En este documento, se describe una configuración para la evaluación de reglas y alertas en un servicio administrado para la implementación de Prometheus que usa la recopilación autoimplementada.
En el siguiente diagrama, se ilustra una implementación que usa varios clústeres en dos proyectos de Google Cloud y usa la evaluación de reglas y alertas:
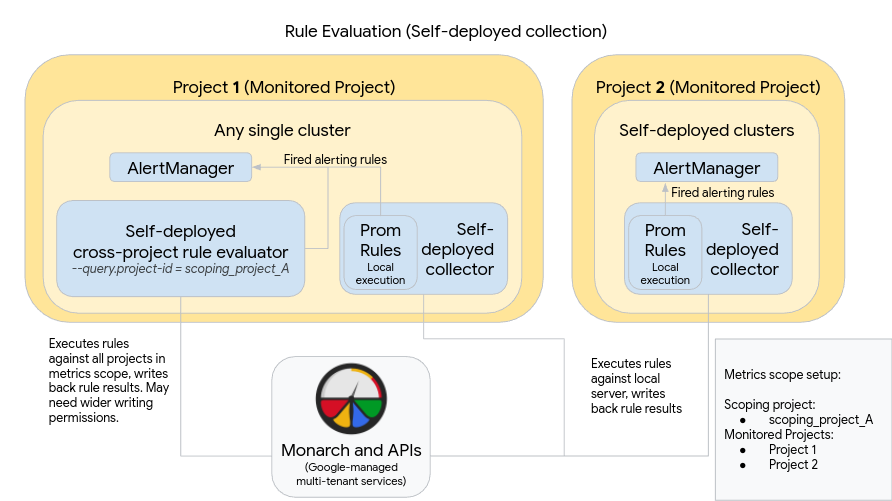
Para configurar y usar una implementación como la del diagrama, ten en cuenta lo siguiente:
Las reglas se instalan dentro de cada servidor de recopilación de Managed Service para Prometheus, tal como lo hacen cuando se usa Prometheus estándar. La evaluación de las reglas se ejecuta en los datos almacenados de forma local en cada servidor. Los servidores están configurados para retener los datos durante el tiempo suficiente a fin de cubrir el período de visualización de todas las reglas, que generalmente no supera 1 hora. Los resultados de las reglas se escriben en Monarch después de la evaluación.
Una instancia de Prometheus AlertManager se implementa de forma manual en cada clúster. Los servidores de Prometheus se configuran mediante la edición del campo
alertmanager_configdel archivo de configuración para enviar reglas de alerta activadas a su instancia de AlertManager local. Los silencios, las confirmaciones y los flujos de trabajo de administración de incidentes suelen manejarse en una herramienta de terceros como PagerDuty.Puedes centralizar la administración de alertas de varios clústeres en un solo AlertManager mediante un recurso Endpoints de Kubernetes.
Un solo clúster que se ejecuta dentro de Google Cloud se designa como el clúster de evaluación de reglas global para un alcance de métricas. El evaluador de reglas independiente se implementa en ese clúster y las reglas se instalan con el formato de archivo de regla estándar de Prometheus.
El evaluador de reglas independiente está configurado para usar scoping_project_A, que contiene los proyectos 1 y 2. Las reglas ejecutadas en scoping_project_A se distribuyen de forma automática a los proyectos 1 y 2. La cuenta de servicio subyacente debe tener los permisos de Monitoring Viewer para scoping_project_A.
El evaluador de reglas está configurado para enviar alertas al Alertmanager local de Prometheus mediante el campo
alertmanager_configdel archivo de configuración.
El uso de un evaluador de reglas global autoimplementado puede tener efectos inesperados, según si conservas o agregas las etiquetas project_id, location, cluster y namespace en tu reglas:
Si tus reglas conservan la etiqueta
project_id(mediante una cláusulaby(project_id)), los resultados de la regla se vuelven a escribir en Monarch con el valor original deproject_idde la serie temporal subyacente.En este caso, debes asegurarte de que la cuenta de servicio subyacente tenga los permisos de Monitoring Metric Writer para cada proyecto supervisado en scoping_project_A. Si agregas un proyecto supervisado nuevo a scoping_project_A, también debes agregar manualmente un permiso nuevo a la cuenta de servicio.
Si tus reglas no conservan la etiqueta
project_id(porque no se usa una cláusulaby(project_id)), los resultados de la regla se vuelven a escribir en Monarch mediante el valorproject_iddel clúster en el que se ejecuta el evaluador de reglas global.En esta situación, no necesitas modificar aún más la cuenta de servicio subyacente.
Si tus reglas conservan la etiqueta
location(porque se usa una cláusulaby(location)), los resultados de la regla se vuelven a escribir en Monarch con cada región original de Google Cloud desde la que se originó la serie temporal subyacente.Si tus reglas no conservan la etiqueta
location, los datos se vuelven a escribir en la ubicación del clúster en el que se ejecuta el evaluador de reglas global.
Recomendamos encarecidamente conservar las etiquetas cluster y namespace en los resultados de la evaluación de reglas siempre que sea posible. De lo contrario, el rendimiento de las consultas podría disminuir y podrías encontrarte con límites de cardinalidad. No se recomienda quitar ambas etiquetas.