HBase에서 Bigtable로 복제
Cloud Bigtable HBase 복제 라이브러리는 오픈소스 Java용 Cloud Bigtable HBase 클라이언트의 구성요소입니다. 이 복제 라이브러리에서는 HBase 복제 서비스를 사용하여 HBase 클러스터에서 Bigtable 인스턴스로 데이터를 비동기적으로 복제할 수 있습니다. 리드미 및 소스 코드를 검토하려면 GitHub 저장소를 참조하세요.
사용 사례
- Bigtable로 온라인 마이그레이션 - 기존 HBase 데이터의 오프라인 마이그레이션과 함께 Bigtable HBase 복제 라이브러리를 사용하여 거의 다운타임 없이 HBase에서 Bigtable로 마이그레이션을 할 수 있습니다.
- 데이터 복구 - HBase 데이터를 오프사이트 Bigtable 인스턴스에 복제하여 예상하지 못한 문제를 대비합니다.
- 데이터 세트 중앙 집중화 - 라이브러리를 사용하여 여러 위치에 있는 HBase 클러스터의 데이터를 클러스터 간에 복제를 자동으로 처리하는 단일 Bigtable 인스턴스에 복제합니다.
- HBase 공간 확장 - 현재 HBase 위치를 넘어서 여러 위치에 클러스터가 있는 Bigtable 인스턴스에 복제합니다.
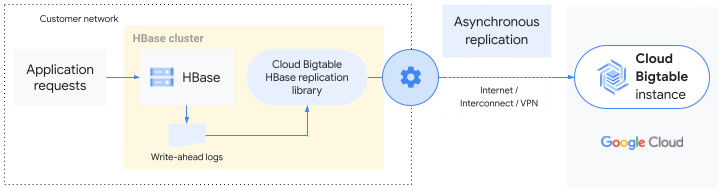
개요
Bigtable HBase 복제 라이브러리는 기본 HBase 복제 서비스를 확장합니다. HBase 클러스터에 기록된 데이터는 표준 HBase 복제가 다른 HBase 클러스터에 데이터를 복사하는 것과 동일한 방법으로 Bigtable 인스턴스에 비동기적으로 복제됩니다. 라이브러리는 소스 HBase 클러스터의 미리 쓰기 로그(WAL)를 사용해서 Bigtable 인스턴스에 변형을 푸시합니다.
전체 HBase 클러스터를 Bigtable에 복제하거나 특정 테이블 또는 열 그룹만 복제할 수 있습니다. 즉, HBase 복제는 클러스터, 테이블 또는 column family 수준에서 사용 설정됩니다.
HBase에서 Bigtable로의 복제는 eventual consistency를 갖습니다.
Bigtable로 마이그레이션
Bigtable HBase 복제 라이브러리에서는 애플리케이션을 일시중지하지 않고 Bigtable로 마이그레이션할 수 있습니다.
대략적으로 HBase에서 Bigtable로의 온라인 마이그레이션 단계는 다음과 같습니다. 자세한 내용은 README를 참조하세요.
- 시작하기 전에 설정 및 구성 단계를 따릅니다.
- HBase 클러스터에서 복제를 사용 설정합니다.
- Bigtable 복제 엔드포인트를 피어로 추가합니다.
- Bigtable 피어를 사용 중지합니다. 그러면 이제부터 HBase에 쓰기를 수행하면 HBase 클러스터 내에서 버퍼링됩니다.
- 새 쓰기를 캡처하도록 버퍼링이 시작되었으면 오프라인 마이그레이션 가이드에 따라 기존 HBase 데이터의 스냅샷을 마이그레이션합니다.
- 오프라인 마이그레이션이 완료되면 계속해서 Bigtable 피어를 다시 사용 설정하여 버퍼가 드레이닝되고 Bigtable에서 쓰기가 재생되도록 합니다.
- 버퍼가 드레이닝된 다음 애플리케이션을 다시 시작해서 Bigtable에 요청을 전송합니다.
복제 라이브러리 설정 및 구성
Bigtable HBase 복제를 사용하려면 먼저 이 섹션의 태스크를 완료해야 합니다.
인증 구성
복제 라이브러리에 Bigtable에 쓰기 권한이 있는지 확인하려면 서비스 계정 만들기 단계를 수행합니다. 새로 생성된 서비스 계정에 roles/bigtable.user 역할을 할당합니다.
그런 후 전체 HBase 클러스터에 걸쳐서 hbase-site.xml 파일에 다음을 추가합니다.
<property>
<name>google.bigtable.auth.json.keyfile</name>
<value>JSON_FILE_PATH</value>
<description>
Service account JSON file to connect to Cloud Bigtable
</description>
</property>
JSON_FILE_PATH를 다운로드한 JSON 파일 경로로 바꿉니다.
설정할 수 있는 추가 속성은 HBaseToCloudBigtableReplicationConfiguration을 참조하세요.
대상 인스턴스 및 테이블 만들기
HBase에서 Bigtable로 복제하려면 먼저 Bigtable 인스턴스를 만듭니다. Bigtable 인스턴스에는 하나의 클러스터 또는 여러 기본 방식으로 작동하는 여러 클러스터가 포함될 수 있습니다. HBase 복제 서비스의 요청은 Bigtable 인스턴스에서 가장 가까운 클러스터로 라우팅된 후 인스턴스의 다른 클러스터에 복제됩니다.
Bigtable 대상 테이블은 HBase 테이블과 이름 및 열 그룹이 동일해야 합니다. Bigtable 스키마 변환 도구를 사용해서 HBase 테이블과 동일한 스키마로 테이블을 만드는 방법에 대한 단계별 안내는 대상 테이블 만들기를 참조하세요. 데이터 가져오기가 아니라 복제의 경우에도 단계가 동일합니다.
구성 속성 설정
전체 HBase 클러스터에 걸쳐서 hbase-site.xml에 다음을 추가합니다.
<property>
<name>google.bigtable.project.id</name>
<value>PROJECT_ID</value>
<description>
Bigtable project ID
</description>
</property>
<property>
<name>google.bigtable.instance.id</name>
<value>INSTANCE_ID</value>
<description>
Bigtable instance ID
</description>
</property>
<property>
<name>google.bigtable.app_profile.id</name>
<value>APP_PROFILE_ID</value>
<description>
Bigtable app profile ID
</description>
</property>
다음을 바꿉니다.
PROJECT_ID: Bigtable 인스턴스가 있는 Google Cloud 프로젝트입니다.INSTANCE_ID: 데이터를 복제하려는 Bigtable 인스턴스의 ID입니다.APP_PROFILE_ID: Bigtable에 연결하기 위해 사용할 앱 프로필의 ID입니다.
복제 라이브러리 설치
Bigtable HBase 복제 라이브러리를 사용하려면 HBase 클러스터의 모든 서버에 설치해야 합니다. HBase 버전에 해당하는 복제 라이브러리 버전을 사용합니다(1.x 또는 2.x).
JAR 다운로드
복제 라이브러리를 가져오려면 HBase 셸에서 다음을 실행합니다.
wget BIGTABLE_HBASE_REPLICATION_URL
BIGTABLE_HBASE_REPLICATION_URL을 복제 라이브러리의 Maven 저장소에서 사용할 수 있는 종속 항목이 포함된 최신 JAR의 URL로 바꿉니다. 파일 이름은 https://repo1.maven.org/maven2/com/google/cloud/bigtable/bigtable-hbase-1.x-replication/1.0.0/bigtable-hbase-1.x-replication-1.0.0-jar-with-dependencies.jar과 유사한 형식입니다.
URL을 찾거나 JAR을 수동으로 다운로드하려면 다음을 수행합니다.
- 사용 중인 HBase 버전의 복제 라이브러리 저장소로 이동합니다.
- 최신 버전 번호를 클릭합니다(예:
1.0.0). - jar-with-dependencies 파일을 확인합니다(일반적으로 맨 위에 있음).
- 마우스 오른쪽 버튼을 클릭하고 URL을 복사하거나 클릭하여 파일을 다운로드합니다.
JAR 설치
마스터 및 리전 서버를 포함하여 모든 HBase 서버에서 바로 전에 다운로드한 파일을 HBase 클래스 경로의 한 폴더에 복사합니다. 예를 들어 파일을 /usr/lib/hbase/lib/에 복사할 수 있습니다.
Bigtable 피어 추가
HBase에서 Bigtable로 복제하려면 Bigtable 엔드포인트를 복제 피어로 추가해야 합니다.
- HBase 서버를 재시작하여 복제 라이브러리가 로드되었는지 확인합니다.
- HBase 셸에서 다음을 실행합니다.
add_peer PEER_ID_NUMBER, ENDPOINT_CLASSNAME =>
'com.google.cloud.bigtable.hbaseHBASE_VERSION_NUMBER_x.replication.HbaseToCloudBigtableReplicationEndpoint`
다음을 바꿉니다.
PEER_ID_NUMBER: Bigtable 복제 피어의 정수 ID입니다. 특정 테이블에 대해서만 HBase 복제를 사용 설정하려면add_peer선택적 매개변수를 사용합니다.HBASE_VERSION_NUMBER: 사용 중인 HBase 버전의 번호입니다. HBase 1.x에는1을 사용하고 HBase 2.x에는2를 사용합니다. (HBase 3.x는 지원되지 않습니다.)