A pesquisa vetorial da Vertex AI permite que os usuários pesquisem itens semanticamente semelhantes usando embeddings de vetor. Usando o fluxo de trabalho do Spanner para a pesquisa de vetores da Vertex AI, é possível integrar seu banco de dados do Spanner à pesquisa de vetores para realizar uma pesquisa de similaridade vetorial nos dados do Spanner.
O diagrama a seguir mostra o fluxo de trabalho de aplicativo de ponta a ponta de como ativar e usar a Pesquisa de vetor nos seus dados do Spanner:
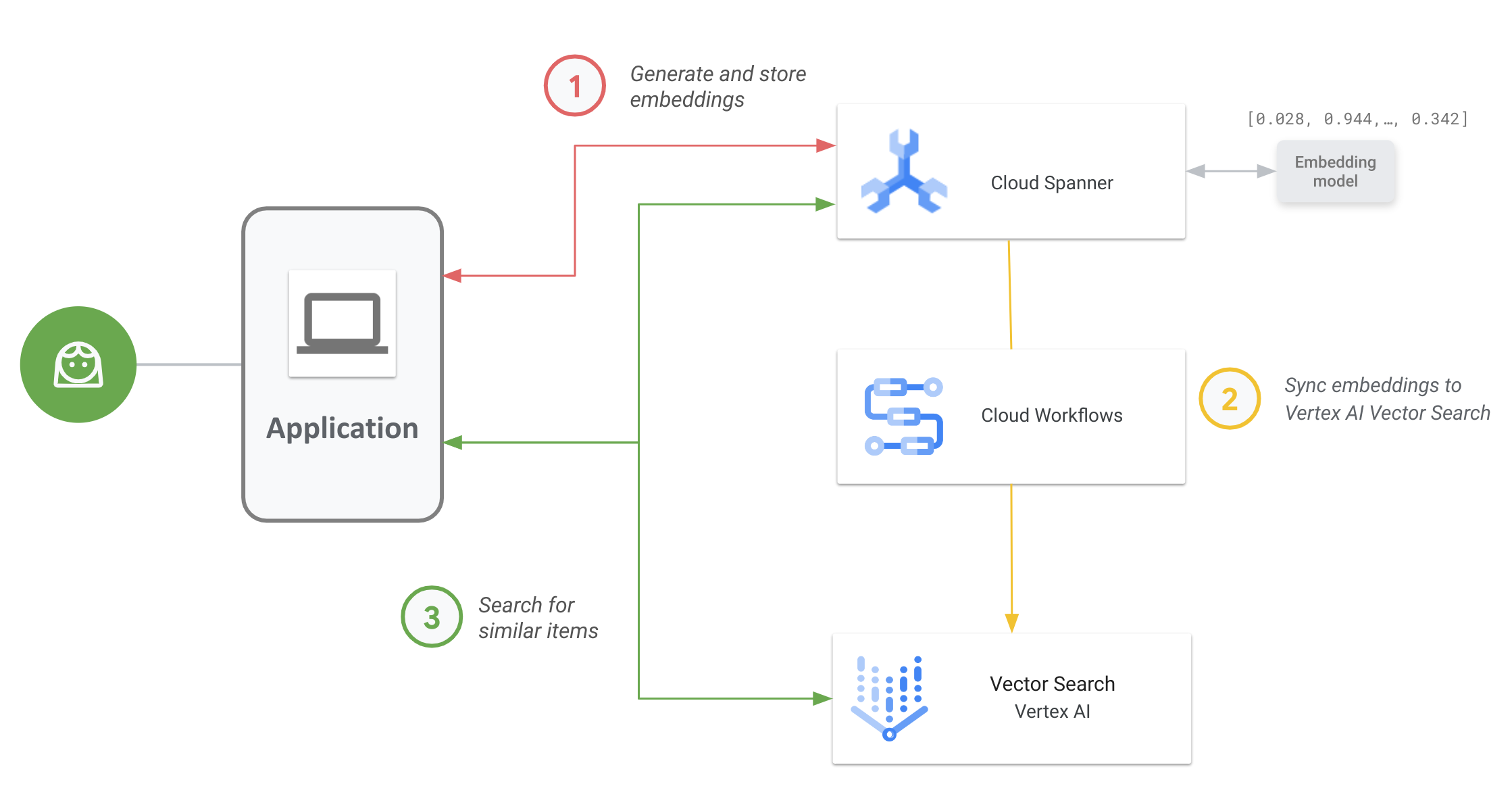
O fluxo de trabalho geral é o seguinte:
Gerar e armazenar embeddings de vetor.
Você pode gerar embeddings de vetor dos seus dados e armazená-los e gerenciá-los no Spanner com seus dados operacionais. É possível gerar embeddings com a função
ML.PREDICTSQL do Spanner para acessar o modelo de embedding de texto da Vertex AI ou usar outros modelos de embedding implantados na Vertex AI.Sincronize embeddings com a Pesquisa de vetor.
Use o fluxo de trabalho do Spanner para a pesquisa de vetores da Vertex AI, que é implantado usando o Workflows para exportar e fazer upload de embeddings em um índice da pesquisa de vetores. Use o Cloud Scheduler para programar periodicamente esse fluxo de trabalho e manter o índice da pesquisa de vetores atualizado com as mudanças mais recentes nos seus embeddings no Spanner.
Realize uma pesquisa de similaridade vetorial usando seu índice do Vector Search.
Consulte o índice da pesquisa vetorial para pesquisar e encontrar resultados de itens semanticamente semelhantes. É possível consultar usando um endpoint público ou por peering de VPC.
Exemplo de caso de uso:
Um caso de uso ilustrativo da pesquisa de vetor é um varejista on-line que tem um inventário com centenas de milhares de itens. Neste cenário, você é um desenvolvedor de uma loja on-line e quer usar a pesquisa de similaridade de vetores no catálogo de produtos do Spanner para ajudar os clientes a encontrar produtos relevantes com base nas consultas de pesquisa.
Siga as etapas 1 e 2 apresentadas no fluxo de trabalho geral para gerar embeddings de vetor para seu catálogo de produtos e sincronize esses embeddings com a Pesquisa de vetor.
Agora imagine um cliente navegando no seu aplicativo e fazendo uma pesquisa como "melhores shorts esportivos de secagem rápida que posso usar na água". Quando o aplicativo receber essa consulta, gere um embedding de solicitação para essa solicitação de pesquisa usando a função SQL ML.PREDICT do Spanner. Use o mesmo modelo de embedding usado para gerar os embeddings do catálogo de produtos.
Em seguida, consulte o índice da Pesquisa de vetor para IDs de produtos cujos embeddings correspondentes sejam semelhantes ao embedding da solicitação gerada pela pesquisa do cliente. O índice de pesquisa pode recomendar IDs de produtos para itens semanticamente semelhantes, como shorts de wakeboard, roupas de surf e sungas.
Depois que a Pesquisa vetorial retorna esses IDs de produtos semelhantes, você pode consultar o Spanner para ver as descrições, a contagem de inventário, o preço e outros metadados relevantes dos produtos e mostrar essas informações ao cliente.
Também é possível usar a IA generativa para processar os resultados retornados do Spanner antes de mostrar para o cliente. Por exemplo, você pode usar os grandes modelos de IA generativa do Google para gerar um resumo conciso dos produtos recomendados. Para mais informações, consulte este tutorial sobre como usar a IA generativa para receber recomendações personalizadas em um aplicativo de e-commerce.
A seguir
- Saiba como gerar embeddings usando o Spanner.
- Saiba mais sobre a multiferramenta de IA: embeddings de vetor
- Saiba mais sobre machine learning e embeddings no nosso curso intensivo sobre embeddings.
- Saiba mais sobre o fluxo de trabalho do Spanner para a pesquisa de vetores da Vertex AI no repositório do GitHub.
- Saiba mais sobre o pacote spanner-analytics de código aberto que facilita operações comuns de análise de dados em Python e inclui integrações com notebooks do Jupyter.