Vertex AI Vector Search memungkinkan pengguna menelusuri item yang mirip secara semantik menggunakan embedding vektor. Dengan menggunakan Alur Kerja Spanner ke Vertex AI Vector Search, Anda dapat mengintegrasikan database Spanner dengan Vector Search untuk melakukan penelusuran kesamaan vektor pada data Spanner.
Diagram berikut menunjukkan alur kerja aplikasi end-to-end tentang cara Anda dapat mengaktifkan dan menggunakan Vector Search pada data Spanner Anda:
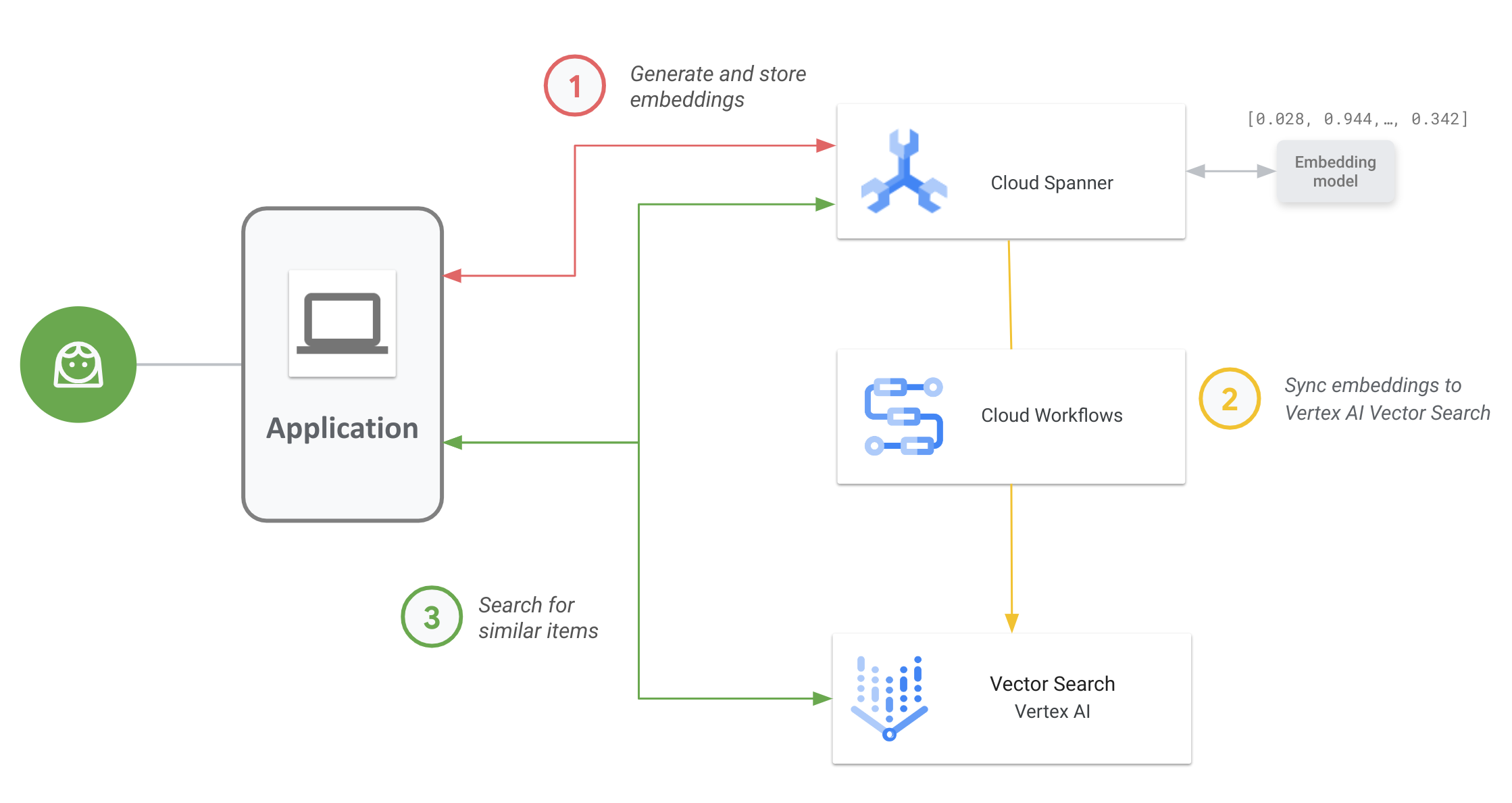
Alur kerja umumnya adalah sebagai berikut:
Buat dan simpan embedding vektor.
Anda dapat membuat embedding vektor data, lalu menyimpan dan mengelolanya di Spanner dengan data operasional Anda. Anda dapat membuat embedding dengan fungsi SQL
ML.PREDICTSpanner untuk mengakses model embedding teks Vertex AI atau menggunakan model embedding lain yang di-deploy ke Vertex AI.Sinkronkan embedding ke Vector Search.
Gunakan Alur Kerja Spanner ke Vertex AI Vector Search, yang di-deploy menggunakan Workflows untuk mengekspor dan mengupload embedding ke indeks Vector Search. Anda dapat menggunakan Cloud Scheduler untuk menjadwalkan alur kerja ini secara berkala agar indeks Vector Search tetap diupdate dengan perubahan terbaru pada embedding di Spanner.
Lakukan penelusuran kemiripan vektor menggunakan indeks Vector Search Anda.
Kueri indeks Vector Search untuk menelusuri dan menemukan hasil untuk item yang mirip secara semantik. Anda dapat membuat kueri menggunakan endpoint publik atau melalui peering VPC.
Contoh kasus penggunaan
Contoh kasus penggunaan untuk Vector Search adalah retailer online yang memiliki inventaris ratusan ribu item. Dalam skenario ini, Anda adalah developer untuk retailer online, dan Anda ingin menggunakan penelusuran kesamaan vektor pada katalog produk di Spanner untuk membantu pelanggan menemukan produk yang relevan berdasarkan kueri penelusuran mereka.
Ikuti langkah 1 dan langkah 2 yang dijelaskan dalam alur kerja umum untuk membuat embedding vektor untuk katalog produk Anda, dan sinkronkan embedding ini ke Vector Search.
Sekarang bayangkan pelanggan yang menjelajahi aplikasi Anda melakukan penelusuran seperti
"celana pendek olahraga cepat kering terbaik yang bisa saya pakai di dalam air". Saat aplikasi Anda menerima kueri ini, Anda perlu membuat embedding permintaan untuk permintaan penelusuran ini menggunakan fungsi SQL ML.PREDICT Spanner. Pastikan untuk menggunakan model embedding yang sama dengan yang digunakan untuk membuat embedding katalog produk Anda.
Selanjutnya, kueri indeks Vector Search untuk ID produk yang embedding terkaitnya mirip dengan embedding permintaan yang dihasilkan dari permintaan penelusuran pelanggan Anda. Indeks penelusuran dapat merekomendasikan ID produk untuk item yang serupa secara semantik seperti celana wakeboarding, pakaian selancar, dan celana renang.
Setelah Vector Search menampilkan ID produk serupa ini, Anda dapat membuat kueri Spanner untuk deskripsi, jumlah inventaris, harga, dan metadata relevan lainnya dari produk, lalu menampilkannya kepada pelanggan.
Anda juga dapat menggunakan AI generatif untuk memproses hasil yang ditampilkan dari Spanner sebelum menampilkannya kepada pelanggan Anda. Misalnya, Anda dapat menggunakan model AI generatif besar Google untuk membuat ringkasan singkat produk yang direkomendasikan. Untuk informasi selengkapnya, lihat tutorial tentang cara menggunakan AI Generatif untuk mendapatkan rekomendasi yang dipersonalisasi dalam aplikasi e-commerce.
Langkah berikutnya
- Pelajari cara membuat sematan menggunakan Spanner.
- Pelajari lebih lanjut Alat serba guna AI: Embedding vektor
- Pelajari lebih lanjut machine learning dan penyematan di kursus singkat tentang penyematan kami.
- Untuk mempelajari lebih lanjut Alur Kerja Spanner To Vertex AI Vector Search, lihat repositori GitHub.
- Pelajari lebih lanjut paket spanner-analytics open source yang memfasilitasi operasi analisis data umum di Python dan mencakup integrasi dengan Notebook Jupyter.