Application Integration でサポートされているコネクタをご覧ください。
コネクタタスク
コネクタタスクでは、すぐに利用できるIntegration Connectors のコネクタを使用して、統合からさまざまな Google Cloud サービスやその他のビジネス アプリケーションにすばやく確実に接続できます。
Application Integration でサポートされているすべてのコネクタの一覧については、コネクタ リファレンスをご覧ください。始める前に
- Google Cloud プロジェクトに対してコネクタ管理者(
roles/connectors.admin)IAM ロールが付与されていることを確認します。ロールの付与の詳細については、アクセスの管理をご覧ください。 - Integration Connectors の一般的なコンセプトについて確認します。
- コネクタを使用して Google Cloud サービスや他のビジネス アプリケーションに接続するには、ご使用の Integration にユーザー管理のサービス アカウントが接続されていることを確認してください。ご使用の Integration にユーザー管理のサービス アカウントが構成されていない場合は、デフォルトで、デフォルトのサービス アカウント(
service-PROJECT_NUMBER@gcp-sa-integrations.iam.gserviceaccount.com)が認証に使用されます。 - サービス アカウントに必要な IAM ロールがあることを確認します。サービス アカウントへのロールの付与については、サービス アカウントに対するアクセス権の管理をご覧ください。
コネクタタスクを追加する
統合にコネクタタスクを追加する手順は次のとおりです。
- Google Cloud コンソールで、[Application Integration] ページに移動します。
- ナビゲーション メニューで [統合] をクリックします。
[統合] ページが開き、Google Cloud プロジェクトで使用可能なすべての統合が一覧表示されます。
- 既存の統合を選択するか、[統合の作成] をクリックして新しい統合を作成します。
新しい統合を作成する場合:
- [統合の作成] ペインで名前と説明を入力します。
- 統合のリージョンを選択します。
- 統合用のサービス アカウントを選択します。統合のサービス アカウントの詳細は、統合ツールバーの [統合の概要] ペインでいつでも変更または更新できます。
- [作成] をクリックします。新しく作成された統合が統合エディタで開きます。
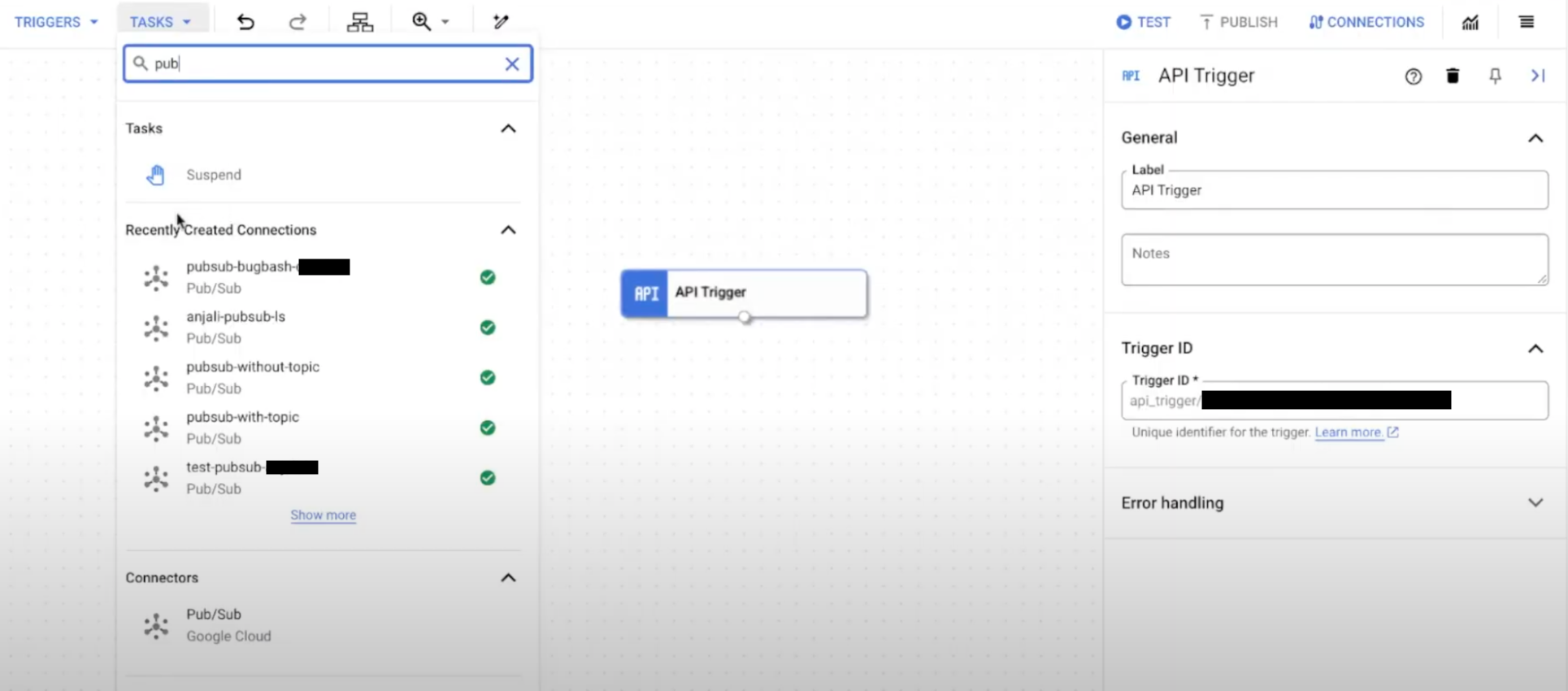
- 統合エディタのナビゲーション バーで、[タスク] をクリックして、使用可能なタスクとコネクタのリストを表示します。
- 新しい接続を構成する場合は、統合エディタでコネクタ要素をクリックして配置します。[コネクタの構成] をクリックして接続を構成します。
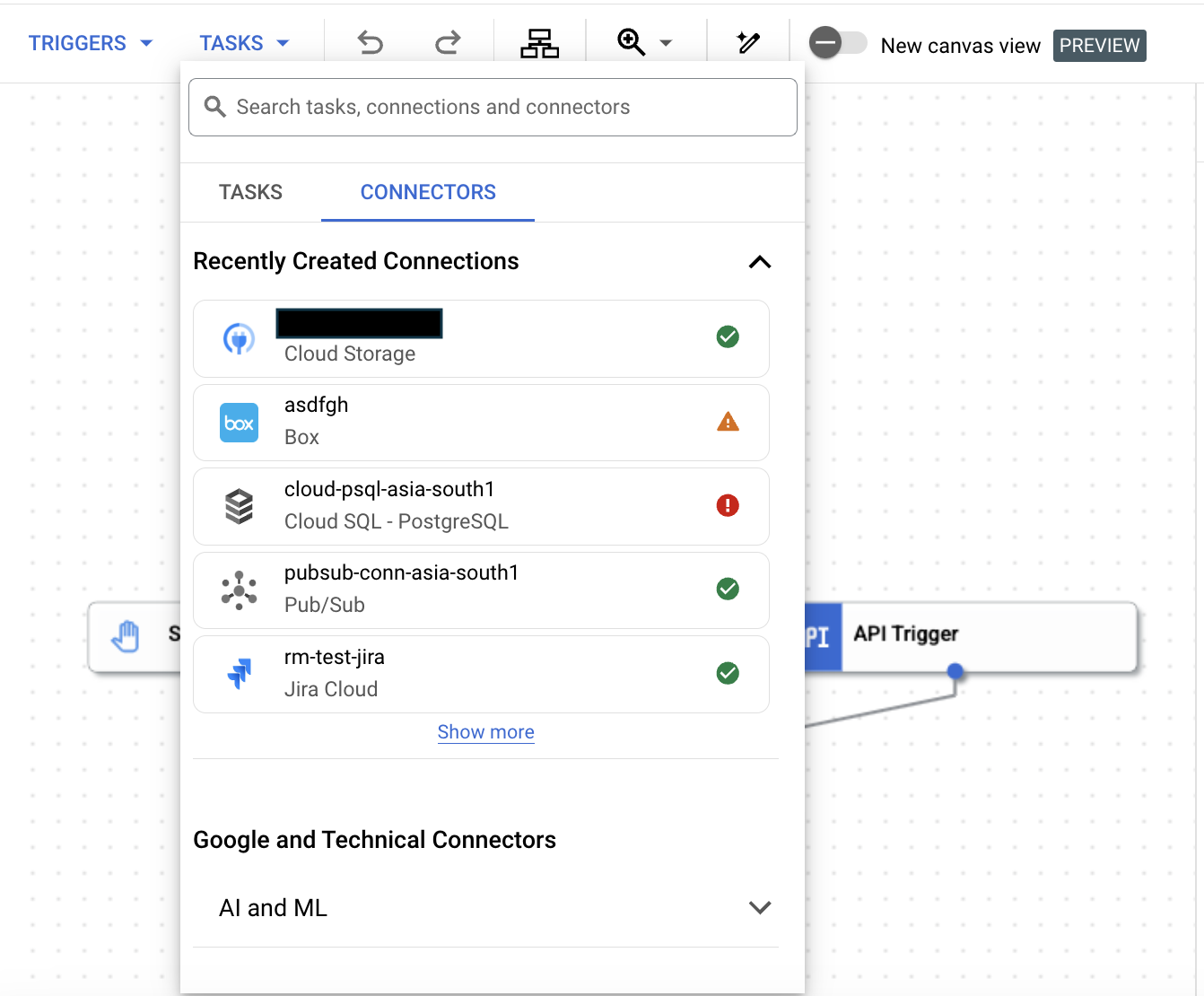
- 既存の接続がある場合は、[コネクタ] タブをクリックして、最近作成した接続を表示します。[検索] フィールドに名前を入力すると、コネクタ、接続、タスクを検索できます。
- 統合エディタでコネクタ要素をクリックして配置します。コネクタタスクを構成する方法については、コネクタタスクを構成するをご覧ください。
コネクタタスクを構成する
コネクタタスクを構成するには、次の手順を行います。
- デザイナーで [コネクタ]タスク要素をクリックして、[コネクタ]タスク構成ペインを表示します。
必要に応じて、[] をクリックしてタスク名を変更します。
- [コネクタを設定する] をクリックします。
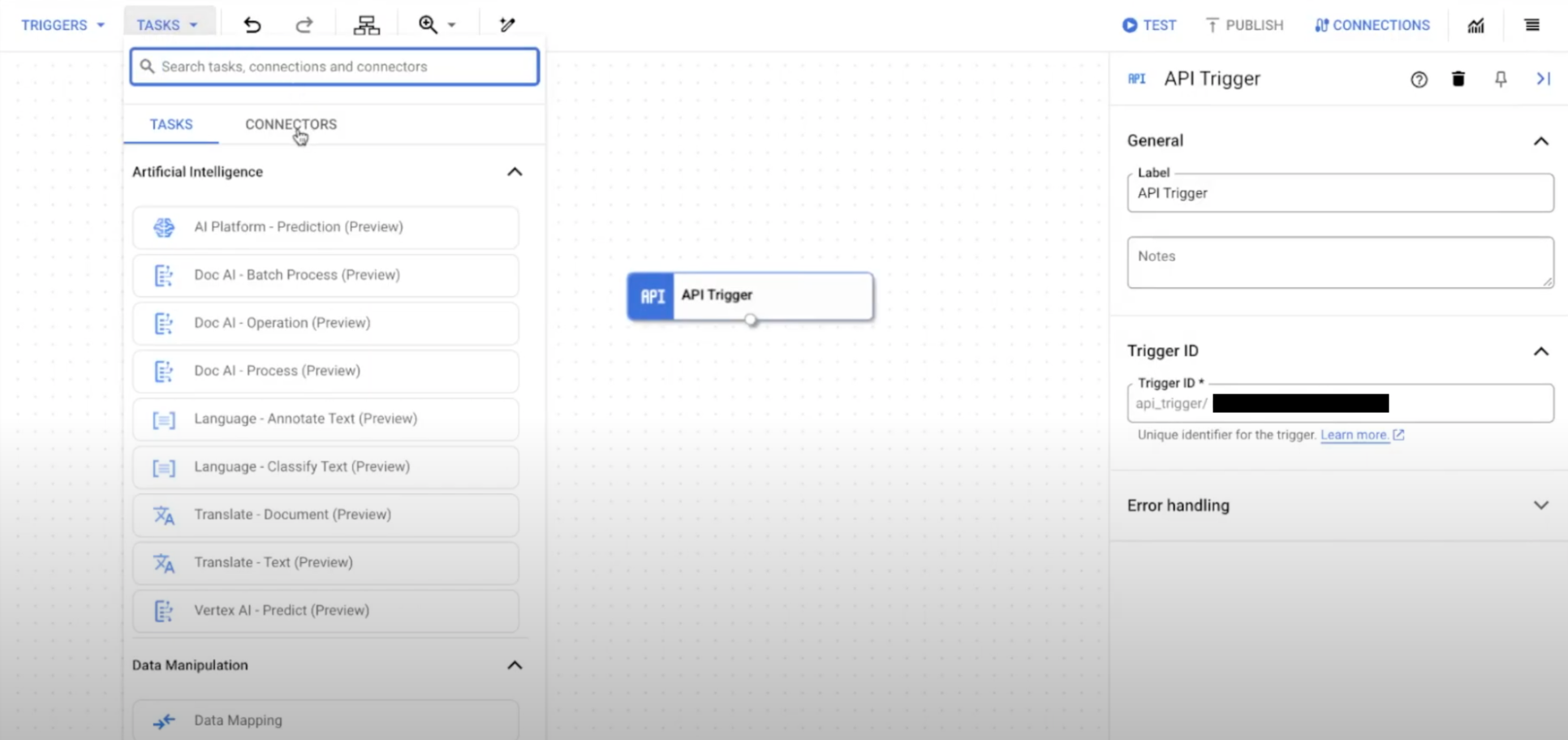
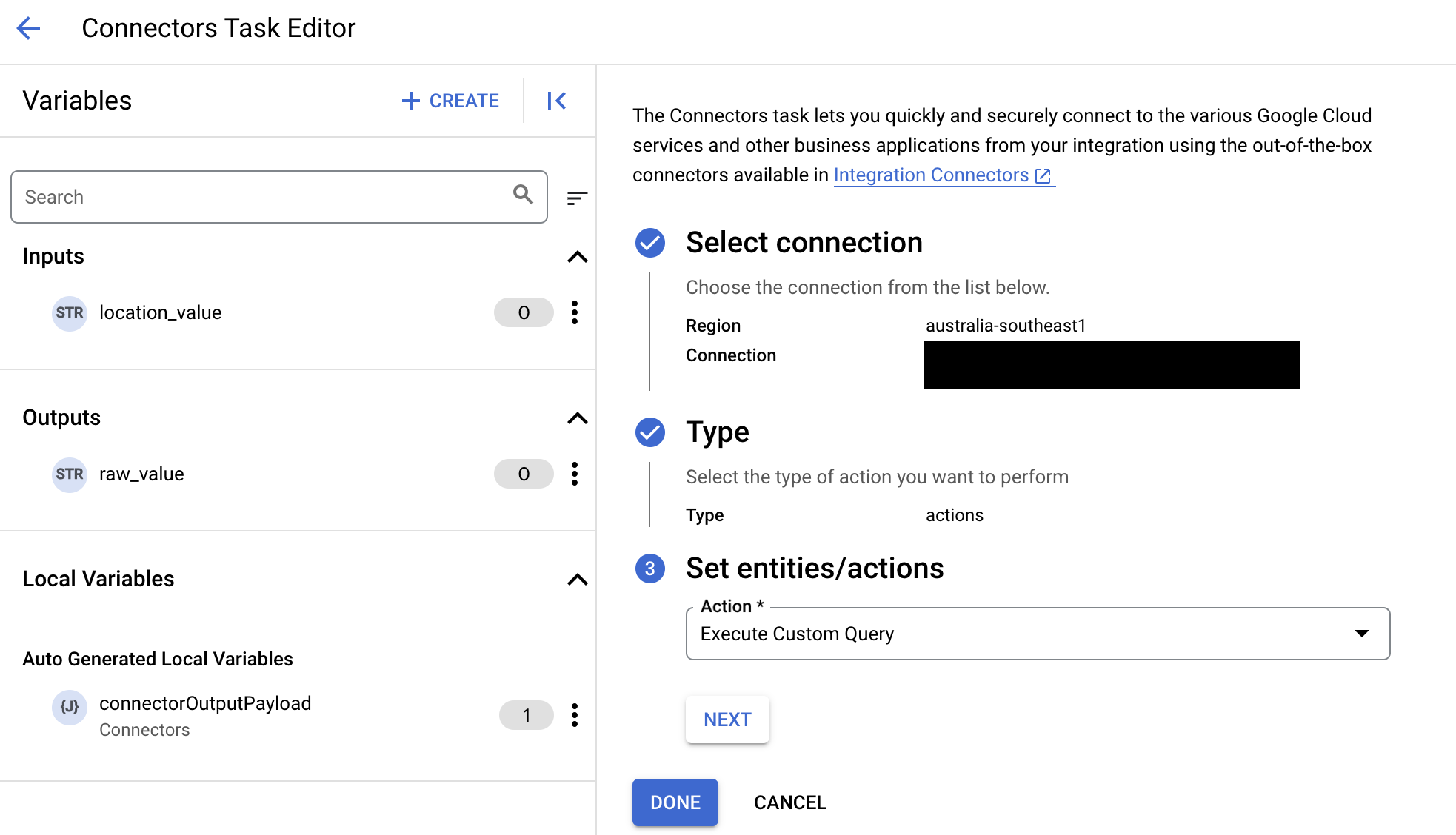
- リージョン内で既存の接続を選択するか、新しい接続を作成することができます。既存の接続を構成するには、[Connectors Task Editor] ページで次の手順を完了します。
次の画像は、[Connectors Task Editor] ページのサンプル レイアウトを示しています。
![[Configure connector task] ダイアログを示す画像](https://cloud.google.com/static/application-integration/images/apip_connector_task.png?hl=ja)
- [Select connection] セクションで、接続のリージョンを選択します。
- 選択したリージョンで利用可能な接続のリストから、既存の接続を選択します。
- [次へ] をクリックします。
- [タイプ] リストで [エンティティ] または [アクション] を選択します。
- [エンティティ] を選択すると、接続でサポートされているエンティティのリストが [Set entities/actions] セクションに表示されます。エンティティを選択してから、そのエンティティで行う[オペレーション]を選択します。
- [アクション] を選択すると、接続でサポートされているアクションのリストが [Set entities/actions] 列に表示されます。接続のアクションを選択します。 サポートされるエンティティとアクションは、コネクタタイプに基づいて決まります。Application Integration でサポートされているすべてのコネクタの一覧については、コネクタ リファレンスをご覧ください。コネクタでサポートされているアクションとエンティティを表示するには、特定のコネクタのドキュメントをご覧ください。
コネクタがカスタム SQL クエリをサポートしている場合は、[アクション] リストで [カスタムクエリを実行する] オプションを選択します。コネクタにカスタム SQL クエリを追加する方法については、アクション: カスタム SQL クエリを実行するをご覧ください。
- [完了] をクリックして接続の構成を完了し、ペインを閉じます。
タスクの入出力変数を構成する
コネクタタスク構成ペインには、[Configure connector task] ダイアログで選択したエンティティとオペレーションまたはアクションに基づいて自動生成されたタスク入力とタスク出力の変数が表示されます。これらの変数は構成可能です。これらの変数は、現在のタスクへの入力として、または現在のインテグレーションで後続のタスクまたは条件への出力としてアクセスできます。
タスク入力変数またはタスク出力変数を構成するには、それぞれの変数をクリックして、[Configure Variable] ペインを開き、次の手順を行います。
- [Default Value] フィールドに変数値を入力します。
- (省略可)[Use as an input to integration] または [Use as an output to integration] を選択します。
- [保存] をクリックします。
コネクタタスクの入出力パラメータの詳細については、エンティティ オペレーションをご覧ください。
認証オーバーライドを構成する
実行時にさまざまなバックエンド認証を動的に受け入れるように接続を有効にするには、Integration Connectors で、接続の [認証オーバーライドを有効にする] オプションが選択されていることを確認します。
認証オーバーライドを構成するには、次の操作を行います。
- デザイナーで コネクタ タスク要素をクリックして、[コネクタ] タスク構成ペインを表示します。
- [タスク入力] セクションを開きます。 [エンドユーザー認証情報] フィールドが
dynamicAuthConfig変数に設定されています。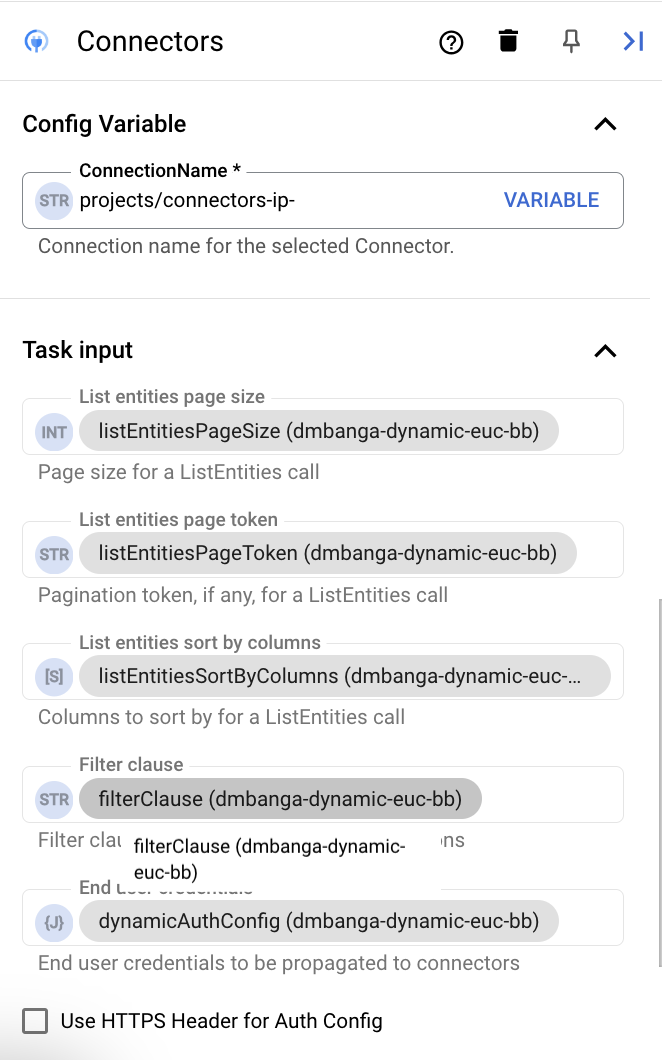
次に、以下の操作を行います。
dynamicAuthConfig変数をクリックします。[変数を編集] ペインが表示されます。認証をオーバーライドするには、統合をテストするときに認証値を指定する必要があります。
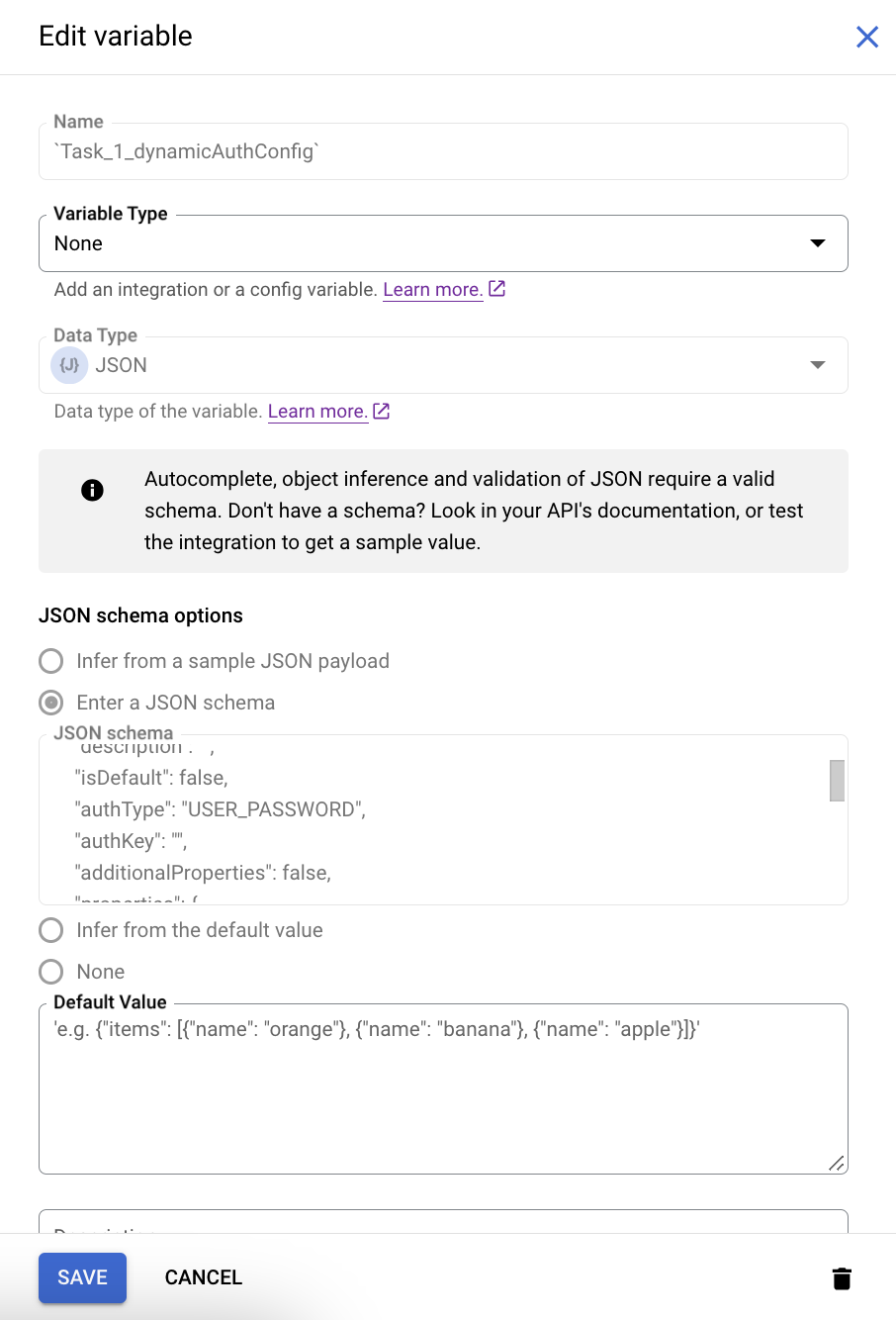
方法は次のとおりです。
- [変数タイプ] リストから [Input to Integration] を選択します。
- [JSON schema options] で、接続に構成されている認証タイプを確認できます。このスキーマを使用して、統合をテストするときに認証値をオーバーライドします。
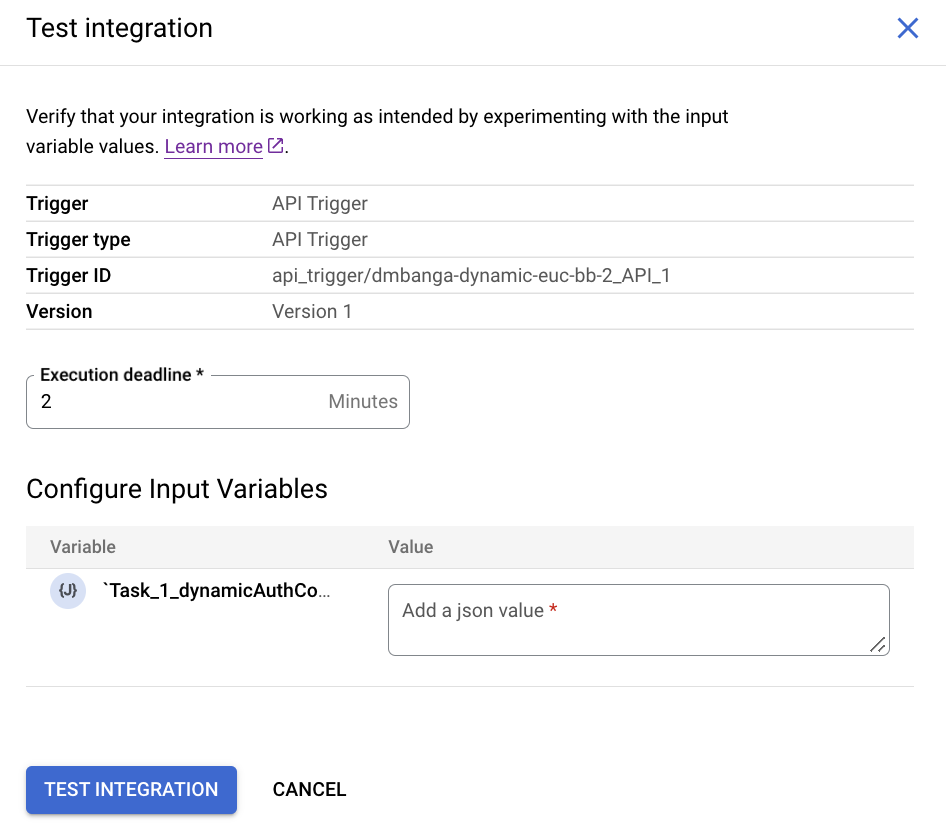
または、[コネクタ] タスク構成ペインの [タスク入力] セクションで [認証構成に HTTPS ヘッダーを使用する] チェックボックスをオンにして、認証を HTTP ヘッダーとして渡すこともできます。
エンティティ オペレーションとアクション
コネクタのエンティティで CRUD(作成、読み取り、更新、削除)オペレーションを行うことができます。これらのエンティティ オペレーションでは、それぞれ入力パラメータと出力パラメータのセットが異なります。次のテーブルに、さまざまなエンティティ オペレーションの入力パラメータと出力パラメータが示されています。
| オペレーション名 | 入力パラメータ | 出力パラメータ |
|---|---|---|
| リスト |
|
|
| 取得 | entityId | connectorOutputPayload |
| 作成 | connectorInputPayload | connectorOutputPayload |
| 更新 |
|
connectorOutputPayload |
| 削除 |
|
該当なし |
入力パラメータ
次のテーブルに、さまざまなエンティティ オペレーションの入力パラメータを示します。
| パラメータ名 | データ型 | 説明 |
|---|---|---|
| entityId | 文字列 | アクセスする行の固有識別子。 通常、 たとえば、MySQL テーブルから特定の行を取得するには、 |
| connectorInputPayload | JSON | エンティティで追加または更新される実際のデータ。次の例は、テーブルに追加される行データの JSON スニペットを示しています。
{
"employee_first_name": "John",
"employee_emailID": "test-05@test.com"
}
この例では、 |
| filterClause | 文字列 | 条件に基づいてオペレーションの結果を制限します。フィルタ句の追加について詳しくは、オペレーション用のフィルタを追加するをご覧ください。 |
| listEntitiesPageSize | 整数 |
ページで返される結果の数を指定します。 ページは、結果セットのレコードの論理グループです。ページのコンセプトは、結果セットに多数のレコードが含まれることが予想される場合に有効に活用できます。結果セットのサイズが大きい場合、コネクタタスクが処理できるデータサイズには上限があるため、コネクタタスクが失敗する可能性があります。この問題は、結果セットをより小さなチャンクに分割することで回避できます。 たとえば、結果セットで 1,000 件のレコードが想定される場合は、 |
| listEntitiesPageToken | 文字列 | 特定のページへのアクセスを可能にするページ識別子(トークン)。 ページトークンの値は、 |
| listEntitiesSortByColumns | 文字列配列 | 結果セットの並べ替えに使用する列の名前。
|
出力パラメータ
次のテーブルに、さまざまなエンティティ オペレーションの出力パラメータを示します。
| パラメータ名 | データ型 | 説明 |
|---|---|---|
| connectorOutputPayload | JSON | オペレーションの出力(JSON 形式)。 |
| listEntitiesNextPageToken | 文字列 |
システムが生成したページの識別子。トークンは、結果セットの特定のページにアクセスするためのポインタと考えられます。
たとえば、 結果セットのページ数が多い場合は、While Loop タスクを使用して次のページを取得し、データ マッピング タスクを使用して実行が完了するたびに |
エンティティ オペレーションのフィルタ句
タスクの入力として使用可能なフィルタ句変数を使用して、コネクタタスクによって処理されるレコードを制限できます。たとえば、削除オペレーションの場合、特定の orderId を含むレコードを削除するフィルタ句を追加できます。
フィルタ句は、次のエンティティ オペレーションにのみ適用できます。
- リスト
- 削除
- 更新
これらのオペレーションのいずれかを選択すると、コネクタタスクの [Task Input] セクションに [Filter clause] フィールドが自動的に表示されます。
フィルタ句を追加
フィルタを追加する手順は、次のとおりです。
- デザイナーでコネクタタスク要素をクリックして、コネクタタスク構成ペインを表示します。
- [Task Input] セクションを開き、[filterClause(Connectors)] 文字列変数をクリックします。
[変数設] ダイアログが表示されます。
- [デフォルト値] フィールドにフィルタ句(syntax 句の後)を入力します。
- [保存] をクリックします。
フィルタ句の構文と例
フィルタ句の形式は次のとおりです。
FIELD_NAME CONDITION FILTER_VALUE
例
OwnerId = '0053t000007941XAAQ'
PoNumber < 2345
OrderNumber = 00110 AND StatusCode = 'Draft'
TotalAmount > 2500
ShippingPostalCode = 94043 OR ShippingPostalCode = 77002
フィルタ句での変数の使用
フィルタ句でイ統合変数を直接使用することはできません。統合変数を使用する場合は、まずデータ マッピング タスクを構成して、統合変数とフィルタ句間のマッピングを作成する必要があります。次のテーブルに、統合変数と filterClause(Connectors) 変数間のマッピング例を示します。
| 入力 | 出力 |
|---|---|
PRIMARY_KEY_ID = ' .CONCAT(INTEGRATION_VARIABLE) .CONCAT(') |
filterClause(Connectors) |
PRIMARY_KEY_ID = ' は入力行に値として入力されています。アクション: カスタム SQL クエリを実行する
カスタムクエリを作成する手順は次のとおりです。
- 詳細な手順に沿って、コネクタタスクを追加します。
- コネクタタスクを構成するときに、実行するアクションの種類で [Actions] を選択します。
- [Actions] リストで [Execute custom query] を選択し、[Done] をクリックします。
- [Task input] セクションを開き、次の操作を行います。
- [タイムアウト後] フィールドに、クエリが実行されるまで待機する秒数を入力します。
デフォルト値:
180秒 - [Maximum number of rows] フィールドに、データベースから返される最大行数を入力します。
デフォルト値:
25。 - カスタムクエリを更新するには、[Edit Custom Script] をクリックします。[Script editor] ダイアログが開きます。
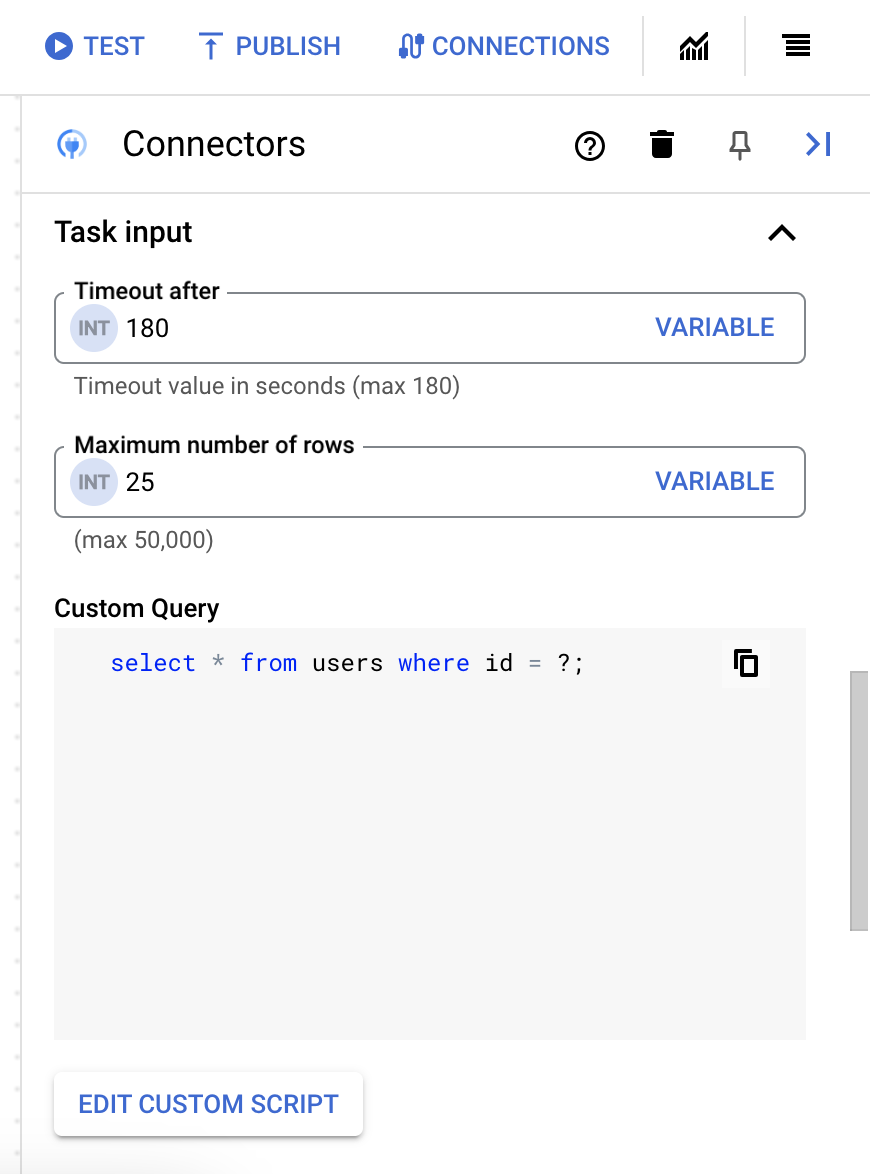
- [Script editor] ダイアログで、SQL クエリを入力して [Save] をクリックします。
SQL ステートメントで疑問符(?)を使用して、クエリ パラメータ リストで指定する必要がある 1 つのパラメータを表すことができます。たとえば、次の SQL クエリは、
LastName列に指定された値と一致するEmployeesテーブルからすべての行を選択します。SELECT * FROM Employees where LastName=?
- SQL クエリで疑問符を使用した場合は、各疑問符の [+ パラメータ名を追加] をクリックして、パラメータを追加する必要があります。統合の実行中に、これらのパラメータにより SQL クエリ内の疑問符(?)が順番に置き換わります。たとえば、3 つの疑問符(?)を追加した場合、3 つのパラメータを順番に追加する必要があります。
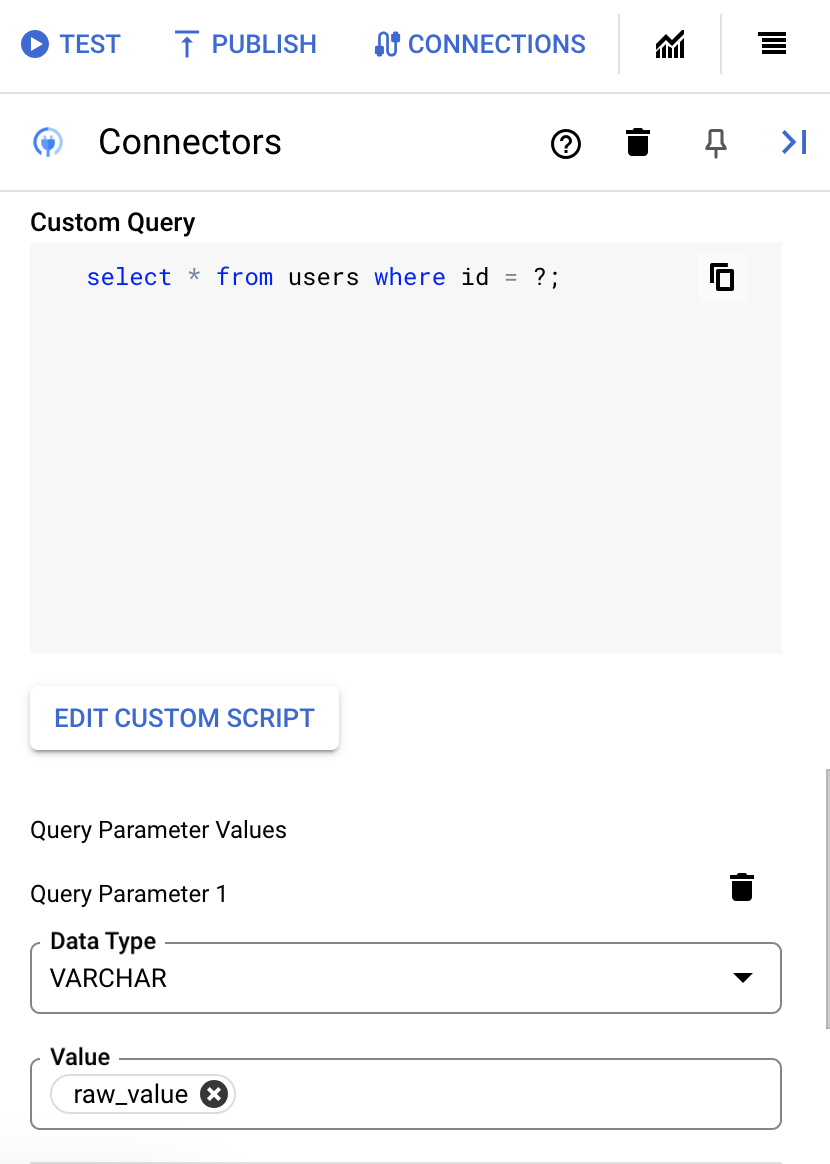
クエリ パラメータを追加する手順は次のとおりです。
- [Type] リストから、パラメータのデータ型を選択します。
- [Value] フィールドに、パラメータの値を入力します。
- 複数のパラメータを追加するには、[+ クエリ パラメータを追加] をクリックします。
カスタムクエリの実行アクションは、配列変数をサポートしていません。
- [タイムアウト後] フィールドに、クエリが実行されるまで待機する秒数を入力します。
スキーマの更新
すべてのエンティティとアクションに、関連するスキーマがあります。たとえば、アクション スキーマにはパラメータの詳細(パラメータ名や対応するデータ型など)が含まれます。エンティティとアクションのスキーマ(メタデータ)は、ランタイムに接続によってバックエンドから取得されます。スキーマが更新されても、既存の接続には自動的に反映されません。スキーマを手動で更新する必要があります。既存のコネクタタスクで更新されたスキーマを表示するには、次の操作を行います。- Integration Connectors で、接続の詳細ページを開き、[Refresh connection schema] をクリックします。
- Application Integration で、同じ接続に対して既存のコネクタタスクを再構成する必要があります。
インライン接続の作成
コネクタタスクを使用して、Integration Connectors で新しい接続を直接作成できます。
始める前に
接続の新規作成
Application Integration から新しい接続を作成するには、次の手順を行います。
- デザイナーで [コネクタ] タスク要素をクリックして、[コネクタ] タスク構成ペインを表示します。
- [コネクタを設定する] をクリックします。
[Connectors Task Editor] ページが表示されます。
- [リージョン] フィールドはスキップします。
- [接続] をクリックし、プルダウン メニューから [接続を作成] オプションを選択します。
- [接続を作成] ペインで、次の操作を行います。
- [ロケーション] ステップで、接続のロケーションを選択します。
- [リージョン] をクリックし、プルダウン リストからロケーションを選択します。
- [次へ] をクリックします。
- [接続の詳細] ステップで、接続の詳細を入力します。
- コネクタ: 作成するコネクタのタイプをプルダウン リストから選択します。サポートされているコネクタのリストについては、すべての Integration Connectors をご覧ください。
- コネクタのバージョン: プルダウン リストから、選択したコネクタタイプの使用可能なバージョンを選択します。
- 接続名: 接続インスタンスの名前を入力します。
- (オプション)接続インスタンスの [説明] を入力します。
- (オプション)接続インスタンスのログデータを保存するには、[Cloud Logging を有効にする] をオンにします。
- サービス アカウント: 必要なロールを持つサービス アカウントを選択します。
- (オプション)[詳細設定] をクリックして接続ノードの設定を構成します。
詳しくは、Integration Connectors のそれぞれの接続に関するドキュメントをご覧ください。
- (オプション)[+ ラベルを追加] をクリックして Key-Value ペアの形式でラベルを接続に追加します。
- [次へ] をクリックします。
-
[認証] ステップで、接続の認証の詳細を入力します。
- このステップでは、作成された接続タイプに基づいた認証方法で入力されます。
接続タイプによって認証方法は異なります。詳細については、Integration Connectors のそれぞれの接続に関するドキュメントの認証を構成するのセクションをご覧ください。
- [次へ] をクリックします。
- このステップでは、作成された接続タイプに基づいた認証方法で入力されます。
- Review: 接続と認証の詳細を確認します。
- [作成] をクリックします。
- [ロケーション] ステップで、接続のロケーションを選択します。
ベスト プラクティス
- コネクタタスクに適用される使用量上限については、使用量上限をご覧ください。
- 失敗したコネクタタスクのトラブルシューティング方法については、ログを使用してコネクタ障害のトラブルシューティングとトレースを行うをご覧ください。
エラー処理方法
タスクのエラー処理方法では、一時的なエラーによってタスクが失敗した場合のアクションを指定します。エラー処理方式と、さまざまな種類のエラー処理方式の詳細については、エラー処理方法をご覧ください。
料金
Cloud Pub/Sub トリガーと Salesforce トリガーでは、コネクタを作成する必要はありません。ただし、コネクタタスクを使用して Pub/Sub または Salesforce に接続する場合は、コネクタの使用量に対して課金されます。料金について詳しくは、Application Integration の料金をご覧ください。
割り当てと上限
割り当てと上限については、割り当てと上限をご覧ください。
次のステップ
- すべてのタスクとトリガーを確認する。
- インテグレーションをテストして公開する方法について学習する。
- エラー処理について学習する。
- 統合の実行ログについて学習する。