Apache Airflow-DAG in Cloud Composer 1 ausführen
Cloud Composer 3 | Cloud Composer 2 | Cloud Composer 1
In dieser Kurzanleitung erfahren Sie, wie Sie eine Cloud Composer-Umgebung erstellen und einen Apache Airflow-DAG in Cloud Composer 1 ausführen.
Wenn Sie Airflow noch nicht kennen, finden Sie in der Apache Airflow-Dokumentation im Airflow-Konzepte-Tutorial weitere Informationen zu den Konzepten und Objekten von Airflow und deren Anwendung.
Wenn Sie stattdessen die Google Cloud CLI verwenden möchten, lesen Sie den Hilfeartikel Apache Airflow-DAG in Cloud Composer ausführen (Google Cloud CLI).
Wenn Sie eine Umgebung mit Terraform erstellen möchten, lesen Sie den Hilfeartikel Umgebungen erstellen (Terraform).
Hinweis
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
Enable the Cloud Composer API.
-
Bitten Sie Ihren Administrator, Ihnen die folgenden IAM-Rollen für Ihr Projekt zuzuweisen, um die Berechtigungen zu erhalten, die Sie zum Ausführen der Kurzanleitung benötigen:
-
So rufen Sie die Cloud Composer-Umgebung auf, erstellen sie und verwalten sie:
-
Administrator für Umgebung und Storage-Objekte (
roles/composer.environmentAndStorageObjectAdmin) -
Service Account User (
roles/iam.serviceAccountUser)
-
Administrator für Umgebung und Storage-Objekte (
-
So rufen Sie Logs auf:
Loganzeige (
roles/logging.viewer)
Weitere Informationen zum Zuweisen von Rollen finden Sie unter Zugriff auf Projekte, Ordner und Organisationen verwalten.
Sie können die erforderlichen Berechtigungen auch über benutzerdefinierte Rollen oder andere vordefinierte Rollen erhalten.
-
So rufen Sie die Cloud Composer-Umgebung auf, erstellen sie und verwalten sie:
Dienstkonto einer Umgebung erstellen
Wenn Sie eine Umgebung erstellen, geben Sie ein Dienstkonto an. Dieses Dienstkonto wird als Dienstkonto der Umgebung bezeichnet. In Ihrer Umgebung wird dieses Dienstkonto für die meisten Vorgänge verwendet.
Das Dienstkonto für Ihre Umgebung ist kein Nutzerkonto. Ein Dienstkonto ist ein spezieller Kontotyp, der nicht von einer Person, sondern von einer Anwendung oder einer VM-Instanz verwendet wird.
So erstellen Sie ein Dienstkonto für Ihre Umgebung:
Erstellen Sie ein neues Dienstkonto, wie in der Dokumentation zur Identitäts- und Zugriffsverwaltung beschrieben.
Weisen Sie ihm eine Rolle zu, wie in der Identity and Access Management-Dokumentation beschrieben. Die erforderliche Rolle ist Composer-Worker (
composer.worker).
Umgebung erstellen
Rufen Sie in der Google Cloud Console die Seite Umgebung erstellen auf.
Geben Sie im Feld Name
example-environmentein.Wählen Sie in der Drop-down-Liste Standort eine Region für die Cloud Composer-Umgebung aus. In diesem Leitfaden wird die Region
us-central1verwendet.Übernehmen Sie für die anderen Optionen der Umgebungskonfiguration die angegebenen Standardeinstellungen.
Klicken Sie auf Erstellen und warten Sie, bis die Umgebung erstellt wurde.
Danach wird neben dem Umgebungsnamen ein grünes Häkchen angezeigt.
DAG-Datei erstellen
Ein Airflow-DAG ist eine Sammlung strukturierter Aufgaben, die Sie planen und ausführen möchten. DAGs werden in Standard-Python-Dateien definiert.
In dieser Anleitung wird ein Beispiel-Airflow-DAG verwendet, das in der Datei quickstart.py definiert ist.
Der Python-Code in dieser Datei führt Folgendes aus:
- Der DAG
composer_sample_dagwird erstellt. Dieser DAG wird jeden Tag ausgeführt. - Die Aufgabe
print_dag_run_confwird ausgeführt. Sie gibt mithilfe des bash-Operators die Konfiguration der DAG-Ausführung aus.
Speichern Sie eine Kopie der Datei quickstart.py auf Ihrem lokalen Computer:
DAG-Datei in den Bucket Ihrer Umgebung hochladen
Jede Cloud Composer-Umgebung ist mit einem Cloud Storage-Bucket verknüpft. Airflow in Cloud Composer plant nur DAGs, die sich in diesem Bucket im Ordner /dags befinden.
Zum Planen Ihres DAG laden Sie quickstart.py von Ihrem lokalen Computer in den Ordner /dags Ihrer Umgebung hoch:
Rufen Sie in der Google Cloud Console die Seite Umgebungen auf.
Klicken Sie in der Liste der Umgebungen auf den Namen Ihrer Umgebung,
example-environment. Die Seite Umgebungsdetails wird geöffnet.Klicken Sie auf DAGs-Ordner öffnen. Die Seite Bucket-Details wird geöffnet.
Klicken Sie auf Dateien hochladen und wählen Sie dann Ihre Kopie von
quickstart.pyaus.Klicken Sie zum Hochladen der Datei auf Öffnen.
DAG aufrufen
Nachdem Sie die DAG-Datei hochgeladen haben, geschieht in Airflow Folgendes:
- Die hochgeladene DAG-Datei wird geparst. Es kann einige Minuten dauern, bis der DAG für Airflow verfügbar ist.
- Der DAG wird der Liste der verfügbaren DAGs hinzugefügt.
- Führt den DAG gemäß dem Zeitplan aus, den Sie in der DAG-Datei angegeben haben.
Prüfen Sie, ob Ihr DAG ohne Fehler verarbeitet wird und in Airflow verfügbar ist. Rufen Sie ihn dazu in der DAG-Benutzeroberfläche auf. Die DAG-Benutzeroberfläche ist die Cloud Composer-Oberfläche, über die Sie DAG-Informationen in der Google Cloud Console aufrufen können. Cloud Composer bietet auch Zugriff auf die Airflow-Benutzeroberfläche, eine native Airflow-Weboberfläche.
Warten Sie etwa fünf Minuten, damit Airflow die zuvor hochgeladene DAG-Datei verarbeiten und die erste DAG-Ausführung abschließen kann (wird später erläutert).
Rufen Sie in der Google Cloud Console die Seite Umgebungen auf.
Klicken Sie in der Liste der Umgebungen auf den Namen Ihrer Umgebung,
example-environment. Die Seite Umgebungsdetails wird geöffnet.Rufen Sie den Tab DAGs auf.
Prüfen Sie, ob der DAG
composer_quickstartin der Liste der DAGs enthalten ist.
Abbildung 1: In der Liste der DAGs wird der DAG „composer_quickstart“ angezeigt (zum Vergrößern anklicken).
Details zur DAG-Ausführung ansehen
Eine einzelne Ausführung eines DAG wird als DAG-Ausführung bezeichnet. Airflow führt sofort eine DAG-Ausführung für den Beispiel-DAG aus, da das Startdatum in der DAG-Datei auf „gestern“ festgelegt ist. So gleicht Airflow den Zeitplan des angegebenen DAGs wieder an.
Der Beispiel-DAG enthält eine Aufgabe, print_dag_run_conf, die den Befehl echo in der Console ausführt. Mit diesem Befehl werden Metainformationen zum DAG ausgegeben (numerische Kennung der DAG-Ausführung).
Klicken Sie auf dem Tab DAGs auf
composer_quickstart. Der Tab Ausführungen für den DAG wird geöffnet.Klicken Sie in der Liste der DAG-Ausführungen auf den ersten Eintrag.
Abbildung 2. Liste der DAG-Ausführungen für den DAG „composer_quickstart“ (zum Vergrößern klicken) Die Details zur DAG-Ausführung werden angezeigt, einschließlich Informationen zu den einzelnen Aufgaben der Beispiel-DAG.
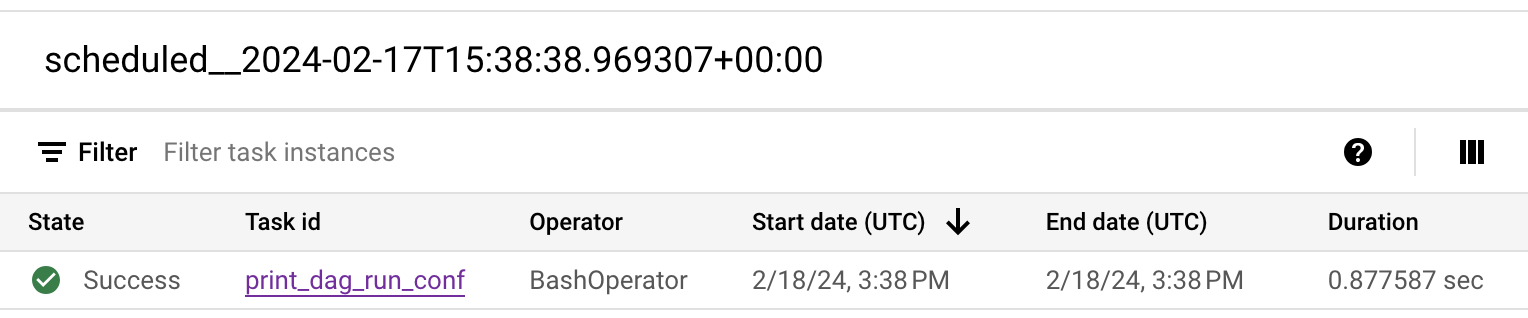
Abbildung 3. Liste der Aufgaben, die bei der DAG-Ausführung ausgeführt wurden (zum Vergrößern klicken) Im Abschnitt Logs für DAG-Ausführung sind Logs für alle Aufgaben in der DAG-Ausführung aufgeführt. Die Ausgabe des Befehls
echofinden Sie in den Protokollen.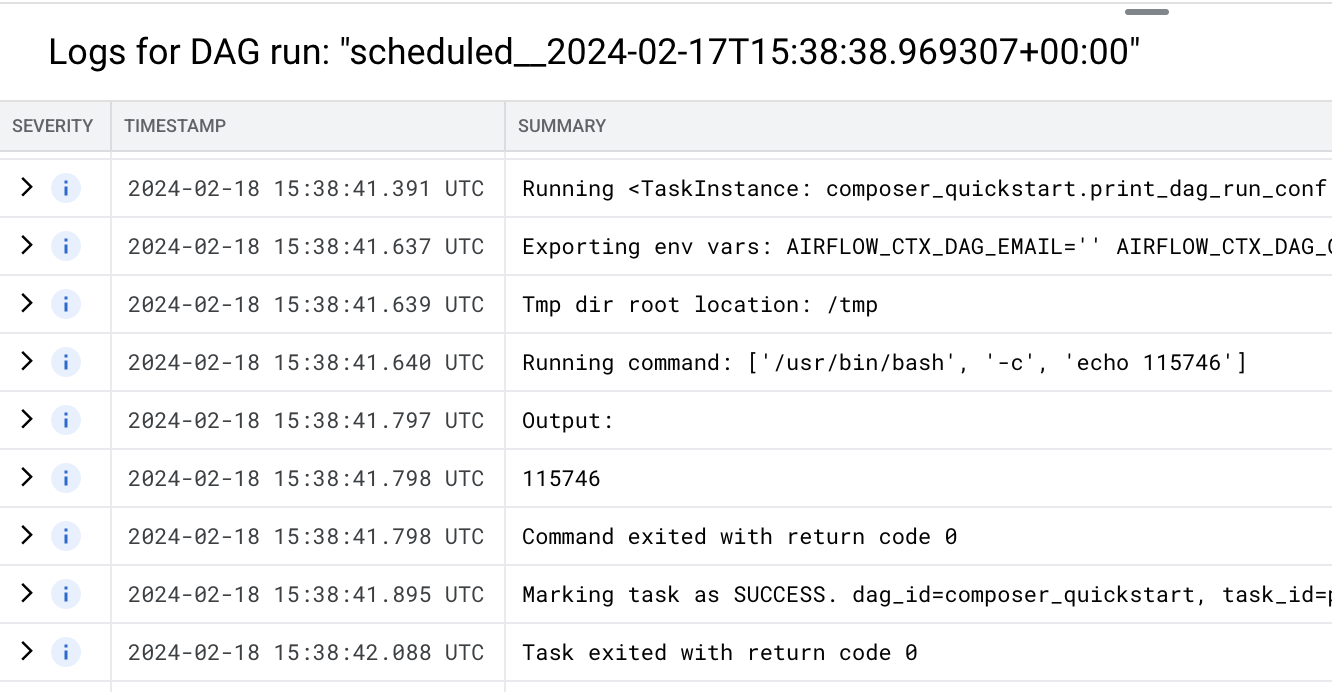
Abbildung 4: Protokolle der Aufgabe „print_dag_run_conf“ (zum Vergrößern anklicken)
Bereinigen
Mit den folgenden Schritten vermeiden Sie, dass Ihrem Google Cloud -Konto die in dieser Anleitung verwendeten Ressourcen in Rechnung gestellt werden:
Löschen Sie die Ressourcen, die in dieser Anleitung verwendet wurden:
Löschen Sie die Cloud Composer-Umgebung.
Rufen Sie in der Google Cloud Console die Seite Umgebungen auf.
Wählen Sie
example-environmentaus und klicken Sie auf Löschen.Warten Sie, bis die Umgebung gelöscht ist.
Löschen Sie den Bucket Ihrer Umgebung. Durch das Löschen der Cloud Composer-Umgebung wird dessen Bucket nicht gelöscht.
Rufen Sie in der Google Cloud Console die Seite Speicher > Browser auf.
Wählen Sie den Bucket der Umgebung aus und klicken Sie auf Löschen. Dieser Bucket kann beispielsweise
us-central1-example-environ-c1616fe8-bucketheißen.
Nächste Schritte