Nesta página, você verá considerações e processos para migrar dados de um cluster Apache HBase para uma instância do Bigtable no Google Cloud.
O processo descrito nesta página exige que você coloque o aplicativo off-line. Se você quiser migrar sem tempo de inatividade, consulte as orientações para migração on-line em Replicar do HBase para o Bigtable.
Para migrar dados para o Bigtable de um cluster do HBase que está hospedado em um Google Cloud serviço, como o Dataproc ou o Compute Engine, consulte Como migrar o HBase hospedado no Google Cloud para o Bigtable.
Antes de começar essa migração, avalie as implicações de desempenho, o design do esquema do Bigtable, as consequências para sua abordagem de autenticação e autorização e o conjunto de recursos do Bigtable.
Considerações pré-migração
Nesta seção, oferecemos algumas considerações e considerações antes de iniciar a migração.
Desempenho
No processamento de cargas de trabalho típicas, o Bigtable tem um desempenho altamente previsível. Entenda os fatores que afetam o desempenho do Bigtable antes de migrar seus dados.
Projeto de esquema do Bigtable
Na maioria dos casos, é possível usar o mesmo design de esquema usado no Bigtable. Se você quiser alterar seu esquema ou se seu caso de uso for alterado, revise os conceitos descritos em Como projetar seu esquema antes de migrar seus dados.
Autenticação e autorização
Antes de projetar o controle de acesso para o Bigtable, analise os processos atuais de autenticação e autorização do HBase.
O Bigtable usa os mecanismos padrão do Google Cloud para autenticação e o Identity and Access Management para fornecer controle de acesso. Assim, você converte sua autorização atual no HBase para o IAM. É possível mapear os grupos atuais do Hadoop que fornecem mecanismos de controle de acesso para o HBase para diferentes contas de serviço.
O Bigtable permite controlar o acesso nos níveis de projeto, instância e tabela. Para mais informações, consulte Controle de acesso.
Requisito de inatividade
A abordagem de migração descrita nesta página envolve colocar seu aplicativo off-line durante a migração. Se sua empresa não puder tolerar inatividade durante a migração para o Bigtable, consulte as orientações para migração on-line em Replicar do HBase para o Bigtable.
Migração do HBase para o Bigtable
Para migrar seus dados do HBase para o Bigtable, exporte um snapshot do HBase para cada tabela no Cloud Storage e importe os dados para o Bigtable. Essas etapas são para um único cluster HBase e são descritas em detalhes nas próximas seções.
- Interrompa o envio de gravações para o cluster HBase.
- Tire snapshots das tabelas do cluster do HBase.
- Exporte os arquivos de snapshot para o Cloud Storage.
- Calcular hash e exportá-los para o Cloud Storage
- Crie tabelas de destino no Bigtable.
- Importe os dados do HBase do Cloud Storage para o Bigtable.
- Validar os dados importados.
- Gravações de rota para o Bigtable.
Antes de começar
Crie um bucket do Cloud Storage para armazenar os snapshots. Crie o bucket no mesmo local em que você planeja executar o job do Dataflow.
Crie uma instância do Bigtable para armazenar suas novas tabelas.
Identifique o cluster do Hadoop que você está exportando. É possível executar os jobs para a migração diretamente no cluster do HBase ou em um cluster do Hadoop separado que tenha conectividade de rede com o namenode e os datanodes do cluster do HBase.
Instale e configure o conector do Cloud Storage em cada nó no cluster do Hadoop, bem como o host de onde o job é iniciado. Para ver os detalhes das etapas de instalação, consulte Como instalar o conector do Cloud Storage.
Abra um shell de comando em um host que possa se conectar ao cluster HBase e ao projeto do Bigtable. É aqui que você concluirá as próximas etapas.
Instale a ferramenta Schema Translation:
wget BIGTABLE_HBASE_TOOLS_URLSubstitua
BIGTABLE_HBASE_TOOLS_URLpelo URL doJAR with dependenciesmais recente disponível no repositório Maven da ferramenta. O nome do arquivo é semelhante ahttps://repo1.maven.org/maven2/com/google/cloud/bigtable/bigtable-hbase-1.x-tools/1.24.0/bigtable-hbase-1.x-tools-1.24.0-jar-with-dependencies.jar.Para encontrar o URL ou fazer o download manual do JAR, faça o seguinte:
- Acesse o repositório.
- Clique no número da versão mais recente.
- Identifique o
JAR with dependencies file(geralmente na parte superior). - Clique com o botão direito do mouse e copie o URL ou clique para fazer o download do arquivo.
Instale a ferramenta de importação:
wget BIGTABLE_BEAM_IMPORT_URLSubstitua
BIGTABLE_BEAM_IMPORT_URLpelo URL doshaded JARmais recente disponível no repositório Maven da ferramenta. O nome do arquivo é semelhante ahttps://repo1.maven.org/maven2/com/google/cloud/bigtable/bigtable-beam-import/1.24.0/bigtable-beam-import-1.24.0-shaded.jar.Para encontrar o URL ou fazer o download manual do JAR, faça o seguinte:
- Acesse o repositório.
- Clique no número da versão mais recente.
- Clique em Downloads.
- Passe o mouse sobre shadow.jar.
- Clique com o botão direito do mouse e copie o URL ou clique para fazer o download do arquivo.
Configure as variáveis de ambiente a seguir:
#Google Cloud export PROJECT_ID=PROJECT_ID export INSTANCE_ID=INSTANCE_ID export REGION=REGION export CLUSTER_NUM_NODES=CLUSTER_NUM_NODES #JAR files export TRANSLATE_JAR=TRANSLATE_JAR export IMPORT_JAR=IMPORT_JAR #Cloud Storage export BUCKET_NAME="gs://BUCKET_NAME" export MIGRATION_DESTINATION_DIRECTORY="$BUCKET_NAME/hbase-migration-snap" #HBase export ZOOKEEPER_QUORUM=ZOOKEPER_QUORUM export ZOOKEEPER_PORT=2181 export ZOOKEEPER_QUORUM_AND_PORT="$ZOOKEEPER_QUORUM:$ZOOKEEPER_PORT" export MIGRATION_SOURCE_DIRECTORY=MIGRATION_SOURCE_DIRECTORYSubstitua:
PROJECT_ID: o projeto Google Cloud em que a instância estáINSTANCE_ID: o identificador da instância do Bigtable para a qual você está importando os dados;REGION: uma região que contém um dos clusters na instância do Bigtable. Exemplo:northamerica-northeast2CLUSTER_NUM_NODES: o número de nós da instância do BigtableTRANSLATE_JAR: o nome e o número da versão do arquivo JARbigtable hbase toolsque você baixou do Maven. O valor será semelhante abigtable-hbase-1.x-tools-1.24.0-jar-with-dependencies.jar.IMPORT_JAR: o nome e o número da versão do arquivo JARbigtable-beam-importque você baixou do Maven. O valor será semelhante abigtable-beam-import-1.24.0-shaded.jar.BUCKET_NAME: o nome do bucket do Cloud Storage em que você está armazenando os snapshotsZOOKEEPER_QUORUM: o host do zoológico a que a ferramenta se conectará, no formatohost1.myownpersonaldomain.comMIGRATION_SOURCE_DIRECTORY: o diretório no seu host do HBase que contém os dados que você quer migrar, no formatohdfs://host1.myownpersonaldomain.com:8020/hbase
(Opcional) Para confirmar se as variáveis foram definidas corretamente, execute o comando
printenvpara visualizar todas as variáveis de ambiente.
Parar de enviar gravações para o HBase
Antes de tirar snapshots das tabelas do HBase, pare de enviar gravações para o cluster do HBase.
Capturar snapshots da tabela HBase
Quando o cluster do HBase não estiver mais processando dados, tire um snapshot de cada tabela que você planeja migrar para o Bigtable.
Os snapshots têm um espaço mínimo de armazenamento no cluster HBase no início, mas, com o tempo, ele pode crescer para o mesmo tamanho da tabela original. O snapshot não consome recursos da CPU.
Execute o seguinte comando para cada tabela, usando um nome exclusivo para cada snapshot:
echo "snapshot 'TABLE_NAME', 'SNAPSHOT_NAME'" | hbase shell -n
Substitua:
TABLE_NAME: o nome da tabela HBase da qual você está exportando dados.SNAPSHOT_NAME: o nome do novo snapshot
Exportar os snapshots do HBase para o Cloud Storage
Depois de criar os snapshots, é necessário exportá-los. Ao executar jobs de exportação em um cluster de produção do HBase, monitore o cluster e outros recursos do HBase para garantir que os clusters permaneçam em um bom estado.
Para cada snapshot que você quer exportar, execute o seguinte comando:
hbase org.apache.hadoop.hbase.snapshot.ExportSnapshot \
-Dhbase.zookeeper.quorum=$ZOOKEEPER_QUORUM_AND_PORT -snapshot SNAPSHOT_NAME \
-copy-from $MIGRATION_SOURCE_DIRECTORY \
-copy-to $MIGRATION_DESTINATION_DIRECTORY/data
Substitua SNAPSHOT_NAME pelo nome do snapshot a ser
exportado.
Computação e exportação de hashes
Em seguida, crie hashes para usar na validação após a migração.
O HashTable é uma ferramenta de validação fornecida pelo HBase que calcula hashes para intervalos de linhas e os exporta para arquivos. Execute um job sync-table na tabela de destino para corresponder aos hashes e ganhar confiança na integridade dos dados migrados.
Execute o seguinte comando para cada tabela exportada:
hbase org.apache.hadoop.hbase.mapreduce.HashTable --batchsize=32000 --numhashfiles=20 \
TABLE_NAME $MIGRATION_DESTINATION_DIRECTORY/hashtable/TABLE_NAME
Substitua:
TABLE_NAME: o nome da tabela HBase para a qual você criou um snapshot e exportou
Criar tabelas de destino
A próxima etapa é criar uma tabela de destino na instância do Bigtable para cada snapshot exportado. Use uma conta que tenha permissão bigtable.tables.create para a instância.
Neste guia, usamos a ferramenta de tradução de esquema do Bigtable, que cria automaticamente a tabela para você. No entanto, se você não quiser que o esquema do Bigtable corresponda exatamente ao esquema do HBase, crie uma tabela usando a ferramenta de linha de comando cbt ou o console Google Cloud .
A ferramenta de tradução de esquemas do Bigtable captura o esquema da tabela HBase, incluindo o nome da tabela, grupos de colunas, políticas de coleta de lixo e divisões. Em seguida, ele cria uma tabela semelhante no Bigtable.
Para cada tabela que você quer importar, execute o código a seguir para copiar o esquema do HBase para o Bigtable.
java \
-Dgoogle.bigtable.project.id=$PROJECT_ID \
-Dgoogle.bigtable.instance.id=$INSTANCE_ID \
-Dgoogle.bigtable.table.filter=TABLE_NAME \
-Dhbase.zookeeper.quorum=$ZOOKEEPER_QUORUM \
-Dhbase.zookeeper.property.clientPort=$ZOOKEEPER_PORT \
-jar $TRANSLATE_JAR
Substitua TABLE_NAME pelo nome da tabela HBase que você está importando. A ferramenta Schema Translation usa esse nome para a nova tabela do Bigtable.
Outra opção é substituir TABLE_NAME por uma expressão regular, como ".*", que captura todas as tabelas que você quer criar e executa o comando apenas uma vez.
Importar os dados do HBase para o Bigtable usando o Dataflow
Depois de ter uma tabela pronta para migrar os dados, você está pronto para importar e validar os dados.
Tabelas descompactadas
Se as tabelas do HBase não estiverem compactadas, execute o seguinte comando para cada tabela que você quer migrar:
java -jar $IMPORT_JAR importsnapshot \
--runner=DataflowRunner \
--project=$PROJECT_ID \
--bigtableInstanceId=$INSTANCE_ID \
--bigtableTableId=TABLE_NAME \
--hbaseSnapshotSourceDir=$MIGRATION_DESTINATION_DIRECTORY/data \
--snapshotName=SNAPSHOT_NAME \
--stagingLocation=$MIGRATION_DESTINATION_DIRECTORY/staging \
--tempLocation=$MIGRATION_DESTINATION_DIRECTORY/temp \
--maxNumWorkers=$(expr 3 \* $CLUSTER_NUM_NODES) \
--region=$REGION
Substitua:
TABLE_NAME: o nome da tabela HBase que você está importando. A ferramenta Schema Translation fornece esse nome para sua nova tabela do Bigtable. Novos nomes de tabela não são compatíveis.SNAPSHOT_NAME: o nome que você atribuiu ao snapshot da tabela que está sendo importada.
Depois de executar o comando, a ferramenta restaura o snapshot do HBase no bucket do Cloud Storage e inicia o job de importação. Pode levar vários minutos para que o processo de restauração do snapshot seja concluído, dependendo do tamanho do snapshot.
Lembre-se destas dicas:
- Para melhorar o desempenho do carregamento de dados, defina
maxNumWorkers. Esse valor ajuda a garantir que o job de importação tenha potência de computação suficiente para ser concluído em um tempo razoável, mas não a ponto de sobrecarregar a instância do Bigtable.- Se você não estiver usando a instância do Bigtable para outra
carga de trabalho, multiplique o número de nós da instância
do Bigtable por 3 e use esse número para
maxNumWorkers. - Se estiver usando a instância para outra carga de trabalho ao mesmo tempo em que
você está importando seus dados do HBase, reduza o valor de
maxNumWorkersadequadamente.
- Se você não estiver usando a instância do Bigtable para outra
carga de trabalho, multiplique o número de nós da instância
do Bigtable por 3 e use esse número para
- Use o tipo de worker padrão.
- Durante a importação, monitore o uso da CPU da instância Bigtable. Se a utilização da CPU na instância do Bigtable for muito alta, talvez seja necessário adicionar nós. Pode levar até 20 minutos para o cluster apresente o benefício de desempenho dos nós extras.
Para mais informações sobre o monitoramento da instância do Bigtable, consulte Monitoramento.
Tabelas compactadas inteligentes
Se você estiver importando tabelas compactadas inteligentes, será necessário usar uma imagem de contêiner personalizada no pipeline do Dataflow. A imagem de contêiner personalizada que você usa para importar dados compactados para o Bigtable oferece suporte à biblioteca de compactação nativa do Hadoop. Você precisa ter a versão 2.30.0 ou posterior do SDK do Apache Beam para usar o Dataflow Runner v2. Além disso, é necessário ter a versão 2.3.0 ou mais recente da biblioteca de cliente do HBase para Java.
Para importar tabelas compactadas, execute o mesmo comando executado para tabelas descompactadas, mas adicione as duas opções a seguir.
--enableSnappy=true
Validar os dados importados no Bigtable
Para validar os dados importados, execute o job sync-table. O
job sync-table calcula hashes para intervalos de linhas no Bigtable e os corresponde à saída HashTable que você calculou anteriormente.
Para executar o job sync-table, execute o seguinte no shell de comando:
java -jar $IMPORT_JAR sync-table \
--runner=dataflow \
--project=$PROJECT_ID \
--bigtableInstanceId=$INSTANCE_ID \
--bigtableTableId=TABLE_NAME \
--outputPrefix=$MIGRATION_DESTINATION_DIRECTORY/sync-table/output-TABLE_NAME-$(date +"%s") \
--stagingLocation=$MIGRATION_DESTINATION_DIRECTORY/sync-table/staging \
--hashTableOutputDir=$MIGRATION_DESTINATION_DIRECTORY/hashtable/TABLE_NAME \
--tempLocation=$MIGRATION_DESTINATION_DIRECTORY/sync-table/dataflow-test/temp \
--region=$REGION
Substitua TABLE_NAME pelo nome da tabela HBase que você está importando.
Quando o job sync-table for concluído, abra a página Detalhes do job do Dataflow e consulte a seção Contadores personalizados do job. Se o job de importação
importar todos os dados com êxito, o valor de ranges_matched terá um
valor, e o valor de ranges_not_matched será 0
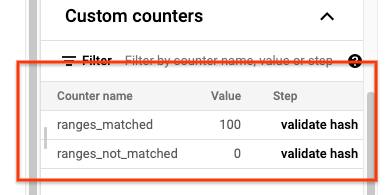
Se ranges_not_matched mostrar um valor, abra a página Registros, escolha
Registros do worker e filtre por Incompatibilidade em intervalo. A saída legível por máquina desses registros é armazenada no Cloud Storage no destino de saída criado na opção outputPrefix da tabela sincronizável.
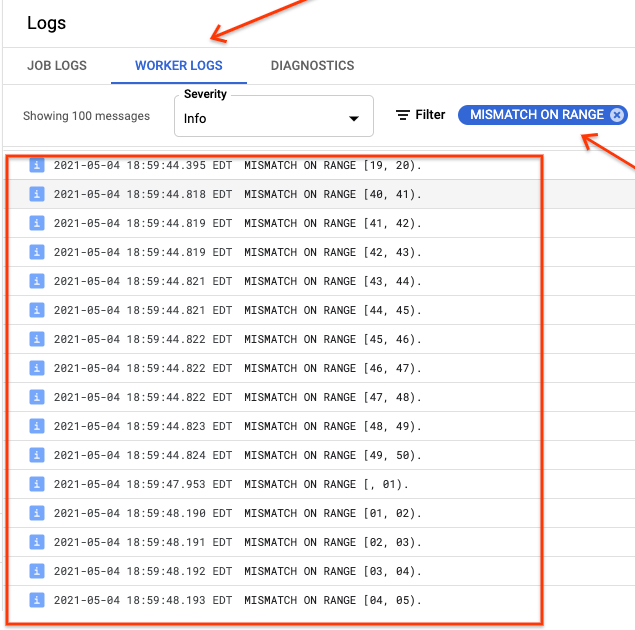
É possível tentar o job de importação novamente ou escrever um script para ler os arquivos de saída e determinar onde as incompatibilidades ocorreram. Cada linha no arquivo de saída é um registro JSON serializado de um intervalo incompatível.
Gravações de rota para o Bigtable
Depois de validar os dados de cada tabela no cluster, é possível configurar aplicativos para rotear todo o tráfego para o Bigtable e suspender o uso da instância do HBase.
Quando a migração estiver concluída, será possível excluir os snapshots na instância do HBase.
A seguir
- Saiba mais sobre o Cloud Storage.