
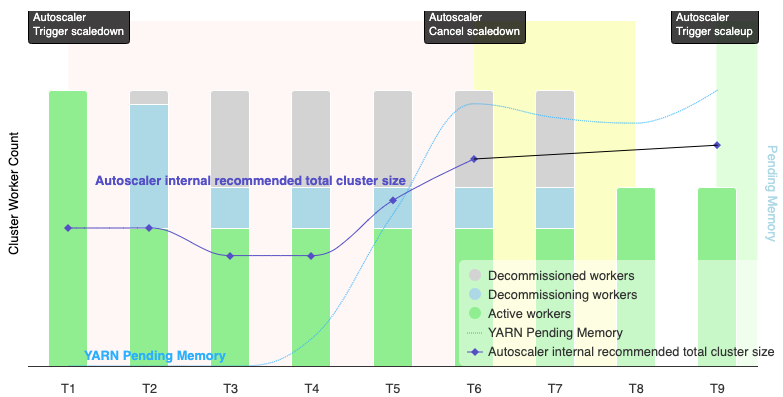
Note:
- Il cluster ha la scalabilità automatica attivata solo in base alle metriche di memoria YARN (impostazione predefinita).
- T1-T9 rappresentano gli intervalli di raffreddamento durante i quali il gestore della scalabilità automatica valuta il numero di worker (la tempistica degli eventi è stata semplificata).
- Le barre in pila rappresentano i conteggi dei worker YARN del cluster attivi, in fase di ritiro e ritirati.
- Il numero di worker consigliato dal gestore della scalabilità automatica (linea nera) si basa sulle metriche di memoria YARN, sul conteggio dei worker attivi YARN e sulle impostazioni dei criteri di scalabilità automatica (vedi Come funziona la scalabilità automatica).
- L'area con sfondo rosso indica il periodo in cui è in esecuzione l'operazione di riduzione delle dimensioni.
- L'area con sfondo giallo indica il periodo in cui l'operazione di riduzione della scalabilità viene annullata.
- L'area con sfondo verde indica il periodo dell'operazione di scalabilità verticale.
Le seguenti operazioni vengono eseguite nei seguenti orari:
T1: il gestore della scalabilità automatica avvia un'operazione di riduzione rimozione controllata perfare lo scale downe circa la metà dei worker del cluster attuali.
T2: Il gestore della scalabilità automatica continua a monitorare le metriche del cluster. Non modifica il suggerimento di riduzione e l'operazione di riduzione continua. Alcuni worker sono stati ritirati e altri sono in fase di ritiro (Dataproc eliminerà i worker ritirati).
T3: il gestore della scalabilità automatica calcola che il numero di worker può essere fare lo scale down ulteriormente, probabilmente perché è disponibile ulteriore memoria YARN. Tuttavia, poiché il numero di worker attivi più la variazione consigliata del numero di worker non è uguale o maggiore del numero di worker attivi più quelli da ritirare, i criteri per l'annullamento della riduzione non sono soddisfatti e il gestore della scalabilità automatica non annulla l'operazione di riduzione.
T4: YARN segnala un aumento della memoria in attesa. Tuttavia, il gestore della scalabilità automatica non modifica il numero di worker consigliato. Come in T3, i criteri di annullamento dello scale down rimangono insoddisfatti e il gestore della scalabilità automatica non annulla l'operazione di scale down.
T5: La memoria in attesa di YARN aumenta e la variazione del numero di worker consigliata dal gestore della scalabilità automatica aumenta. Tuttavia, poiché il numero di worker attivi più la variazione consigliata del numero di worker è inferiore al numero di worker attivi più quelli di ritiro, i criteri di annullamento rimangono insoddisfatti e l'operazione di riduzione delle risorse non viene annullata.
T6: La memoria YARN in attesa aumenta ulteriormente. Il numero di worker attivi più la variazione del numero di worker consigliati dallo strumento di scalabilità automatica ora è maggiore del numero di worker attivi più quelli in fase di ritiro. I criteri di annullamento vengono soddisfatti e il gestore della scalabilità automatica annulla l'operazione di scale down.
T7: Il gestore della scalabilità automatica è in attesa del completamento dell'annullamento dell'operazione di riduzione della scalabilità. Il gestore della scalabilità automatica non valuta e non consiglia una modifica del numero di worker durante questo intervallo.
T8: L'annullamento dell'operazione di riduzione delle dimensioni viene completato. I worker di ritiro vengono aggiunti al cluster e diventano attivi. Il gestore della scalabilità automatica rileva il completamento dell'annullamento dell'operazione di riduzione e attende il periodo di valutazione successivo (T9) per calcolare il numero consigliato di worker.
T9: Non sono presenti operazioni attive all'ora T9. In base ai criteri del gestore della scalabilità automatica e alle metriche YARN, il gestore della scalabilità automatica consiglia un'operazione di scale up.