本文档介绍了如何使用代管式收集设置 Google Cloud Managed Service per Prometheus。此设置是工作注入的最小示例,它使用 Prometheus 部署来监控示例应用并将收集的指标存储在 Monarch 中。
本页面介绍如何完成以下任务:
- 设置环境和命令行工具。
- 为集群设置托管式收集。
- 配置用于目标爬取和指标注入的资源。
- 迁移现有的 prometheus-operator 自定义资源。
我们建议您使用代管式收集;它降低了部署、扩缩、分片、配置和维护收集器的复杂性。GKE 和所有其他 Kubernetes 环境均支持代管式收集。
代管式收集将基于 Prometheus 的收集器作为 Daemonset 运行,并通过仅抓取共置节点上的目标来确保可扩缩性。您可以将具有轻量级自定义资源的收集器配置为使用拉取收集来抓取导出器,然后,收集器将抓取的数据推送到中央数据存储区 Monarch。 Google Cloud 绝不会直接访问集群来拉取或抓取指标数据;收集器将数据推送到Google Cloud。如需详细了解托管式和自行部署的数据收集,请参阅使用 Managed Service for Prometheus 收集数据以及使用托管式和自行部署的收集功能进行注入和查询。
准备工作
本部分介绍本文档中描述的任务所需的配置。
设置项目和工具
要使用 Google Cloud Managed Service for Prometheus,您需要以下资源:
启用了 Cloud Monitoring API 的 Google Cloud 项目。
如果您没有 Google Cloud 项目,请执行以下操作:
在 Google Cloud 控制台中,前往新建项目:
在项目名称字段中,为您的项目输入一个名称,然后点击创建。
转到结算:
在页面顶部选择您刚刚创建的项目(如果尚未选择)。
系统会提示您选择现有付款资料或创建新的付款资料。
默认情况下,新项目会启用 Monitoring API。
如果您已有 Google Cloud 项目,请确保已启用 Monitoring API:
转到 API 和服务:
选择您的项目。
点击启用 API 和服务。
搜索“Monitoring”。
在搜索结果中,点击“Cloud Monitoring API”。
如果未显示“API 已启用”,请点击启用按钮。
Kubernetes 集群。如果您没有 Kubernetes 集群,请按照 GKE 快速入门中的说明进行操作。
您还需要以下命令行工具:
gcloudkubectl
gcloud 和 kubectl 工具是 Google Cloud CLI 的一部分。如需了解如何安装这些工具,请参阅管理 Google Cloud CLI 组件。如需查看已安装的 gcloud CLI 组件,请运行以下命令:
gcloud components list
配置您的环境
为避免重复输入您的项目 ID 或集群名称,请执行以下配置:
按如下方式配置命令行工具:
配置 gcloud CLI 以引用您的Google Cloud 项目的 ID:
gcloud config set project PROJECT_ID
配置
kubectlCLI 以使用集群:kubectl config set-cluster CLUSTER_NAME
如需详细了解这些工具,请参阅以下内容:
设置命名空间
为您在示例应用中创建的资源创建 NAMESPACE_NAME Kubernetes 命名空间:
kubectl create ns NAMESPACE_NAME
设置代管式收集
您可以在 GKE 集群和非 GKE Kubernetes 集群上使用代管式收集。
启用代管式收集后,集群内组件将运行,但不会生成任何指标。这些组件需要 PodMonitoring 或 ClusterPodMonitoring 资源才能正确抓取指标端点。您必须使用有效的指标端点部署这些资源,或者启用某个代管式指标数据包,例如 GKE 中内置的 Kube 状态指标。如需了解问题排查信息,请参阅注入端问题。
启用代管式收集会在集群中安装以下组件:
gmp-operatorDeployment,用于为 Managed Service for Prometheus 部署 Kubernetes Operator。rule-evaluatorDeployment,用于配置并运行提醒和记录规则。collectorDaemonSet,可通过仅从与每个收集器所在节点上运行的 Pod 爬取指标来横向扩缩收集。alertmanagerStatefulSet,配置为将触发的提醒发送到您的首选通知渠道。
如需了解 Managed Service for Prometheus Operator,请参阅清单页面。
启用代管式收集:GKE
默认情况下,系统会为以下各项启动代管式收集:
运行 GKE 1.25 版或更高版本的 GKE Autopilot 集群。
运行 GKE 1.27 版或更高版本的 GKE Standard 集群。您可以在创建集群时替换此默认值;请参阅停用代管式收集。
如果您在默认不启用代管式收集的 GKE 环境中运行,请参阅手动启用代管式收集。
新的集群内组件版本发布后,GKE 上的代管式收集会自动升级。
GKE 上的托管式收集使用向默认 Compute Engine 服务账号授予的权限。如果您的政策修改了默认节点服务账号的标准权限,您可能需要添加 Monitoring Metric Writer 角色以继续。
手动启用托管式集合
如果您在默认不启用托管式收集的 GKE 环境中运行,则可以使用以下项启用托管式收集:
- Cloud Monitoring 中的启用托管式 Prometheus 批量集群信息中心。
- Google Cloud 控制台中的 Kubernetes Engine 页面。
- Google Cloud CLI。如需使用 gcloud CLI,您必须运行 GKE 1.21.4-gke.300 版或更高版本。
适用于 Google Kubernetes Engine 的 Terraform。如需使用 Terraform 启用 Managed Service for Prometheus,您必须运行 GKE 1.21.4-gke.300 或更高版本。
“启用托管式 Prometheus 批量集群”信息中心
您可以使用 Cloud Monitoring 中的启用托管式 Prometheus 批量集群信息中心执行以下操作。
- 确定集群是否已启用 Managed Service for Prometheus,以及您使用的是托管式收集还是自部署收集。
- 在项目中的集群上启用托管式收集。
- 查看有关集群的其他信息。
如需查看启用托管式 Prometheus 批量集群信息中心,请执行以下操作:
-
在 Google Cloud 控制台中,前往
 信息中心页面:
信息中心页面:
如果您使用搜索栏查找此页面,请选择子标题为监控的结果。
使用过滤条件栏搜索启用托管式 Prometheus 批量集群条目,然后选择该条目。
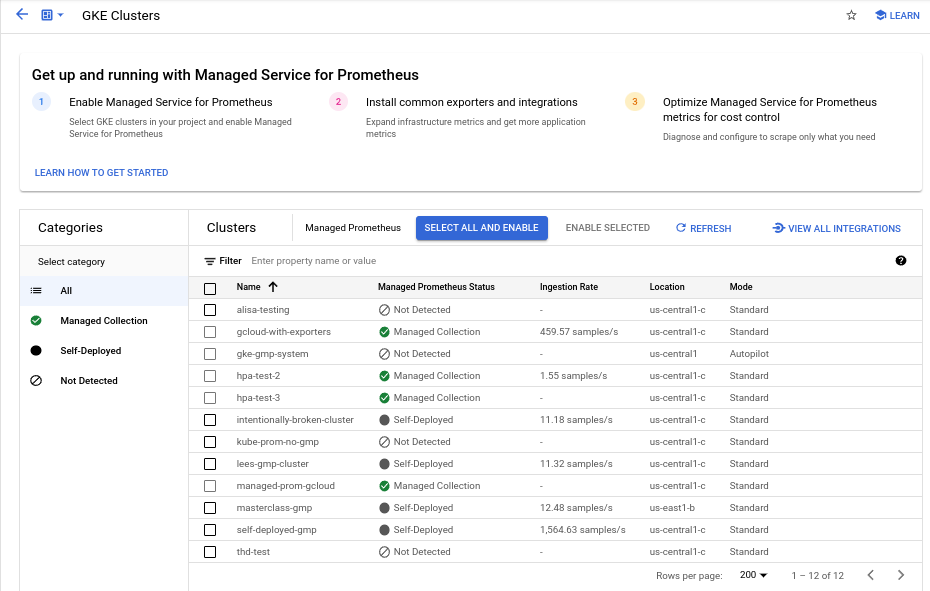
如需使用启用托管式 Prometheus 批量集群信息中心对一个或多个 GKE 集群启用托管式收集,请执行以下操作:
选中要为其启用代管式收集的每个 GKE 集群对应的复选框。
选择启用所选项。
Kubernetes Engine 界面
您可以使用 Google Cloud 控制台执行以下操作:
- 在现有 GKE 集群上启用托管式收集。
- 创建启用了代管式收集的新 GKE 集群。
如需更新现有集群,请执行以下命令:
-
在 Google Cloud 控制台中,前往 Kubernetes 集群页面:
如果您使用搜索栏查找此页面,请选择子标题为 Kubernetes Engine 的结果。
点击集群的名称。
在功能列表中,找到 Managed Service for Prometheus 选项。如果该选项被列为已停用,请点击 edit 修改,然后选择启用 Managed Service for Prometheus。
点击保存更改。
如需创建启用了代管式收集的集群,请执行以下命令:
-
在 Google Cloud 控制台中,前往 Kubernetes 集群页面:
如果您使用搜索栏查找此页面,请选择子标题为 Kubernetes Engine 的结果。
点击创建。
针对标准选项点击配置。
在导航面板中,点击功能。
在操作部分中,选择启用 Managed Service for Prometheus。
点击保存。
gcloud CLI
您可以使用 gcloud CLI 执行以下操作:
- 在现有 GKE 集群上启用托管式收集。
- 创建启用了代管式收集的新 GKE 集群。
这些命令最长可能需要 5 分钟才能完成。
首先,设置您的项目:
gcloud config set project PROJECT_ID
如需更新现有集群,请根据您的集群是可用区级还是区域级来运行以下 update 命令之一:
gcloud container clusters update CLUSTER_NAME --enable-managed-prometheus --zone ZONE
gcloud container clusters update CLUSTER_NAME --enable-managed-prometheus --region REGION
如需创建启用了代管式收集的集群,请运行以下命令:
gcloud container clusters create CLUSTER_NAME --zone ZONE --enable-managed-prometheus
GKE Autopilot
默认情况下,运行 GKE 1.25 或更高版本的 GKE Autopilot 集群支持代管式收集。您无法关闭代管式收集。
如果您的集群在升级到 1.25 时未能自动启用托管式收集,您可以通过运行 gcloud CLI 部分中的更新命令来手动启用它。
Terraform
如需了解如何使用 Terraform 配置代管式收集,请参阅 google_container_cluster 的 Terraform 注册表。
如需了解有关将 Google Cloud 与 Terraform 搭配使用的一般信息,请参阅将 Terraform 与 Google Cloud搭配使用。
停用托管式集合
如果要在集群上停用托管式收集,您可以使用以下方法之一:
Kubernetes Engine 界面
您可以使用 Google Cloud 控制台执行以下操作:
- 在现有 GKE 集群上停用代管式收集。
- 在创建运行 GKE 1.27 版或更高版本的新 GKE Standard 集群时替换自动启用代管式收集。
如需更新现有集群,请执行以下命令:
-
在 Google Cloud 控制台中,前往 Kubernetes 集群页面:
如果您使用搜索栏查找此页面,请选择子标题为 Kubernetes Engine 的结果。
点击集群的名称。
在功能部分中,找到 Managed Service for Prometheus 选项。点击 edit 修改,然后清除启用 Managed Service for Prometheus。
点击保存更改。
如需在创建新的 GKE Standard 集群(1.27 版或更高版本)时替换自动启用代管式收集的功能,请执行以下操作:
-
在 Google Cloud 控制台中,前往 Kubernetes 集群页面:
如果您使用搜索栏查找此页面,请选择子标题为 Kubernetes Engine 的结果。
点击创建。
针对标准选项点击配置。
在导航面板中,点击功能。
在操作部分中,清除启用 Managed Service for Prometheus。
点击保存。
gcloud CLI
您可以使用 gcloud CLI 执行以下操作:
- 在现有 GKE 集群上停用代管式收集。
- 在创建运行 GKE 1.27 版或更高版本的新 GKE Standard 集群时替换自动启用代管式收集。
这些命令最长可能需要 5 分钟才能完成。
首先,设置您的项目:
gcloud config set project PROJECT_ID
如需在现有集群上停用托管式收集功能,请根据集群是可用区级还是区域级来运行以下 update 命令之一:
gcloud container clusters update CLUSTER_NAME --disable-managed-prometheus --zone ZONE
gcloud container clusters update CLUSTER_NAME --disable-managed-prometheus --region REGION
如需在创建新的 GKE Standard 集群(1.27 版或更高版本)时替换自动启用托管式收集的功能,请运行以下命令:
gcloud container clusters create CLUSTER_NAME --zone ZONE --no-enable-managed-prometheus
GKE Autopilot
您无法在运行 GKE 1.25 或更高版本的 GKE Autopilot 集群中停用托管式收集。
Terraform
如需停用托管式收集,请将 managed_prometheus 配置块中的 enabled 属性设置为 false。如需详细了解此配置块,请参阅 google_container_cluster 的 Terraform 注册表。
如需了解有关将 Google Cloud 与 Terraform 搭配使用的一般信息,请参阅将 Terraform 与 Google Cloud搭配使用。
启用代管式收集:非 GKE Kubernetes
如果您正在非 GKE 环境中运行,那么可以使用以下命令启用代管式收集:
kubectlCLI。运行 1.12 版或更高版本的 VMware 或裸金属本地部署。
kubectl CLI
如需在使用非 GKE Kubernetes 集群时安装代管式收集器,请运行以下命令来安装设置和 Operator 清单:
kubectl apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/prometheus-engine/v0.15.3/manifests/setup.yaml kubectl apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/prometheus-engine/v0.15.3/manifests/operator.yaml
本地
如需了解如何为本地集群配置托管式收集功能,请参阅发行版的文档:
部署示例应用
示例应用在其 metrics 端口上发出 example_requests_total 计数器指标和 example_random_numbers 直方图指标(以及其他指标)。应用的清单定义了三个副本。
要部署示例应用,请运行以下命令:
kubectl -n NAMESPACE_NAME apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/prometheus-engine/v0.15.3/examples/example-app.yaml
配置 PodMonitoring 资源
为了注入示例应用发出的指标数据,Managed Service for Prometheus 使用目标爬取。目标爬取和指标注入使用 Kubernetes 自定义资源进行配置。托管式服务使用 PodMonitoring 自定义资源 (CR)。
PodMonitoring CR 仅在部署了 CR 的命名空间中抓取目标。如需抓取多个命名空间中的目标,请在每个命名空间中部署同一 PodMonitoring CR。 您可以通过运行 kubectl get podmonitoring -A 来验证 PodMonitoring 资源是否已安装在预期的命名空间中。
如需查看所有 Managed Service for Prometheus CR 的参考文档,请参阅 prometheus-engine/doc/api 参考文档。
以下清单在 NAMESPACE_NAME 命名空间中定义了 PodMonitoring 资源 prom-example。该资源使用 Kubernetes 标签选择器查找命名空间中值为 prom-example 的 app.kubernetes.io/name 标签的所有 pod。在 /metrics HTTP 路径上,每 30 秒在名为 metrics 的端口上抓取匹配的 Pod。
apiVersion: monitoring.googleapis.com/v1
kind: PodMonitoring
metadata:
name: prom-example
spec:
selector:
matchLabels:
app.kubernetes.io/name: prom-example
endpoints:
- port: metrics
interval: 30s
要应用此资源,请运行以下命令:
kubectl -n NAMESPACE_NAME apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/prometheus-engine/v0.15.3/examples/pod-monitoring.yaml
您的代管式收集器现在正在爬取匹配的 pod。 您可以通过启用目标状态功能来查看爬取目标的状态。
要配置应用于所有命名空间中的一系列 pod 的横向收集,请使用 ClusterPodMonitoring 资源。ClusterPodMonitoring 资源提供与 PodMonitoring 资源相同的接口,但不会将发现的 pod 限制为给定命名空间。
如果您在 GKE 上运行,则可以执行以下操作:
- 如需在 Cloud Monitoring 中使用 PromQL 查询示例应用注入的指标,请参阅使用 Cloud Monitoring 进行查询。
- 如需使用 Grafana 查询示例应用注入的指标,请参阅使用 Grafana 或任何 Prometheus API 使用者进行查询。
- 如需了解如何过滤导出的指标以及调整 prom-operator 资源,请参阅托管式收集的其他主题。
如果您在 GKE 之外运行,则需要创建服务账号并授权其写入指标数据,如以下部分所述。
明确提供凭据
在 GKE 上运行时,收集 Prometheus 服务器会根据节点的服务账号自动从环境中检索凭据。在非 GKE Kubernetes 集群中,必须通过 gmp-public 命名空间中的 OperatorConfig 资源明确提供凭据。
将上下文设置为目标项目:
gcloud config set project PROJECT_ID
创建服务账号:
gcloud iam service-accounts create gmp-test-sa
向服务账号授予所需权限:
gcloud projects add-iam-policy-binding PROJECT_ID\ --member=serviceAccount:gmp-test-sa@PROJECT_ID.iam.gserviceaccount.com \ --role=roles/monitoring.metricWriter
创建并下载服务账号的密钥:
gcloud iam service-accounts keys create gmp-test-sa-key.json \ --iam-account=gmp-test-sa@PROJECT_ID.iam.gserviceaccount.com
将密钥文件作为 Secret 添加到非 GKE 集群:
kubectl -n gmp-public create secret generic gmp-test-sa \ --from-file=key.json=gmp-test-sa-key.json
打开 OperatorConfig 资源以进行修改:
kubectl -n gmp-public edit operatorconfig config
将粗体显示的文本添加到资源:
apiVersion: monitoring.googleapis.com/v1 kind: OperatorConfig metadata: namespace: gmp-public name: config collection: credentials: name: gmp-test-sa key: key.jsonrules部分,以便托管式规则评估正常工作。保存该文件并关闭编辑器。应用更改后,系统会重新创建 pod 并使用给定服务账号向指标后端进行身份验证。
代管式收集的其他主题
本部分介绍了如何执行以下操作:
- 启用目标状态功能,以便更轻松地进行调试。
- 使用 Terraform 配置目标抓取。
- 过滤您导出到托管式服务的数据。
- 抓取 Kubelet 和 cAdvisor 指标。
- 转换现有 prom-operator 资源以用于代管式服务。
- 在 GKE 之外运行代管式收集。
启用目标状态功能
Managed Service for Prometheus 提供了一种方法来检查收集器是否正确发现和抓取了目标。此目标状态报告旨在成为调试严重问题的工具。我们强烈建议您仅在需要调查紧急问题时才启用此功能。在大型集群中开启目标状态报告可能会导致 Operator 耗尽内存并陷入崩溃循环。
您可以通过在 OperatorConfig 资源中将
features.targetStatus.enabled值设置为true来检查 PodMonitoring 或 ClusterPodMonitoring 资源中的目标状态,如下所示:apiVersion: monitoring.googleapis.com/v1 kind: OperatorConfig metadata: namespace: gmp-public name: config features: targetStatus: enabled: true配置后,
Status.Endpoint Statuses字段会在几秒钟后显示在每个有效的 PodMonitoring 或 ClusterPodMonitoring 资源上。如果您在
NAMESPACE_NAME命名空间中有名为prom-example的 PodMonitoring 资源,则可以运行以下命令来检查状态:kubectl -n NAMESPACE_NAME describe podmonitorings/prom-example
输出如下所示:
API Version: monitoring.googleapis.com/v1 Kind: PodMonitoring ... Status: Conditions: ... Status: True Type: ConfigurationCreateSuccess Endpoint Statuses: Active Targets: 3 Collectors Fraction: 1 Last Update Time: 2023-08-02T12:24:26Z Name: PodMonitoring/custom/prom-example/metrics Sample Groups: Count: 3 Sample Targets: Health: up Labels: Cluster: CLUSTER_NAME Container: prom-example Instance: prom-example-589ddf7f7f-hcnpt:metrics Job: prom-example Location: REGION Namespace: NAMESPACE_NAME Pod: prom-example-589ddf7f7f-hcnpt project_id: PROJECT_ID Last Scrape Duration Seconds: 0.020206416 Health: up Labels: ... Last Scrape Duration Seconds: 0.054189485 Health: up Labels: ... Last Scrape Duration Seconds: 0.006224887输出包括以下状态字段:
- 当 Managed Service for Prometheus 确认和处理 PodMonitoring 或 ClusterPodMonitoring 时,
Status.Conditions.Status为 true。 Status.Endpoint Statuses.Active Targets显示 Managed Service for Prometheus 在所有收集器上计算的此 PodMonitoring 资源的爬取目标数。在示例应用中,prom-example部署有三个副本,且具有单个指标目标,因此值为3。如果有健康状况不佳的目标,则会显示Status.Endpoint Statuses.Unhealthy Targets字段。- 如果 Managed Service for Prometheus 可以访问所有代管式收集器,则
Status.Endpoint Statuses.Collectors Fraction显示的值为1(表示 100%)。 Status.Endpoint Statuses.Last Update Time显示上次更新时间。如果上次更新时间显著长于您所需的爬取间隔时间,则差异可能表示目标或集群存在问题。Status.Endpoint Statuses.Sample Groups字段显示按收集器注入的通用目标标签分组的示例目标。此值有助于调试未发现目标的情况。如果所有目标健康状况良好且正在收集,则Health字段的预期值为up,Last Scrape Duration Seconds字段的值是典型目标的常规时长值。
如需详细了解这些字段,请参阅 Managed Service for Prometheus API 文档。
以下各项均表示配置可能存在问题:
- PodMonitoring 资源中没有
Status.Endpoint Statuses字段。 Last Scrape Duration Seconds字段的值太早。- 您看到的目标太少。
Health字段的值表示目标是down。
如需详细了解如何调试目标发现问题,请参阅问题排查文档中的注入端问题。
配置授权的爬取端点
如果您的爬取目标需要授权,您可以将收集器设置为使用正确的授权类型并提供相关 Secret。
Google Cloud Managed Service for Prometheus 支持以下授权类型:
mTLS
mTLS 通常在零信任环境(例如 Istio 服务网格或 Cloud Service Mesh)中配置。
如需爬取使用 mTLS 保护的端点,请将 PodMonitoring 资源中的
Spec.Endpoints[].Scheme字段设置为https。您也可以将 PodMonitoring 资源中的Spec.Endpoints[].tls.insecureSkipVerify字段设置为true,以跳过证书授权机构验证步骤,但我们不建议这样做。或者,您也可以配置 Managed Service for Prometheus,从 Secret 资源加载证书和密钥。例如,以下 Secret 资源包含客户端 (
cert)、私钥 (key) 和证书授权机构 (ca) 证书的密钥:kind: Secret metadata: name: secret-example stringData: cert: ******** key: ******** ca: ********
向 Managed Service for Prometheus 收集器授予访问该 Secret 资源的权限:
apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: secret-example-read rules: - resources: - secrets apiGroups: [""] verbs: ["get", "list", "watch"] resourceNames: ["secret-example"] --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: gmp-system:collector:secret-example-read namespace: default roleRef: name: secret-example-read kind: Role apiGroup: rbac.authorization.k8s.io subjects: - name: collector namespace: gmp-system kind: ServiceAccount
在 GKE Autopilot 集群上,如下所示:
apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: secret-example-read rules: - resources: - secrets apiGroups: [""] verbs: ["get", "list", "watch"] resourceNames: ["secret-example"] --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: gmp-system:collector:secret-example-read namespace: default roleRef: name: secret-example-read kind: Role apiGroup: rbac.authorization.k8s.io subjects: - name: collector namespace: gke-gmp-system kind: ServiceAccount
如需配置使用先前的 Secret 资源的 PodMonitoring 资源,请修改资源以添加
scheme和tls部分:apiVersion: monitoring.googleapis.com/v1 kind: PodMonitoring metadata: name: prom-example spec: selector: matchLabels: app.kubernetes.io/name: prom-example endpoints: - port: metrics interval: 30s scheme: https tls: ca: secret: name: secret-example key: ca cert: secret: name: secret-example key: cert key: secret: name: secret-example key: key如需查看所有 Managed Service for Prometheus mTLS 选项的参考文档,请参阅 API 参考文档。
BasicAuth
如需爬取使用 BasicAuth 保护的端点,请使用您的用户名和密码设置 PodMonitoring 资源中的
Spec.Endpoints[].BasicAuth字段。如需了解其他 HTTP 授权标头类型,请参阅 HTTP 授权标头。例如,以下 Secret 资源包含用于存储密码的密钥:
kind: Secret metadata: name: secret-example stringData: password: ********
向 Managed Service for Prometheus 收集器授予访问该 Secret 资源的权限:
apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: secret-example-read rules: - resources: - secrets apiGroups: [""] verbs: ["get", "list", "watch"] resourceNames: ["secret-example"] --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: gmp-system:collector:secret-example-read namespace: default roleRef: name: secret-example-read kind: Role apiGroup: rbac.authorization.k8s.io subjects: - name: collector namespace: gmp-system kind: ServiceAccount
在 GKE Autopilot 集群上,如下所示:
apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: secret-example-read rules: - resources: - secrets apiGroups: [""] verbs: ["get", "list", "watch"] resourceNames: ["secret-example"] --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: gmp-system:collector:secret-example-read namespace: default roleRef: name: secret-example-read kind: Role apiGroup: rbac.authorization.k8s.io subjects: - name: collector namespace: gke-gmp-system kind: ServiceAccount
如需配置使用先前的 Secret 资源和用户名
foo的 PodMonitoring 资源,请修改资源以添加basicAuth部分:apiVersion: monitoring.googleapis.com/v1 kind: PodMonitoring metadata: name: prom-example spec: selector: matchLabels: app.kubernetes.io/name: prom-example endpoints: - port: metrics interval: 30s basicAuth: username: foo password: secret: name: secret-example key: password如需查看所有 Managed Service for Prometheus BasicAuth 选项的参考文档,请参阅 API 参考文档。
HTTP 授权标头
如需爬取使用 HTTP 授权标头保护的端点,请使用类型和凭据设置 PodMonitoring 资源中的
Spec.Endpoints[].Authorization字段。对于 BasicAuth 端点,请改用 BasicAuth 配置。例如,以下 Secret 资源包含用于存储凭据的密钥:
kind: Secret metadata: name: secret-example stringData: credentials: ********
向 Managed Service for Prometheus 收集器授予访问该 Secret 资源的权限:
apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: secret-example-read rules: - resources: - secrets apiGroups: [""] verbs: ["get", "list", "watch"] resourceNames: ["secret-example"] --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: gmp-system:collector:secret-example-read namespace: default roleRef: name: secret-example-read kind: Role apiGroup: rbac.authorization.k8s.io subjects: - name: collector namespace: gmp-system kind: ServiceAccount
在 GKE Autopilot 集群上,如下所示:
apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: secret-example-read rules: - resources: - secrets apiGroups: [""] verbs: ["get", "list", "watch"] resourceNames: ["secret-example"] --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: gmp-system:collector:secret-example-read namespace: default roleRef: name: secret-example-read kind: Role apiGroup: rbac.authorization.k8s.io subjects: - name: collector namespace: gke-gmp-system kind: ServiceAccount
如需配置使用先前的 Secret 资源和
Bearer类型的 PodMonitoring 资源,请修改资源以添加authorization部分:apiVersion: monitoring.googleapis.com/v1 kind: PodMonitoring metadata: name: prom-example spec: selector: matchLabels: app.kubernetes.io/name: prom-example endpoints: - port: metrics interval: 30s authorization: type: Bearer credentials: secret: name: secret-example key: credentials如需查看所有 Managed Service for Prometheus HTTP 授权标头选项的参考文档,请参阅 API 参考文档。
OAuth 2
如需爬取使用 OAuth 2 保护的端点,您必须在 PodMonitoring 资源中设置
Spec.Endpoints[].OAuth2字段。例如,以下 Secret 资源包含用于存储客户端 Secret 的密钥:
kind: Secret metadata: name: secret-example stringData: clientSecret: ********
向 Managed Service for Prometheus 收集器授予访问该 Secret 资源的权限:
apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: secret-example-read rules: - resources: - secrets apiGroups: [""] verbs: ["get", "list", "watch"] resourceNames: ["secret-example"] --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: gmp-system:collector:secret-example-read namespace: default roleRef: name: secret-example-read kind: Role apiGroup: rbac.authorization.k8s.io subjects: - name: collector namespace: gmp-system kind: ServiceAccount
在 GKE Autopilot 集群上,如下所示:
apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: secret-example-read rules: - resources: - secrets apiGroups: [""] verbs: ["get", "list", "watch"] resourceNames: ["secret-example"] --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: gmp-system:collector:secret-example-read namespace: default roleRef: name: secret-example-read kind: Role apiGroup: rbac.authorization.k8s.io subjects: - name: collector namespace: gke-gmp-system kind: ServiceAccount
如需配置使用先前的客户端 ID 为
foo且令牌网址为example.com/token的 Secret 资源的 PodMonitoring 资源,请修改资源以添加oauth2部分:apiVersion: monitoring.googleapis.com/v1 kind: PodMonitoring metadata: name: prom-example spec: selector: matchLabels: app.kubernetes.io/name: prom-example endpoints: - port: metrics interval: 30s oauth2: clientID: foo clientSecret: secret: name: secret-example key: password tokenURL: example.com/token如需查看所有 Managed Service for Prometheus OAuth 2 选项的参考文档,请参阅 API 参考文档。
使用 Terraform 配置目标抓取
如需自动创建和管理 PodMonitoring 和 ClusterPodMonitoring 资源,您可以使用
kubernetes_manifestTerraform 资源类型或kubectl_manifestTerraform 资源类型,其中任何一个都可让您指定任意的自定义资源。如需了解有关将 Google Cloud 与 Terraform 搭配使用的一般信息,请参阅将 Terraform 与 Google Cloud搭配使用。
过滤导出的指标
如果您收集大量数据,则可能需要防止将一些时序发送到 Managed Service for Prometheus,以降低费用。为此,您可以使用包含
keep操作的 Prometheus 重新添加标签规则作为许可名单,或使用包含drop操作的 Prometheus 重新添加标签规则作为拒绝名单。对于托管式收集,此规则位于 PodMonitoring 或 ClusterPodMonitoring 资源的metricRelabeling部分。例如,以下指标重新添加标签规则将过滤掉以
foo_bar_、foo_baz_或foo_qux_开头的所有指标:metricRelabeling: - action: drop regex: foo_(bar|baz|qux)_.+ sourceLabels: [__name__]Cloud Monitoring 指标管理页面提供的信息可帮助您控制在收费指标上支出的金额,而不会影响可观测性。指标管理页面报告以下信息:
- 针对指标网域中基于字节和基于样本的结算以及各个指标的注入量。
- 有关标签和指标基数的数据。
- 每个指标的读取次数。
- 指标在提醒政策和自定义信息中心内的使用。
- 指标写入错误率。
您还可以使用指标管理来排除不需要的指标,从而免除注入这些指标的费用。 如需详细了解指标管理页面,请参阅查看和管理指标使用情况。
如需了解降低费用的其他建议,请参阅费用控制和归因。
抓取 Kubelet 和 cAdvisor 指标
Kubelet 会公开有关其自身的指标以及有关在其节点上运行的容器的 cAdvisor 指标。您可以通过修改 OperatorConfig 资源,将代管式收集功能配置为抓取 Kubelet 和 cAdvisor 指标。如需查看相关说明,请参阅有关 Kubelet 和 cAdvisor 的导出器文档。
转换现有的 prometheus-operator 资源
您通常可以将现有的 prometheus-operator 资源转换为 Managed Service for Prometheus 代管式收集 PodMonitoring 和 ClusterPodMonitoring 资源。
例如,ServiceMonitor 资源定义了对一组服务的监控。PodMonitoring 资源提供 ServiceMonitor 资源提供的部分字段。您可以通过映射下表中介绍的字段来将 ServiceMonitor CR 转换为 PodMonitoring CR:
monitoring.coreos.com/v1
ServiceMonitor兼容性
monitoring.googleapis.com/v1
PodMonitoring.ServiceMonitorSpec.Selector完全相同 .PodMonitoringSpec.Selector.ServiceMonitorSpec.Endpoints[].TargetPort映射到.Port
.Path:兼容
.Interval:兼容
.Timeout:兼容.PodMonitoringSpec.Endpoints[].ServiceMonitorSpec.TargetLabelsPodMonitor 必须指定:
.FromPod[].Frompod 标签
.FromPod[].To目标标签.PodMonitoringSpec.TargetLabels以下是 ServiceMonitor CR 示例;转换操作会替换粗体内容,而斜体内容则直接映射:
apiVersion: monitoring.coreos.com/v1 kind: ServiceMonitor metadata: name: example-app spec: selector: matchLabels: app: example-app endpoints: - targetPort: web path: /stats interval: 30s targetLabels: - foo以下是类似的 PodMonitoring CR,假设您的服务及其 pod 带有
app=example-app标签。如果此假设不适用,则您需要使用底层 Service 资源的标签选择器。转换操作已替换粗体内容:
apiVersion: monitoring.googleapis.com/v1 kind: PodMonitoring metadata: name: example-app spec: selector: matchLabels: app: example-app endpoints: - port: web path: /stats interval: 30s targetLabels: fromPod: - from: foo # pod label from example-app Service pods. to: foo您始终可以通过自行部署的收集器(而不是代管式收集器)继续使用现有的 prometheus-operator 资源和部署配置。您可以查询从这两种收集器类型发送的指标,因此您可以为现有 Prometheus 部署使用自行部署的收集器,同时为新的 Prometheus 部署使用代管式收集器。
预留标签
Managed Service for Prometheus 会自动将以下标签添加到收集的所有指标。这些标签用于唯一标识 Monarch 中的资源:
project_id:与指标关联的 Google Cloud 项目的标识符。location:存储数据的物理位置(Google Cloud 区域)。此值通常是 GKE 集群所在的区域。如果从 AWS 或本地部署收集数据,则值可能是最接近的 Google Cloud 区域。cluster:与指标关联的 Kubernetes 集群的名称。namespace:与指标关联的 Kubernetes 命名空间的名称。job:Prometheus 目标的作业标签(如果已知);对于规则评估结果,可能为空。instance:Prometheus 目标的实例标签(如果已知);对于规则评估结果,可能为空。
您可以将
project_id、location和cluster标签添加为operator.yaml中的 Deployment 资源的args,从而替换这些标签。但在 Google Kubernetes Engine 上运行时,这不是推荐的方法。如果您使用任何预留标签作为指标标签,则 Prometheus 托管式服务会自动添加前缀exported_以为它们重新添加标签。此行为与上游 Prometheus 处理与预留标签的冲突的方式相匹配。压缩配置
如果您有许多 PodMonitoring 资源,则可能会耗尽 ConfigMap 空间。如需解决此问题,请在 OperatorConfig 资源中启用
gzip压缩:apiVersion: monitoring.googleapis.com/v1 kind: OperatorConfig metadata: namespace: gmp-public name: config features: config: compression: gzip为托管式收集启用 Pod 纵向自动扩缩 (VPA)
如果您在集群中遇到收集器 Pod 内存不足 (OOM) 错误,或者收集器的默认资源请求和限制无法满足您的需求,则可以使用 Pod 纵向自动扩缩来动态分配资源。
当您在
OperatorConfig资源上设置scaling.vpa.enabled: true字段时,Operator 会在集群中部署VerticalPodAutoscaler清单,以便可以根据使用情况自动设置收集器 Pod 的资源请求和限制。如需在 Managed Service for Prometheus 中为收集器 Pod 启用 VPA,请运行以下命令:
kubectl -n gmp-public patch operatorconfig/config -p '{"scaling":{"vpa":{"enabled":true}}}' --type=merge如果该命令成功完成,则 Operator 会为收集器 Pod 设置 Pod 纵向自动扩缩。内存不足错误会导致资源限制立即增加。如果没有 OOM 错误,则收集器 Pod 的资源请求和限制的首次调整通常会在 24 小时内完成。
在尝试启用 VPA 时,您可能会收到以下错误消息:
vertical pod autoscaling is not available - install vpa support and restart the operator如需解决此错误,您需要先在集群级别启用 Pod 纵向自动扩缩:
在Google Cloud 控制台中,前往 Kubernetes Engine - 集群页面。
在 Google Cloud 控制台中,前往 Kubernetes 集群页面:
如果您使用搜索栏查找此页面,请选择子标题为 Kubernetes Engine 的结果。
选择您要修改的集群。
在自动化部分中,修改 Pod 纵向自动扩缩选项的值。
选中启用 Pod 纵向自动扩缩复选框,然后点击保存更改。此更改会重启集群。Operator 会在此过程中重启。
重试命令
kubectl -n gmp-public patch operatorconfig/config -p '{"scaling":{"vpa":{"enabled":true}}}' --type=merge,为 Managed Service for Prometheus 启用 VPA。
如需确认
OperatorConfig资源已成功修改,请使用命令kubectl -n gmp-public edit operatorconfig config打开该资源。如果成功,OperatorConfig会包含以下部分(以粗体显示):apiVersion: monitoring.googleapis.com/v1 kind: OperatorConfig metadata: namespace: gmp-public name: config scaling: vpa: enabled: true如果您已在集群级启用 Pod 纵向自动扩缩,但仍看到
vertical pod autoscaling is not available - install vpa support and restart the operator错误,则gmp-operatorPod 可能需要重新评估集群配置。如果您运行的是 Standard 集群,请运行以下命令以重新创建 Pod:kubectl -n gmp-system rollout restart deployment/gmp-operator
gmp-operatorPod 重启后,请按照上述步骤再次为OperatorConfig打补丁。如果您运行的是 Autopilot 集群,请与支持团队联系以获取有关重启集群的帮助。
在注入稳定数量的样本(平均分配到各个节点)时,Pod 纵向自动扩缩功能效果最佳。如果指标负载不规则或激增,或者如果各个节点之间的指标负载差异很大,VPA 可能不是一个高效的解决方案。
如需了解详情,请参阅 GKE 中的 Pod 纵向自动扩缩。
配置 statsd_exporter 和其他集中报告指标的导出器
如果您使用的是 Prometheus 的 statsd_exporter、Envoy for Istio、SNMP 导出器、Prometheus Pushgateway、kube-state-metrics,或者您使用的是会代表在您的环境中运行的其他资源中间传递和报告指标的类似导出器,那么您需要对导出器进行一些小更改,以便导出器与 Managed Service for Prometheus 配合使用。
如需了解如何配置这些导出器,请参阅“问题排查”部分中的此备注。
删除
如需停用通过
gcloud或 GKE 界面部署的代管式收集,您可以执行以下任一操作:运行以下命令:
gcloud container clusters update CLUSTER_NAME --disable-managed-prometheus
使用 GKE 界面:
在 Google Cloud 控制台中选择 Kubernetes Engine,然后选择集群。
找到要停用代管式收集功能的集群,然后点击其名称。
在详细信息标签页上,向下滚动到功能,然后使用修改按钮将状态切换至已停用。
如需停用通过 Terraform 部署的代管式收集,请在
google_container_cluster资源的managed_prometheus部分中指定enabled = false。如需停用通过
kubectl部署的代管式收集,请运行以下命令:kubectl delete -f https://raw.githubusercontent.com/GoogleCloudPlatform/prometheus-engine/v0.15.3/manifests/operator.yaml
停用代管式收集会导致您的集群停止向 Managed Service for Prometheus 发送新数据。执行此操作不会删除已存储在系统中的任何现有指标数据。
停用代管式收集还会删除
gmp-public命名空间及其中的所有资源,包括该命名空间中所有已安装的导出器。在 GKE 之外运行代管式收集
在 GKE 环境中,您无需进一步配置,即可运行代管式收集。在其他 Kubernetes 环境中,您需要明确提供凭据、用于包含指标的
project-id值、用于存储指标的location值(Google Cloud 区域),以及用于保存收集器运行所在集群的名称的cluster值。由于
gcloud在 Google Cloud 环境之外不起作用,因此您需要改为使用 kubectl 进行部署。与使用gcloud不同,如果使用kubectl部署托管式收集,系统不会在有新版本可用时自动升级集群。请务必检查版本页面是否有新版本,并通过使用新版本重新运行kubectl命令来手动升级。您可以按照明确提供凭据中的说明修改
operator.yaml中的 OperatorConfig 资源,以提供服务账号密钥。如需提供project-id、location和cluster值,您可以将其作为args添加到operator.yaml中的 Deployment 资源中。我们建议您根据计划的读取租用模型选择
project-id。根据您以后计划通过指标范围组织读取的方式,选择用于存储指标的项目。如果您不介意,可以将所有内容放到一个项目中。对于
location,我们建议您选择最靠近您的部署的 Google Cloud 区域。选择的 Google Cloud 区域距离您的部署越远,写入延迟时间就越长,您受到潜在网络问题的影响就越大。建议您参阅跨多个云的区域列表。如果您不介意,则可以将所有内容放入一个 Google Cloud 区域中。您不能将global用作位置。对于
cluster,我们建议您选择在其中部署了运算符的集群的名称。正确配置后,您的 OperatorConfig 应如下所示:
apiVersion: monitoring.googleapis.com/v1 kind: OperatorConfig metadata: namespace: gmp-public name: config collection: credentials: name: gmp-test-sa key: key.json rules: credentials: name: gmp-test-sa key: key.json此外,您的 Deployment 资源应如下所示:
apiVersion: apps/v1 kind: Deployment ... spec: ... template: ... spec: ... containers: - name: operator ... args: - ... - "--project-id=PROJECT_ID" - "--cluster=CLUSTER_NAME" - "--location=REGION"此示例假定您已将
REGION变量设置为us-central1之类的值。在 Google Cloud 之外运行 Managed Service for Prometheus 会产生数据传输费用。将数据传输到 Google Cloud会产生费用,而从另一个云传出数据也可能会产生费用。您可以通过 OperatorConfig 启用在线 gzip 压缩,从而最大限度地降低这些费用。将粗体显示的文本添加到资源:
apiVersion: monitoring.googleapis.com/v1 kind: OperatorConfig metadata: namespace: gmp-public name: config collection: compression: gzip ...关于代管式收集自定义资源的更多内容
如需了解所有 Managed Service for Prometheus 自定义资源的参考文档,请参阅 prometheus-engine/doc/api 参考文档。
后续步骤