Migra de DynamoDB a Bigtable
Bigtable y DynamoDB son almacenes de clave-valor distribuidos que pueden admitir millones de consultas por segundo (QPS), proporcionar almacenamiento que se escala hasta petabytes de datos y tolerar fallas de nodos.
Este documento está dirigido a desarrolladores de DynamoDB y administradores de bases de datos que deseen migrar a Bigtable. También es útil cuando deseas diseñar aplicaciones para usar con Bigtable como almacén de datos.
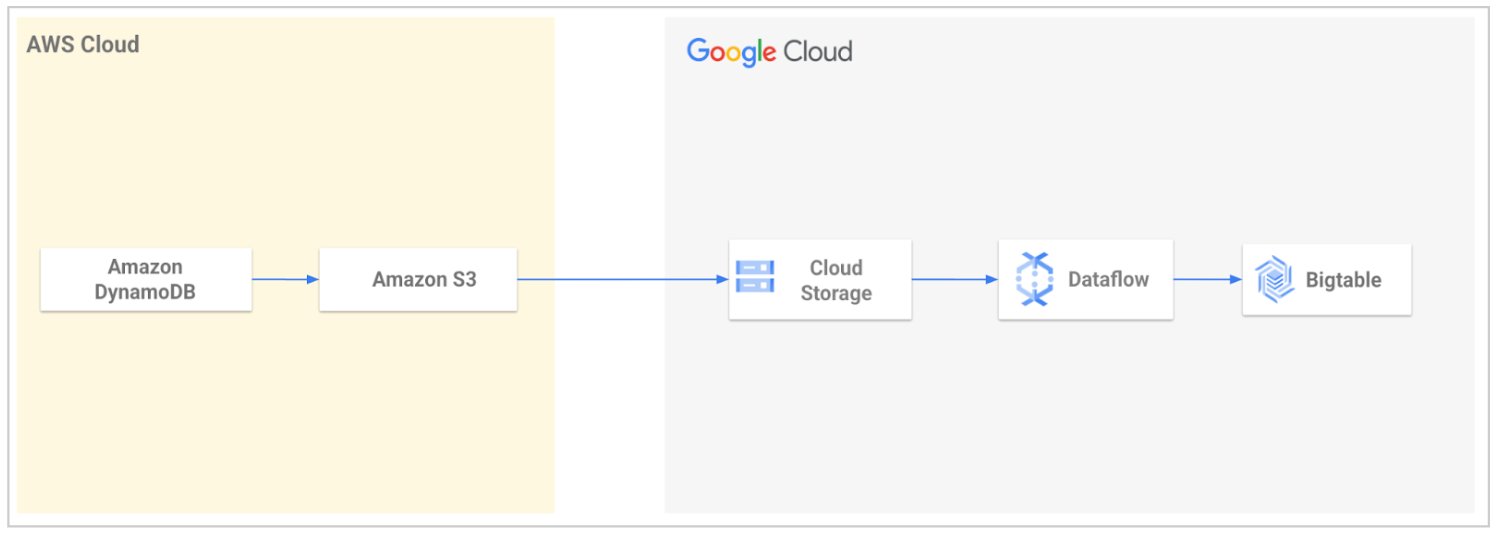
Para comenzar, usa una herramienta de migración proporcionada por Google que te ayude a migrar de DynamoDB a Bigtable. En esta página, se describe la herramienta de migración, se comparan los dos sistemas de bases de datos y se describen la arquitectura subyacente y los detalles de interacción que difieren y que es importante comprender antes de realizar la migración.
Comienza a usar la herramienta de migración de DynamoDB a Bigtable
Google Cloud Servicios Profesionales proporciona una herramienta de migración de código abierto para agilizar la migración de datos de DynamoDB a Bigtable. La herramienta automatiza el proceso de importar tus datos a Google Cloud y, luego, cargarlos en Bigtable.
Con la herramienta, exportas tu tabla de DynamoDB y, luego, la transfieres a Cloud Storage. La herramienta lee los archivos exportados de tu bucket de Cloud Storage y usa una plantilla de Dataflow para transformar los datos de modo que sean compatibles con Bigtable. Esta transformación incluye la asignación de atributos de DynamoDB a filas de Bigtable. Luego, el trabajo de Dataflow escribe los datos transformados en tu tabla de Bigtable.
Para obtener más información o comenzar a usar la herramienta, consulta Utilidad de migración de DynamoDB a Bigtable.
Comparación de DynamoDB y Bigtable
En esta sección, se analizan las similitudes y diferencias entre DynamoDB y Bigtable.
Plano de control
En DynamoDB y Bigtable, el plano de control te permite configurar tu capacidad, y administrar y configurar recursos. DynamoDB es un producto sin servidores, y el nivel más alto de interacción con DynamoDB es el nivel de la tabla. En el modo de capacidad aprovisionada, aquí es donde aprovisionas tus unidades de solicitud de lectura y escritura, seleccionas tus regiones y replicación, y administras las copias de seguridad. Bigtable no es un producto sin servidores. Debes crear una instancia con uno o más clústeres, cuya capacidad está determinada por la cantidad de nodos que tienen. Para obtener detalles sobre estos recursos, consulta Instancias, clústeres y nodos.
En la siguiente tabla, se comparan los recursos del plano de control para DynamoDB y Bigtable.
| DynamoDB | Bigtable |
|---|---|
| Tabla: Es una colección de elementos con una clave primaria definida. Las tablas tienen parámetros de configuración para copias de seguridad, replicación y capacidad. | Instancia: Es un grupo de clústeres de Bigtable en diferentes Google Cloud zonas o regiones, entre los que se producen la replicación y el enrutamiento de conexión. Las políticas de replicación se establecen a nivel de la instancia. Clúster: Es un grupo de nodos en la misma zona geográfica de Google Cloud Google Cloud, idealmente ubicado junto con el servidor de tu aplicación por motivos de latencia y replicación. La capacidad se administra ajustando la cantidad de nodos en cada clúster. Tabla: Es una organización lógica de valores que se indexa por clave de fila. Las copias de seguridad se controlan a nivel de la tabla. |
| Unidad de capacidad de lectura (RCU) y unidad de capacidad de escritura (WCU):
Unidades que permiten lecturas o escrituras por segundo con un tamaño de carga útil fijo. Se te cobran unidades de lectura o escritura por cada operación con tamaños de carga útil más grandes. Las operaciones UpdateItem consumen la capacidad de escritura que se usa para el tamaño más grande de un elemento actualizado, ya sea antes o después de la actualización, incluso si esta involucra un subconjunto de los atributos del elemento. |
Nodo: Es un recurso de procesamiento virtual responsable de leer y escribir datos. La cantidad de nodos que tiene un clúster se traduce en límites de capacidad de procesamiento para lecturas, escrituras y análisis. Puedes ajustar la cantidad de nodos según la combinación de tus objetivos de latencia, el recuento de solicitudes y el tamaño de la carga útil. Los nodos SSD ofrecen el mismo rendimiento para las lecturas y escrituras, a diferencia de la diferencia significativa entre las RCU y las WCU. Para obtener más información, consulta Rendimiento de cargas de trabajo típicas. |
| Partición: Es un bloque de filas contiguas, respaldado por unidades de estado sólido (SSD) ubicadas junto con los nodos. Cada partición está sujeta a un límite estricto de 1,000 WCUs, 3,000 RCUs y 10 GB de datos. |
Tabla: Es un bloque de filas contiguas respaldado por el medio de almacenamiento de elección (SSD o HDD). Las tablas se fragmentan en tablets para equilibrar la carga de trabajo. Los tablets no se almacenan en nodos de Bigtable, sino en el sistema de archivos distribuido de Google, lo que permite una redistribución rápida de los datos cuando se escala y proporciona durabilidad adicional, ya que mantiene varias copias. |
| Tablas globales: Una forma de aumentar la disponibilidad y durabilidad de tus datos propagando automáticamente los cambios de datos en varias regiones. | Replicación: Es una forma de aumentar la disponibilidad y la durabilidad de tus datos propagando automáticamente los cambios de datos en varias regiones o en varias zonas dentro de la misma región. |
| No aplicable (N/A) | Perfil de aplicación: Es la configuración que indica a Bigtable cómo enrutar una llamada a la API de cliente al clúster adecuado en la instancia. También puedes usar un perfil de la aplicación como etiqueta para segmentar las métricas de atribución. |
Replicación geográfica
La replicación se usa para satisfacer los requisitos de los clientes en los siguientes casos:
- Alta disponibilidad para la continuidad del negocio en caso de una falla zonal o regional
- Coloca los datos de tu servicio cerca de los usuarios finales para ofrecer un servicio con baja latencia dondequiera que estén en el mundo.
- Aislamiento de la carga de trabajo cuando necesitas implementar una carga de trabajo por lotes en un clúster y depender de la replicación en los clústeres de entrega
Bigtable admite clústeres replicados en tantas zonas como estén disponibles en hasta 8 Google Cloud regiones en las que Bigtable esté disponible. La mayoría de las regiones tienen tres zonas. Para obtener más información, consulta Regiones y zonas.
Bigtable replica automáticamente los datos en todos los clústeres en una topología multiclúster principal, lo que significa que puedes leer y escribir en cualquier clúster. La replicación de Bigtable tiene coherencia eventual. Para obtener más información, consulta la Descripción general de la replicación.
DynamoDB proporciona tablas globales para admitir la replicación de tablas en varias regiones. Las tablas globales son multilíderes y se replican automáticamente en todas las regiones. La replicación tiene coherencia eventual.
En la siguiente tabla, se enumeran los conceptos de replicación y se describe su disponibilidad en DynamoDB y Bigtable.
| Propiedad | DynamoDB | Bigtable |
|---|---|---|
| Replicación con varios elementos principales | Sí. Puedes leer y escribir en cualquier tabla global. |
Sí. Puedes leer y escribir en cualquier clúster de Bigtable. |
| Modelo de coherencia | Tiene coherencia eventual. Coherencia en la lectura de tus escrituras a nivel regional para las tablas globales. |
Tiene coherencia eventual. Coherencia en la lectura de tus escrituras a nivel del clúster para todas las tablas, siempre que envíes las lecturas y las escrituras al mismo clúster. |
| Latencia de replicación | No hay Acuerdo de Nivel de Servicio (ANS). Segundos |
Sin ANS. Segundos |
| Nivel de detalle de la configuración | Nivel de tabla. | Es a nivel de la instancia. Una instancia puede contener varias tablas. |
| Implementación | Crea una tabla global con una réplica de la tabla en cada región seleccionada. Nivel regional. Replicación automática en todas las réplicas convirtiendo una tabla en una tabla global. Las tablas deben tener habilitado DynamoDB Streams, con el flujo que contiene las imágenes nuevas y las anteriores del elemento. Borra una región para quitar la tabla global en esa región. |
Crea una instancia con más de un clúster. La replicación es automática en todos los clústeres de esa instancia. Es el nivel zonal. Agregar y quitar clústeres de una instancia de Bigtable |
| Opciones de replicación | Por tabla. | Por instancia. |
| Enrutamiento y disponibilidad del tráfico | El tráfico se enruta a la réplica geográfica más cercana. En caso de falla, aplicas lógica empresarial personalizada para determinar cuándo redireccionar las solicitudes a otras regiones. |
Usa perfiles de aplicación para configurar políticas de enrutamiento del tráfico del clúster. Usa el enrutamiento de varios clústeres para enrutar el tráfico automáticamente al clúster en buen estado más cercano. En caso de falla, Bigtable admite la conmutación por error automática entre clústeres para la alta disponibilidad. |
| Ajuste | La capacidad de escritura en unidades de solicitud de escritura replicadas (R-WRU) se sincroniza en todas las réplicas. La capacidad de lectura en unidades de capacidad de lectura replicadas (R-RCU) es por réplica. |
Puedes escalar los clústeres de forma independiente agregando o quitando nodos de cada clúster replicado según sea necesario. |
| Costo | Las RWU de retransmisión cuestan un 50% más que las WRU normales. | Se te factura por los nodos y el almacenamiento de cada clúster. No hay costos de replicación de red para la replicación regional en las zonas. Se incurren costos cuando la replicación se realiza entre regiones o continentes. |
| ANS | 99.999% | 99.999% |
Plano de datos
En la siguiente tabla, se comparan los conceptos del modelo de datos de DynamoDB y Bigtable. Cada fila de la tabla describe características análogas. Por ejemplo, un elemento en DynamoDB es similar a una fila en Bigtable.
| DynamoDB | Bigtable |
|---|---|
| Artículo: Es un grupo de atributos que se puede identificar de forma única entre todos los demás artículos por su clave primaria. El tamaño máximo permitido es de 400 KB. | Fila: Es una sola entidad identificada por la clave de fila. El tamaño máximo permitido es de 256 MB. |
| N/A | Familia de columnas: Es un espacio de nombres especificado por el usuario que agrupa columnas. |
| Atributo: Es una agrupación de un nombre y un valor. Un valor de atributo puede ser un tipo escalar, un conjunto o un documento. No hay un límite explícito en el tamaño del atributo en sí. Sin embargo, dado que cada elemento está limitado a 400 KB, en el caso de un elemento que solo tiene un atributo, este puede tener un tamaño de hasta 400 KB menos el tamaño que ocupa el nombre del atributo. | Calificador de columna: Es el identificador único dentro de una familia de columnas para una columna. El identificador completo de una columna se expresa como familia-de-columnas:calificador-de-columna. Los calificadores de columnas se ordenan lexicográficamente dentro de la familia de columnas. El tamaño máximo permitido para un calificador de columna es de 16 KB. Celda: Una celda contiene los datos de una fila, una columna y una marca de tiempo determinados. Una celda contiene un valor que puede tener hasta 100 MB. |
| Clave primaria: Es un identificador único para un elemento de una tabla. Puede ser una clave de partición o una clave compuesta. Clave de partición: Es una clave primaria simple, compuesta por un atributo. Determina la partición física en la que se encuentra el elemento. El tamaño máximo permitido es de 2 KB. Clave de ordenamiento: Es una clave que determina el orden de las filas dentro de una partición. El tamaño máximo permitido es de 1 KB. Clave compuesta: Es una clave primaria compuesta por dos propiedades: la clave de partición y una clave de ordenamiento o un atributo de rango. |
Clave de fila: Es un identificador único para un elemento en una tabla.
Por lo general, se representa con una concatenación de valores y delimitadores.
El tamaño máximo permitido es de 4 KB. Los calificadores de columnas se pueden usar para ofrecer un comportamiento equivalente al de la clave de ordenamiento de DynamoDB. Las claves compuestas se pueden crear con claves de fila y calificadores de columna concatenados. Para obtener más detalles, consulta el ejemplo de traducción de esquemas en la sección Diseño de esquemas de este documento. |
| Tiempo de actividad: Las marcas de tiempo por elemento determinan cuándo ya no se necesita un elemento. Después de la fecha y hora de la marca de tiempo especificada, el elemento se borra de la tabla sin consumir ninguna capacidad de procesamiento de escritura. | Recolección de elementos no utilizados: Las marcas de tiempo por celda determinan cuándo ya no se necesita un elemento. La recolección de elementos no utilizados borra los elementos vencidos durante un proceso en segundo plano llamado compactación. Las políticas de recolección de elementos no utilizados se establecen a nivel de la familia de columnas y pueden borrar elementos no solo según su antigüedad, sino también según la cantidad de versiones que el usuario desea conservar. No es necesario que tengas en cuenta la capacidad de compactación cuando determines el tamaño de tus clústeres. |
| Índice secundario global: Es una tabla que contiene atributos seleccionados de la tabla base, organizados por una clave primaria que es diferente de la de la tabla. La clave de índice no necesita incluir ninguno de los atributos clave de la tabla. Ni siquiera necesita tener el mismo esquema de clave que la tabla. | Índice secundario asíncrono: Para consultar los mismos datos con diferentes patrones o atributos de búsqueda, puedes usar vistas materializadas continuas como índices secundarios asíncronos para las tablas. Para obtener más información, consulta Crea un índice secundario asíncrono. |
Operaciones
Las operaciones del plano de datos te permiten realizar acciones de creación, lectura, actualización y eliminación (CRUD) en los datos de una tabla. En la siguiente tabla, se comparan operaciones similares del plano de datos para DynamoDB y Bigtable.
| DynamoDB | Bigtable |
|---|---|
CreateTable |
CreateTable |
PutItemBatchWriteItem |
MutateRow MutateRowsBigtable trata las operaciones de escritura como upserts. |
UpdateItem
|
Bigtable trata las operaciones de escritura como upserts. |
GetItemBatchGetItem, Query, Scan |
`ReadRow`` ReadRows` (rango, prefijo, exploración inversa)Bigtable admite la exploración eficiente por prefijo de clave de fila, patrón de expresión regular o rango de claves de fila hacia adelante o hacia atrás. |
Tipos de datos
Tanto Bigtable como DynamoDB no tienen esquemas. Las columnas se pueden definir en el momento de la escritura sin ninguna aplicación a nivel de la tabla para la existencia de columnas o los tipos de datos. Del mismo modo, un tipo de datos de columna o atributo determinado puede diferir de una fila o un elemento a otro. Sin embargo, las APIs de DynamoDB y Bigtable manejan los tipos de datos de diferentes maneras.
Cada solicitud de escritura de DynamoDB incluye una definición de tipo para cada atributo, que se devuelve con la respuesta para las solicitudes de lectura.
Bigtable trata todo como bytes y espera que el código del cliente conozca el tipo y la codificación para que el cliente pueda analizar las respuestas correctamente. Las operaciones de incremento son una excepción, ya que interpretan los valores como números enteros de 64 bits con signo big-endian.
En la siguiente tabla, se comparan las diferencias en los tipos de datos entre DynamoDB y Bigtable.
| DynamoDB | Bigtable |
|---|---|
| Tipos escalares: Se devuelven como tokens de descriptor de tipo de datos en la respuesta del servidor. | Bytes: Los bytes se transmiten a los tipos previstos en la aplicación cliente. Increment interpreta el valor como un número entero de 64 bits firmado como un valor big-endian. |
| Set: Es una colección sin ordenar de elementos únicos. | Familia de columnas: Puedes usar calificadores de columnas como nombres de miembros del conjunto y, para cada uno, proporcionar un solo byte 0 como valor de la celda. Los miembros del conjunto se ordenan lexicográficamente dentro de su familia de columnas. |
| Mapa: Es una colección no ordenada de pares clave-valor con claves únicas. | Familia de columnas Usa el calificador de columna como clave de mapa y el valor de la celda para el valor. Las claves del mapa se ordenan de manera lexicográfica. |
| Lista: Es una colección ordenada de elementos. | Calificador de columna Usa la marca de tiempo de inserción para lograr el equivalente del comportamiento de list_append, y la marca de tiempo de inserción inversa para prepend. |
Diseño de esquemas
Una consideración importante en el diseño del esquema es cómo se almacenan los datos. Entre las principales diferencias entre Bigtable y DynamoDB, se incluyen las siguientes:
- Actualizaciones de valores únicos
- Ordenación de datos
- Control de las versiones de los datos
- Almacenamiento de valores grandes
Actualizaciones de valores únicos
Las operaciones UpdateItem en DynamoDB consumen la capacidad de escritura para el mayor de los tamaños de elementos "antes" y "después", incluso si la actualización involucra un subconjunto de los atributos del elemento. Esto significa que, en DynamoDB, puedes colocar las columnas que se actualizan con frecuencia en filas separadas, incluso si, lógicamente, pertenecen a la misma fila con otras columnas.
Bigtable puede actualizar una celda con la misma eficiencia, ya sea que sea la única columna en una fila determinada o una entre miles. Para obtener más información, consulta Escrituras simples.
Ordenación de datos
DynamoDB genera un hash y distribuye de forma aleatoria las claves de partición, mientras que Bigtable almacena las filas en orden lexicográfico por clave de fila y deja cualquier generación de hash a cargo del usuario.
La distribución aleatoria de claves no es óptima para todos los patrones de acceso. Reduce el riesgo de rangos de filas activas, pero hace que los patrones de acceso que involucran análisis que cruzan los límites de las particiones sean costosos y poco eficientes. Estos análisis sin límites son comunes, en especial para los casos de uso que tienen una dimensión temporal.
El control de este tipo de patrón de acceso (análisis que cruzan los límites de las particiones) requiere un índice secundario en DynamoDB, pero no en Bigtable. Si bien puedes diseñar la clave de fila lexicográfica en Bigtable para controlar muchos patrones de análisis de manera eficiente, Bigtable también admite índices secundarios asíncronos que implementas como vistas materializadas continuas para proporcionar búsquedas eficientes y de coherencia eventual para patrones de consultas alternativos. Del mismo modo, en DynamoDB, las operaciones de consulta y análisis se limitan a 1 MB de datos analizados, lo que requiere paginación más allá de este límite. Bigtable no tiene ese límite.
A pesar de sus claves de partición distribuidas de forma aleatoria, DynamoDB puede tener particiones activas si una clave de partición elegida no distribuye el tráfico de manera uniforme, lo que afecta negativamente el rendimiento. Para abordar este problema, DynamoDB recomienda el fragmentado de escritura, que divide aleatoriamente las escrituras en varios valores de clave de partición lógica.
Para aplicar este patrón de diseño, debes crear un número aleatorio a partir de un conjunto fijo (por ejemplo, del 1 al 10) y, luego, usar este número como clave de partición lógica. Como aleatorizas la clave de partición, las escrituras en la tabla se distribuyen de manera uniforme en todos los valores de la clave de partición.
Bigtable se refiere a este procedimiento como salado de claves, y puede ser una forma eficaz de evitar las tablets activas.
Control de las versiones de los datos
Cada celda de Bigtable tiene una marca de tiempo, y la marca de tiempo más reciente siempre es el valor predeterminado para cualquier columna determinada. Un caso de uso común para las marcas de tiempo es el control de versiones, que consiste en escribir una celda nueva en una columna que se diferencia de las versiones anteriores de los datos para esa fila y columna por su marca de tiempo.
DynamoDB no tiene ese concepto y requiere diseños de esquemas complejos para admitir el control de versiones. Este enfoque implica crear dos copias de cada elemento: una copia con un prefijo de número de versión de cero, como v0_, al comienzo de la clave de ordenamiento, y otra copia con un prefijo de número de versión de uno, como v1_. Cada vez que se actualiza el elemento, se usa el siguiente prefijo de versión más alto en la clave de ordenamiento de la versión actualizada y se copia el contenido actualizado en el elemento con el prefijo de versión cero. Esto garantiza que la versión más reciente de cualquier elemento se pueda ubicar con el prefijo cero. Esta estrategia no solo requiere que se mantenga la lógica del lado de la aplicación, sino que también hace que las escrituras de datos sean muy costosas y lentas, ya que cada escritura requiere una lectura del valor anterior más dos escrituras.
Transacciones de varias filas en comparación con la capacidad de filas grandes
Bigtable no admite transacciones de varias filas. Sin embargo, como te permite almacenar filas mucho más grandes de lo que pueden ser los elementos en DynamoDB, a menudo puedes obtener la transaccionalidad deseada diseñando tus esquemas para agrupar los elementos pertinentes bajo una clave de fila compartida. Para ver un ejemplo que ilustra este enfoque, consulta Patrón de diseño de una sola tabla.
Cómo almacenar valores grandes
Dado que un elemento de DynamoDB, que es análogo a una fila de Bigtable, está limitado a 400 KB, almacenar valores grandes requiere dividir el valor en varios elementos o almacenarlo en otros medios, como S3. Ambos enfoques agregan complejidad a tu aplicación. En cambio, una celda de Bigtable puede almacenar hasta 100 MB, y una fila de Bigtable puede admitir hasta 256 MB.
Ejemplos de traducción de esquemas
En los ejemplos de esta sección, se traducen esquemas de DynamoDB a Bigtable teniendo en cuenta las diferencias de diseño del esquema de claves.
Migra esquemas básicos
Los catálogos de productos son un buen ejemplo para demostrar el patrón básico de clave-valor. A continuación, se muestra cómo podría verse un esquema de este tipo en DynamoDB.
| Clave primaria | Atributos | |||
|---|---|---|---|---|
| Clave de partición | Clave de ordenamiento | Descripción | Precio | Miniatura |
| sombreros | fedoras#brandA | Confeccionado con lana premium… | 30 | https://storage… |
| sombreros | fedoras#brandB | Lona duradera y resistente al agua diseñada para… | 28 | https://storage… |
| sombreros | newsboy#brandB | Agrega un toque de encanto vintage a tu estilo diario. | 25 | https://storage… |
| zapatos | sneakers#brandA | Sal con estilo y comodidad con… | 40 | https://storage… |
| zapatos | sneakers#brandB | Características clásicas con materiales contemporáneos… | 50 | https://storage… |
Para esta tabla, la asignación de DynamoDB a Bigtable es sencilla: conviertes la clave primaria compuesta de DynamoDB en una clave de fila compuesta de Bigtable. Creas una familia de columnas (SKU) que contiene el mismo conjunto de columnas.
| SKU | |||
|---|---|---|---|
| Clave de fila | Descripción | Precio | Miniatura |
| hats#fedoras#brandA | Confeccionado con lana premium… | 30 | https://storage… |
| hats#fedoras#brandB | Lona duradera y resistente al agua diseñada para… | 28 | https://storage… |
| hats#newsboy#brandB | Agrega un toque de encanto vintage a tu estilo diario. | 25 | https://storage… |
| zapatos#zapatillas#marcaA | Sal con estilo y comodidad con… | 40 | https://storage… |
| zapatos#zapatillas#marcaB | Características clásicas con materiales contemporáneos… | 50 | https://storage… |
Patrón de diseño de una sola tabla
Un patrón de diseño de una sola tabla reúne lo que serían varias tablas en una base de datos relacional en una sola tabla en DynamoDB. Puedes adoptar el enfoque del ejemplo anterior y duplicar este esquema tal como está en Bigtable. Sin embargo, es mejor abordar los problemas del esquema durante el proceso.
En este esquema, la clave de partición contiene el ID único de un video, lo que ayuda a ubicar todos los atributos relacionados con ese video para un acceso más rápido. Dadas las limitaciones de tamaño de los elementos de DynamoDB, no puedes incluir una cantidad ilimitada de comentarios de texto libre en una sola fila. Por lo tanto, se usa una clave de ordenamiento con el patrón VideoComment#reverse-timestamp para que cada comentario sea una fila independiente dentro de la partición, ordenado en orden cronológico inverso.
Supongamos que este video tiene 500 comentarios y el propietario quiere quitarlo. Esto significa que también se deben borrar todos los comentarios y atributos del video. Para hacerlo en DynamoDB, debes analizar todas las claves dentro de esta partición y, luego, enviar varias solicitudes de eliminación, iterando a través de cada una. DynamoDB admite transacciones de varias filas, pero esta solicitud de eliminación es demasiado grande para realizarla en una sola transacción.
| Clave primaria | Atributos | |||
|---|---|---|---|---|
| Clave de partición | Clave de ordenamiento | UploadDate | Formatos | |
| 0123 | Video | 2023-09-10T15:21:48 | {"480": "https://storage…", "720": "https://storage…", "1080p": "https://storage…"} | |
| VideoComment#98765481 | Contenido | |||
| Me gusta mucho. Los efectos especiales son increíbles. | ||||
| VideoComment#86751345 | Contenido | |||
| Parece que hay una falla de audio en el minuto 1:05. | ||||
| VideoStatsLikes | Recuento | |||
| 3 | ||||
| VideoStatsViews | Recuento | |||
| 156 | ||||
| 0124 | Video | 2023-09-10T17:03:21 | {"480": "https://storage…", "720": "https://storage…"} | |
| VideoComment#97531849 | Contenido | |||
| Compartí esto con todos mis amigos. | ||||
| VideoComment#87616471 | Contenido | |||
| El estilo me recuerda a un director de cine, pero no puedo identificarlo. | ||||
| VideoStats | ViewCount | |||
| 45 | ||||
Modifica este esquema a medida que migras para que puedas simplificar tu código y hacer que las solicitudes de datos sean más rápidas y económicas. Las filas de Bigtable tienen una capacidad mucho mayor que los elementos de DynamoDB y pueden controlar una gran cantidad de comentarios. Para controlar un caso en el que un video recibe millones de comentarios, puedes establecer una política de recolección de basura para conservar solo una cantidad fija de los comentarios más recientes.
Como los contadores se pueden actualizar sin la sobrecarga de actualizar toda la fila, tampoco es necesario dividirlos. Tampoco tienes que usar una columna UploadDate ni calcular una marca de tiempo inversa y convertirla en tu clave de ordenamiento, ya que las marcas de tiempo de Bigtable te brindan automáticamente los comentarios ordenados de forma cronológica inversa. Esto simplifica significativamente el esquema y, si se quita un video, puedes quitar de forma transaccional la fila del video, incluidos todos los comentarios, en una sola solicitud.
Por último, debido a que las columnas de Bigtable se ordenan lexicográficamente, como optimización, puedes cambiarles el nombre de manera que permitan un análisis de rango rápido (desde las propiedades del video hasta los N comentarios más recientes) en una sola solicitud de lectura, que es lo que querrías hacer cuando se carga el video. Luego, puedes paginar el resto de los comentarios a medida que el usuario se desplaza.
| Atributos | ||||
|---|---|---|---|---|
| Clave de fila | Formatos | Me gusta | Vistas | UserComments |
| 0123 | {"480": "https://storage…", "720": "https://storage…", "1080p": "https://storage…"} @2023-09-10T15:21:48 | 3 | 156 | Me gusta mucho. Los efectos especiales son increíbles. @
2023-09-10T19:01:15 Parece que hay un error de audio en 1:05. @ 2023-09-10T16:30:42 |
| 0124 | {"480": "https://storage…", "720":"https://storage…"} @2023-09-10T17:03:21 | 45 | El estilo me recuerda a un director de cine, pero no puedo identificarlo. @2023-10-12T07:08:51 | |
Patrón de diseño de lista de adyacencia
Considera una versión ligeramente diferente de este diseño, al que DynamoDB suele referirse como el patrón de diseño de lista de adyacencia.
| Clave primaria | Atributos | |||
|---|---|---|---|---|
| Clave de partición | Clave de ordenamiento | DateCreated | Detalles | |
| Invoice-0123 | Invoice-0123 | 2023-09-10T15:21:48 | {"discount": 0.10, "sales_tax_usd":"8", "due_date":"2023-10-03.."} |
|
| Payment-0680 | 2023-09-10T15:21:40 | {"amount_usd": 120, "bill_to":"John…", "address":"123 Abc St…"} |
||
| Payment-0789 | 2023-09-10T15:21:31 | {"amount_usd": 120, "bill_to":"Jane…", "address":"13 Xyz St…"} |
||
| Invoice-0124 | Invoice-0124 | 2023-09-09T10:11:28 | {"discount": 0.20, "sales_tax_usd":"11", "due_date":"2023-10-03.."} |
|
| Payment-0327 | 2023-09-09T10:11:10 | {"amount_usd": 180, "bill_to":"Bob…", "address":"321 Cba St…"} |
||
| Payment-0275 | 2023-09-09T10:11:03 | {"amount_usd": 70, "bill_to":"Kate…", "address":"21 Zyx St…"} |
||
En esta tabla, las claves de ordenamiento no se basan en el tiempo, sino en los IDs de pago, por lo que puedes usar un patrón de columna ancha diferente y hacer que esos IDs sean columnas separadas en Bigtable, con beneficios similares al ejemplo anterior.
| Factura | Pago | |||
|---|---|---|---|---|
| clave de fila | Detalles | 0680 | 0789 | |
| 0123 | {"discount": 0.10, "sales_tax_usd":"8", "due_date":"2023-10-03.."} @ 2023-09-10T15:21:48 |
{"amount_usd": 120, "bill_to":"John…", "address":"123 Abc St…"} @ 2023-09-10T15:21:40 |
{"amount_usd": 120, "bill_to":"Jane…", "address":"13 Xyz St…"} @ 2023-09-10T15:21:31 |
|
| clave de fila | Detalles | 0275 | 0327 | |
| 0124 | {"discount": 0.20, "sales_tax_usd":"11", "due_date":"2023-10-03.."} @ 2023-09-09T10:11:28 |
{"amount_usd": 70, "bill_to":"Kate…", "address":"21 Zyx St…"} @ 2023-09-09T10:11:03 |
{"amount_usd": 180, "bill_to":"Bob…", "address":"321 Cba St…"} @ 2023-09-09T10:11:10 |
|
Como puedes ver en los ejemplos anteriores, con el diseño de esquema adecuado, el modelo de columnas amplias de Bigtable puede ser muy potente y ofrecer muchos casos de uso que requerirían transacciones costosas de varias filas, indexación secundaria o comportamiento en cascada de eliminación en otras bases de datos.
¿Qué sigue?
- Lee sobre el diseño del esquema de Bigtable.
- Obtén más información sobre el emulador de Bigtable.
- Explora arquitecturas de referencia, diagramas y prácticas recomendadas sobreGoogle Cloud. Consulta nuestro Cloud Architecture Center.