쿼리 계획 시각화 도구를 사용하면 Spanner에서 쿼리를 평가하기 위해 선택한 쿼리 계획의 구조를 빠르게 파악할 수 있습니다. 이 가이드에서는 쿼리 계획을 사용하여 쿼리 실행을 이해하는 방법을 설명합니다.
시작하기 전에
이 가이드에서 언급된 Google Cloud 콘솔 사용자 인터페이스 부분을 이해하려면 다음을 참조하세요.
Google Cloud 콘솔에서 쿼리 실행
- Google Cloud 콘솔에서 Spanner 인스턴스 페이지로 이동합니다.
-
쿼리할 데이터베이스가 포함된 인스턴스의 이름을 선택합니다.
Google Cloud 콘솔에 인스턴스의 개요 페이지가 표시됩니다.
-
쿼리할 데이터베이스의 이름을 선택합니다.
Google Cloud 콘솔에 데이터베이스의 개요 페이지가 표시됩니다.
-
사이드 메뉴에서 Spanner Studio를 클릭합니다.
Google Cloud 콘솔에 데이터베이스의 Spanner Studio 페이지가 표시됩니다.
- 편집기 창에 SQL 쿼리를 입력합니다.
-
실행을 클릭합니다.
Spanner가 쿼리를 실행합니다.
- 설명 탭을 클릭하여 쿼리 계획 시각화를 확인합니다.
쿼리 편집기 둘러보기
Spanner Studio 페이지에서는 SQL 쿼리 및 DML 문을 입력하거나 붙여넣고 데이터베이스에 대해 실행하고 결과와 쿼리 실행 계획을 볼 수 있도록 하는 쿼리 탭을 제공합니다. 다음 스크린샷에서는 Spanner Studio 페이지의 주요 구성요소에 번호가 매겨집니다.
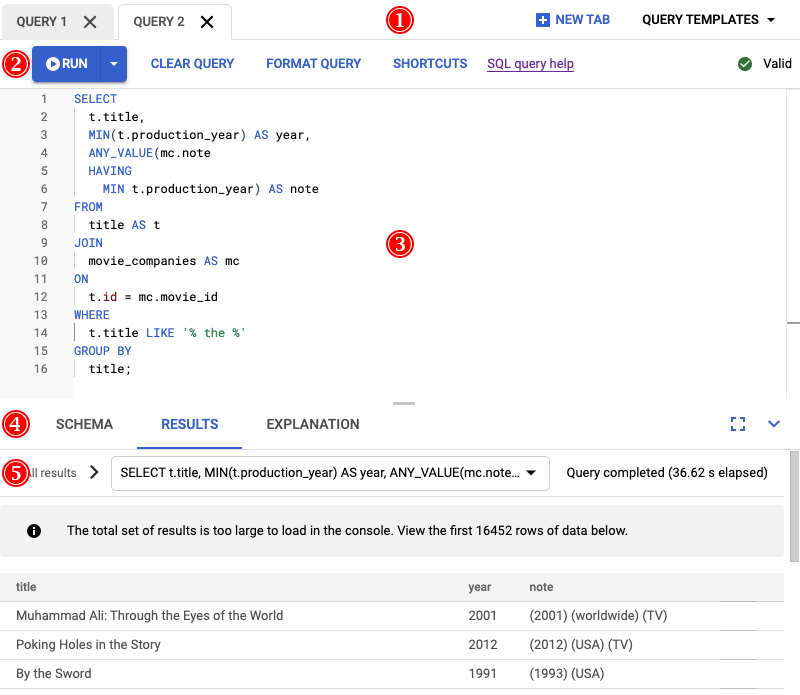
- 탭 표시줄에는 열어 둔 쿼리 탭이 표시됩니다. 새 탭을 만들려면 새 탭을 클릭합니다.
또한 이 탭 표시줄에는 점검 도구 개요에 명시된 대로 데이터베이스 쿼리, 트랜잭션, 읽기 등에 대한 통계를 제공하는 쿼리를 붙여넣는 데 사용할 수 있는 쿼리 템플릿 목록을 제공합니다.
- 편집기 명령어 표시줄은 다음 옵션을 제공합니다.
- 실행 명령어는 수정 창에 입력된 문을 실행하여 결과 탭에 쿼리 결과를, 설명 탭에 쿼리 실행 계획을 생성합니다. 드롭다운을 사용해 기본 동작을 변경하여 결과만 또는 설명만을 생성합니다.
편집기에서 강조표시하면 실행 명령어가 선택한 부분 실행으로 변경되어 개발자가 선택한 항목을 실행할 수 있습니다.
- 쿼리 삭제 명령어는 편집기에서 모든 텍스트를 삭제하고 결과 및 설명 하위 탭을 삭제합니다.
- 쿼리 형식 지정 명령어는 쉽게 읽을 수 있도록 편집기에서 문의 형식을 지정합니다.
- 단축키 명령어는 편집기에서 사용할 수 있는 키보드 단축키를 표시합니다.
- SQL 쿼리 도움말 링크를 클릭하면 SQL 쿼리 구문에 대한 문서가 포함된 브라우저 탭이 열립니다.
쿼리는 편집기에서 업데이트될 때마다 자동으로 검증됩니다. 문이 유효하면 편집기 명령어 표시줄에 확인 체크표시와 Valid 메시지가 표시됩니다. 문제가 발생하면 세부정보가 포함된 오류 메시지가 표시됩니다.
- 실행 명령어는 수정 창에 입력된 문을 실행하여 결과 탭에 쿼리 결과를, 설명 탭에 쿼리 실행 계획을 생성합니다. 드롭다운을 사용해 기본 동작을 변경하여 결과만 또는 설명만을 생성합니다.
- 편집기는 SQL 쿼리와 DML 문을 입력하는 곳입니다.
이는 색상으로 구분되고 여러 행으로 된 문에는 행 번호가 자동으로 추가됩니다.
편집기에 문을 두 개 이상 입력하는 경우 마지막 문을 제외한 각 문 다음에 종료 세미콜론을 사용해야 합니다.
- 쿼리 탭의 하단 창에는 3가지 하위 탭이 제공됩니다.
- 스키마 하위 탭에는 데이터베이스의 테이블과 스키마가 표시됩니다. 편집기에서 문을 작성할 때 이를 빠른 참조로 사용하세요.
- 결과 하위 탭에는 편집기에서 문을 실행할 때 결과가 표시됩니다. 쿼리의 경우 결과 테이블을 표시하고
INSERT및 >UPDATE와 같은 DML 문의 경우 영향을 받은 행 수에 대한 메시지를 표시합니다. - 설명 하위 탭에는 편집기에서 문을 실행할 때 생성된 쿼리 계획의 시각적 그래프가 표시됩니다.
- 결과 및 설명 하위 탭 모두 사용할 문 결과 또는 보고자 하는 쿼리 계획을 선택하는 데 사용하는 문 선택기를 제공합니다.
샘플링된 쿼리 계획 보기
- Google Cloud 콘솔에서 Spanner 인스턴스 페이지로 이동합니다.
-
조사하려는 쿼리가 있는 인스턴스의 이름을 클릭합니다.
Google Cloud 콘솔에 인스턴스의 개요 페이지가 표시됩니다.
-
탐색 메뉴의 모니터링 가능성 제목 아래에서 쿼리 통계를 클릭합니다.
Google Cloud 콘솔에 인스턴스의 쿼리 통계 페이지가 표시됩니다.
-
데이터베이스 드롭다운 메뉴에서 조사하려는 쿼리가 있는 데이터베이스를 선택합니다.
Google Cloud 콘솔에 데이터베이스의 쿼리 부하 정보가 표시됩니다. TopN 쿼리 및 태그 테이블에 CPU 사용률을 기준으로 정렬된 상위 쿼리 및 요청 태그의 목록이 표시됩니다.
-
샘플링된 쿼리 계획을 보려는 CPU 사용률이 높은 쿼리를 찾습니다. 해당 쿼리의 FPRINT 값을 클릭합니다.
쿼리 세부정보 페이지에 시간 경과에 따른 쿼리의 쿼리 계획 샘플 그래프가 표시됩니다. 현재 시간부터 최대 7일까지 축소하여 볼 수 있습니다. 참고: 쿼리 계획은 PartitionQuery API 및 파티션을 나눈 DML 쿼리에서 가져온 partitionTokens가 있는 쿼리에 지원되지 않습니다.
-
이전 쿼리 계획을 보고 쿼리 실행 중에 수행된 단계를 시각화하려면 그래프의 점 중 하나를 클릭합니다. 또한 연산자를 클릭하여 연산자에 대한 확장된 정보를 확인할 수 있습니다.
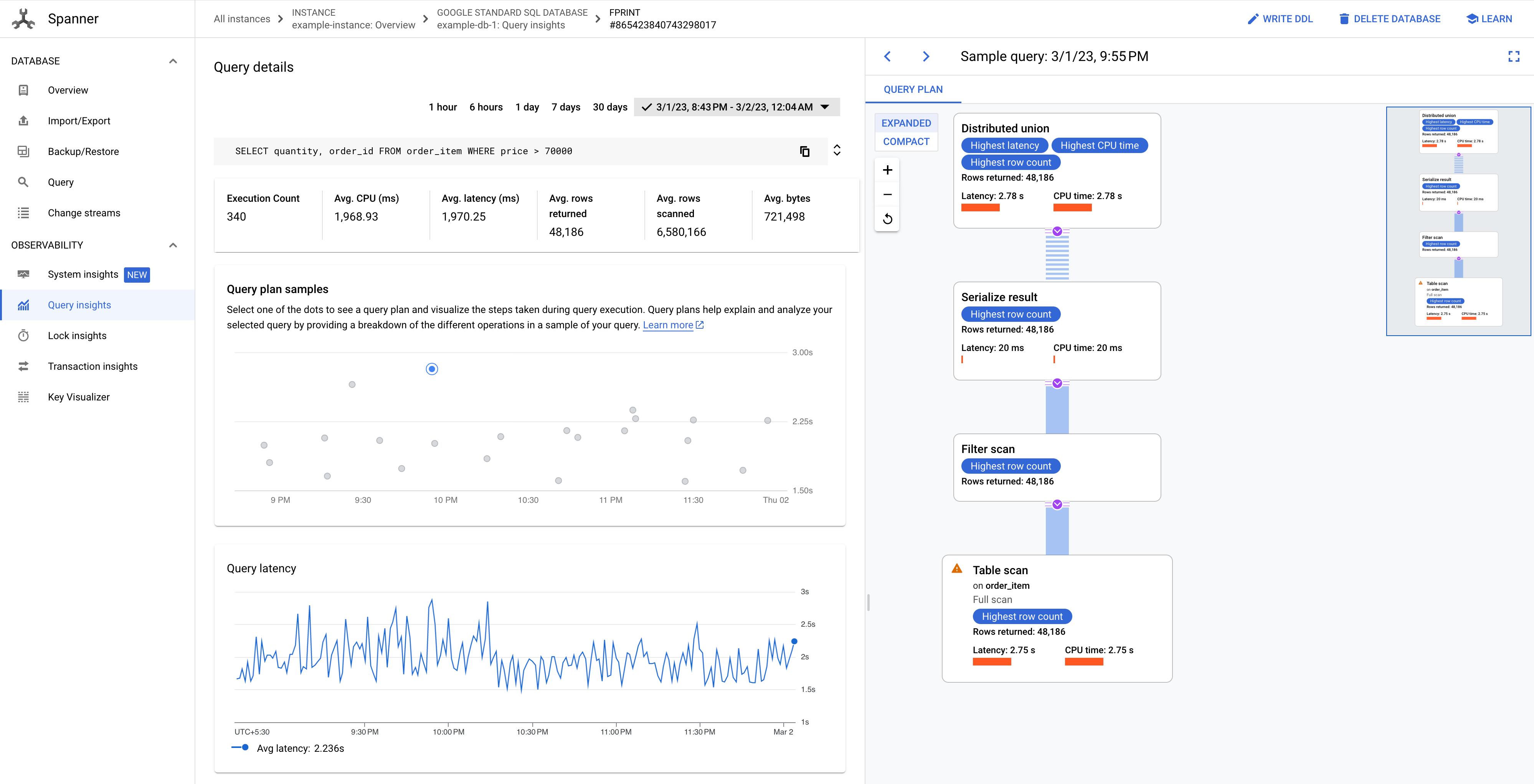
그림 8. 쿼리 계획 샘플 그래프
경우에 따라 샘플링된 쿼리 계획을 보고 시간 경과에 따른 쿼리 성능을 비교해야 할 수 있습니다. CPU를 더 많이 사용하는 쿼리의 경우 Spanner는 Google Cloud 콘솔의 쿼리 통계 페이지에 샘플링된 쿼리 계획을 30일 동안 보관합니다. 샘플링된 쿼리 계획을 보려면 다음 안내를 따르세요.
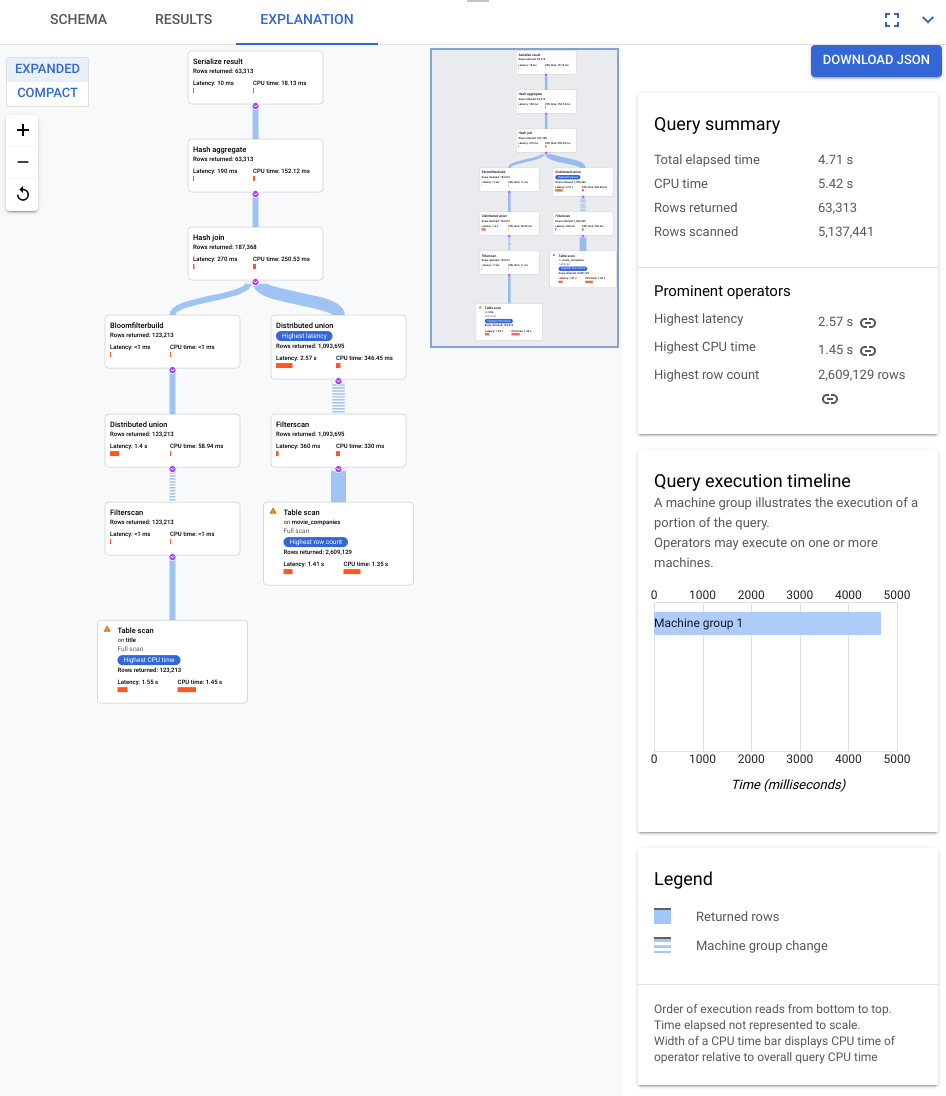
쿼리 계획 시각화 도구 둘러보기
시각화 도구의 주요 구성요소는 다음 스크린샷에 주석이 추가되어 있고 더 자세히 설명되어 있습니다. 쿼리 탭에서 쿼리를 실행한 후 쿼리 편집기 아래의 설명 탭을 선택하여 쿼리 실행 계획 시각화 도구를 엽니다.
다음 다이어그램의 데이터 흐름은 상향식으로 작동합니다. 즉, 모든 테이블과 색인이 다이어그램의 맨 아래에 있으며 최종 출력은 상단에 표시됩니다.
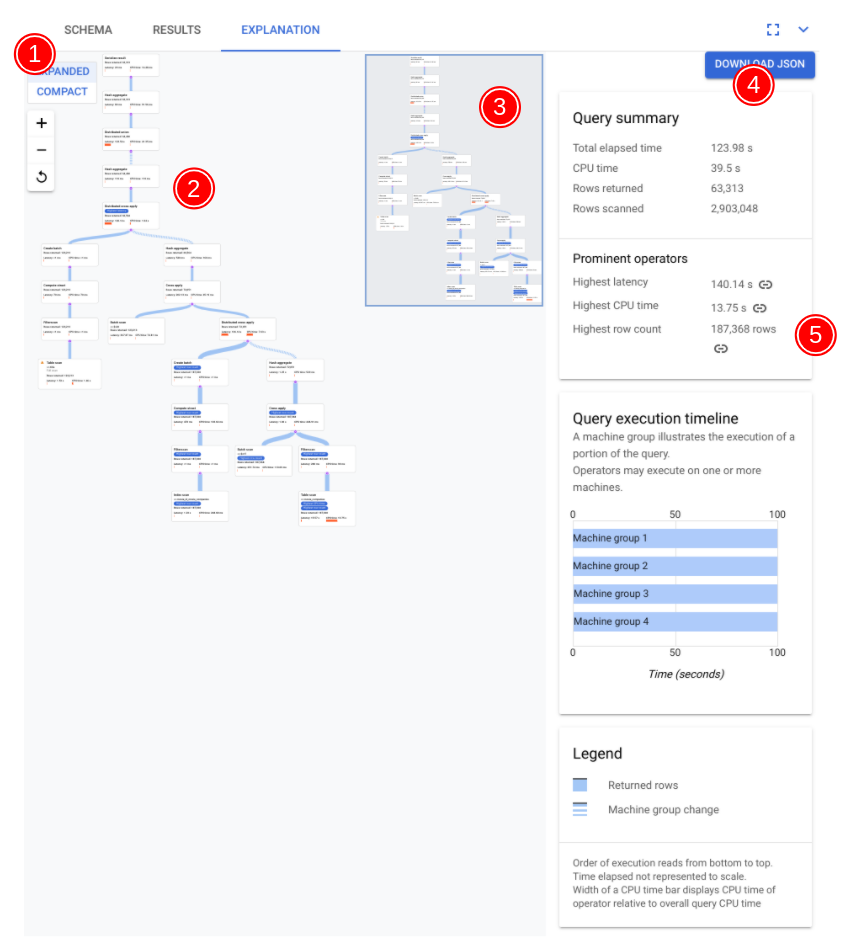
- 실행한 쿼리에 따라 계획의 시각화가 커질 수 있습니다. 세부정보를 숨기거나 표시하려면 확장된 뷰/간단한 뷰 선택기를 전환합니다. 확대/축소 컨트롤을 사용하여 언제든지 표시할 계획을 맞춤설정할 수 있습니다.
- Spanner가 쿼리를 실행하는 방법을 설명하는 대수는 비순환 그래프로 표현됩니다. 여기서 각 노드는 입력에서 행을 사용하고 상위 행을 생성하는 반복자에 해당합니다. 그림 9는 계획 샘플을 보여줍니다. 다이어그램을 클릭하여 계획 세부정보 일부에 대한 확장된 뷰를 확인합니다.
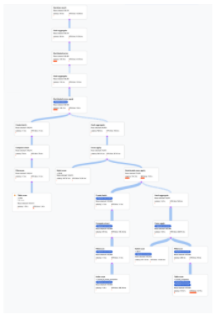
그림 9. 시각적 계획 샘플(확대하려면 클릭) 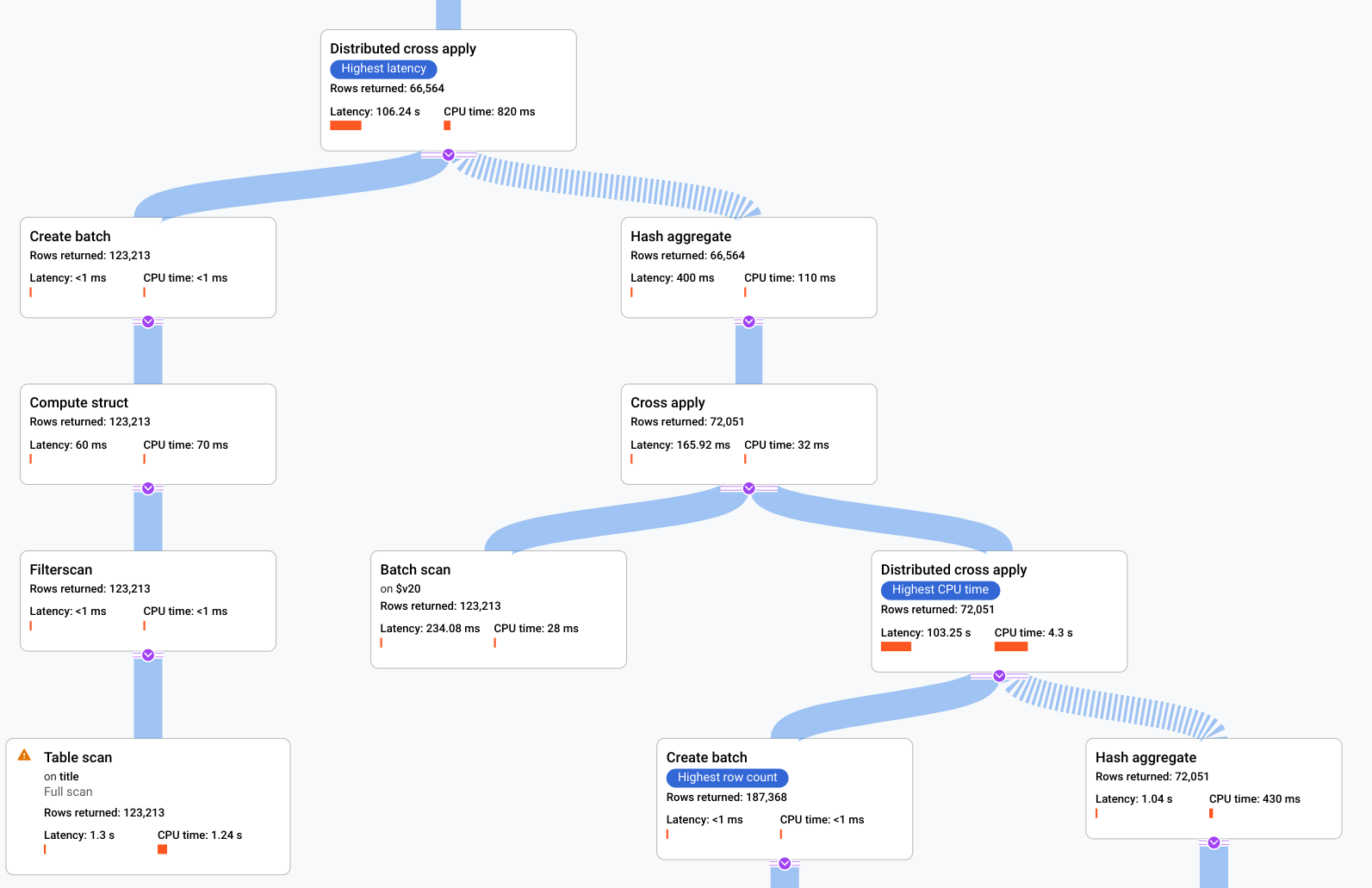
그래프의 각 노드 또는 카드는 반복자를 나타내며 다음 정보가 포함됩니다.
- 반복자 이름입니다. 반복자는 입력의 행을 사용하고 행을 생성합니다.
- 반환된 행 수, 지연 시간, CPU 소비량을 나타내는 런타임 통계입니다.
- 쿼리 실행 계획 내에서 잠재적인 문제를 식별할 수 있도록 다음과 같은 시각적 큐를 제공합니다.
- 노드의 빨간색 막대는 쿼리의 합계와 비교하여 이 반복자에 대한 지연 시간 또는 CPU 시간의 백분율을 시각적으로 표시합니다.
- 각 노드를 연결하는 선의 두께는 행 수를 나타냅니다. 선이 두꺼울수록 다음 노드에 전달되는 행 수가 늘어납니다. 각 카드 및 커넥터 위로 포인터를 가져가면 실제 행 수가 표시됩니다.
- 전체 테이블 스캔이 수행된 노드에 경고 삼각형이 표시됩니다. 정보 패널의 추가 세부정보에는 색인 추가 또는 가능한 경우 전체 검사를 방지하기 위해 다른 방식으로 쿼리 또는 스키마 수정 등 권장사항이 포함됩니다.
- 계획에서 카드를 선택하여 오른쪽 정보 패널에 세부정보를 표시합니다(5).
- 실행 계획 미니 맵은 전체 계획을 축소하여 보여주며 실행 계획의 전반적인 형태를 파악하고 계획의 다른 부분으로 빠르게 이동하는 데 유용합니다. 시각적 맵의 다른 부분으로 이동하려면 미니 맵에서 직접 드래그하거나 초점을 둘 위치를 클릭합니다.
JSON 다운로드를 선택하여 실행 계획의 JSON 버전을 다운로드합니다. 이는 문제 해결에 유용합니다. 지원을 위해 Spanner팀에 문의할 때도 공유할 수 있습니다. JSON을 저장해도 쿼리 결과는 저장되지 않습니다.
나중에 시각화할 수 있도록 실행 계획의 JSON 버전을 다운로드하고 저장하려면 다음 단계를 따르세요.
- Spanner Studio에서 쿼리를 실행합니다.
- 설명 탭을 선택합니다.
- JSON 다운로드를 클릭하여 실행 계획의 JSON 버전을 다운로드합니다.
- JSON 파일의 콘텐츠를 저장하고 복사합니다.
- 새 쿼리 편집기 탭을 엽니다.
- 편집기 탭에 다음을 입력합니다.
PROTO: CONTENT_OF_JSON
- 실행을 클릭합니다.
- 쿼리 편집기 아래의 설명 탭을 선택하여 다운로드한 실행 계획의 시각적 표현을 확인합니다.
- 정보 패널에는 쿼리 계획 다이어그램에서 선택된 노드에 대한 자세한 컨텍스트 정보가 표시됩니다. 정보는 다음 카테고리로 구성됩니다.
- 반복자 정보는 그래프에서 선택한 반복자 카드의 세부정보와 함께 런타임 통계를 제공합니다.
- 쿼리 요약은 반환된 행 수와 쿼리 실행에 걸린 시간에 대한 세부정보를 제공합니다. 중요한 연산자는 상당한 지연 시간을 보이고, 다른 연산자와 비교하여 상당한 CPU를 사용하며, 많은 수의 데이터 행을 반환합니다.
- 쿼리 실행 타임라인은 각 머신 그룹이 쿼리의 일부를 얼마나 오래 실행했는지를 나타내는 시간 기반 그래프입니다. 머신 그룹이 전체 쿼리 실행 시간 동안 실행되지 않을 수도 있습니다. 또한 쿼리를 실행하는 동안 머신 그룹이 여러 번 실행되었지만, 타임라인은 처음 실행된 시작 시간과 마지막 실행된 종료 시간만 나타냅니다.
성능 저하를 보이는 쿼리 미세 조정
한 회사에서 캐스팅, 프로덕션 기업, 영화 세부정보 등 영화에 대한 정보가 포함된 온라인 영화 데이터베이스를 실행한다고 가정해 보겠습니다. 서비스가 Spanner에서 실행되지만 최근 성능 문제가 발생했습니다.
서비스의 수석 개발자는 이러한 성능 문제로 인해 서비스 등급이 낮아지므로 이러한 성능 문제를 조사하도록 요청을 받게 됩니다. Google Cloud 콘솔을 열고 데이터베이스 인스턴스로 이동한 다음 쿼리 편집기를 엽니다. 편집기에 다음 쿼리를 입력하고 실행합니다.
SELECT
t.title,
MIN(t.production_year) AS year,
ANY_VALUE(mc.note HAVING MIN t.production_year) AS note
FROM
title AS t
JOIN
movie_companies AS mc
ON
t.id = mc.movie_id
WHERE
t.title LIKE '% the %'
GROUP BY
title;
이 쿼리를 실행한 결과는 다음 스크린샷에 표시됩니다. 쿼리 형식 지정을 선택하여 편집기에서 쿼리 형식을 지정합니다. 또한 화면 오른쪽 상단에 쿼리가 유효하다는 메시지가 표시됩니다.
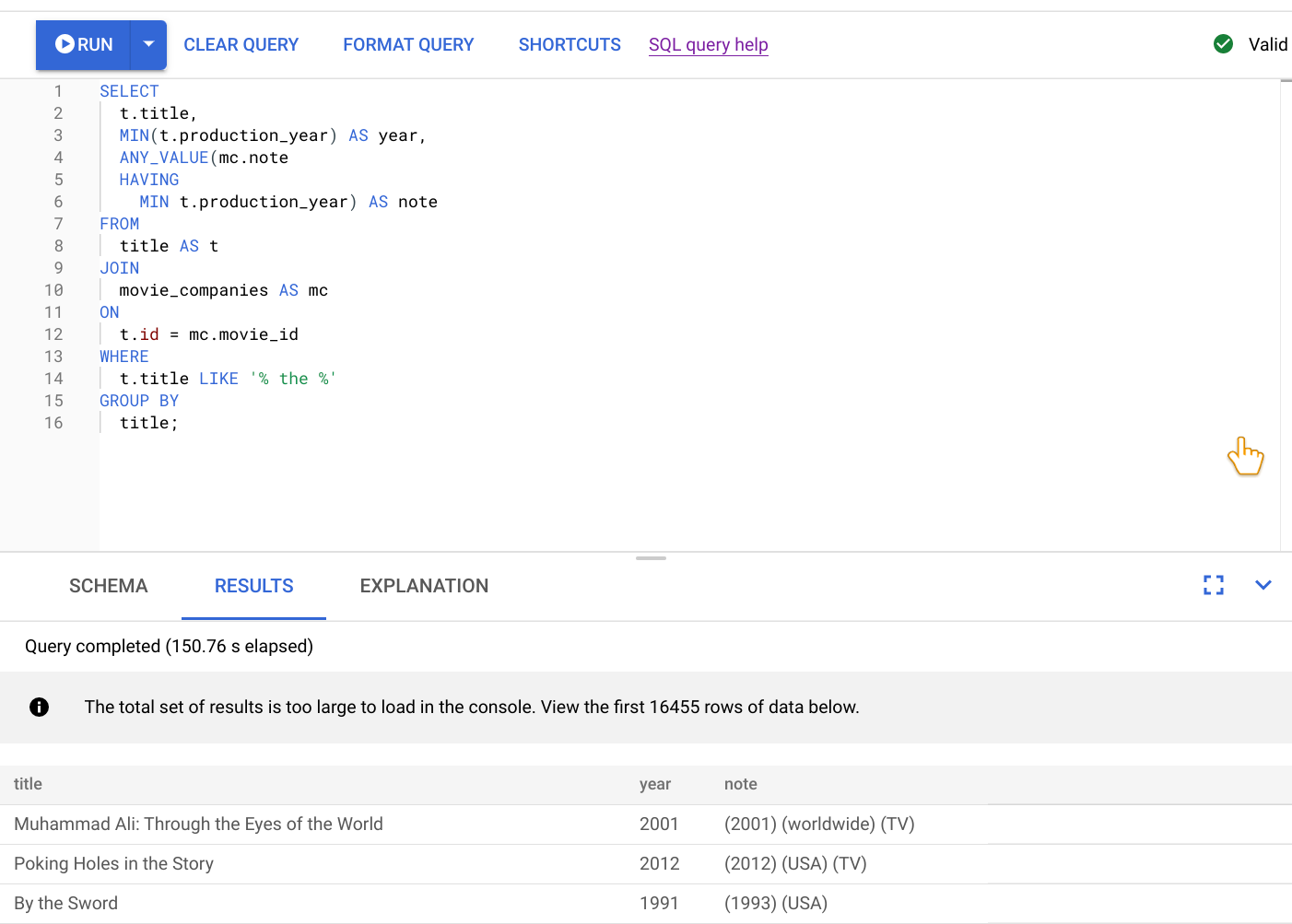
쿼리 편집기 아래의 결과 탭에는 쿼리가 2분 이상 완료되었음을 보여줍니다. 쿼리를 면밀히 검토하여 쿼리가 효율적인지 확인합니다.
쿼리 계획 시각화 도구를 사용하여 느린 쿼리 분석
이 시점에서 이전 단계의 쿼리가 2분 이상 걸린다는 점을 알고 있지만 쿼리가 최대한 효율적인지, 따라서 이 기간이 예상되는지 여부를 알 수 없습니다.
쿼리 편집기 바로 아래의 설명 탭을 선택하여 Spanner가 쿼리를 실행하고 결과를 반환하기 위해 만든 실행 계획의 시각적 표현을 확인합니다.
다음 스크린샷에 표시된 계획은 비교적 크지만 이 확대/축소 수준에서도 다음 사항을 관찰할 수 있습니다.
오른쪽 정보 패널에 있는 쿼리 요약을 보면 약 3백만 개의 행이 스캔되었으며 64K 미만은 반환되었음을 알 수 있습니다.
쿼리 실행 타임라인 패널에서도 4개의 머신 그룹이 쿼리에 포함되었음을 알 수 있습니다. 머신 그룹은 쿼리 중 일부의 실행을 담당합니다. 1개 이상의 머신에서 연산자가 실행될 수 있습니다. 타임라인에서 머신 그룹을 선택하면 해당 그룹에서 실행된 쿼리의 시각적 계획이 강조표시됩니다.
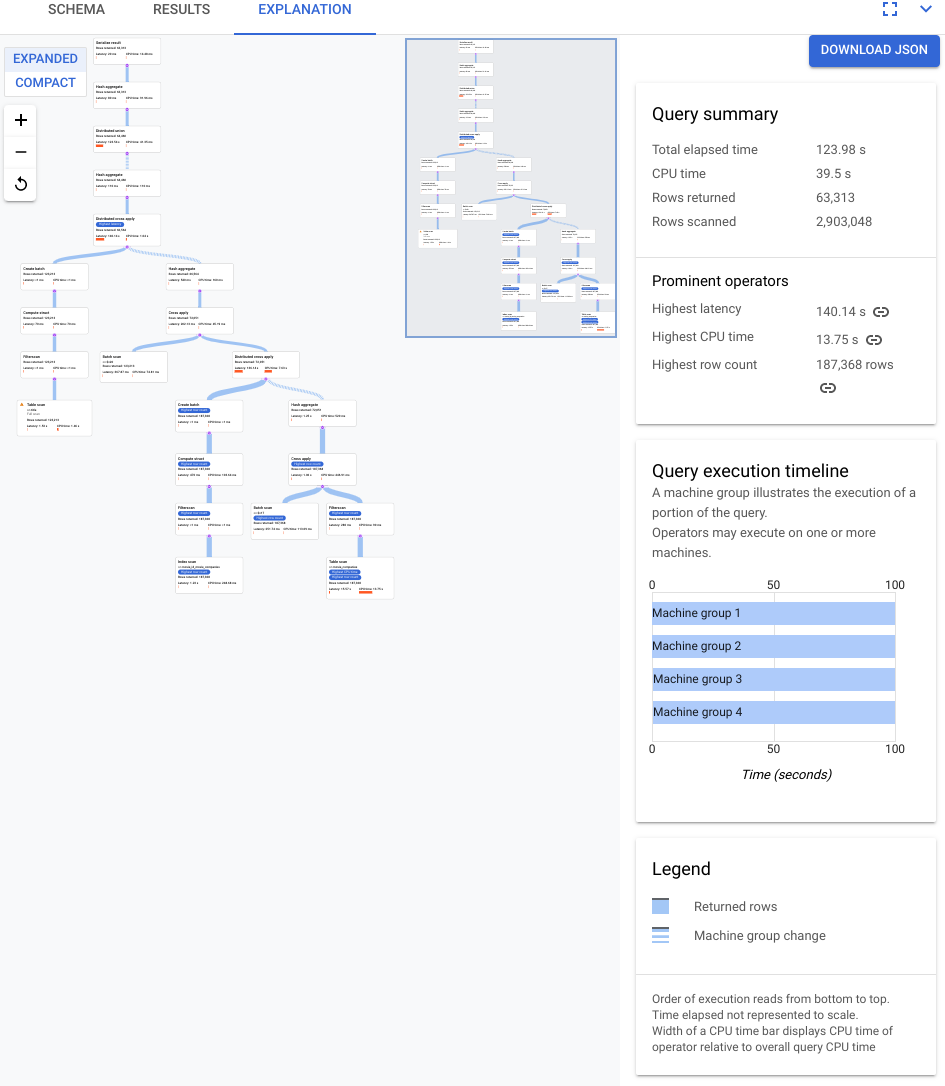
이러한 요인으로 인해 Spanner에서 기본적으로 선택되어 적용되는 적용 조인에서 조인을 해시 조인으로 변경하면 성능이 개선될 수 있습니다.
쿼리 개선
쿼리 성능을 개선하려면 조인 힌트를 사용하여 조인 방법을 해시 조인으로 변경합니다. 이 조인 구현은 설정 기반 처리를 실행합니다.
업데이트된 쿼리는 다음과 같습니다.
SELECT
t.title,
MIN(t.production_year) AS year,
ANY_VALUE(mc.note HAVING MIN t.production_year) AS note
FROM
title AS t
JOIN
@{join_method=hash_join} movie_companies AS mc
ON
t.id = mc.movie_id
WHERE
t.title LIKE '% the %'
GROUP BY
title;
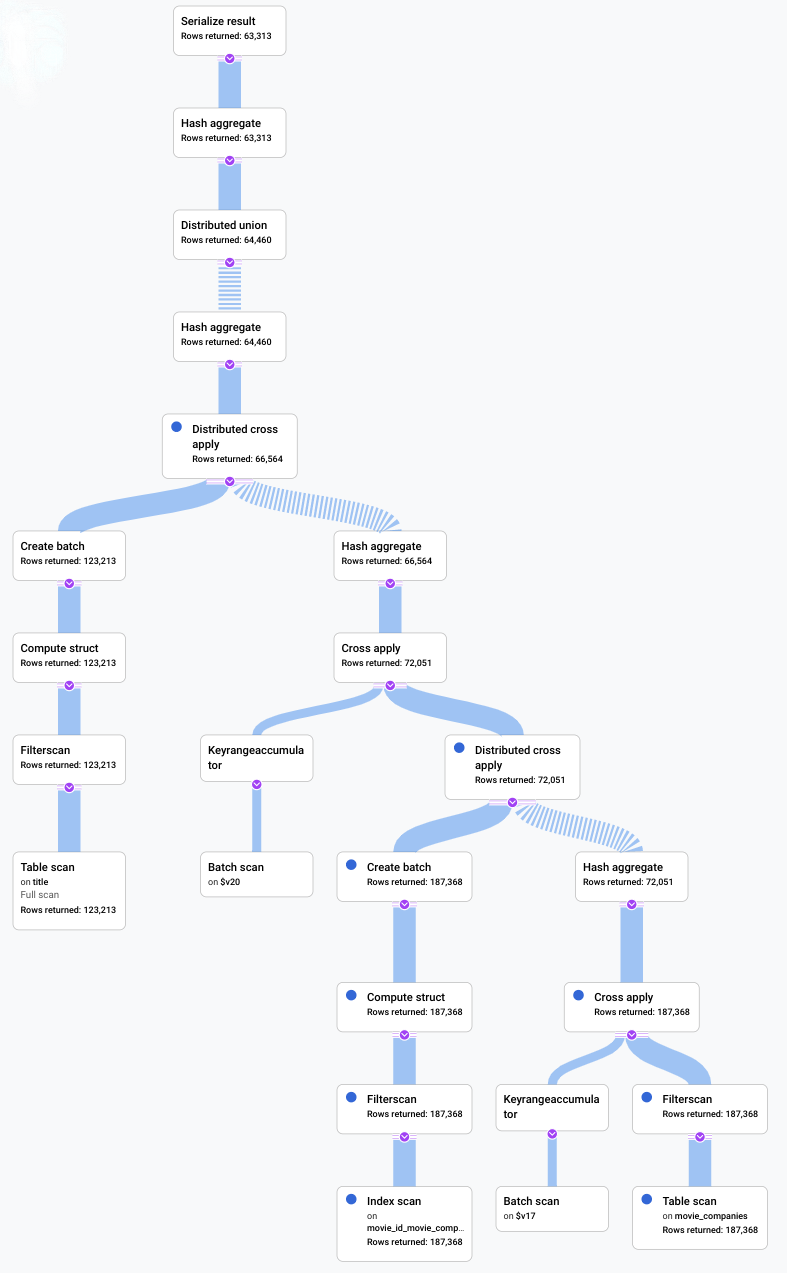
다음 스크린샷은 업데이트된 쿼리를 보여줍니다. 스크린샷에 나와 있듯이 쿼리가 5초 이내에 완료되었으며, 이러한 변경사항을 적용하기에 앞서 120초 런타임 동안 대폭 개선되었습니다.
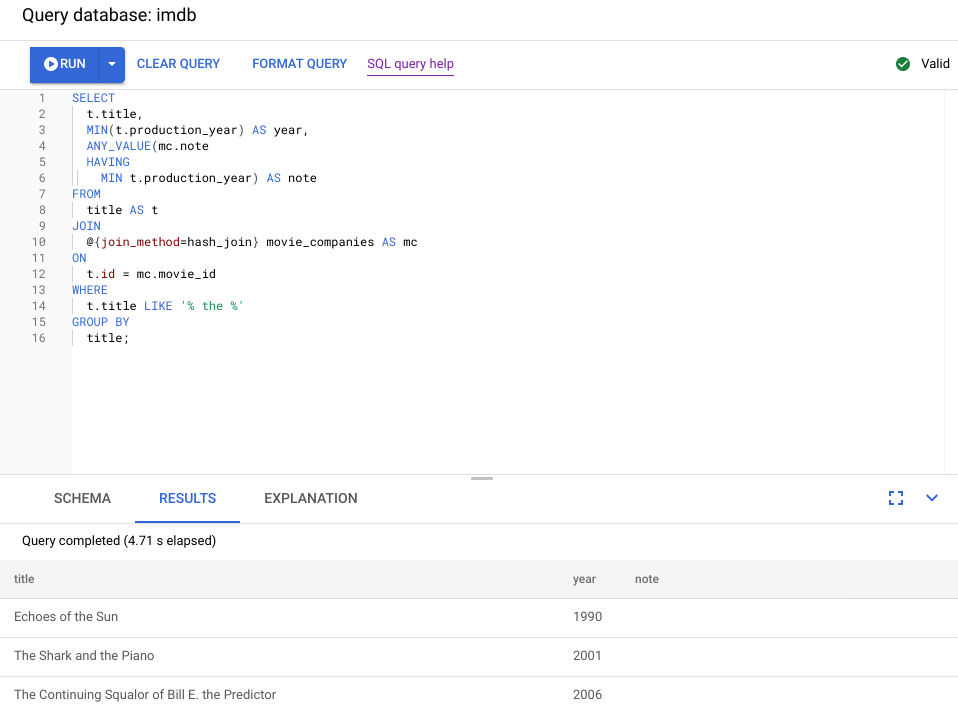
다음 다이어그램에 표시된 새 시각적 계획을 살펴보고 이러한 개선의 내용을 살펴봅니다.
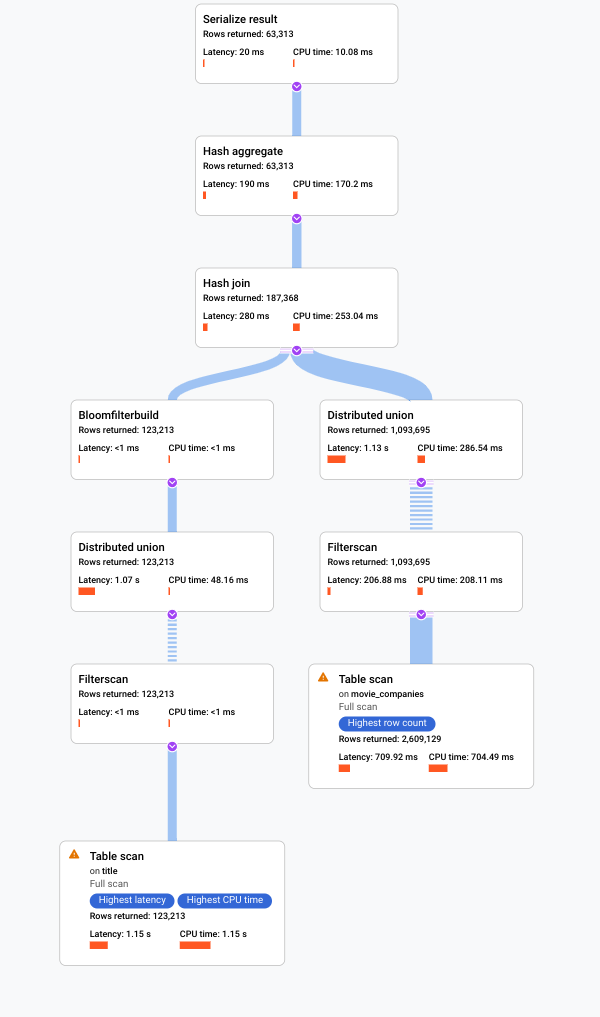
즉시 다음과 같은 차이를 알 수 있습니다.
이 쿼리 실행에는 한 머신 그룹만 포함되었습니다.
집계 수가 대폭 감소했습니다.
결론
이 시나리오에서는 느린 쿼리를 실행하고 비효율성을 찾기 위해 시각적 계획을 조사했습니다. 다음은 변경 전후의 쿼리 및 계획에 대한 요약입니다. 각 탭에는 실행된 쿼리와 전체 쿼리 실행 계획 시각화의 간단한 뷰가 표시됩니다.
이전
SELECT
t.title,
MIN(t.production_year) AS year,
ANY_VALUE(mc.note
HAVING
MIN t.production_year) AS note
FROM
title AS t
JOIN
movie_companies AS mc
ON
t.id = mc.movie_id
WHERE
t.title LIKE '% the %'
GROUP BY
title;
이후
SELECT
t.title,
MIN(t.production_year) AS year,
ANY_VALUE(mc.note
HAVING
MIN t.production_year) AS note
FROM
title AS t
JOIN
@{join_method=hash_join} movie_companies AS mc
ON
t.id = mc.movie_id
WHERE
t.title LIKE '% the %'
GROUP BY
title;
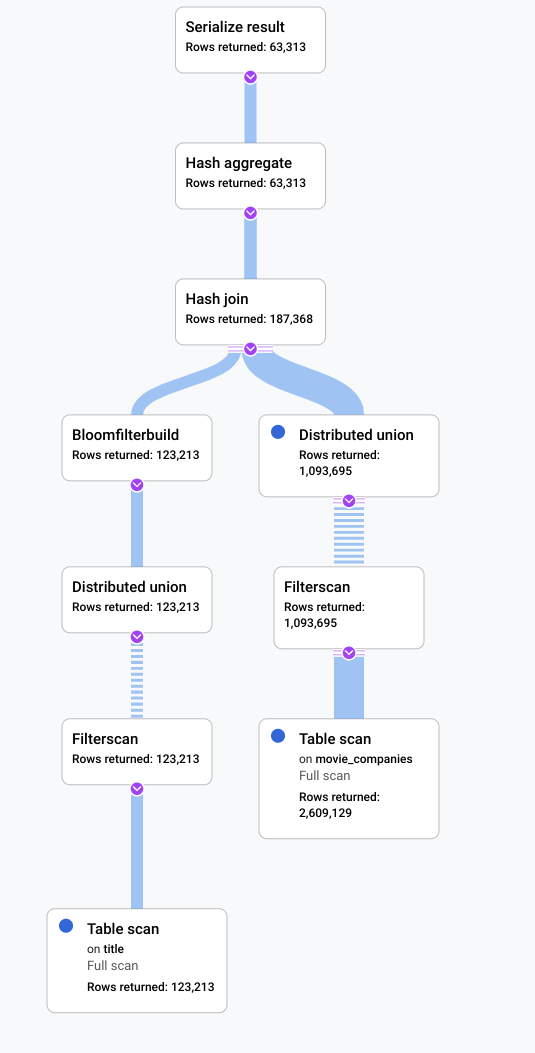
이 시나리오에서 개선할 수 있는 지표는 title 테이블의 행 중 상당 부분이 LIKE
'% the %' 필터를 정규화했다는 점입니다. 행이 너무 많은 다른 테이블을 살펴보면 비용이 많이 들 수 있습니다. 조인 구현을 해시 조인으로 변경하면 성능이 크게 향상됩니다.