将 Cloud Storage 数据加载到 BigQuery 中
您可以使用适用于 Cloud Storage 的 BigQuery Data Transfer Service 连接器将数据从 Cloud Storage 加载到 BigQuery。借助 BigQuery Data Transfer Service,您可以安排周期性转移作业,以将 Cloud Storage 中的最新数据添加到 BigQuery 中。
准备工作
创建 Cloud Storage 数据转移作业之前,请执行以下操作:
- 验证您是否已完成启用 BigQuery Data Transfer Service 中要求的所有操作。
- 检索您的 Cloud Storage URI。
- 创建 BigQuery 数据集来存储数据。
- 为数据转移作业创建目标表并指定架构定义。
- 如果您计划指定客户管理的加密密钥 (CMEK),请确保您的服务账号有权加密和解密,并且您拥有使用 CMEK 所需的 Cloud KMS 密钥资源 ID。如需了解 CMEK 如何与 BigQuery Data Transfer Service 搭配使用,请参阅使用转移作业指定加密密钥。
限制
从 Cloud Storage 到 BigQuery 的周期性数据转移作业受到以下限制:
- 数据转移作业中所有与通配符或运行时参数定义的模式匹配的文件都必须共用您已为目标表定义的相同架构,否则该转移作业将失败。如果表架构在多次运行期间发生更改,也会导致转移作业失败。
- 由于可以对 Cloud Storage 对象进行版本控制,因此请务必注意,BigQuery 数据转移作业不支持已归档的 Cloud Storage 对象。对象必须处于活跃状态才能被转移。
- 对于正在运行的数据转移作业,您必须先创建目标表,然后再设置转移作业,这一点与从 Cloud Storage 到 BigQuery 的各个数据加载作业不同。对于 CSV 和 JSON 文件,您还必须提前定义表架构。BigQuery 无法在周期性数据转移过程中创建表。
- 默认情况下,Cloud Storage 中的数据转移作业会将写入偏好设置参数设为
APPEND。在此模式下,未修改的文件只能加载到 BigQuery 中一次。如果文件的last modification time属性更新,文件将重新加载。 如果 Cloud Storage 文件在数据转移期间进行了修改,则 BigQuery Data Transfer Service 不保证转移所有文件或仅转移一次。将数据从 Cloud Storage 存储桶加载到 BigQuery 时,需要遵循以下限制:
BigQuery 不保证外部数据源的数据一致性。在查询运行的过程中,底层数据的更改可能会导致意外行为。
BigQuery 不支持 Cloud Storage 对象版本控制。如果您在 Cloud Storage URI 中添加了世代编号,则加载作业将失败。
另外,可能还存在其他限制,具体取决于 Cloud Storage 源数据的格式。有关详情,请参阅:
您的 Cloud Storage 存储桶必须位于与 BigQuery 中目标数据集的单区域或多区域兼容的位置。这称为“共置”。如需了解详情,请参阅 Cloud Storage 转移作业数据位置。
最短间隔时间
- 系统会立即选择源文件进行数据转移,源文件没有最短的期限。
- 周期性数据转移作业之间的最短间隔时间为 15 分钟。周期性数据转移作业的默认间隔时间为 24 小时。
- 您可以设置事件驱动型转移,以自动安排以更短间隔进行的数据转移。
所需权限
在将数据加载到 BigQuery 时,您需要拥有相关权限,才能将数据加载到新的或现有的 BigQuery 表和分区中。如果要从 Cloud Storage 加载数据,您还需要拥有对您的数据所在的存储桶的访问权限。确保您拥有以下必要的权限:
所需 BigQuery 角色
如需获得创建 BigQuery Data Transfer Service 数据转移作业所需的权限,请让您的管理员为您授予项目的 BigQuery Admin (roles/bigquery.admin) IAM 角色。
如需详细了解如何授予角色,请参阅管理对项目、文件夹和组织的访问权限。
此预定义角色可提供创建 BigQuery Data Transfer Service 数据转移作业所需的权限。如需查看所需的确切权限,请展开所需权限部分:
所需权限
创建 BigQuery Data Transfer Service 数据转移作业需要以下权限:
-
BigQuery Data Transfer Service 权限:
-
bigquery.transfers.update -
bigquery.transfers.get
-
-
BigQuery 权限:
-
bigquery.datasets.get -
bigquery.datasets.getIamPolicy -
bigquery.datasets.update -
bigquery.datasets.setIamPolicy -
bigquery.jobs.create
-
如需了解详情,请参阅授予 bigquery.admin 访问权限。
所需的 Cloud Storage 角色
您必须拥有针对单个存储桶的 storage.objects.get 权限,或更高级别的权限。如果要使用 URI 通配符,您必须拥有 storage.objects.list 权限。如果您要在每次成功转移后删除源文件,还需要拥有 storage.objects.delete 权限。预定义的 IAM 角色 storage.objectAdmin 具有所有的这些权限。
设置 Cloud Storage 转移作业
如需在 BigQuery Data Transfer Service 中创建 Cloud Storage 数据转移作业,请按下列步骤操作:
控制台
前往 Google Cloud 控制台中的“数据转移”页面。
点击 创建转移作业。
在来源类型部分的来源中,选择 Google Cloud Storage。
在转移配置名称部分的显示名称中,输入数据转移作业的名称,例如
My Transfer。转移作业名称可以是任何可让您在需要修改转移作业时识别该转移作业的名称。
在时间表选项部分,选择重复频率:
在目标设置部分的目标数据集中,选择您创建用来存储数据的数据集。
在数据源详细信息部分,执行以下操作:
- 在目标表部分,输入目标表的名称。 目标表必须遵循表命名规则。 目标表名称也支持使用参数。
- 在 Cloud Storage URI 字段中,输入 Cloud Storage URI。支持通配符和参数。如果 URI 与任何文件均不匹配,目标表中的数据也不会被覆盖。
在写入偏好设置字段中:
- 选择 APPEND 会采用增量方式将新数据附加到现有目标表。APPEND 是写入偏好设置的默认值。
- 选择 MIRROR 会在每次数据转移作业运行期间覆盖目标表中的数据。
如需详细了解 BigQuery Data Transfer Service 如何使用 APPEND 或 MIRROR 注入数据,请参阅 Cloud Storage 转移作业的数据注入。如需详细了解
writeDisposition字段,请参阅JobConfigurationLoad。如果您希望在每次数据转移作业成功完成后删除源文件,请选中在转移作业完成后删除源文件复选框。系统会尽力运行删除作业。如果首次删除源文件失败,则系统不会重试删除作业。
在转移选项部分,执行以下操作:
- 在所有格式下方:
- 在允许的错误数部分,输入 BigQuery 在运行作业时可以忽略的错误记录数上限。如果错误记录数超过此值,作业结果中将返回
invalid错误,并且作业将失败。默认值为0。 - (可选)在小数目标类型 (Decimal target types) 部分,输入一个源小数值可转换为的可能 SQL 数据类型的英文逗号分隔列表。选择用于转换的 SQL 数据类型取决于以下条件:
- 系统选择的数据类型将会是以下列表中第一个支持源数据的
精度和小数位数的数据类型(按以下顺序):
NUMERIC、BIGNUMERIC和STRING。 - 如果列出的数据类型均不支持相应精度和小数位数,系统会选择支持指定列表中最宽泛的范围的数据类型。如果在读取源数据时值超出支持的范围,将抛出错误。
- 数据类型
STRING支持所有精度和小数位数。 - 如果将此字段留空,对于 ORC,数据类型默认为
NUMERIC,STRING,对于其他文件格式,数据类型默认为NUMERIC。 - 此字段不能包含重复的数据类型。
- 系统会忽略此字段中所列数据类型的顺序。
- 系统选择的数据类型将会是以下列表中第一个支持源数据的
精度和小数位数的数据类型(按以下顺序):
- 在允许的错误数部分,输入 BigQuery 在运行作业时可以忽略的错误记录数上限。如果错误记录数超过此值,作业结果中将返回
- 在 JSON、CSV 下,如果您想让数据转移作业删除不符合目标表架构的数据,请选中忽略未知值复选框。
- 在 AVRO 下,如果您想让数据转移作业将 Avro 逻辑类型转换为相应的 BigQuery 数据类型,请选中 Use avro logical types(使用 Avro 逻辑类型)复选框。默认行为是忽略大多数类型的
logicalType属性,并改为使用基础 Avro 类型。 在 CSV 下方:
- 在字段分隔符部分,输入用于分隔字段的字符。默认值为英文逗号。
- 在引号字符部分,输入用于括起 CSV 文件中数据部分的字符。默认值为英文双引号 (
")。 - 对于要跳过的标题行数部分,如果您不想导入源文件中的标题行,请输入相应的标题行数。默认值为
0。 - 对于允许引用的数据中包含换行符部分,如果您想要允许在引用字段中使用换行符,请选中此复选框。
- 如果您想允许对缺少
NULLABLE列内容的行进行数据转移,请选中允许使用可选列留空的行复选框。
如需了解详情,请参阅仅适用于 CSV 的选项。
- 在所有格式下方:
在服务账号菜单中,从与您的 Google Cloud 项目关联的服务账号中选择一个服务账号。您可以将服务账号与数据转移作业相关联,而不是使用用户凭证。如需详细了解如何将服务账号用于数据转移作业,请参阅使用服务账号。
可选:在通知选项部分,执行以下操作:
可选:如果您使用 CMEK,请在高级选项部分中选择客户管理的密钥。系统会显示一系列可用的 CMEK 供您选择。如需了解 CMEK 如何与 BigQuery Data Transfer Service 搭配使用,请参阅为转移作业指定加密密钥。
点击保存。
bq
输入 bq mk 命令并提供转移作业创建标志 --transfer_config。此外,还必须提供以下标志:
--data_source--display_name--target_dataset--params
可选标志:
--destination_kms_key:如果您将客户管理的加密密钥 (CMEK) 用于此数据转移作业,请指定 Cloud KMS 密钥的密钥资源 ID。如需了解 CMEK 如何与 BigQuery Data Transfer Service 搭配使用,请参阅使用转移作业指定加密密钥。--service_account_name:指定用于 Cloud Storage 转移作业身份验证的服务账号,而不是您的用户账号。
bq mk \ --transfer_config \ --project_id=PROJECT_ID \ --data_source=DATA_SOURCE \ --display_name=NAME \ --target_dataset=DATASET \ --destination_kms_key="DESTINATION_KEY" \ --params='PARAMETERS' \ --service_account_name=SERVICE_ACCOUNT_NAME
其中:
- PROJECT_ID 是项目 ID。如果未提供
--project_id来指定具体项目,则系统会使用默认项目。 - DATA_SOURCE 是数据源,例如
google_cloud_storage。 - NAME 是数据转移作业配置的显示名称。转移作业名称可以是任何可让您在需要修改转移作业时识别该转移作业的名称。
- DATASET 是转移作业配置的目标数据集。
- DESTINATION_KEY:Cloud KMS 密钥资源 ID,例如
projects/project_name/locations/us/keyRings/key_ring_name/cryptoKeys/key_name。 - PARAMETERS 包含所创建转移作业配置的参数(采用 JSON 格式),例如:
--params='{"param":"param_value"}'。destination_table_name_template:目标 BigQuery 表的名称。data_path_template:包含待转移文件的 Cloud Storage URI。支持通配符和参数。write_disposition:确定是将匹配的文件附加到目标表还是完全镜像。支持的值为APPEND或MIRROR。如需了解 BigQuery Data Transfer Service 如何在 Cloud Storage 转移作业中附加或镜像数据,请参阅 Cloud Storage 转移作业的数据注入。file_format:您要转移的文件的格式。格式可以是CSV、JSON、AVRO、PARQUET或ORC。默认值为CSV。max_bad_records:对于任何file_format值,是可忽略的错误记录的数量上限。默认值为0。decimal_target_types:对于任何file_format值,是源小数值可转换为的可能 SQL 数据类型的英文逗号分隔列表。如果未提供此字段,对于ORC,数据类型默认为"NUMERIC,STRING",对于其他文件格式,数据类型默认为"NUMERIC"。ignore_unknown_values:对于任何file_format值,设置为TRUE,以接受包含与架构不匹配的值的行。如需了解详情,请参阅JobConfigurationLoad参考表中的ignoreUnknownvalues字段详细信息。use_avro_logical_types:对于AVROfile_format值,设置为TRUE,以将逻辑类型解释为其对应的类型(例如TIMESTAMP),而不仅仅是使用其原始类型(例如INTEGER)。parquet_enum_as_string:对于PARQUETfile_format值,设置为TRUE,以将PARQUETENUM逻辑类型推断为STRING,而不是默认的BYTES。parquet_enable_list_inference:对于PARQUETfile_format值,请设置为TRUE以专门将架构推断用于PARQUETLIST逻辑类型。reference_file_schema_uri:包含读取器架构的参考文件的 URI 路径。field_delimiter:对于CSVfile_format值,是用于分隔字段的字符。默认值为英文逗号。quote:对于CSVfile_format值,是用于括起 CSV 文件中数据部分的字符串。默认值为英文双引号 (")。skip_leading_rows:对于CSVfile_format值,表示您不想导入的前导标题行数。默认值为 0。allow_quoted_newlines:对于CSVfile_format值,设置为TRUE,以允许在引号字段中使用换行符。allow_jagged_rows:对于CSVfile_format值,设置为TRUE,以接受末尾处缺少可选列的行。缺少的值会填入NULL。preserve_ascii_control_characters:对于CSVfile_format值,设置为TRUE,以保留任何嵌入的 ASCII 控制字符。encoding:指定CSV编码类型。支持的值包括UTF8、ISO_8859_1、UTF16BE、UTF16LE、UTF32BE和UTF32LE。delete_source_files:设置为TRUE以在每次成功转移后删除源文件。如果首次尝试删除源文件失败,则系统不会重新运行删除作业。默认值为FALSE。
- SERVICE_ACCOUNT_NAME 是用于对转移作业进行身份验证的服务账号名称。该服务账号应属于用于创建转移作业的同一
project_id,并且应具有所有所需的权限。
例如,以下命令使用 data_path_template 值 gs://mybucket/myfile/*.csv、目标数据集 mydataset 和 file_format CSV 创建一个名为 My Transfer 的 Cloud Storage 数据转移作业。此示例包含与 CSV file_format 关联的可选参数的非默认值。
该数据转移作业将在默认项目中创建:
bq mk --transfer_config \
--target_dataset=mydataset \
--project_id=myProject \
--display_name='My Transfer' \
--destination_kms_key=projects/myproject/locations/mylocation/keyRings/myRing/cryptoKeys/myKey \
--params='{"data_path_template":"gs://mybucket/myfile/*.csv",
"destination_table_name_template":"MyTable",
"file_format":"CSV",
"max_bad_records":"1",
"ignore_unknown_values":"true",
"field_delimiter":"|",
"quote":";",
"skip_leading_rows":"1",
"allow_quoted_newlines":"true",
"allow_jagged_rows":"false",
"delete_source_files":"true"}' \
--data_source=google_cloud_storage \
--service_account_name=abcdef-test-sa@abcdef-test.iam.gserviceaccount.com projects/862514376110/locations/us/transferConfigs/ 5dd12f26-0000-262f-bc38-089e0820fe38
运行命令后,您会收到如下消息:
[URL omitted] Please copy and paste the above URL into your web browser and
follow the instructions to retrieve an authentication code.
请按照说明操作,并将身份验证代码粘贴到命令行中。
API
使用 projects.locations.transferConfigs.create 方法并提供一个 TransferConfig 资源实例。
Java
试用此示例之前,请按照 BigQuery 快速入门:使用客户端库中的 Java 设置说明进行操作。 如需了解详情,请参阅 BigQuery Java API 参考文档。
如需向 BigQuery 进行身份验证,请设置应用默认凭证。如需了解详情,请参阅为客户端库设置身份验证。
使用转移作业指定加密密钥
您可以指定客户管理的加密密钥 (CMEK) 来加密转移作业运行的数据。您可以使用 CMEK 支持来自 Cloud Storage 的转移作业。当您使用转移作业指定 CMEK 时,BigQuery Data Transfer Service 会将 CMEK 应用于所注入数据的任何中间磁盘缓存,从而使整个数据转移工作流符合 CMEK 的规定。
如果最初不是使用 CMEK 创建转移作业,则无法更新现有转移作业来添加 CMEK。例如,您无法将最初默认加密的目标表更改为现在使用 CMEK 加密。反之,您也无法将 CMEK 加密的目标表更改为采用其他类型的加密。
如果转移配置最初是使用 CMEK 加密创建的,则可以为转移作业更新 CMEK。当您为转移配置更新 CMEK 时,BigQuery Data Transfer Service 会在下次运行转移作业时将 CMEK 传播到目标表,其中 BigQuery Data Transfer Service 会在转移作业运行期间将所有过时的 CMEK 替换为新的 CMEK。如需了解详情,请参阅更新转移作业。
您也可以使用项目默认密钥。当您使用转移作业指定项目默认密钥时,BigQuery Data Transfer Service 会将项目默认密钥用作任何新转移配置的默认密钥。
手动触发转移作业
除了从 Cloud Storage 自动安排的数据转移作业外,您还可以手动触发转移作业来加载其他数据文件。
如果转移作业配置会进行运行时参数化,则您需要指定要开始执行其他转移作业的日期范围。
如需触发数据转移作业,请执行以下操作:
控制台
前往 Google Cloud 控制台中的 BigQuery 页面。
点击 数据转移。
从列表中选择您的数据转移作业。
点击立即运行转移作业或安排回填(对于运行时参数化转移作业配置)。
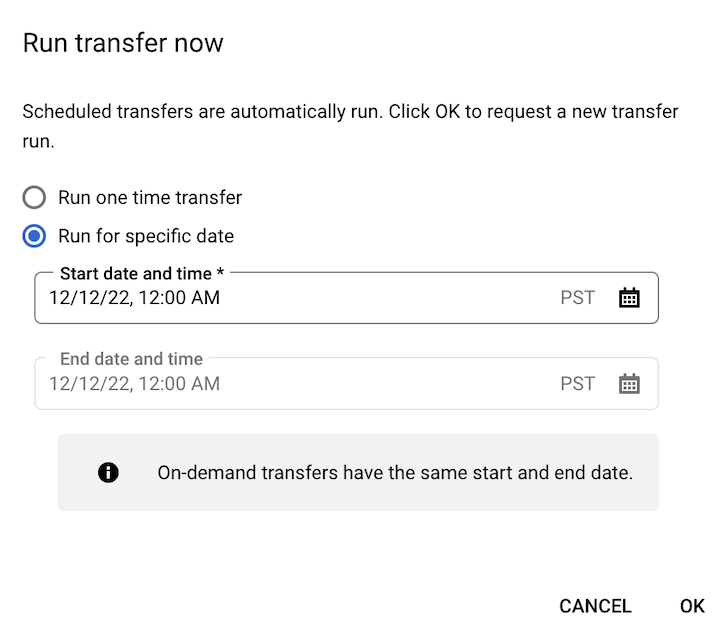
如果您点击了立即运行转移作业,请选择运行一次性转移作业或在特定日期运行(如适用)。如果您选择了在特定日期运行,请选择特定日期和时间:
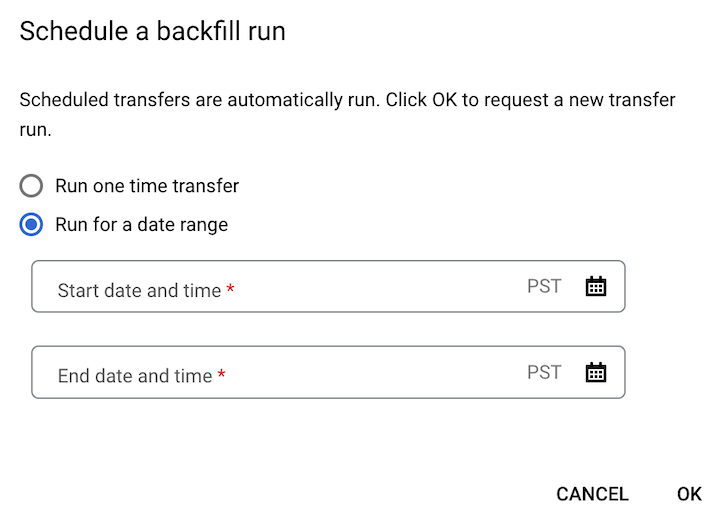
如果您点击了安排回填,请选择运行一次性转移作业或在某个日期范围运行(如适用)。如果您选择了在某个日期范围运行,请选择开始和结束日期及时间:
点击确定。
bq
输入 bq mk 命令并提供 --transfer_run 标志。您可以使用 --run_time 标志或是 --start_time 和 --end_time 标志。
bq mk \ --transfer_run \ --start_time='START_TIME' \ --end_time='END_TIME' \ RESOURCE_NAME
bq mk \ --transfer_run \ --run_time='RUN_TIME' \ RESOURCE_NAME
其中:
START_TIME 和 END_TIME 是以
Z结尾或包含有效时区偏移量的时间戳。例如:2017-08-19T12:11:35.00Z2017-05-25T00:00:00+00:00
RUN_TIME 是时间戳,用于指定安排数据转移运行的时间。如果要为当前时间运行一次性转移作业,您可以使用
--run_time标志。RESOURCE_NAME 是转移作业的资源名称(也称为转移作业配置),例如
projects/myproject/locations/us/transferConfigs/1234a123-1234-1a23-1be9-12ab3c456de7。如果您不知道转移作业的资源名称,请运行bq ls --transfer_config --transfer_location=LOCATION命令以查找资源名称。
API
使用 projects.locations.transferConfigs.startManualRuns 方法并通过 parent 参数提供转移作业配置资源。