In diesem Dokument erfahren Sie, wie Sie die Onlinebereitstellungsleistung von Modellen für maschinelles Lernen (ML) testen und überwachen, die in AI Platform Prediction bereitgestellt werden. Dieses Dokument verwendet das Open-Source-Tool Locust für Lasttests.
Das Dokument richtet sich an Data Scientists und MLOps-Entwickler, die die Dienstarbeitslast, Latenz und Ressourcennutzung ihrer ML-Modelle in der Produktion überwachen möchten.
In diesem Dokument wird davon ausgegangen, dass Sie Erfahrung mit Google Cloud, TensorFlow, AI Platform Prediction, Cloud Monitoring und Jupyter-Notebooks haben.
Außerdem wird das Dokument von einem GitHub-Repository begleitet, das den Code und eine Bereitstellungsanleitung für die Implementierung des in diesem Dokument beschriebenen Systems enthält. Die Aufgaben sind in Jupyter-Notebooks eingebunden.
Kosten
Die Notebooks, mit denen Sie in diesem Dokument arbeiten, verwenden die folgenden kostenpflichtigen Komponenten von Google Cloud:
- Vertex AI Workbench: Nutzerverwaltete Notebooks
- AI Platform Prediction
- Cloud Storage
- Cloud Monitoring
- Google Kubernetes Engine (GKE)
Mit dem Preisrechner können Sie eine Kostenschätzung für Ihre voraussichtliche Nutzung vornehmen.
Hinweis
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
Architektur
Das folgende Diagramm zeigt die Systemarchitektur für die Bereitstellung des ML-Modells für die Onlinevorhersage, die Ausführung des Lasttests und das Erfassen und Analysieren der Messwerte für die Bereitstellung des ML-Modells.
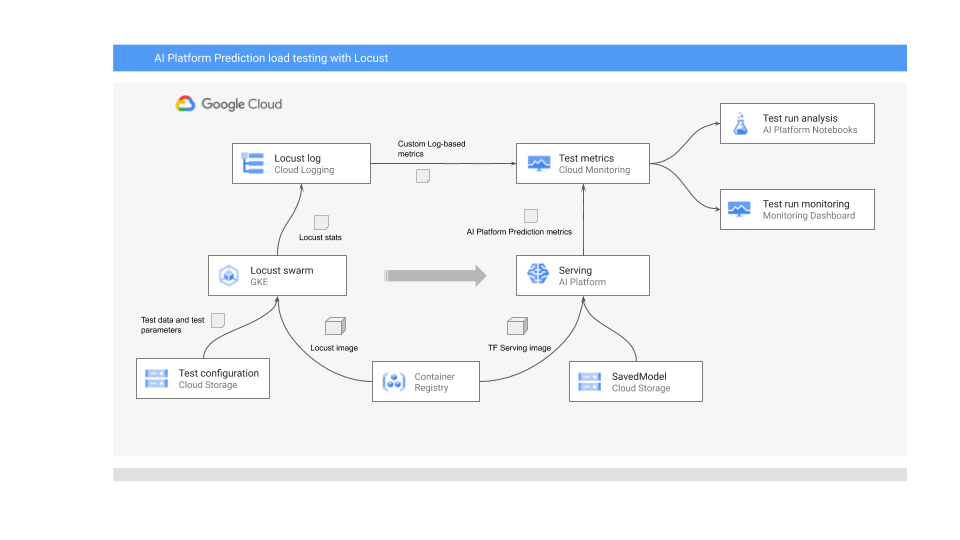
Das Diagramm zeigt den folgenden Ablauf:
- Ihr trainiertes Modell kann sich in Cloud Storage befinden, z. B. ein TensorFlow-SavedModel oder scikit-learn joblib. Alternativ kann es in einen benutzerdefinierten Bereitstellungscontainer in Container Registry eingebunden werden, z. B. TorchServe zum Bereitstellen von PyTorch-Modellen.
- Das Modell wird in AI Platform Prediction als REST API bereitgestellt. AI Platform Prediction ist ein vollständig verwalteter Dienst für die Modellbereitstellung, der verschiedene Maschinentypen unterstützt. Außerdem werden das Autoscaling basierend auf Ressourcennutzung und verschiedene GPU-Beschleuniger unterstützt.
- Locust wird zur Implementierung einer Testaufgabe (d. h. Nutzerverhalten) verwendet. Dazu wird das in AI Platform Prediction bereitgestellte ML-Modell aufgerufen und in großem Maßstab in Google Kubernetes Engine (GKE) ausgeführt. Dadurch werden viele gleichzeitige Nutzeraufrufe für Lasttests des Modellvorhersagedienstes simuliert. Sie können den Fortschritt der Tests über die Locust-Weboberfläche überwachen.
- Locust protokolliert Teststatistiken in Cloud Logging. Mit den vom Locust-Test erstellten Logeinträgen wird eine Reihe von logbasierten Messwerten in Cloud Monitoring definiert. Diese Messwerte ergänzen die standardmäßigen AI Platform Prediction-Messwerte.
- Sowohl AI Platform-Messwerte als auch die benutzerdefinierten Locust-Messwerte stehen in einem Cloud Monitoring-Dashboard in Echtzeit zur Visualisierung zur Verfügung. Nach Abschluss des Tests werden die Messwerte auch programmatisch erfasst, sodass Sie die Messwerte in nutzerverwalteten Notebooks von Vertex AI Workbench analysieren und visualisieren können.
Die Jupyter-Notebooks für dieses Szenario
Alle Aufgaben zum Vorbereiten und Bereitstellen des Modells, zum Ausführen des Locust-Tests und zum Erfassen und Analysieren der Testergebnisse sind in den folgenden Jupyter-Notebooks codiert. Zum Ausführen dieser Aufgaben führen Sie die Zellensequenzen in jedem Notebook aus.
01-prepare-and-deploy.ipynb: Sie führen dieses Notebook aus, um ein TensorFlow SavedModel für die Bereitstellung vorzubereiten und das Modell in AI Platform Prediction bereitzustellen.02-perf-testing.ipynb: Sie führen dieses Notebook aus, um in Cloud Monitoring logbasierte Messwerte für den Locust-Test zu erstellen und den Locust-Test in GKE bereitzustellen und auszuführen.03-analyze-results.ipynb: Sie führen dieses Notebook aus, um die Ergebnisse des Locust-Lasttests aus den standardmäßigen Cloud Platform-Messwerten, die von Cloud Monitoring erstellt werden, und aus den benutzerdefinierten Locust-Messwerten zu erfassen und zu analysieren.
Umgebung initialisieren
Wie in der Datei README.md des zugehörigen GitHub-Repositorys beschrieben, müssen Sie die Umgebung zur Ausführung der Notebooks mithilfe der folgenden Schritte vorbereiten:
- Erstellen Sie in Ihrem Google Cloud-Projekt einen Cloud Storage-Bucket, der zum Speichern des trainierten Modells und der Locust-Testkonfiguration erforderlich ist. Notieren Sie sich den Namen, den Sie für den Bucket verwenden, da Sie ihn später benötigen.
- Erstellen Sie einen Cloud Monitoring-Arbeitsbereich in Ihrem Projekt.
- Erstellen Sie einen Google Kubernetes Engine-Cluster mit den erforderlichen CPUs. Der Knotenpool muss Zugriff auf die Cloud APIs haben.
- Erstellen Sie eine nutzerverwaltete Notebooks-Instanz von Vertex AI Workbench, die TensorFlow 2 verwendet. Für diese Anleitung benötigen Sie keine GPUs, da Sie das Modell nicht trainieren. GPUs können in anderen Szenarien nützlich sein, insbesondere um das Training Ihrer Modelle zu beschleunigen.
JupyterLab öffnen
Sie müssen die JupyterLab-Umgebung öffnen und die Notebooks abrufen, um die Aufgaben für das Szenario zu bearbeiten.
Rufen Sie in der Google Cloud Console die Seite Notebooks auf.
Klicken Sie auf dem Tab Nutzerverwaltete Notebooks neben der von Ihnen erstellten Notebookumgebung auf Jupyterlab öffnen.
Dadurch wird die JupyterLab-Umgebung im Browser geöffnet.
Klicken Sie auf dem Tab Launcher auf das Symbol für Terminal, um einen Terminal-Tab zu öffnen.
Klonen Sie im Terminal das GitHub-Repository
mlops-on-gcp:git clone https://github.com/GoogleCloudPlatform/mlops-on-gcp.gitWenn der Befehl ausgeführt ist, wird der Ordner
mlops-on-gcpim Dateibrowser angezeigt. In diesem Ordner sehen Sie die Notebooks, mit denen Sie in diesem Dokument arbeiten.
Notebook-Einstellungen konfigurieren
In diesem Abschnitt richten Sie im Notebook Variablen ein, die für Ihren Kontext spezifisch sind, und Sie bereiten die Python-Umgebung für die Ausführung des Codes für das Szenario vor.
- Rufen Sie das Verzeichnis
model_serving/caip-load-testingauf. - Gehen Sie für jedes der drei Notebooks so vor:
- Öffnen Sie das Notebook.
- Führen Sie die Zellen unter Google Cloud-Umgebungseinstellungen konfigurieren aus.
In den folgenden Abschnitten werden die wichtigsten Teile des Prozesses aufgezeigt und Aspekte des Designs und des Codes erläutert.
Modell für Onlinevorhersagen bereitstellen
Das in diesem Dokument verwendete ML-Modell verwendet das vortrainierte Bildklassifizierungsmodell ResNet V2 101 von TensorFlow Hub. Sie können die Systemdesignmuster und -techniken aus diesem Dokument jedoch an andere Domains und andere Modelltypen anpassen.
Der Code zum Vorbereiten und Bereitstellen des ResNet 101-Modells befindet sich im Notebook 01-prepare-and-deploy.ipynb. Sie führen die Zellen im Notebook aus, um die folgenden Aufgaben auszuführen:
- ResNet-Modell von TensorFlow Hub herunterladen und ausführen.
- Bereitstellungssignaturen für das Modell erstellen.
- Modell als SavedModel exportieren.
- SavedModel in AI Platform Prediction bereitstellen.
- Bereitgestelltes Modell prüfen.
In den nächsten Abschnitten dieses Dokuments wird ausführlich beschrieben, wie Sie das ResNet-Modell vorbereiten und bereitstellen.
ResNet-Modell für die Bereitstellung vorbereiten
Das ResNet-Modell von TensorFlow Hub hat keine Bereitstellungssignaturen, da es für die Neuzusammensetzung und Feinabstimmung optimiert ist. Daher müssen Sie Bereitstellungssignaturen für das Modell erstellen, damit es das Modell für Onlinevorhersagen bereitstellen kann.
Darüber hinaus empfehlen wir zum Bereitstellen des Modells, dass Sie die Feature-Engineering-Logik in die Bereitstellungsschnittstelle einbetten. Dadurch wird die Affinität zwischen der Vorverarbeitung und der Modellbereitstellung garantiert, statt dass die Clientanwendung Daten im erforderlichen Format vorverarbeiten muss. Außerdem müssen Sie in der Bereitstellungsschnittstelle die Nachbearbeitung einrichten, z. B. die Konvertierung einer Klassen-ID in ein Klassenlabel.
Damit das ResNet-Modell ausgeliefert werden kann, müssen Sie Bereitstellungssignaturen implementieren, die die Inferenzmethoden des Modells beschreiben. Deshalb fügt der Notebook-Code zwei Signaturen hinzu:
- Die Standardsignatur. Diese Signatur stellt die Standardmethode
predictdes ResNet V2 101-Modells bereit. Die Standardmethode hat keine Vorverarbeitungs- oder Nachbearbeitungslogik. - Vorverarbeitungs- und Nachbearbeitungssignatur. Die erwarteten Eingaben in dieser Schnittstelle erfordern eine relativ komplexe Vorverarbeitung, einschließlich Codierung, Skalierung und Normalisierung des Bildes. Daher stellt das Modell auch eine alternative Signatur bereit, die die Vorverarbeitungs- und Nachbearbeitungslogik einbettet. Diese Signatur akzeptiert unverarbeitete Rohbilder und gibt die Liste der Klassenlabels mit Rang sowie die zugehörigen Labelwahrscheinlichkeiten zurück.
Die Signaturen werden in einer benutzerdefinierten Modulklasse erstellt. Die Klasse wird aus der Basisklasse tf.Module abgeleitet, die das ResNet-Modell kapselt. Die benutzerdefinierte Klasse erweitert die Basisklasse durch eine Methode, die die Bildvorverarbeitungs- und Ausgabenachbearbeitungslogik implementiert. Die Standardmethode des benutzerdefinierten Moduls wird der Standardmethode des Basis-ResNet-Modells zugeordnet, um die analoge Schnittstelle beizubehalten. Das benutzerdefinierte Modul wird als SavedModel exportiert, das das ursprüngliche Modell, die Vorverarbeitungslogik und zwei Bereitstellungssignaturen enthält.
Die Implementierung der Klasse des benutzerdefinierten Moduls wird im folgenden Code-Snippet veranschaulicht:
LABELS_KEY = 'labels'
PROBABILITIES_KEY = 'probabilities'
NUM_LABELS = 5
class ServingModule(tf.Module):
"""
A custom tf.Module that adds image preprocessing and output post processing to
a base TF 2 image classification model from TensorFlow Hub.
"""
def __init__(self, base_model, input_size, output_labels):
super(ServingModule, self).__init__()
self._model = base_model
self._input_size = input_size
self._output_labels = tf.constant(output_labels, dtype=tf.string)
def _decode_and_scale(self, raw_image):
"""
Decodes, crops, and resizes a single raw image.
"""
image = tf.image.decode_image(raw_image, dtype=tf.dtypes.uint8, expand_animations=False)
image_shape = tf.shape(image)
image_height = image_shape[0]
image_width = image_shape[1]
crop_size = tf.minimum(image_height, image_width)
offset_height = ((image_height - crop_size) + 1) // 2
offset_width = ((image_width - crop_size) + 1) // 2
image = tf.image.crop_to_bounding_box(image, offset_height, offset_width, crop_size, crop_size)
image = tf.image.resize(image, [self._input_size, self._input_size])
image = tf.cast(image, tf.uint8)
return image
def _preprocess(self, raw_inputs):
"""
Preprocesses raw inputs as sent by the client.
"""
# A mitigation for https://github.com/tensorflow/tensorflow/issues/28007
with tf.device('/cpu:0'):
images = tf.map_fn(self._decode_and_scale, raw_inputs, dtype=tf.uint8)
images = tf.image.convert_image_dtype(images, tf.float32)
return images
def _postprocess(self, model_outputs):
"""
Postprocess outputs returned by the base model.
"""
probabilities = tf.nn.softmax(model_outputs)
indices = tf.argsort(probabilities, axis=1, direction='DESCENDING')
return {
LABELS_KEY: tf.gather(self._output_labels, indices, axis=-1)[:,:NUM_LABELS],
PROBABILITIES_KEY: tf.sort(probabilities, direction='DESCENDING')[:,:NUM_LABELS]
}
@tf.function(input_signature=[tf.TensorSpec([None, 224, 224, 3], tf.float32)])
def __call__(self, x):
"""
A pass-through to the base model.
"""
return self._model(x)
@tf.function(input_signature=[tf.TensorSpec([None], tf.string)])
def predict_labels(self, raw_images):
"""
Preprocesses inputs, calls the base model
and postprocess outputs from the base model.
"""
# Call the preprocessing handler
images = self._preprocess(raw_images)
# Call the base model
logits = self._model(images)
# Call the postprocessing handler
outputs = self._postprocess(logits)
return outputs
serving_module = ServingModule(model, 224, imagenet_labels)
Das folgende Code-Snippet zeigt, wie das Modell als SavedModel mit den zuvor definierten Bereitstellungssignaturen exportiert wird:
...
default_signature = serving_module.__call__.get_concrete_function()
preprocess_signature = serving_module.predict_labels.get_concrete_function()
signatures = {
'serving_default': default_signature,
'serving_preprocess': preprocess_signature
}
tf.saved_model.save(serving_module, model_path, signatures=signatures)
Modell in AI Platform Prediction bereitstellen
Wenn das Modell als SavedModel exportiert wird, werden die folgenden Aufgaben ausgeführt:
- Das Modell wird in Cloud Storage hochgeladen.
- In AI Platform Prediction wird ein Modellobjekt erstellt.
- Für das SavedModel wird eine Modellversion erstellt.
Das folgende Code-Snippet aus dem Notebook zeigt die Befehle, die diese Aufgaben ausführen.
gcloud storage cp {model_path} {GCS_MODEL_LOCATION} --recursive
gcloud ai-platform models create {MODEL_NAME} \
--project {PROJECT_ID} \
--regions {REGION}
MACHINE_TYPE='n1-standard-8'
ACCELERATOR='count=1,type=nvidia-tesla-p4'
gcloud beta ai-platform versions create {MODEL_VERSION} \
--model={MODEL_NAME} \
--origin={GCS_MODEL_LOCATION} \
--runtime-version=2.1 \
--framework=TENSORFLOW \
--python-version=3.7 \
--machine-type={MACHINE_TYPE} \
--accelerator={ACCELERATOR} \
--project={PROJECT_ID}
Der Befehl erstellt einen n1-standard-8-Maschinentyp für den Modellvorhersagedienst zusammen mit einem GPU-Beschleuniger nvidia-tesla-p4.
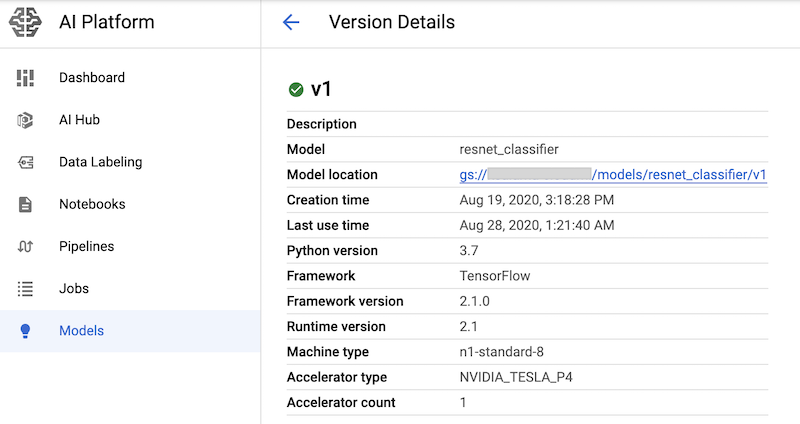
Nachdem Sie die Notebook-Zellen mit diesen Befehlen ausgeführt haben, können Sie überprüfen, ob die Modellversion bereitgestellt wird. Rufen Sie dazu die Seite AI Platform-Modelle der Google Cloud Console auf: Die Ausgabe sieht etwa so aus:
Cloud Monitoring-Messwerte erstellen
Nachdem das Modell für die Bereitstellung eingerichtet wurde, können Sie Messwerte konfigurieren, mit denen Sie die Bereitstellungsleistung überwachen können. Der Code zum Konfigurieren der Messwerte befindet sich im Notebook 02-perf-testing.ipynb.
Im ersten Teil des Notebooks 02-perf-testing.ipynb werden mithilfe des Python Cloud Logging SDK benutzerdefinierte logbasierte Messwerte in Cloud Monitoring erstellt.
Die Messwerte basieren auf den Logeinträgen, die von der Locust-Aufgabe generiert werden.
Mit der Methode log_stats werden die Logeinträge in ein Cloud Logging-Log namens locust geschrieben.
Jeder Logeintrag enthält eine Reihe von Schlüssel/Wert-Paaren im JSON-Format, wie in der folgenden Tabelle aufgeführt. Die Messwerte basieren auf der Teilmenge von Schlüsseln aus dem Logeintrag.
| Schlüssel | Beschreibung des Werts | Nutzung |
|---|---|---|
test_id
|
Die ID eines Tests | Filter- attribute |
model |
Der Name des AI Platform Prediction-Modells | |
model_version |
Die AI Platform Prediction-Modellversion | |
latency
|
Die Antwortzeit des 95. Perzentils, die über ein gleitendes 10-Sekunden-Fenster berechnet wird | Messwerte |
num_requests |
Gesamtzahl der Anfragen seit Beginn des Tests | |
num_failures |
Gesamtzahl der Fehler seit Beginn des Tests | |
user_count |
Anzahl der simulierten Nutzer | |
rps |
Die Anfragen pro Sekunde |
Das folgende Code-Snippet zeigt die Funktion create_locust_metric im Notebook, die einen benutzerdefinierten logbasierten Messwert erstellt.
def create_locust_metric(
metric_name:str,
log_path:str,
value_field:str,
bucket_bounds:List[int]):
metric_path = logging_client.metric_path(PROJECT_ID, metric_name)
log_entry_filter = 'resource.type=global AND logName={}'.format(log_path)
metric_descriptor = {
'metric_kind': 'DELTA',
'value_type': 'DISTRIBUTION',
'labels': [{'key': 'test_id', 'value_type': 'STRING'},
{'key': 'signature', 'value_type': 'STRING'}]}
bucket_options = {
'explicit_buckets': {'bounds': bucket_bounds}}
value_extractor = 'EXTRACT(jsonPayload.{})'.format(value_field)
label_extractors = {
'test_id': 'EXTRACT(jsonPayload.test_id)',
'signature': 'EXTRACT(jsonPayload.signature)'}
metric = logging_v2.types.LogMetric(
name=metric_name,
filter=log_entry_filter,
value_extractor=value_extractor,
bucket_options=bucket_options,
label_extractors=label_extractors,
metric_descriptor=metric_descriptor,
)
try:
logging_client.get_log_metric(metric_path)
print('Metric: {} already exists'.format(metric_path))
except:
logging_client.create_log_metric(parent, metric)
print('Created metric {}'.format(metric_path))
Das folgende Code-Snippet zeigt, wie die Methode create_locust_metric im Notebook aufgerufen wird, um die vier benutzerdefinierten Locust-Messwerte zu erstellen, die in der vorherigen Tabelle angezeigt wurden.
# user count metric
metric_name = 'locust_users'
value_field = 'user_count'
bucket_bounds = [1, 16, 32, 64, 128]
create_locust_metric(metric_name, log_path, value_field, bucket_bounds)
# latency metric
metric_name = 'locust_latency'
value_field = 'latency'
bucket_bounds = [1, 50, 100, 200, 500]
create_locust_metric(metric_name, log_path, value_field, bucket_bounds)
# failure count metric
metric_name = 'num_failures'
value_field = 'num_failures'
bucket_bounds = [1, 1000]
create_locust_metric(metric_name, log_path, value_field, bucket_bounds)
# request count metric
metric_name = 'num_requests'
value_field = 'num_requests'
bucket_bounds = [1, 1000]
create_locust_metric(metric_name, log_path, value_field, bucket_bounds)
Das Notebook erstellt das benutzerdefinierte Cloud Monitoring-Dashboard AI Platform Prediction und Locust. Das Dashboard kombiniert die standardmäßigen AI Platform Prediction-Messwerte mit den benutzerdefinierten Messwerten, die basierend auf den Locust-Logs erstellt wurden.
Weitere Informationen finden Sie in der Dokumentation zur Cloud Logging API.
Dieses Dashboard und seine Diagramme können manuell erstellt werden.
Das Notebook bietet jedoch eine programmatische Möglichkeit, es mithilfe der JSON-Vorlage monitoring-template.json zu erstellen. Der Code verwendet die Klasse DashboardsServiceClient, um die JSON-Vorlage zu laden und das Dashboard in Cloud Monitoring zu erstellen, wie im folgenden Code-Snippet gezeigt:
parent = 'projects/{}'.format(PROJECT_ID)
dashboard_template_file = 'monitoring-template.json'
with open(dashboard_template_file) as f:
dashboard_template = json.load(f)
dashboard_proto = Dashboard()
dashboard_proto = ParseDict(dashboard_template, dashboard_proto)
dashboard = dashboard_service_client.create_dashboard(parent, dashboard_proto)
Nachdem das Dashboard erstellt wurde, wird es in der Liste der Cloud Monitoring-Dashboards in der Google Cloud Console angezeigt:
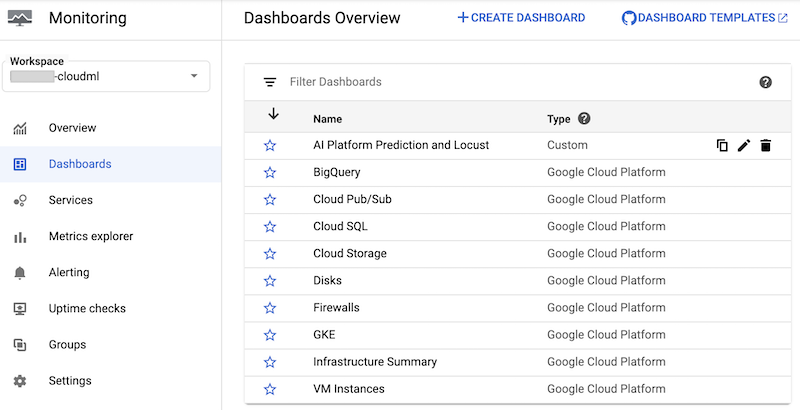
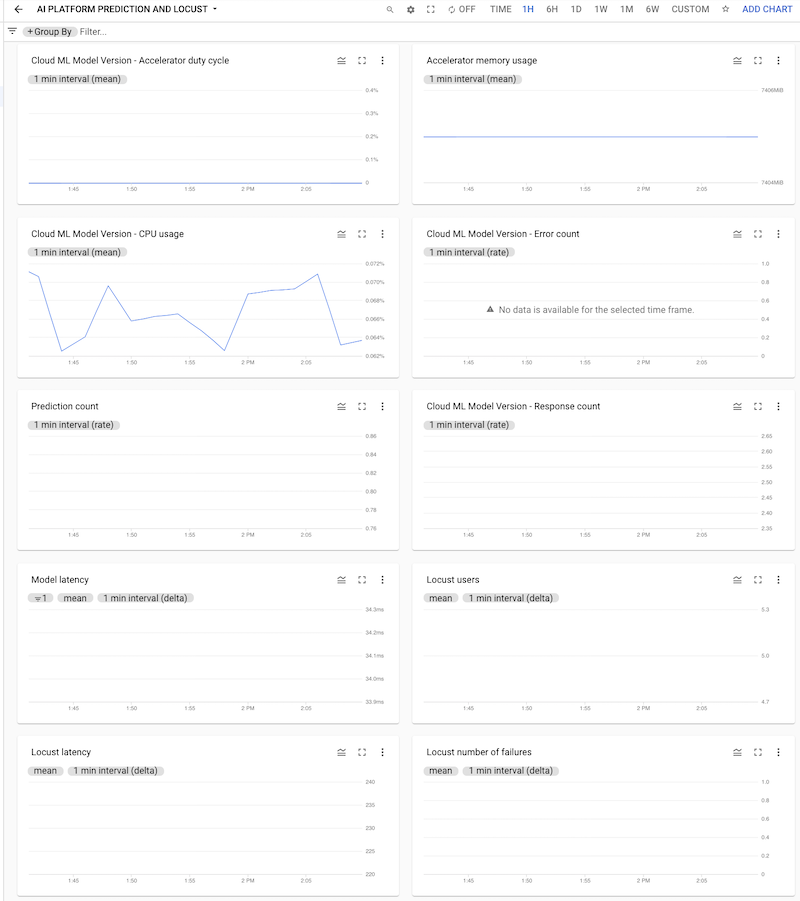
Sie können auf das Dashboard klicken, um es zu öffnen und sich die Diagramme anzusehen. Jedes Diagramm zeigt einen Messwert entweder aus AI Platform Prediction oder aus den Locust-Logs, wie in den folgenden Screenshots dargestellt.
Locust-Test im GKE-Cluster bereitstellen
Bevor Sie das Locust-System in GKE bereitstellen, müssen Sie das Docker-Container-Image erstellen, das die in die Datei task.py eingebundene Testlogik enthält. Das Image wird aus dem baseline locust.io-Image abgeleitet und für die Locust-Master- und -Worker-Pods verwendet.
Die Logik zum Erstellen und Bereitstellen befindet sich im Notebook unter 3. Locust in einem GKE-Cluster bereitstellen. Das Image wird mit dem folgenden Code erstellt:
image_uri = 'gcr.io/{}/locust'.format(PROJECT_ID)
!gcloud builds submit --tag {image_uri} locust/locust-image
Der im Notebook beschriebene Bereitstellungsprozess wurde mit Kustomize definiert. Die Locust Kustomize-Bereitstellungsmanifeste definieren die folgenden Dateien, die Komponenten definieren:
locust-master. Diese Datei definiert eine Bereitstellung, die eine Weboberfläche hostet, auf der Sie den Test starten und sich Live-Statistiken ansehen können.locust-worker. Diese Datei definiert eine Bereitstellung, die eine Aufgabe zum Ausführen eines Lasttests für Ihren ML-Modellvorhersagedienst ausführt. In der Regel werden mehrere Worker erstellt, um die Auswirkungen mehrerer gleichzeitiger Nutzer zu simulieren, die Aufrufe an Ihre Prediction Service API senden.locust-worker-service. Diese Datei definiert einen Dienst, der über einen HTTP-Load-Balancer auf die Weboberfläche inlocust-masterzugreift.
Sie müssen das Standardmanifest aktualisieren, bevor der Cluster bereitgestellt wird. Das Standardmanifest besteht aus den Dateien kustomization.yaml und patch.yaml. Sie müssen Änderungen in beiden Dateien vornehmen.
Führen Sie in der Datei kustomization.yaml folgende Schritte aus:
- Legen Sie den Namen des benutzerdefinierten Locust-Images fest. Setzen Sie im Feld
imagesdas FeldnewNameauf den Namen des benutzerdefinierten Images, das Sie zuvor erstellt haben. - Optional können Sie die Anzahl der Worker-Pods festlegen. In der Standardkonfiguration werden 32 Worker-Pods bereitgestellt. Ändern Sie die Nummer im Feld
countim Abschnittreplicas. Achten Sie darauf, dass Ihr GKE-Cluster eine ausreichende Anzahl von CPUs für die Locust-Worker hat. - Legen Sie den Cloud Storage-Bucket für die Testkonfigurations- und Nutzlastdateien fest. Achten Sie im Abschnitt
configMapGeneratordarauf, dass Folgendes festgelegt ist:LOCUST_TEST_BUCKET. Geben Sie hier den Namen des Cloud Storage-Buckets an, den Sie zuvor erstellt haben.LOCUST_TEST_CONFIG. Legen Sie hier den Namen der Testkonfigurationsdatei fest. In der YAML-Datei ist dies auftest-config.jsongesetzt. Sie können diese Einstellung jedoch ändern, wenn Sie einen anderen Namen verwenden möchten.LOCUST_TEST_PAYLOAD. Legen Sie hier den Namen der Testnutzlastdatei fest. In der YAML-Datei ist dies auftest-payload.jsongesetzt. Sie können diese Einstellung jedoch ändern, wenn Sie einen anderen Namen verwenden möchten.
Führen Sie in der Datei patch.yaml folgende Schritte aus:
- Ändern Sie optional den Knotenpool, der den Locust-Master und die Worker hostet. Wenn Sie die Locust-Arbeitslast in einem anderen Knotenpool als
default-poolbereitstellen, suchen Sie den AbschnittmatchExpressionsund aktualisieren Sie dann untervaluesden Namen des Knotenpools, in dem die Locust-Arbeitslast bereitgestellt wird.
Nachdem Sie diese Änderungen vorgenommen haben, können Sie die Anpassungen in die Kustomize-Manifeste einbinden und die Locust-Bereitstellung (locust-master, locust-worker und locust-master-service) auf den GKE-Cluster anwenden. Mit dem folgenden Befehl im Notebook werden diese Aufgaben ausgeführt:
!kustomize build locust/manifests | kubectl apply -f -
Sie können die bereitgestellten Arbeitslasten in der Google Cloud Console prüfen. Die Ausgabe sieht etwa so aus:
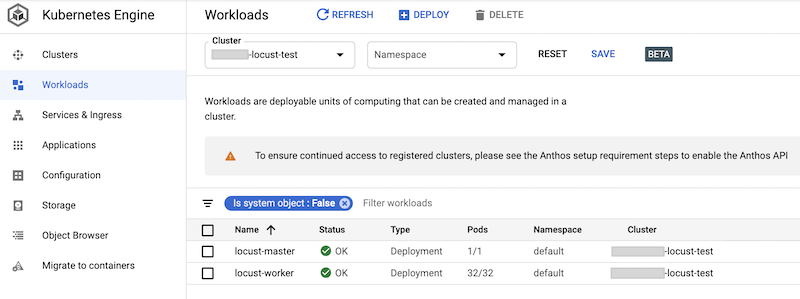
Locust-Lasttest implementieren
Die Testaufgabe für Locust ist, das Modell aufzurufen, das in AI Platform Prediction bereitgestellt wird.
Diese Aufgabe ist in der Klasse AIPPClient im Modul task.py implementiert, das sich im Ordner /locust/locust-image/ befindet. Das folgende Code-Snippet zeigt die Klassenimplementierung.
class AIPPClient(object):
"""
A convenience wrapper around AI Platform Prediction REST API.
"""
def __init__(self, service_endpoint):
logging.info(
"Setting the AI Platform Prediction service endpoint: {}".format(service_endpoint))
credentials, _ = google.auth.default()
self._authed_session = AuthorizedSession(credentials)
self._service_endpoint = service_endpoint
def predict(self, project_id, model, version, signature, instances):
"""
Invokes the predict method on the specified signature.
"""
url = '{}/v1/projects/{}/models/{}/versions/{}:predict'.format(
self._service_endpoint, project_id, model, version)
request_body = {
'signature_name': signature,
'instances': instances
}
response = self._authed_session.post(url, data=json.dumps(request_body))
return response
Die Klasse AIPPUser in der Datei task.py übernimmt die Klasse locust.User, um das Nutzerverhalten des Aufrufens des AI Platform Prediction-Modells zu simulieren. Dieses Verhalten ist in der Methode predict_task implementiert. Mit der Methode on_start der Klasse AIPPUser werden die folgenden Dateien aus einem Cloud Storage-Bucket heruntergeladen, der in der Variable LOCUST_TEST_BUCKET in der Datei task.py angegeben ist:
test-config.json. Diese JSON-Datei enthält die folgenden Konfigurationen für den Test:test_id,project_id,modelundversion.test-payload.json. Diese JSON-Datei enthält die Dateninstanzen in dem Format, das von AI Platform Prediction erwartet wird, sowie die Zielsignatur.
Der Code zur Vorbereitung der Testdaten und der Testkonfiguration ist im Notebook 02-perf-testing.ipynb unter 4. Locust-Test konfigurieren enthalten.
Die Testkonfigurationen und Dateninstanzen werden als Parameter für die Methode predict in der Klasse AIPPClient verwendet, um das Zielmodell mithilfe der erforderlichen Testdaten zu testen. Der AIPPUser
simuliert eine Wartezeit von 1 bis 2 Sekunden zwischen Aufrufen eines einzelnen Nutzers.
Locust-Test ausführen
Nachdem Sie die Notebook-Zellen ausgeführt haben, um die Locust-Arbeitslast im GKE-Cluster bereitzustellen, und nachdem Sie die Dateien test-config.json und test-payload.json erstellt und in Cloud Storage hochgeladen haben, können Sie einen neuen Locust-Lasttest über die Weboberfläche starten, stoppen und konfigurieren.
Der Code im Notebook ruft die URL des externen Load-Balancers ab, der die Weboberfläche mit dem folgenden Befehl bereitstellt:
%%bash
IP_ADDRESS=$(kubectl get service locust-master | awk -v col=4 'FNR==2{print $col}')
echo http://$IP_ADDRESS:8089
So führen Sie den Test durch:
- Geben Sie in einem Browser die URL ein, die Sie abgerufen haben.
Wenn Sie Ihre Testarbeitslast mit verschiedenen Konfigurationen simulieren möchten, geben Sie Werte in die Locust-Oberfläche ein, die in etwa so aussieht:
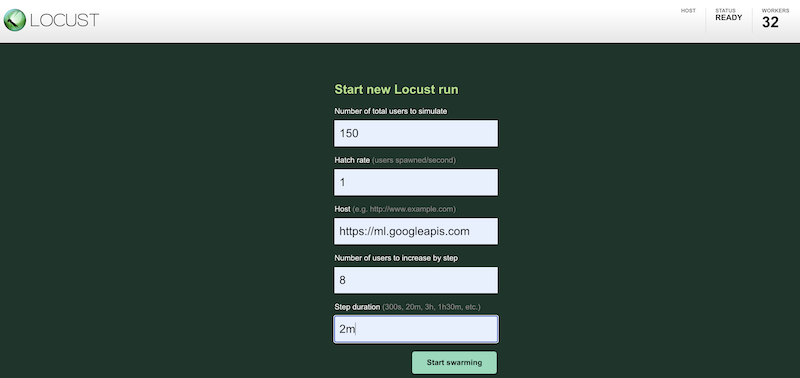
Der vorherige Screenshot zeigt die folgenden Konfigurationswerte:
- Gesamtzahl der zu simulierenden Nutzer:
150 - Erzeugungsrate:
1 - Host:
http://ml.googleapis.com - Anzahl der hinzuzufügenden Nutzer pro Schritt:
10 - Schrittdauer:
2m
- Gesamtzahl der zu simulierenden Nutzer:
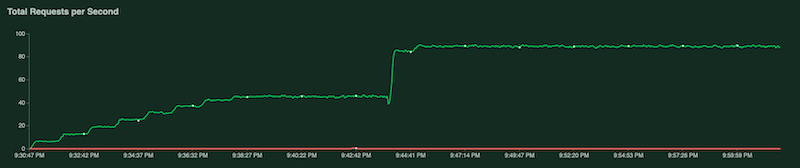
Während der Test ausgeführt wird, können Sie ihn durch Untersuchen von Locust-Diagrammen überwachen. Die folgenden Screenshots zeigen, wie Werte angezeigt werden.
Ein Diagramm zeigt die Gesamtzahl der Anfragen pro Sekunde:
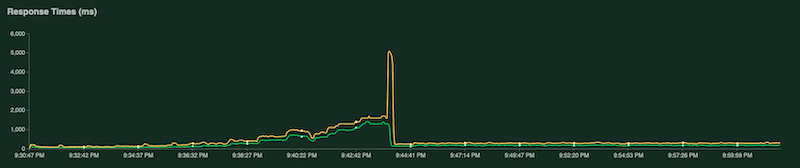
Ein weiteres Diagramm zeigt die Antwortzeit in Millisekunden:
Wie bereits erwähnt, werden diese Statistiken auch in Cloud Logging protokolliert, sodass Sie benutzerdefinierte logbasierte Cloud Monitoring-Messwerte erstellen können.
Testergebnisse erfassen und analysieren
Als Nächstes müssen Sie die Cloud Monitoring-Messwerte erfassen und analysieren, die aus den Ergebnislogs als Pandas-DataFrame-Objekt berechnet werden, damit Sie sie die Ergebnisse im Notebook visualisieren und analysieren können. Der Code zum Ausführen dieser Aufgabe befindet sich im Notebook 03-analyze-results.ipynb.
Der Code verwendet das Cloud Monitoring Query Python SDK zum Filtern und Abrufen der Messwerte mit den Werten, die in den Parametern project_id, test_id, start_time, end_time, model, model_version und log_name übergeben werden.
Das folgende Code-Snippet zeigt die Methoden zum Abrufen von AI Platform Prediction-Messwerten und den benutzerdefinierten logbasierten Locust-Messwerten.
import pandas as pd
from google.cloud.monitoring_v3.query import Query
def _get_aipp_metric(metric_type: str, labels: List[str]=[], metric_name=None)-> pd.DataFrame:
"""
Retrieves a specified AIPP metric.
"""
query = Query(client, project_id, metric_type=metric_type)
query = query.select_interval(end_time, start_time)
query = query.select_resources(model_id=model)
query = query.select_resources(version_id=model_version)
if metric_name:
labels = ['metric'] + labels
df = query.as_dataframe(labels=labels)
if not df.empty:
if metric_name:
df.columns.set_levels([metric_name], level=0, inplace=True)
df = df.set_index(df.index.round('T'))
return df
def _get_locust_metric(metric_type: str, labels: List[str]=[],
metric_name=None)-> pd.DataFrame:
"""
Retrieves a specified custom logs-based metric.
"""
query = Query(client, project_id, metric_type=metric_type)
query = query.select_interval(end_time, start_time)
query = query.select_metrics(log=log_name)
query = query.select_metrics(test_id=test_id)
if metric_name:
labels = ['metric'] + labels
df = query.as_dataframe(labels=labels)
if not df.empty:
if metric_name:
df.columns.set_levels([metric_name], level=0, inplace=True)
df = df.apply(lambda row: [metric.mean for metric in row])
df = df.set_index(df.index.round('T'))
return df
Die Messwertdaten werden als Pandas-DataFrame-Objekt für jeden Messwert abgerufen. Die einzelnen Daten-Frames werden dann zu einem einzigen DataFrame-Objekt zusammengeführt. Das endgültige DataFrame-Objekt mit den zusammengeführten Ergebnissen sieht in Ihrem Notebook so aus:
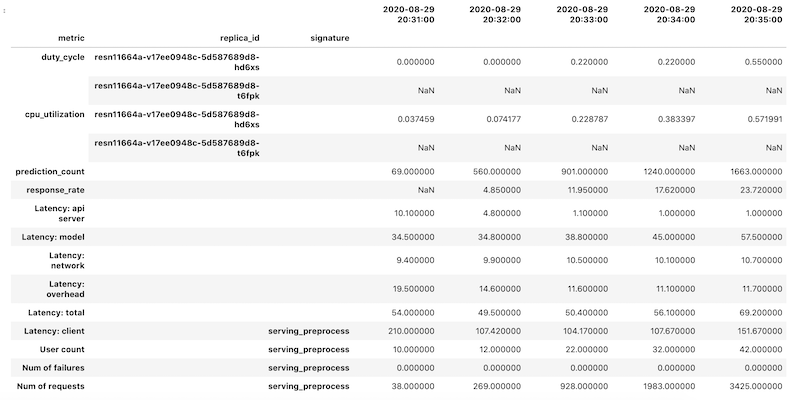
Das abgerufene DataFrame-Objekt verwendet die hierarchische Indexierung für Spaltennamen. Das liegt daran, dass einige Messwerte mehrere Zeitachsen enthalten.
Der GPU-Messwert duty_cycle beispielsweise enthält eine Zeitreihe für jede GPU, die in der Bereitstellung verwendet wird, angegeben als replica_id. Die oberste Ebene des Spaltenindex zeigt den Namen eines einzelnen Messwerts an. Die zweite Ebene ist eine Replikat-ID. Auf der dritten Ebene wird die Signatur eines Modells angezeigt. Alle Messwerte sind auf derselben Zeitreihe ausgerichtet.
Die folgenden Diagramme zeigen die GPU-Auslastung, die CPU-Auslastung und die Latenz, wie Sie sie im Notebook sehen.
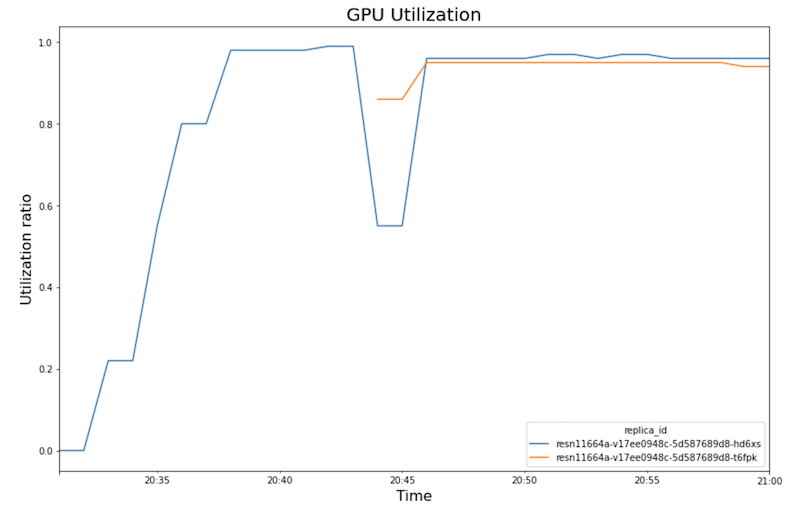
GPU-Auslastung:
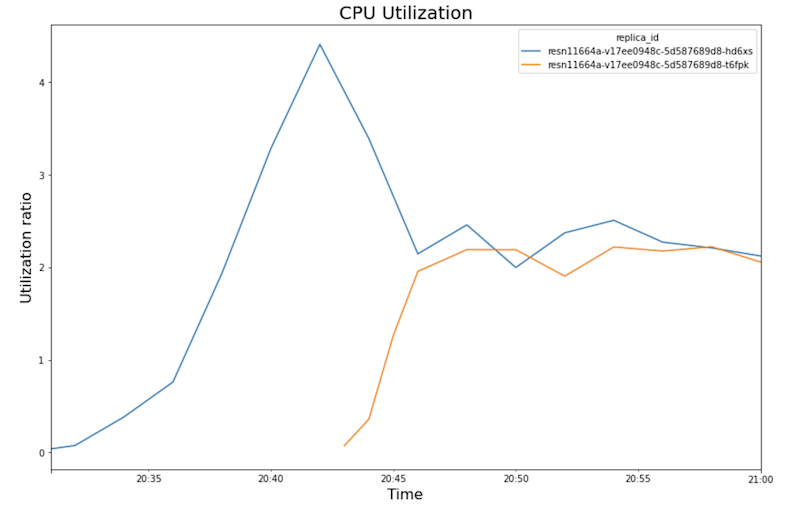
CPU-Auslastung:
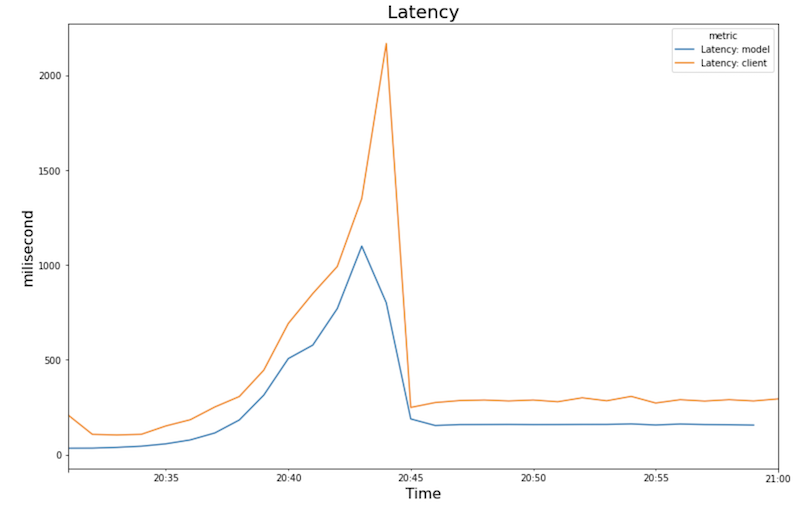
Latenz:
Das Diagramm zeigt Folgendes für Verhalten und Abfolge:
- Mit zunehmender Arbeitslast (Anzahl der Nutzer) steigen die CPU- und die GPU-Auslastung. Infolgedessen erhöht sich die Latenz und der Unterschied zwischen der Modelllatenz und der Gesamtlatenz nimmt bis zum Höchstwert um etwa 20:40 Uhr zu.
- Um 20:40 Uhr erreicht die GPU-Auslastung 100 %, während das CPU-Diagramm zeigt, dass die Auslastung 4 CPUs erreicht. Im Beispiel wird in diesem Test eine
n1-standard-8-Maschine mit acht CPUs verwendet. Daher erreicht die CPU-Auslastung 50 %. - An dieser Stelle fügt das Autoscaling Kapazitäten hinzu: Ein neuer Bereitstellungsknoten wird mit einem zusätzlichen GPU-Replikat hinzugefügt. Die erste GPU-Replikatauslastung nimmt ab und die zweite GPU-Replikatauslastung steigt.
- Die Latenz verringert sich, wenn das neue Replikat mit der Bereitstellung von Vorhersagen beginnt und etwa 200 Millisekunden erreicht.
- Die CPU-Auslastung nähert sich für jedes Replikat etwa 250 % an, was bedeutet, dass 2,5 von 8 CPUs verwendet werden. Dieser Wert bedeutet, dass Sie eine
n1-standard-4-Maschine anstelle einern1-standard-8-Maschine verwenden können.
Bereinigen
Damit Ihrem Google Cloud -Konto die in diesem Dokument verwendeten Ressourcen nicht in Rechnung gestellt werden, löschen Sie entweder das Projekt, das die Ressourcen enthält, oder behalten Sie das Projekt und löschen Sie die einzelnen Ressourcen.
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Wenn Sie das Google Cloud-Projekt beibehalten, aber die von Ihnen erstellten Ressourcen löschen möchten, löschen Sie den Google Kubernetes Engine-Cluster und das bereitgestellte AI Platform-Modell.
Nächste Schritte
- Weitere Informationen zu MLOps, Continuous Delivery und Pipelines zur Automatisierung im maschinellen Lernen
- Weitere Informationen zur Architektur für MLOps mit TFX, Kubeflow Pipelines und Cloud Build
- Weitere Referenzarchitekturen, Diagramme und Best Practices finden Sie im Cloud-Architekturcenter.