Esta página descreve as considerações e os processos para migrar dados de um cluster do Apache HBase para uma instância do Bigtable noGoogle Cloud.
O processo descrito nesta página requer que coloque a sua aplicação offline. Se quiser migrar sem tempo de inatividade, consulte as orientações para a migração online em Replique do HBase para o Bigtable.
Para migrar dados para o Bigtable a partir de um cluster do HBase alojado num Google Cloud serviço, como o Dataproc ou o Compute Engine, consulte o artigo Migrar o HBase alojado no Google Cloud para o Bigtable.
Antes de iniciar esta migração, deve considerar as implicações no desempenho, a estrutura do esquema do Bigtable, a sua abordagem à autenticação e autorização, e o conjunto de funcionalidades do Bigtable.
Considerações pré-migração
Esta secção sugere alguns aspetos a rever e a ter em conta antes de iniciar a migração.
Desempenho
Com uma carga de trabalho típica, o Bigtable oferece um desempenho altamente previsível. Certifique-se de que compreende os fatores que afetam o desempenho do Bigtable antes de migrar os seus dados.
Design do esquema do Bigtable
Na maioria dos casos, pode usar o mesmo esquema de design no Bigtable que usa no HBase. Se quiser alterar o seu esquema ou se o seu exemplo de utilização estiver a mudar, reveja os conceitos apresentados em Conceber o seu esquema antes de migrar os seus dados.
Autenticação e autorização
Antes de conceber o controlo de acesso para o Bigtable, reveja os processos de autenticação e autorização do HBase existentes.
O Bigtable usa os mecanismos padrão Google Cloud's para autenticaçãoe gestão de identidade e acesso para fornecer controlo de acesso, pelo que converte a sua autorização existente no HBase para IAM. Pode mapear os grupos Hadoop existentes que fornecem mecanismos de controlo de acesso para o HBase a diferentes contas de serviço.
O Bigtable permite-lhe controlar o acesso ao nível do projeto, da instância e da tabela. Para mais informações, consulte o artigo Controlo de acesso.
Requisito de período de descanso
A abordagem de migração descrita nesta página envolve colocar a sua aplicação offline durante a migração. Se a sua empresa não puder tolerar o tempo de inatividade enquanto migra para o Bigtable, consulte as orientações para a migração online em Replique do HBase para o Bigtable.
Migre o HBase para o Bigtable
Para migrar os seus dados do HBase para o Bigtable, exporte uma cópia instantânea do HBase para cada tabela para o Cloud Storage e, em seguida, importe os dados para o Bigtable. Estes passos destinam-se a um único cluster do HBase e são descritos detalhadamente nas próximas secções.
- Parar de enviar gravações para o cluster do HBase.
- Tire instantâneos das tabelas do cluster HBase.
- Exporte os ficheiros de instantâneos para o Cloud Storage.
- Calcular hashes e exportá-los para o Cloud Storage.
- Crie tabelas de destino no Bigtable.
- Importe os dados do HBase do Cloud Storage para o Bigtable.
- Valide os dados importados.
- A rota escreve no Bigtable.
Antes de começar
Crie um contentor do Cloud Storage para armazenar os seus instantâneos. Crie o contentor na mesma localização em que planeia executar a tarefa do Dataflow.
Crie uma instância do Bigtable para armazenar as novas tabelas.
Identifique o cluster Hadoop que está a exportar. Pode executar as tarefas para a migração diretamente no cluster do HBase ou num cluster do Hadoop separado que tenha conetividade de rede com o Namenode e os Datanodes do cluster do HBase.
Instale e configure o conetor do Cloud Storage em todos os nós no cluster do Hadoop, bem como no anfitrião a partir do qual a tarefa é iniciada. Para ver os passos de instalação detalhados, consulte o artigo Instalar o conector do Cloud Storage.
Abra uma shell de comandos num anfitrião que possa estabelecer ligação ao cluster do HBase e ao projeto do Bigtable. É aqui que vai concluir os passos seguintes.
Obtenha a ferramenta de tradução de esquemas:
wget BIGTABLE_HBASE_TOOLS_URLSubstitua
BIGTABLE_HBASE_TOOLS_URLpelo URL daJAR with dependenciesmais recente disponível no repositório Maven da ferramenta. O nome do ficheiro é semelhante ahttps://repo1.maven.org/maven2/com/google/cloud/bigtable/bigtable-hbase-1.x-tools/1.24.0/bigtable-hbase-1.x-tools-1.24.0-jar-with-dependencies.jar.Para encontrar o URL ou transferir manualmente o JAR, faça o seguinte:
- Aceda ao repositório.
- Clique no número da versão mais recente.
- Identifique o
JAR with dependencies file(normalmente, na parte superior). - Clique com o botão direito do rato e copie o URL ou clique para transferir o ficheiro.
Obtenha a ferramenta de importação:
wget BIGTABLE_BEAM_IMPORT_URLSubstitua
BIGTABLE_BEAM_IMPORT_URLpelo URL dashaded JARmais recente disponível no repositório Maven da ferramenta. O nome do ficheiro é semelhante ahttps://repo1.maven.org/maven2/com/google/cloud/bigtable/bigtable-beam-import/1.24.0/bigtable-beam-import-1.24.0-shaded.jar.Para encontrar o URL ou transferir manualmente o JAR, faça o seguinte:
- Aceda ao repositório.
- Clique no número da versão mais recente.
- Clique em Transferências.
- Passe o cursor do rato sobre shaded.jar.
- Clique com o botão direito do rato e copie o URL ou clique para transferir o ficheiro.
Defina as seguintes variáveis de ambiente:
#Google Cloud export PROJECT_ID=PROJECT_ID export INSTANCE_ID=INSTANCE_ID export REGION=REGION export CLUSTER_NUM_NODES=CLUSTER_NUM_NODES #JAR files export TRANSLATE_JAR=TRANSLATE_JAR export IMPORT_JAR=IMPORT_JAR #Cloud Storage export BUCKET_NAME="gs://BUCKET_NAME" export MIGRATION_DESTINATION_DIRECTORY="$BUCKET_NAME/hbase-migration-snap" #HBase export ZOOKEEPER_QUORUM=ZOOKEPER_QUORUM export ZOOKEEPER_PORT=2181 export ZOOKEEPER_QUORUM_AND_PORT="$ZOOKEEPER_QUORUM:$ZOOKEEPER_PORT" export MIGRATION_SOURCE_DIRECTORY=MIGRATION_SOURCE_DIRECTORYSubstitua o seguinte:
PROJECT_ID: o Google Cloud projeto em que a sua instância se encontraINSTANCE_ID: o identificador da instância do Bigtable para a qual está a importar os dadosREGION: uma região que contém um dos clusters na sua instância do Bigtable. Exemplo:northamerica-northeast2CLUSTER_NUM_NODES: o número de nós na sua instância do BigtableTRANSLATE_JAR: o nome e o número da versão do ficheiro JARbigtable hbase toolsque transferiu do Maven. O valor deve ter um aspeto semelhante abigtable-hbase-1.x-tools-1.24.0-jar-with-dependencies.jar.IMPORT_JAR: o nome e o número da versão do ficheiro JARbigtable-beam-importque transferiu do Maven. O valor deve ter um aspeto semelhante abigtable-beam-import-1.24.0-shaded.jar.BUCKET_NAME: o nome do contentor do Cloud Storage onde está a armazenar as suas capturas de ecrãZOOKEEPER_QUORUM: o anfitrião do zookeeper ao qual a ferramenta se vai ligar, no formatohost1.myownpersonaldomain.comMIGRATION_SOURCE_DIRECTORY: o diretório no seu anfitrião do HBase que contém os dados que quer migrar, no formatohdfs://host1.myownpersonaldomain.com:8020/hbase
(Opcional) Para confirmar que as variáveis foram definidas corretamente, execute o comando
printenvpara ver todas as variáveis de ambiente.
Pare de enviar gravações para o HBase
Antes de tirar instantâneos das suas tabelas HBase, pare de enviar gravações para o seu cluster HBase.
Tire instantâneos de tabelas HBase
Quando o cluster do HBase deixar de ingerir dados, tire uma captura de ecrã de cada tabela que planeia migrar para o Bigtable.
Inicialmente, uma captura instantânea tem uma pegada de armazenamento mínima no cluster do HBase, mas, ao longo do tempo, pode crescer até atingir o mesmo tamanho da tabela original. A captura instantânea não consome recursos da CPU.
Execute o seguinte comando para cada tabela, usando um nome exclusivo para cada instantâneo:
echo "snapshot 'TABLE_NAME', 'SNAPSHOT_NAME'" | hbase shell -n
Substitua o seguinte:
TABLE_NAME: o nome da tabela HBase a partir da qual está a exportar dados.SNAPSHOT_NAME: o nome do novo instantâneo
Exporte as capturas instantâneas do HBase para o Cloud Storage
Depois de criar as capturas instantâneas, tem de as exportar. Quando estiver a executar tarefas de exportação num cluster HBase de produção, monitorize o cluster e outros recursos do HBase para garantir que os clusters permanecem em bom estado.
Para cada instantâneo que quer exportar, execute o seguinte:
hbase org.apache.hadoop.hbase.snapshot.ExportSnapshot \
-Dhbase.zookeeper.quorum=$ZOOKEEPER_QUORUM_AND_PORT -snapshot SNAPSHOT_NAME \
-copy-from $MIGRATION_SOURCE_DIRECTORY \
-copy-to $MIGRATION_DESTINATION_DIRECTORY/data
Substitua SNAPSHOT_NAME pelo nome do instantâneo a exportar.
Calcule e exporte hashes
Em seguida, crie hashes para usar na validação após a conclusão da migração.
HashTable é uma ferramenta de validação fornecida pelo HBase que calcula hashes para intervalos de linhas e exporta-os para ficheiros. Pode executar uma tarefa sync-table na tabela de destino para fazer corresponder os hashes e ganhar confiança na integridade dos dados migrados.
Execute o seguinte comando para cada tabela que exportou:
hbase org.apache.hadoop.hbase.mapreduce.HashTable --batchsize=32000 --numhashfiles=20 \
TABLE_NAME $MIGRATION_DESTINATION_DIRECTORY/hashtable/TABLE_NAME
Substitua o seguinte:
TABLE_NAME: o nome da tabela HBase para a qual criou uma captura instantânea e exportou
Crie tabelas de destino
O passo seguinte é criar uma tabela de destino na instância do Bigtable para cada instantâneo que exportou. Use uma conta com autorização bigtable.tables.create para a instância.
Este guia usa a ferramenta de tradução do esquema do Bigtable, que cria automaticamente a tabela para si. No entanto, se não quiser que o esquema do Bigtable corresponda exatamente ao esquema do HBase, pode criar uma tabela através da ferramenta de linha de comandos cbt ou da consola Google Cloud .
A ferramenta de tradução de esquemas do Bigtable captura o esquema da tabela do HBase, incluindo o nome da tabela, as famílias de colunas, as políticas de recolha de lixo e as divisões. Em seguida, cria uma tabela semelhante no Bigtable.
Para cada tabela que quer importar, execute o seguinte comando para copiar o esquema do HBase para o Bigtable.
java \
-Dgoogle.bigtable.project.id=$PROJECT_ID \
-Dgoogle.bigtable.instance.id=$INSTANCE_ID \
-Dgoogle.bigtable.table.filter=TABLE_NAME \
-Dhbase.zookeeper.quorum=$ZOOKEEPER_QUORUM \
-Dhbase.zookeeper.property.clientPort=$ZOOKEEPER_PORT \
-jar $TRANSLATE_JAR
Substitua TABLE_NAME pelo nome da tabela HBase que está a importar. A ferramenta de tradução de esquemas usa este nome para a nova tabela do Bigtable.
Opcionalmente, também pode substituir TABLE_NAME por uma expressão regular, como ".*", que capture todas as tabelas que quer criar e, em seguida, executar o comando apenas uma vez.
Importe os dados do HBase para o Bigtable através do Dataflow
Depois de ter uma tabela pronta para migrar os dados, pode importar e validar os dados.
Tabelas não comprimidas
Se as suas tabelas HBase não estiverem comprimidas, execute o seguinte comando para cada tabela que quer migrar:
java -jar $IMPORT_JAR importsnapshot \
--runner=DataflowRunner \
--project=$PROJECT_ID \
--bigtableInstanceId=$INSTANCE_ID \
--bigtableTableId=TABLE_NAME \
--hbaseSnapshotSourceDir=$MIGRATION_DESTINATION_DIRECTORY/data \
--snapshotName=SNAPSHOT_NAME \
--stagingLocation=$MIGRATION_DESTINATION_DIRECTORY/staging \
--tempLocation=$MIGRATION_DESTINATION_DIRECTORY/temp \
--maxNumWorkers=$(expr 3 \* $CLUSTER_NUM_NODES) \
--region=$REGION
Substitua o seguinte:
TABLE_NAME: o nome da tabela HBase que está a importar. A ferramenta de tradução de esquemas usa este nome para a nova tabela do Bigtable. Não são suportados novos nomes de tabelas.SNAPSHOT_NAME: o nome que atribuiu à imagem da tabela que está a importar
Depois de executar o comando, a ferramenta restaura a cópia instantânea do HBase para o seu contentor do Cloud Storage e, em seguida, inicia a tarefa de importação. O processo de restauro da captura de ecrã pode demorar vários minutos a ser concluído, consoante o tamanho da captura de ecrã.
Tenha em atenção as seguintes dicas quando importar:
- Para melhorar o desempenho do carregamento de dados, certifique-se de que define
maxNumWorkers. Este valor ajuda a garantir que a tarefa de importação tem capacidade de computação suficiente para ser concluída num período razoável, mas não tanta que sobrecarregue a instância do Bigtable.- Se também não estiver a usar a instância do Bigtable para outra carga de trabalho, multiplique o número de nós na instância do Bigtable por 3 e use esse número para
maxNumWorkers. - Se estiver a usar a instância para outra carga de trabalho ao mesmo tempo que
está a importar os dados do HBase, reduza o valor de
maxNumWorkersadequadamente.
- Se também não estiver a usar a instância do Bigtable para outra carga de trabalho, multiplique o número de nós na instância do Bigtable por 3 e use esse número para
- Use o tipo de trabalhador predefinido.
- Durante a importação, deve monitorizar a utilização da CPU da instância do Bigtable. Se a utilização da CPU na instância do Bigtable for demasiado elevada, pode ter de adicionar nós adicionais. Pode demorar até 20 minutos para o cluster oferecer a vantagem de desempenho dos nós adicionais.
Para mais informações sobre a monitorização da instância do Bigtable, consulte o artigo Monitorização.
Tabelas comprimidas com Snappy
Se estiver a importar tabelas comprimidas com Snappy, tem de usar uma imagem de contentor personalizada no pipeline do Dataflow. A imagem do contentor personalizado que usa para importar dados comprimidos para o Bigtable oferece suporte para a biblioteca de compressão nativa do Hadoop. Tem de ter a versão 2.30.0 ou posterior do SDK do Apache Beam para usar o Dataflow Runner v2 e tem de ter a versão 2.3.0 ou posterior da biblioteca do cliente HBase para Java.
Para importar tabelas comprimidas com o formato Snappy, execute o mesmo comando que executa para tabelas não comprimidas, mas adicione a seguinte opção:
--enableSnappy=true
Valide os dados importados no Bigtable
Para validar os dados importados, tem de executar a tarefa sync-table. A tarefa sync-tablecalcula hashes para intervalos de linhas no Bigtable e, em seguida, faz a correspondência com o resultado da tabela de hash que calculou anteriormente.
Para executar a tarefa sync-table, execute o seguinte na shell de comandos:
java -jar $IMPORT_JAR sync-table \
--runner=dataflow \
--project=$PROJECT_ID \
--bigtableInstanceId=$INSTANCE_ID \
--bigtableTableId=TABLE_NAME \
--outputPrefix=$MIGRATION_DESTINATION_DIRECTORY/sync-table/output-TABLE_NAME-$(date +"%s") \
--stagingLocation=$MIGRATION_DESTINATION_DIRECTORY/sync-table/staging \
--hashTableOutputDir=$MIGRATION_DESTINATION_DIRECTORY/hashtable/TABLE_NAME \
--tempLocation=$MIGRATION_DESTINATION_DIRECTORY/sync-table/dataflow-test/temp \
--region=$REGION
Substitua TABLE_NAME pelo nome da tabela HBase que está a importar.
Quando a tarefa sync-table estiver concluída, abra a página Detalhes da tarefa do Dataflow e
reveja a secção Contadores personalizados da tarefa. Se a tarefa de importação importar com êxito todos os dados, o valor de ranges_matched tem um valor e o valor de ranges_not_matched é 0.
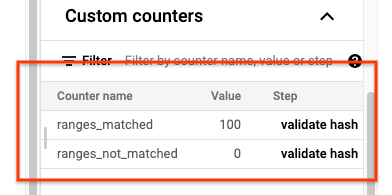
Se ranges_not_matched mostrar um valor, abra a página Registos, escolha Registos do trabalhador e filtre por Divergência no intervalo. O resultado legível por computador
destes registos é armazenado no Cloud Storage no destino
de saída que cria na opção outputPrefix da tabela de sincronização.
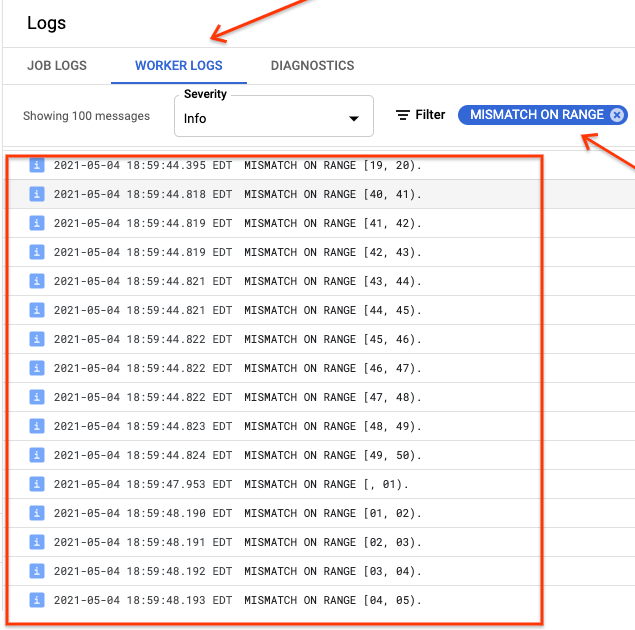
Pode tentar novamente a tarefa de importação ou escrever um script para ler os ficheiros de saída e determinar onde ocorreram as incompatibilidades. Cada linha no ficheiro de saída é um registo JSON serializado de um intervalo com incompatibilidade.
A rota escreve no Bigtable
Depois de validar os dados de cada tabela no cluster, pode configurar as suas aplicações para encaminhar todo o respetivo tráfego para o Bigtable e, em seguida, descontinuar a instância do HBase.
Quando a migração estiver concluída, pode eliminar as capturas de ecrã na instância do HBase.
O que se segue?
- Saiba mais sobre o Cloud Storage.