Répliquer de HBase vers Bigtable
La bibliothèque de réplication Cloud Bigtable HBase est un composant du client Cloud Bigtable HBase pour Java (Open Source). La bibliothèque de réplication vous permet de répliquer de manière asynchrone les données d'un cluster HBase vers une instance Bigtable à l'aide du service de réplication HBase. Vous pouvez ainsi effectuer une migration en ligne de HBase vers Bigtable. Pour consulter le fichier README et le code source, accédez au dépôt GitHub.
Pour la migration hors connexion de HBase vers Bigtable, consultez Migrer des données de HBase vers Bigtable hors connexion.
Cas d'utilisation
- Migration en ligne vers Bigtable : vous pouvez utiliser la bibliothèque de réplication Bigtable HBase, conjointement avec une migration hors connexion de vos données HBase existantes, pour migrer de HBase vers Bigtable avec un temps d'arrêt presque nul.
- Récupération de données : préparez-vous à l'inattendu en répliquant vos données HBase vers une instance Bigtable hors site.
- Centralisation des ensembles de données : utilisez la bibliothèque pour répliquer les données des clusters HBase situés dans plusieurs emplacements vers une instance Bigtable unique qui gère automatiquement la réplication entre ses clusters.
- Extension de votre empreinte HBase : répliquez sur une instance Bigtable comportant des clusters dans des emplacements autres que vos emplacements HBase actuels.
Présentation
La bibliothèque de réplication Bigtable HBase étend le service de réplication HBase de base. Les données écrites sur un cluster HBase sont répliquées de manière asynchrone sur une instance Bigtable de la même manière que la réplication HBase standard, qui copie les données sur un autre cluster HBase. Elle utilise le journal des opérations d'écriture (WAL) du cluster HBase source pour envoyer les mutations à l'instance Bigtable.
Vous pouvez répliquer un cluster HBase entier vers Bigtable ou ne répliquer que des tables ou des familles de colonnes spécifiques. En d'autres termes, la réplication HBase est activée au niveau du cluster, de la table ou de la famille de colonnes.
La réplication de HBase vers Bigtable est cohérente à terme.
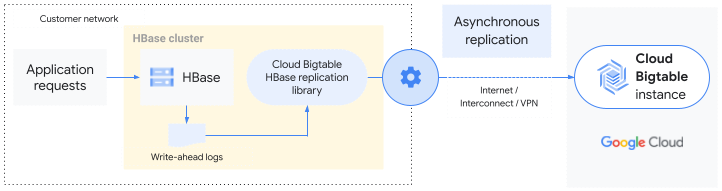
Migrer vers Bigtable
La bibliothèque de réplication Bigtable HBase vous permet de migrer vers Bigtable sans suspendre votre application.
De manière générale, les étapes de migration en ligne de HBase vers Bigtable sont les suivantes : Pour en savoir plus, consultez le fichier README.
- Avant de commencer, suivez les étapes d'installation et de configuration.
- Activez la réplication sur votre cluster HBase.
- Ajoutez un point de terminaison de réplication Bigtable en tant que pair.
- Désactivez le pair Bigtable. Cela entraîne la mise en mémoire tampon des écritures HBase sur le cluster HBase.
- Une fois que la mise en mémoire tampon a commencé à capturer de nouvelles écritures, suivez le Guide de migration hors connexion pour migrer un instantané de vos données HBase existantes.
- Une fois la migration hors connexion terminée, réactivez le pair Bigtable pour permettre au tampon de drainer et réappliquer les écritures sur Bigtable.
- Une fois le tampon drainé, redémarrez votre application pour envoyer des requêtes à Bigtable.
Configurer la bibliothèque de réplication
Avant de pouvoir utiliser la réplication Bigtable HBase, vous devez effectuer les tâches de la présente section.
Configurer l'authentification
Pour vous assurer que la bibliothèque de réplication est autorisée à écrire sur Bigtable, suivez les étapes décrites dans la section Créer un compte de service. Attribuez le rôle roles/bigtable.user au nouveau compte de service.
Ajoutez ensuite les éléments suivants à votre fichier hbase-site.xml sur l'ensemble du cluster HBase.
<property>
<name>google.bigtable.auth.json.keyfile</name>
<value>JSON_FILE_PATH</value>
<description>
Service account JSON file to connect to Cloud Bigtable
</description>
</property>
Remplacez JSON_FILE_PATH par le chemin d'accès au fichier JSON que vous avez téléchargé.
Pour connaître les autres propriétés que vous pouvez définir, consultez la section sur HBaseToCloudBigtableReplicationConfiguration.
Créer une instance de destination et des tables
Pour pouvoir effectuer une réplication de HBase vers Bigtable, créez une instance Bigtable. Une instance Bigtable peut avoir un ou plusieurs clusters fonctionnant simultanément en tant que serveurs principaux. Les requêtes du service de réplication HBase sont acheminées vers le cluster le plus proche dans l'instance Bigtable, puis répliquées sur les autres clusters de l'instance.
Votre table de destination Bigtable doit avoir le même nom et les mêmes familles de colonnes que votre table HBase. Pour obtenir des instructions détaillées sur l'utilisation de l'outil de traduction de schéma Bigtable pour créer une table ayant le même schéma que votre table HBase, consultez Migrer des données de HBase vers Bigtable hors connexion. Même si vous répliquez des données plutôt que de les importer, les étapes sont les mêmes.
Définir les propriétés de configuration
Ajoutez les éléments suivants à votre fichier hbase-site.xml sur l'ensemble du cluster HBase.
<property>
<name>google.bigtable.project.id</name>
<value>PROJECT_ID</value>
<description>
Bigtable project ID
</description>
</property>
<property>
<name>google.bigtable.instance.id</name>
<value>INSTANCE_ID</value>
<description>
Bigtable instance ID
</description>
</property>
<property>
<name>google.bigtable.app_profile.id</name>
<value>APP_PROFILE_ID</value>
<description>
Bigtable app profile ID
</description>
</property>
Remplacez les éléments suivants :
PROJECT_ID: projet Google Cloud dans lequel se trouve votre instance Bigtable.INSTANCE_ID: ID de l'instance Bigtable vers laquelle vous répliquez vos données.APP_PROFILE_ID: ID du profil d'application à utiliser pour se connecter à Bigtable.
Installer la bibliothèque de réplication
Pour utiliser la bibliothèque de réplication HBase, vous devez l'installer sur chaque serveur du cluster HBase. Utilisez la version de la bibliothèque de réplication correspondant à votre version de HBase (1.x ou 2.x).
Télécharger le fichier JAR
Pour obtenir la bibliothèque de réplication, exécutez la commande suivante dans le shell HBase.
wget BIGTABLE_HBASE_REPLICATION_URL
Remplacez BIGTABLE_HBASE_REPLICATION_URL par l'URL du dernier fichier JAR contenant les dépendances, disponible dans le dépôt Maven de la bibliothèque de réplication. Le nom du fichier est semblable à https://repo1.maven.org/maven2/com/google/cloud/bigtable/bigtable-hbase-1.x-replication/1.0.0/bigtable-hbase-1.x-replication-1.0.0-jar-with-dependencies.jar.
Pour trouver l'URL ou télécharger manuellement le fichier JAR, procédez comme suit.
- Accédez au dépôt de la bibliothèque de réplication pour la version de HBase que vous utilisez.
- Cliquez sur le numéro de version le plus récent, par exemple
1.0.0. - Identifiez le fichier jar-with-dependencies (généralement en haut).
- Effectuez un clic droit et copiez l'URL, ou cliquez pour télécharger le fichier.
Installer le fichier JAR
Sur chaque serveur HBase, y compris les serveurs maître et de région, copiez le fichier que vous venez de télécharger dans un dossier du classpath HBase. Par exemple, vous pouvez copier le fichier dans /usr/lib/hbase/lib/.
Ajouter un pair Bigtable
Pour effectuer une réplication de HBase vers Bigtable, vous devez ajouter un point de terminaison Bigtable en tant que pair de réplication.
- Redémarrez les serveurs HBase pour vous assurer que la bibliothèque de réplication est bien chargée.
- Exécutez la commande suivante dans le shell HBase.
add_peer PEER_ID_NUMBER, ENDPOINT_CLASSNAME =>
'com.google.cloud.bigtable.hbaseHBASE_VERSION_NUMBER_x.replication.HbaseToCloudBigtableReplicationEndpoint`
Remplacez les éléments suivants :
PEER_ID_NUMBER: ID (entier) pour le pair de réplication Bigtable. Pour activer la réplication HBase uniquement sur certaines tables, utilisez un paramètre facultatifadd_peer.HBASE_VERSION_NUMBER: numéro de la version HBase que vous utilisez. Utilisez1pour HBase 1.x et2pour HBase 2.x. (HBase 3.x n'est pas compatible.)
Étape suivante
- Consultez une présentation du modèle de stockage, de l'architecture et des fonctionnalités de Bigtable.
- Découvrez quelques-unes des différences entre HBase et Bigtable.