In diesem Dokument wird eine Konfiguration für die Regel- und Benachrichtigungsbewertung in einer Managed Service for Prometheus-Bereitstellung beschrieben, die die selbst bereitgestellte Erfassung verwendet.
Das folgende Diagramm veranschaulicht eine Bereitstellung, die mehrere Cluster in zwei Google Cloud -Projekten verwendet und sowohl die Regel- als auch die Benachrichtigungsbewertung verwendet:
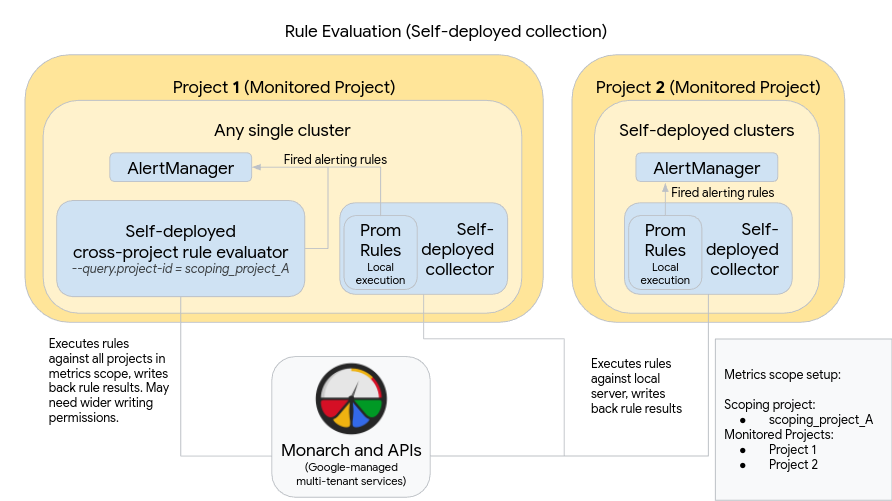
Beachten Sie Folgendes, um eine Bereitstellung wie im Diagramm einzurichten und zu verwenden:
Regeln werden in jedem Managed Service for Prometheus-Erfassungsserver installiert, wie bei der Verwendung von Standard-Prometheus. Die Regelbewertung wird für die Daten ausgeführt, die lokal auf jedem Server gespeichert sind. Die Server sind so konfiguriert, dass Daten so lange aufbewahrt werden, dass der Lookback-Zeitraum aller Regeln abgedeckt wird, der normalerweise nicht mehr als eine Stunde beträgt. Regelergebnisse werden nach der Bewertung in Monarch geschrieben.
Eine Prometheus AlertManager-Instanz wird in jedem einzelnen Cluster manuell bereitgestellt. Um Prometheus-Server zu konfigurieren, bearbeiten Sie das Feld
alertmanager_configder Konfigurationsdatei, um ausgelöste Benachrichtigungsregeln an ihre lokale AlertManager-Instanz zu senden. Stummschaltungen, Bestätigungen und Workflows für das Vorfallmanagement werden normalerweise in einem Drittanbietertool wie PagerDuty verarbeitet.Sie können die Benachrichtigungsverwaltung über mehrere Kubernetes-Endpunkte hinweg in einem einzigen AlertManager verwalten, indem Sie eine Endpunktressource von Kubernetes verwenden.
Ein einzelner Cluster, der in Google Cloud ausgeführt wird, wird als globaler Cluster zur Regelbewertung für einen Messwertbereich festgelegt. Die eigenständige Regelbewertung wird in diesem Cluster bereitgestellt und Regeln werden im Prometheus-Standardformat für Regeldateien installiert.
Die eigenständige Regelbewertung ist für die Verwendung von Bereichsprojekt_A konfiguriert, das die Projekte 1 und 2 enthält. Regeln, die für Bereichsprojekt_A ausgeführt werden, werden automatisch auf die Projekte 1 und 2 verteilt. Dem zugrunde liegenden Dienstkonto müssen die Berechtigungen des Monitoring-Betrachters für Bereichsprojekt_A gewährt werden.
Der Regelbewertung ist so konfiguriert, dass Benachrichtigungen mithilfe des Feldes
alertmanager_configder Konfigurationsdatei an den lokalen Prometheus Alertmanager gesendet werden.
Die Verwendung einer selbst bereitgestellten globalen Regelbewertung kann unerwartete Auswirkungen haben, je nachdem, ob Sie die Labels project_id, location, cluster und namespace in Ihren Regeln beibehalten oder zusammenfassen:
Wenn Ihre Regeln das Label
project_idmithilfe einerby(project_id)-Klausel beibehalten, werden die Regelergebnisse mit dem ursprünglichenproject_id-Wert der zugrunde liegenden Zeitachse wieder in Monarch geschrieben.In diesem Szenario müssen Sie dafür sorgen, dass das zugrunde liegende Dienstkonto die Berechtigungen Monitoring-Messwert-Autor für jedes überwachte Projekt in Bereichsprojekt_A hat. Wenn Sie ein neues überwachtes Projekt zu Bereichsprojekt_A hinzufügen, müssen Sie dem Dienstkonto manuell eine neue Berechtigung hinzufügen.
Wenn Ihre Regeln das Label
project_idnicht beibehalten (da keineby(project_id)-Klausel verwendet wird), werden die Regelergebnisse mit demproject_id-Wert des Clusters, in dem die globale Regelbewertung ausgeführt wird, wieder in Monarch geschrieben.In diesem Szenario müssen Sie das zugrunde liegende Dienstkonto nicht weiter ändern.
Wenn Ihre Regeln das Label
locationmithilfe einerby(location)-Klausel beibehalten, werden die Regelergebnisse mit jeder ursprünglichen Google Cloud -Region, aus der die zugrunde liegende Zeitachse stammt, wieder in Monarch geschrieben.Wenn Ihre Regeln das Label
locationnicht beibehalten, werden die Daten an den Standort des Clusters geschrieben, in dem die globale Regelbewertung ausgeführt wird.
Es wird dringend empfohlen, wenn möglich die Labels cluster und namespace in den Ergebnissen der Regelbewertung beizubehalten. Andernfalls kann die Abfrageleistung sinken und es können Kardinalitätslimits auftreten. Es wird dringend davon abgeraten, beide Labels zu entfernen.