本文介绍将数据从 Apache HBase 集群迁移到Google Cloud上的 Bigtable 实例时的注意事项和流程。
本页所述的流程要求您将应用设为离线状态。如果您想在迁移过程中实现零停机时间,请参阅从 HBase 复制到 Bigtable 中的在线迁移指南。
如需将数据从 Google Cloud 服务(如 Dataproc 或 Compute Engine)上托管的 HBase 集群迁移到 Bigtable,请参阅将 Google Cloud 上托管的 HBase 迁移到 Bigtable。
在开始迁移之前,您应该考虑性能影响、Bigtable 架构设计、身份验证和授权方法以及 Bigtable 功能集。
迁移前的注意事项
本部分针对您在开始迁移之前应注意并考虑的一些事项提出建议。
性能
在典型工作负载下,Bigtable 的性能具有高度可预测性。在迁移数据之前,请确保您了解影响 Bigtable 性能的因素。
Bigtable 架构设计
在大多数情况下,您可以在 Bigtable 中使用与 HBase 中相同的架构设计。如果您想要更改架构或用例发生变化,请在迁移数据之前先查看设计架构中列出的一些概念。
身份验证和授权
在为 Bigtable 设计访问权限控制之前,请查看现有的 HBase 身份验证和授权流程。
Bigtable 使用 Google Cloud的标准身份验证机制和 Identity and Access Management 来提供访问权限控制,因此您可以将 HBase 上的现有授权转换为 IAM。您可以将为 HBase 提供访问权限控制机制的现有 Hadoop 组映射到不同的服务账号。
通过 Bigtable,您可以在项目级层、实例级层和表级层控制访问权限。如需了解详情,请参阅访问权限控制。
停机时间要求
本页介绍的迁移方法涉及在迁移期间将应用置于离线状态。如果您的企业在迁移到 Bigtable 时无法容忍停机,请参阅从 HBase 复制到 Bigtable,了解在线迁移指南。
将 HBase 迁移到 Bigtable
如需将数据从 HBase 迁移到 Bigtable,请将每个表的 HBase 快照导出到 Cloud Storage,然后将数据导入 Bigtable。这些步骤适用于单个 HBase 集群,接下来几个部分将对此进行详细介绍。
- 停止向 HBase 集群发送写入数据。
- 截取 HBase 集群表的快照。
- 将快照文件导出到 Cloud Storage。
- 计算哈希值并将其导出到 Cloud Storage。
- 在 Bigtable 中创建目标表。
- 将 HBase 数据从 Cloud Storage 导入 Bigtable。
- 验证导入的数据。
- 将写入内容路由到 Bigtable。
准备工作
创建 Cloud Storage 存储桶以存储快照。在计划运行 Dataflow 作业的位置创建存储桶。
创建 Bigtable 实例以存储新表。
确定要导出的 Hadoop 集群。您可以直接在 HBase 集群或与 HBase 集群的 Namenode 和 Datanode 建立网络连接的单独 Hadoop 集群上运行迁移作业。
在 Hadoop 集群的每个节点以及在其中启动作业的主机上安装和配置 Cloud Storage 连接器。如需了解详细安装步骤,请参阅安装 Cloud Storage 连接器。
在可连接到 HBase 集群和 Bigtable 项目的主机上打开一个命令 shell。您将在该 shell 中完成后续步骤。
获取 Schema Translation 工具:
wget BIGTABLE_HBASE_TOOLS_URL将
BIGTABLE_HBASE_TOOLS_URL替换为该工具的 Maven 代码库中可用的最新JAR with dependencies的网址。文件名类似于https://repo1.maven.org/maven2/com/google/cloud/bigtable/bigtable-hbase-1.x-tools/1.24.0/bigtable-hbase-1.x-tools-1.24.0-jar-with-dependencies.jar。如需查找网址或手动下载 JAR,请执行以下操作:
- 转到代码库。
- 点击最新的版本号。
- 找到
JAR with dependencies file(通常位于顶部)。 - 右键点击并复制网址,或点击以下载该文件。
获取导入工具:
wget BIGTABLE_BEAM_IMPORT_URL将
BIGTABLE_BEAM_IMPORT_URL替换为该工具的 Maven 代码库中可用的最新shaded JAR的网址。文件名类似于https://repo1.maven.org/maven2/com/google/cloud/bigtable/bigtable-beam-import/1.24.0/bigtable-beam-import-1.24.0-shaded.jar。如需查找网址或手动下载 JAR,请执行以下操作:
- 转到代码库。
- 点击最新的版本号。
- 点击下载内容。
- 将鼠标悬停在 shaded.jar 上。
- 右键点击并复制网址,或点击以下载该文件。
设置以下环境变量:
#Google Cloud export PROJECT_ID=PROJECT_ID export INSTANCE_ID=INSTANCE_ID export REGION=REGION export CLUSTER_NUM_NODES=CLUSTER_NUM_NODES #JAR files export TRANSLATE_JAR=TRANSLATE_JAR export IMPORT_JAR=IMPORT_JAR #Cloud Storage export BUCKET_NAME="gs://BUCKET_NAME" export MIGRATION_DESTINATION_DIRECTORY="$BUCKET_NAME/hbase-migration-snap" #HBase export ZOOKEEPER_QUORUM=ZOOKEPER_QUORUM export ZOOKEEPER_PORT=2181 export ZOOKEEPER_QUORUM_AND_PORT="$ZOOKEEPER_QUORUM:$ZOOKEEPER_PORT" export MIGRATION_SOURCE_DIRECTORY=MIGRATION_SOURCE_DIRECTORY替换以下内容:
PROJECT_ID:您的实例所在的 Google Cloud 项目INSTANCE_ID:要向其中导入数据的 Bigtable 实例的标识符REGION:包含 Bigtable 实例中某一集群的区域。示例:northamerica-northeast2CLUSTER_NUM_NODES:Bigtable 实例中的节点数TRANSLATE_JAR:您从 Maven 下载的bigtable hbase toolsJAR 文件的名称和版本号。该值应该类似于bigtable-hbase-1.x-tools-1.24.0-jar-with-dependencies.jar。IMPORT_JAR:您从 Maven 下载的bigtable-beam-importJAR 文件的名称和版本号。该值应该类似于bigtable-beam-import-1.24.0-shaded.jar。BUCKET_NAME:您存储快照的 Cloud Storage 存储桶的名称ZOOKEEPER_QUORUM:该工具将连接的 zooKeeper 主机,格式为host1.myownpersonaldomain.comMIGRATION_SOURCE_DIRECTORY:HBase 主机上用于保存要迁移的数据的目录,格式为hdfs://host1.myownpersonaldomain.com:8020/hbase
(可选)如需确认变量已正确设置,请运行
printenv命令以查看所有环境变量。
停止向 HBase 发送写入
在截取 HBase 表的快照之前,停止向 HBase 集群发送写入数据。
截取 HBase 表快照
当 HBase 集群不再注入数据时,请为计划迁移到 Bigtable 的每个表截取快照。
快照最初在 HBase 集群上占用的存储空间很小,但随着时间的推移,其大小可能会增长到与原始表相同。快照不会消耗任何 CPU 资源。
对每个表运行以下命令,并对每个快照使用唯一名称:
echo "snapshot 'TABLE_NAME', 'SNAPSHOT_NAME'" | hbase shell -n
替换以下内容:
TABLE_NAME:要从中导出数据的 HBase 表的名称。SNAPSHOT_NAME:新快照的名称
将 HBase 快照导出到 Cloud Storage
创建快照后,需要导出快照。在 HBase 生产集群上执行导出作业时,请监控集群和其他 HBase 资源,以确保集群保持良好状态。
对于要导出的每个快照,请运行以下命令:
hbase org.apache.hadoop.hbase.snapshot.ExportSnapshot \
-Dhbase.zookeeper.quorum=$ZOOKEEPER_QUORUM_AND_PORT -snapshot SNAPSHOT_NAME \
-copy-from $MIGRATION_SOURCE_DIRECTORY \
-copy-to $MIGRATION_DESTINATION_DIRECTORY/data
将 SNAPSHOT_NAME 替换为要导出的快照的名称。
计算和导出哈希值
接下来,创建哈希,以便在迁移完成后用于验证。HashTable 是 HBase 提供的验证工具,可计算行范围的哈希值并将其导出到文件中。您可以在目标表上运行 sync-table 作业,以匹配哈希值并确保迁移后数据的完整性。
对导出的每个表运行以下命令:
hbase org.apache.hadoop.hbase.mapreduce.HashTable --batchsize=32000 --numhashfiles=20 \
TABLE_NAME $MIGRATION_DESTINATION_DIRECTORY/hashtable/TABLE_NAME
替换以下内容:
TABLE_NAME:您为其创建快照并导出的 HBase 表的名称
创建目标表
下一步是在 Bigtable 实例中为导出的每个快照创建目标表。使用对实例具有 bigtable.tables.create 权限的账号。
本指南使用 Bigtable Schema Translation 工具,该工具会自动为您创建表。但是,如果您不希望 Bigtable 架构与 HBase 架构完全匹配,可以使用 cbt 命令行工具或 Google Cloud 控制台创建表。
Bigtable Schema Translation 工具可捕获 HBase 表的架构,包括表名称、列族、垃圾回收政策和分块。然后,它在 Bigtable 中创建一个类似的表。
对于要导入的每个表,请运行以下命令,将架构从 HBase 复制到 Bigtable。
java \
-Dgoogle.bigtable.project.id=$PROJECT_ID \
-Dgoogle.bigtable.instance.id=$INSTANCE_ID \
-Dgoogle.bigtable.table.filter=TABLE_NAME \
-Dhbase.zookeeper.quorum=$ZOOKEEPER_QUORUM \
-Dhbase.zookeeper.property.clientPort=$ZOOKEEPER_PORT \
-jar $TRANSLATE_JAR
将 TABLE_NAME 替换为您要导入的 HBase 表的名称。Schema Translation 工具会为新的 Bigtable 表使用此名称。
您还可以视情况将 TABLE_NAME 替换为正则表达式,例如“.*”,这样会捕获要创建的所有表,然后仅运行一次该命令。
使用 Dataflow 将 HBase 数据导入 Bigtable
准备好要向其迁移数据的目标表后,您就可以导入并验证数据了。
未压缩的表
如果 HBase 表未压缩,请对要迁移的每个表运行以下命令:
java -jar $IMPORT_JAR importsnapshot \
--runner=DataflowRunner \
--project=$PROJECT_ID \
--bigtableInstanceId=$INSTANCE_ID \
--bigtableTableId=TABLE_NAME \
--hbaseSnapshotSourceDir=$MIGRATION_DESTINATION_DIRECTORY/data \
--snapshotName=SNAPSHOT_NAME \
--stagingLocation=$MIGRATION_DESTINATION_DIRECTORY/staging \
--tempLocation=$MIGRATION_DESTINATION_DIRECTORY/temp \
--maxNumWorkers=$(expr 3 \* $CLUSTER_NUM_NODES) \
--region=$REGION
替换以下内容:
TABLE_NAME:您要导入的 HBase 表的名称。Schema Translation 工具会为新的 Bigtable 表使用此名称。不支持使用新的表名称。SNAPSHOT_NAME:您为要导入的表的快照分配的名称
运行该命令后,该工具会将 HBase 快照恢复到 Cloud Storage 存储桶,然后启动导入作业。恢复快照的过程可能需要几分钟时间才能完成,具体取决于快照的大小。
导入时请谨记以下提示:
- 要提高数据加载的性能,请务必设置
maxNumWorkers。 此值有助于确保导入作业具有足够的计算能力,能够在合理的时间内完成导入,同时避免 Bigtable 实例过载。- 如果您未将 Bigtable 实例用于其他工作负载,请将 Bigtable 实例中的节点数乘以 3,然后将此数字用于
maxNumWorkers。 - 如果您要在导入 HBase 数据的同时将该实例用于其他工作负载,请适当降低
maxNumWorkers的值。
- 如果您未将 Bigtable 实例用于其他工作负载,请将 Bigtable 实例中的节点数乘以 3,然后将此数字用于
- 使用默认工作器类型。
- 在导入期间,您应监控 Bigtable 实例的 CPU 使用情况。如果 Bigtable 实例的 CPU 利用率过高,则可能需要添加更多节点。集群最多可能需要 20 分钟即可完成此操作,从而降低利用率,提高性能。
如需详细了解如何监控 Bigtable 实例,请参阅监控。
Snappy 压缩表
如果您要导入 Snappy 压缩表,则需要在 Dataflow 流水线中使用自定义容器映像。您用于将压缩数据导入 Bigtable 的自定义容器映像会提供 Hadoop 原生压缩库支持。您必须拥有 Apache Beam SDK 2.30.0 版或更高版本才能使用 Dataflow Runner v2,并且必须拥有 Java 版 HBase 客户端库 2.3.0 版或更高版本。
如需导入 Snappy 压缩表,请运行针对未压缩表的相同命令,但需要添加以下选项:
--enableSnappy=true
验证 Bigtable 中导入的数据
如需验证导入的数据,您需要运行 sync-table 作业。sync-table 作业会计算 Bigtable 中行范围的哈希值,然后将其与之前计算的 HashTable 输出匹配。
如需运行 sync-table 作业,请在命令 shell 中运行以下命令:
java -jar $IMPORT_JAR sync-table \
--runner=dataflow \
--project=$PROJECT_ID \
--bigtableInstanceId=$INSTANCE_ID \
--bigtableTableId=TABLE_NAME \
--outputPrefix=$MIGRATION_DESTINATION_DIRECTORY/sync-table/output-TABLE_NAME-$(date +"%s") \
--stagingLocation=$MIGRATION_DESTINATION_DIRECTORY/sync-table/staging \
--hashTableOutputDir=$MIGRATION_DESTINATION_DIRECTORY/hashtable/TABLE_NAME \
--tempLocation=$MIGRATION_DESTINATION_DIRECTORY/sync-table/dataflow-test/temp \
--region=$REGION
将 TABLE_NAME 替换为您要导入的 HBase 表的名称。
sync-table 作业完成后,打开 Dataflow 作业详情页面,然后查看该作业的自定义计数器部分。如果导入作业成功导入所有数据,则 ranges_matched 的值和 ranges_not_matched 的值为 0。
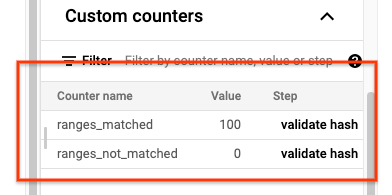
如果 ranges_not_matched 显示值,请打开日志页面,选择工作器日志,并按不匹配范围进行过滤。这些日志的机器可读输出存储于您在同步表 outputPrefix 选项中创建的 Cloud Storage 输出目标位置。
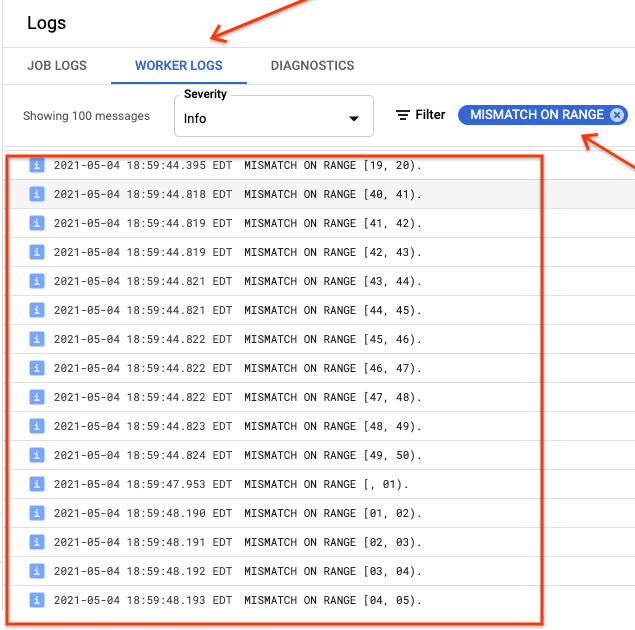
您可以重新尝试导入作业或编写脚本来读取输出文件以确定出现不匹配的位置。输出文件中的每一行都是不匹配范围的一个序列化 JSON 记录。
将写入路由到 Bigtable
验证集群中每个表的数据后,您可以配置应用以将所有流量路由到 Bigtable,然后弃用 HBase 实例。
迁移完成后,您便可以删除 HBase 实例上的快照。
后续步骤
- 详细了解 Cloud Storage。