Ce document est destiné aux développeurs de logiciels et aux administrateurs de bases de données qui souhaitent migrer des applications existantes ou concevoir de nouvelles applications à utiliser avec Bigtable en tant que datastore. Ce document met à profit vos connaissances d'Apache Cassandra pour l'utilisation de Bigtable afin de décrire les concepts que vous devez comprendre avant la migration. Pour en savoir plus sur les outils Open Source que vous pouvez utiliser pour effectuer votre migration, consultez Migrer de Cassandra vers Bigtable.
Bigtable et Cassandra sont des bases de données distribuées. Elles mettent en œuvre des magasins de paires clé-valeur multidimensionnels capables de prendre en charge des dizaines de milliers de requêtes par seconde (RPS), un espace de stockage avec scaling à la hausse jusqu'à plusieurs pétaoctets de données, ainsi qu'une tolérance aux défaillances de nœud.
Quand Bigtable est-il une bonne destination pour les charges de travail Cassandra ?
Le meilleur service Google Cloud pour votre charge de travail Cassandra dépend de vos objectifs de migration et des fonctionnalités Cassandra dont vous avez besoin après la migration.
Bigtable est optimal si une ou plusieurs des conditions suivantes s'appliquent :
- Vous souhaitez bénéficier d'un service entièrement géré, sans intervalle de maintenance et à haute disponibilité.
- Vous avez besoin d'un scaling élastique qui réponde automatiquement aux variations du trafic serveur.
- Vous utilisez des types de collections, des compteurs ou des vues matérialisées Cassandra en plus des types scalaires.
- Vous disposez d'une application qui utilise le paramètre
USING TIMESTAMP. - Votre débit et votre latence d'écriture sont tout aussi importants que les lectures.
- Vous vous appuyez sur l'un des modèles de réplication cohérents à terme de Cassandra.
- Votre cas d'utilisation nécessite un stockage économique.
Pour migrer des applications sans modifier le code, vous pouvez choisir d'autogérer Cassandra sur GKE ou d'utiliser un partenaire Google Cloudtel que DataStax ou ScyllaDB. Si votre application est lourde en lecture et que vous êtes prêt à refactoriser votre code pour obtenir des fonctionnalités de base de données relationnelle et une cohérence forte, vous pouvez envisager d'utiliser Spanner.
Ce document fournit des conseils sur les éléments à prendre en compte lors de la refactorisation de votre application, si vous choisissez Bigtable comme cible de migration pour vos charges de travail Cassandra.
Comment utiliser ce document
Vous n'avez pas besoin de lire ce document du début à la fin. Bien que ce document compare les deux bases de données, vous pouvez également vous concentrer sur les sujets qui s'appliquent à votre cas d'utilisation ou à vos centres d'intérêt.
Pour vous aider à comparer Bigtable et Cassandra, ce document effectue les opérations suivantes :
- Compare la terminologie, qui peut différer entre les deux bases de données.
- Présente une vue d'ensemble des deux systèmes de base de données.
- Examine la manière dont chaque base de données gère la modélisation des données afin de comprendre les différentes considérations en termes de conception.
- Compare le chemin emprunté par les données lors des écritures et des lectures.
- Examine la disposition des données physiques pour comprendre certains aspects de l'architecture de base de données.
- Explique comment configurer la réplication géographique pour répondre à vos besoins et comment aborder le dimensionnement du cluster.
- Examine les différents détails sur la gestion, la surveillance et la sécurité des clusters.
Comparaison terminologique
Bien que de nombreux concepts utilisés dans Bigtable et Cassandra soient similaires, chaque base de données présente des conventions de dénomination légèrement différentes et d'autres différences subtiles.
L'un des composants principaux des deux bases de données est la table des chaînes triées (SSTable). Dans les deux architectures, les SSTables sont créées pour conserver les données utilisées pour répondre aux requêtes de lecture.
Dans un article de blog (2012), Ilya Grigorik écrit la phrase suivante : "Une SSTable est une abstraction simple permettant de stocker efficacement un grand nombre de paires clé/valeur tout en optimisant les charges de travail de lecture ou d'écriture séquentielles à haut débit".
Le tableau suivant décrit les concepts partagés et la terminologie correspondante utilisée par chaque produit :
| Cassandra | Bigtable |
|---|---|
|
clé primaire : valeur unique ou multi-champs qui détermine l'emplacement et l'ordre des données. clé de partitionnement : valeur unique ou multi-champs qui détermine l'emplacement des données par hachage cohérent. Colonne de clustering : valeur unique ou multi-champs qui détermine le tri des données lexicographiques dans une partition. |
clé de ligne : chaîne d'octets unique qui détermine l'emplacement des données par un tri lexicographique. Les clés composites sont imitées en joignant les données de plusieurs colonnes à l'aide d'un délimiteur commun, par exemple les symboles de hachage (#) ou de pourcentage (%). |
| nœud : machine chargée de la lecture et de l'écriture des données associées à une série de plages de hachage de partition de clé primaire. Dans Cassandra, les données sont stockées dans un stockage au niveau du bloc associé au serveur de nœuds. | nœud : ressource de calcul virtuel chargée de lire et d'écrire des données associées à une série de plages de clés de ligne. Dans Bigtable, les données ne sont pas colocalisées avec les nœuds de calcul. Les données sont stockées dans Colossus, le système de fichiers distribué de Google. Les nœuds sont temporairement responsables de la diffusion de différentes plages de données en fonction de la charge de l'opération et de l'état des autres nœuds du cluster. |
|
Centre de données : semblable à un cluster Bigtable, sauf que certains aspects de la topologie et de la stratégie de réplication sont configurables dans Cassandra. rack : regroupement de nœuds dans un centre de données qui influence l'emplacement des instances dupliquées. |
cluster : groupe de nœuds dans la même zone géographiqueGoogle Cloud , colocalisés pour des questions de latence et de réplication. |
| cluster : déploiement Cassandra composé d'un ensemble de centres de données. | instance : groupe de clusters Bigtable dans différentes zones ou régions Google Cloud entre lesquelles la réplication et le routage de connexion se produisent. |
| vnode : plage fixe de valeurs de hachage attribuées à un nœud physique spécifique. Les données d'un vnode sont stockées physiquement sur le nœud Cassandra dans une série de SSTables. | tablet : SSTable contenant toutes les données d'une plage contiguë de clés de lignes triées de façon lexicographique. Les tablets ne sont pas stockés sur les nœuds dans Bigtable, mais sont stockés dans une série de SSTables sur Colossus. |
| facteur de réplication : nombre d'instances dupliquées d'un vnode qui sont conservées dans tous les nœuds du centre de données. Le facteur de réplication est configuré indépendamment pour chaque centre de données. | réplication : processus de réplication des données stockées dans Bigtable vers tous les clusters de l'instance. La réplication dans un cluster zonal est gérée par la couche de stockage Colossus. |
| table (anciennement famille de colonnes) : organisation logique de valeurs indexée par la clé primaire unique. | table : organisation logique de valeurs indexée par la clé de ligne unique. |
| espace de clés : espace de noms de table logique qui définit le facteur de réplication des tables qu'il contient. | Non applicable. Bigtable gère les problèmes d'espace de clés de manière transparente. |
| map : type de collection Cassandra contenant des paires clé/valeur. | famille de colonnes : espace de noms spécifié par l'utilisateur qui regroupe les qualificatifs de colonne afin de rendre les opérations de lecture et d'écriture plus efficaces. Lorsque vous interrogez Bigtable à l'aide de SQL, les familles de colonnes sont traitées comme des cartes Cassandra. |
| map key : clé qui identifie de manière unique une entrée clé-valeur dans une carte Cassandra. | qualificatif de colonne : libellé d'une valeur stockée dans une table indexée par la clé de ligne unique. Lorsque vous interrogez Bigtable à l'aide de SQL, les colonnes sont traitées comme des clés d'une carte. |
| colonne : libellé d'une valeur stockée dans une table indexée par la clé primaire unique. | colonne : libellé d'une valeur stockée dans une table indexée par la clé de ligne unique. Le nom de la colonne est construit en combinant la famille de colonnes avec le qualificatif de colonne. |
| cellule : valeur d'horodatage dans une table associée à l'intersection d'une clé primaire avec la colonne. | cellule : valeur d'horodatage dans une table associée à l'intersection d'une clé de ligne avec le nom de la colonne. Plusieurs versions horodatées peuvent être stockées et récupérées pour chaque cellule. |
| counter : type de champ incrémentable optimisé pour les opérations de somme d'entiers. | Compteurs : cellules qui utilisent des types de données spécialisés pour les opérations de somme d'entiers. Pour en savoir plus, consultez Créer et mettre à jour des compteurs. |
| règle d'équilibrage de charge : une règle que vous configurez dans la logique de l'application pour router les opérations vers un nœud approprié dans le cluster. La règle prend en compte la topologie du centre de données et les plages de jetons vnode. | profil d'application : paramètres indiquant à Bigtable comment router un appel d'API cliente vers le cluster approprié dans l'instance. Vous pouvez également utiliser le profil d'application en tant que tag pour segmenter les métriques. Vous configurez le profil d'application dans le service. |
| CQL : langage de requête Cassandra, un langage tel que SQL utilisé pour la création de tables, les modifications de schéma, les mutations de ligne et les requêtes. | Le client Cassandra vers Bigtable pour Java remplace facilement vos pilotes Cassandra. Le client Java comprend vos requêtes CQL et vous permet d'utiliser Bigtable de manière transparente avec votre application existante basée sur Cassandra, sans avoir à réécrire de code. L'adaptateur de proxy Cassandra vers Bigtable est une couche autonome que vous pouvez exécuter en parallèle de votre application et connecter à Bigtable en tant que nœud Cassandra. L'adaptateur de proxy assure la compatibilité avec CQL et prend en charge les migrations à double écriture et groupées. Cette fonctionnalité est semblable à celle proposée par le client Cassandra vers Bigtable pour Java. Les API Bigtable sont les bibliothèques clientes et les API gRPC utilisées pour la création d'instances et de clusters, la création de tables et de familles de colonnes, les mutations de lignes et l'exécution de requêtes. L'API SQL de Bigtable est familière aux utilisateurs de CQL. |
Vue matérialisée : instruction SELECT qui définit un ensemble de lignes correspondant à des lignes d'une table source sous-jacente. Lorsque la table source change, Cassandra met automatiquement à jour la vue matérialisée.
|
Vue matérialisée continue : résultat précalculé et entièrement géré d'une requête SQL, qui est mis à jour de manière incrémentielle et automatique à partir d'une table source. Pour en savoir plus, consultez Vues matérialisées continues. |
Présentations des produits
Les sections suivantes présentent la philosophie de conception et les attributs clés de Bigtable et Cassandra.
Bigtable
Bigtable fournit de nombreuses fonctionnalités principales décrites dans l'article Bigtable : Un système de stockage distribué pour les données structurées. Bigtable sépare les nœuds de calcul, desservant les requêtes des clients, de la gestion de stockage sous-jacente. Les données sont stockées sur Colossus. La couche de stockage réplique automatiquement les données afin de fournir une durabilité qui dépasse les niveaux fournis par la réplication à trois voies HDFS (Hadoop Distributed File System) standard.
Cette architecture fournit des opérations de lecture et d'écriture cohérentes au sein d'un cluster et permet d'effectuer un scaling à la hausse ou à la baisse sans frais de redistribution du stockage, et de rééquilibrer les charges de travail sans modifier le cluster ou le schéma. Si un nœud de traitement de données est altéré, le service Bigtable le remplace de manière transparente. Bigtable est également compatible avec la réplication asynchrone.
En plus de gRPC et des bibliothèques clientes pour divers langages de programmation, Bigtable conserve la compatibilité avec la bibliothèque cliente Java Open Source Apache HBase, une mise en œuvre alternative du moteur de base de données Open Source de l'article sur Bigtable.
Le schéma suivant montre comment Bigtable sépare physiquement les nœuds de traitement de la couche de stockage :
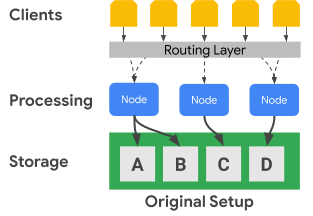
Dans le schéma précédent, le nœud de traitement du milieu n'est responsable que de la diffusion des requêtes de données pour l'ensemble de données C dans la couche de stockage. Si Bigtable détecte qu'un rééquilibrage d'attribution de plage est requis pour un ensemble de données, les plages de données d'un nœud de traitement sont faciles à modifier, car la couche de stockage est séparée de la couche de traitement.
Le schéma suivant illustre, en termes simplifiées, un rééquilibrage de la plage de clés et un redimensionnement de cluster :
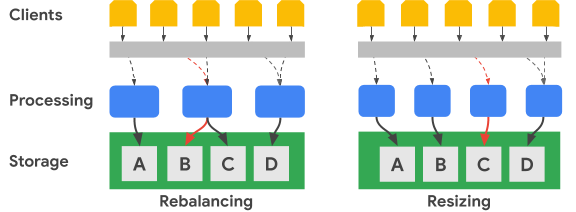
L'image Rééquilibrage illustre l'état du cluster Bigtable après réception d'un nombre accru de requêtes pour l'ensemble de données A par le nœud de traitement le plus à gauche. Une fois le rééquilibrage effectué, le nœud du milieu, au lieu du nœud le plus à gauche, est responsable de la diffusion des requêtes de données pour l'ensemble de données B. Le nœud le plus à gauche continue de traiter les requêtes pour l'ensemble de données A.
Bigtable peut réorganiser les plages de clés de ligne afin d'équilibrer les plages d'ensembles de données sur un plus grand nombre de nœuds de traitement disponibles. L'image Redimensionner affiche l'état du cluster Bigtable après l'ajout d'un nœud.
Cassandra
Apache Cassandra est une base de données Open Source partiellement influencée par les concepts de l'article sur Bigtable. Elle utilise une architecture de nœuds distribuée, où le stockage est colocalisé avec les serveurs qui répondent aux opérations de données. Une série de nœuds virtuels (vnodes) est attribuée de manière aléatoire à chaque serveur pour desservir une partie de l'espace de clés du cluster.
Les données sont stockées dans les nœuds vnode en fonction de la clé de partition. En règle générale, une fonction de hachage cohérente est utilisée pour générer un jeton permettant de déterminer l'emplacement des données. Comme avec Bigtable, vous pouvez utiliser un partitionnement préservant l'ordre pour la génération de jetons, ainsi que pour l'emplacement des données. Toutefois, la documentation Cassandra déconseille cette approche, car le cluster risque de devenir déséquilibré, une condition difficile à résoudre. Pour cette raison, ce document suppose que vous utilisez une stratégie de hachage cohérente pour générer des jetons qui entraînent une distribution des données entre les nœuds.
Cassandra assure une tolérance aux pannes à l'aide des niveaux de disponibilité, qui sont corrélés au niveau de cohérence ajustable, ce qui permet à un cluster de desservir des clients alors qu'un ou plusieurs nœuds sont altérés. Vous définissez la réplication géographique via une stratégie de topologie de réplication de données configurable.
Vous spécifiez un niveau de cohérence pour chaque opération. Le paramètre type est QUORUM (ou LOCAL_QUORUM dans certaines topologies de centres de données multiples). Pour que l'opération soit considérée comme réussie, ce paramètre de niveau de cohérence nécessite qu'une majorité de nœuds d'instance dupliquée réponde au nœud coordinateur. Le facteur de réplication, que vous configurez pour chaque espace de clés, détermine le nombre d'instances dupliquées de données stockées dans chaque centre de données du cluster. Par exemple, il est courant d'utiliser une valeur de facteur de réplication de 3 pour fournir un équilibre pratique entre durabilité et volume de stockage.
Le schéma suivant illustre en termes simplifiés un cluster de six nœuds avec une plage de clés de chaque nœud divisée en cinq vnodes. En pratique, vous pouvez avoir plus de nœuds, et vous aurez probablement davantage de vnodes.

Dans le schéma précédent, vous pouvez observer le chemin d'une opération d'écriture, avec un niveau de cohérence de QUORUM, provenant d'une application ou d'un service client (Client). Pour les besoins de ce schéma, les plages de clés sont affichées sous forme de plages alphabétiques. En réalité, les jetons générés par un hachage de la clé primaire sont de très grands entiers signés.
Dans cet exemple, le hachage de clé est M et les vnodes pour M se trouvent sur les nœuds 2, 4 et 6. Le coordinateur doit contacter chaque nœud sur lequel les plages de hachage de clé sont stockées localement pour que l'écriture puisse être traitée. Comme le niveau de cohérence est QUORUM, deux instances dupliquées (une majorité) doivent répondre au nœud de coordinateur avant que le client ne soit informé que l'écriture est terminée.
Contrairement à Bigtable, déplacer ou modifier des plages de clés dans Cassandra nécessite de copier physiquement les données d'un nœud à un autre. Si un nœud est surchargé avec des requêtes pour une plage de hachage de jeton donnée, l'ajout d'un traitement pour cette plage de jetons est plus complexe dans Cassandra que dans Bigtable.
Réplication et cohérence géographique
Bigtable et Cassandra gèrent différemment la réplication et la cohérence géographique (également appelée multirégionale). Un cluster Cassandra se compose de nœuds de traitement regroupés en racks, et les racks sont regroupés en centres de données. Cassandra utilise une stratégie de topologie de réseau que vous configurez pour déterminer la manière dont les instances dupliquées de vnodes sont distribuées entre les hôtes d'un centre de données. Cette stratégie révèle les racines de Cassandra comme une base de données initialement déployée sur des centres de données sur site physiques. Cette configuration spécifie également le facteur de réplication pour chaque centre de données du cluster.
Cassandra utilise les configurations de centre de données et de rack pour améliorer la tolérance aux pannes des instances dupliquées de données. Lors des opérations de lecture et d'écriture, la topologie détermine les nœuds participants requis pour fournir des garanties de cohérence. Vous devez configurer manuellement les nœuds, les racks et les centres de données lorsque vous créez ou étendez un cluster. Dans un environnement cloud, un déploiement Cassandra classique traite une zone cloud comme un rack et une région cloud comme un centre de données.
Vous pouvez utiliser les contrôles de quorum de Cassandra pour ajuster les garanties de cohérence pour chaque opération de lecture ou d'écriture. Les niveaux d'importance de cohérence à terme peuvent varier, y compris les options qui nécessitent un seul nœud d'instance dupliquée (ONE), une majorité de nœuds d'instances dupliquées de centre de données unique (LOCAL_QUORUM), ou une majorité de nœuds d'instances dupliquées dans tous les centres de données (QUORUM).
Dans Bigtable, les clusters sont des ressources zonales. Une instance Bigtable peut contenir un seul cluster, ou un groupe de clusters entièrement répliqués. Vous pouvez placer des clusters d'instances dans n'importe quelle combinaison de zones dans toutes les régions proposées par Google Cloud . Vous pouvez ajouter et supprimer des clusters d'une instance avec un impact minimal sur les autres clusters de l'instance.
Dans Bigtable, les écritures sont effectuées (avec la cohérence écriture-lecture) sur un seul cluster et seront cohérentes à terme dans les autres clusters d'instances. Comme les cellules individuelles comprennent des versions gérées par horodatage, aucune écriture n'est perdue, et chaque cluster diffuse les cellules comportant les horodatages les plus récents.
Le service expose l'état de cohérence du cluster. L'API Cloud Bigtable fournit un mécanisme permettant d'obtenir un jeton de cohérence au niveau de la table. Vous pouvez utiliser ce jeton pour vérifier si toutes les modifications apportées à cette table avant la création du jeton ont été entièrement répliquées.
Compatibilité avec les transactions
Bien qu'aucune base de données ne soit compatible avec les transactions multilignes complexes, chacune offre une prise en charge des transactions.
Cassandra dispose d'une méthode de transaction légère (LWT) qui permet une atomicité des mises à jour des valeurs de colonne dans une partition unique. Cassandra dispose également de sémantiques Compare-And-Set qui permettent d'effectuer une comparaison des opérations de lecture et de valeur d'une ligne avant le lancement d'une écriture.
Bigtable prend en charge les écritures à ligne unique et à cohérence totale au sein d'un cluster. Les transactions à ligne unique sont davantage activées grâce aux opérations de lecture-modification-écriture et de vérification-mutation. Les profils d'application de routage multicluster sont compatibles avec les transactions à ligne unique.
Modèle de données
Bigtable et Cassandra organisent les données dans des tables compatibles avec les recherches et les analyses de plages à l'aide de l'identifiant unique de la ligne. Les deux systèmes sont considérés comme des magasins NoSQL orientés colonnes.
Dans Cassandra, vous devez utiliser CQL pour créer le schéma de table complet à l'avance, y compris la définition de la clé primaire, ainsi que les noms des colonnes et leurs types. Les clés primaires dans Cassandra sont des valeurs composites uniques qui contiennent une clé de partition obligatoire et une clé de cluster facultative. La clé de partition détermine l'emplacement de nœud d'une ligne, et la clé du cluster détermine l'ordre de tri dans une partition. Lorsque vous créez des schémas, vous devez avoir conscience des compromis potentiels entre l'exécution d'analyses efficaces au sein d'une partition unique et les coûts liés au système associés à la gestion de grandes partitions.
Dans Bigtable, il vous suffit de créer la table et de définir ses familles de colonnes à l'avance. Les colonnes ne sont pas déclarées lors de la création des tables, mais elles sont créées lorsque les appels d'API d'applications ajoutent des cellules aux lignes de la table.
Les clés de ligne sont classées de façon lexicographique dans le cluster Bigtable. Les nœuds dans Bigtable équilibrent automatiquement la responsabilité nodale pour les plages de clés, souvent appelés tablets et parfois divisions. Les clés de ligne Bigtable sont souvent constituées de plusieurs valeurs de champ qui sont jointes à l'aide d'un caractère de séparateur couramment utilisé (par exemple, un pourcentage). Lorsqu'ils sont séparés, les composants de chaîne individuels sont analogues aux champs d'une clé primaire Cassandra.
Conception des clés de ligne
Dans Bigtable, l'identifiant unique d'une ligne de table est la clé de ligne. La clé de ligne doit être une valeur unique appliquée à une table entière. Vous pouvez créer des clés composées de plusieurs parties en concaténant les éléments disparates séparés par un délimiteur commun. La clé de ligne détermine l'ordre de tri global des données dans une table. Le service Bigtable détermine de manière dynamique les plages de clés attribuées à chaque nœud.
Contrairement à Cassandra, où le hachage de clé de partitionnement détermine l'emplacement des lignes et les colonnes de clustering déterminent l'ordre, la clé de ligne Bigtable fournit à la fois l'attribution et l'ordre nodal. Comme avec Cassandra, vous devez concevoir une clé de ligne dans Bigtable de sorte que les lignes que vous souhaitez récupérer ensemble soient stockées ensemble. Toutefois, dans Bigtable, il n'est pas nécessaire de concevoir la clé de ligne pour l'emplacement et l'ordre avant d'utiliser une table.
Types de données
Le service Bigtable n'applique pas les types de données de colonne envoyés par le client. Les bibliothèques clientes fournissent des méthodes d'assistance pour écrire les valeurs de cellule sous forme d'octets, de chaînes encodées en UTF-8 et d'entiers encodés de 64 bits en mode big-endian (les entiers encodés en mode big-endian sont requis pour les opérations d'incrémentation atomique).
Famille de colonnes
Dans Bigtable, une famille de colonnes détermine quelles colonnes d'une table sont stockées et récupérées ensemble. Chaque table doit contenir au moins une famille de colonnes, bien que les tables en contiennent souvent davantage (la limite est de 100 familles de colonnes pour chaque table). Pour qu'une application puisse les utiliser dans une opération, vous devez explicitement créer les familles de colonnes.
Qualificatifs de colonne
Chaque valeur stockée dans une table au niveau d'une clé de ligne est associée à un libellé appelé qualificatif de colonne. Étant donné que les qualificatifs de colonne ne sont que des libellés, il n'existe aucune limite pratique quant au nombre de colonnes que vous pouvez ajouter à une famille de colonnes. Les qualificatifs de colonne sont souvent utilisés dans Bigtable pour représenter les données de l'application.
Cellules
Dans Bigtable, une cellule est l'intersection de la clé de ligne et du nom de la colonne (une famille de colonnes combinée à un qualificatif de colonne). Chaque cellule contient une ou plusieurs valeurs horodatées pouvant être fournies par le client ou appliquées automatiquement par le service. Les anciennes valeurs de cellule sont récupérées en fonction d'une stratégie de récupération de mémoire configurée au niveau de la famille de colonnes.
Index secondaires
Vous pouvez utiliser des vues matérialisées continues comme index secondaires asynchrones pour les tables afin d'interroger les mêmes données à l'aide de différents attributs ou modèles de recherche. Pour en savoir plus, consultez Créer un index secondaire asynchrone.
Équilibrage de charge et basculement des clients
Dans Cassandra, le client contrôle l'équilibrage de charge des requêtes. Le pilote du client définit une stratégie qui est spécifiée dans le cadre d'une configuration ou de manière programmatique lors de la création de la session. Le cluster informe la stratégie concernant les centres de données les plus proches de l'application, et le client identifie les nœuds de ces centres de données pour traiter une opération.
Le service Bigtable route les appels d'API vers un cluster de destination en fonction d'un paramètre (un identifiant de profil d'application) fourni avec chaque opération. Les profils d'application sont gérés dans le service Bigtable. Les opérations client qui ne sélectionnent pas un profil utilisent un profil par défaut.
Bigtable propose deux types de règles de routage pour le profil d'application : cluster unique et multicluster. Un profil multicluster achemine les opérations vers le cluster disponible le plus proche. Les clusters d'une même région sont considérés comme étant équidistants du point de vue du routeur d'opérations. Si le nœud responsable de la plage de clés demandée est surchargé ou temporairement indisponible dans un cluster, ce type de profil assure le basculement automatique.
En ce qui concerne Cassandra, une stratégie multicluster fournit les avantages de basculement d'une règle d'équilibrage de charge qui tient compte des centres de données.
Un profil d'application comportant un routage à cluster unique dirige tout le trafic vers un seul cluster. La cohérence de ligne forte et les transactions à ligne unique ne sont disponibles que dans les profils disposant d'un routage à cluster unique.
L'inconvénient d'une approche à cluster unique est que lors d'un basculement, l'application doit pouvoir réessayer en utilisant un autre identifiant de profil d'application, ou vous devez effectuer manuellement le basculement des profils de routage à cluster unique impactés.
Routage des opérations
Cassandra et Bigtable utilisent des méthodes différentes pour sélectionner le nœud de traitement des opérations de lecture et d'écriture. Dans Cassandra, la clé de partition est identifiée, tandis que dans Bigtable, la clé de ligne est utilisée.
Dans Cassandra, le client inspecte d'abord la règle d'équilibrage de charge. Cet objet côté client détermine le centre de données vers lequel l'opération est acheminée.
Une fois le centre de données identifié, Cassandra contacte un nœud coordinateur pour gérer l'opération. Si la règle reconnaît des jetons, le coordinateur est un nœud qui diffuse les données de la partition vnode cible. Dans le cas contraire, le coordinateur est un nœud aléatoire. Le nœud coordinateur identifie les nœuds dans lesquels se trouvent les instances dupliquées de données pour la clé de partition d'opération, puis indique à ces nœuds d'effectuer l'opération.
Dans Bigtable, comme mentionné précédemment, chaque opération inclut un identifiant de profil d'application. Le profil d'application est défini au niveau du service. La couche de routage Bigtable inspecte le profil pour choisir le cluster de destination approprié pour l'opération. La couche de routage fournit ensuite un chemin permettant à l'opération d'atteindre les nœuds de traitement corrects à l'aide de la clé de ligne de l'opération.
Processus d'écriture des données
Ces deux bases de données sont optimisées pour des opérations d'écriture rapides et utilisent un processus similaire pour terminer une écriture. Toutefois, les étapes des bases de données peuvent varier légèrement, en particulier pour Cassandra où, selon le niveau de cohérence des opérations, une communication avec des nœuds participants supplémentaires peut être requise.
Une fois la requête d'écriture acheminée vers les nœuds appropriés (Cassandra) ou le nœud (Bigtable), les opérations d'écriture sont d'abord conservées sur le disque de manière séquentielle dans un journal de commit (Cassandra) ou un journal partagé (Bigtable). Les écritures sont ensuite insérées dans une table en mémoire (également appelée memtable) classée de la même manière que les SSTables.
Après ces deux étapes, le nœud répond pour indiquer que l'écriture est terminée. Dans Cassandra, plusieurs instances dupliquées (selon le niveau de cohérence spécifié pour chaque opération) doivent répondre avant que le coordinateur informe le client que l'écriture est terminée. Dans Bigtable, étant donné que chaque clé de ligne n'est attribuée qu'à un seul nœud à tout moment, une réponse du nœud suffit pour confirmer qu'une écriture a réussi.
Plus tard, si nécessaire, vous pouvez vider la memtable sur le disque sous la forme d'une nouvelle SSTable. Dans Cassandra, la vidage se produit lorsque le journal de commit atteint une taille maximale ou lorsque la memtable dépasse un seuil que vous avez configuré. Dans Bigtable, un vidage est lancé pour créer de nouvelles SSTables immutable lorsque la memtable atteint une taille maximale spécifiée par le service. Régulièrement, un processus de compactage fusionne les SSTables d'une plage de clés donnée en une seule SSTable.
Mises à jour des données
Les deux bases de données traitent les mises à jour de données de façon similaire. Toutefois, Cassandra n'autorise qu'une seule valeur par cellule, tandis que Bigtable peut conserver un grand nombre de valeurs avec versions gérées pour chaque cellule.
Lorsque la valeur à l'intersection d'un identifiant de ligne unique et d'une colonne est modifiée, la mise à jour est conservée comme décrit précédemment dans la section Processus d'écriture de données. L'horodatage d'écriture est stocké avec la valeur de la structure SSTable.
Si vous n'avez pas vidé une cellule mise à jour vers une SSTable, vous ne pouvez stocker que la valeur de cellule de la memtable, mais les bases de données diffèrent selon les éléments stockés. Cassandra n'enregistre que la valeur la plus récente dans la memtable, tandis que Bigtable enregistre toutes les versions dans la memtable.
Par ailleurs, si vous avez vidé au moins une version d'une valeur de cellule sur un disque dans des SSTables distinctes, les bases de données traitent les requêtes pour ces données différemment. Lorsque la cellule est demandée depuis Cassandra, seule la valeur la plus récente d'après l'horodatage est renvoyée. Autrement dit, la dernière écriture l'emporte. Dans Bigtable, vous utilisez des filtres pour contrôler les versions des cellules renvoyées par une requête de lecture.
Suppressions de lignes
Étant donné que les deux bases de données utilisent des SSTables immuables pour conserver les données sur le disque, il n'est pas possible de supprimer immédiatement une ligne. Pour garantir que les requêtes renvoient les résultats corrects après la suppression d'une ligne, les deux bases de données gèrent les suppressions à l'aide du même mécanisme. Un repère (appelé Tombstone dans Cassandra) est d'abord ajouté à la memtable. À terme, une SSTable nouvellement écrite contient un marqueur horodaté indiquant que l'identifiant de ligne unique est supprimé et ne doit pas être renvoyé dans les résultats de requête.
Durée de vie
Les capacités de la valeur TTL (Time To Live) des deux bases de données sont similaires, à une différence près. Dans Cassandra, vous pouvez définir la valeur TTL d'une colonne ou d'une table, tandis que dans Bigtable, vous ne pouvez définir des valeurs TTL que pour la famille de colonnes. Il existe une méthode pour Bigtable qui permet de simuler la valeur TTL au niveau de la cellule.
Récupération de mémoire
Comme les mises à jour ou les suppressions de données immédiates ne sont pas possibles avec des SSTables immuables, comme indiqué précédemment, la récupération de mémoire se produit lors d'un processus appelé compactage. Le processus supprime les cellules ou les lignes qui ne doivent pas être diffusées dans les résultats de la requête.
Le processus de récupération de mémoire exclut une ligne ou une cellule lorsqu'une fusion SSTable a lieu. Si un repère ou un tombstone existe pour une ligne, celle-ci n'est pas incluse dans la SSTable résultante. Les deux bases de données peuvent exclure une cellule de la table SSTable fusionnée. Si l'horodatage de la cellule dépasse une qualification de valeur TTL, les bases de données excluent la cellule. S'il existe deux versions horodatées pour une cellule donnée, Cassandra n'inclut que la valeur la plus récente dans la table SSTable fusionnée
Chemin de lecture des données
Lorsqu'une opération de lecture atteint le nœud de traitement approprié, le processus de lecture permettant d'obtenir des données pour satisfaire un résultat de requête est le même pour les deux bases de données.
Pour chaque SSTable sur disque pouvant contenir des résultats de requête, un filtre Bloom est vérifié pour déterminer si chaque fichier contient des lignes à renvoyer. Étant donné que les filtres Bloom ne fournissent jamais de faux négatif, toutes les SSTables éligibles sont ajoutées à une liste de candidats pour être incluses dans un traitement supplémentaire des résultats de lecture.
L'opération de lecture est effectuée à l'aide d'une vue fusionnée créée à partir de la memtable et des SSTables candidates sur le disque. Comme toutes les clés sont triées de façon lexicographique, obtenir une vue fusionnée analysée pour obtenir des résultats de requête est une méthode efficace.
Dans Cassandra, un ensemble de nœuds de traitement déterminés par le niveau de cohérence de l'opération doit participer à l'opération. Dans Bigtable, seul le nœud responsable de la plage de clés a besoin d'être consulté. Pour Cassandra, vous devez prendre en compte les implications en matière de dimensionnement, car il est probable que plusieurs nœuds traiteront chaque lecture.
Les résultats de lecture peuvent être limités au nœud de traitement de façons légèrement différentes.
Dans Cassandra, la clause WHERE d'une requête CQL limite les lignes renvoyées. La contrainte est que les colonnes de la clé primaire ou les colonnes incluses dans un index secondaire peuvent être utilisées pour limiter les résultats.
Bigtable propose un large éventail de filtres qui ont une incidence sur les lignes ou les cellules récupérées par une requête de lecture.
Il existe trois catégories de filtres :
- Les filtres de limitation, qui contrôlent les lignes ou les cellules incluses dans la réponse.
- Les filtres de modification, qui affectent les données ou les métadonnées des cellules individuelles.
- Les filtres de composition, qui vous permettent de combiner plusieurs filtres dans un même filtre.
Les filtres de limitation sont les plus couramment utilisés, par exemple, l'expression régulière de famille de colonnes et l'expression régulière de qualificatif de colonnes.
Stockage de données physiques
Bigtable et Cassandra stockent les données dans des SSTables, qui sont régulièrement fusionnées pendant une phase de compactage. La compression des données SSTable offre des avantages similaires en termes de réduction de la taille de stockage. Cependant, la compression est automatiquement appliquée dans Bigtable et constitue une option de configuration dans Cassandra.
Lorsque vous comparez les deux bases de données, vous devez comprendre comment chaque base de données stocke physiquement les données de manière différente selon les aspects suivvants :
- La stratégie de distribution des données
- Le nombre de versions de cellule disponibles
- Le type de disque de stockage
- Le mécanisme de durabilité et de réplication des données
Distribution des données
Dans Cassandra, un hachage cohérent des colonnes de partition de la clé primaire est la méthode recommandée pour déterminer la distribution des données sur les différentes SSTables diffusées par les nœuds de cluster.
Bigtable utilise un préfixe de variable sur la clé de ligne complète afin de placer les données de manière lexicographique dans les SSTables.
Versions de cellules
Cassandra ne conserve qu'une seule version active de valeur de cellule. Si deux écritures sont effectuées dans une cellule, une règle "last-write-wins" garantit qu'une seule valeur est renvoyée.
Bigtable ne limite pas le nombre de versions horodatées pour chaque cellule. D'autres limites de taille de ligne peuvent s'appliquer. Si ce champ n'est pas défini par la requête client, l'horodatage est déterminé par le service Bigtable au moment où le nœud de traitement reçoit la mutation. Les versions de cellule peuvent être éliminées à l'aide d'une stratégie de récupération de mémoire qui peut être différente pour chaque famille de colonnes de la table, ou qui peut être filtrée à partir d'un ensemble de résultats de requête via l'API.
Stockage sur disque
Cassandra stocke les SSTables sur les disques associés à chaque nœud de cluster. Pour rééquilibrer les données dans Cassandra, les fichiers doivent être copiés physiquement entre des serveurs
Bigtable utilise Colossus pour stocker les SSTables. Comme Bigtable utilise ce système de fichiers distribué, il est possible que le service Bigtable puisse réattribuer presque instantanément des SSTables à différents nœuds.
Durabilité et réplication des données
Cassandra assure la durabilité des données via le paramètre du facteur de réplication. Le facteur de réplication détermine le nombre de copies SSTable stockées sur différents nœuds du cluster. Généralement, le paramètre por le facteur de réplication est 3, qui permet toujours de renforcer la cohérence avec QUORUM ou LOCAL_QUORUM même si une défaillance du nœud se produit.
Avec Bigtable, des garanties élevées de durabilité des données sont fournies via la réplication proposée par Colossus.
Le schéma suivant illustre la disposition des données physiques, les nœuds de traitement des calculs et la couche de routage pour Bigtable :

Dans la couche de stockage Colossus, chaque nœud est attribué pour diffuser les données stockées dans une série de SSTables. Ces SSTables contiennent les données des plages de clés de ligne attribuées de manière dynamique à chaque nœud. Bien que le schéma montre trois SSTables pour chaque nœud, il est probable qu'il y en ait plus, car les SSTables sont créées en continu à mesure que les nœuds reçoivent de nouvelles modifications de données.
Chaque nœud possède un journal partagé. Les écritures traitées par chaque nœud sont immédiatement conservées dans le journal partagé avant que le client ne reçoive une confirmation d'écriture. Étant donné qu'une écriture dans Colossus est répliquée plusieurs fois, la durabilité est garantie même si une défaillance matérielle nodale se produit avant que les données ne soient conservées dans une SSTable pour la plage de lignes.
Interfaces de l'application
À l'origine, l'accès à la base de données Cassandra a été exposé via une API Thrift, mais cette méthode d'accès est obsolète. L'interaction client recommandée est via CQL.
Semblable à l'API Thrift d'origine de Cassandra, l'accès à la base de données Bigtable est fourni via une API qui lit et écrit des données en fonction des clés de ligne fournies.
Tout comme Cassandra, Bigtable dispose d'une interface de ligne de commande, nommée CLI cbt, et de bibliothèques clientes compatibles avec de nombreux langages de programmation courants. Ces bibliothèques sont basées sur les API gRPC et REST. Les applications écrites pour Hadoop et basées sur la bibliothèque Open Source Apache HBase pour Java peuvent se connecter sans modification importante à Bigtable. Pour les applications qui ne nécessitent pas de compatibilité HBase, nous vous recommandons d'utiliser le client Java intégré Bigtable.
Les contrôles de gestion de l'authentification et des accès (IAM) de Bigtable sont entièrement intégrés à Google Cloud, et les tables peuvent également être utilisées en tant que source de données externe depuis BigQuery.
Configuration de la base de données
Lorsque vous configurez un cluster Cassandra, vous devez prendre plusieurs décisions de configuration et compléter différentes étapes. Tout d'abord, vous devez configurer les nœuds du serveur pour fournir la capacité de calcul et provisionner l'espace de stockage local. Lorsque vous utilisez un facteur de réplication de trois, le paramètre recommandé et le plus courant, vous devez provisionner le stockage pour stocker trois fois la quantité de données que vous prévoyez de conserver dans votre cluster. Vous devez également déterminer et définir les configurations de vnodes, de racks et de réplication.
La séparation entre calcul et stockage dans Bigtable simplifie le scaling à la hausse des clusters par rapport à Cassandra. Dans un cluster en cours d'exécution normal, vous n'êtes généralement concerné que par le stockage total utilisé par les tables gérées, qui détermine le nombre minimum de nœuds, et par le fait d'avoir suffisamment de nœuds pour maintenir le RPS actuel.
Vous pouvez ajuster rapidement la taille du cluster Bigtable si le cluster est sur-provisionné ou sous-provisionné en fonction de la charge de production.
Stockage Bigtable
À l'exception de l'emplacement géographique du cluster initial, le seul choix que vous devez effectuer lorsque vous créez votre instance Bigtable est le type de stockage. Bigtable propose deux options de stockage : les disques durs SSD ou HDD. Tous les clusters d'une instance doivent partager le même type de stockage.
Lorsque vous tenez compte des besoins de stockage avec Bigtable, vous n'avez pas besoin de prendre en compte les instances dupliquées de stockage comme vous le feriez lors du dimensionnement d'un cluster Cassandra. Il n'y a pas de perte de densité de stockage pour atteindre la tolérance aux pannes, comme c'est le cas dans Cassandra. De plus, comme l'espace de stockage n'a pas besoin d'être provisionné de manière explicite, vous ne payez que l'espace de stockage utilisé.
SSD
La capacité du nœud SSD de 5 To, idéale pour la plupart des charges de travail, offre une densité de stockage plus élevée que la configuration recommandée pour les machines Cassandra, qui possèdent une densité de stockage maximale pratique inférieure à 2 To pour chaque nœud. Lorsque vous évaluez les besoins en capacité de stockage, n'oubliez pas que Bigtable ne comptabilise qu'une seule copie des données. À titre de comparaison, Cassandra doit prendre en compte trois copies des données dans la plupart des configurations.
Bien que le nombre de RPS en écriture pour un SSD soit à peu près identique à celui d'un HDD, les SSD fournissent un RPS en lecture beaucoup plus élevé qu'un HDD. Le prix du stockage SSD est égal ou proche du coût des disques persistants SSD provisionnés et varie selon les régions.
HDD
Le type de stockage HDD offre une densité de stockage considérable : 16 To pour chaque nœud. La seule différence est que les lectures aléatoires sont considérablement ralenties et n'acceptent que 500 lignes lues par seconde pour chaque nœud. Le stockage HDD est préférable pour les charges de travail intensives d'écriture où les lectures sont censées être des analyses de plage associées au traitement par lot. Le prix du stockage HDD est égal ou proche du coût associé à Cloud Storage et varie en fonction de la région.
Considérations relatives à la taille du cluster
Lorsque vous dimensionnez une instance Bigtable pour préparer la migration d'une charge de travail Cassandra, il y a des considérations à prendre en compte lorsque vous comparez les clusters Cassandra à centre de données unique aux instances Bigtable à cluster unique, et les clusters Cassandra à centres de données multiples aux instances Bigtable à clusters multiples. Les instructions des sections suivantes supposent qu'aucune modification importante du modèle de données n'est nécessaire pour la migration, et qu'il existe une compression de stockage équivalente entre Cassandra et Bigtable.
Un cluster à centre de données unique
Lorsque vous comparez un cluster à centre de données unique à une instance Bigtable à cluster unique, vous devez d'abord tenir compte des exigences en matière de stockage. Vous pouvez estimer la taille non répliquée de chaque espace de clés à l'aide de la commande tablestats nodetool, et en divisant la taille totale de l'espace de stockage vide par le facteur de réplication de l'espace de clés. Vous divisez ensuite l'espace de stockage non répliqué de tous les espaces de clés par 3,5 To (5 To * 70) pour déterminer le nombre suggéré de nœuds SSD afin de gérer l'espace de stockage seul. Comme indiqué, Bigtable gère la réplication et la durabilité du stockage dans un niveau distinct, transparent pour l'utilisateur.
Ensuite, vous devez tenir compte des exigences de calcul pour le nombre de nœuds. Vous pouvez consulter les métriques du serveur Cassandra et des applications clientes pour obtenir un nombre approximatif de lectures et d'écritures soutenues exécutées. Pour estimer le nombre minimum de nœuds SSD pour exécuter votre charge de travail, divisez cette métrique par 10 000. Vous aurez probablement besoin de plus de nœuds pour les applications nécessitant des résultats de requête à faible latence. Google vous recommande de tester les performances de Bigtable avec des données et des requêtes représentatives afin d'établir une métrique pour le RPS par nœud réalisable pour votre charge de travail.
Le nombre de nœuds requis pour le cluster doit être égal au plus grand nombre en termes de besoins de stockage et de calcul. Si vous n'êtes pas sûr de vos besoins en matière de stockage ou de débit, vous pouvez mettre en correspondance le nombre de nœuds Bigtable avec le nombre de machines Cassandra classiques. Vous pouvez effectuer le scaling d'un cluster Bigtable à la hausse ou à la baisse pour répondre aux besoins de charge de travail, avec un minimum d'efforts et aucun temps d'arrêt.
Un cluster à centres de données multiples
Avec les clusters à centres de données multiples, il est plus difficile de déterminer la configuration d'une instance Bigtable. Idéalement, vous devez avoir un cluster dans l'instance pour chaque centre de données dans la topologie Cassandra. Chaque cluster Bigtable de l'instance doit stocker toutes les données de l'instance et être en mesure de gérer le taux d'insertion total sur l'ensemble du cluster. Les clusters d'une instance peuvent être créés dans n'importe quelle région cloud compatible à travers le monde.
La technique permettant d'estimer les besoins de stockage est semblable à celle des clusters à centre de données unique. Vous utilisez nodetool pour obtenir la taille de stockage de chaque espace de clés dans le cluster Cassandra, puis divisez cette taille par le nombre d'instances dupliquées. N'oubliez pas que l'espace de clés d'une table peut avoir des facteurs de réplication différents pour chaque centre de données.
Le nombre de nœuds de chaque cluster dans une instance doit pouvoir gérer toutes les écritures dans le cluster et toutes les lectures vers au moins deux centres de données afin de maintenir les objectifs de niveau de service (SLO) pendant une panne de cluster. Une approche courante consiste à démarrer avec tous les clusters ayant la capacité de nœud équivalente au centre de données le plus actif dans le cluster Cassandra. Vous pouvez définir le scaling à la hausse des clusters Bigtable d'une instance de manière individuelle afin de répondre aux besoins de charge de travail, sans temps d'arrêt.
Administration
Bigtable fournit des composants entièrement gérés pour les fonctions d'administration courantes exécutées dans Cassandra.
Sauvegarde et restauration
Bigtable propose deux méthodes pour répondre aux besoins de sauvegarde courants : les sauvegardes Bigtable et les exportations de données gérées.
Les sauvegardes Bigtable peuvent être assimilées à une version gérée de la fonctionnalité d'instantané nodetool de Cassandra.
Les sauvegardes Bigtable créent des copies reproductibles d'une table, qui sont stockées en tant qu'objets membres d'un cluster. Vous pouvez restaurer des sauvegardes en tant que nouvelle table du cluster qui a déclenché la sauvegarde. Les sauvegardes sont conçues pour créer des points de restauration en cas de corruption au niveau de l'application. Les sauvegardes que vous créez via cet utilitaire ne consomment pas de ressources de nœuds et leur tarif est égal ou proche aux tarifs de Cloud Storage. Vous pouvez appeler des sauvegardes Bigtable de manière automatisée ou via la console Google Cloud pour Bigtable.
Une autre façon de sauvegarder Bigtable consiste à utiliser une exportation de données gérée vers Cloud Storage. Vous pouvez les exporter aux formats de fichiers Avro, Parquet ou Hadoop Sequence. Par rapport aux sauvegardes Bigtable, l'exécution des exportations prend plus de temps et entraîne des coûts de calcul supplémentaires, car les exportations utilisent Dataflow. Toutefois, ces exportations créent des fichiers de données portables que vous pouvez interroger hors connexion ou importer dans un autre système.
Redimensionner
Étant donné que Bigtable sépare le stockage et le calcul, vous pouvez ajouter ou supprimer des nœuds Bigtable en réponse à la demande de requête de façon plus fluide que dans Cassandra. L'architecture homogène de Cassandra nécessite de rééquilibrer les nœuds (ou vnodes) entre les machines du cluster.
Vous pouvez modifier la taille du cluster manuellement dans la console Google Cloud ou de manière automatisée à l'aide de l'API Cloud Bigtable. L'ajout de nœuds à un cluster peut vous permettre d'améliorer considérablement les performances en quelques minutes. Certains clients ont utilisé avec succès un autoscaler Open Source développé par Spotify.
Maintenance interne
Le service Bigtable gère de manière transparente les tâches de maintenance interne courantes de Cassandra telles que les applications de correctifs du système d'exploitation, la récupération des nœuds, la réparation des nœuds, la surveillance du compactage du stockage et la rotation des certificats SSL.
Surveillance
La connexion de Bigtable à la visualisation des métriques ou aux alertes ne nécessite aucune opération d'administration ou de développement. La page Bigtable Google Cloud de la console comprend des tableaux de bord prédéfinis pour suivre le débit et les métriques d'utilisation au niveau de l'instance, du cluster et de la table. Les vues et les alertes personnalisées peuvent être créées dans les tableaux de bord Cloud Monitoring, où les métriques sont automatiquement disponibles.
L'outil Key Visualizer de Bigtable, une fonctionnalité de surveillance de la console Google Cloud , vous permet d'effectuer un réglage avancé des performances.
IAM et sécurité
Dans Bigtable, l'autorisation est entièrement intégrée au framework IAM deGoogle Cloudet nécessite une configuration et une maintenance minimales. Les comptes utilisateur locaux et les mots de passe ne sont pas partagés avec les applications clientes. À la place, des autorisations et des rôles précis sont attribués aux utilisateurs et aux comptes de service au niveau de l'organisation.
Bigtable chiffre automatiquement toutes les données au repos et en transit. Il n'existe aucune option permettant de désactiver ces fonctionnalités. Tous les accès administratifs sont entièrement consignés. Vous pouvez utiliser VPC Service Controls pour contrôler l'accès aux instances Bigtable depuis l'extérieur des réseaux approuvés.
Étapes suivantes
- Découvrez la conception de schémas Bigtable.
- Essayez l'atelier de programmation Bigtable pour les utilisateurs de Cassandra.
- Découvrez l'émulateur Bigtable.
- Découvrez des architectures de référence, des schémas et des bonnes pratiques concernant Google Cloud. Consultez notre Cloud Architecture Center.