Vertex AI Vector Search consente agli utenti di cercare elementi semanticamente simili utilizzando incorporamenti vettoriali. Utilizzando il flusso di lavoro Spanner to Vertex AI Vector Search, puoi integrare il tuo database Spanner con Vector Search per eseguire una ricerca di somiglianza vettoriale nei tuoi dati Spanner.
Il seguente diagramma mostra il flusso di lavoro end-to-end dell'applicazione per l'attivazione e l'utilizzo di Vector Search sui dati Spanner:
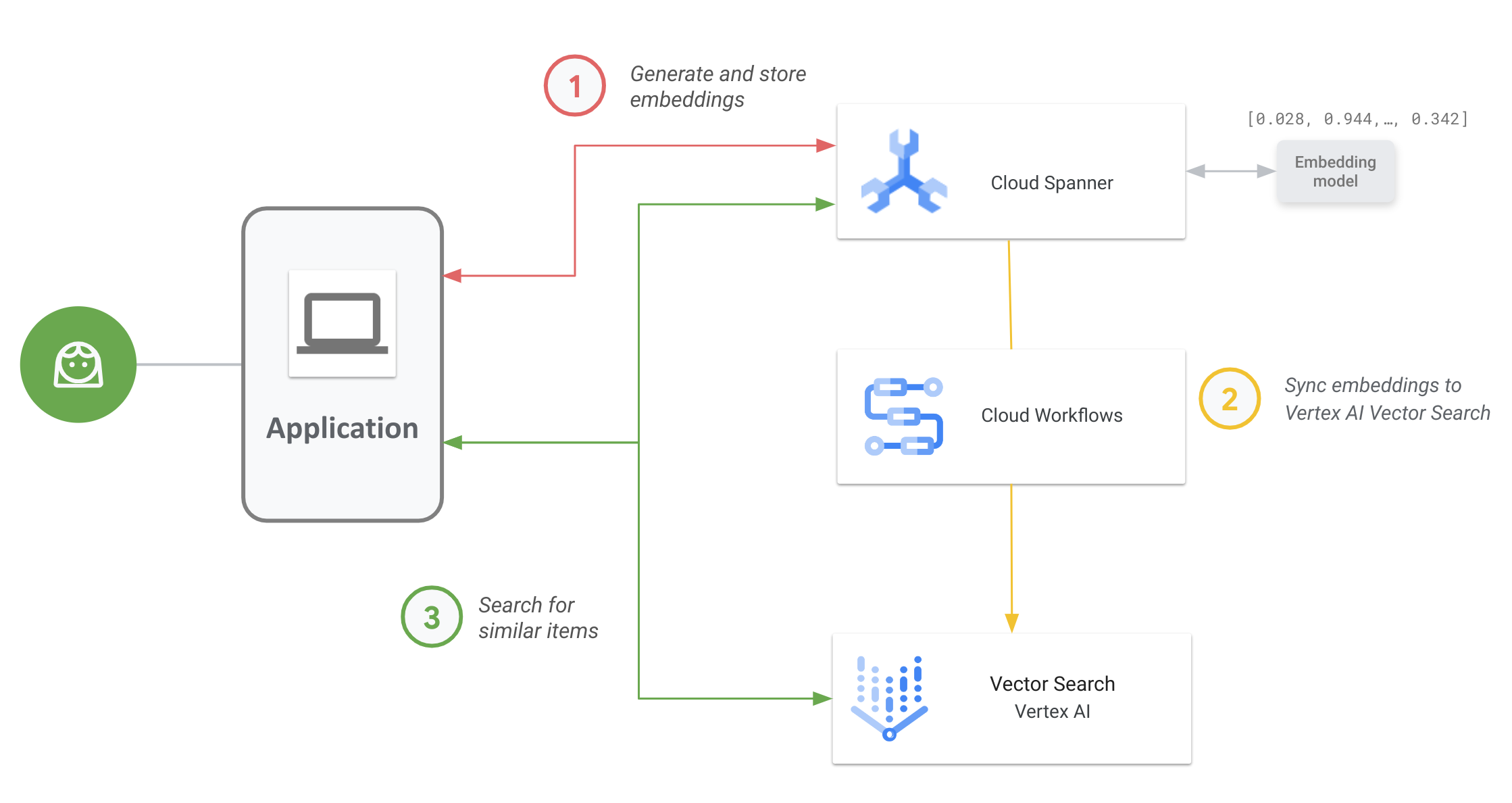
Il workflow generale è il seguente:
Generare e archiviare vector embedding.
Puoi generare incorporamenti vettoriali dei tuoi dati, quindi archiviarli e gestirli in Spanner insieme ai tuoi dati operativi. Puoi generare incorporamenti con la funzione SQL
ML.PREDICTdi Spanner per accedere al modello di text embedding Vertex AI o utilizzare altri modelli di embedding di cui è stato eseguito il deployment su Vertex AI.Sincronizza gli embedding con Vector Search.
Utilizza il flusso di lavoro Spanner to Vertex AI Vector Search, di cui viene eseguito il deployment utilizzando Workflows per esportare e caricare gli incorporamenti in un indice Vector Search. Puoi utilizzare Cloud Scheduler per pianificare periodicamente questo flusso di lavoro in modo da mantenere l'indice Vector Search aggiornato con le ultime modifiche apportate agli incorporamenti in Spanner.
Esegui la ricerca di similarità vettoriale utilizzando l'indice Vector Search.
Esegui query sull'indice Vector Search per cercare e trovare risultati per elementi semanticamente simili. Puoi eseguire query utilizzando un endpoint pubblico o tramite il peering VPC.
Caso d'uso di esempio
Un caso d'uso illustrativo per Vector Search è un rivenditore online che ha un inventario di centinaia di migliaia di articoli. In questo scenario, sei uno sviluppatore per un rivenditore online e vuoi utilizzare la ricerca di similarità vettoriale nel tuo catalogo prodotti in Spanner per aiutare i tuoi clienti a trovare prodotti pertinenti in base alle loro query di ricerca.
Segui i passaggi 1 e 2 presentati nel flusso di lavoro generale per generare incorporamenti vettoriali per il catalogo prodotti e sincronizzarli con la ricerca vettoriale.
Ora immagina che un cliente che naviga nella tua applicazione esegua una ricerca come
"migliori pantaloncini sportivi ad asciugatura rapida che posso indossare in acqua". Quando la tua
applicazione riceve questa query, devi generare un embedding della richiesta per
questa richiesta di ricerca utilizzando la funzione SQL ML.PREDICT di Spanner. Assicurati di utilizzare lo stesso modello di incorporamento utilizzato per generare
gli incorporamenti per il catalogo prodotti.
A questo punto, esegui una query sull'indice di ricerca vettoriale per gli ID prodotto i cui incorporamenti corrispondenti sono simili all'incorporamento della richiesta generato dalla richiesta di ricerca del cliente. L'indice di ricerca potrebbe consigliare ID prodotto per articoli semanticamente simili, come pantaloncini da wakeboard, abbigliamento da surf e costumi da bagno.
Dopo che Vector Search restituisce questi ID prodotto simili, puoi eseguire query Spanner per le descrizioni, il conteggio dell'inventario, il prezzo e altri metadati pertinenti dei prodotti e mostrarli al tuo cliente.
Puoi anche utilizzare l'AI generativa per elaborare i risultati restituiti da Spanner prima di mostrarli al tuo cliente. Ad esempio, potresti utilizzare i modelli di AI generativa di grandi dimensioni di Google per generare un riepilogo conciso dei prodotti consigliati. Per saperne di più, consulta questo tutorial su come utilizzare l'AI generativa per ricevere consigli personalizzati in un'applicazione di e-commerce.
Passaggi successivi
- Scopri come generare embedding utilizzando Spanner.
- Scopri di più su Lo strumento multifunzione dell'AI: gli incorporamenti vettoriali
- Scopri di più sul machine learning e sugli incorporamenti nel nostro corso intensivo sugli incorporamenti.
- Scopri di più sul flusso di lavoro Spanner to Vertex AI Vector Search, consulta il repository GitHub.
- Scopri di più sul pacchetto spanner-analytics open source che facilita le operazioni comuni di analisi dei dati in Python e include integrazioni con Jupyter Notebooks.