Migrer de DynamoDB vers Bigtable
Bigtable et DynamoDB sont des magasins de paires clé-valeur distribués capables de prendre en charge des millions de requêtes par seconde (RPS), de fournir un espace de stockage avec scaling à la hausse jusqu'à plusieurs pétaoctets de données, ainsi que de tolérer les défaillances de nœud.
Ce document est destiné aux développeurs DynamoDB et aux administrateurs de bases de données qui souhaitent migrer vers Bigtable. Il est également utile lorsque vous souhaitez concevoir des applications à utiliser avec Bigtable en tant que datastore.
Pour commencer, utilisez un outil de migration fourni par Google qui vous aide à migrer de DynamoDB vers Bigtable. Cette page décrit l'outil de migration, compare les deux systèmes de base de données et décrit l'architecture sous-jacente et les détails d'interaction qui diffèrent et qu'il est important de comprendre avant la migration.
Premiers pas avec l'outil de migration DynamoDB vers Bigtable
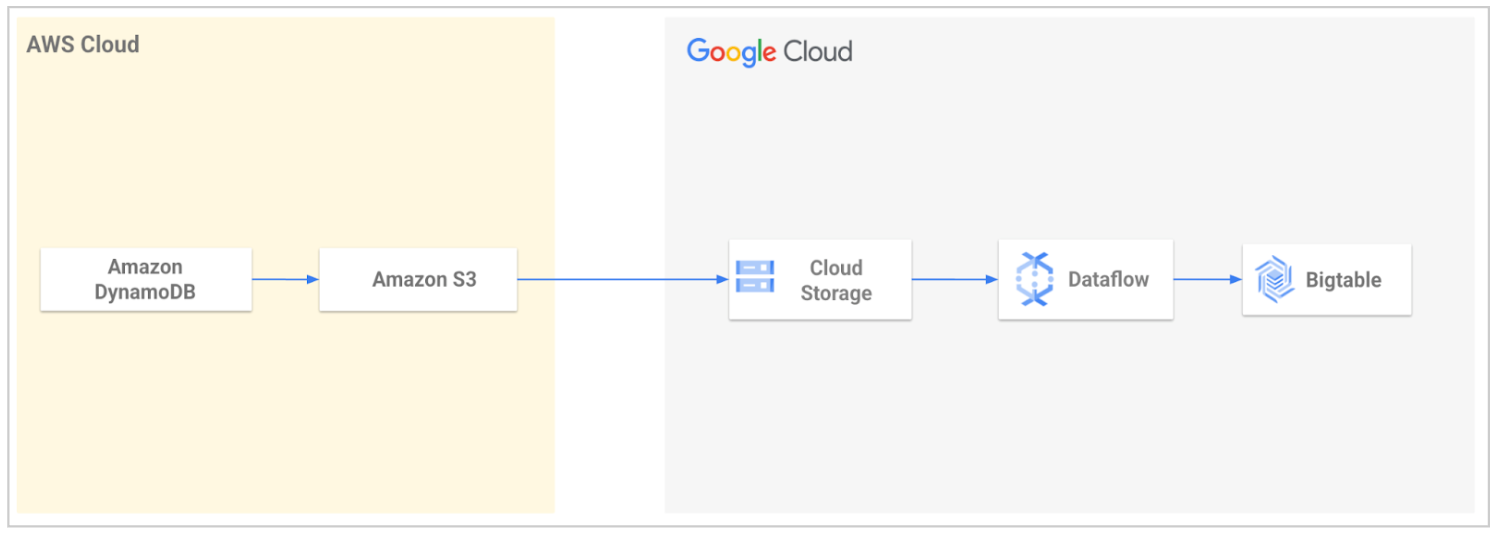
Les services professionnels Google Cloud fournissent un outil de migration Open Source pour simplifier la migration des données de DynamoDB vers Bigtable. Cet outil automatise le processus d'importation de vos données dans Google Cloud , puis leur chargement dans Bigtable.
À l'aide de cet outil, vous exportez votre table DynamoDB, puis vous la transférez vers Cloud Storage. L'outil lit les fichiers exportés depuis votre bucket Cloud Storage et utilise un modèle Dataflow pour transformer les données afin qu'elles soient compatibles avec Bigtable. Cette transformation inclut le mappage des attributs DynamoDB aux lignes Bigtable. La tâche Dataflow écrit ensuite les données transformées dans votre table Bigtable.
Pour en savoir plus ou vous lancer, consultez Utilitaire de migration de DynamoDB vers Bigtable.
Comparaison entre DynamoDB et Bigtable
Cette section examine les similitudes et les différences entre DynamoDB et Bigtable.
Plan de contrôle
Dans DynamoDB et Bigtable, le plan de contrôle vous permet de configurer votre capacité, et de configurer et gérer les ressources. DynamoDB est un produit sans serveur. Le niveau d'interaction le plus élevé avec DynamoDB est celui des tables. En mode de capacité provisionnée, vous pouvez provisionner vos unités de requête de lecture et d'écriture, sélectionner vos régions et la réplication, et gérer les sauvegardes. Bigtable n'est pas un produit sans serveur. Vous devez créer une instance avec un ou plusieurs clusters, dont la capacité est déterminée par le nombre de nœuds qu'ils contiennent. Pour en savoir plus sur ces ressources, consultez Instances, clusters et nœuds.
Le tableau suivant compare les ressources du plan de contrôle pour DynamoDB et Bigtable.
| DynamoDB | Bigtable |
|---|---|
| Table : ensemble d'éléments avec une clé primaire définie. Les tables comportent des paramètres pour les sauvegardes, la réplication et la capacité. | Instance : groupe de clusters Bigtable dans différentes zones ou régions Google Cloud , entre lesquelles la réplication et le routage de connexion se produisent. Les règles de réplication sont définies au niveau de l'instance. Cluster : groupe de nœuds dans la même zoneGoogle Cloud géographique, idéalement colocalisés avec votre serveur d'application pour des raisons de latence et de réplication. La capacité est gérée en ajustant le nombre de nœuds dans chaque cluster. Table : organisation logique de valeurs indexée par clé de ligne. Les sauvegardes sont contrôlées au niveau de la table. |
Unité de capacité de lecture (RCU) et unité de capacité d'écriture (WCU)
: unités permettant d'effectuer des lectures ou des écritures par seconde avec une taille de charge utile fixe. Vous êtes facturé en unités de lecture ou d'écriture pour chaque opération avec des tailles de charge utile plus importantes.Les opérations UpdateItem consomment la capacité d'écriture utilisée pour la taille la plus grande d'un élément mis à jour (avant ou après la mise à jour), même si la mise à jour concerne un sous-ensemble des attributs de l'élément. |
Nœud : ressource de calcul virtuel chargée de lire et d'écrire des données. Le nombre de nœuds d'un cluster se traduit par des limites de débit pour les lectures, les écritures et les analyses. Vous pouvez ajuster le nombre de nœuds en fonction de la combinaison de vos objectifs de latence, du nombre de requêtes et de la taille de la charge utile. Les nœuds SSD offrent le même débit pour les lectures et les écritures, contrairement à la différence significative entre les unités de capacité de lecture et d'écriture. Pour en savoir plus, consultez Performances pour des charges de travail types. |
| Partition : bloc de lignes contiguës, soutenu par des disques SSD (Solid State Drives) colocalisés avec les nœuds. Chaque partition est soumise à une limite stricte de 1 000 UCW, 3 000 UCR et 10 Go de données. |
Tablette : bloc de lignes contiguës soutenu par le support de stockage de votre choix (SSD ou HDD). Les tables sont segmentées en tablets pour équilibrer la charge de travail. Les tablets ne sont pas stockés sur les nœuds dans Bigtable, mais plutôt sur le système de fichiers distribué de Google, qui permet une redistribution rapide des données lors de la mise à l'échelle et qui offre une durabilité supplémentaire en conservant plusieurs copies. |
| Tables mondiales : elles permettent d'améliorer la disponibilité et la durabilité de vos données en propageant automatiquement les modifications de données dans plusieurs régions. | Réplication : méthode permettant d'améliorer la disponibilité et la durabilité de vos données en propageant automatiquement les modifications apportées aux données dans plusieurs régions ou plusieurs zones d'une même région. |
| Non applicable (N/A) | Profil d'application : paramètres indiquant à Bigtable comment router un appel d'API cliente vers le cluster approprié dans l'instance. Vous pouvez également utiliser un profil d'application en tant que tag pour segmenter les métriques d'attribution. |
Réplication géographique
La réplication est utilisée pour répondre aux exigences des clients concernant les éléments suivants :
- Haute disponibilité pour la continuité de l'activité en cas de défaillance de zone ou régionale.
- Placer les données de votre service à proximité des utilisateurs finaux pour une diffusion à faible latence, où qu'ils se trouvent dans le monde.
- Isolation des charges de travail lorsque vous devez implémenter une charge de travail par lot sur un cluster et vous appuyer sur la réplication pour les clusters de diffusion.
Bigtable est compatible avec les clusters répliqués dans autant de zones que possible, dans un maximum de huit régions Google Cloud où Bigtable est disponible. La plupart des régions comportent trois zones. Pour en savoir plus, consultez Régions et zones.
Bigtable réplique automatiquement les données entre les clusters dans une topologie multimaître, ce qui signifie que vous pouvez lire et écrire dans n'importe quel cluster. La réplication de Bigtable est cohérente à terme. Pour en savoir plus, consultez Présentation de la réplication.
DynamoDB fournit des tables mondiales pour prendre en charge la réplication de tables dans plusieurs régions. Les tables globales sont multiprimaires et se répliquent automatiquement dans les régions. La réplication est cohérente à terme.
Le tableau suivant liste les concepts de réplication et décrit leur disponibilité dans DynamoDB et Bigtable.
| Propriété | DynamoDB | Bigtable |
|---|---|---|
| Réplication multiprimaire | Oui. Vous pouvez lire et écrire dans n'importe quelle table globale. |
Oui. Vous pouvez lire et écrire dans n'importe quel cluster Bigtable. |
| Modèle de cohérence | Cohérence à terme Cohérence écriture-lecture au niveau régional pour les tables globales. |
Cohérence à terme Cohérence écriture-lecture au niveau du cluster pour toutes les tables, à condition d'envoyer les lectures et les écritures au même cluster. |
| Latence de réplication | Aucun contrat de niveau de service (SLA) secondes |
Aucun contrat de niveau de service. secondes |
| Précision de la configuration | Au niveau de la table. | Au niveau de l'instance. Une instance peut contenir plusieurs tables. |
| Mise en œuvre | Créez une table globale avec une réplique de table dans chaque région sélectionnée. Niveau régional. Réplication automatique sur les réplicas en convertissant une table en table globale. Les tables doivent avoir DynamoDB Streams activé, avec le flux contenant les nouvelles et les anciennes images de l'élément. Supprimez une région pour supprimer le tableau global dans cette région. |
Créez une instance avec plusieurs clusters. La réplication est automatique entre les clusters de cette instance. Au niveau zonal. Ajoutez et supprimez des clusters d'une instance Bigtable. |
| Options de réplication | Par table. | Par instance. |
| Routage et disponibilité du trafic | Le trafic est acheminé vers le réplica géographique le plus proche. En cas d'échec, vous appliquez une logique métier personnalisée pour déterminer quand rediriger les requêtes vers d'autres régions. |
Utilisez des profils d'application pour configurer les règles de routage du trafic de cluster. Utilisez le routage multicluster pour acheminer automatiquement le trafic vers le cluster sain le plus proche. En cas d'échec, Bigtable permet le basculement automatique entre les clusters pour la haute disponibilité. |
| Mise à l'échelle | La capacité d'écriture en unités de requête d'écriture répliquées (R-WRU) est synchronisée entre les réplicas. La capacité de lecture en unités de capacité de lecture répliquées (R-RCU) est par réplica. |
Vous pouvez mettre à l'échelle les clusters de manière indépendante en ajoutant ou en supprimant des nœuds de chaque cluster répliqué selon les besoins. |
| Coût | Les UAR avec remise coûtent 50 % de plus que les UAR standards. | Vous êtes facturé pour les nœuds et le stockage de chaque cluster. Aucuns frais de réplication réseau ne s'appliquent pour la réplication régionale entre les zones. Des coûts sont générés lorsque la réplication s'effectue entre régions ou continents. |
| Contrat de niveau de service | 99,999 % | 99,999 % |
Plan de données
Le tableau suivant compare les concepts de modèle de données pour DynamoDB et Bigtable. Chaque ligne du tableau décrit des fonctionnalités analogues. Par exemple, un élément dans DynamoDB est semblable à une ligne dans Bigtable.
| DynamoDB | Bigtable |
|---|---|
| Élément : groupe d'attributs qui est identifiable de manière unique parmi tous les autres éléments par sa clé primaire. La taille maximale autorisée est de 400 Ko. | Ligne : une seule entité identifiée par la clé de ligne. La taille maximale autorisée est de 256 Mo. |
| N/A | Famille de colonnes : espace de noms spécifié par l'utilisateur qui regroupe les colonnes. |
| Attribut : regroupement d'un nom et d'une valeur. Une valeur d'attribut peut être de type scalaire, ensemble ou document. Il n'existe pas de limite explicite sur la taille des attributs eux-mêmes. Toutefois, comme chaque élément est limité à 400 Ko, pour un élément qui ne comporte qu'un seul attribut, celui-ci peut atteindre 400 Ko moins la taille occupée par le nom de l'attribut. | Qualificatif de colonne : identifiant unique d'une colonne au sein d'une famille de colonnes. L'identifiant complet d'une colonne est exprimé sous la forme famille-de-colonnes:qualificatif-de-colonne. Les qualificatifs de colonne sont triés par ordre lexicographique au sein de la famille de colonnes. La taille maximale autorisée pour un qualificatif de colonne est de 16 Ko. Cellule : une cellule contient les données d'une ligne, d'une colonne et d'un code temporel donnés. Une cellule contient une valeur qui peut atteindre 100 Mo. |
| Clé primaire : identifiant unique d'un élément dans un tableau. Il peut s'agir d'une clé de partition ou d'une clé composite. Clé de partitionnement : clé primaire simple, composée d'un attribut. Cela détermine la partition physique dans laquelle se trouve l'article. La taille maximale autorisée est de 2 Ko. Clé de tri : clé qui détermine l'ordre des lignes dans une partition. La taille maximale autorisée est de 1 ko. Clé composite : clé primaire composée de deux propriétés, la clé de partition et une clé de tri ou un attribut de plage. |
Clé de ligne : identifiant unique d'un élément dans un tableau.
Généralement représenté par une concaténation de valeurs et de délimiteurs.
La taille maximale autorisée est de 4 Ko. Les qualificatifs de colonne peuvent être utilisés pour fournir un comportement équivalent à celui de la clé de tri de DynamoDB. Les clés composites peuvent être créées à l'aide de clés de lignes et de qualificatifs de colonnes concaténés. Pour en savoir plus, consultez l'exemple de traduction de schéma dans la section "Conception du schéma" de ce document. |
| Durée de vie : les codes temporels par élément déterminent quand un élément n'est plus nécessaire. Après la date et l'heure de l'horodatage spécifié, l'élément est supprimé de votre tableau sans consommer de débit d'écriture. | Récupération de mémoire : les codes temporels par cellule déterminent quand un élément n'est plus nécessaire. La récupération de mémoire supprime les éléments expirés lors d'un processus en arrière-plan appelé "compactage". Les règles de récupération de mémoire sont définies au niveau de la famille de colonnes. Elles peuvent supprimer des éléments en fonction de leur ancienneté, mais aussi en fonction du nombre de versions que l'utilisateur souhaite conserver. Vous n'avez pas besoin de prévoir de la capacité pour la compaction lorsque vous dimensionnez vos clusters. |
| Index secondaire global : table contenant des attributs sélectionnés de la table de base, organisés par une clé primaire différente de celle de la table. La clé d'index n'a pas besoin d'inclure d'attributs clés de la table. Il n'a même pas besoin d'avoir le même schéma de clé que la table. | Index secondaire asynchrone : pour interroger les mêmes données à l'aide de différents attributs ou schémas de recherche, vous pouvez utiliser des vues matérialisées continues comme index secondaires asynchrones pour les tables. Pour en savoir plus, consultez Créer un index secondaire asynchrone. |
Opérations
Les opérations du plan de données vous permettent d'effectuer des actions de création, de lecture, de mise à jour et de suppression (CRUD) sur les données d'une table. Le tableau suivant compare les opérations de plan de données similaires pour DynamoDB et Bigtable.
| DynamoDB | Bigtable |
|---|---|
CreateTable |
CreateTable |
PutItemBatchWriteItem |
MutateRow MutateRowsBigtable traite les opérations d'écriture comme des opérations d'upsert. |
UpdateItem
|
Bigtable traite les opérations d'écriture comme des upserts. |
GetItemBatchGetItem, Query, Scan |
`ReadRow`` ReadRows` (range, prefix, reverse scan)Bigtable permet d'analyser efficacement les données par préfixe de clé de ligne, par modèle d'expression régulière ou par plage de clés de ligne (vers l'avant ou vers l'arrière). |
Types de données
Bigtable et DynamoDB sont tous deux sans schéma. Les colonnes peuvent être définies au moment de l'écriture sans aucune application à l'échelle de la table pour l'existence des colonnes ou les types de données. De même, le type de données d'une colonne ou d'un attribut donné peut varier d'une ligne ou d'un élément à l'autre. Toutefois, les API DynamoDB et Bigtable gèrent les types de données de différentes manières.
Chaque requête d'écriture DynamoDB inclut une définition de type pour chaque attribut, qui est renvoyée avec la réponse pour les requêtes de lecture.
Bigtable traite tout comme des octets et s'attend à ce que le code client connaisse le type et l'encodage afin que le client puisse analyser correctement les réponses. Les opérations increment font exception, car elles interprètent les valeurs comme des entiers signés de 64 bits en mode big-endian.
Le tableau suivant compare les différences entre les types de données de DynamoDB et Bigtable.
| DynamoDB | Bigtable |
|---|---|
| Types scalaires : renvoyés sous forme de jetons descripteurs de type de données dans la réponse du serveur. | Octets : les octets sont convertis dans les types prévus dans l'application cliente. Increment interprète la valeur comme un entier signé en mode big-endian de 64 bits. |
| Ensemble : collection non triée d'éléments uniques. | Famille de colonnes : vous pouvez utiliser des qualificatifs de colonne comme noms de membres de l'ensemble et, pour chacun d'eux, fournir un seul octet 0 comme valeur de cellule. Les membres de l'ensemble sont triés par ordre lexicographique au sein de leur famille de colonnes. |
| Map : collection non triée de paires clé/valeur avec des clés uniques. | Famille de colonnes Utilisez le qualificatif de colonne comme clé de mappage et la valeur de cellule pour la valeur. Les clés de mappage sont triées de manière lexicographique. |
| Liste : ensemble trié d'éléments. | Qualificateur de colonne Utilisez l'horodatage d'insertion pour obtenir un comportement équivalent à list_append, et l'inverse de l'horodatage d'insertion pour le préfixe. |
Conception de schémas
Un point important à prendre en compte dans la conception du schéma est la manière dont les données sont stockées. Voici quelques-unes des principales différences entre Bigtable et DynamoDB :
- Mises à jour de valeurs uniques
- Tri des données
- Gestion des versions de données
- Stockage de valeurs volumineuses
Mises à jour de valeurs uniques
Les opérations UpdateItem dans DynamoDB consomment la capacité d'écriture pour la plus grande des tailles d'élément "avant" et "après", même si la mise à jour implique un sous-ensemble des attributs de l'élément. Cela signifie que dans DynamoDB, vous pouvez placer les colonnes fréquemment mises à jour dans des lignes distinctes, même si, logiquement, elles appartiennent à la même ligne que d'autres colonnes.
Bigtable peut mettre à jour une cellule aussi efficacement, qu'il s'agisse de la seule colonne d'une ligne donnée ou de l'une des milliers de colonnes. Pour en savoir plus, consultez Écritures simples.
Tri des données
DynamoDB hache et distribue aléatoirement les clés de partition, tandis que Bigtable stocke les lignes dans l'ordre lexicographique par clé de ligne et laisse le hachage à la charge de l'utilisateur.
La distribution aléatoire des clés n'est pas optimale pour tous les modèles d'accès. Cela réduit le risque de plages de lignes actives, mais rend les modèles d'accès impliquant des analyses qui traversent les limites de partition coûteux et inefficaces. Ces analyses illimitées sont courantes, en particulier pour les cas d'utilisation qui comportent une dimension temporelle.
La gestion de ce type de modèle d'accès (analyses qui traversent les limites de partition) nécessite un index secondaire dans DynamoDB, mais pas dans Bigtable. Bien que vous puissiez concevoir la clé de ligne lexicographique dans Bigtable pour gérer efficacement de nombreux modèles d'analyse, Bigtable prend également en charge les index secondaires asynchrones que vous implémentez en tant que vues matérialisées continues pour fournir des recherches efficaces et cohérentes à terme pour d'autres modèles de requête. De même, dans DynamoDB, les opérations de requête et d'analyse sont limitées à 1 Mo de données analysées, ce qui nécessite une pagination au-delà de cette limite. Bigtable n'impose pas de limite de ce type.
Malgré ses clés de partition distribuées de manière aléatoire, DynamoDB peut toujours avoir des partitions actives si une clé de partition choisie ne distribue pas uniformément le trafic, ce qui nuit au débit. Pour résoudre ce problème, DynamoDB recommande le partitionnement d'écriture, qui consiste à répartir aléatoirement les écritures sur plusieurs valeurs de clé de partition logique.
Pour appliquer ce modèle de conception, vous devez créer un nombre aléatoire à partir d'un ensemble fixe (par exemple, de 1 à 10), puis utiliser ce nombre comme clé de partition logique. Comme vous randomisez la clé de partition, les écritures dans la table sont réparties de manière uniforme sur toutes les valeurs de clé de partition.
Bigtable appelle cette procédure salage de clé. Elle peut être un moyen efficace d'éviter les tablets actifs.
Gestion des versions de données
Chaque cellule Bigtable possède un code temporel, et le code temporel le plus récent est toujours la valeur par défaut pour une colonne donnée. Un cas d'utilisation courant des codes temporels est le versioning, qui consiste à écrire une nouvelle cellule dans une colonne qui se distingue des versions précédentes des données pour cette ligne et cette colonne par son code temporel.
DynamoDB ne dispose pas d'un tel concept et nécessite des conceptions de schéma complexes pour prendre en charge la gestion des versions. Cette approche consiste à créer deux copies de chaque élément : une copie avec un préfixe de numéro de version égal à zéro, tel que v0_, au début de la clé de tri, et une autre copie avec un préfixe de numéro de version égal à un, tel que v1_. Chaque fois que l'élément est mis à jour, vous utilisez le préfixe de version immédiatement supérieur dans la clé de tri de la version mise à jour, et vous copiez le contenu mis à jour dans l'élément avec le préfixe de version zéro. Cela permet de s'assurer que la dernière version de chaque élément peut être trouvée à l'aide du préfixe zéro. Cette stratégie nécessite non seulement une logique côté application pour la maintenance, mais elle rend également les écritures de données très coûteuses et lentes, car chaque écriture nécessite une lecture de la valeur précédente plus deux écritures.
Transactions multilignes et grande capacité de lignes
Bigtable n'est pas compatible avec les transactions multilignes. Toutefois, comme il vous permet de stocker des lignes beaucoup plus volumineuses que les éléments dans DynamoDB, vous pouvez souvent obtenir la transactionnalité souhaitée en concevant vos schémas de manière à regrouper les éléments pertinents sous une clé de ligne partagée. Pour obtenir un exemple illustrant cette approche, consultez Modèle de conception à table unique.
Stocker de grandes valeurs
Étant donné qu'un élément DynamoDB, qui est analogue à une ligne Bigtable, est limité à 400 Ko, le stockage de grandes valeurs nécessite de les fractionner sur plusieurs éléments ou de les stocker sur d'autres supports tels que S3. Ces deux approches ajoutent de la complexité à votre application. En revanche, une cellule Bigtable peut stocker jusqu'à 100 Mo et une ligne Bigtable peut prendre en charge jusqu'à 256 Mo.
Exemples de traduction de schémas
Les exemples de cette section traduisent les schémas de DynamoDB en schémas Bigtable en tenant compte des principales différences de conception des schémas de clés.
Migrer des schémas de base
Les catalogues de produits sont un bon exemple pour illustrer le modèle clé/valeur de base. Voici à quoi pourrait ressembler un tel schéma dans DynamoDB.
| Clé primaire | Attributs | |||
|---|---|---|---|---|
| Clé de partition | Clé de tri | Description | Prix | Thumbnail |
| chapeaux | fedoras#brandA | Conçue en laine de qualité… | 30 | https://storage… |
| chapeaux | fedoras#brandB | Toile résistante à l'eau et durable, conçue pour… | 28 | https://storage… |
| chapeaux | newsboy#brandB | Ajoutez une touche de charme vintage à votre look de tous les jours. | 25 | https://storage… |
| chaussures | sneakers#brandA | Sortez avec style et confort grâce à… | 40 | https://storage… |
| chaussures | sneakers#brandB | Des fonctionnalités classiques avec des matériaux contemporains… | 50 | https://storage… |
Pour cette table, le mappage de DynamoDB à Bigtable est simple : vous convertissez la clé primaire composite de DynamoDB en clé de ligne composite Bigtable. Vous créez une famille de colonnes (SKU) contenant le même ensemble de colonnes.
| SKU | |||
|---|---|---|---|
| Clé de ligne | Description | Prix | Thumbnail |
| hats#fedoras#brandA | Conçue en laine de qualité… | 30 | https://storage… |
| hats#fedoras#brandB | Toile résistante à l'eau et durable, conçue pour… | 28 | https://storage… |
| hats#newsboy#brandB | Ajoutez une touche de charme vintage à votre look de tous les jours. | 25 | https://storage… |
| shoes#sneakers#brandA | Sortez avec style et confort grâce à… | 40 | https://storage… |
| shoes#sneakers#brandB | Des fonctionnalités classiques avec des matériaux contemporains… | 50 | https://storage… |
Modèle de conception à table unique
Un modèle de conception à table unique rassemble ce qui serait plusieurs tables dans une base de données relationnelle en une seule table dans DynamoDB. Vous pouvez adopter l'approche de l'exemple précédent et dupliquer ce schéma tel quel dans Bigtable. Toutefois, il est préférable de résoudre les problèmes du schéma au cours du processus.
Dans ce schéma, la clé de partition contient l'ID unique d'une vidéo, ce qui permet de colocaliser tous les attributs associés à cette vidéo pour un accès plus rapide. Compte tenu des limites de taille des éléments de DynamoDB, vous ne pouvez pas placer un nombre illimité de commentaires en texte libre dans une même ligne. Par conséquent, une clé de tri avec le modèle VideoComment#reverse-timestamp est utilisée pour que chaque commentaire soit une ligne distincte dans la partition, triée par ordre chronologique inversé.
Imaginons que cette vidéo comporte 500 commentaires et que le propriétaire souhaite la supprimer. Cela signifie que tous les commentaires et attributs vidéo doivent également être supprimés. Pour ce faire dans DynamoDB, vous devez analyser toutes les clés de cette partition, puis envoyer plusieurs requêtes de suppression en les parcourant une par une. DynamoDB accepte les transactions multi-lignes, mais cette requête de suppression est trop volumineuse pour être effectuée en une seule transaction.
| Clé primaire | Attributs | |||
|---|---|---|---|---|
| Clé de partition | Clé de tri | UploadDate | Formats | |
| 0123 | Vidéo | 2023-09-10T15:21:48 | {"480": "https://storage…", "720": "https://storage…", "1080p": "https://storage…"} | |
| VideoComment#98765481 | Contenu | |||
| J'aime beaucoup. Les effets spéciaux sont incroyables. | ||||
| VideoComment#86751345 | Contenu | |||
| Il semble y avoir un problème audio à 1:05. | ||||
| VideoStatsLikes | Nombre | |||
| 3 | ||||
| VideoStatsViews | Nombre | |||
| 156 | ||||
| 0124 | Vidéo | 2023-09-10T17:03:21 | {"480": "https://storage…", "720": "https://storage…"} | |
| VideoComment#97531849 | Contenu | |||
| J'ai partagé ça avec tous mes amis. | ||||
| VideoComment#87616471 | Contenu | |||
| Ce style me rappelle un réalisateur de cinéma, mais je n'arrive pas à mettre le doigt dessus. | ||||
| VideoStats | ViewCount | |||
| 45 | ||||
Modifiez ce schéma lors de la migration pour simplifier votre code et rendre les demandes de données plus rapides et moins coûteuses. Les lignes Bigtable ont une capacité beaucoup plus importante que les éléments DynamoDB et peuvent gérer un grand nombre de commentaires. Pour gérer le cas où une vidéo reçoit des millions de commentaires, vous pouvez définir une stratégie de collecte des déchets afin de ne conserver qu'un nombre fixe des commentaires les plus récents.
Étant donné que les compteurs peuvent être mis à jour sans la surcharge liée à la mise à jour de l'intégralité de la ligne, vous n'avez pas non plus besoin de les fractionner. Vous n'avez pas non plus besoin d'utiliser une colonne UploadDate ni de calculer un code temporel inversé pour en faire votre clé de tri, car les codes temporels Bigtable vous donnent automatiquement les commentaires dans l'ordre chronologique inverse. Cela simplifie considérablement le schéma. Si une vidéo est supprimée, vous pouvez supprimer de manière transactionnelle la ligne de la vidéo, y compris tous les commentaires, en une seule requête.
Enfin, comme les colonnes de Bigtable sont triées par ordre lexicographique, vous pouvez, pour optimiser le processus, renommer les colonnes de manière à permettre une analyse rapide de la plage (des propriétés vidéo aux N commentaires les plus récents) en une seule requête de lecture, ce que vous devez faire lorsque la vidéo est chargée. Vous pouvez ensuite parcourir le reste des commentaires au fur et à mesure que le spectateur fait défiler la page.
| Attributs | ||||
|---|---|---|---|---|
| Clé de ligne | Formats | J'aime | Vues | UserComments |
| 0123 | {"480": "https://storage…", "720": "https://storage…", "1080p": "https://storage…"} @2023-09-10T15:21:48 | 3 | 156 | J'aime beaucoup. Les effets spéciaux sont incroyables. @
2023-09-10T19:01:15 Il semble y avoir un problème audio à 1:05. @ 2023-09-10T16:30:42 |
| 0124 | {"480": "https://storage…", "720":"https://storage…"} @2023-09-10T17:03:21 | 45 | Ce style me rappelle un réalisateur de cinéma, mais je n'arrive pas à mettre le doigt dessus. @2023-10-12T07:08:51 | |
Modèle de conception de liste d'adjacence
Envisagez une version légèrement différente de cette conception, que DynamoDB appelle souvent le modèle de conception de liste d'adjacence.
| Clé primaire | Attributs | |||
|---|---|---|---|---|
| Clé de partition | Clé de tri | DateCreated | Détails | |
| Invoice-0123 | Invoice-0123 | 2023-09-10T15:21:48 | {"discount": 0.10, "sales_tax_usd":"8", "due_date":"2023-10-03.."} |
|
| Payment-0680 | 2023-09-10T15:21:40 | {"amount_usd": 120, "bill_to":"John…", "address":"123 Abc St…"} |
||
| Payment-0789 | 2023-09-10T15:21:31 | {"amount_usd": 120, "bill_to":"Jane…", "address":"13 Xyz St…"} |
||
| Invoice-0124 | Invoice-0124 | 2023-09-09T10:11:28 | {"discount": 0.20, "sales_tax_usd":"11", "due_date":"2023-10-03.."} |
|
| Payment-0327 | 2023-09-09T10:11:10 | {"amount_usd": 180, "bill_to":"Bob…", "address":"321 Cba St…"} |
||
| Payment-0275 | 2023-09-09T10:11:03 | {"amount_usd": 70, "bill_to":"Kate…", "address":"21 Zyx St…"} |
||
Dans ce tableau, les clés de tri ne sont pas basées sur le temps, mais sur les ID de paiement. Vous pouvez donc utiliser un autre modèle de colonne large et faire de ces ID des colonnes distinctes dans Bigtable, avec des avantages similaires à l'exemple précédent.
| Facture | Paiement | |||
|---|---|---|---|---|
| clé de ligne | Détails | 0680 | 0789 | |
| 0123 | {"discount": 0.10, "sales_tax_usd":"8", "due_date":"2023-10-03.."} @ 2023-09-10T15:21:48 |
{"amount_usd": 120, "bill_to":"John…", "address":"123 Abc St…"} @ 2023-09-10T15:21:40 |
{"amount_usd": 120, "bill_to":"Jane…", "address":"13 Xyz St…"} @ 2023-09-10T15:21:31 |
|
| clé de ligne | Détails | 0275 | 0327 | |
| 0124 | {"discount": 0.20, "sales_tax_usd":"11", "due_date":"2023-10-03.."} @ 2023-09-09T10:11:28 |
{"amount_usd": 70, "bill_to":"Kate…", "address":"21 Zyx St…"} @ 2023-09-09T10:11:03 |
{"amount_usd": 180, "bill_to":"Bob…", "address":"321 Cba St…"} @ 2023-09-09T10:11:10 |
|
Comme vous pouvez le voir dans les exemples précédents, avec la bonne conception de schéma, le modèle à colonnes larges de Bigtable peut être très puissant et offrir de nombreux cas d'utilisation qui nécessiteraient des transactions multi-lignes coûteuses, un indexage secondaire ou un comportement en cascade lors de la suppression dans d'autres bases de données.
Étapes suivantes
- Découvrez la conception de schémas Bigtable.
- Découvrez l'émulateur Bigtable.
- Découvrez des architectures de référence, des schémas et des bonnes pratiques concernantGoogle Cloud. Consultez notre Cloud Architecture Center.