A Vertex AI Vector Search permite que os utilizadores pesquisem itens semanticamente semelhantes através de incorporações vetoriais. Com o fluxo de trabalho do Spanner para o Vertex AI Vector Search, pode integrar a sua base de dados do Spanner com o Vector Search para realizar uma pesquisa de similaridade vetorial nos seus dados do Spanner.
O diagrama seguinte mostra o fluxo de trabalho da aplicação integral de como pode ativar e usar a pesquisa vetorial nos seus dados do Spanner:
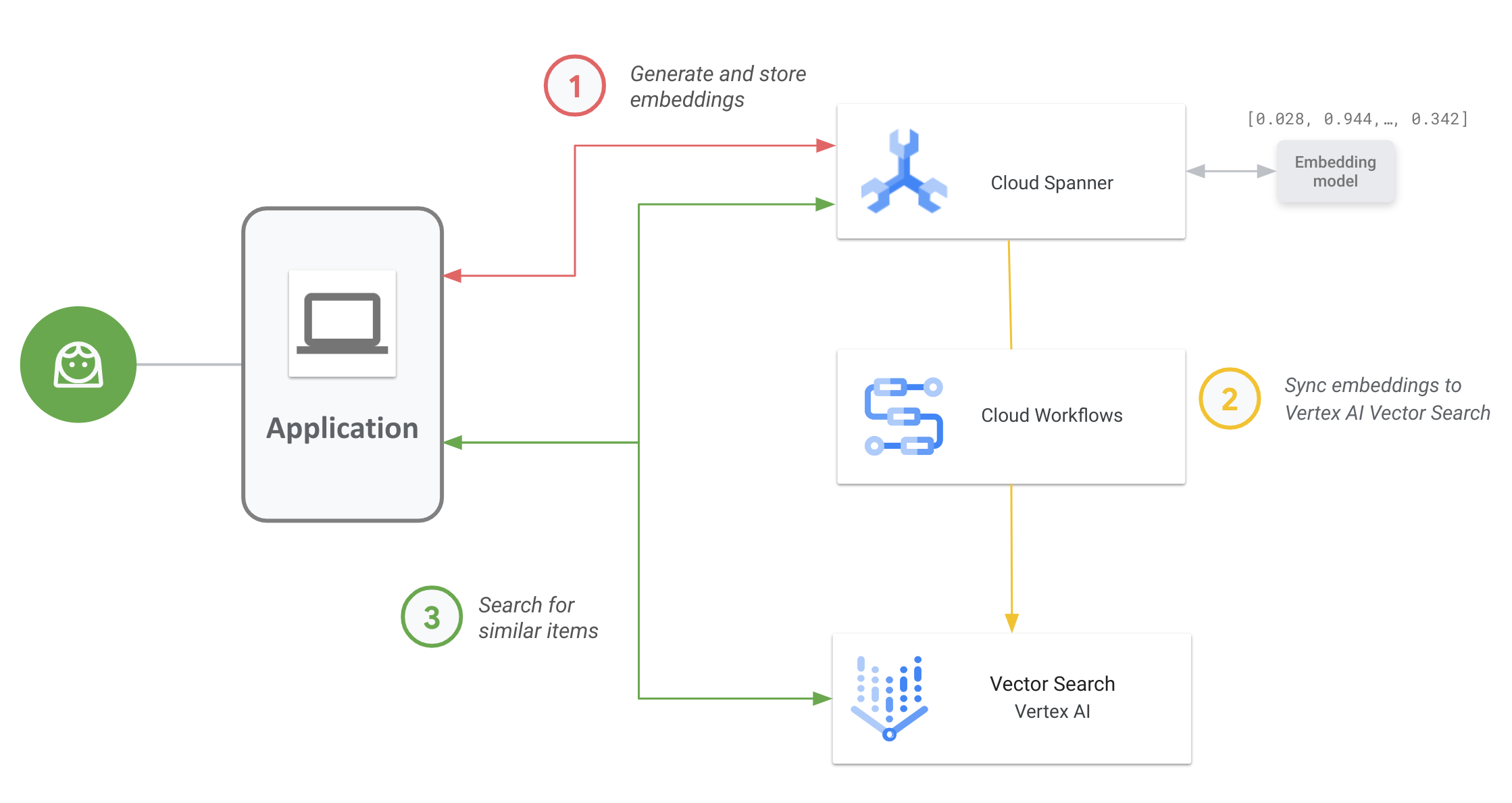
O fluxo de trabalho geral é o seguinte:
Gere e armazene incorporações vetoriais.
Pode gerar incorporações vetoriais dos seus dados e, em seguida, armazená-los e gerir no Spanner com os seus dados operacionais. Pode gerar incorporações com a função
ML.PREDICTSQL do Spanner para aceder ao modelo de incorporação de texto do Vertex AI ou usar outros modelos de incorporação implementados no Vertex AI.Sincronize incorporações com a Vector Search.
Use o fluxo de trabalho do Spanner para o Vertex AI Vector Search, que é implementado através dos fluxos de trabalho para exportar e carregar incorporações num índice do Vector Search. Pode usar o Cloud Scheduler para agendar periodicamente este fluxo de trabalho de modo a manter o índice de pesquisa vetorial atualizado com as alterações mais recentes às suas incorporações no Spanner.
Realize uma pesquisa de similaridade vetorial usando o seu índice do Vector Search.
Consultar o índice do Vector Search para pesquisar e encontrar resultados de itens semanticamente semelhantes. Pode consultar através de um ponto final público ou através da interligação de VPCs.
Exemplo de utilização
Um exemplo de utilização ilustrativo da pesquisa vetorial é um retalhista online que tem um inventário de centenas de milhares de artigos. Neste cenário, é um programador de um retalhista online e quer usar a pesquisa de similaridade vetorial no seu catálogo de produtos no Spanner para ajudar os seus clientes a encontrar produtos relevantes com base nas respetivas consultas de pesquisa.
Siga os passos 1 e 2 apresentados no fluxo de trabalho geral para gerar incorporações de vetores para o seu catálogo de produtos e sincronizar estas incorporações com a pesquisa vetorial.
Agora, imagine que um cliente a explorar a sua aplicação faz uma pesquisa como "melhores calções desportivos de secagem rápida que posso usar na água". Quando a sua aplicação recebe esta consulta, tem de gerar uma incorporação de pedidos para este pedido de pesquisa através da função SQL ML.PREDICT do Spanner. Certifique-se de que usa o mesmo modelo de incorporação usado para gerar as incorporações para o seu catálogo de produtos.
Em seguida, consulte o índice do Vector Search para IDs de produtos cujas incorporações correspondentes sejam semelhantes à incorporação do pedido gerada a partir do pedido de pesquisa do cliente. O índice de pesquisa pode recomendar IDs de produtos para itens semanticamente semelhantes, como calções de wakeboard, vestuário de surf e calções de banho.
Depois de a pesquisa vetorial devolver estes IDs de produtos semelhantes, pode consultar o Spanner para obter as descrições, a quantidade em inventário, o preço e outros metadados relevantes dos produtos, e apresentá-los ao cliente.
Também pode usar a IA generativa para processar os resultados devolvidos do Spanner antes de os apresentar ao seu cliente. Por exemplo, pode usar os modelos de IA generativa grandes da Google para gerar um resumo conciso dos produtos recomendados. Para mais informações, consulte este tutorial sobre como usar a IA generativa para receber recomendações personalizadas numa aplicação de comércio eletrónico.
O que se segue?
- Saiba como gerar incorporações com o Spanner.
- Saiba mais sobre a ferramenta multifunções da IA: incorporações vetoriais
- Saiba mais sobre a aprendizagem automática e as incorporações no nosso curso intensivo sobre incorporações.
- Para saber mais sobre o fluxo de trabalho do Spanner para o Vertex AI Vector Search, consulte o repositório do GitHub.
- Saiba mais acerca do pacote spanner-analytics de código aberto que facilita as operações de análise de dados comuns em Python e inclui integrações com os Jupyter Notebooks.