En esta página se describen los aspectos y procesos relacionados con la migración de datos de un clúster de Apache HBase a una instancia de Bigtable enGoogle Cloud.
El proceso descrito en esta página requiere que pongas tu aplicación sin conexión. Si quieres migrar sin tiempo de inactividad, consulta las directrices para la migración online en Replicar de HBase a Bigtable.
Para migrar datos a Bigtable desde un clúster de HBase alojado en un Google Cloud servicio, como Dataproc o Compute Engine, consulta Migrar HBase alojado en Google Cloud a Bigtable.
Antes de empezar esta migración, debes tener en cuenta las implicaciones en el rendimiento, el diseño del esquema de Bigtable, tu enfoque de autenticación y autorización, y el conjunto de funciones de Bigtable.
Consideraciones previas a la migración
En esta sección, se sugieren algunas cosas que debes revisar y tener en cuenta antes de empezar la migración.
Rendimiento
Con una carga de trabajo típica, Bigtable ofrece un rendimiento muy predecible. Antes de migrar tus datos, asegúrate de que conoces los factores que afectan al rendimiento de Bigtable.
Diseño de esquemas de Bigtable
En la mayoría de los casos, puedes usar el mismo diseño de esquema en Bigtable que en HBase. Si quieres cambiar tu esquema o si tu caso de uso va a cambiar, consulta los conceptos que se explican en Diseñar tu esquema antes de migrar tus datos.
Autenticación y autorización
Antes de diseñar el control de acceso de Bigtable, revisa los procesos de autenticación y autorización de HBase.
Bigtable usa los Google Cloudmecanismos estándar de autenticación y de gestión de identidades y accesos para proporcionar control de acceso, por lo que puedes convertir tu autorización de HBase a IAM. Puedes asignar los grupos de Hadoop que proporcionan mecanismos de control de acceso para HBase a diferentes cuentas de servicio.
Bigtable te permite controlar el acceso a nivel de proyecto, instancia y tabla. Para obtener más información, consulta Control de acceso.
Requisito de tiempo de inactividad
El método de migración que se describe en esta página implica que la aplicación no esté disponible durante la migración. Si tu empresa no puede permitirse un tiempo de inactividad mientras migras a Bigtable, consulta las directrices para la migración online en Replicar de HBase a Bigtable.
Migrar de HBase a Bigtable
Para migrar los datos de HBase a Bigtable, exporta una captura de HBase de cada tabla a Cloud Storage y, a continuación, importa los datos a Bigtable. Estos pasos son para un solo clúster de HBase y se describen en detalle en las siguientes secciones.
- Dejar de enviar escrituras a tu clúster de HBase.
- Haz capturas de las tablas del clúster de HBase.
- Exporta los archivos de la instantánea a Cloud Storage.
- Calcula los hashes y expórtalos a Cloud Storage.
- Crea tablas de destino en Bigtable.
- Importa los datos de HBase de Cloud Storage a Bigtable.
- Valida los datos importados.
- Route escribe en Bigtable.
Antes de empezar
Crea un segmento de Cloud Storage para almacenar tus copias de seguridad. Crea el segmento en la misma ubicación en la que tienes previsto ejecutar la tarea de Dataflow.
Crea una instancia de Bigtable para almacenar las nuevas tablas.
Identifica el clúster de Hadoop que vas a exportar. Puedes ejecutar las tareas de tu migración directamente en el clúster de HBase o en un clúster de Hadoop independiente que tenga conectividad de red con el nodo de nombres y los nodos de datos del clúster de HBase.
Instala y configura el conector de Cloud Storage en todos los nodos del clúster de Hadoop, así como en el host desde el que se inicia el trabajo. Para obtener información detallada sobre los pasos de instalación, consulta Instalar el conector de Cloud Storage.
Abre una shell de comandos en un host que pueda conectarse a tu clúster de HBase y a tu proyecto de Bigtable. Aquí es donde completarás los pasos siguientes.
Obtén la herramienta Traducción de esquemas:
wget BIGTABLE_HBASE_TOOLS_URLSustituye
BIGTABLE_HBASE_TOOLS_URLpor la URL de la versión más reciente deJAR with dependenciesdisponible en el repositorio de Maven de la herramienta. El nombre del archivo es similar ahttps://repo1.maven.org/maven2/com/google/cloud/bigtable/bigtable-hbase-1.x-tools/1.24.0/bigtable-hbase-1.x-tools-1.24.0-jar-with-dependencies.jar.Para encontrar la URL o descargar el archivo JAR manualmente, siga estos pasos:
- Ve al repositorio.
- Haz clic en el número de la versión más reciente.
- Identifica el
JAR with dependencies file(normalmente en la parte superior). - Haz clic con el botón derecho y copia la URL, o haz clic para descargar el archivo.
Obtener la herramienta Importar:
wget BIGTABLE_BEAM_IMPORT_URLSustituye
BIGTABLE_BEAM_IMPORT_URLpor la URL de la versión más reciente deshaded JARdisponible en el repositorio de Maven de la herramienta. El nombre del archivo es similar ahttps://repo1.maven.org/maven2/com/google/cloud/bigtable/bigtable-beam-import/1.24.0/bigtable-beam-import-1.24.0-shaded.jar.Para encontrar la URL o descargar el archivo JAR manualmente, sigue estos pasos:
- Ve al repositorio.
- Haz clic en el número de la versión más reciente.
- Haz clic en Descargas.
- Coloca el cursor sobre shaded.jar.
- Haz clic con el botón derecho y copia la URL, o haz clic para descargar el archivo.
Define las siguientes variables de entorno:
#Google Cloud export PROJECT_ID=PROJECT_ID export INSTANCE_ID=INSTANCE_ID export REGION=REGION export CLUSTER_NUM_NODES=CLUSTER_NUM_NODES #JAR files export TRANSLATE_JAR=TRANSLATE_JAR export IMPORT_JAR=IMPORT_JAR #Cloud Storage export BUCKET_NAME="gs://BUCKET_NAME" export MIGRATION_DESTINATION_DIRECTORY="$BUCKET_NAME/hbase-migration-snap" #HBase export ZOOKEEPER_QUORUM=ZOOKEPER_QUORUM export ZOOKEEPER_PORT=2181 export ZOOKEEPER_QUORUM_AND_PORT="$ZOOKEEPER_QUORUM:$ZOOKEEPER_PORT" export MIGRATION_SOURCE_DIRECTORY=MIGRATION_SOURCE_DIRECTORYHaz los cambios siguientes:
PROJECT_ID: el Google Cloud proyecto en el que se encuentra tu instanciaINSTANCE_ID: identificador de la instancia de Bigtable a la que vas a importar los datos.REGION: una región que contiene uno de los clústeres de tu instancia de Bigtable. Ejemplo:northamerica-northeast2CLUSTER_NUM_NODES: el número de nodos de tu instancia de BigtableTRANSLATE_JAR: el nombre y el número de versión del archivo JARbigtable hbase toolsque has descargado de Maven. El valor debe ser similar abigtable-hbase-1.x-tools-1.24.0-jar-with-dependencies.jar.IMPORT_JAR: el nombre y el número de versión del archivo JARbigtable-beam-importque has descargado de Maven. El valor debe ser similar abigtable-beam-import-1.24.0-shaded.jar.BUCKET_NAME: el nombre del segmento de Cloud Storage en el que almacenas tus copias de seguridadZOOKEEPER_QUORUM: el host de Zookeeper al que se conectará la herramienta, en el formatohost1.myownpersonaldomain.comMIGRATION_SOURCE_DIRECTORY: el directorio de tu host de HBase que contiene los datos que quieres migrar, en el formatohdfs://host1.myownpersonaldomain.com:8020/hbase
(Opcional) Para confirmar que las variables se han definido correctamente, ejecuta el comando
printenvpara ver todas las variables de entorno.
Dejar de enviar operaciones de escritura a HBase
Antes de hacer copias de tus tablas de HBase, deja de enviar escrituras a tu clúster de HBase.
Hacer capturas de tablas de HBase
Cuando tu clúster de HBase deje de ingerir datos, haz una instantánea de cada tabla que quieras migrar a Bigtable.
Al principio, una instantánea ocupa un espacio de almacenamiento mínimo en el clúster de HBase, pero, con el tiempo, puede llegar a tener el mismo tamaño que la tabla original. La captura no consume recursos de CPU.
Ejecuta el siguiente comando para cada tabla, usando un nombre único para cada instantánea:
echo "snapshot 'TABLE_NAME', 'SNAPSHOT_NAME'" | hbase shell -n
Haz los cambios siguientes:
TABLE_NAME: el nombre de la tabla de HBase de la que quieres exportar datos.SNAPSHOT_NAME: el nombre de la nueva captura
Exportar las copias de HBase a Cloud Storage
Después de crear las capturas, debes exportarlas. Cuando ejecutes trabajos de exportación en un clúster de HBase de producción, monitoriza el clúster y otros recursos de HBase para asegurarte de que los clústeres se mantienen en buen estado.
Ejecuta lo siguiente para cada instantánea que quieras exportar:
hbase org.apache.hadoop.hbase.snapshot.ExportSnapshot \
-Dhbase.zookeeper.quorum=$ZOOKEEPER_QUORUM_AND_PORT -snapshot SNAPSHOT_NAME \
-copy-from $MIGRATION_SOURCE_DIRECTORY \
-copy-to $MIGRATION_DESTINATION_DIRECTORY/data
Sustituye SNAPSHOT_NAME por el nombre de la instantánea que quieras exportar.
Calcular y exportar hashes
A continuación, crea los hashes que se usarán para la validación una vez que se haya completado la migración.
HashTable es una herramienta de validación proporcionada por HBase que calcula los hashes de los intervalos de filas y los exporta a archivos. Puedes ejecutar una tarea sync-table en la tabla de destino para comparar los hashes y asegurarte de la integridad de los datos migrados.
Ejecuta el siguiente comando en cada tabla que hayas exportado:
hbase org.apache.hadoop.hbase.mapreduce.HashTable --batchsize=32000 --numhashfiles=20 \
TABLE_NAME $MIGRATION_DESTINATION_DIRECTORY/hashtable/TABLE_NAME
Haz los cambios siguientes:
TABLE_NAME: el nombre de la tabla de HBase de la que has creado una instantánea y que has exportado.
Crear tablas de destino
El siguiente paso es crear una tabla de destino en tu instancia de Bigtable para cada instantánea que hayas exportado. Usa una cuenta que tenga permiso bigtable.tables.create para la instancia.
En esta guía se usa la herramienta de traducción de esquemas de Bigtable, que crea la tabla automáticamente. Sin embargo, si no quieres que tu esquema de Bigtable coincida exactamente con el esquema de HBase, puedes crear una tabla con la herramienta de línea de comandos cbt o la consola Google Cloud .
La herramienta de traducción de esquemas de Bigtable captura el esquema de la tabla de HBase, incluido el nombre de la tabla, las familias de columnas, las políticas de recogida de elementos no utilizados y las divisiones. A continuación, crea una tabla similar en Bigtable.
En cada tabla que quieras importar, ejecuta el siguiente comando para copiar el esquema de HBase a Bigtable.
java \
-Dgoogle.bigtable.project.id=$PROJECT_ID \
-Dgoogle.bigtable.instance.id=$INSTANCE_ID \
-Dgoogle.bigtable.table.filter=TABLE_NAME \
-Dhbase.zookeeper.quorum=$ZOOKEEPER_QUORUM \
-Dhbase.zookeeper.property.clientPort=$ZOOKEEPER_PORT \
-jar $TRANSLATE_JAR
Sustituye TABLE_NAME por el nombre de la tabla de HBase que vas a importar. La herramienta Traducción de esquemas usa este nombre para la nueva tabla de Bigtable.
También puedes sustituir TABLE_NAME por una expresión regular, como ".*", que capture todas las tablas que quieras crear y, a continuación, ejecutar el comando solo una vez.
Importar los datos de HBase a Bigtable mediante Dataflow
Cuando tengas una tabla lista para migrar tus datos, podrás importarlos y validarlos.
Tablas sin comprimir
Si tus tablas de HBase no están comprimidas, ejecuta el siguiente comando para cada tabla que quieras migrar:
java -jar $IMPORT_JAR importsnapshot \
--runner=DataflowRunner \
--project=$PROJECT_ID \
--bigtableInstanceId=$INSTANCE_ID \
--bigtableTableId=TABLE_NAME \
--hbaseSnapshotSourceDir=$MIGRATION_DESTINATION_DIRECTORY/data \
--snapshotName=SNAPSHOT_NAME \
--stagingLocation=$MIGRATION_DESTINATION_DIRECTORY/staging \
--tempLocation=$MIGRATION_DESTINATION_DIRECTORY/temp \
--maxNumWorkers=$(expr 3 \* $CLUSTER_NUM_NODES) \
--region=$REGION
Haz los cambios siguientes:
TABLE_NAME: el nombre de la tabla de HBase que vas a importar. La herramienta Traducción de esquemas usa este nombre para la nueva tabla de Bigtable. No se admiten nombres de tabla nuevos.SNAPSHOT_NAME: el nombre que has asignado a la instantánea de la tabla que vas a importar
Después de ejecutar el comando, la herramienta restaura la instantánea de HBase en tu segmento de Cloud Storage y, a continuación, inicia el trabajo de importación. El proceso de restauración de la instantánea puede tardar varios minutos en completarse, en función del tamaño de la instantánea.
Ten en cuenta los siguientes consejos al importar:
- Para mejorar el rendimiento de la carga de datos, asegúrese de definir
maxNumWorkers. Este valor ayuda a asegurarse de que el trabajo de importación tenga suficiente potencia de cálculo para completarse en un tiempo razonable, pero no tanta como para sobrecargar la instancia de Bigtable.- Si no vas a usar la instancia de Bigtable para otra carga de trabajo, multiplica por 3 el número de nodos de tu instancia de Bigtable y usa ese número para
maxNumWorkers. - Si usas la instancia para otra carga de trabajo al mismo tiempo que importas tus datos de HBase, reduce el valor de
maxNumWorkerssegún corresponda.
- Si no vas a usar la instancia de Bigtable para otra carga de trabajo, multiplica por 3 el número de nodos de tu instancia de Bigtable y usa ese número para
- Usa el tipo de trabajador predeterminado.
- Durante la importación, debes monitorizar el uso de CPU de la instancia de Bigtable. Si el uso de la CPU en la instancia de Bigtable es demasiado alto, es posible que tengas que añadir más nodos. El clúster puede tardar hasta 20 minutos en ofrecer la mejora del rendimiento que suponen los nodos adicionales.
Para obtener más información sobre la monitorización de la instancia de Bigtable, consulta Monitorización.
Tablas comprimidas con Snappy
Si va a importar tablas comprimidas con Snappy, debe usar una imagen de contenedor personalizada en la canalización de Dataflow. La imagen de contenedor personalizada que usas para importar datos comprimidos a Bigtable proporciona compatibilidad con la biblioteca de compresión nativa de Hadoop. Para usar Dataflow Runner v2, debes tener la versión 2.30.0 o una posterior del SDK de Apache Beam, así como la versión 2.3.0 o una posterior de la biblioteca de cliente de HBase para Java.
Para importar tablas comprimidas con Snappy, ejecuta el mismo comando que para las tablas sin comprimir, pero añade la siguiente opción:
--enableSnappy=true
Validar los datos importados en Bigtable
Para validar los datos importados, debes ejecutar el trabajo sync-table. El trabajo sync-table calcula los hashes de los intervalos de filas de Bigtable y, a continuación, los compara con el resultado de HashTable que has calculado anteriormente.
Para ejecutar el trabajo sync-table, ejecuta lo siguiente en el shell de comandos:
java -jar $IMPORT_JAR sync-table \
--runner=dataflow \
--project=$PROJECT_ID \
--bigtableInstanceId=$INSTANCE_ID \
--bigtableTableId=TABLE_NAME \
--outputPrefix=$MIGRATION_DESTINATION_DIRECTORY/sync-table/output-TABLE_NAME-$(date +"%s") \
--stagingLocation=$MIGRATION_DESTINATION_DIRECTORY/sync-table/staging \
--hashTableOutputDir=$MIGRATION_DESTINATION_DIRECTORY/hashtable/TABLE_NAME \
--tempLocation=$MIGRATION_DESTINATION_DIRECTORY/sync-table/dataflow-test/temp \
--region=$REGION
Sustituye TABLE_NAME por el nombre de la tabla de HBase que vas a importar.
Cuando se complete la tarea sync-table, abre la página Detalles de la tarea de Dataflow y consulta la sección Contadores personalizados de la tarea. Si el trabajo de importación importa correctamente todos los datos, el valor de ranges_matched tendrá un valor y el de ranges_not_matched será 0.
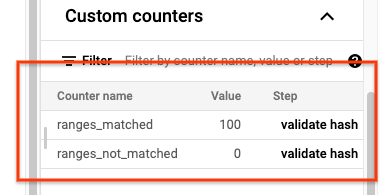
Si ranges_not_matched muestra un valor, abra la página Registros, elija Registros de trabajador y filtre por Desajuste en el intervalo. La salida legible por máquina de estos registros se almacena en Cloud Storage en el destino de salida que crees en la opción outputPrefix de la tabla de sincronización.
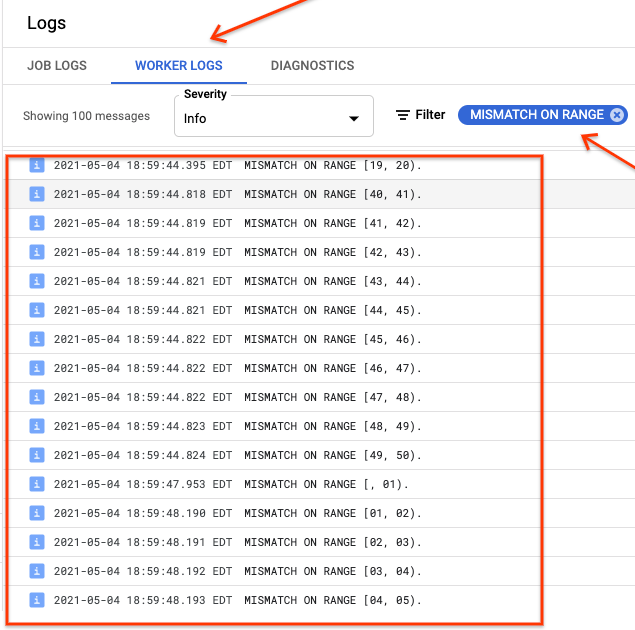
Puedes volver a intentar la importación o escribir una secuencia de comandos para leer los archivos de salida y determinar dónde se han producido las discrepancias. Cada línea del archivo de salida es un registro JSON serializado de un intervalo que no coincide.
Route escribe en Bigtable
Una vez que hayas validado los datos de cada tabla del clúster, puedes configurar tus aplicaciones para que dirijan todo su tráfico a Bigtable y, a continuación, retirar la instancia de HBase.
Cuando se haya completado la migración, puedes eliminar las copias de los datos de tu instancia de HBase.
Siguientes pasos
- Obtén más información sobre Cloud Storage.