Nesta página, descrevemos como usar a recuperação pontual (PITR, na sigla em inglês) para reter e recuperar dados no Spanner para bancos de dados com dialeto GoogleSQL e PostgreSQL.
Para saber mais, consulte Recuperação pontual.
Pré-requisitos
Este guia usa o banco de dados e o esquema definidos no guia de início rápido do Spanner. Você pode executar o guia de início rápido para criar o banco de dados e o esquema ou modificar os comandos para uso com seu próprio banco de dados.
Defina o período de armazenamento
Para definir o período de armazenamento do banco de dados:
Console
Acesse a página "Instâncias do Spanner" no Google Cloud console.
Clique na instância que contém o banco de dados para abrir a página Visão geral correspondente.
Clique no banco de dados para abrir a página Visão geral correspondente.
Selecione a guia Backup/Restaurar.
Clique no ícone de lápis no campo Período de armazenamento da versão.
Digite uma quantidade e uma unidade de tempo para o período de armazenamento e clique em Atualizar.
gcloud
Atualize o esquema do banco de dados com a instrução ALTER DATABASE. Exemplo:
gcloud spanner databases ddl update example-db \
--instance=test-instance \
--ddl='ALTER DATABASE `example-db` \
SET OPTIONS (version_retention_period="7d");'Para visualizar o período de armazenamento, localize a DDL do seu banco de dados:
gcloud spanner databases ddl describe example-db \
--instance=test-instanceEsta é a saída:
ALTER DATABASE example-db SET OPTIONS (
version_retention_period = '7d'
);
...
Bibliotecas de cliente
C#
C++
Go
Java
Node.js
PHP
Python
Ruby
Observações sobre o uso:
- O período de armazenamento precisa ser de 1 hora a 7 dias e pode ser especificado
em dias, horas, minutos ou segundos. Por exemplo, os valores
1d,24h,1440me86400ssão equivalentes. - Se você tiver ativado a geração de registros para a API Spanner no seu projeto, o evento será registrado como UpdateDatabaseDdl e ficará visível no Explorador de registros.
- Para reverter para o período de armazenamento padrão de 1 hora, defina a opção de banco de dados
version_retention_periodcomoNULLpara bancos de dados do GoogleSQL ouDEFAULTpara bancos de dados do PostgreSQL. - Quando você estende o período de armazenamento, o sistema não preenche versões anteriores de dados. Por exemplo, se você estender o período de armazenamento de uma hora para 24 horas, será preciso aguardar 23 horas para que o sistema acumule dados antigos antes de recuperar dados das 24 horas anteriores.
Conseguir o período de armazenamento e o horário da versão mais antiga
O recurso Banco de dados inclui dois campos:
version_retention_period: o período em que o Spanner retém todas as versões de dados para o banco de dados.earliest_version_time: o carimbo de data/hora mais antigo em que as versões anteriores dos dados podem ser lidas no banco de dados. Esse valor é atualizado continuamente pelo Spanner e fica desatualizado quando é consultado. Se você estiver usando esse valor para recuperar dados, não deixe de considerar o momento entre o momento em que o valor é consultado e o momento em que você inicia a recuperação.
Console
Acesse a página "Instâncias do Spanner" no console Google Cloud .
Clique na instância que contém o banco de dados para abrir a página Visão geral correspondente.
Clique no banco de dados para abrir a página Visão geral correspondente.
Selecione a guia Backup/Restaurar para abrir a página Backup/Restaurar e exibir o período de armazenamento.
Clique em Criar para abrir a página Criar um backup e exibir o horário da versão mais antiga.

gcloud
Para receber esses campos, chame descrever bancos de dados ou listar bancos de dados. Por exemplo:
gcloud spanner databases describe example-db \
--instance=test-instanceEsta é a saída:
createTime: '2020-09-07T16:56:08.285140Z'
earliestVersionTime: '2020-10-07T16:56:08.285140Z'
name: projects/my-project/instances/test-instance/databases/example-db
state: READY
versionRetentionPeriod: 3d
Recuperar uma parte do banco de dados
Execute uma leitura desatualizada e especifique o carimbo de data/hora de recuperação necessário. Verifique se o carimbo de data/hora especificado é mais recente que o
earliest_version_time.do banco de dados.gcloud
Use execute-sql Por exemplo:
gcloud spanner databases execute-sql example-db \ --instance=test-instance --read-timestamp=2020-09-11T10:19:36.010459-07:00\ --sql='SELECT * FROM SINGERS'Bibliotecas de cliente
Consulte Executar leitura desatualizada.
Armazenar os resultados da consulta. Isso é necessário porque não é possível gravar os resultados da consulta no banco de dados na mesma transação. Para pequenas quantidades de dados, você pode imprimir no console ou armazenar na memória. Para quantidades maiores, talvez seja necessário gravar em um arquivo local.
Grave os dados recuperados de volta na tabela que precisa ser recuperada. Exemplo:
gcloud
gcloud spanner rows update --instance=test-instance --database=example-db --table=Singers \ --data=SingerId=1,FirstName='Marc'Para mais informações, consulte Como atualizar dados usando o gcloud.
Bibliotecas de cliente
Para mais informações, consulte Como atualizar dados usando DML ou Como atualizar dados com mutações.
Se quiser fazer uma análise dos dados recuperados antes de gravar novamente, crie manualmente uma tabela temporária no mesmo banco de dados, grave os dados recuperados nessa tabela temporária primeiro, faça a análise e leia os dados que você quer recuperar dessa tabela temporária e grave na tabela que precisa ser recuperada.
Recuperar um banco de dados inteiro
É possível recuperar todo o banco de dados usando as opções Backup e restauração ou Importar e exportar e especificando um carimbo de data/hora de recuperação.
Backup e restauração
Crie um backup e defina o
version_timepara o carimbo de data/hora de recuperação necessário.Console
Acesse a página Detalhes do banco de dados no console do Cloud.
Na guia Backup/Restaurar, clique em Criar.
Marque a caixa Criar backup de um momento mais antigo.
gcloud
gcloud spanner backups create example-db-backup-1 \ --instance=test-instance \ --database=example-db \ --retention-period=1y \ --version-time=2021-01-22T01:10:35Z --asyncPara mais informações, consulte Criar um backup usando o gcloud.
Bibliotecas de cliente
C#
C++
Go
Java
Node.js
PHP
Python
Ruby
Restaurar do backup para um novo banco de dados. O Spanner preserva a configuração do período de armazenamento do backup para o banco de dados restaurado.
Console
Acesse a página Detalhes da instância no Console do Cloud.
Na guia Backup/Restaurar, selecione um backup e clique em Restaurar.
gcloud
gcloud spanner databases restore --async \ --destination-instance=destination-instance --destination-database=example-db-restored \ --source-instance=test-instance --source-backup=example-db-backup-1Para mais informações, consulte Como restaurar um banco de dados de um backup.
Bibliotecas de cliente
C#
C++
Go
Java
Node.js
PHP
Python
Ruby
Importar e exportar
- Exporte o banco de dados, especificando o parâmetro
snapshotTimepara o carimbo de data/hora de recuperação necessário.Console
Acesse a página Detalhes da instância no Console do Cloud.
Na guia Importar/Exportar, clique em Exportar.
Marque a caixa Exportar banco de dados de um momento mais antigo.
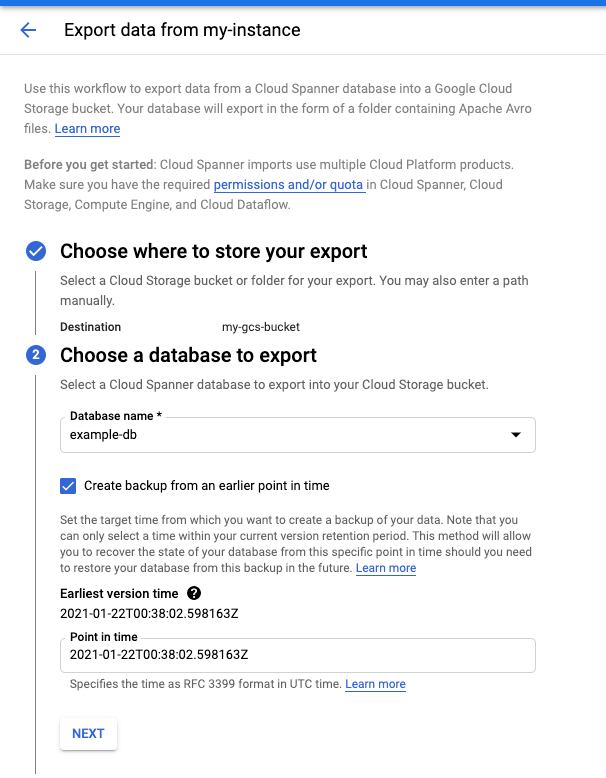
Para instruções detalhadas, consulte exportar um banco de dados.
gcloud
Use o modelo do Dataflow Spanner para Avro para exportar o banco de dados.
gcloud dataflow jobs run JOB_NAME \ --gcs-location='gs://cloud-spanner-point-in-time-recovery/Import Export Template/export/templates/Cloud_Spanner_to_GCS_Avro' --region=DATAFLOW_REGION \ --parameters='instanceId=test-instance,databaseId=example-db,outputDir=YOUR_GCS_DIRECTORY,snapshotTime=2020-09-01T23:59:40.125245Z'Observações sobre o uso:
- É possível acompanhar o andamento dos jobs de importação e exportação no console do Dataflow.
- O Spanner garante que os dados exportados terão consistência transacional e externa no carimbo de data/hora especificado.
- Especifique o carimbo de data/hora no formato RFC 3339. Por exemplo, 2020-09-01T23:59:30.234233Z.
- Verifique se o carimbo de data/hora especificado é mais recente que o
earliest_version_timedo banco de dados. Se os dados não existirem mais no carimbo de data/hora especificado, você vai receber um erro.
Importar para um novo banco de dados.
Console
Acesse a página Detalhes da instância no Console do Cloud.
Na guia Importar/Exportar, clique em Importar.
Para instruções detalhadas, consulte Como importar arquivos Avro do Spanner.
gcloud
Use o modelo do Cloud Dataflow Cloud Storage Avro para Spanner para importar os arquivos Avro.
gcloud dataflow jobs run JOB_NAME \ --gcs-location='gs://cloud-spanner-point-in-time-recovery/Import Export Template/import/templates/GCS_Avro_to_Cloud_Spanner' \ --region=DATAFLOW_REGION \ --staging-location=YOUR_GCS_STAGING_LOCATION \ --parameters='instanceId=test-instance,databaseId=example-db,inputDir=YOUR_GCS_DIRECTORY'
Estimar o aumento do armazenamento
Antes de aumentar o período de armazenamento da versão de um banco de dados, calcule o aumento esperado no uso do armazenamento do banco de dados totalizando os bytes da transação pelo período necessário. Por exemplo, a consulta a seguir calcula o número de GiB gravado nos últimos sete dias (168h) lendo as tabelas de estatísticas de transações.
GoogleSQL
SELECT
SUM(bytes_per_hour) / (1024 * 1024 * 1024 ) as GiB
FROM (
SELECT
((commit_attempt_count - commit_failed_precondition_count - commit_abort_count) * avg_bytes)
AS bytes_per_hour, interval_end
FROM
spanner_sys.txn_stats_total_hour
ORDER BY
interval_end DESC
LIMIT
168);
PostgreSQL
SELECT
bph / (1024 * 1024 * 1024 ) as GiB
FROM (
SELECT
SUM(bytes_per_hour) as bph
FROM (
SELECT
((commit_attempt_count - commit_failed_precondition_count - commit_abort_count) * avg_bytes)
AS bytes_per_hour, interval_end
FROM
spanner_sys.txn_stats_total_hour
ORDER BY
interval_end DESC
LIMIT
168)
sub1) sub2;
Observe que a consulta fornece uma estimativa aproximada e pode ser imprecisa por alguns motivos:
- A consulta não considera o carimbo de data/hora que precisa ser armazenado para cada versão dos dados antigos. Se o banco de dados consistir em muitos pequenos tipos de dados, a consulta poderá subestimar o aumento do armazenamento.
- A consulta inclui todas as operações de gravação, mas apenas operações de atualização criam versões anteriores de dados. Se a carga de trabalho incluir muitas operações de inserção, a consulta poderá superestimar o aumento do armazenamento.