Auf dieser Seite werden Überlegungen und Verfahren zur Migration von Daten von einem Apache HBase-Cluster zu einer Bigtable-Instanz inGoogle Cloudbeschrieben.
Für den auf dieser Seite beschriebenen Vorgang müssen Sie Ihre Anwendung offline nehmen. Wenn Sie ohne Ausfallzeit migrieren möchten, lesen Sie die Anleitung zur Onlinemigration unter Von HBase aus in Bigtable replizieren.
Informationen zum Migrieren von Daten zu Bigtable aus einem HBase-Cluster, der auf einem Google Cloud -Dienst wie Dataproc oder Compute Engine gehostet wird, finden Sie unter HBase, das auf Google Cloud gehostet wird, zu Bigtable migrieren.
Bevor Sie mit der Migration beginnen, bedenken Sie die Auswirkungen auf die Leistung, das Schemadesign von Bigtable, die Auswirkungen auf die Authentifizierung und Autorisierung und die Features von Bigtable.
Überlegungen vor der Migration
In diesem Abschnitt werden einige Punkte erläutert, die Sie vor der Migration bedenken sollten.
Leistung
Bei typischer Arbeitslast liefert Bigtable genau vorhersehbare Leistungen. Informieren Sie sich über die Faktoren, die sich auf die Bigtable-Leistung auswirken, bevor Sie Ihre Daten migrieren.
Bigtable-Schemadesign
In den meisten Fällen können Sie in Bigtable dasselbe Schemadesign wie in HBase verwenden. Wenn Sie Ihr Schema ändern möchten oder wenn sich Ihr Anwendungsfall ändert, lesen Sie die Konzepte unter Schema entwerfen, bevor Sie Ihre Daten migrieren.
Authentifizierung und Autorisierung
Lesen Sie die Informationen zu den vorhandenen HBase-Authentifizierungs- und Autorisierungsprozessen, bevor Sie die Zugriffssteuerung für Bigtable entwerfen.
Bigtable verwendet die Standardmechanismen für die Authentifizierung von Google Cloudund Identity and Access Management, um Zugriffssteuerungsfunktionen bereitzustellen. Entsprechend wird die auf HBase vorhandene Autorisierung in IAM konvertiert. Sie können die vorhandenen Hadoop-Gruppen, die Zugriffssteuerungsmechanismen für HBase ermöglichen, verschiedenen Dienstkonten zuordnen.
Mit Bigtable können Sie den Zugriff auf Projekt-, Instanz- und Tabellenebene verwalten. Weitere Informationen finden Sie unter Zugriffssteuerung.
Anforderung an Ausfallzeiten
Bei dem auf dieser Seite beschriebenen Migrationsansatz wird Ihre Anwendung für die Dauer der Migration offline genommen. Wenn Ihr Unternehmen während der Migration zu Bigtable keine Ausfallzeiten tolerieren kann, finden Sie unter Von HBase aus in Bigtable replizieren eine Anleitung zur Onlinemigration.
Von HBase zu Bigtable migrieren
Exportieren Sie für jede Tabelle einen HBase-Snapshot an Cloud Storage und importieren Sie die Daten dann in Bigtable, um Daten von HBase zu Bigtable zu migrieren. Diese Schritte beziehen sich auf einen einzelnen HBase-Cluster und werden in den nächsten Abschnitten ausführlich beschrieben.
- Beenden Sie das Senden von Schreibvorgängen an den HBase-Cluster.
- Erstellen Sie Snapshots der Tabellen des HBase-Clusters.
- Exportieren Sie die Snapshot-Dateien nach Cloud Storage.
- Berechnen Sie Hashes und exportieren Sie sie nach Cloud Storage
- Erstellen Sie Zieltabellen in Bigtable.
- Importieren Sie die HBase-Daten aus Cloud Storage nach Bigtable.
- Importierte Daten validieren
- Schreibvorgänge an Bigtable weiterleiten
Hinweis
Erstellen Sie einen Cloud Storage-Bucket zum Speichern Ihrer Snapshots. Erstellen Sie den Bucket am selben Speicherort, an dem Sie Ihren Dataflow-Job ausführen möchten.
Erstellen Sie eine Bigtable-Instanz zum Speichern Ihrer neuen Tabellen.
Identifizieren Sie den Hadoop-Cluster, den Sie exportieren möchten. Sie können die Jobs für Ihre Migration entweder direkt auf dem HBase-Cluster oder auf einem separaten Hadoop-Cluster ausführen, der eine Netzwerkverbindung zum NameNode und DataNodes des HBase-Clusters hat.
Installieren und konfigurieren Sie den Cloud Storage-Connector auf jedem Knoten im Hadoop-Cluster sowie auf dem Host, von dem aus der Job initiiert wird. Eine ausführliche Installationsanleitung finden Sie unter Installation des Cloud Storage-Connectors.
Öffnen Sie eine Befehls-Shell auf einem Host, der eine Verbindung zu Ihrem HBase-Cluster und Ihrem Bigtable-Projekt herstellen kann. Hier führen Sie die nächsten Schritte aus.
Rufen Sie das Tool Translation Schema ab:
wget BIGTABLE_HBASE_TOOLS_URLErsetzen Sie
BIGTABLE_HBASE_TOOLS_URLdurch die URL des neuestenJAR with dependencies, der im Maven-Repository des Tools verfügbar ist. Der Dateiname ähnelthttps://repo1.maven.org/maven2/com/google/cloud/bigtable/bigtable-hbase-1.x-tools/1.24.0/bigtable-hbase-1.x-tools-1.24.0-jar-with-dependencies.jar.So finden Sie die URL oder laden die JAR-Datei manuell herunter:
- Rufen Sie das Repository auf
- Klicken Sie auf die neueste Versionsnummer.
- Identifizieren Sie den
JAR with dependencies file(normalerweise oben). - Klicken Sie mit der rechten Maustaste und kopieren Sie die URL oder klicken Sie, um die Datei herunterzuladen.
Rufen Sie das Importtool auf:
wget BIGTABLE_BEAM_IMPORT_URLErsetzen Sie
BIGTABLE_BEAM_IMPORT_URLdurch die URL des neuestenshaded JAR, der im Maven-Repository des Tools verfügbar ist. Der Dateiname ähnelthttps://repo1.maven.org/maven2/com/google/cloud/bigtable/bigtable-beam-import/1.24.0/bigtable-beam-import-1.24.0-shaded.jar.So finden Sie die URL oder laden die JAR-Datei manuell herunter:
- Rufen Sie das Repository auf
- Klicken Sie auf die neueste Versionsnummer.
- Klicken Sie auf Downloads.
- Bewegen Sie den Mauszeiger auf Shading.jar.
- Klicken Sie mit der rechten Maustaste und kopieren Sie die URL oder klicken Sie, um die Datei herunterzuladen.
Legen Sie die folgenden Umgebungsvariablen fest:
#Google Cloud export PROJECT_ID=PROJECT_ID export INSTANCE_ID=INSTANCE_ID export REGION=REGION export CLUSTER_NUM_NODES=CLUSTER_NUM_NODES #JAR files export TRANSLATE_JAR=TRANSLATE_JAR export IMPORT_JAR=IMPORT_JAR #Cloud Storage export BUCKET_NAME="gs://BUCKET_NAME" export MIGRATION_DESTINATION_DIRECTORY="$BUCKET_NAME/hbase-migration-snap" #HBase export ZOOKEEPER_QUORUM=ZOOKEPER_QUORUM export ZOOKEEPER_PORT=2181 export ZOOKEEPER_QUORUM_AND_PORT="$ZOOKEEPER_QUORUM:$ZOOKEEPER_PORT" export MIGRATION_SOURCE_DIRECTORY=MIGRATION_SOURCE_DIRECTORYErsetzen Sie Folgendes:
PROJECT_ID: Das Google Cloud Projekt, in dem sich Ihre Instanz befindet.INSTANCE_ID: die ID der Bigtable-Instanz, in die Sie Ihre Daten importieren.REGION: eine Region, die einen der Cluster in Ihrer Bigtable-Instanz enthält. Beispiel:northamerica-northeast2CLUSTER_NUM_NODES: die Anzahl der Knoten in Ihrer Bigtable-InstanzTRANSLATE_JAR: der Name und die Versionsnummer der JAR-Dateibigtable hbase tools, die Sie von Maven heruntergeladen haben. Der Wert sollte in etwa so aussehen:bigtable-hbase-1.x-tools-1.24.0-jar-with-dependencies.jar.IMPORT_JAR: der Name und die Versionsnummer der JAR-Dateibigtable-beam-import, die Sie von Maven heruntergeladen haben. Der Wert sollte in etwa so aussehen:bigtable-beam-import-1.24.0-shaded.jar.BUCKET_NAME: der Name des Cloud Storage-Buckets, in dem Sie die Snapshots speichern.ZOOKEEPER_QUORUM: der Zookeeper-Host, zu dem das Tool eine Verbindung herstellt, im Formathost1.myownpersonaldomain.com.MIGRATION_SOURCE_DIRECTORY: das Verzeichnis auf Ihrem HBase-Host, das die zu migrierenden Daten im Formathdfs://host1.myownpersonaldomain.com:8020/hbaseenthält.
(Optional) Führen Sie den Befehl
printenvaus, um zu prüfen, ob die Variablen richtig festgelegt wurden. Damit können Sie alle Umgebungsvariablen aufrufen.
Senden von Schreibvorgängen an HBase beenden
Bevor Sie Snapshots Ihrer HBase-Tabellen erstellen, beenden Sie das Senden von Schreibvorgängen an Ihren HBase-Cluster.
HBase-Tabellen-Snapshots erstellen
Wenn Ihr HBase-Cluster keine Daten mehr aufnimmt, erstellen Sie einen Snapshot aller Tabellen, die Sie zu Bigtable migrieren möchten.
Ein Snapshot hat zuerst nur minimalen Speicherbedarf auf dem HBase-Cluster, kann aber mit der Zeit dieselbe Größe wie die ursprüngliche Tabelle erreichen. Der Snapshot verbraucht keine CPU-Ressourcen.
Führen Sie für jede Tabelle den folgenden Befehl aus. Verwenden Sie dabei für jeden Snapshot einen eindeutigen Namen:
echo "snapshot 'TABLE_NAME', 'SNAPSHOT_NAME'" | hbase shell -n
Dabei gilt:
TABLE_NAME: der Name der HBase-Tabelle, aus der Sie Daten exportieren.SNAPSHOT_NAME: der Name des neuen Snapshots.
HBase-Snapshots nach Cloud Storage exportieren
Nachdem Sie die Snapshots erstellt haben, müssen Sie sie exportieren. Wenn Sie Exportjobs auf einem HBase-Produktionscluster ausführen, überwachen Sie den Cluster und andere HBase-Ressourcen, um zu prüfen, ob die Cluster in einem guten Zustand bleiben.
Führen Sie für jeden Snapshot, den Sie exportieren möchten, Folgendes aus:
hbase org.apache.hadoop.hbase.snapshot.ExportSnapshot \
-Dhbase.zookeeper.quorum=$ZOOKEEPER_QUORUM_AND_PORT -snapshot SNAPSHOT_NAME \
-copy-from $MIGRATION_SOURCE_DIRECTORY \
-copy-to $MIGRATION_DESTINATION_DIRECTORY/data
Ersetzen Sie dabei SNAPSHOT_NAME durch den Namen des zu exportierenden Snapshots.
Computing- und Export-Hashwerte
Erstellen Sie als Nächstes die Hashes, die nach Abschluss der Migration zur Validierung verwendet werden sollen.
HashTable ist ein von HBase bereitgestelltes Validierungstool, das Hashes für Zeilenbereiche berechnet und in Dateien exportiert. Sie können einen sync-table-Job für die Zieltabelle ausführen, um die Hashes abzugleichen und größeres Vertrauen in die Integrität der migrierten Daten gewinnen.
Führen Sie den folgenden Befehl für jede exportierte Tabelle aus:
hbase org.apache.hadoop.hbase.mapreduce.HashTable --batchsize=32000 --numhashfiles=20 \
TABLE_NAME $MIGRATION_DESTINATION_DIRECTORY/hashtable/TABLE_NAME
Dabei gilt:
TABLE_NAME: der Name der HBase-Tabelle, für die Sie einen Snapshot erstellt und exportiert haben.
Zieltabellen erstellen
Als Nächstes erstellen Sie in Ihrer Bigtable-Instanz für jeden exportierten Snapshot eine Zieltabelle. Verwenden Sie ein Konto mit der Berechtigung bigtable.tables.create für die Instanz.
In dieser Anleitung wird das Bigtable Schema Translation-Tool verwendet, das die Tabelle automatisch für Sie erstellt. Wenn Ihr Bigtable-Schema jedoch nicht genau mit dem HBase-Schema übereinstimmen soll, können Sie mit dem cbt-Befehlszeilentool oder der Google Cloud -Konsole eine Tabelle erstellen.
Das Bigtable Schema Translation-Tool erfasst das Schema der HBase-Tabelle, einschließlich Tabellenname, Spaltenfamilien, Richtlinien für die automatische Speicherbereinigung und Splits. Anschließend wird eine ähnliche Tabelle in Bigtable erstellt.
Führen Sie für jede zu importierende Tabelle den folgenden Befehl aus, um das Schema von HBase in Bigtable zu kopieren.
java \
-Dgoogle.bigtable.project.id=$PROJECT_ID \
-Dgoogle.bigtable.instance.id=$INSTANCE_ID \
-Dgoogle.bigtable.table.filter=TABLE_NAME \
-Dhbase.zookeeper.quorum=$ZOOKEEPER_QUORUM \
-Dhbase.zookeeper.property.clientPort=$ZOOKEEPER_PORT \
-jar $TRANSLATE_JAR
Ersetzen Sie TABLE_NAME durch den Namen der HBase-Tabelle, die Sie importieren. Das Schema Translation-Tool verwendet diesen Namen für die neue Bigtable-Tabelle.
Optional können Sie TABLE_NAME auch durch einen regulären Ausdruck wie „.*“ ersetzen, der alle zu erstellenden Tabellen erfasst, und dann den Befehl nur einmal ausführen.
HBase-Daten mit Dataflow in Bigtable importieren
Sobald Sie eine Tabelle haben, in die Sie Ihre Daten migrieren können, können Sie Ihre Daten importieren und validieren.
Nicht komprimierte Tabellen
Wenn Ihre HBase-Tabellen nicht komprimiert sind, führen Sie für jede zu migrierende Tabelle den folgenden Befehl aus:
java -jar $IMPORT_JAR importsnapshot \
--runner=DataflowRunner \
--project=$PROJECT_ID \
--bigtableInstanceId=$INSTANCE_ID \
--bigtableTableId=TABLE_NAME \
--hbaseSnapshotSourceDir=$MIGRATION_DESTINATION_DIRECTORY/data \
--snapshotName=SNAPSHOT_NAME \
--stagingLocation=$MIGRATION_DESTINATION_DIRECTORY/staging \
--tempLocation=$MIGRATION_DESTINATION_DIRECTORY/temp \
--maxNumWorkers=$(expr 3 \* $CLUSTER_NUM_NODES) \
--region=$REGION
Dabei gilt:
TABLE_NAME: der Name der HBase-Tabelle, die Sie importieren. Das Schema Translation-Tool verwendet diesen Namen für die neue Bigtable-Tabelle. Neue Tabellennamen werden nicht unterstützt.SNAPSHOT_NAME: der Name, den Sie dem Snapshot der zu importierenden Tabelle zugewiesen haben
Nachdem Sie den Befehl ausgeführt haben, stellt das Tool den HBase-Snapshot in Ihrem Cloud Storage-Bucket wieder her und startet dann den Importjob. Es kann einige Minuten dauern, bis der Snapshot wiederhergestellt ist, je nach Größe des Snapshots.
Beachten Sie beim Importieren die folgenden Tipps:
- Achten Sie darauf,
maxNumWorkersfestzulegen, um die Leistung beim Datenupload zu verbessern. Mit diesem Wert wird sichergestellt, dass der Importjob über genügend Compute-Leistung verfügt, um den Vorgang in einer akzeptablen Zeit abzuschließen, aber nicht so viel, dass die Bigtable-Instanz überlastet wird- Wenn Sie die Bigtable-Instanz nicht auch für eine andere Arbeitslast verwenden, multiplizieren Sie die Anzahl der Knoten in der Bigtable-Instanz mit 3 und verwenden diese Anzahl für
maxNumWorkers. - Wenn Sie die Instanz für eine andere Arbeitslast zur gleichen Zeit wie den Import Ihrer HBase-Daten verwenden, reduzieren Sie den Wert von
maxNumWorkersentsprechend.
- Wenn Sie die Bigtable-Instanz nicht auch für eine andere Arbeitslast verwenden, multiplizieren Sie die Anzahl der Knoten in der Bigtable-Instanz mit 3 und verwenden diese Anzahl für
- Verwenden Sie den Standard-Worker-Typ.
- Achten Sie während des Imports auf die CPU-Auslastung der Bigtable-Instanz. Wenn die CPU-Auslastung in der Bigtable-Instanz zu hoch ist, müssen Sie ggf. weitere Knoten hinzufügen. Es kann bis zu 20 Minuten dauern, bis sich die Leistung aufgrund der zusätzlichen Knoten erhöht.
Weitere Informationen zum Überwachen der Bigtable-Instanz finden Sie unter Monitoring.
Komprimierte Snappy-Tabellen
Wenn Sie komprimierte Snappy-Tabellen importieren, müssen Sie ein benutzerdefiniertes Container-Image in der Dataflow-Pipeline verwenden. Das benutzerdefinierte Container-Image, das Sie zum Importieren komprimierter Daten in Bigtable verwenden, bietet Unterstützung für native Hadoop-Komprimierungsbibliotheken. Zur Verwendung von Dataflow Runner v2 benötigen Sie das Apache Beam SDK in der Version 2.30.0 oder höher und die Version 2.3.0 oder höher der HBase-Clientbibliothek für Java.
Führen Sie denselben Befehl aus, den Sie für unkomprimierte Tabellen ausführen, aber ergänzen Sie die folgenden Optionen, um komprimierte Snappy-Tabellen zu importieren:
--enableSnappy=true
Importierte Daten in Bigtable validieren
Zum Validieren der importierten Daten müssen Sie den Job sync-table ausführen. Der sync-table-Job berechnet Hashes für Zeilenbereiche in Bigtable und ordnet sie dann der HashTable-Ausgabe zu, die Sie zuvor berechnet haben.
Führen Sie in der Befehls-Shell folgenden Befehl aus, um den Job sync-table auszuführen:
java -jar $IMPORT_JAR sync-table \
--runner=dataflow \
--project=$PROJECT_ID \
--bigtableInstanceId=$INSTANCE_ID \
--bigtableTableId=TABLE_NAME \
--outputPrefix=$MIGRATION_DESTINATION_DIRECTORY/sync-table/output-TABLE_NAME-$(date +"%s") \
--stagingLocation=$MIGRATION_DESTINATION_DIRECTORY/sync-table/staging \
--hashTableOutputDir=$MIGRATION_DESTINATION_DIRECTORY/hashtable/TABLE_NAME \
--tempLocation=$MIGRATION_DESTINATION_DIRECTORY/sync-table/dataflow-test/temp \
--region=$REGION
Ersetzen Sie TABLE_NAME durch den Namen der HBase-Tabelle, die Sie importieren.
Wenn der sync-table-Job abgeschlossen ist, öffnen Sie die Dataflow-Jobdetails und prüfen Sie den Bereich Benutzerdefinierte Zähler für den Job. Wenn der Importjob alle Daten erfolgreich importiert, hat der Wert für ranges_matched einen Wert und der Wert für ranges_not_matched ist 0.
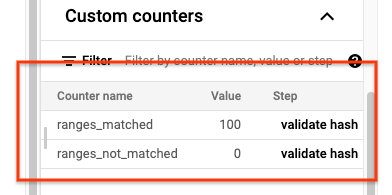
Wenn ranges_not_matched einen Wert anzeigt, öffnen Sie die Seite Logs, wählen Sie die Worker-Logs aus und filtern Sie nach Fehler bei Bereich. Die maschinenlesbare Ausgabe dieser Logs wird in Cloud Storage an dem Ausgabeziel gespeichert, das Sie in der Option outputPrefix der Synchronisierungstabelle erstellen.
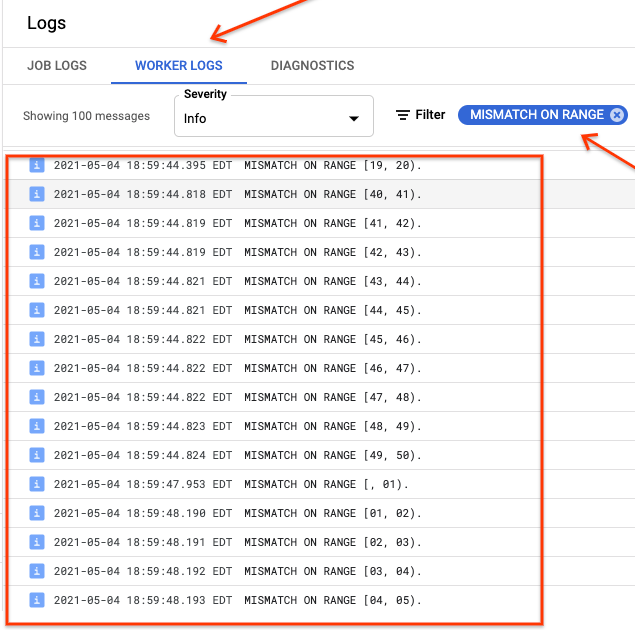
Sie können den Importjob noch einmal versuchen oder ein Skript schreiben, um die Ausgabedateien zu lesen, um zu ermitteln, wo die Abweichungen auftreten. Jede Zeile in der Ausgabedatei ist ein serialisierter JSON-Eintrag eines nicht übereinstimmenden Bereichs.
Schreibvorgänge an Bigtable weiterleiten
Nachdem Sie die Daten für jede Tabelle im Cluster validiert haben, können Sie Ihre Anwendungen so konfigurieren, dass der gesamte Traffic an Bigtable weitergeleitet wird. Danach wird die HBase-Instanz verworfen.
Wenn die Migration abgeschlossen ist, können Sie die Snapshots auf Ihrer HBase-Instanz löschen.