Halaman ini menjelaskan pertimbangan dan proses migrasi data dari cluster Apache HBase ke instance Bigtable diGoogle Cloud.
Proses yang dijelaskan di halaman ini mengharuskan Anda mengalihkan aplikasi ke offline. Jika Anda ingin melakukan migrasi tanpa periode nonaktif, lihat panduan untuk migrasi online di Mereplikasi dari HBase ke Bigtable.
Untuk memigrasikan data ke Bigtable dari cluster HBase yang di-hosting di Google Cloud layanan, seperti Dataproc atau Compute Engine, lihat Memigrasikan HBase yang di-hosting di Google Cloud ke Bigtable.
Sebelum memulai migrasi ini, Anda harus mempertimbangkan implikasi performa, desain skema Bigtable, pendekatan Anda terhadap autentikasi dan otorisasi, serta set fitur Bigtable.
Pertimbangan pra-migrasi
Bagian ini menyarankan beberapa hal yang perlu ditinjau dan dipikirkan sebelum Anda memulai migrasi.
Performa
Dalam workload umum, Bigtable memberikan performa yang sangat dapat diprediksi. Pastikan Anda memahami faktor-faktor yang memengaruhi performa Bigtable sebelum memigrasikan data Anda.
Desain skema Bigtable
Dalam sebagian besar kasus, Anda dapat menggunakan desain skema yang sama di Bigtable seperti yang Anda lakukan di HBase. Jika Anda ingin mengubah skema atau kasus penggunaan Anda berubah, tinjau konsep yang diuraikan dalam Mendesain skema Anda sebelum Anda memigrasikan data.
Autentikasi dan otorisasi
Sebelum mendesain kontrol akses untuk Bigtable, tinjau proses autentikasi dan otorisasi HBase yang ada.
Bigtable menggunakan Google Cloud's standard mekanisme untuk autentikasi dan Identity and Access Management untuk menyediakan kontrol akses, sehingga Anda mengonversi otorisasi yang ada di HBase ke IAM. Anda dapat memetakan grup Hadoop yang ada yang menyediakan mekanisme kontrol akses untuk HBase ke akun layanan yang berbeda.
Bigtable memungkinkan Anda mengontrol akses di tingkat project, instance, dan tabel. Untuk mengetahui informasi selengkapnya, lihat Kontrol Akses.
Persyaratan periode nonaktif
Pendekatan migrasi yang dijelaskan di halaman ini melibatkan penonaktifan aplikasi Anda selama durasi migrasi. Jika bisnis Anda tidak dapat mentoleransi periode nonaktif saat Anda melakukan migrasi ke Bigtable, lihat panduan untuk migrasi online di Mereplikasi dari HBase ke Bigtable.
Memigrasikan HBase ke Bigtable
Untuk memigrasikan data dari HBase ke Bigtable, Anda mengekspor snapshot HBase untuk setiap tabel ke Cloud Storage, lalu mengimpor data ke Bigtable. Langkah-langkah ini ditujukan untuk satu cluster HBase dan dijelaskan secara mendetail di beberapa bagian berikutnya.
- Berhenti mengirim operasi tulis ke cluster HBase Anda.
- Ambil snapshot tabel cluster HBase.
- Mengekspor file snapshot ke Cloud Storage.
- Hitung hash dan ekspor ke Cloud Storage.
- Buat tabel tujuan di Bigtable.
- Impor data HBase dari Cloud Storage ke Bigtable.
- Memvalidasi data yang diimpor.
- Rute menulis ke Bigtable.
Sebelum memulai
Buat bucket Cloud Storage untuk menyimpan snapshot Anda. Buat bucket di lokasi yang sama dengan tempat Anda berencana menjalankan tugas Dataflow.
Buat instance Bigtable untuk menyimpan tabel baru Anda.
Identifikasi cluster Hadoop yang Anda ekspor. Anda dapat menjalankan tugas untuk migrasi secara langsung di cluster HBase atau di cluster Hadoop terpisah yang memiliki konektivitas jaringan ke Namenode dan Datanode cluster HBase.
Instal dan konfigurasi konektor Cloud Storage di setiap node dalam cluster Hadoop serta host tempat tugas dimulai. Untuk langkah-langkah penginstalan yang mendetail, lihat Menginstal konektor Cloud Storage.
Buka shell perintah di host yang dapat terhubung ke cluster HBase dan project Bigtable Anda. Di sinilah Anda akan menyelesaikan langkah berikutnya.
Dapatkan alat Terjemahan Skema:
wget BIGTABLE_HBASE_TOOLS_URLGanti
BIGTABLE_HBASE_TOOLS_URLdengan URLJAR with dependenciesterbaru yang tersedia di repositori Maven alat. Nama file mirip denganhttps://repo1.maven.org/maven2/com/google/cloud/bigtable/bigtable-hbase-1.x-tools/1.24.0/bigtable-hbase-1.x-tools-1.24.0-jar-with-dependencies.jar.Untuk menemukan URL atau mendownload JAR secara manual, lakukan hal berikut:
- Buka repositori.
- Klik nomor versi terbaru.
- Identifikasi
JAR with dependencies file(biasanya di bagian atas). - Klik kanan dan salin URL, atau klik untuk mendownload file.
Mendapatkan alat Impor:
wget BIGTABLE_BEAM_IMPORT_URLGanti
BIGTABLE_BEAM_IMPORT_URLdengan URLshaded JARterbaru yang tersedia di repositori Maven alat. Nama file mirip denganhttps://repo1.maven.org/maven2/com/google/cloud/bigtable/bigtable-beam-import/1.24.0/bigtable-beam-import-1.24.0-shaded.jar.Untuk menemukan URL atau mendownload JAR secara manual, lakukan langkah-langkah berikut:
- Buka repositori.
- Klik nomor versi terbaru.
- Klik Hasil download.
- Arahkan kursor ke shaded.jar.
- Klik kanan dan salin URL, atau klik untuk mendownload file.
Tetapkan variabel lingkungan berikut:
#Google Cloud export PROJECT_ID=PROJECT_ID export INSTANCE_ID=INSTANCE_ID export REGION=REGION export CLUSTER_NUM_NODES=CLUSTER_NUM_NODES #JAR files export TRANSLATE_JAR=TRANSLATE_JAR export IMPORT_JAR=IMPORT_JAR #Cloud Storage export BUCKET_NAME="gs://BUCKET_NAME" export MIGRATION_DESTINATION_DIRECTORY="$BUCKET_NAME/hbase-migration-snap" #HBase export ZOOKEEPER_QUORUM=ZOOKEPER_QUORUM export ZOOKEEPER_PORT=2181 export ZOOKEEPER_QUORUM_AND_PORT="$ZOOKEEPER_QUORUM:$ZOOKEEPER_PORT" export MIGRATION_SOURCE_DIRECTORY=MIGRATION_SOURCE_DIRECTORYGanti kode berikut:
PROJECT_ID: Google Cloud project tempat instance Anda beradaINSTANCE_ID: ID instance Bigtable yang menjadi tujuan impor data AndaREGION: region yang berisi salah satu cluster di instance Bigtable Anda. Contoh:northamerica-northeast2CLUSTER_NUM_NODES: jumlah node dalam instance Bigtable AndaTRANSLATE_JAR: nama dan nomor versi file JARbigtable hbase toolsyang Anda download dari Maven. Nilainya akan terlihat sepertibigtable-hbase-1.x-tools-1.24.0-jar-with-dependencies.jar.IMPORT_JAR: nama dan nomor versi file JARbigtable-beam-importyang Anda download dari Maven. Nilainya akan terlihat sepertibigtable-beam-import-1.24.0-shaded.jar.BUCKET_NAME: nama bucket Cloud Storage tempat Anda menyimpan snapshotZOOKEEPER_QUORUM: host zookeeper yang akan dihubungkan oleh alat, dalam formathost1.myownpersonaldomain.comMIGRATION_SOURCE_DIRECTORY: direktori di host HBase yang berisi data yang ingin Anda migrasikan, dalam formathdfs://host1.myownpersonaldomain.com:8020/hbase
(Opsional) Untuk mengonfirmasi bahwa variabel telah ditetapkan dengan benar, jalankan perintah
printenvuntuk melihat semua variabel lingkungan.
Menghentikan pengiriman penulisan ke HBase
Sebelum mengambil snapshot tabel HBase, hentikan pengiriman penulisan ke cluster HBase.
Mengambil snapshot tabel HBase
Saat cluster HBase Anda tidak lagi menyerap data, ambil snapshot setiap tabel yang akan Anda migrasikan ke Bigtable.
Snapshot memiliki jejak penyimpanan minimal pada cluster HBase pada awalnya, tetapi seiring waktu, snapshot dapat bertambah hingga berukuran sama dengan tabel asli. Snapshot tidak menggunakan resource CPU apa pun.
Jalankan perintah berikut untuk setiap tabel, menggunakan nama unik untuk setiap snapshot:
echo "snapshot 'TABLE_NAME', 'SNAPSHOT_NAME'" | hbase shell -n
Ganti kode berikut:
TABLE_NAME: nama tabel HBase tempat Anda mengekspor data.SNAPSHOT_NAME: nama untuk snapshot baru
Mengekspor snapshot HBase ke Cloud Storage
Setelah membuat snapshot, Anda perlu mengekspornya. Saat Anda menjalankan tugas ekspor di cluster HBase produksi, pantau cluster dan resource HBase lainnya untuk memastikan cluster tetap dalam kondisi baik.
Untuk setiap snapshot yang ingin Anda ekspor, jalankan perintah berikut:
hbase org.apache.hadoop.hbase.snapshot.ExportSnapshot \
-Dhbase.zookeeper.quorum=$ZOOKEEPER_QUORUM_AND_PORT -snapshot SNAPSHOT_NAME \
-copy-from $MIGRATION_SOURCE_DIRECTORY \
-copy-to $MIGRATION_DESTINATION_DIRECTORY/data
Ganti SNAPSHOT_NAME dengan nama snapshot yang akan diekspor.
Menghitung dan mengekspor hash
Selanjutnya, buat hash untuk digunakan dalam validasi setelah migrasi selesai.
HashTable adalah alat validasi yang disediakan oleh HBase yang menghitung hash untuk rentang baris dan mengekspornya ke file. Anda dapat menjalankan tugas sync-table pada
tabel tujuan untuk mencocokkan hash dan mendapatkan keyakinan akan integritas
data yang dimigrasikan.
Jalankan perintah berikut untuk setiap tabel yang Anda ekspor:
hbase org.apache.hadoop.hbase.mapreduce.HashTable --batchsize=32000 --numhashfiles=20 \
TABLE_NAME $MIGRATION_DESTINATION_DIRECTORY/hashtable/TABLE_NAME
Ganti kode berikut:
TABLE_NAME: nama tabel HBase yang Anda buat snapshotnya dan diekspor
Membuat tabel tujuan
Langkah selanjutnya adalah membuat tabel tujuan di instance Bigtable
untuk setiap snapshot yang Anda ekspor. Gunakan akun yang memiliki izin bigtable.tables.create untuk instance.
Panduan ini menggunakan
alat Terjemahan Skema Bigtable,
yang secara otomatis membuat tabel untuk Anda. Namun, jika tidak ingin skema Bigtable Anda sama persis dengan skema HBase, Anda dapat membuat tabel menggunakan alat command line cbt atau konsol Google Cloud .
Alat Terjemahan Skema Bigtable merekam skema tabel HBase, termasuk nama tabel, grup kolom, kebijakan pengumpulan sampah, dan pemisahan. Kemudian, tabel ini membuat tabel serupa di Bigtable.
Untuk setiap tabel yang ingin Anda impor, jalankan perintah berikut untuk menyalin skema dari HBase ke Bigtable.
java \
-Dgoogle.bigtable.project.id=$PROJECT_ID \
-Dgoogle.bigtable.instance.id=$INSTANCE_ID \
-Dgoogle.bigtable.table.filter=TABLE_NAME \
-Dhbase.zookeeper.quorum=$ZOOKEEPER_QUORUM \
-Dhbase.zookeeper.property.clientPort=$ZOOKEEPER_PORT \
-jar $TRANSLATE_JAR
Ganti TABLE_NAME dengan nama tabel HBase
yang Anda impor. Alat Schema Translation menggunakan nama ini untuk
tabel Bigtable baru Anda.
Anda juga dapat mengganti TABLE_NAME dengan ekspresi reguler, seperti ".*", yang mencakup semua tabel yang ingin Anda buat, lalu jalankan perintah hanya sekali.
Impor data HBase ke Bigtable menggunakan Dataflow
Setelah memiliki tabel yang siap untuk memigrasikan data, Anda siap mengimpor dan memvalidasi data.
Tabel yang tidak dikompresi
Jika tabel HBase Anda tidak dikompresi, jalankan perintah berikut untuk setiap tabel yang ingin Anda migrasikan:
java -jar $IMPORT_JAR importsnapshot \
--runner=DataflowRunner \
--project=$PROJECT_ID \
--bigtableInstanceId=$INSTANCE_ID \
--bigtableTableId=TABLE_NAME \
--hbaseSnapshotSourceDir=$MIGRATION_DESTINATION_DIRECTORY/data \
--snapshotName=SNAPSHOT_NAME \
--stagingLocation=$MIGRATION_DESTINATION_DIRECTORY/staging \
--tempLocation=$MIGRATION_DESTINATION_DIRECTORY/temp \
--maxNumWorkers=$(expr 3 \* $CLUSTER_NUM_NODES) \
--region=$REGION
Ganti kode berikut:
TABLE_NAME: nama tabel HBase yang Anda impor. Alat Terjemahan Skema memberikan nama ini untuk tabel Bigtable baru Anda. Nama tabel baru tidak didukung.SNAPSHOT_NAME: nama yang Anda tetapkan ke snapshot tabel yang Anda impor
Setelah Anda menjalankan perintah, alat akan memulihkan snapshot HBase ke bucket Cloud Storage Anda, lalu memulai tugas impor. Proses pemulihan snapshot dapat berlangsung selama beberapa menit, bergantung pada ukuran snapshot.
Perhatikan tips berikut saat Anda mengimpor:
- Untuk meningkatkan performa pemuatan data, pastikan untuk menyetel
maxNumWorkers. Nilai ini membantu memastikan bahwa tugas impor memiliki daya komputasi yang cukup untuk diselesaikan dalam jangka waktu yang wajar, tetapi tidak terlalu besar sehingga akan membebani instance Bigtable.- Jika Anda tidak menggunakan instance Bigtable untuk beban kerja lain, kalikan jumlah node di instance Bigtable dengan 3, lalu gunakan angka tersebut untuk
maxNumWorkers. - Jika Anda menggunakan instance untuk workload lain pada saat yang sama dengan
mengimpor data HBase, kurangi nilai
maxNumWorkersdengan tepat.
- Jika Anda tidak menggunakan instance Bigtable untuk beban kerja lain, kalikan jumlah node di instance Bigtable dengan 3, lalu gunakan angka tersebut untuk
- Gunakan jenis pekerja default.
- Selama impor, Anda harus memantau penggunaan CPU instance Bigtable. Jika pemakaian CPU di seluruh instance Bigtable terlalu tinggi, Anda mungkin perlu menambahkan node tambahan. Diperlukan waktu hingga 20 menit agar cluster memberikan manfaat performa dari node tambahan.
Untuk mengetahui informasi selengkapnya tentang pemantauan instance Bigtable, lihat Pemantauan.
Tabel terkompresi yang cepat
Jika Anda mengimpor tabel yang dikompresi Snappy, Anda harus menggunakan image container kustom di pipeline Dataflow. Image container kustom yang Anda gunakan untuk mengimpor data terkompresi ke Bigtable menyediakan dukungan library kompresi native Hadoop. Anda harus memiliki Apache Beam SDK versi 2.30.0 atau yang lebih baru untuk menggunakan Dataflow Runner v2, dan Anda harus memiliki library klien HBase untuk Java versi 2.3.0 atau yang lebih baru.
Untuk mengimpor tabel yang dikompresi Snappy, jalankan perintah yang sama yang Anda jalankan untuk tabel yang tidak dikompresi, tetapi tambahkan opsi berikut:
--enableSnappy=true
Memvalidasi data yang diimpor di Bigtable
Untuk memvalidasi data yang diimpor, Anda perlu menjalankan tugas sync-table. Tugas
sync-table menghitung hash untuk rentang baris di Bigtable,
lalu mencocokkannya dengan output HashTable yang Anda hitung sebelumnya.
Untuk menjalankan tugas sync-table, jalankan perintah berikut di command shell:
java -jar $IMPORT_JAR sync-table \
--runner=dataflow \
--project=$PROJECT_ID \
--bigtableInstanceId=$INSTANCE_ID \
--bigtableTableId=TABLE_NAME \
--outputPrefix=$MIGRATION_DESTINATION_DIRECTORY/sync-table/output-TABLE_NAME-$(date +"%s") \
--stagingLocation=$MIGRATION_DESTINATION_DIRECTORY/sync-table/staging \
--hashTableOutputDir=$MIGRATION_DESTINATION_DIRECTORY/hashtable/TABLE_NAME \
--tempLocation=$MIGRATION_DESTINATION_DIRECTORY/sync-table/dataflow-test/temp \
--region=$REGION
Ganti TABLE_NAME dengan nama tabel HBase
yang Anda impor.
Setelah tugas sync-table selesai, buka halaman Detail Tugas Dataflow dan tinjau bagian Penghitung kustom untuk tugas tersebut. Jika tugas impor berhasil mengimpor semua data, nilai untuk ranges_matched akan memiliki nilai dan nilai untuk ranges_not_matched adalah 0.
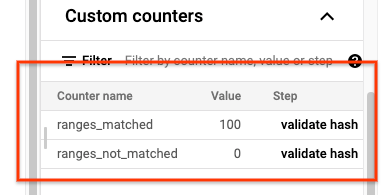
Jika ranges_not_matched menampilkan nilai, buka halaman Logs, pilih
Worker Logs, lalu filter menurut Mismatch on range. Output yang dapat dibaca mesin dari log ini disimpan di Cloud Storage di tujuan output yang Anda buat dalam opsi outputPrefix sync-table.
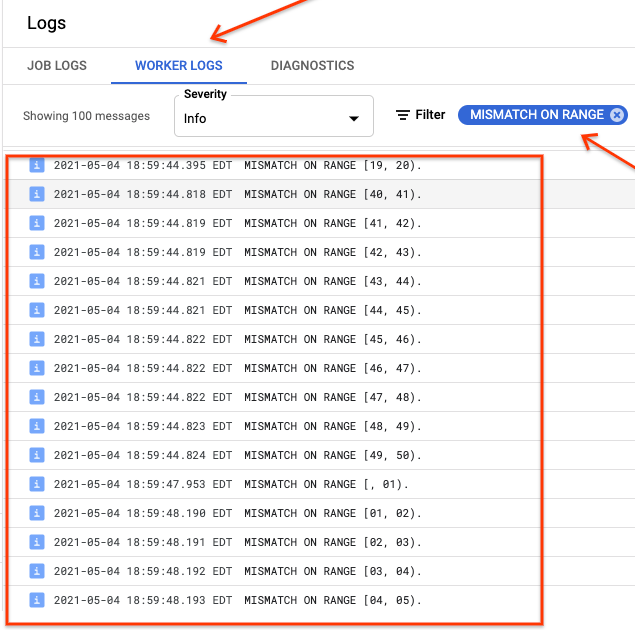
Anda dapat mencoba lagi tugas impor atau menulis skrip untuk membaca file output guna menentukan lokasi terjadinya ketidakcocokan. Setiap baris dalam file output adalah rekaman JSON yang diserialkan dari rentang yang tidak cocok.
Rute menulis ke Bigtable
Setelah memvalidasi data untuk setiap tabel di cluster, Anda dapat mengonfigurasi aplikasi untuk merutekan semua trafficnya ke Bigtable, lalu menghentikan penggunaan instance HBase.
Setelah migrasi selesai, Anda dapat menghapus snapshot di instance HBase.
Langkah berikutnya
- Pelajari Cloud Storage lebih lanjut.