이 페이지에서는 point-in-time recovery(PITR)를 사용하여 GoogleSQL 언어 데이터베이스 및 PostgreSQL 언어 데이터베이스의 Spanner에서 데이터를 보관하고 복구하는 방법을 설명합니다.
자세한 내용은 point-in-time recovery를 참조하세요.
기본 요건
이 가이드에서는 Spanner 빠른 시작에 정의된 데이터베이스와 스키마를 사용합니다. 빠른 시작을 통해 실행하여 데이터베이스와 스키마를 만들거나 자체 데이터베이스에 사용할 명령어를 수정할 수 있습니다.
보관 기간 설정
데이터베이스의 보관 기간을 설정하려면 다음 안내를 따르세요.
콘솔
Google Cloud 콘솔에서 Spanner 인스턴스 페이지로 이동합니다.
데이터베이스가 포함된 인스턴스를 클릭하여 개요 페이지를 엽니다.
데이터베이스를 클릭하여 개요 페이지를 엽니다.
백업/복원 탭을 선택합니다.
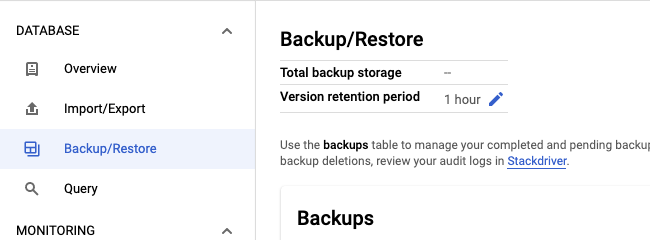
버전 보관 기간 필드에서 연필 아이콘을 클릭합니다.
보관 기간의 수량 및 시간 단위를 입력한 후 업데이트를 클릭합니다.
gcloud
ALTER DATABASE 문으로 데이터베이스의 스키마를 업데이트합니다. 예를 들면 다음과 같습니다.
gcloud spanner databases ddl update example-db \
--instance=test-instance \
--ddl='ALTER DATABASE `example-db` \
SET OPTIONS (version_retention_period="7d");'보관 기간을 확인하려면 데이터베이스의 DDL을 가져옵니다.
gcloud spanner databases ddl describe example-db \
--instance=test-instance출력은 다음과 같습니다.
ALTER DATABASE example-db SET OPTIONS (
version_retention_period = '7d'
);
...
클라이언트 라이브러리
C#
C++
Go
자바
Node.js
PHP
Python
Ruby
사용 참고사항:
- 보관 기간은 1시간에서 7일 사이여야 하며 일, 시간, 분, 초 단위로 지정할 수 있습니다. 예를 들어
1d,24h,1440m,86400s값은 동일합니다. - 프로젝트에서 Spanner API에 로깅을 사용 설정한 경우 해당 이벤트가 UpdateDatabaseDdl로 기록되고 로그 탐색기에 표시됩니다.
- 기본 보관 기간인 1시간으로 되돌리려면
version_retention_period데이터베이스 옵션을 GoogleSQL 데이터베이스는NULL로, PostgreSQL 데이터베이스는DEFAULT로 설정합니다. - 보관 기간을 연장하면 시스템에서는 이전 버전의 데이터를 백필하지 않습니다. 예를 들어 보관 기간을 1시간에서 24시간으로 연장할 경우 시스템에서 이전 데이터를 누적하기까지 23시간 동안 기다려야 이전 24시간부터 데이터를 복구할 수 있습니다.
보관 기간 및 가장 초기 버전 시간 가져오기
데이터베이스 리소스에는 두 필드가 포함됩니다.
version_retention_period: Spanner가 데이터베이스에 대한 모든 버전의 데이터를 보관하는 기간입니다.earliest_version_time: 데이터베이스에서 이전 버전의 데이터를 읽을 수 있는 가장 초기 타임스탬프입니다. 이 값은 Spanner에 의해 지속적으로 업데이트되고 쿼리될 때 비활성 상태가 됩니다. 이 값을 사용하여 데이터를 복구하는 경우, 값이 쿼리된 순간부터 복구를 시작하는 순간까지의 기간을 고려해야 합니다.
콘솔
Google Cloud 콘솔에서 Spanner 인스턴스 페이지로 이동합니다.
데이터베이스가 포함된 인스턴스를 클릭하여 개요 페이지를 엽니다.
데이터베이스를 클릭하여 개요 페이지를 엽니다.
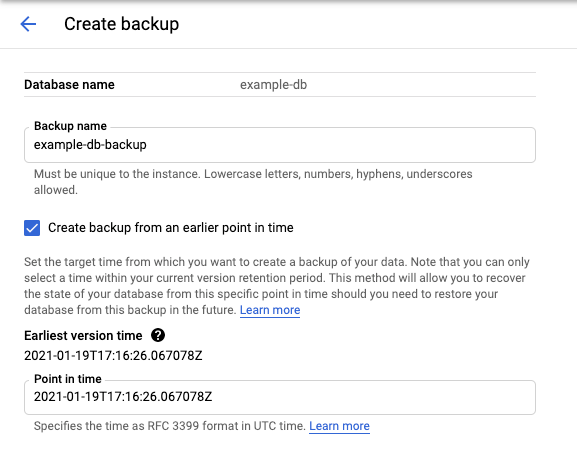
백업/복원 탭을 선택하여 백업/복원 페이지를 열고 보관 기간을 표시합니다.
만들기를 클릭하여 백업 만들기 페이지를 열고 가장 초기 버전 시간을 표시합니다.
gcloud
이러한 필드는 데이터베이스 설명 또는 데이터베이스 나열을 호출하여 가져올 수 있습니다. 예를 들면 다음과 같습니다.
gcloud spanner databases describe example-db \
--instance=test-instance출력은 다음과 같습니다.
createTime: '2020-09-07T16:56:08.285140Z'
earliestVersionTime: '2020-10-07T16:56:08.285140Z'
name: projects/my-project/instances/test-instance/databases/example-db
state: READY
versionRetentionPeriod: 3d
데이터베이스 일부 복구
비활성 읽기를 수행하고 원하는 복구 타임스탬프를 지정합니다. 지정한 타임스탬프가 데이터베이스의
earliest_version_time.보다 최신인지 확인합니다.gcloud
execute-sql을 사용합니다. 예를 들면 다음과 같습니다.
gcloud spanner databases execute-sql example-db \ --instance=test-instance --read-timestamp=2020-09-11T10:19:36.010459-07:00\ --sql='SELECT * FROM SINGERS'클라이언트 라이브러리
비활성 읽기 수행을 참조하세요.
쿼리 결과를 저장합니다. 쿼리 결과를 동일한 트랜잭션의 데이터베이스에 다시 쓸 수 없으므로 이는 필수 항목입니다. 소량의 데이터의 경우 콘솔로 인쇄하거나 메모리에 저장할 수 있습니다. 대용량 데이터의 경우 로컬 파일에 써야 할 수 있습니다.
복구된 데이터를 복구해야 하는 테이블에 다시 씁니다. 예를 들면 다음과 같습니다.
gcloud
gcloud spanner rows update --instance=test-instance --database=example-db --table=Singers \ --data=SingerId=1,FirstName='Marc'자세한 내용은 gcloud를 사용하여 데이터 업데이트를 참조하세요.
클라이언트 라이브러리
자세한 내용은 DML을 사용하여 데이터 업데이트 또는 변형을 사용하여 데이터 업데이트를 참고하세요.
필요한 경우 다시 쓰기 전에 복구된 데이터에서 분석을 수행하려면 동일한 데이터베이스에서 임시 테이블을 수동으로 만들고 복구된 데이터를 먼저 이 임시 테이블에 기록한 후 이 임시 테이블에서 복구하려는 데이터를 읽고 복구해야 하는 테이블에 기록하면 됩니다.
전체 데이터베이스 복구
백업 및 복원 또는 가져오기 및 내보내기를 사용하고 복구 타임스탬프를 지정하여 전체 데이터베이스를 복구할 수 있습니다.
백업 및 복원
백업을 만들고
version_time을 원하는 복구 타임스탬프로 설정합니다.콘솔
Cloud 콘솔에서 데이터베이스 세부정보 페이지로 이동합니다.
백업/복원 탭에서 만들기를 클릭합니다.
이전 시점의 백업 만들기 체크박스를 선택합니다.
gcloud
gcloud spanner backups create example-db-backup-1 \ --instance=test-instance \ --database=example-db \ --retention-period=1y \ --version-time=2021-01-22T01:10:35Z --async자세한 내용은 gcloud를 사용하여 백업 만들기를 참조하세요.
클라이언트 라이브러리
C#
C++
Go
자바
Node.js
PHP
Python
Ruby
백업에서 새 데이터베이스로 복원합니다. Spanner는 백업에서 복원된 데이터베이스로 보관 기간 설정을 그대로 유지합니다.
콘솔
Cloud 콘솔에서 인스턴스 세부정보 페이지로 이동합니다.
백업/복원 탭에서 백업을 선택하고 복원을 클릭합니다.
gcloud
gcloud spanner databases restore --async \ --destination-instance=destination-instance --destination-database=example-db-restored \ --source-instance=test-instance --source-backup=example-db-backup-1자세한 내용은 백업에서 데이터베이스 복원을 참조하세요.
클라이언트 라이브러리
C#
C++
Go
자바
Node.js
PHP
Python
Ruby
가져오기 및 내보내기
snapshotTime파라미터를 원하는 복구 타임스탬프로 지정하여 데이터베이스를 내보냅니다.콘솔
Cloud 콘솔에서 인스턴스 세부정보 페이지로 이동합니다.
가져오기/내보내기 탭에서 내보내기를 클릭합니다.
이전 시점의 데이터베이스 내보내기 체크박스를 선택합니다.
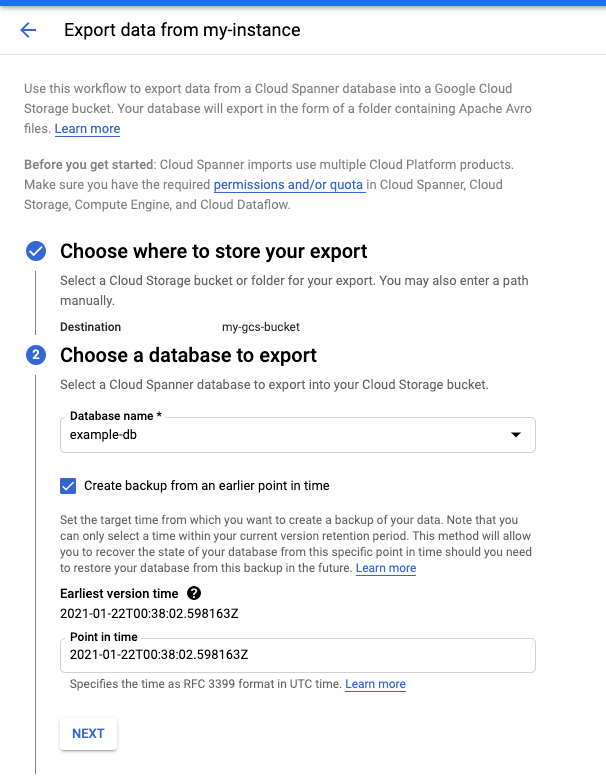
자세한 안내는 데이터베이스 내보내기를 참조하세요.
gcloud
Spanner to Avro Dataflow 템플릿을 사용하여 데이터베이스를 내보냅니다.
gcloud dataflow jobs run JOB_NAME \ --gcs-location='gs://cloud-spanner-point-in-time-recovery/Import Export Template/export/templates/Cloud_Spanner_to_GCS_Avro' --region=DATAFLOW_REGION \ --parameters='instanceId=test-instance,databaseId=example-db,outputDir=YOUR_GCS_DIRECTORY,snapshotTime=2020-09-01T23:59:40.125245Z'사용 참고사항:
- Dataflow 콘솔에서 가져오기 및 내보내기 작업의 진행 상황을 추적할 수 있습니다.
- Spanner는 내보낸 데이터가 지정된 타임스탬프에서 외적 일관성 및 트랜잭션 일관성을 갖도록 보장합니다.
- RFC 3339 형식으로 타임스탬프를 지정합니다. 예를 들면 2020-09-01T23:59:30.234233Z입니다.
- 지정한 타임스탬프가 데이터베이스의
earliest_version_time보다 최신인지 확인합니다. 지정된 타임스탬프에 데이터가 더 이상 존재하지 않으면 오류가 발생합니다.
새 데이터베이스로 가져옵니다.
콘솔
Cloud 콘솔에서 인스턴스 세부정보 페이지로 이동합니다.
가져오기/내보내기 탭에서 가져오기를 클릭합니다.
자세한 안내는 Spanner Avro 파일 가져오기를 참조하세요.
gcloud
Cloud Storage Avro to Spanner Dataflow 템플릿을 사용하여 Avro 파일을 가져옵니다.
gcloud dataflow jobs run JOB_NAME \ --gcs-location='gs://cloud-spanner-point-in-time-recovery/Import Export Template/import/templates/GCS_Avro_to_Cloud_Spanner' \ --region=DATAFLOW_REGION \ --staging-location=YOUR_GCS_STAGING_LOCATION \ --parameters='instanceId=test-instance,databaseId=example-db,inputDir=YOUR_GCS_DIRECTORY'
스토리지 증가 추정
데이터베이스의 버전 보관 기간을 늘리기 전에 원하는 기간의 트랜잭션 바이트를 합하여 예상되는 데이터베이스 스토리지 사용량 증가를 예측할 수 있습니다. 예를 들어 다음 쿼리는 트랜잭션 통계 테이블에서 읽어 지난 7일간(168시간) 기록된 GiB의 수를 계산합니다.
GoogleSQL
SELECT
SUM(bytes_per_hour) / (1024 * 1024 * 1024 ) as GiB
FROM (
SELECT
((commit_attempt_count - commit_failed_precondition_count - commit_abort_count) * avg_bytes)
AS bytes_per_hour, interval_end
FROM
spanner_sys.txn_stats_total_hour
ORDER BY
interval_end DESC
LIMIT
168);
PostgreSQL
SELECT
bph / (1024 * 1024 * 1024 ) as GiB
FROM (
SELECT
SUM(bytes_per_hour) as bph
FROM (
SELECT
((commit_attempt_count - commit_failed_precondition_count - commit_abort_count) * avg_bytes)
AS bytes_per_hour, interval_end
FROM
spanner_sys.txn_stats_total_hour
ORDER BY
interval_end DESC
LIMIT
168)
sub1) sub2;
이러한 쿼리는 대략적인 추정치를 제공하며 몇 가지 이유로 부정확할 수 있습니다.
- 쿼리에는 이전 데이터의 각 버전에 대해 저장해야 하는 타임스탬프가 반영되지 않습니다. 데이터베이스가 다수의 작은 데이터 유형으로 구성되어 있는 경우 쿼리가 스토리지 증가를 과소평가할 수 있습니다.
- 쿼리는 모든 쓰기 작업을 포함하지만 업데이트 작업만 데이터의 이전 버전을 만듭니다. 워크로드에 삽입 작업이 많이 포함되어 있으면 쿼리가 스토리지 증가를 과대평가할 수 있습니다.