콘솔에서 쿼리 빌드
Bigtable Studio 쿼리 빌더를 사용해서 Bigtable 데이터를 쿼리하고 볼 수 있습니다. 쿼리 빌더는 Google Cloud 콘솔에서 쿼리를 빌드하고, 테이블에 대해 실행하고, 콘솔에서 결과를 볼 수 있게 해주는 대화형 양식입니다.
Bigtable Studio 쿼리 빌더에서는 애플리케이션을 작성하거나 CLI를 사용할 필요 없이 드롭다운 선택기를 사용해서 쿼리 절 조합을 지정할 수 있습니다. 쿼리를 실행하면 콘솔이 Bigtable Data API를 호출하여 쿼리와 일치하는 데이터를 반환합니다.
이 문서에서는 쿼리 빌더를 사용하는 방법을 설명하고 쿼리 최적화에 대한 팁을 제공합니다. 이 페이지를 읽기 전에 Bigtable 개요를 숙지해야 합니다.
쿼리 빌더에서 실행되는 쿼리에는 테이블에 전송되는 다른 쿼리와 동일한 가격 책정 및 할당량이 적용됩니다.
쿼리 빌더를 사용해야 하는 경우
Google Cloud 콘솔에서 Bigtable 데이터를 쿼리하는 기능은 다음을 수행해야 할 때 유용합니다.
- 테이블의 스키마를 시각적으로 빠르게 표현합니다.
- 특정 데이터가 성공적으로 기록되었는지 확인합니다.
- 마이그레이션 중에 데이터 무결성을 검증합니다.
- 발생 가능한 데이터 문제를 디버깅합니다.
- 코드에서 사용하기 전에 특정 절 조합이 반환하는 결과를 미리봅니다. 이는 특히 Bigtable 신규 사용자는 물론
cbtCLI 사용을 원하지 않는 숙련된 사용자에게도 유용합니다.
시작하기 전에
쿼리 빌더를 사용하는 데 필요한 권한을 얻으려면 관리자에게 프로젝트에 대해 Bigtable 리더 (roles/bigtable.reader) IAM 역할을 부여해 달라고 요청하세요.
역할 부여에 대한 자세한 내용은 프로젝트, 폴더, 조직에 대한 액세스 관리를 참조하세요.
이 사전 정의된 역할에는 쿼리 빌더를 사용하는 데 필요한 권한이 포함되어 있습니다. 필요한 정확한 권한을 보려면 필수 권한 섹션을 펼치세요.
필수 권한
쿼리 빌더를 사용하려면 다음 권한이 필요합니다.
-
bigtable.tables.get -
bigtable.instances.get -
bigtable.appProfiles.list -
bigtable.tables.list -
bigtable.tables.readRows
커스텀 역할이나 다른 사전 정의된 역할을 사용하여 이 권한을 부여받을 수도 있습니다.
쿼리할 테이블이 없으면 작은 테스트 테이블을 만들고 이에 대해 쿼리를 실행할 수 있습니다.
쿼리 빌더 열기
쿼리 빌더를 열면 기본 쿼리가 실행되고 인스턴스에서 알파벳 순으로 첫 번째 테이블에 대해 표시됩니다. 기본 쿼리는 기본 앱 프로필을 사용하여 실행되고 최대 100개의 행이 반환됩니다.
Google Cloud 콘솔에서 Bigtable 인스턴스 목록을 엽니다.
쿼리하려는 테이블이 포함된 인스턴스 이름을 클릭합니다.
탐색창에서 Bigtable Studio를 클릭합니다. Bigtable Studio 페이지가 쿼리 빌더 모드로 열립니다. 탐색기 창에 인스턴스의 테이블 목록이 제공되고 쿼리 결과 창에 기본 쿼리 결과가 표시됩니다.
선택사항: 쿼리 빌더 창을 더 크게 표시하려면 탐색기 창을 축소합니다.
데이터 표시 형식
쿼리 빌더 결과가 테이블에 표시됩니다. 첫 번째 제목 및 열은 row key입니다. 나머지 제목은 각각 콜론으로 구분된 column family 및 column qualifier로 표시되는 Bigtable 테이블의 열을 나타냅니다. 예를 들어 cell_plan: data_plan_01gb 제목은 해당 열의 값이 data_plan_01gb 열 및 cell_plan column family에서 가져온 것임을 나타냅니다.
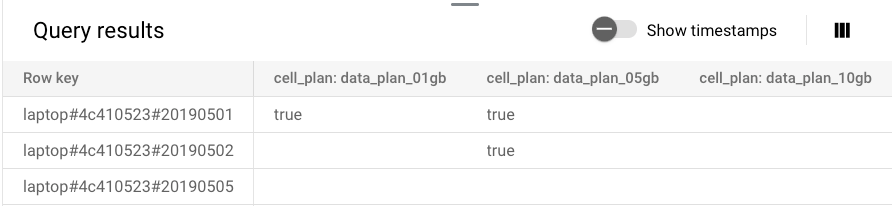
열의 최근 값만 반환됩니다. 타임스탬프는 기본적으로 숨겨지지만 전환 버튼을 클릭해서 이를 표시할 수 있습니다.
테이블 선택
테이블 드롭다운을 사용해서 쿼리하려는 테이블의 ID를 선택합니다.
선택사항: 앱 프로필 지정
특히 쿼리 빌더에 사용하기 위해 만드는 앱 프로필을 사용할 수 있습니다. 이 방법은 예를 들어 기본 애플리케이션에서 사용하는 클러스터가 아닌 다른 클러스터를 사용하여 쿼리 트래픽을 격리하려는 경우에 유용할 수 있습니다.
다른 앱 프로필을 사용해서 다음 쿼리를 실행하려면 다음 단계를 수행합니다.
- 쿼리에 추가를 클릭합니다.
- 앱 프로필 변경(기본값)을 클릭합니다. 새 드롭다운이 표시됩니다.
- 앱 프로필 드롭다운을 사용하여 인스턴스의 앱 프로필 목록 중에서 선택합니다.
여러 다른 워크로드에 대해 서로 다른 앱 프로필을 사용하는 이점에 대해 자세히 알아보려면 앱 프로필 정보를 참조하세요. 앱 프로필을 만드는 방법은 앱 프로필 만들기 및 구성을 참조하세요.
테이블이 애플리케이션을 사용하는 인스턴스에 있으면 지리적으로 사용자에게 가장 가까운 클러스터에서 읽기를 수행하도록 앱 프로필을 구성합니다.
쿼리에 절 추가 후 실행
- 테이블과 앱 프로필을 선택한 후 쿼리에 절을 추가합니다. 사용 가능한 절에 대한 자세한 내용은 다음 섹션을 참조하세요.
- 절을 모두 추가한 후 실행을 클릭합니다.
- 결과를 확인합니다.
쿼리 절
쿼리 빌더를 사용하여 쿼리에 절을 추가합니다. 쿼리를 실행하면 쿼리 빌더가 읽기 요청을 만들고 이를 테이블로 전송합니다. 읽기 요청에 대한 자세한 내용은 읽기를 참조하세요.
row key, row key 범위, row key 프리픽스 절은 스토리지에서 가져오는 행을 결정합니다. row key 정규식, 열, 시간 범위 절은 생성된 읽기 요청에 필터를 추가합니다. 쿼리 빌더에서 사용하는 필터는 클라이언트 라이브러리에서 사용할 때와 동일하게 작동합니다. Bigtable 필터 세부정보 및 사용 시 성능에 미치는 영향은 필터 및 필터 사용을 참조하세요.
row key 지정
테이블에서 단일 행을 검색하려면 row key 값을 제공합니다. row key 절을 여러 개 추가할 수 있습니다.
- 쿼리에 추가를 클릭합니다.
- 드롭다운 목록에서 row key를 선택합니다.
- 값을 보려는 row key의 정확한 값을 입력합니다.
row key 범위 지정
테이블에서 행 범위를 검색하려면 시작 및 종료 row key를 지정합니다. Bigtable은 row key에 따라 사전순으로 데이터를 저장합니다.
- 쿼리에 추가를 클릭합니다.
- 드롭다운 목록에서 row key 범위를 선택합니다.
- 전체 시작 row key를 입력합니다.
- 전체 종료 row key를 입력합니다.
row key 프리픽스 지정
row key가 특정 문자 집합으로 시작되는 행만 검색하려면 row key 프리픽스로 필터링합니다. row key 프리픽스는 row key의 처음 N개 문자입니다. 기본적으로 row key의 프리픽스와 나머지 부분 사이에는 해시태그, 파이프, 기타 기호가 자주 사용됩니다.
- 쿼리에 추가를 클릭합니다.
- 드롭다운 목록에서 row key 프리픽스를 선택합니다.
- row key 프리픽스를 입력합니다. 와일드 카드 기호는 입력할 필요가 없습니다.
row key 정규식으로 필터링
row key 값이 지정된 정규 표현식과 일치하는 행만 가져오려면 row key 정규식 필터를 사용합니다. 성능 향상을 위해서는 row key 정규식 필터를 추가하기 전에 row key 범위 또는 row key 프리픽스 절을 추가합니다. 정규식 작성에 대한 안내는 row key 정규식을 참조하세요.
- 쿼리에 추가를 클릭합니다.
- 드롭다운 목록에서 row key 정규식을 선택합니다.
- re2 구문을 사용하는 정규 표현식을 입력합니다.
열로 필터링
쿼리에 포함할 열을 하나 이상 지정하려면 열 절을 추가해서 필터링하려는 각 열에 대해 column family 및 column qualifier를 선택합니다. 이 절을 추가할 때 생성되는 읽기 요청에는 column family 정규식 필터 및 열 범위 필터가 포함됩니다.
- 쿼리에 추가를 클릭합니다.
- 드롭다운 목록에서 열을 선택합니다.
- 열 필드를 클릭합니다. column family 목록이 표시됩니다.
- column family ID를 클릭합니다. column family 목록이 표시됩니다.
- column qualifier를 클릭합니다.
기간으로 필터링
특정 범위 내의 타임스탬프가 포함된 셀만 검색하려면 타임스탬프 범위 필터를 사용하는 기간 절을 추가합니다.
- 쿼리에 추가를 클릭합니다.
- 드롭다운 목록에서 기간을 선택합니다.
- 시작 타임스탬프를 입력합니다.
- 종료 타임스탬프를 입력합니다.
다음 형식 중 하나로 타임스탬프를 제공합니다.
- 마이크로초 단위의 Unix 타임스탬프(예:
3023483279876000) - YYYY-MM-DDThh:mm:ss:ss[z]
- YYYY/MM/DD-hh:mm:ss.sss[z]
- MM/DD/YYYY
- YYYY/MM/DD
선택적인 T는 시간을 나타내는 리터럴이고 선택적인 z는 로컬 시간 대신 UTC 시간을 나타냅니다. 타임스탬프 형식에 대한 자세한 내용은 ISO 8601을 참조하세요.
한도 지정
반환되는 최대 행수를 지정하려면 한도 절을 추가합니다.
- 쿼리에 추가를 클릭합니다.
- 드롭다운 목록에서 한도를 선택합니다.
- 1~100 사이의 숫자를 입력합니다.
제한사항
쿼리 빌더에는 다음과 같은 제한사항이 적용됩니다.
- 셀당 1,000자 - Bigtable은 셀당 최대 1,000자를 반환합니다. 셀에 1,000자 넘게 포함된 경우 표시되지 않는 문자 수와 함께 잘린 결과가 표시됩니다.
- 최대 100개 열 - Bigtable은 쿼리와 일치하는 각 행의 처음 100개 열을 반환합니다. column family는 특정 순서로 저장되지 않지만 해당 column family 내에서 열이 사전순으로 정렬됩니다.
- 최대 1,000 행 - 쿼리 빌더는 쿼리와 일치하는 최대 1,000개의 데이터 행을 반환합니다.
- Base64 - Bigtable은 Base64 인코딩 데이터를 정확하게 표시하려고 하지만 결과가 보장되지 않습니다. Bigtable이 셀의 데이터를 표시할 수 없으면 대신 셀 값의 크기가 바이트로 표시됩니다.
이전 데이터 - 쿼리하는 열의 최신 셀(또는 버전)만 검색할 수 있습니다. 이 개념에 대한 자세한 내용은 Bigtable 스토리지 모델 및 일반 개념을 참조하세요.
직렬화된 데이터 - 프로토콜 버퍼로 저장된 데이터는 쿼리 결과에 올바르게 표시되지 않습니다. JSON 데이터가 더 잘 지원되지만 올바른 표시가 보장되지 않습니다.
인위적인 타임스탬프 - 애플리케이션이 테이블에 데이터를 기록할 때 셀의 타임스탬프 속성에 타임스탬프 이외의 숫자를 할당할 경우 쿼리에서 기간 필터를 사용하여 타임스탬프 대신 사용하는 값의 범위를 가져올 수 있습니다. 단 이를 마이크로초로 지정해야 합니다. 테이블 데이터에 인위적인 타임스탬프가 사용될 수 있는 이유는 타임스탬프를 참조하세요.