Questo documento descrive come configurare OpenTelemetry Collector per eseguire lo scraping delle metriche Prometheus standard e segnalarle a Google Cloud Managed Service per Prometheus. OpenTelemetry Collector è un agente che puoi eseguire il deployment autonomamente e configurare per l'esportazione in Managed Service per Prometheus. La configurazione è simile all'esecuzione di Managed Service per Prometheus con la raccolta con deployment automatico.
Potresti scegliere OpenTelemetry Collector anziché la raccolta con deployment autonomo per i seguenti motivi:
- OpenTelemetry Collector ti consente di indirizzare i dati di telemetria a più backend configurando diversi esportatori nella pipeline.
- Il raccoglitore supporta anche gli indicatori di metriche, log e tracce, quindi utilizzandolo puoi gestire tutti e tre i tipi di indicatori in un unico agente.
- Il formato dei dati indipendente dal fornitore di OpenTelemetry (il protocollo OpenTelemetry o OTLP) supporta un solido ecosistema di librerie e componenti Collector collegabili. Ciò consente una serie di opzioni di personalizzazione per la ricezione, l'elaborazione e l'esportazione dei dati.
Il compromesso per questi vantaggi è che l'esecuzione di un OpenTelemetry Collector richiede un approccio di deployment e manutenzione autogestito. L'approccio che scegli dipende dalle tue esigenze specifiche, ma in questo documento offriamo linee guida consigliate per configurare OpenTelemetry Collector utilizzando Managed Service per Prometheus come backend.
Prima di iniziare
Questa sezione descrive la configurazione necessaria per le attività descritte in questo documento.
Configurare progetti e strumenti
Per utilizzare Google Cloud Managed Service per Prometheus, devi disporre delle seguenti risorse:
Un progetto Google Cloud con l'API Cloud Monitoring abilitata.
Se non hai un Google Cloud progetto, procedi nel seguente modo:
Nella console Google Cloud , vai a Nuovo progetto:
Nel campo Nome progetto, inserisci un nome per il progetto e poi fai clic su Crea.
Vai a Fatturazione:
Seleziona il progetto appena creato se non è già selezionato nella parte superiore della pagina.
Ti viene chiesto di scegliere un profilo pagamenti esistente o di crearne uno nuovo.
L'API Monitoring è abilitata per impostazione predefinita per i nuovi progetti.
Se hai già un progetto Google Cloud , assicurati che l'API Monitoring sia abilitata:
Vai ad API e servizi:
Seleziona il progetto.
Fai clic su Abilita API e servizi.
Cerca "Monitoraggio".
Nei risultati di ricerca, fai clic su "API Cloud Monitoring".
Se non viene visualizzato il messaggio "API abilitata", fai clic sul pulsante Abilita.
Un cluster Kubernetes. Se non hai un cluster Kubernetes, segui le istruzioni riportate nella guida rapida per GKE.
Sono necessari anche i seguenti strumenti a riga di comando:
gcloudkubectl
Gli strumenti gcloud e kubectl fanno parte di
Google Cloud CLI. Per informazioni sulla loro installazione, vedi Gestione dei componenti di Google Cloud CLI. Per visualizzare i componenti di
gcloud CLI installati, esegui questo comando:
gcloud components list
Configura il tuo ambiente
Per evitare di inserire ripetutamente l'ID progetto o il nome del cluster, esegui la seguente configurazione:
Configura gli strumenti a riga di comando come segue:
Configura gcloud CLI in modo che faccia riferimento all'ID del tuo progettoGoogle Cloud :
gcloud config set project PROJECT_ID
Configura la CLI
kubectlper utilizzare il cluster:kubectl config set-cluster CLUSTER_NAME
Per ulteriori informazioni su questi strumenti, consulta quanto segue:
Configurare uno spazio dei nomi
Crea lo spazio dei nomi Kubernetes NAMESPACE_NAME per le risorse che crei
nell'ambito dell'applicazione di esempio:
kubectl create ns NAMESPACE_NAME
Verificare le credenziali del account di servizio
Se nel tuo cluster Kubernetes è abilitata Workload Identity Federation for GKE, puoi saltare questa sezione.
Quando viene eseguito su GKE, Managed Service per Prometheus
recupera automaticamente le credenziali dall'ambiente in base alaccount di serviziont predefinito di Compute Engine. Per impostazione predefinita, il account di servizio predefinito dispone delle autorizzazioni necessarie, monitoring.metricWriter e monitoring.viewer. Se non utilizzi Workload Identity Federation for GKE e hai rimosso in precedenza uno di questi ruoli dall'account di servizio del nodo predefinito, dovrai aggiungere nuovamente le autorizzazioni mancanti prima di continuare.
Configura un account di servizio per Workload Identity Federation for GKE
Se il tuo cluster Kubernetes non ha abilitato Workload Identity Federation for GKE, puoi saltare questa sezione.
Managed Service per Prometheus acquisisce i dati delle metriche utilizzando l'API Cloud Monitoring. Se il tuo cluster utilizza Workload Identity Federation for GKE, devi concedere al tuo account di servizio Kubernetes l'autorizzazione per l'API Monitoring. Questa sezione descrive quanto segue:
- Creazione di un service accountGoogle Cloud dedicato,
gmp-test-sa. - Associazione del service account Google Cloud al service account Kubernetes predefinito in uno spazio dei nomi di test,
NAMESPACE_NAME. - Concessione dell'autorizzazione necessaria al service account Google Cloud .
Crea e associa il account di servizio
Questo passaggio viene visualizzato in diversi punti della documentazione di Managed Service per Prometheus. Se hai già eseguito questo passaggio nell'ambito di un'attività precedente, non è necessario ripeterlo. Vai direttamente alla sezione Autorizzare il service account.
La seguente sequenza di comandi crea il account di servizio gmp-test-sa
e lo associa alaccount di serviziot Kubernetes predefinito nello spazio dei nomi
NAMESPACE_NAME:
gcloud config set project PROJECT_ID \ && gcloud iam service-accounts create gmp-test-sa \ && gcloud iam service-accounts add-iam-policy-binding \ --role roles/iam.workloadIdentityUser \ --member "serviceAccount:PROJECT_ID.svc.id.goog[NAMESPACE_NAME/default]" \ gmp-test-sa@PROJECT_ID.iam.gserviceaccount.com \ && kubectl annotate serviceaccount \ --namespace NAMESPACE_NAME \ default \ iam.gke.io/gcp-service-account=gmp-test-sa@PROJECT_ID.iam.gserviceaccount.com
Se utilizzi uno spazio dei nomi GKE o account di servizio diverso, modifica i comandi di conseguenza.
Autorizzare il account di servizio
I gruppi di autorizzazioni correlate vengono raccolti in ruoli e concedi i ruoli a un'entità, in questo esempio, il account di servizio account Google Cloud. Per ulteriori informazioni sui ruoli di monitoraggio, consulta Controllo dell'accesso.
Il comando seguente concede all'account di servizio Google Cloud ,
gmp-test-sa, i ruoli API Monitoring necessari per
scrivere
dati delle metriche.
Se hai già concesso un ruolo specifico al service account Google Cloud nell'ambito di un'attività precedente, non devi farlo di nuovo.
gcloud projects add-iam-policy-binding PROJECT_ID\ --member=serviceAccount:gmp-test-sa@PROJECT_ID.iam.gserviceaccount.com \ --role=roles/monitoring.metricWriter
Esegui il debug della configurazione di Workload Identity Federation for GKE
Se hai difficoltà a far funzionare Workload Identity Federation for GKE, consulta la documentazione per verificare la configurazione di Workload Identity Federation for GKE e la guida alla risoluzione dei problemi di Workload Identity Federation for GKE.
Poiché gli errori di battitura e i copia-incolla parziali sono le fonti più comuni di errori durante la configurazione di Workload Identity Federation for GKE, ti consigliamo vivamente di utilizzare le variabili modificabili e le icone di copia-incolla selezionabili incorporate negli esempi di codice in queste istruzioni.
Workload Identity Federation for GKE negli ambienti di produzione
L'esempio descritto in questo documento associa il service account Google Cloud al account di servizio Kubernetes predefinito e concede al account di servizio Google Cloudtutte le autorizzazioni necessarie per utilizzare l'API Monitoring.
In un ambiente di produzione, potresti voler utilizzare un approccio più granulare, con unaccount di serviziot per ogni componente, ciascuno con autorizzazioni minime. Per saperne di più sulla configurazione dei service account per la gestione delle identità dei workload, consulta Utilizzare la federazione delle identità dei workload per GKE.
Configura il raccoglitore OpenTelemetry
Questa sezione ti guida nella configurazione e nell'utilizzo di OpenTelemetry Collector per estrarre le metriche da un'applicazione di esempio e inviare i dati a Google Cloud Managed Service per Prometheus. Per informazioni dettagliate sulla configurazione, consulta le sezioni seguenti:
- Recupera le metriche Prometheus
- Aggiungere responsabili del trattamento
- Configurare l'esportatore
googlemanagedprometheus
OpenTelemetry Collector è analogo al binario dell'agente Managed Service per Prometheus. La community OpenTelemetry pubblica regolarmente release che includono codice sorgente, file binari e immagini container.
Puoi eseguire il deployment di questi artefatti su VM o cluster Kubernetes utilizzando i valori predefiniti delle best practice oppure puoi utilizzare lo strumento di creazione di raccoglitori per creare il tuo raccoglitore composto solo dai componenti di cui hai bisogno. Per creare un raccoglitore da utilizzare con Managed Service per Prometheus, devi disporre dei seguenti componenti:
- L'esportatore di Managed Service per Prometheus, che scrive le metriche in Managed Service for Prometheus.
- Un ricevitore per estrarre le metriche. Questo documento presuppone che tu stia utilizzando il ricevitore OpenTelemetry Prometheus, ma l'esportatore Managed Service per Prometheus è compatibile con qualsiasi ricevitore di metriche OpenTelemetry.
- Processori per raggruppare e contrassegnare le metriche in modo da includere identificatori di risorse importanti a seconda dell'ambiente.
Questi componenti vengono abilitati utilizzando un file di configurazione passato al raccoglitore con il flag --config.
Le sezioni seguenti descrivono in dettaglio come configurare ciascuno di questi componenti. Questo documento descrive come eseguire il raccoglitore su GKE e altrove.
Configura ed esegui il deployment del raccoglitore
Indipendentemente dal fatto che esegui la raccolta su Google Cloud o in un altro ambiente, puoi comunque configurare OpenTelemetry Collector per l'esportazione in Managed Service per Prometheus. La differenza maggiore riguarda la configurazione del raccoglitore. Negli ambienti nonGoogle Cloud , potrebbe essere necessario un'ulteriore formattazione dei dati delle metriche per renderli compatibili con Managed Service per Prometheus. Su Google Cloud, tuttavia, gran parte di questa formattazione può essere rilevata automaticamente dal raccoglitore.
Esegui OpenTelemetry Collector su GKE
Puoi copiare la seguente configurazione in un file denominato config.yaml per configurare
OpenTelemetry Collector su GKE:
receivers:
prometheus:
config:
scrape_configs:
- job_name: 'SCRAPE_JOB_NAME'
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_pod_label_app_kubernetes_io_name]
action: keep
regex: prom-example
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
action: replace
regex: (.+):(?:\d+);(\d+)
replacement: $$1:$$2
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
processors:
resourcedetection:
detectors: [gcp]
timeout: 10s
transform:
# "location", "cluster", "namespace", "job", "instance", and "project_id" are reserved, and
# metrics containing these labels will be rejected. Prefix them with exported_ to prevent this.
metric_statements:
- context: datapoint
statements:
- set(attributes["exported_location"], attributes["location"])
- delete_key(attributes, "location")
- set(attributes["exported_cluster"], attributes["cluster"])
- delete_key(attributes, "cluster")
- set(attributes["exported_namespace"], attributes["namespace"])
- delete_key(attributes, "namespace")
- set(attributes["exported_job"], attributes["job"])
- delete_key(attributes, "job")
- set(attributes["exported_instance"], attributes["instance"])
- delete_key(attributes, "instance")
- set(attributes["exported_project_id"], attributes["project_id"])
- delete_key(attributes, "project_id")
batch:
# batch metrics before sending to reduce API usage
send_batch_max_size: 200
send_batch_size: 200
timeout: 5s
memory_limiter:
# drop metrics if memory usage gets too high
check_interval: 1s
limit_percentage: 65
spike_limit_percentage: 20
# Note that the googlemanagedprometheus exporter block is intentionally blank
exporters:
googlemanagedprometheus:
service:
pipelines:
metrics:
receivers: [prometheus]
processors: [batch, memory_limiter, resourcedetection, transform]
exporters: [googlemanagedprometheus]
La configurazione precedente utilizza il ricevitore Prometheus e l'esportatore di Managed Service per Prometheus per eseguire lo scraping degli endpoint delle metriche sui pod Kubernetes ed esportare queste metriche in Managed Service per Prometheus. I processori della pipeline formattano e raggruppano i dati.
Per ulteriori dettagli sulla funzione di ogni parte di questa configurazione, nonché sulle configurazioni per piattaforme diverse, consulta le sezioni seguenti su estrazione delle metriche e aggiunta di processori.
Quando utilizzi una configurazione Prometheus esistente con il ricevitore
prometheus di OpenTelemetry Collector, sostituisci tutti i caratteri del singolo dollaro,
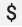 , con caratteri doppi,
, con caratteri doppi, 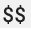 ,
per evitare di attivare la sostituziovariabile di ambientente. Per maggiori informazioni, consulta Scraping delle metriche Prometheus.
,
per evitare di attivare la sostituziovariabile di ambientente. Per maggiori informazioni, consulta Scraping delle metriche Prometheus.
Puoi modificare questa configurazione in base all'ambiente, al provider e alle metriche che vuoi estrarre, ma la configurazione di esempio è un punto di partenza consigliato per l'esecuzione su GKE.
Esegui OpenTelemetry Collector all'esterno Google Cloud
L'esecuzione di OpenTelemetry Collector all'esterno Google Cloud, ad esempio on-premise o su altri cloud provider, è simile all'esecuzione del raccoglitore su GKE. Tuttavia, è meno probabile che le metriche di cui esegui lo scraping includano automaticamente i dati che li formattano al meglio per Managed Service per Prometheus. Pertanto, devi prestare particolare attenzione alla configurazione dell'agente di raccolta per formattare le metriche in modo che siano compatibili con Managed Service per Prometheus.
Puoi copiare la seguente configurazione in un file denominato config.yaml per configurare
OpenTelemetry Collector per il deployment su un cluster Kubernetes non GKE:
receivers:
prometheus:
config:
scrape_configs:
- job_name: 'SCRAPE_JOB_NAME'
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_pod_label_app_kubernetes_io_name]
action: keep
regex: prom-example
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
action: replace
regex: (.+):(?:\d+);(\d+)
replacement: $$1:$$2
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
processors:
resource:
attributes:
- key: "cluster"
value: "CLUSTER_NAME"
action: upsert
- key: "namespace"
value: "NAMESPACE_NAME"
action: upsert
- key: "location"
value: "REGION"
action: upsert
transform:
# "location", "cluster", "namespace", "job", "instance", and "project_id" are reserved, and
# metrics containing these labels will be rejected. Prefix them with exported_ to prevent this.
metric_statements:
- context: datapoint
statements:
- set(attributes["exported_location"], attributes["location"])
- delete_key(attributes, "location")
- set(attributes["exported_cluster"], attributes["cluster"])
- delete_key(attributes, "cluster")
- set(attributes["exported_namespace"], attributes["namespace"])
- delete_key(attributes, "namespace")
- set(attributes["exported_job"], attributes["job"])
- delete_key(attributes, "job")
- set(attributes["exported_instance"], attributes["instance"])
- delete_key(attributes, "instance")
- set(attributes["exported_project_id"], attributes["project_id"])
- delete_key(attributes, "project_id")
batch:
# batch metrics before sending to reduce API usage
send_batch_max_size: 200
send_batch_size: 200
timeout: 5s
memory_limiter:
# drop metrics if memory usage gets too high
check_interval: 1s
limit_percentage: 65
spike_limit_percentage: 20
exporters:
googlemanagedprometheus:
project: "PROJECT_ID"
service:
pipelines:
metrics:
receivers: [prometheus]
processors: [batch, memory_limiter, resource, transform]
exporters: [googlemanagedprometheus]
Questa configurazione esegue le seguenti operazioni:
- Configura una configurazione di scraping per Service Discovery Kubernetes per Prometheus. Per ulteriori informazioni, consulta la sezione Scraping delle metriche Prometheus.
- Imposta manualmente gli attributi delle risorse
cluster,namespaceelocation. Per ulteriori informazioni sugli attributi delle risorse, incluso il rilevamento delle risorse per Amazon EKS e Azure AKS, vedi Rilevare gli attributi delle risorse. - Imposta l'opzione
projectnell'esportatoregooglemanagedprometheus. Per ulteriori informazioni sull'esportatore, vedi Configurare l'esportatoregooglemanagedprometheus.
Quando utilizzi una configurazione Prometheus esistente con il ricevitore
prometheus di OpenTelemetry Collector, sostituisci tutti i caratteri del singolo dollaro,
, con caratteri doppi, ,
per evitare di attivare la sostituziovariabile di ambientente. Per maggiori informazioni, consulta Scraping delle metriche Prometheus.
Per informazioni sulle best practice per la configurazione del raccoglitore su altri cloud, consulta Amazon EKS o Azure AKS.
Esegui il deployment dell'applicazione di esempio
L'applicazione di esempio emette la metrica del contatore
example_requests_total e la metrica dell'istogramma example_random_numbers (tra le altre) sulla porta metrics.
Il manifest per questo esempio definisce tre repliche.
Per eseguire il deployment dell'applicazione di esempio, esegui questo comando:
kubectl -n NAMESPACE_NAME apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/prometheus-engine/v0.15.3/examples/example-app.yaml
Crea la configurazione del collettore come ConfigMap
Dopo aver creato la configurazione e averla inserita in un file denominato config.yaml,
utilizza questo file per creare un oggetto ConfigMap di Kubernetes basato sul file config.yaml.
Quando il raccoglitore viene sottoposto a deployment, monta ConfigMap e carica il file.
Per creare un ConfigMap denominato otel-config con la tua configurazione, utilizza il comando
seguente:
kubectl -n NAMESPACE_NAME create configmap otel-config --from-file config.yaml
Esegui il deployment del raccoglitore
Crea un file denominato collector-deployment.yaml con i seguenti contenuti:
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: NAMESPACE_NAME:prometheus-test
rules:
- apiGroups: [""]
resources:
- pods
verbs: ["get", "list", "watch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: NAMESPACE_NAME:prometheus-test
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: NAMESPACE_NAME:prometheus-test
subjects:
- kind: ServiceAccount
namespace: NAMESPACE_NAME
name: default
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: otel-collector
spec:
replicas: 1
selector:
matchLabels:
app: otel-collector
template:
metadata:
labels:
app: otel-collector
spec:
containers:
- name: otel-collector
image: otel/opentelemetry-collector-contrib:0.128.0
args:
- --config
- /etc/otel/config.yaml
- --feature-gates=exporter.googlemanagedprometheus.intToDouble
volumeMounts:
- mountPath: /etc/otel/
name: otel-config
volumes:
- name: otel-config
configMap:
name: otel-config
Crea il deployment del raccoglitore nel cluster Kubernetes eseguendo il seguente comando:
kubectl -n NAMESPACE_NAME create -f collector-deployment.yaml
Dopo l'avvio del pod, esegue lo scraping dell'applicazione di esempio e segnala le metriche a Managed Service per Prometheus.
Per informazioni sui modi per eseguire query sui dati, consulta Query tramite Cloud Monitoring o Query tramite Grafana.
Fornisci le credenziali in modo esplicito
Quando viene eseguito su GKE, OpenTelemetry Collector
recupera automaticamente le credenziali dall'ambiente in base alaccount di serviziont del nodo.
Nei cluster Kubernetes non GKE, le credenziali devono essere fornite
in modo esplicito a OpenTelemetry Collector utilizzando flag o la
variabile di ambiente GOOGLE_APPLICATION_CREDENTIALS.
Imposta il contesto sul progetto di destinazione:
gcloud config set project PROJECT_ID
Crea un account di servizio:
gcloud iam service-accounts create gmp-test-sa
Questo passaggio crea il account di servizio che potresti aver già creato nelle istruzioni per Workload Identity Federation for GKE.
Concedi le autorizzazioni richieste al account di servizio:
gcloud projects add-iam-policy-binding PROJECT_ID\ --member=serviceAccount:gmp-test-sa@PROJECT_ID.iam.gserviceaccount.com \ --role=roles/monitoring.metricWriter
Crea e scarica una chiave per il account di servizio:
gcloud iam service-accounts keys create gmp-test-sa-key.json \ --iam-account=gmp-test-sa@PROJECT_ID.iam.gserviceaccount.com
Aggiungi il file della chiave come secret al cluster non GKE:
kubectl -n NAMESPACE_NAME create secret generic gmp-test-sa \ --from-file=key.json=gmp-test-sa-key.json
Apri la risorsa di deployment di OpenTelemetry per la modifica:
kubectl -n NAMESPACE_NAME edit deployment otel-collector
Aggiungi il testo mostrato in grassetto alla risorsa:
apiVersion: apps/v1 kind: Deployment metadata: namespace: NAMESPACE_NAME name: otel-collector spec: template spec: containers: - name: otel-collector env: - name: "GOOGLE_APPLICATION_CREDENTIALS" value: "/gmp/key.json" ... volumeMounts: - name: gmp-sa mountPath: /gmp readOnly: true ... volumes: - name: gmp-sa secret: secretName: gmp-test-sa ...Salva il file e chiudi l'editor. Una volta applicata la modifica, i pod vengono ricreati e iniziano l'autenticazione al backend delle metriche con iaccount di serviziont specificato.
Estrai le metriche Prometheus
Questa sezione e quella successiva forniscono ulteriori informazioni sulla personalizzazione per l'utilizzo di OpenTelemetry Collector. Queste informazioni potrebbero essere utili in determinate situazioni, ma nessuna è necessaria per eseguire l'esempio descritto in Configurare OpenTelemetry Collector.
Se le tue applicazioni espongono già endpoint Prometheus, OpenTelemetry Collector può eseguire lo scraping di questi endpoint utilizzando lo stesso formato di configurazione dello scraping che utilizzeresti con qualsiasi configurazione Prometheus standard. Per farlo, attiva il ricevitore Prometheus nella configurazione del raccoglitore.
Una configurazione del ricevitore Prometheus per i pod Kubernetes potrebbe avere il seguente aspetto:
receivers:
prometheus:
config:
scrape_configs:
- job_name: 'kubernetes-pods'
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
action: replace
regex: (.+):(?:\d+);(\d+)
replacement: $$1:$$2
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
service:
pipelines:
metrics:
receivers: [prometheus]
Si tratta di una configurazione di scraping basata sul Service Discovery che puoi modificare in base alle tue esigenze per eseguire lo scraping delle tue applicazioni.
Quando utilizzi una configurazione Prometheus esistente con il ricevitore
prometheus di OpenTelemetry Collector, sostituisci tutti i caratteri del singolo dollaro,
, con caratteri doppi, ,
per evitare di attivare la sostituziovariabile di ambientente. Questo è particolarmente importante per
il valore replacement
all'interno della sezione relabel_configs. Ad esempio, se hai la seguente sezione relabel_config:
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port] action: replace regex: (.+):(?:\d+);(\d+) replacement: $1:$2 target_label: __address__
Poi riscrivilo in questo modo:
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port] action: replace regex: (.+):(?:\d+);(\d+) replacement: $$1:$$2 target_label: __address__
Per saperne di più, consulta la documentazione di OpenTelemetry.
A questo punto, ti consigliamo vivamente di utilizzare i processori per formattare le metriche. In molti casi, i processori devono essere utilizzati per formattare correttamente le metriche.
Aggiungere processori
I processori OpenTelemetry modificano i dati di telemetria prima dell'esportazione. Puoi utilizzare i seguenti processori per assicurarti che le metriche siano scritte in un formato compatibile con Managed Service per Prometheus.
Rilevare gli attributi delle risorse
L'esportatore Managed Service per Prometheus per OpenTelemetry utilizza la
risorsa
prometheus_target monitorata
per identificare in modo univoco i punti dati delle serie temporali. L'esportatore analizza i campi
monitored-resource richiesti dagli attributi delle risorse nei punti dati delle metriche.
I campi e gli attributi da cui vengono estratti i valori sono:
- project_id: rilevato automaticamente da Application Default
Credentials,
gcp.project.idoprojectnella configurazione dell'esportatore (vedi Configurazione dell'esportatore) - location:
location,cloud.availability_zone,cloud.region - cluster:
cluster,k8s.cluster_name - namespace:
namespace,k8s.namespace_name - job:
service.name+service.namespace - instance:
service.instance.id
Se non imposti queste etichette su valori univoci, potrebbero verificarsi errori di "serie temporali duplicate" durante l'esportazione in Managed Service for Prometheus. In molti casi, i valori possono essere rilevati automaticamente per queste etichette, ma in alcuni casi potresti doverli mappare manualmente. Il resto di questa sezione descrive questi scenari.
Il ricevitore Prometheus imposta automaticamente l'attributo service.name
in base a job_name nella configurazione di scraping e l'attributo service.instance.id
in base a instance del target di scraping. Il ricevitore imposta anche
k8s.namespace.name quando si utilizza role: pod nella configurazione dello scraping.
Se possibile, compila automaticamente gli altri attributi utilizzando il processore di rilevamento delle risorse. Tuttavia, a seconda dell'ambiente, alcuni attributi potrebbero non essere rilevabili automaticamente. In questo caso, puoi utilizzare altri processori per inserire manualmente questi valori o analizzarli dalle etichette delle metriche. Le seguenti sezioni illustrano le configurazioni per il rilevamento delle risorse su varie piattaforme.
GKE
Quando esegui OpenTelemetry su GKE, devi abilitare il processore di rilevamento delle risorse per compilare le etichette delle risorse. Assicurati che le metriche non contengano già nessuna delle etichette delle risorse riservate. Se questo è inevitabile, consulta la sezione Evitare conflitti tra attributi delle risorse rinominando gli attributi.
processors:
resourcedetection:
detectors: [gcp]
timeout: 10s
Questa sezione può essere copiata direttamente nel file di configurazione, sostituendo la sezione
processors, se già esistente.
Amazon EKS
Il rilevatore di risorse EKS non compila automaticamente gli attributi cluster o
namespace. Puoi fornire questi valori manualmente utilizzando
il processore
di risorse,
come mostrato nel seguente esempio:
processors:
resourcedetection:
detectors: [eks]
timeout: 10s
resource:
attributes:
- key: "cluster"
value: "my-eks-cluster"
action: upsert
- key: "namespace"
value: "my-app"
action: upsert
Puoi anche convertire questi valori dalle etichette delle metriche utilizzando il processore groupbyattrs (vedi Spostare le etichette delle metriche nelle etichette delle risorse di seguito).
Azure AKS
Il rilevatore di risorse AKS non compila automaticamente gli attributi cluster o
namespace. Puoi fornire questi valori manualmente utilizzando il
processore
di risorse,
come mostrato nell'esempio seguente:
processors:
resourcedetection:
detectors: [aks]
timeout: 10s
resource:
attributes:
- key: "cluster"
value: "my-eks-cluster"
action: upsert
- key: "namespace"
value: "my-app"
action: upsert
Puoi anche convertire questi valori dalle etichette delle metriche utilizzando il processore groupbyattrs; vedi Spostare le etichette delle metriche nelle etichette delle risorse.
Ambienti on-premise e non cloud
Con gli ambienti on-premise o non cloud, probabilmente non puoi rilevare automaticamente nessuno degli attributi di risorsa necessari. In questo caso, puoi emettere queste etichette nelle metriche e spostarle negli attributi delle risorse (vedi Spostare le etichette delle metriche nelle etichette delle risorse) o impostare manualmente tutti gli attributi delle risorse come mostrato nell'esempio seguente:
processors:
resource:
attributes:
- key: "cluster"
value: "my-on-prem-cluster"
action: upsert
- key: "namespace"
value: "my-app"
action: upsert
- key: "location"
value: "us-east-1"
action: upsert
Crea la configurazione del collettore come ConfigMap descrive come
utilizzare la configurazione. In questa sezione si presuppone che tu abbia inserito la configurazione in un file
denominato config.yaml.
L'attributo della risorsa project_id può comunque essere impostato automaticamente quando esegui il raccoglitore con le credenziali predefinite dell'applicazione.
Se il tuo raccoglitore non ha accesso alle Credenziali predefinite dell'applicazione, consulta
Impostazione project_id.
In alternativa, puoi impostare manualmente gli attributi delle risorse che ti servono in una
variabile di ambiente, OTEL_RESOURCE_ATTRIBUTES, con un elenco separato da virgole di
coppie chiave-valore, ad esempio:
export OTEL_RESOURCE_ATTRIBUTES="cluster=my-cluster,namespace=my-app,location=us-east-1"
Quindi, utilizza il processore di rilevamento delle risorse
env
per impostare gli attributi delle risorse:
processors:
resourcedetection:
detectors: [env]
Evitare conflitti tra gli attributi delle risorse rinominandoli
Se le metriche contengono già etichette che entrano in conflitto con gli attributi
delle risorse obbligatori (ad esempio location, cluster o namespace), rinominale
per evitare il conflitto. La convenzione di Prometheus prevede l'aggiunta del prefisso exported_
al nome dell'etichetta. Per aggiungere questo prefisso, utilizza il processore
di trasformazione.
La seguente configurazione processors rinomina eventuali collisioni e
risolve le chiavi in conflitto della metrica:
processors:
transform:
# "location", "cluster", "namespace", "job", "instance", and "project_id" are reserved, and
# metrics containing these labels will be rejected. Prefix them with exported_ to prevent this.
metric_statements:
- context: datapoint
statements:
- set(attributes["exported_location"], attributes["location"])
- delete_key(attributes, "location")
- set(attributes["exported_cluster"], attributes["cluster"])
- delete_key(attributes, "cluster")
- set(attributes["exported_namespace"], attributes["namespace"])
- delete_key(attributes, "namespace")
- set(attributes["exported_job"], attributes["job"])
- delete_key(attributes, "job")
- set(attributes["exported_instance"], attributes["instance"])
- delete_key(attributes, "instance")
- set(attributes["exported_project_id"], attributes["project_id"])
- delete_key(attributes, "project_id")
Spostare le etichette delle metriche nelle etichette delle risorse
In alcuni casi, le metriche potrebbero segnalare intenzionalmente etichette come
namespace perché l'esportatore monitora più spazi dei nomi. Ad
esempio, quando esegui l'esportatore
kube-state-metrics.
In questo scenario, queste etichette possono essere spostate negli attributi delle risorse utilizzando il processore groupbyattrs:
processors:
groupbyattrs:
keys:
- namespace
- cluster
- location
Nell'esempio precedente, data una metrica con le etichette namespace, cluster o location, queste etichette verranno convertite negli attributi della risorsa corrispondenti.
Limitare le richieste API e l'utilizzo della memoria
Altri due processori, il processore batch e il processore di limitazione della memoria, ti consentono di limitare il consumo di risorse del tuo raccoglitore.
Elaborazione dei dati in modalità batch
Il raggruppamento delle richieste consente di definire il numero di punti dati da inviare in un'unica richiesta. Tieni presente che Cloud Monitoring ha un limite di 200 serie temporali per richiesta. Attiva il batch processor utilizzando le seguenti impostazioni:
processors:
batch:
# batch metrics before sending to reduce API usage
send_batch_max_size: 200
send_batch_size: 200
timeout: 5s
Limitazione della memoria
Ti consigliamo di attivare il processore di limitazione della memoria per evitare che il raccoglitore si arresti in modo anomalo in periodi di throughput elevato. Attiva l'elaborazione utilizzando le seguenti impostazioni:
processors:
memory_limiter:
# drop metrics if memory usage gets too high
check_interval: 1s
limit_percentage: 65
spike_limit_percentage: 20
Configura l'esportatore googlemanagedprometheus
Per impostazione predefinita, l'utilizzo dell'esportatore googlemanagedprometheus su GKE
non richiede alcuna configurazione aggiuntiva. Per molti casi d'uso è sufficiente abilitarlo con un blocco vuoto nella sezione exporters:
exporters: googlemanagedprometheus:
Tuttavia, lo strumento di esportazione fornisce alcune impostazioni di configurazione facoltative. Le sezioni seguenti descrivono le altre impostazioni di configurazione.
Impostazione project_id
Per associare la serie temporale a un progetto, la risorsa monitorata deve avere project_id impostato. Google Cloud prometheus_target
Quando esegui OpenTelemetry su Google Cloud, l'esportatore Managed Service per Prometheus imposta questo valore per impostazione predefinita in base alle credenziali predefinite dell'applicazione che trova. Se non sono disponibili credenziali o vuoi eseguire l'override del progetto predefinito, hai due opzioni:
- Imposta
projectnella configurazione dell'esportatore - Aggiungi un attributo della risorsa
gcp.project.idalle metriche.
Consigliamo vivamente di utilizzare il valore predefinito (non impostato) per project_id anziché
impostarlo in modo esplicito, quando possibile.
Imposta project nella configurazione dell'esportatore
Il seguente estratto della configurazione invia le metriche a
Managed Service per Prometheus nel progetto Google Cloud MY_PROJECT:
receivers:
prometheus:
config:
...
processors:
resourcedetection:
detectors: [gcp]
timeout: 10s
exporters:
googlemanagedprometheus:
project: MY_PROJECT
service:
pipelines:
metrics:
receivers: [prometheus]
processors: [resourcedetection]
exporters: [googlemanagedprometheus]
L'unica modifica rispetto agli esempi precedenti è la nuova riga project: MY_PROJECT.
Questa impostazione è utile se sai che ogni metrica che passa attraverso questo
collettore deve essere inviata a MY_PROJECT.
Imposta l'attributo della risorsa gcp.project.id
Puoi impostare l'associazione di progetto in base alla metrica aggiungendo un
attributo risorsa gcp.project.id alle metriche. Imposta il valore dell'attributo sul nome del progetto a cui deve essere associata la metrica.
Ad esempio, se la metrica ha già un'etichetta project, questa etichetta può essere
spostata in un attributo risorsa e rinominata in gcp.project.id utilizzando
i processori nella configurazione del collettore, come mostrato nell'esempio seguente:
receivers:
prometheus:
config:
...
processors:
resourcedetection:
detectors: [gcp]
timeout: 10s
groupbyattrs:
keys:
- project
resource:
attributes:
- key: "gcp.project.id"
from_attribute: "project"
action: upsert
exporters:
googlemanagedprometheus:
service:
pipelines:
metrics:
receivers: [prometheus]
processors: [resourcedetection, groupbyattrs, resource]
exporters: [googlemanagedprometheus]
Impostazione delle opzioni del client
L'esportatore googlemanagedprometheus utilizza i client gRPC per
Managed Service per Prometheus. Pertanto, sono disponibili impostazioni facoltative
per la configurazione del client gRPC:
compression: attiva la compressione gzip per le richieste gRPC, utile per ridurre al minimo le tariffe di trasferimento dei dati quando invii dati da altri cloud a Managed Service for Prometheus (valori validi:gzip).user_agent: sostituisce la stringa user agent inviata nelle richieste a Cloud Monitoring; si applica solo alle metriche. Il valore predefinito è il numero di build e di versione di OpenTelemetry Collector, ad esempioopentelemetry-collector-contrib 0.128.0.endpoint: imposta l'endpoint a cui verranno inviati i dati delle metriche.use_insecure: se è true, utilizza gRPC come trasporto di comunicazione. Ha effetto solo quando il valore diendpointnon è "".grpc_pool_size: imposta la dimensione del pool di connessioni nel client gRPC.prefix: configura il prefisso delle metriche inviate a Managed Service per Prometheus. Il valore predefinito èprometheus.googleapis.com. Non modificare questo prefisso, altrimenti le metriche non potranno essere interrogate con PromQL nella UI di Cloud Monitoring.
Nella maggior parte dei casi, non è necessario modificare i valori predefiniti. Tuttavia, puoi modificarli per adattarli a circostanze speciali.
Tutte queste impostazioni sono impostate in un blocco metric nella sezione
googlemanagedprometheus dell'esportatore, come mostrato nell'esempio seguente:
receivers:
prometheus:
config:
...
processors:
resourcedetection:
detectors: [gcp]
timeout: 10s
exporters:
googlemanagedprometheus:
metric:
compression: gzip
user_agent: opentelemetry-collector-contrib 0.128.0
endpoint: ""
use_insecure: false
grpc_pool_size: 1
prefix: prometheus.googleapis.com
service:
pipelines:
metrics:
receivers: [prometheus]
processors: [resourcedetection]
exporters: [googlemanagedprometheus]
Passaggi successivi
- Utilizza PromQL in Cloud Monitoring per eseguire query sulle metriche Prometheus.
- Utilizza Grafana per eseguire query sulle metriche Prometheus.
- Configura OpenTelemetry Collector come agente sidecar in Cloud Run.
-
La pagina Gestione delle metriche di Cloud Monitoring fornisce informazioni che possono aiutarti a controllare l'importo che spendi per le metriche fatturabili senza influire sull'osservabilità. La pagina Gestione delle metriche riporta le seguenti informazioni:
- Volumi di importazione per la fatturazione basata su byte e su campioni, in tutti i domini delle metriche e per le singole metriche.
- Dati su etichette e cardinalità delle metriche.
- Numero di letture per ogni metrica.
- Utilizzo delle metriche nelle policy di avviso e nelle dashboard personalizzate.
- Tasso di errori di scrittura delle metriche.
Puoi anche utilizzare la pagina Gestione metriche per escludere le metriche non necessarie, eliminando il costo della loro importazione. Per saperne di più sulla pagina Gestione metriche, consulta Visualizzare e gestire l'utilizzo delle metriche.