Von HBase in Bigtable replizieren
Die Cloud Bigtable HBase-Replikationsbibliothek ist eine Komponente des Open-Source-Cloud Bigtable HBase-Clients für Java. Mit der Replikationsbibliothek können Sie Daten mithilfe des HBase-Replikationsdienstes asynchron von einem HBase-Cluster in eine Bigtable-Instanz replizieren. So können Sie eine Online-Migration von HBase zu Bigtable durchführen. Die README-Datei und den Quellcode finden Sie im GitHub-Repository.
Informationen zur Offlinemigration von HBase zu Bigtable finden Sie unter Daten von HBase zu Bigtable offline migrieren.
Anwendungsfälle
- Online-Migration zu Bigtable: Sie können die Bigtable-HBase-Replikationsbibliothek in Verbindung mit einer Offline-Migration Ihrer vorhandenen HBase-Daten verwenden, um nahezu ohne Ausfallzeiten von HBase zu Bigtable zu migrieren.
- Datenwiederherstellung: Vorbereitungen für das Unerwartete, indem Sie Ihre HBase-Daten auf eine externe Bigtable-Instanz replizieren.
- Datasets zentralisieren: Verwenden Sie die Bibliothek, um Daten aus HBase-Clustern an mehreren Standorten in einer einzigen Bigtable-Instanz zu replizieren, die automatisch die Replikation zwischen den Clustern übernimmt.
- HBase-Bedarf erweitern: Replizieren Sie auf eine Bigtable-Instanz, die Cluster an Standorten außerhalb der aktuellen HBase-Standorte hat.
Übersicht
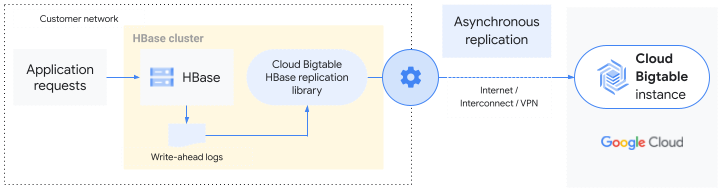
Die Bigtable-HBase-Replikationsbibliothek erweitert den HBase-Replikationsdienst. In einen HBase-Cluster geschriebene Daten werden auf dieselbe Weise in eine Bigtable-Instanz repliziert, wie die standardmäßige HBase-Replikation Daten in einen anderen HBase-Cluster kopiert. Die Bibliothek verwendet das Write-Ahead-Log (WAL) des HBase-Quellclusters, um die Mutationen an die Bigtable-Instanz zu übertragen.
Sie können einen gesamten HBase-Cluster in Bigtable replizieren oder nur bestimmte Tabellen oder Spaltenfamilien replizieren. Das bedeutet, dass die HBase-Replikation auf Cluster-, Tabellen- oder Spaltenfamilien aktiviert ist.
Die Replikation von HBase zu Bigtable unterliegt der Eventual Consistency.
Zu Bigtable migrieren
Mit der HBase-Replikationsbibliothek von Bigtable können Sie zu Bigtable migrieren, ohne dass Ihre Anwendung angehalten wird.
Im Allgemeinen sind für die Onlinemigration von HBase zu Bigtable die folgenden Schritte notwendig. Weitere Informationen finden Sie in der README-Datei.
- Folgen Sie zuerst den Schritten zur Einrichtung und Konfiguration.
- Aktivieren Sie die Replikation auf dem HBase-Cluster.
- Fügen Sie einen Bigtable-Replikationsendpunkt als Peer hinzu.
- Deaktivieren Sie den Bigtable-Peer. Dadurch werden Schreibvorgänge in HBase von diesem Punkt an zwischengespeichert, um den HBase-Cluster zu nutzen.
- Sobald die Zwischenspeicherung mit dem Erfassen neuer Schreibvorgänge beginnt, folgen Sie der Offline-Migrationsanleitung, um einen Snapshot Ihrer vorhandenen HBase-Daten zu migrieren.
- Wenn die Offline-Migration abgeschlossen ist, aktivieren Sie den Bigtable-Peer wieder, damit der Puffer geleert und Schreibvorgänge in Bigtable wiederholt werden können.
- Nachdem der Puffer geleert wurde, starten Sie die Anwendung neu, um Anfragen an Bigtable zu senden.
Replikationsbibliothek einrichten und konfigurieren
Bevor Sie die Bigtable-HBase-Replikation verwenden können, müssen Sie die Aufgaben in diesem Abschnitt ausführen.
Authentifizierung konfigurieren
Führen Sie die Schritte unter Dienstkonto erstellen aus, damit die Replikationsbibliothek zum Schreiben in Bigtable berechtigt ist. Weisen Sie dem neu erstellten Dienstkonto die Rolle roles/bigtable.user zu.
Als Nächstes fügen Sie Folgendes in die Datei hbase-site.xml für den gesamten HBase-Cluster ein.
<property>
<name>google.bigtable.auth.json.keyfile</name>
<value>JSON_FILE_PATH</value>
<description>
Service account JSON file to connect to Cloud Bigtable
</description>
</property>
Ersetzen Sie JSON_FILE_PATH durch den Pfad zur heruntergeladenen JSON-Datei.
Weitere Attribute, die Sie festlegen können, finden Sie unter HBaseToCloudBigtableReplicationConfiguration.
Zielinstanz und Tabellen erstellen
Bevor Sie von HBase zu Bigtable replizieren können, erstellen Sie eine Bigtable-Instanz. Eine Bigtable-Instanz kann einen oder mehrere Cluster haben, die multiprimär arbeiten. Anfragen vom HBase-Replikationsdienst werden an den nächsten Cluster in der Bigtable-Instanz weitergeleitet und dann zu den anderen Clustern in der Instanz repliziert.
Die Bigtable-Zieltabelle muss denselben Namen und dieselben Spaltenfamilien wie die HBase-Tabelle haben. Eine detaillierte Anleitung zur Verwendung des Bigtable-Schemaübersetzungstools zum Erstellen einer Tabelle mit demselben Schema wie Ihre HBase-Tabelle finden Sie unter Daten von HBase zu Bigtable offline migrieren. Obwohl Sie die Daten replizieren, statt die Daten zu importieren, sind die Schritte identisch.
Konfigurationsattribute festlegen
Fügen Sie Folgendes in Ihre hbase-site.xml für den gesamten HBase-Cluster ein.
<property>
<name>google.bigtable.project.id</name>
<value>PROJECT_ID</value>
<description>
Bigtable project ID
</description>
</property>
<property>
<name>google.bigtable.instance.id</name>
<value>INSTANCE_ID</value>
<description>
Bigtable instance ID
</description>
</property>
<property>
<name>google.bigtable.app_profile.id</name>
<value>APP_PROFILE_ID</value>
<description>
Bigtable app profile ID
</description>
</property>
Ersetzen Sie Folgendes:
PROJECT_ID: Das Google Cloud -Projekt, in dem sich Ihre Bigtable-Instanz befindet.INSTANCE_ID: die ID der Bigtable-Instanz, zu der Sie Ihre Daten replizieren.APP_PROFILE_ID: die ID des Anwendungsprofils, das für die Verbindung mit Bigtable verwendet werden soll.
Replikationsbibliothek installieren
Wenn Sie die Bigtable-Replikationsbibliothek verwenden möchten, müssen Sie sie auf allen Servern im HBase-Cluster installieren. Verwenden Sie die Replikationsbibliotheksversion, die der HBase-Version (1.x oder 2.x) entspricht.
JAR-Datei herunterladen
Führen Sie in der HBase-Shell Folgendes aus, um die Replikationsbibliothek abzurufen.
wget BIGTABLE_HBASE_REPLICATION_URL
Ersetzen Sie BIGTABLE_HBASE_REPLICATION_URL durch die URL der neuesten JAR-Datei mit Abhängigkeiten, die im Maven-Repository der Replikationsbibliothek verfügbar sind. Der Dateiname ähnelt https://repo1.maven.org/maven2/com/google/cloud/bigtable/bigtable-hbase-1.x-replication/1.0.0/bigtable-hbase-1.x-replication-1.0.0-jar-with-dependencies.jar.
So finden Sie die URL oder laden die JAR-Datei manuell herunter:
- Rufen Sie das Repository der Replikationsbibliothek für die von Ihnen verwendete HBase-Version auf.
- Klicken Sie auf die neueste Versionsnummer, z. B.
1.0.0. - Ermitteln Sie die Datei jar-with-dependencies (normalerweise oben).
- Klicken Sie mit der rechten Maustaste und kopieren Sie die URL oder klicken Sie, um die Datei herunterzuladen.
JAR installieren
Kopieren Sie die gerade heruntergeladene Datei auf jedem HBase-Server, einschließlich des Master- und der Region-Server, in einen Ordner im HBase-Classpath. Sie können die Datei beispielsweise nach /usr/lib/hbase/lib/ kopieren.
Bigtable-Peer hinzufügen
Für die Replikation von HBase zu Bigtable müssen Sie einen Bigtable-Endpunkt als Replikations-Peer hinzufügen.
- Starten Sie die HBase-Server neu, damit die Replikationsbibliothek geladen wird.
- Führen Sie in der HBase-Shell Folgendes aus.
add_peer PEER_ID_NUMBER, ENDPOINT_CLASSNAME =>
'com.google.cloud.bigtable.hbaseHBASE_VERSION_NUMBER_x.replication.HbaseToCloudBigtableReplicationEndpoint`
Dabei gilt:
PEER_ID_NUMBER: eine Ganzzahl-ID für den Bigtable-Replikations-Peer. Wenn Sie die HBase-Replikation nur ausgewählter Tabellen aktivieren möchten, verwenden Sie einen optionalen Parameteradd_peer.HBASE_VERSION_NUMBER: die Nummer der HBase-Version, die Sie verwenden. Verwenden Sie1für HBase 1.x und2für HBase 2.x. (HBase 3.x wird nicht unterstützt.)
Nächste Schritte
- Überblick über das Speichermodell, die Architektur und die Features von Bigtable
- Unterschiede zwischen HBase und Bigtable.