Vertex AI 벡터 검색을 사용하면 사용자가 벡터 임베딩을 사용하여 의미상 유사한 항목을 검색할 수 있습니다. Spanner To Vertex AI Vector Search 워크플로를 사용하면 Spanner 데이터베이스를 벡터 검색과 통합하여 Spanner 데이터에서 벡터 유사성 검색을 수행할 수 있습니다.
다음 다이어그램에서는 Spanner 데이터에 대한 벡터 검색을 사용 설정하고 사용하는 방법에 대한 엔드 투 엔드 애플리케이션 워크플로를 보여줍니다.
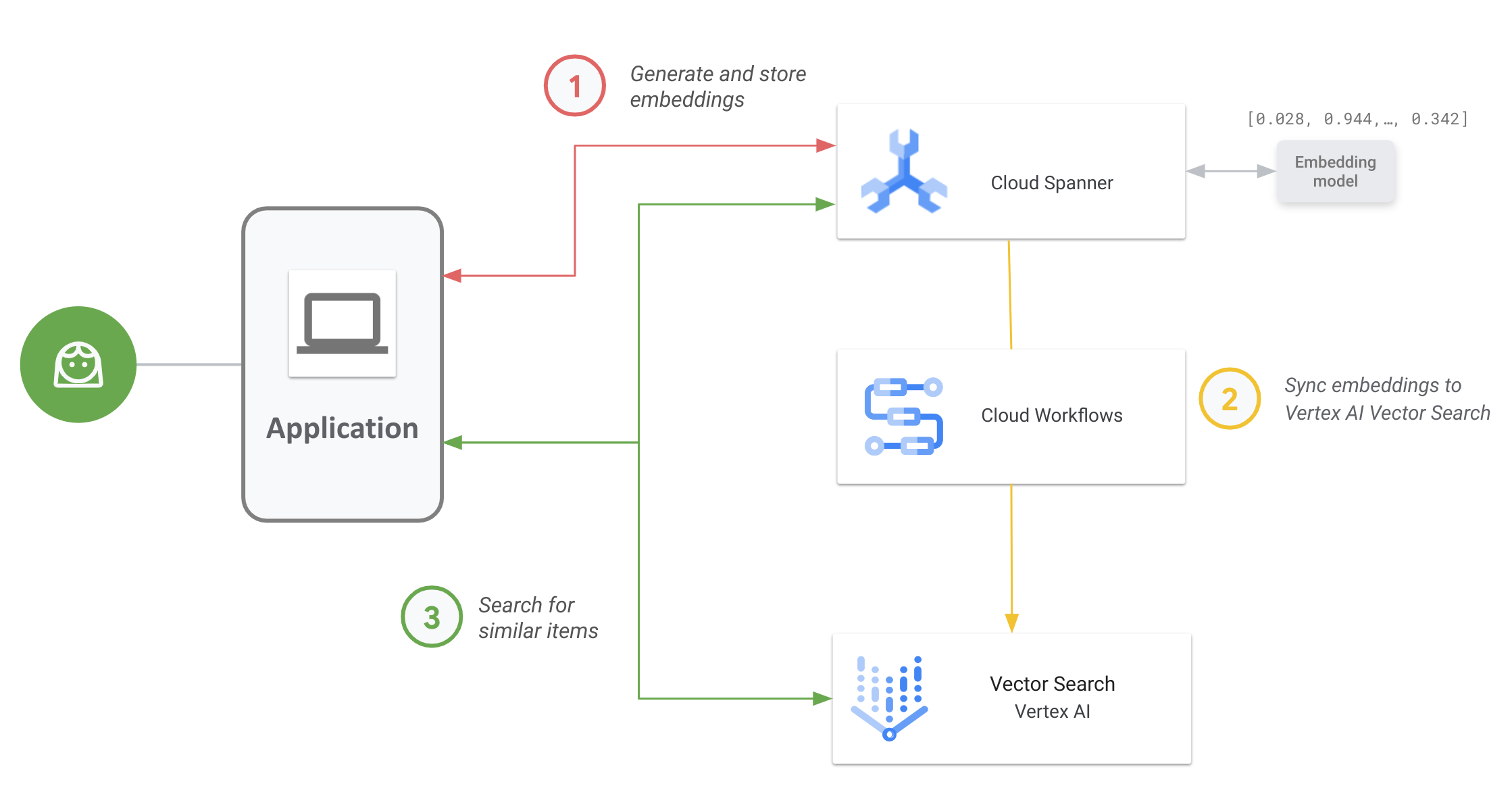
일반적인 워크플로는 다음과 같습니다.
벡터 임베딩을 생성하고 저장합니다.
데이터의 벡터 임베딩을 생성한 후 운영 데이터로 Spanner에 저장하고 관리할 수 있습니다. Spanner의
ML.PREDICTSQL 함수로 임베딩을 생성하여 Vertex AI 텍스트 임베딩 모델에 액세스하거나 Vertex AI에 배포된 다른 임베딩 모델을 사용할 수 있습니다.임베딩을 벡터 검색에 동기화합니다.
Workflows를 통해 배포되는 Spanner To Vertex AI Vector Search 워크플로를 사용하여 임베딩을 내보내고 벡터 검색 색인으로 업로드합니다. Cloud Scheduler를 사용하여 이 워크플로를 주기적으로 예약해 벡터 검색 색인을 Spanner의 임베딩에 대한 최신 변경사항이 포함된 최신 상태로 유지할 수 있습니다.
벡터 검색 색인을 사용하여 벡터 유사성 검색을 수행합니다.
벡터 검색 색인을 쿼리하여 의미상 유사한 항목의 결과를 검색하고 찾습니다. 공개 엔드포인트를 사용하거나 VPC 피어링을 통해 쿼리할 수 있습니다.
사용 사례
벡터 검색 사용 사례 예시는 수십만 개 항목의 인벤토리가 있는 온라인 소매업체입니다. 이 시나리오에서는 온라인 소매업체 개발자는 Spanner에서 제품 카탈로그에 대한 벡터 유사성 검색을 사용하여 고객이 검색어 기반으로 관련 제품을 찾는 데 도움을 주려고 합니다.
일반 워크플로에 제공된 1단계와 2단계를 수행하여 제품 카탈로그의 벡터 임베딩을 생성하고 이러한 임베딩을 벡터 검색에 동기화합니다.
이제 고객이 애플리케이션에서 탐색하는 동안 '물에서 착용할 수 있는 가장 빨리 마르는 스포츠 반바지'와 같은 검색을 수행한다고 가정해 보겠습니다. 애플리케이션에서 이 쿼리를 수신하면 개발자는 Spanner ML.PREDICT SQL 함수를 사용하여 이 검색 요청에 대한 요청 임베딩을 생성해야 합니다. 제품 카탈로그의 임베딩을 생성하는 데 사용된 모델과 동일한 임베딩 모델을 사용해야 합니다.
다음으로 해당 임베딩이 고객의 검색 요청에서 생성된 요청 임베딩과 유사한 제품 ID에 대한 벡터 검색 색인을 쿼리합니다. 검색 색인에서 웨이크보딩 반바지, 서핑 의류, 수영복과 같이 의미상 비슷한 항목의 제품 ID를 추천할 수 있습니다.
벡터 검색에서 유사한 제품 ID를 반환하면 제품 설명, 인벤토리 수, 가격, 관련 기타 메타데이터에 대해 Spanner를 쿼리하여 고객에게 표시할 수 있습니다.
또한 생성형 AI를 사용하여 Spanner에서 반환된 결과를 처리한 후 고객에게 표시할 수도 있습니다. 예를 들어 Google의 대규모 생성형 AI 모델을 사용하여 추천 제품의 간결한 요약을 생성할 수 있습니다. 자세한 내용은 생성형 AI를 사용하여 전자상거래 애플리케이션에서 맞춤형 추천을 가져오는 방법을 설명하는 튜토리얼을 참조하세요.
다음 단계
- Spanner를 사용하여 임베딩을 생성하는 방법을 알아봅니다.
- AI 멀티 도구: 벡터 임베딩에 대해 자세히 알아봅니다.
- 임베딩 단기집중과정에서 머신러닝 및 임베딩에 대해 자세히 알아봅니다.
- Spanner To Vertex AI Vector Search 워크플로를 자세히 알아보려면 GitHub 저장소를 참조하세요.
- Python에서 일반적인 데이터 분석 작업을 용이하게 하고 Jupyter 노트북과의 통합을 포함하는 오픈소스 spanner-analytics 패키지에 대해 자세히 알아봅니다.