This page describes considerations and processes for migrating data from an Apache HBase cluster to a Bigtable instance on Google Cloud.
The process described on this page requires you to take your application offline. If you want to migrate with no downtime, see the guidance for online migration at Replicate from HBase to Bigtable.
To migrate data to Bigtable from an HBase cluster that is hosted on a Google Cloud service, such as Dataproc or Compute Engine, see Migrating HBase hosted on Google Cloud to Bigtable.
Before you begin this migration, you should consider performance implications, Bigtable schema design, your approach to authentication and authorization, and the Bigtable feature set.
Pre-migration considerations
This section suggests a few things to review and think about before you begin your migration.
Performance
Under a typical workload, Bigtable delivers highly predictable performance. Make sure that you understand the factors that affect Bigtable performance before you migrate your data.
Bigtable schema design
In most cases, you can use the same schema design in Bigtable as you do in HBase. If you want to change your schema or if your use case is changing, review the concepts laid out in Designing your schema before you migrate your data.
Authentication and authorization
Before you design access control for Bigtable, review the existing HBase authentication and authorization processes.
Bigtable uses Google Cloud's standard mechanisms for authentication and Identity and Access Management to provide access control, so you convert your existing authorization on HBase to IAM. You can map the existing Hadoop groups that provide access control mechanisms for HBase to different service accounts.
Bigtable allows you to control access at the project, instance, and table levels. For more information, see Access Control.
Downtime requirement
The migration approach that is described on this page involves taking your application offline for the duration of the migration. If your business can't tolerate downtime while you migrate to Bigtable, see the guidance for online migration at Replicate from HBase to Bigtable.
Migrate HBase to Bigtable
To migrate your data from HBase to Bigtable, you export an HBase snapshot for each table to Cloud Storage and then import the data into Bigtable. These steps are for a single HBase cluster and are described in detail in the next several sections.
- Stop sending writes to your HBase cluster.
- Take snapshots of the HBase cluster's tables.
- Export the snapshot files to Cloud Storage.
- Compute hashes and export them to Cloud Storage.
- Create destination tables in Bigtable.
- Import the HBase data from Cloud Storage into Bigtable.
- Validate the imported data.
- Route writes to Bigtable.
Before you begin
Create a Cloud Storage bucket to store your snapshots. Create the bucket in the same location that you plan to run your Dataflow job in.
Create a Bigtable instance to store your new tables.
Identify the Hadoop cluster that you are exporting. You can run the jobs for your migration either directly on the HBase cluster or on a separate Hadoop cluster that has network connectivity to the HBase cluster's Namenode and Datanodes.
Install and configure the Cloud Storage connector on every node in the Hadoop cluster as well as the host where the job is initiated from. For detailed installation steps, see Installing the Cloud Storage connector.
Open a command shell on a host that can connect to your HBase cluster and your Bigtable project. This is where you'll complete the next steps.
Get the Schema Translation tool:
wget BIGTABLE_HBASE_TOOLS_URLReplace
BIGTABLE_HBASE_TOOLS_URLwith the URL of the latestJAR with dependenciesavailable in the tool's Maven repository. The file name is similar tohttps://repo1.maven.org/maven2/com/google/cloud/bigtable/bigtable-hbase-1.x-tools/1.24.0/bigtable-hbase-1.x-tools-1.24.0-jar-with-dependencies.jar.To find the URL or to manually download the JAR, do the following:
- Go to the repository.
- Click the most recent version number.
- Identify the
JAR with dependencies file(usually at the top). - Either right-click and copy the URL, or click to download the file.
Get the Import tool:
wget BIGTABLE_BEAM_IMPORT_URLReplace
BIGTABLE_BEAM_IMPORT_URLwith the URL of the latestshaded JARavailable in the tool's Maven repository. The file name is similar tohttps://repo1.maven.org/maven2/com/google/cloud/bigtable/bigtable-beam-import/1.24.0/bigtable-beam-import-1.24.0-shaded.jar.To find the URL or to manually download the JAR, do the following:
- Go to the repository.
- Click the most recent version number.
- Click Downloads.
- Mouse over shaded.jar.
- Either right-click and copy the URL, or click to download the file.
Set the following environment variables:
#Google Cloud export PROJECT_ID=PROJECT_ID export INSTANCE_ID=INSTANCE_ID export REGION=REGION export CLUSTER_NUM_NODES=CLUSTER_NUM_NODES #JAR files export TRANSLATE_JAR=TRANSLATE_JAR export IMPORT_JAR=IMPORT_JAR #Cloud Storage export BUCKET_NAME="gs://BUCKET_NAME" export MIGRATION_DESTINATION_DIRECTORY="$BUCKET_NAME/hbase-migration-snap" #HBase export ZOOKEEPER_QUORUM=ZOOKEPER_QUORUM export ZOOKEEPER_PORT=2181 export ZOOKEEPER_QUORUM_AND_PORT="$ZOOKEEPER_QUORUM:$ZOOKEEPER_PORT" export MIGRATION_SOURCE_DIRECTORY=MIGRATION_SOURCE_DIRECTORYReplace the following:
PROJECT_ID: the Google Cloud project that your instance is inINSTANCE_ID: the identifier of the Bigtable instance that you are importing your data toREGION: a region that contains one of the clusters in your Bigtable instance. Example:northamerica-northeast2CLUSTER_NUM_NODES: the number of nodes in your Bigtable instanceTRANSLATE_JAR: the name and version number of thebigtable hbase toolsJAR file that you downloaded from Maven. The value should look something likebigtable-hbase-1.x-tools-1.24.0-jar-with-dependencies.jar.IMPORT_JAR: the name and version number of thebigtable-beam-importJAR file that you downloaded from Maven. The value should look something likebigtable-beam-import-1.24.0-shaded.jar.BUCKET_NAME: the name of the Cloud Storage bucket where you are storing your snapshotsZOOKEEPER_QUORUM: the zookeeper host that the tool will connect to, in the formathost1.myownpersonaldomain.comMIGRATION_SOURCE_DIRECTORY: the directory on your HBase host that holds the data that you want to migrate, in the formathdfs://host1.myownpersonaldomain.com:8020/hbase
(Optional) To confirm that the variables were set correctly, run the
printenvcommand to view all environment variables.
Stop sending writes to HBase
Before you take snapshots of your HBase tables, stop sending writes to your HBase cluster.
Take HBase table snapshots
When your HBase cluster is no longer ingesting data, take a snapshot of each table that you plan to migrate to Bigtable.
A snapshot has a minimal storage footprint on the HBase cluster at first, but over time it might grow to the same size as the original table. The snapshot does not consume any CPU resources.
Run the following command for each table, using a unique name for each snapshot:
echo "snapshot 'TABLE_NAME', 'SNAPSHOT_NAME'" | hbase shell -n
Replace the following:
TABLE_NAME: the name of the HBase table that you are exporting data from.SNAPSHOT_NAME: the name for the new snapshot
Export the HBase snapshots to Cloud Storage
After you create the snapshots, you need to export them. When you're executing export jobs on a production HBase cluster, monitor the cluster and other HBase resources to ensure that the clusters remain in a good state.
For each snapshot that you want to export, run the following:
hbase org.apache.hadoop.hbase.snapshot.ExportSnapshot \
-Dhbase.zookeeper.quorum=$ZOOKEEPER_QUORUM_AND_PORT -snapshot SNAPSHOT_NAME \
-copy-from $MIGRATION_SOURCE_DIRECTORY \
-copy-to $MIGRATION_DESTINATION_DIRECTORY/data
Replace SNAPSHOT_NAME with the name of the snapshot to
export.
Compute and export hashes
Next, create hashes to use for validation after the migration is complete.
HashTable is a validation tool provided by HBase that computes hashes for
row ranges and exports them to files. You can run a sync-table job on the
destination table to match the hashes and gain confidence in the integrity of
migrated data.
Run the following command for each table that you exported:
hbase org.apache.hadoop.hbase.mapreduce.HashTable --batchsize=32000 --numhashfiles=20 \
TABLE_NAME $MIGRATION_DESTINATION_DIRECTORY/hashtable/TABLE_NAME
Replace the following:
TABLE_NAME: the name of the HBase table that you created a snapshot for and exported
Create destination tables
The next step is to create a destination table in your Bigtable
instance for each snapshot that you exported. Use an account that has
bigtable.tables.create permission for the instance.
This guide uses the
Bigtable Schema Translation tool,
which automatically creates the table for you. However, if you don't want your
Bigtable schema to exactly match the HBase schema, you can
create a table using the
cbt command-line tool or the Google Cloud console.
The Bigtable Schema Translation tool captures the schema of the HBase table, including the table name, column families, garbage collection policies, and splits. Then it creates a similar table in Bigtable.
For each table that you want to import, run the following to copy the schema from HBase to Bigtable.
java \
-Dgoogle.bigtable.project.id=$PROJECT_ID \
-Dgoogle.bigtable.instance.id=$INSTANCE_ID \
-Dgoogle.bigtable.table.filter=TABLE_NAME \
-Dhbase.zookeeper.quorum=$ZOOKEEPER_QUORUM \
-Dhbase.zookeeper.property.clientPort=$ZOOKEEPER_PORT \
-jar $TRANSLATE_JAR
Replace TABLE_NAME with the name of the HBase table
that you are importing. The Schema Translation tool uses this name for
your new Bigtable table.
You can also optionally replace TABLE_NAME with a
regular expression, such as ".*", that captures all the tables that you want to
create, and then run the command only once.
Import the HBase data into Bigtable using Dataflow
After you have a table ready to migrate your data to, you are ready to import and validate your data.
Uncompressed tables
If your HBase tables are not compressed, run the following command for each table that you want to migrate:
java -jar $IMPORT_JAR importsnapshot \
--runner=DataflowRunner \
--project=$PROJECT_ID \
--bigtableInstanceId=$INSTANCE_ID \
--bigtableTableId=TABLE_NAME \
--hbaseSnapshotSourceDir=$MIGRATION_DESTINATION_DIRECTORY/data \
--snapshotName=SNAPSHOT_NAME \
--stagingLocation=$MIGRATION_DESTINATION_DIRECTORY/staging \
--tempLocation=$MIGRATION_DESTINATION_DIRECTORY/temp \
--maxNumWorkers=$(expr 3 \* $CLUSTER_NUM_NODES) \
--region=$REGION
Replace the following:
TABLE_NAME: the name of the HBase table that you are importing. The Schema Translation tool gives uses this name for your new Bigtable table. New table names are not supported.SNAPSHOT_NAME: the name that you assigned to the snapshot of the table that you are importing
After you run the command, the tool restores the HBase snapshot to your Cloud Storage bucket, then starts the import job. It can take several minutes for the process of restoring the snapshot to finish, depending on the size of the snapshot.
Keep the following tips in mind when you import:
- To improve the performance of data loading, be sure to set
maxNumWorkers. This value helps to ensure that the import job has enough compute power to complete in a reasonable amount of time, but not so much that it would overwhelm the Bigtable instance.- If you are not also using the Bigtable instance for another
workload, multiply the number of nodes in your Bigtable
instance by 3, and use that number for
maxNumWorkers. - If you are using the instance for another workload at the same time that
you are importing your HBase data, reduce the value of
maxNumWorkersappropriately.
- If you are not also using the Bigtable instance for another
workload, multiply the number of nodes in your Bigtable
instance by 3, and use that number for
- Use the default worker type.
- During the import, you should monitor the Bigtable instance's CPU usage. If the CPU utilization across the Bigtable instance is too high, you might need to add additional nodes. It can take up to 20 minutes for the cluster to provide the performance benefit of additional nodes.
For more information about monitoring the Bigtable instance, see Monitoring.
Snappy compressed tables
If you are importing Snappy compressed tables, you need to use a custom container image in the Dataflow pipeline. The custom container image that you use to import compressed data into Bigtable provides Hadoop native compression library support. You must have the Apache Beam SDK version 2.30.0 or later to use Dataflow Runner v2, and you must have version 2.3.0 or later of the HBase client library for Java.
To import Snappy compressed tables, run the same command that you run for uncompressed tables, but add the following option:
--enableSnappy=true
Validate the imported data in Bigtable
To validate the imported data, you need to run the sync-table job. The
sync-table job computes hashes for row ranges in Bigtable,
then matches them with the HashTable output that you computed earlier.
To run the sync-table job, run the following in the command shell:
java -jar $IMPORT_JAR sync-table \
--runner=dataflow \
--project=$PROJECT_ID \
--bigtableInstanceId=$INSTANCE_ID \
--bigtableTableId=TABLE_NAME \
--outputPrefix=$MIGRATION_DESTINATION_DIRECTORY/sync-table/output-TABLE_NAME-$(date +"%s") \
--stagingLocation=$MIGRATION_DESTINATION_DIRECTORY/sync-table/staging \
--hashTableOutputDir=$MIGRATION_DESTINATION_DIRECTORY/hashtable/TABLE_NAME \
--tempLocation=$MIGRATION_DESTINATION_DIRECTORY/sync-table/dataflow-test/temp \
--region=$REGION
Replace TABLE_NAME with the name of the HBase table
that you are importing.
When the sync-table job is complete, open the Dataflow Job details page and
review the Custom counters section for the job. If the import job
successfully imports all of the data, the value for ranges_matched has a
value and the value for ranges_not_matched is 0.

If ranges_not_matched shows a value, open the Logs page, choose
Worker Logs, and filter by Mismatch on range. The machine-readable
output of these logs is stored in Cloud Storage at the output
destination that you create in the sync-table outputPrefix option.
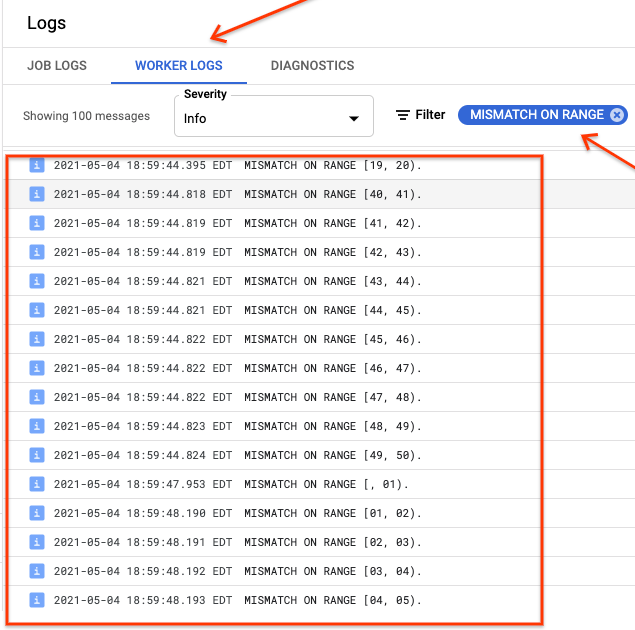
You can try the import job again or write a script to read the output files to determine where the mismatches occurred. Each line in the output file is a serialized JSON record of a mismatched range.
Route writes to Bigtable
After you've validated the data for each table in the cluster, you can configure your applications to route all their traffic to Bigtable, then deprecate the HBase instance.
When your migration is complete, you can delete the snapshots on your HBase instance.
What's next
- Learn more about Cloud Storage.