Dieses Dokument richtet sich an Softwareentwickler und Datenbankadministratoren, die vorhandene Anwendungen migrieren oder neue Anwendungen für die Verwendung von Bigtable als Datenspeicher entwickeln möchten. Dieses Dokument baut auf Ihrer Kenntnis von Apache Cassandra für die Nutzung von Bigtable auf und beschreibt Konzepte, die Sie vor der Migration kennen sollten. Informationen zu Open-Source-Tools, mit denen Sie die Migration durchführen können, finden Sie unter Von Cassandra zu Bigtable migrieren.
Bigtable und Cassandra sind verteilte Datenbanken. Sie implementieren mehrdimensionale Schlüssel/Wert-Paar-Speicher, die Zehntausende von Abfragen pro Sekunde (Queries per second, QPS), Speicher für eine Skalierung bis zu Petabyte an Daten sowie eine Toleranz bei Knotenausfällen unterstützen.
Wann ist Bigtable ein gutes Ziel für Cassandra-Arbeitslasten?
Der beste Google Cloud Dienst für Ihre Cassandra-Arbeitslast hängt von Ihren Migrationszielen und den Cassandra-Funktionen ab, die Sie nach der Migration benötigen.
Bigtable ist optimal, wenn mindestens eine der folgenden Bedingungen zutrifft:
- Sie möchten einen vollständig verwalteten Dienst ohne Wartungsfenster und mit hoher Verfügbarkeit.
- Sie benötigen eine elastische Skalierung, die automatisch auf Änderungen des Server-Traffics reagiert.
- Sie verwenden neben skalaren Typen auch Cassandra-Sammlungstypen, Zähler oder materialisierte Ansichten.
- Sie haben eine Anwendung, die den Parameter
USING TIMESTAMPverwendet. - Ihr Schreibdurchsatz und Ihre Latenz sind genauso wichtig wie Lesevorgänge.
- Sie verwenden eines der letztendlich konsistenten Replikationsmodelle von Cassandra.
- Für Ihren Anwendungsfall ist kostengünstiger Speicher erforderlich.
Wenn Sie Anwendungen ohne Codeänderungen migrieren möchten, können Sie Cassandra in GKE selbst verwalten oder einen Google CloudPartner wie DataStax oder ScyllaDB verwenden. Wenn Ihre Anwendung viele Lesevorgänge ausführt und Sie bereit sind, Ihren Code umzugestalten, um relationale Datenbankfunktionen und strikte Konsistenz zu erhalten, sollten Sie Spanner in Betracht ziehen.
In diesem Dokument finden Sie Tipps, was Sie beim Refactoring Ihrer Anwendung beachten sollten, wenn Sie Bigtable als Migrationsziel für Ihre Cassandra-Arbeitslasten auswählen.
Verwendung dieses Dokuments
Sie müssen dieses Dokument nicht komplett lesen. Das Dokument bietet durchgehend einen ausführlichen Vergleich der beiden Datenbanken. Es besteht aber die Möglichkeit, sich auf die Themen zu konzentrieren, die für Ihren Anwendungsfall oder Ihre Interessen relevant sind.
Um Ihnen den Vergleich von Bigtable und Cassandra zu erleichtern, wird in diesem Dokument Folgendes behandelt:
- Vergleich der Terminologie, die sich zwischen den beiden Datenbanken partiell unterscheidet
- Übersicht über die beiden Datenbanksysteme
- Beschreibung, wie in jeder Datenbank die Datenmodellierung verarbeitet wird, um die unterschiedliche Designaspekte zu verdeutlichen
- Vergleich des Pfads der Daten bei Schreib- und Lesevorgängen
- Erläuterung des physischen Datenlayouts zum besseren Verständnis der verschiedenen Aspekte der Datenbankarchitektur
- Erläuterung der Konfiguration der geografischen Replikation für Ihre Anforderungen und der Festlegung der Clustergröße
- Detailinformationen zur Clusterverwaltung, zu Monitoring und zur Sicherheit
Vergleich der Terminologie
Obwohl sich viele der in Bigtable und Cassandra verwendeten Konzepte ähneln, weichen neben anderen kleineren Unterschieden die Namenskonventionen für jede Datenbank etwas voneinander ab.
Einer der zentralen Bausteine beider Datenbanken ist die sortierte Stringtabelle (SSTable). In beiden Architekturen werden SSTables erstellt, um Daten für die Antwort auf Leseabfragen zu speichern.
Ilya Grigorik schreibt dazu in einem Blogpost (2012) Folgendes: „Eine SSTable ist eine einfache Abstraktion, um eine große Anzahl an Schlüssel/Wert-Paaren effizient zu speichern und damit einen hohen Durchsatz sowie sequenzielle Lese- oder Schreibarbeitslasten zu ermöglichen.“
In der folgenden Tabelle sind gemeinsame Konzepte und die entsprechende Terminologie für jedes Produkt dargestellt.
| Cassandra | Bigtable |
|---|---|
|
Primärschlüssel: Ein eindeutiger Wert für ein einzelnes oder mehrere Felder, der die Datenplatzierung und -reihenfolge bestimmt. Partitionierungsschlüssel: Ein Wert für ein einzelnes oder mehrere Felder, der die Datenplatzierung durch einen konsistenten Hash bestimmt. Clustering-Spalte: Ein Wert für ein einzelnes oder mehrere Felder, der die lexikografische Datensortierung innerhalb einer Partition bestimmen. |
Zeilenschlüssel: Ein eindeutiger einzelner Bytestring, der die Platzierung von Daten gemäß einer lexikografischen Sortierung bestimmt. Zusammengesetzte Schlüssel werden durch das Verknüpfen der Daten mehrerer Spalten mithilfe eines allgemeinen Trennzeichens, z. B. das Rautezeichen (#) oder das Prozentzeichen (%), imitiert. |
| Knoten: Eine Maschine, die für das Lesen und Schreiben von Daten sorgt, die einer Reihe von Hash-Bereichen mit primären Schlüsselpartitionen zugeordnet sind. In Cassandra werden Daten in einem Speicher auf Blockebene gespeichert, der dem Knotenserver zugeordnet ist. | Knoten: Eine virtuelle Computing-Ressource, die für das Lesen und Schreiben von Daten sorgt, die mit einer Reihe von Zeilenschlüsseln verknüpft sind. In Bigtable befinden sich die Daten an einer anderen Stelle als die Computing-Knoten. Sie werden stattdessen in Colossus, dem verteilten Dateisystem von Google, gespeichert. Knoten sorgen temporär für die Bereitstellung von Daten verschiedener Bereiche anhand der Vorgangslast und des Status anderer Knoten im Cluster. |
|
Rechenzentrum: Entspricht einem Bigtable-Cluster. Allerdings sind in Cassandra einige Elemente der Topologie und der Replikationsstrategie konfigurierbar. Rack: Eine Gruppe von Knoten in einem Rechenzentrum, die die Replikatplatzierung beeinflussen. |
Cluster: Eine Gruppe von Knoten in derselben geografischenGoogle Cloud -Zone, die aus Gründen der Latenz und der Replikation an einem Speicherort verfügbar sind. |
| Cluster: Eine Cassandra-Bereitstellung, die aus einer Zusammenstellung von Rechenzentren besteht. | Instanz: Eine Gruppe von Bigtable-Clustern in verschiedenen Google Cloud Zonen oder -Regionen, zwischen denen ein Replikations- und ein Verbindungsrouting stattfinden. |
| VNode: Ein fester Bereich von Hashwerten, die einem bestimmten physischen Knoten zugewiesen sind. Daten in einem VNode-Knoten werden auf dem Cassandra-Knoten in einer Reihe von SSTables physisch gespeichert. | Tabellenreihen: Eine SSTable, die alle Daten für einen zusammenhängenden Bereich von lexikografisch sortierten Zeilenschlüsseln enthält. Tabellenreihen werden nicht auf Knoten in Bigtable gespeichert, sondern in einer Reihe von SSTables unter Colossus. |
| Replikationsfaktor: Die Anzahl der Replikate eines VNode-Knotens, die für alle Knoten im Rechenzentrum verwaltet werden. Der Replikationsfaktor wird für jedes Rechenzentrum separat konfiguriert. | Replikation: Der Vorgang, der die in Bigtable gespeicherten Daten in alle Clustern der Instanz kopiert. Die Replikation in einem zonalen Cluster wird von der Colossus-Speicherebene verarbeitet. |
| Tabelle (früher Spaltenfamilie): Eine logische Struktur von Werten, die durch den eindeutigen Primärschlüssel indexiert sind. | Tabelle: Eine logische Struktur von Werten, die durch den eindeutigen Zeilenschlüssel indexiert sind. |
| Schlüsselbereich: Ein logischer Tabellen-Namespace, der den Replikationsfaktor für die darin enthaltenen Tabellen definiert. | Nicht zutreffend. Bigtable behandelt die Probleme von Schlüsselbereichen transparent. |
| map: Ein Cassandra-Sammlungstyp, der Schlüssel/Wert-Paare enthält. | Spaltenfamilie: Ein benutzerdefinierter Namespace, der Spaltenqualifizierer für effizientere Lese- und Schreibvorgänge gruppiert. Wenn Sie Bigtable mit SQL abfragen, werden Spaltenfamilien wie Cassandra-Maps behandelt. |
| Karten-Schlüssel: Schlüssel, der einen Schlüssel/Wert-Eintrag in einer Cassandra-Karte eindeutig identifiziert | Spaltenqualifizierer: Ein Label für einen Wert, der in einer Tabelle gespeichert und durch den eindeutigen Zeilenschlüssel indexiert ist. Wenn Sie Bigtable mit SQL abfragen, werden Spalten wie Schlüssel einer Map behandelt. |
| Spalte: Das Label für einen Wert, der in einer Tabelle gespeichert und durch den eindeutigen Primärschlüssel indexiert ist. | Spalte: Das Label für einen Wert, der in einer Tabelle gespeichert und durch den eindeutigen Zeilenschlüssel indexiert ist. Der Spaltenname wird durch Kombination von Spaltenfamilie und Spaltenqualifizierer erstellt. |
| Zelle: Ein Zeitstempelwert in einer Tabelle, der dem Schnittpunkt eines Primärschlüssels mit der Spalte zugeordnet ist. | Zelle: Ein Zeitstempelwert in einer Tabelle, der dem Schnittpunkt eines Zeilenschlüssels mit dem Spaltennamen zugeordnet ist. Es können für jede Zelle mehrere Versionen mit Zeitstempel gespeichert und abgerufen werden. |
| counter: Ein inkrementierbarer Feldtyp, der für Summenoperationen mit Ganzzahlen optimiert ist. | Zähler: Zellen, in denen spezielle Datentypen für Ganzzahlsummenvorgänge verwendet werden. Weitere Informationen finden Sie unter Zähler erstellen und aktualisieren. |
| Load-Balancing-Richtlinie: Eine Richtlinie, die Sie in der Anwendungslogik konfigurieren, um Vorgänge an einen geeigneten Knoten im Cluster weiterzuleiten. Die Richtlinie berücksichtigt die Rechenzentrumstopologie und die Bereiche von VNode-Tokens. | Anwendungsprofil: Einstellungen, die festlegen, wie Bigtable einen Client-API-Aufruf an den entsprechenden Cluster in der Instanz weiterleiten soll. Außerdem können Sie das Anwendungsprofil als Tag verwenden, um Messwerte zu segmentieren. Das Anwendungsprofil wird im Dienst konfiguriert. |
| CQL: Die Cassandra-Abfragesprache, eine SQL-ähnliche Sprache, die für das Erstellen von Tabellen, Schemaänderungen, Zeilenmutationen und Abfragen verwendet wird. | Der Cassandra-zu-Bigtable-Client für Java ist ein nahtloser Ersatz für Ihre Cassandra-Treiber. Der Java-Client versteht Ihre CQL-Abfragen und ermöglicht es Ihnen, Bigtable transparent mit Ihrer vorhandenen Cassandra-basierten Anwendung zu verwenden, ohne Code neu schreiben zu müssen. Der Cassandra-zu-Bigtable-Proxyadapter ist eine eigenständige Ebene, die Sie parallel zu Ihrer Anwendung ausführen und als weiteren Cassandra-Knoten mit Bigtable verbinden können. Der Proxy-Adapter bietet Kompatibilität mit CQL und unterstützt Dual-Write- und Bulk-Migrationen. Diese Funktion ähnelt der, die der Cassandra-zu-Bigtable-Client für Java bietet. Die Bigtable APIs sind die Clientbibliotheken und die gRPC APIs, die zum Erstellen von Instanzen und Clustern, zum Anlegen von Tabellen und Spaltenfamilien, für Zeilenmutationen und für die Ausführung von Abfragen verwendet werden. Die Bigtable-SQL API ist CQL-Nutzern vertraut. |
Materialisierte Ansicht: Eine SELECT-Anweisung, die eine Reihe von Zeilen definiert, die Zeilen in einer zugrunde liegenden Quelltabelle entsprechen. Wenn sich die Quelltabelle ändert, aktualisiert Cassandra die materialisierte Ansicht automatisch.
|
Kontinuierliche materialisierte Ansicht: Ein vollständig verwaltetes, vorausberechnetes Ergebnis einer SQL-Abfrage, das inkrementell und automatisch aus einer Quelltabelle aktualisiert wird. Weitere Informationen finden Sie unter Kontinuierliche materialisierte Ansichten. |
Produktübersicht
Die folgenden Abschnitte geben einen Überblick über die Designphilosophie und die wichtigsten Merkmale von Bigtable und Cassandra.
Bigtable
Bigtable bietet eine Vielzahl zentraler Features, die im Artikel Bigtable: Ein verteiltes Speichersystem für strukturierte Daten beschrieben werden. Bigtable trennt die Computing-Knoten, die Clientanfragen verarbeiten, von der zugrunde liegenden Speicherverwaltung. Die Daten werden in Colossus gespeichert. Die Speicherebene repliziert die Daten automatisch für eine höhere Langlebigkeit, als sie mit der standardmäßigen Drei-Wege-Replikation von Hadoop Distributed File System (HDFS) möglich ist.
Diese Architektur bietet konsistente Lese- und Schreibvorgänge innerhalb eines Clusters, skaliert in beide Richtungen ohne Speicherneuverteilungskosten und kann Arbeitslasten ausgleichen, ohne den Cluster oder das Schema zu ändern. Wenn ein Datenverarbeitungsknoten eingeschränkt ist, ersetzt der Bigtable-Dienst diesen transparent. Bigtable unterstützt auch die asynchrone Replikation.
Neben gRPC und Clientbibliotheken für eine Vielzahl von Programmiersprachen unterstützt Bigtable die Kompatibilität mit der Open-Source-HBase-Java-Clientbibliothek von Apache. Dies ist eine alternative Implementierung der Open-Source-Datenbank-Engine des Bigtable-Papiers.
Im folgenden Diagramm wird gezeigt, wie Bigtable die Verarbeitungsknoten physisch von der Speicherebene trennt:
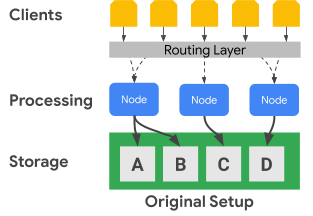
Im vorherigen Diagramm ist der mittlere Verarbeitungsknoten nur für die Verarbeitung von Datenanfragen an das C-Dataset in der Speicherebene zuständig. Wenn Bigtable ermittelt, dass für ein Dataset ein Ausgleich der Bereichszuordnung erforderlich ist, lassen sich die Datenbereiche für einen Verarbeitungsknoten einfach ändern, da die Speicherebene von der Verarbeitungsebene getrennt ist.
Das folgende Diagramm zeigt in vereinfachter Form den Ausgleich eines Schlüsselbereichs und die Anpassung der Clustergröße:
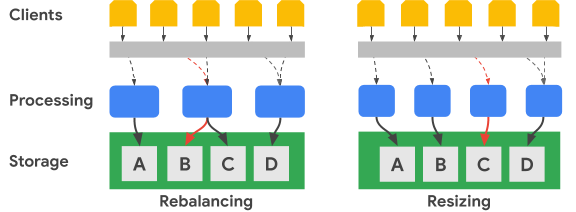
Das Bild für den Ausgleich zeigt den Status des Bigtable-Clusters an, nachdem der Verarbeitungsknoten ganz links eine erhöhte Anzahl an Anfragen für das Dataset A erhalten hat. Nach dem Ausgleich ist dann statt des Knotens ganz links der mittlere Knoten für die Verarbeitung von Datenanfragen für das Dataset B zuständig. Der Knoten auf der linken Seite verarbeitet weiter Dienstanfragen für das Dataset A.
Bigtable kann Zeilenschlüsselbereiche neu anordnen, um Dataset-Bereiche auf eine erhöhte Anzahl verfügbarer Verarbeitungsknoten abzustimmen. Das Bild für die Größenanpassung zeigt den Status des Bigtable-Clusters nach Hinzufügen eines Knotens.
Cassandra
Apache Cassandra ist eine Open-Source-Datenbank, die teilweise den Konzepten aus dem Bigtable-Papier entspricht. Sie nutzt eine verteilte Knotenarchitektur, bei der der Speicher sich am selben Ort wie die Server befindet, die auf Datenvorgänge antworten. Jedem Server wird nach dem Zufallsprinzip eine Reihe von virtuellen Knoten (VNodes) zugewiesen, um einen Teil des Clusterschlüsselbereichs bereitzustellen.
Die Daten werden in den VNode-Knoten anhand des Partitionierungsschlüssels gespeichert. In der Regel wird eine einheitliche Hash-Funktion verwendet, um ein Token zur Bestimmung der Datenplatzierung zu generieren. Wie bei Bigtable können Sie für die Token-Generierung und somit auch für die Datenplatzierung einen Partitionierer verwenden, der die Reihenfolge nicht verändert. Die Cassandra-Dokumentation rät allerdings von diesem Ansatz ab, da der Cluster damit sehr wahrscheinlich nicht mehr ausgeglichen wird. Das lässt sich nicht so einfach korrigieren. Aus diesem Grund wird in diesem Dokument davon ausgegangen, dass Sie eine konsistente Hashing-Strategie verwenden, um Tokens zu generieren, die zur Datenverteilung auf Knoten führen.
Cassandra bietet Fehlertoleranz für Verfügbarkeitsebenen in Verbindung mit der optimierbaren Konsistenzebene. Dies ermöglicht einem Cluster, Clients bereitzustellen, wenn ein oder mehrere Knoten eingeschränkt sind. Sie definieren die geografische Replikation über eine konfigurierbare Strategie für die Datenreplikationstopologie.
Dabei geben Sie für jeden Vorgang eine Konsistenzebene an. Die Einstellung ist in der Regel QUORUM oder in bestimmten Topologien mit mehreren Rechenzentren LOCAL_QUORUM. Diese Einstellung der Konsistenzebene erfordert eine Mehrheit an Replikatknoten, um auf den Koordinatorknoten antworten zu können, damit der Vorgang als erfolgreich betrachtet wird. Der Replikationsfaktor, den Sie für jeden Schlüsselbereich separat konfigurieren, bestimmt die Anzahl der Datenreplikate, die in jedem Rechenzentrum im Cluster gespeichert werden. Beispielsweise wird in der Regel ein Replikationsfaktor von 3 verwendet, um einen sinnvollen Ausgleich zwischen Langlebigkeit und Speichervolumen zu ermöglichen.
Das folgende Diagramm zeigt in vereinfachter Form einen Cluster mit sechs Knoten, wobei der Schlüsselbereich jedes Knotens in fünf VNode-Knoten unterteilt ist. In der Praxis können mehr Knoten vorhanden sein, meist sind auch mehr VNode-Knoten erforderlich.

Im obigen Diagramm ist der Pfad eines Schreibvorgangs mit der Konsistenzebene QUORUM dargestellt, der von einer Clientanwendung oder einem Clientdienst stammt (Client). Für dieses Diagramm werden die Schlüsselbereiche in alphabetischer Form angezeigt. In der Praxis sind die Tokens, die durch einen Hash des Primärschlüssels generiert werden, sehr große signierte Ganzzahlen.
In diesem Beispiel ist der Schlüsselhash M und die VNnode-Knoten für M befinden sich auf den Knoten 2, 4 und 6. Der Koordinator muss mit jedem Knoten Kontakt aufnehmen, auf dem die Bereiche des Hashschlüssels lokal gespeichert werden, damit der Schreibvorgang verarbeitet werden kann. Da die Konsistenzebene QUORUM ist, müssen zwei Replikate (die Mehrheit) auf den Koordinatorknoten antworten, damit der Client benachrichtigt wird, dass der Schreibvorgang abgeschlossen ist.
Im Gegensatz zu Bigtable erfordert das Verschieben oder Ändern von Schlüsselbereichen in Cassandra, dass die Daten physisch von einem Knoten zu einem anderen kopiert werden. Wenn ein Knoten mit Anfragen für einen bestimmten Tokenhashbereich überlastet ist, ist in Cassandra das Hinzufügen zusätzlicher Verarbeitungskapazität für diesen Tokenbereich komplexer als in Bigtable.
Geografische Replikation und Konsistenz
Bigtable und Cassandra handhaben geografische Replikation (auch als multiregionale Replikation bezeichnet) und Konsistenz unterschiedlich. Ein Cassandra-Cluster besteht aus Verarbeitungsknoten, die in Rechenzentren gruppierten Racks zusammengefasst sind. Cassandra basiert auf einer Strategie der Netzwerktopologie, für die Sie konfigurieren müssen, wie Replikate von VNode-Knoten auf Hosts in einem Rechenzentrum verteilt werden. Diese Strategie geht auf anfängliche Nutzung von Cassandra als Datenbank zurück, die ursprünglich in physischen lokalen Rechenzentren bereitgestellt wurde. Diese Konfiguration definiert auch den Replikationsfaktor für jedes Rechenzentrum im Cluster.
In Cassandra wird mithilfe der Rechenzentrums- und Rack-Konfiguration versucht, die Fehlertoleranz der Datenreplikate zu verbessern. Bei Lese- und Schreibvorgängen bestimmt die Topologie die Teilnehmerknoten, die für die Gewährleistung der Konsistenz erforderlich sind. Wenn Sie einen Cluster erstellen oder erweitern, müssen Sie Knoten, Racks und Rechenzentren manuell konfigurieren. In einer Cloud-Umgebung gilt für eine typische Cassandra-Bereitstellung eine Cloud-Zone als Rack und eine Cloud-Region als Rechenzentrum.
Mit den Quorumsteuerelementen von Cassandra können Sie die Gewährleistung der Konsistenz für jeden Lese- oder Schreibvorgang anpassen. Der Grad an Eventual Consistency kann variieren. Dazu gehören Optionen, die einen einzelnen Replikatknoten (ONE), eine Mehrheit von Replikatknoten für ein einzelnes Rechenzentrum (LOCAL_QUORUM) oder eine Mehrheit aller Replikatknoten in allen Rechenzentren (QUORUM) benötigen.
In Bigtable sind Cluster zonale Ressourcen. Eine Bigtable-Instanz kann einen einzelnen Cluster enthalten oder aus einer Gruppe von vollständig replizierten Clustern bestehen. Sie können Instanzcluster in jeder Kombination von Zonen in allen von Google Cloud angebotenen Regionen platzieren. Cluster lassen sich aus einer Instanz mit minimalen Auswirkungen auf andere Cluster in der Instanz hinzufügen und entfernen.
In Bigtable werden Schreibvorgänge (mit Read-Your-Writes-Konsistenz) auf einem einzelnen Cluster ausgeführt. Sie sind in den anderen Instanzclustern letztendlich konsistent. Da einzelne Zellen nach Zeitstempel versioniert werden, gehen keine Schreibvorgänge verloren, und jeder Cluster stellt die Zellen mit den neuesten verfügbaren Zeitstempeln bereit.
Der Dienst stellt den Clusterkonsistenzstatus dar. Die Cloud Bigtable API bietet ein Verfahren zum Abrufen eines Konsistenztokens auf Tabellenebene. Sie können mit diesem Token feststellen, ob alle Änderungen an dieser Tabelle vor dem Erstellen des Tokens vollständig repliziert wurden.
Transaktionsunterstützung
Auch wenn keine der beiden Datenbanken komplexe Transaktionen mit mehreren Zeilen unterstützt, bieten sie eine gewisse Transaktionsunterstützung.
Cassandra enthält eine Lightweight-Transaktion-Methode (LWT), die Atomarität für die Aktualisierung von Spaltenwerten in einer einzelnen Partition bietet. Cassandra hat außerdem eine Vergleichs- und Set-Semantik, mit der der Lesevorgang für Zeilen und der Wertevergleich vor Initiieren eines Schreibvorgangs ausgeführt werden.
Bigtable unterstützt vollständig konsistente, einzeilige Schreibvorgänge innerhalb eines Clusters. Transaktionen für einzelne Zeilen werden außerdem durch die Read-Modify-Write- und Check-Mutate-Vorgänge aktiviert. Multi-Cluster-Routing-Anwendungsprofile unterstützen keine Transaktionen für einzelne Zeilen.
Datenmodell
Sowohl Bigtable als auch Cassandra organisieren Daten in Tabellen, die Suchvorgänge und Bereichsscans anhand der eindeutigen Kennung der Zeile unterstützen. Beide Systeme sind spaltenorientierte NoSQL-Speicher.
In Cassandra müssen Sie mit CQL das vollständige Tabellenschema im Voraus erstellen. Dazu gehören die Primärschlüsseldefinition sowie die Festlegung der Spaltennamen und Spaltentypen. Primärschlüssel in Cassandra sind eindeutige zusammengesetzte Werte, die aus einem obligatorischen Partitionierungsschlüssel und einem optionalen Clusterschlüssel bestehen. Der Partitionierungsschlüssel bestimmt die Knotenplatzierung einer Zeile und der Clusterschlüssel legt die Sortierfolge innerhalb einer Partition fest. Beim Erstellen von Schemas müssen Sie beachten, dass die Ausführung effizienter Scans in einer einzelnen Partition mit den Systemkosten, die mit der Verwaltung großer Partitionen verbunden sind, abgestimmt werden muss.
In Bigtable müssen Sie nur die Tabelle erstellen und deren Spaltenfamilien im Voraus definieren. Spalten werden beim Erstellen von Tabellen nicht deklariert. Sie werden angelegt, wenn Anwendungs-API-Aufrufe Zellen zu Tabellenzeilen hinzufügen.
Zeilenschlüssel werden lexikografisch im Bigtable-Cluster angeordnet. Knoten in Bigtable weisen die Knotenzuständigkeit für Schlüsselbereiche automatisch zu. Diese werden oft als Tabellenreihen und manchmal auch als Aufteilungen bezeichnet. Bigtable-Zeilenschlüssel bestehen häufig aus mehreren Feldwerten, die mit einem von Ihnen ausgewählten gängigen Trennzeichen (z. B. das Prozentzeichen) verknüpft werden. Getrennt entsprechen die einzelnen Stringkomponenten den Feldern eines Cassandra-Primärschlüssels.
Zeilenschlüsseldesign
In Bigtable ist die eindeutige Kennung einer Tabellenzeile der Zeilenschlüssel. Der Zeilenschlüssel muss ein einzelner eindeutiger Wert für die gesamte Tabelle sein. Sie können mehrteilige Schlüssel erstellen und dafür unterschiedliche Elemente verketten, die durch ein gängiges Trennzeichen getrennt werden. Der Zeilenschlüssel bestimmt die globale Datensortierung einer Tabelle. Der Bigtable-Dienst ermittelt dynamisch die Schlüsselbereiche, die jedem Knoten zugewiesen werden.
Im Gegensatz zu Cassandra, wo der Hash des Partitionierungsschlüssels die Zeilenposition bestimmt und die Clustering-Spalten die Reihenfolge festlegen, bietet der Bigtable-Zeilenschlüssel sowohl eine Knotenzuweisung als auch eine entsprechende Sortierung. Wie bei Cassandra sollten Sie in Bigtable einen Zeilenschlüssel so festlegen, dass Zeilen, die Sie zusammen abrufen möchten, auch zusammen gespeichert werden. In Bigtable ist es jedoch nicht erforderlich, den Zeilenschlüssel für Platzierung und Sortierung festzulegen, bevor Sie eine Tabelle verwenden.
Datentypen
Der Bigtable-Dienst erzwingt keine Spaltendatentypen, die der Client sendet. Die Clientbibliotheken bieten Hilfsmethoden, mit denen Zellenwerte als Byte, als UTF-8-codierte Strings und als Big-Endian-codierte 64-Bit-Ganzzahlen geschrieben werden können. Für atomare inkrementelle Vorgänge sind Big-Endian-codierte Ganzzahlen erforderlich.
Spaltenfamilie
In Bigtable bestimmt eine Spaltenfamilie, welche Spalten in einer Tabelle gespeichert und gemeinsam abgerufen werden. Jede Tabelle benötigt mindestens eine Spaltenfamilie, wobei Tabellen häufig mehr Spaltenfamilien enthalten. Es sind maximal 100 Spaltenfamilien pro Tabelle möglich. Sie müssen Spaltenfamilien explizit erstellen, bevor eine Anwendung diese in einem Vorgang verwenden kann.
Spaltenqualifizierer
Jeder Wert, der in einer Tabelle mit einem Zeilenschlüssel gespeichert ist, wird mit einem Label namens Spaltenqualifizierer verknüpft. Da Spaltenqualifizierer ausschließlich Labels sind, gibt es für die Anzahl der Spalten einer Spaltenfamilie praktisch keine Beschränkung. Spaltenqualifizierer werden in Bigtable häufig dafür verwendet, um Anwendungsdaten darzustellen.
Zellen
In Bigtable ist eine Zelle die Schnittstelle des Zeilenschlüssels und des Spaltennamens (eine Spaltenfamilie in Kombination mit einem Spaltenqualifizierer). Jede Zelle enthält einen oder mehrere Zeitstempelwerte, die vom Client bereitgestellt oder automatisch vom Dienst angewendet werden. Alte Zellenwerte werden auf Grundlage einer Richtlinie zur automatischen Speicherbereinigung zurückgewonnen, die auf der Ebene der Spaltenfamilie konfiguriert wird.
Sekundäre Indexe
Sie können kontinuierliche materialisierte Ansichten als asynchrone sekundäre Indexe für Tabellen verwenden, um dieselben Daten mit verschiedenen Suchmustern oder Attributen abzufragen. Weitere Informationen finden Sie unter Asynchronen sekundären Index erstellen.
Load-Balancing und Failover von Clients
In Cassandra steuert der Client das Load-Balancing von Anfragen. Der Clienttreiber legt eine Richtlinie fest, die entweder als Teil der Konfiguration oder programmatisch bei der Sitzungserstellung festgelegt wird. Der Cluster gibt für die Richtlinie die Rechenzentren an, die der Anwendung am nächsten sind, und der Client ermittelt Knoten aus diesen Rechenzentren für einen Vorgang.
Der Bigtable-Dienst leitet API-Aufrufe an einen Zielcluster anhand eines Parameters (die Anwendungsprofil-ID) weiter, der bei jedem Vorgang bereitgestellt wird. Anwendungsprofile werden im Bigtable-Dienst verwaltet. Für Clientvorgänge, bei denen kein Profil ausgewählt wird, verwenden Sie ein Standardprofil.
Bigtable enthält zwei Arten von Routingrichtlinien für Anwendungsprofile: Single-Cluster-Routing und Multi-Cluster-Routing. Ein Multi-Cluster-Profil leitet Vorgänge an den nächstgelegenen verfügbaren Cluster weiter. Cluster in einer Region werden aus Sicht des Vorgangs-Routers als äquidistant eingestuft. Wenn der Knoten, der für den angeforderten Schlüsselbereich zuständig ist, überlastet oder in einem Cluster vorübergehend nicht verfügbar ist, bietet dieser Profiltyp automatisches Failover.
Bei Cassandra bietet eine Multi-Cluster-Richtlinie die Failover-Vorteile einer Load-Balancing-Richtlinie, die Rechenzentren erfasst.
Ein Anwendungsprofil mit Single-Cluster-Routing leitet den gesamten Traffic an einen einzigen Cluster weiter. Strikte Zeilenkonsistenz und Transaktionen für einzelne Zeilen sind nur in Profilen mit Single-Cluster-Routing verfügbar.
Der Nachteil eines Single-Cluster-Ansatzes besteht darin, dass bei einem Failover entweder die Anwendung in der Lage sein muss, den Vorgang mithilfe mit einer anderen Anwendungsprofil-ID zu wiederholen, oder Sie für betroffene Single-Cluster-Routingprofile das Failover manuell ausführen müssen.
Vorgangsrouting
Cassandra und Bigtable verwenden unterschiedliche Methoden, um den Verarbeitungsknoten für Lese- und Schreibvorgänge auszuwählen. In Cassandra wird dafür der Partitionierungsschlüssel ermittelt, während in Bigtable der Zeilenschlüssel verwendet wird.
In Cassandra prüft der Client zuerst die Load-Balancing-Richtlinie. Dieses clientseitige Objekt legt das Rechenzentrum fest, an das der Vorgang weitergeleitet wird.
Nachdem das Rechenzentrum ermittelt wurde, kontaktiert Cassandra einen Koordinatorknoten für die Verwaltung des Vorgangs. Wenn die Richtlinie Tokens erkennt, ist der Koordinator ein Knoten, der Daten aus der Ziel-VNode-Partition bereitstellt. Andernfalls ist der Koordinator ein zufälliger Knoten. Der Koordinatorknoten ermittelt die Knoten, in denen sich die Datenreplikate für den Vorgangspartitionsschlüssel befinden. Diese Knoten werden dann angewiesen, den Vorgang auszuführen.
In Bigtable erhält, wie bereits erwähnt, jeder Vorgang eine Anwendungsprofil-ID. Das Anwendungsprofil wird auf Dienstebene definiert. Die Bigtable-Routingebene prüft das Profil, um den entsprechenden Zielcluster für den Vorgang auszuwählen. Die Routingebene stellt dann einen Pfad für den Vorgang bereit, um mithilfe des Zeilenschlüssels des Vorgangs den richtigen Verarbeitungsknoten nutzen zu können.
Datenschreibvorgang
Beide Datenbanken sind für schnelle Schreibvorgänge optimiert und nutzen eine ähnliche Art des Schreibens. Die Schritte, die bei den Datenbanken ausgeführt werden, können jedoch leicht variieren, insbesondere für Cassandra. Je nach Betriebskonsistenzstufe ist möglicherweise die Kommunikation mit zusätzlichen Teilnehmerknoten erforderlich.
Nachdem die Schreibanfrage an die entsprechenden Knoten (Cassandra) oder an den Knoten (Bigtable) weitergeleitet wurde, werden die Schreibvorgänge zuerst in einem Commit-Log (Cassandra) oder in einem freigegebenen Log (Bigtable) nacheinander auf dem Laufwerk gespeichert. Als Nächstes werden die Schreibvorgänge in eine speicherinterne Tabelle eingefügt, auch als memtable bezeichnet, die wie die SSTables angeordnet ist.
Nach diesen beiden Schritten antwortet der Knoten, um anzugeben, dass der Schreibvorgang abgeschlossen ist. In Cassandra müssen mehrere Replikate (abhängig von der für jeden Vorgang festgelegten Konsistenzstufe) antworten, bevor der Koordinator den Client darüber informiert, dass der Schreibvorgang abgeschlossen ist. In Bigtable ist jeder Zeilenschlüssel zu einem bestimmten Zeitpunkt immer nur einem Knoten zugewiesen. Eine Antwort vom Knoten ist ausreichend, um zu bestätigen, dass ein Schreibvorgang erfolgreich war.
Später können Sie bei Bedarf die speicherinterne Tabelle in Form einer neuen SSTable auf das Laufwerk schreiben. Das Leeren des Speichers erfolgt in Cassandra, wenn das Commit-Log die maximale Größe erreicht hat oder wenn die speicherinterne Tabelle einen von Ihnen konfigurierten Schwellenwert überschreitet. In Bigtable wird ein solcher Vorgang zum Erstellen neuer immutable SSTables initiiert, wenn die vom Dienst festgelegte maximale Größe der speicherinternen Tabelle erreicht wurde. Zur Verdichtung werden regelmäßig SSTables für einen bestimmten Schlüsselbereich zu einer einzigen SSTable zusammengeführt.
Datenaktualisierungen
Beide Datenbanken verarbeiten Datenaktualisierungen in ähnlicher Weise. Cassandra unterstützt jedoch nur einen Wert für jede Zelle, während Bigtable eine große Anzahl versionierter Werte für jede Zelle verwalten kann.
Wenn der Wert an der Schnittstelle einer eindeutigen Zeilenkennzeichnung und einer Spalte geändert wird, erfolgt die Aktualisierung wie zuvor im Abschnitt Datenschreibvorgang beschrieben. Der Schreibzeitstempel wird dann zusammen mit dem Wert in der SSTable-Struktur gespeichert.
Wenn Sie den Wert einer aktualisierten Zelle noch nicht in eine SSTable übertragen haben, können Sie nur den Zellenwert der speicherinternen Tabelle speichern. Die Datenbanken unterscheiden sich dann in den gespeicherten Elementen. Cassandra speichert nur den neuesten Wert in der speicherinternen Tabelle, während Bigtable alle Versionen in der speicherinternen Tabelle speichert.
Alternativ werden, wenn Sie mindestens eine Version eines Zellenwerts auf ein Laufwerk in separate SSTables übertragen haben, die Anfragen für diese Daten von den Datenbanken unterschiedlich verarbeitet. Wenn die Zelle von Cassandra angefordert wird, wird nur der neueste Wert gemäß Zeitstempel zurückgegeben. Das heißt also, dass nur der letzte Schreibvorgang verfügbar ist. In Bigtable können Sie Filter verwenden, um festzulegen, welche Zellenversionen für eine Leseanfrage zurückgegeben werden.
Zeilen löschen
Da bei beiden Datenbanken Daten in unveränderlichen SSTable-Dateien auf dem Laufwerk gespeichert werden, kann eine Zeile nicht sofort gelöscht werden. Das Verfahren, das dafür sorgen soll, dass Abfragen nach dem Löschen einer Zeile die richtigen Ergebnisse zurückgeben, ist bei beiden Datenbanken gleich. Als Erstes wird der speicherinternen Tabelle eine Markierung (in Cassandra auch als Tombstone bezeichnet) hinzugefügt. Schließlich erhält eine neu geschriebene SSTable eine Zeitstempelmarkierung, die angibt, dass die eindeutige Zeilenkennzeichnung gelöscht wurde und nicht in Abfrageergebnissen zurückgegeben werden soll.
Gültigkeitsdauer
Die Funktionen für die Gültigkeitsdauer (Time to Live, TTL) sind in den beiden Datenbanken mit einer Ausnahme gleich. In Cassandra können Sie die Gültigkeitsdauer für eine Spalte oder für eine Tabelle festlegen. Für Bigtable lässt sich die Gültigkeitsdauer nur für die Spaltenfamilie angeben. In Bigtable gibt es auch die Möglichkeit, die Gültigkeitsdauer auf Zellenebene zu simulieren.
Automatische Speicherbereinigung
Da das sofortige Aktualisieren und Löschen von Daten mit unveränderlichen SSTables wie oben beschrieben nicht möglich ist, wird eine automatische Speicherbereinigung im Rahmen eines Vorgangs ausgeführt, der als Verdichtung bezeichnet wird. Bei diesem Vorgang werden Zellen oder Zeilen entfernt, die nicht in Abfrageergebnissen enthalten werden sollen.
Bei der automatischen Speicherbereinigung wird eine Zeile oder Zelle ausgeschlossen, wenn eine SSTable-Zusammenführung vorhanden ist. Wenn es für eine Zeile eine Markierung oder ein Tombstone gibt, wird diese Zeile nicht in die Ergebnistabelle aufgenommen. Bei beiden Datenbanken kann eine Zelle aus der zusammengeführten SSTable ausgeschlossen werden. So schließen die Datenbanken eine Zelle aus, wenn der Zellenzeitstempel eine festgelegte Gültigkeitsdauer überschreitet. Wenn es für eine bestimmte Zelle zwei Versionen mit Zeitstempel gibt, übernimmt Cassandra nur den neuesten Wert in die zusammengeführte SSTable.
Datenlesepfad
Wenn ein Lesevorgang den entsprechenden Verarbeitungsknoten erreicht, ist dieser Lesevorgang zum Abrufen von Daten für ein Abfrageergebnis bei beiden Datenbanken identisch.
Für jede SSTable auf dem Laufwerk, die möglicherweise Abfrageergebnisse enthält, wird über einen Bloom-Filter geprüft, ob die einzelnen Dateien Zeilen enthalten, die zurückgegeben werden sollen. Da Bloom-Filter auf keinen Fall einen falsch negativen Wert bereitstellen, werden alle infrage kommenden SSTables einer Kandidatenliste für die weitere Verarbeitung der Ergebnisse hinzugefügt.
Der Lesevorgang wird mithilfe einer zusammengeführten Ansicht ausgeführt, die aus der speicherinternen Tabelle und den Kandidaten-SSTables auf dem Laufwerk erstellt wird. Da alle Schlüssel lexikografisch sortiert sind, kann so auf effiziente Weise eine zusammengeführte Ansicht abgerufen werden, die auf Abfrageergebnisse gescannt wird.
In Cassandra ist dafür eine Reihe von durch die Konsistenzebene des Vorgangs bestimmten Verarbeitungsknoten für den Vorgang erforderlich. In Bigtable muss nur der für den Schlüsselbereich zuständige Knoten kontaktiert werden. Bei Cassandra müssen Sie die Auswirkungen auf die Computing-Größe beachten, da die Lesevorgänge wahrscheinlich durch mehrere Knoten verarbeitet werden.
Leseergebnisse können auf dem Verarbeitungsknoten auf unterschiedliche Weise beschränkt sein.
In Cassandra beschränkt die WHERE-Klausel einer CQL-Abfrage die zurückgegebenen Zeilen. Möglicherweise werden die Ergebnisse auch durch Spalten im Primärschlüssel oder durch in einem sekundären Index enthaltene Spalten beschränkt.
Bigtable bietet eine Vielzahl an Filtern, die Auswirkungen auf die Zeilen oder Zellen haben, die von einer Leseabfrage abgerufen werden.
Es gibt drei Filterkategorien:
- Einschränkende Filter, die Zeilen und Zellen der Antwort festlegen.
- Änderungsfilter, die sich auf die Daten oder Metadaten einzelner Zellen auswirken.
- Zusammengesetzte Filter, mit denen Sie mehrere Filter zu einem Filter kombinieren können.
Am häufigsten werden einschränkende Filter angewendet, beispielsweise durch einen regulären Ausdruck für Spaltenfamilien und einen regulären Ausdruck für Spaltenqualifizierer.
Physische Datenspeicher
Bigtable und Cassandra speichern beide Daten in SSTables, die im Zuge einer Verdichtungsphase regelmäßig zusammengeführt werden. Die Komprimierung von SSTable-Daten bietet ähnliche Möglichkeiten für das Reduzieren der Speichergröße. Diese Komprimierung wird in Bigtable automatisch angewendet und ist in Cassandra eine Konfigurationsoption.
Für den Vergleich der beiden Datenbanken müssen Sie wissen, wie jede Datenbank die Daten unter folgenden Aspekten physisch speichert:
- Strategie zur Datenverteilung
- Anzahl der verfügbaren Zellenversionen
- Speichertyp
- Verfahren für Langlebigkeit und Replikation von Daten
Datenverteilung
In Cassandra ist ein konsistenter Hash der Partitionsspalten des Primärschlüssels die empfohlene Methode zur Festlegung der Datenverteilung über die verschiedenen SSTables, die durch Clusterknoten bereitgestellt werden.
Bigtable verwendet ein Variablenpräfix für den vollständigen Zeilenschlüssel, um Daten lexikografisch in SSTables zu platzieren.
Zellversionen
Cassandra behält nur eine aktive Zellenwertversion bei. Wenn zwei Schreibvorgänge in eine Zelle ausgeführt werden, sorgt die Richtlinie „Last-Write-wins“ dafür, dass nur ein Wert zurückgegeben wird.
In Bigtable ist die Anzahl der Zeitstempelversionen für jede Zelle nicht begrenzt. Möglicherweise gelten aber andere Zeilengrößenlimits. Wenn es in der Clientanfrage nicht festgelegt ist, wird der Zeitstempel vom Bigtable-Dienst für den Zeitpunkt ermittelt, an dem der Verarbeitungsknoten die Mutation erhält. Zellenversionen können mit einer Richtlinie für die automatische Speicherbereinigung bereinigt werden. Diese kann sich für die Spaltenfamilie der einzelnen Tabellen unterscheiden oder aus einem von der API festgelegten Abfrageergebnis gefiltert werden.
Festplattenspeicher
Cassandra speichert SSTables auf Laufwerken, die an die Clusterknoten angehängt sind. Wenn Sie Daten in Cassandra ausgleichen möchten, müssen die Dateien physisch zwischen Servern kopiert werden.
Bigtable verwendet Colossus zum Speichern von SSTables. Dank diesem verteilten Dateisystem kann der Bigtable-Dienst SSTables beinahe sofort anderen Knoten neu zuweisen.
Langlebigkeit und Replikation von Daten
In Cassandra wird die Langlebigkeit von Daten über die Einstellung des Replikationsfaktors definiert. Der Replikationsfaktor bestimmt die Anzahl der SSTable-Kopien, die auf verschiedenen Knoten im Cluster gespeichert werden. Eine typische Einstellung für den Replikationsfaktor ist der Wert 3. Dieser garantiert eine striktere Konsistenz mit QUORUM oder LOCAL_QUORUM, auch wenn ein Knotenfehler auftritt.
Bigtable garantiert über die Replikation von Colossus eine hohe Datenlanglebigkeit.
Das folgende Diagramm veranschaulicht das physische Datenlayout, Computing-Verarbeitungsknoten und die Routingebene für Bigtable:

In der Speicherschicht von Colossus hat jeder Knoten die Aufgabe, die in einer Reihe von SSTables gespeicherten Daten bereitzustellen. Diese SSTables enthalten die Daten für die Zeilenschlüsselbereiche, die jedem Knoten dynamisch zugewiesen werden. Im Diagramm sind für jeden Knoten drei SSTables aufgeführt. In der Regel gibt es aber mehr SSTables, da diese kontinuierlich erstellt werden, wenn die Knoten neue Datenänderungen erhalten.
Jeder Knoten hat ein freigegebenes Log. Die Schreibvorgänge, die ein Knoten verarbeitet, werden sofort im freigegebenen Log festgehalten, bevor der Client eine Schreibbestätigung erhält. Da ein Schreibvorgang in Colossus mehrfach repliziert wird, ist die Langlebigkeit auch dann gewährleistet, wenn im Knoten Hardwarefehler auftreten, bevor die Daten in einer SSTable für den Zeilenbereich gespeichert werden.
Anwendungsschnittstellen
Ursprünglich war der Cassandra-Datenbankzugriff über eine Thrift API verfügbar. Diese Zugriffsmethode wurde aber verworfen. Empfohlen wird nun die Clientinteraktion über CQL.
Ähnlich wie mit der ursprünglichen Thrift API von Cassandra wird der Bigtable-Datenbankzugriff über eine API bereitgestellt, die Daten anhand der bereitgestellten Zeilenschlüssel liest und schreibt.
Wie Cassandra enthält auch Bigtable eine Befehlszeile namens cbt sowie Clientbibliotheken, die viele gängige Programmiersprachen unterstützen. Diese Bibliotheken basieren auf gRPC und REST APIs. Anwendungen, die für Hadoop geschrieben sind und denen die Open-Source-HBase-Bibliothek von Apache für Java zugrunde liegt, können ohne spezielle Anpassung eine Verbindung zu Bigtable herstellen. Für Anwendungen, die keine HBase-Kompatibilität benötigen, empfehlen wir die Verwendung des integrierten Bigtable-Java-Clients.
Die IAM-Steuerelemente (Identity and Access Management) von Bigtable sind vollständig in Google Cloudeingebunden. Tabellen können auch als externe Datenquelle von BigQuery verwendet werden.
Datenbank einrichten
Wenn Sie einen Cassandra-Cluster einrichten, müssen Sie verschiedene Konfigurationen festlegen und die entsprechenden Schritte ausführen. Zuerst konfigurieren Sie Ihre Serverknoten so, dass sie Computing-Kapazität und lokalen Speicher bereitstellen. Wenn Sie einen Replikationsfaktor von drei verwenden – die empfohlene und am häufigsten verwendete Einstellung –, müssen Sie so viel Speicher bereitstellen, dass dreimal so viel Daten wie für Ihren Cluster vorgesehen gespeichert werden können. Außerdem müssen Sie Konfigurationen für VNodes, Racks und Replikation ermitteln und festlegen.
Die Trennung von Computing und Speicherung in Bigtable vereinfacht die Skalierung von Clustern in jeder Richtung im Vergleich zu Cassandra. In einem normal ausgeführten Cluster müssen Sie in der Regel nur auf den Gesamtspeicher achten, der von den verwalteten Tabellen belegt wird. Dieser bestimmt die Mindestanzahl an Knoten, um den aktuellen Wert für die Abfragen pro Sekunde zu gewährleisten.
Wenn der Cluster je nach Produktionslast über- oder unterdimensioniert ist, können Sie die Bigtable-Clustergröße auf einfache Weise anpassen.
Bigtable-Speicher
Abgesehen vom geografischen Speicherort des ersten Clusters müssen Sie beim Erstellen einer Bigtable-Instanz nur den Speichertyp auswählen. Bigtable bietet zwei Optionen für die Speicherung: SSDs (Solid-State Drives) und Festplattenlaufwerke (HDDs). Alle Cluster in einer Instanz müssen den gleichen Speichertyp haben.
Bei der Bereitstellung von Speicher mit Bigtable spielen Speicherreplikate nicht die gleiche Rolle wie bei der Festlegung der Größe eines Cassandra-Clusters. Für die Gewährleistung von Fehlertoleranz kommt es hier nicht zum Verlust an Speicherdichte wie bei Cassandra. Da der Speicher nicht ausdrücklich bereitgestellt werden muss, wird Ihnen außerdem nur der genutzte Speicher berechnet.
SSD
Die Kapazität des SSD-Knotens von 5 TB, die für die meisten Arbeitslasten bevorzugt wird, bietet eine höhere Speicherdichte als die empfohlene Konfiguration für Cassandra-Maschinen, die eine praktische Speicherdichte von weniger als 2 TB pro Knoten hat. Bei der Bewertung der Speicherkapazität ist zu beachten, dass bei Bigtable nur eine Kopie der Daten berücksichtigt wird. Im Vergleich dazu müssen bei Cassandra bei den meisten Konfigurationen drei Kopien der Daten einbezogen werden.
Der Wert für Schreibabfragen pro Sekunde für SSDs entspricht ungefähr dem für HDDs. SSDs bieten aber deutlich höhere Abfragewerte für Leseabfragen als HDDs. Die Preise für SSD-Speicher entsprechen ungefähr den Kosten für bereitgestellten nichtflüchtigen SSD-Speicher und sind von der jeweiligen Region abhängig.
HDD
Der HDD-Speichertyp ermöglicht eine hohe Speicherdichte: 16 TB pro Knoten. Dieser Typ hat den Nachteil, dass zufällige Lesevorgänge erheblich langsamer sind und nur das Lesen von 500 Zeilen pro Sekunde für jeden Knoten unterstützt wird. HDD wird für schreibintensive Arbeitslasten bevorzugt, bei denen für Lesevorgänge von Bereichscans mit Batchverarbeitung ausgegangen wird. Die Preise für HDD-Speicher entsprechen ungefähr den Kosten für Cloud Storage und variieren je nach Region.
Überlegungen zur Clustergröße
Wenn Sie die Größe einer Bigtable-Instanz im Rahmen der Vorbereitung der Migration einer Cassandra-Arbeitslast festlegen, müssen Sie beim Vergleich von Cassandra-Clustern in einem einzelnen Rechenzentrum mit Bigtable-Instanzen in einem einzelnen Cluster und von Cassandra-Clustern in mehreren Rechenzentren mit Bigtable-Instanzen in mehreren Clustern verschiedene Aspekte berücksichtigen. Bei den Leitlinien in den folgenden Abschnitten wird davon ausgegangen, dass für die Migration keine größeren Änderungen des Datenmodells erforderlich sind und dass zwischen Cassandra und Bigtable eine entsprechende Speicherkomprimierung erfolgt.
Ein Cluster in einem Rechenzentrum
Wenn Sie einen Cluster in einem einzelnen Rechenzentrum mit einer Bigtable-Instanz in einem einzelnen Cluster vergleichen, müssen Sie als Erstes die Speicheranforderungen prüfen. Sie können dazu die nicht replizierte Größe jedes Schlüsselbereichs mithilfe des Befehls nodetool tablestats abschätzen und die gesamte Größe des übertragenen Speichers durch den Replikationsfaktor des Schlüsselbereichs teilen. Anschließend teilen Sie den nicht replizierten Speicherplatz aller Schlüsselbereiche durch 3,5 TB (5 TB * 0,70), um die empfohlene Anzahl an SSD-Knoten zu ermitteln, die den Speicher allein verarbeiten sollen. Wie bereits erwähnt, sorgt Bigtable für Speicherreplikation und -langlebigkeit auf einer separaten Ebene, die für den Nutzer aber transparent ist.
Als Nächstes sollten Sie die Computing-Anforderungen für die Anzahl der Knoten prüfen. Sie können dafür anhand der Messwerte der Server- und Clientanwendung in Cassandra die ungefähre Anzahl der ausgeführten Lese- und Schreibvorgänge ermitteln. Um die Mindestzahl an SSD-Knoten für die Ausführung einer Arbeitslast abzuschätzen, teilen Sie diesen Messwert durch 10.000. Wahrscheinlich benötigen Sie mehr Knoten für Anwendungen, für die Abfrageergebnisse mit niedriger Latenz erforderlich sind. Google empfiehlt, die Leistung von Bigtable mit repräsentativen Daten und Abfragen zu testen, um den Messwert für die Abfragen pro Sekunde pro Knoten zu ermitteln, der für Ihre Arbeitslast möglich sind.
Die Anzahl der Knoten, die für den Cluster erforderlich sind, sollte der größten angenommenen Speicher- und Computing-Anforderung entsprechen. Wenn Sie sich nicht sicher sind, welchen Speicher oder Durchsatz Sie benötigen, können Sie die Anzahl der Bigtable-Knoten mit der Anzahl der typischen Cassandra-Maschinen abgleichen. Bigtable-Cluster lassen sich mit minimalem Aufwand und ohne Ausfallzeiten gemäß den Anforderungen der Arbeitslast hoch- oder herunterskalieren.
Ein Cluster in mehreren Rechenzentren
Bei Clustern in mehreren Rechenzentren ist die Konfiguration einer Bigtable-Instanz etwas komplexer. Idealerweise sollte für jedes Rechenzentrum in der Cassandra-Topologie ein Cluster auf der Instanz vorhanden sein. Jeder Bigtable-Cluster in der Instanz muss alle Daten innerhalb der Instanz speichern und in der Lage sein, die gesamte Einfügungsrate für den kompletten Cluster zu verarbeiten. Cluster in einer Instanz können in jeder unterstützten Cloud-Region weltweit erstellt werden.
Die Methode zum Abschätzen der Speicheranforderungen entspricht dem Ansatz für Cluster in einem einzelnen Rechenzentrum. Mit nodetool ermitteln Sie die Speichergröße jedes Schlüsselbereichs im Cassandra-Cluster und teilen dann diesen Wert durch die Anzahl der Replikate. Beachten Sie, dass der Schlüsselbereich einer Tabelle für jedes Rechenzentrum unterschiedliche Replikationsfaktoren haben kann.
Die Anzahl der Knoten in jedem Cluster einer Instanz sollte alle Schreibvorgänge im Cluster und alle Lesevorgänge für mindestens zwei Rechenzentren verarbeiten können, um die Service Level Objectives (SLOs) während eines Clusterausfalls zu gewährleisten. Ein gängiger Ansatz besteht darin, mit allen Clustern zu starten, die die Knotenkapazität des am meisten genutzten Rechenzentrums im Cassandra-Cluster haben. Bigtable-Cluster auf einer Instanz können individuell skaliert werden, um Arbeitslastanforderungen ohne Ausfallzeiten zu erfüllen.
Verwaltung
Bigtable bietet vollständig verwaltete Komponenten für allgemeine Verwaltungsfunktionen von Cassandra.
Sichern und wiederherstellen
Bigtable bietet zwei Methoden zur Gewährleistung der allgemeinen Sicherungsanforderungen: Bigtable-Sicherungen und verwaltete Datenexporte.
Bigtable-Sicherungen entsprechen einer verwalteten Version der nodetool-Snapshot-Funktion von Cassandra.
Aus Bigtable-Sicherungen werden wiederherstellbare Kopien einer Tabelle erstellt und als Mitgliederobjekte eines Clusters gespeichert. Sie können Sicherungen als neue Tabelle in dem Cluster wiederherstellen, der die Sicherung initiiert hat. Die Sicherungen sind so konzipiert, dass Wiederherstellungspunkte erstellt werden, wenn Beschädigungen auf Anwendungsebene auftreten. Die Sicherungen, die Sie mit diesem Dienstprogramm erstellen, verbrauchen keine Knotenressourcen und werden ungefähr zum Cloud Storage-Preis abgerechnet. Sie können Bigtable-Sicherungen programmatisch oder über die Google Cloud Konsole für Bigtable aufrufen.
Eine weitere Möglichkeit zur Sicherung von Bigtable ist die Verwendung eines verwalteten Datenexports nach Cloud Storage. Sie können in die Dateiformate Avro, Parquet oder Hadoop Sequence exportieren. Im Vergleich zu Bigtable-Sicherungen dauern Exporte länger und es fallen zusätzliche Computing-Kosten an, da für die Exporte Dataflow verwendet wird. Mit diesen Exporten werden aber portierbare Datendateien erstellt, die Sie offline abfragen oder in ein anderes System importieren können.
Größe anpassen
Da bei Bigtable Speicher und Computing getrennt sind, können Sie Bigtable-Knoten je nach Abfragebedarf nahtloser hinzufügen oder entfernen, als dies in Cassandra möglich ist. Aufgrund der homogenen Architektur von Cassandra müssen Sie dort Knoten (oder VNode-Knoten) auf den gesamten Maschinen im Cluster ausgleichen.
Sie können die Clustergröße manuell in der Google Cloud Console oder programmatisch mit der Cloud Bigtable API ändern. Das Hinzufügen von Knoten zu einem Cluster kann zu einer erheblichen Leistungsverbesserung innerhalb weniger Minuten führen. Einige Kunden haben erfolgreich ein Open-Source-Autoscaling von Spotify angewendet.
Interne Wartung
Der Bigtable-Dienst kann problemlos allgemeine Cassandra-interne Wartungsaufgaben wie z. B. Betriebssystem-Patching, Knotenwiederherstellung, Knotenreparatur, Monitoring der Speicherverdichtung sowie Rotation von SSL-Zertifikaten ausführen.
Monitoring
Bigtable ermöglicht eine Messwertvisualisierung und -benachrichtigung ohne speziellen Verwaltungs- oder Entwicklungsaufwand. DieGoogle Cloud -Console-Seite von Bigtable enthält vorkonfigurierte Dashboards, mit denen Sie die Messwerte zu Durchsatz und Auslastung auf Instanz-, Cluster- und Tabellenebene verfolgen können. Benutzerdefinierte Ansichten und Benachrichtigungen können in den Cloud Monitoring-Dashboards erstellt werden, in denen Messwerte automatisch verfügbar sind.
Mit Key Visualizer in Bigtable, einem Monitoring-Feature in der Google Cloud Console, haben Sie die Möglichkeit, eine erweiterte Leistungsoptimierung vorzunehmen.
IAM und Sicherheit
In Bigtable ist die Autorisierung vollständig in das IAM-Framework vonGoogle Cloudeingebunden. Sie erfordert deshalb nur eine minimale Einrichtung und Wartung. Lokale Nutzerkonten und Passwörter werden nicht für Clientanwendungen freigegeben. Stattdessen werden Nutzern und Dienstkonten auf Organisationsebene detaillierte Berechtigungen und Rollen gewährt.
Bigtable verschlüsselt automatisch alle inaktiven und übertragenen Daten. Dies kann nicht deaktiviert werden. Der gesamte administrative Zugriff wird vollständig protokolliert. Mit VPC Service Controls können Sie den Zugriff auf Bigtable-Instanzen außerhalb von genehmigten Netzwerken steuern.
Nächste Schritte
- Erfahren Sie mehr über das Bigtable-Schemadesign.
- Codelab zu Bigtable für Cassandra-Nutzer ausführen
- Erfahren Sie mehr über den Bigtable-Emulator.
- Referenzarchitekturen, Diagramme und Best Practices zu Google Cloud kennenlernen. Weitere Informationen zu Cloud Architecture Center