Il visualizzatore del piano di query ti consente di comprendere rapidamente la struttura del piano di query scelto da Spanner per valutare una query. Questa guida descrive come utilizzare un piano di query per comprendere l'esecuzione delle query.
Prima di iniziare
Per familiarizzare con le parti dell'interfaccia utente della console Google Cloud menzionate in questa guida, leggi quanto segue:
Esegui una query nella console Google Cloud
- Vai alla pagina Istanze di Spanner nella console Google Cloud .
-
Seleziona il nome dell'istanza contenente il database su cui vuoi eseguire query.
La consoleGoogle Cloud mostra la pagina Panoramica dell'istanza.
-
Seleziona il nome del database su cui vuoi eseguire la query.
La consoleGoogle Cloud mostra la pagina Panoramica del database.
-
Nel menu laterale, fai clic su Spanner Studio.
Google Cloud visualizza la pagina Spanner Studio del database.
- Inserisci la query SQL nel riquadro dell'editor.
-
Fai clic su Esegui.
Spanner esegue la query.
- Fai clic sulla scheda Spiegazione per visualizzare la visualizzazione del piano di query.
Tour dell'editor di query
La pagina Spanner Studio fornisce schede di query che consentono di digitare o incollare query SQL e istruzioni DML, eseguirle sul database e visualizzare i risultati e i piani di esecuzione delle query. I componenti chiave della pagina Spanner Studio sono numerati nello screenshot seguente.
- La barra delle schede mostra le schede delle query aperte. Per creare una nuova
scheda, fai clic su Nuova scheda.
La barra delle schede fornisce anche un elenco di modelli di query che puoi utilizzare per incollare query che forniscono informazioni su query di database, transazioni, letture e altro ancora, come descritto in Panoramica degli strumenti di introspezione.
- La barra dei comandi dell'editor offre le seguenti opzioni:
- Il comando Esegui esegue le istruzioni inserite nel riquadro di modifica, producendo i risultati della query nella scheda Risultati e i piani di esecuzione della query nella scheda Spiegazione. Modifica il
comportamento predefinito utilizzando il menu a discesa per produrre Solo risultati
o Solo spiegazione.
L'evidenziazione di un elemento nell'editor modifica il comando Esegui in Esegui selezione, consentendoti di eseguire solo ciò che hai selezionato.
- Il comando Cancella query elimina tutto il testo nell'editor e cancella le schede secondarie Risultati e Spiegazione.
- Il comando Formatta query formatta le istruzioni nell'editor in modo che siano più facili da leggere.
- Il comando Scorciatoie mostra l'insieme di scorciatoie da tastiera che puoi utilizzare nell'editor.
- Il link Guida alle query SQL apre una scheda del browser con la documentazione sulla sintassi delle query SQL.
Le query vengono convalidate automaticamente ogni volta che vengono aggiornate nell'editor. Se le istruzioni sono valide, la barra dei comandi dell'editor mostra un segno di spunta di conferma e il messaggio Valido. In caso di problemi, viene visualizzato un messaggio di errore con i dettagli.
- Il comando Esegui esegue le istruzioni inserite nel riquadro di modifica, producendo i risultati della query nella scheda Risultati e i piani di esecuzione della query nella scheda Spiegazione. Modifica il
comportamento predefinito utilizzando il menu a discesa per produrre Solo risultati
o Solo spiegazione.
- L'editor è il punto in cui inserisci la query SQL e le istruzioni DML.
Sono codificati a colori e i numeri di riga vengono aggiunti automaticamente per
le istruzioni su più righe.
Se inserisci più di un'istruzione nell'editor, devi utilizzare un punto e virgola di terminazione dopo ogni istruzione, tranne l'ultima.
- Il riquadro inferiore di una scheda di query fornisce tre schede secondarie:
- La scheda secondaria Schema mostra le tabelle nel database e i relativi schemi. Utilizzalo come riferimento rapido quando componi le istruzioni nell'editor.
- La scheda secondaria Risultati mostra i risultati quando esegui le
istruzioni nell'editor. Per le query mostra una tabella dei risultati e
per le istruzioni DML come
INSERTe >UPDATEmostra un messaggio sul numero di righe interessate. - La scheda secondaria Spiegazione mostra grafici visivi dei piani di query creati quando esegui le istruzioni nell'editor.
- Le schede secondarie Risultati e Spiegazione forniscono entrambe un selettore di istruzioni che utilizzi per scegliere i risultati o il piano di query dell'istruzione che vuoi visualizzare.
Visualizzare i piani di query campionati
- Vai alla pagina Istanze di Spanner nella console Google Cloud .
-
Fai clic sul nome dell'istanza con le query che vuoi esaminare.
La consoleGoogle Cloud mostra la pagina Panoramica dell'istanza.
-
Nel menu Navigazione e nella sezione Osservabilità, fai clic su Approfondimenti sulle query.
La consoleGoogle Cloud mostra la pagina Query Insights dell'istanza.
-
Nel menu a discesa Database, seleziona il database con le query che vuoi esaminare.
La consoleGoogle Cloud mostra le informazioni sul carico delle query per il database. La tabella Query e tag TopN mostra l'elenco delle query e dei tag di richiesta principali ordinati in base all'utilizzo della CPU.
-
Trova la query con un utilizzo elevato della CPU per la quale vuoi visualizzare i piani di query campionati. Fai clic sul valore FPRINT di quella query.
La pagina Dettagli query mostra un grafico Esempi di piani di query per la query nel tempo. Puoi ridurre lo zoom fino a un massimo di sette giorni prima dell'ora attuale. Nota: i piani di query non sono supportati per le query con partitionTokens ottenuti dall'API PartitionQuery e query DML partizionate.
-
Fai clic su uno dei punti del grafico per visualizzare un piano di query precedente e visualizzare i passaggi eseguiti durante l'esecuzione della query. Puoi anche fare clic su un operatore per visualizzare informazioni più dettagliate.
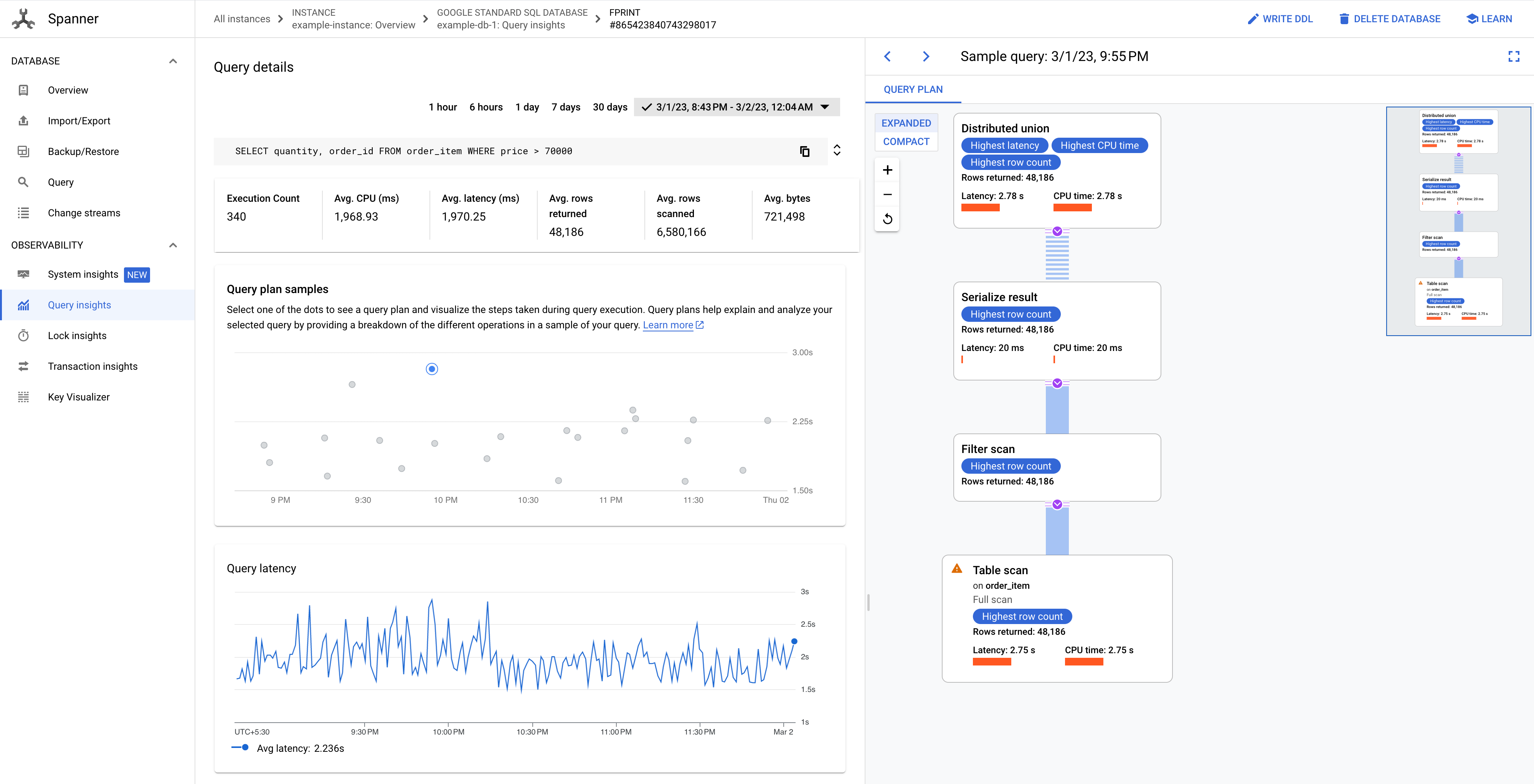
Figura 8. Grafico degli esempi di piani di query.
In alcuni casi, potresti voler visualizzare piani di query campionati e confrontare il rendimento di una query nel tempo. Per le query che consumano più CPU, Spanner conserva i piani di query campionati per 30 giorni nella pagina Query Insights della console Google Cloud . Per visualizzare i piani di query campionati:
Fai un tour del visualizzatore del piano di query
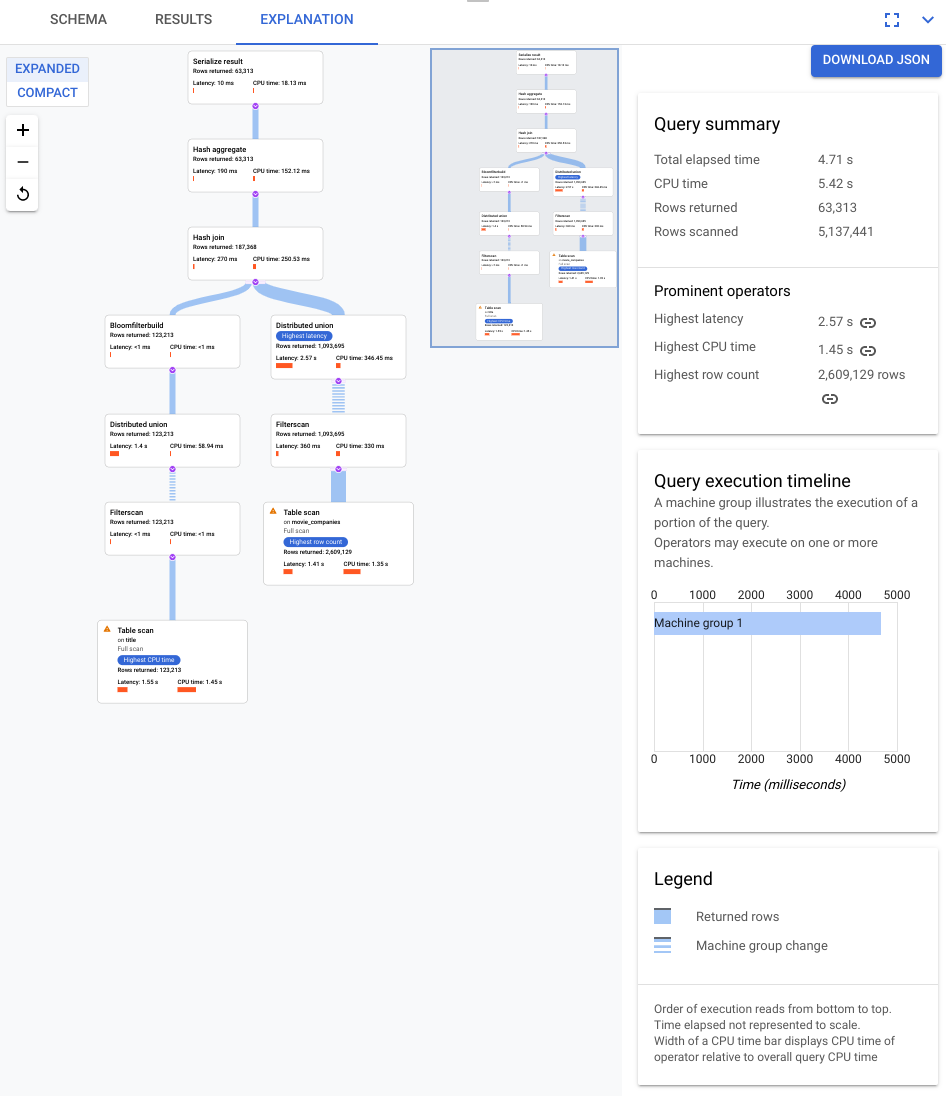
I componenti chiave del visualizzatore sono annotati nello screenshot seguente e descritti in modo più dettagliato. Dopo aver eseguito una query in una scheda della query, seleziona la scheda SPIEGAZIONE sotto l'editor di query per aprire il visualizzatore del piano di esecuzione della query.
Il flusso di dati nel seguente diagramma è dal basso verso l'alto, ovvero tutte le tabelle e gli indici si trovano nella parte inferiore del diagramma e l'output finale si trova nella parte superiore.
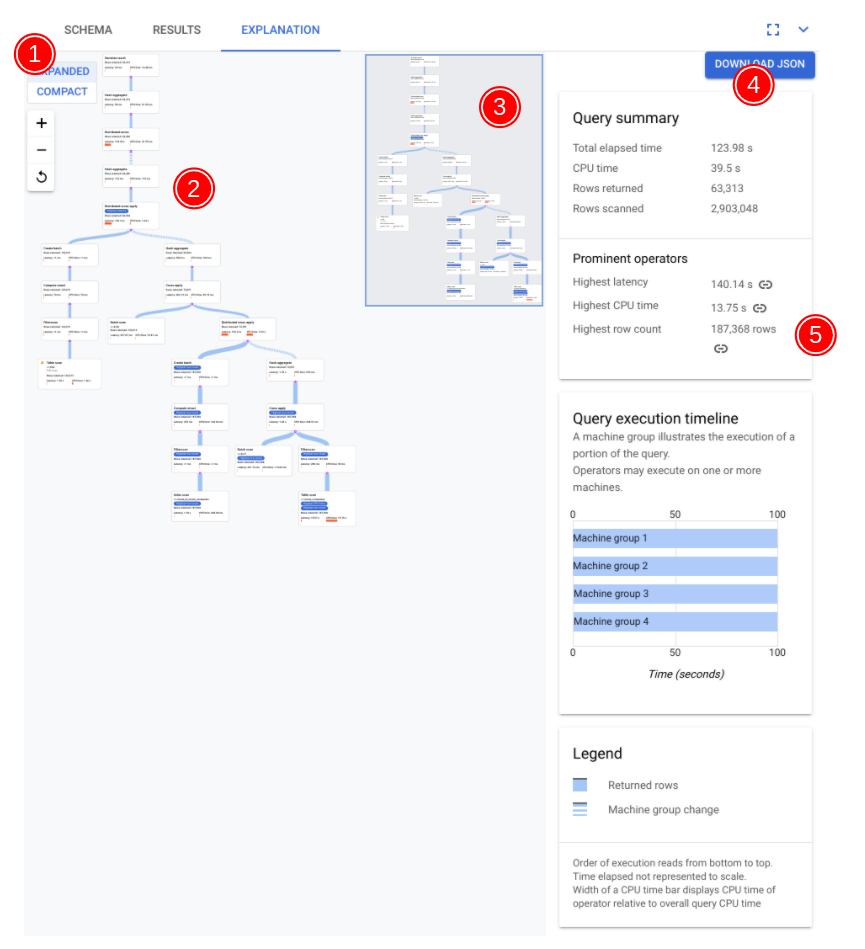
- La visualizzazione del piano può essere di grandi dimensioni, a seconda della query che hai eseguito. Per nascondere e mostrare i dettagli, attiva/disattiva il selettore della visualizzazione ESPANDI/COMPATTA. Puoi personalizzare la quantità di piano che vedi in un determinato momento utilizzando il controllo dello zoom.
- L'algebra che spiega come Spanner esegue la query
è rappresentata come un grafo aciclico, in cui ogni nodo corrisponde a un
iteratore che utilizza le righe dei suoi input e produce righe per il suo
elemento principale. Un piano di esempio è mostrato nella Figura 9. Fai clic sul diagramma
per visualizzare una versione espansa di alcuni dettagli del piano.
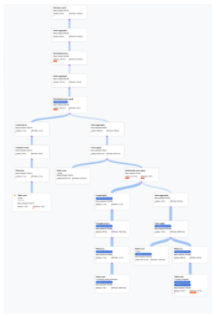
Figura 9. Piano visivo di esempio (fai clic per ingrandire). 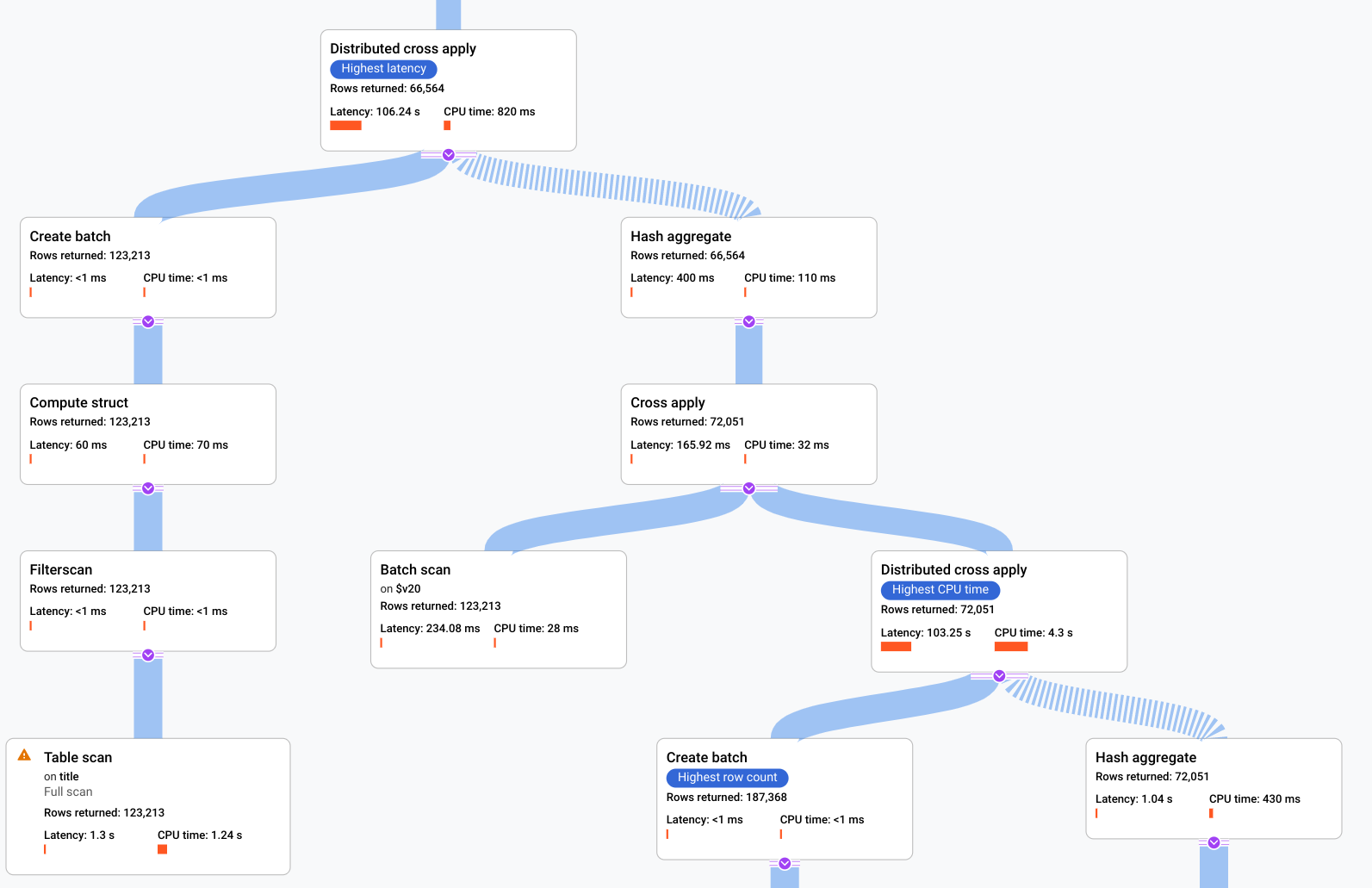
Ogni nodo, o scheda, del grafico rappresenta un iteratore e contiene le seguenti informazioni:
- Il nome dell'iteratore. Un iteratore utilizza le righe dell'input e produce righe.
- Statistiche di runtime che indicano quante righe sono state restituite, qual è stata la latenza e quanta CPU è stata utilizzata.
- Forniamo i seguenti suggerimenti visivi per aiutarti a identificare potenziali problemi all'interno del piano di esecuzione della query.
- Le barre rosse in un nodo sono indicatori visivi della percentuale di latenza o tempo CPU per questo iteratore rispetto al totale per la query.
- Lo spessore delle linee che collegano ogni nodo rappresenta il conteggio delle righe. Più spessa è la linea, maggiore è il numero di righe passate al nodo successivo. Il numero effettivo di righe viene visualizzato in ogni scheda e quando tieni il puntatore sopra un connettore.
- Su un nodo in cui è stata eseguita una scansione completa della tabella viene visualizzato un triangolo di avviso. Ulteriori dettagli nel riquadro delle informazioni includono consigli come l'aggiunta di un indice o la revisione della query o dello schema in altri modi, se possibile, per evitare una scansione completa.
- Seleziona una scheda nel piano per visualizzare i dettagli nel riquadro delle informazioni a destra (5).
- La mini mappa del piano di esecuzione mostra una visualizzazione ridotta del piano completo ed è utile per determinare la forma complessiva del piano di esecuzione e per navigare rapidamente nelle diverse parti del piano. Trascina direttamente sulla mini mappa o fai clic sul punto che vuoi mettere a fuoco per andare in un'altra parte del piano visivo.
Seleziona SCARICA JSON per scaricare una versione JSON del piano di esecuzione, utile per la risoluzione dei problemi. Puoi anche condividerlo quando contatti il team di Spanner per assistenza. Il salvataggio del JSON non salva il risultato della query.
Per scaricare e salvare una versione JSON del piano di esecuzione da visualizzare in un secondo momento:
- In Spanner Studio, esegui una query.
- Seleziona la scheda Spiegazione.
- Fai clic su SCARICA JSON per scaricare la versione JSON del piano di esecuzione.
- Salva e copia i contenuti del file JSON.
- Apri una nuova scheda dell'editor di query.
- Nella scheda dell'editor, inserisci:
PROTO: CONTENT_OF_JSON
- Fai clic su Esegui.
- Seleziona la scheda Spiegazione sotto l'editor di query per visualizzare una rappresentazione visiva del piano di esecuzione scaricato.
- Il riquadro delle informazioni mostra informazioni contestuali dettagliate sul nodo selezionato nel diagramma del piano di query. Le informazioni sono
organizzate nelle seguenti categorie.
- Informazioni sull'iteratore fornisce dettagli e statistiche di runtime per la scheda iteratore selezionata nel grafico.
- Riepilogo query fornisce dettagli sul numero di righe restituite e sul tempo impiegato per eseguire la query. Gli operatori prominenti sono quelli che mostrano una latenza significativa, consumano una CPU significativa rispetto ad altri operatori e restituiscono un numero significativo di righe di dati.
- La cronologia di esecuzione delle query è un grafico basato sul tempo che mostra per quanto tempo ogni gruppo di macchine ha eseguito la propria parte della query. Un gruppo di macchine potrebbe non essere in esecuzione per l'intera durata del tempo di esecuzione della query. È anche possibile che un gruppo di macchine sia stato eseguito più volte durante l'esecuzione della query, ma la sequenza temporale qui rappresenta solo l'inizio della prima esecuzione e la fine dell'ultima esecuzione.
Ottimizzare una query che mostra prestazioni scadenti
Immagina che la tua azienda gestisca un database di film online che contiene informazioni su film come cast, società di produzione, dettagli del film e altro ancora. Il servizio viene eseguito su Spanner, ma di recente ha riscontrato alcuni problemi di prestazioni.
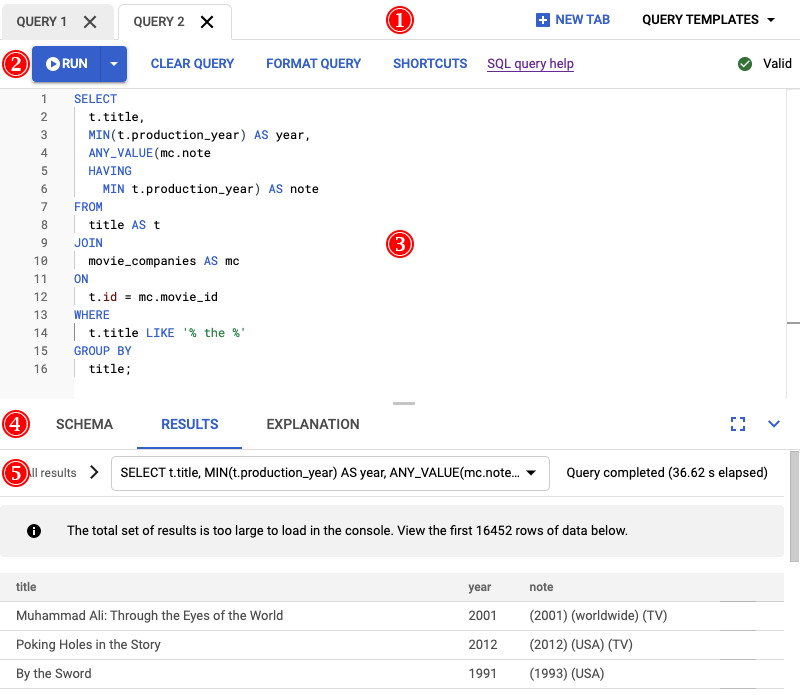
In qualità di sviluppatore principale del servizio, ti viene chiesto di esaminare questi problemi di prestazioni perché stanno causando valutazioni negative per il servizio. Apri la console Google Cloud , vai all'istanza di database e poi apri l'editor di query. Inserisci la seguente query nell'editor ed eseguila.
SELECT
t.title,
MIN(t.production_year) AS year,
ANY_VALUE(mc.note HAVING MIN t.production_year) AS note
FROM
title AS t
JOIN
movie_companies AS mc
ON
t.id = mc.movie_id
WHERE
t.title LIKE '% the %'
GROUP BY
title;
Il risultato dell'esecuzione di questa query è mostrato nello screenshot seguente. Abbiamo formattato la query nell'editor selezionando FORMATTA QUERY. Nell'angolo in alto a destra dello schermo è presente anche una nota che indica che la query è valida.
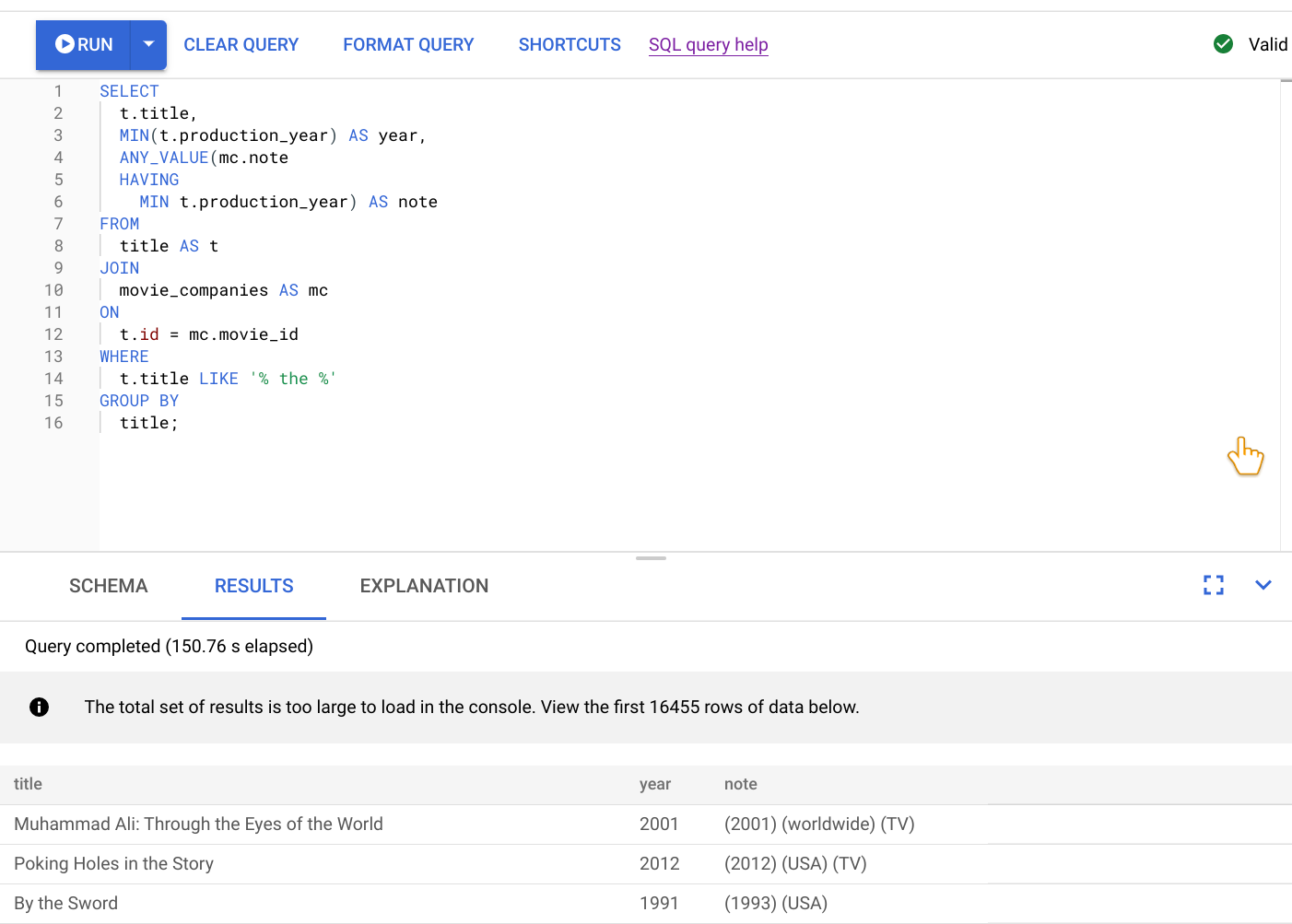
La scheda RISULTATI sotto l'editor di query mostra che la query è stata completata in poco più di due minuti. Decidi di esaminare più da vicino la query per verificare se è efficiente.
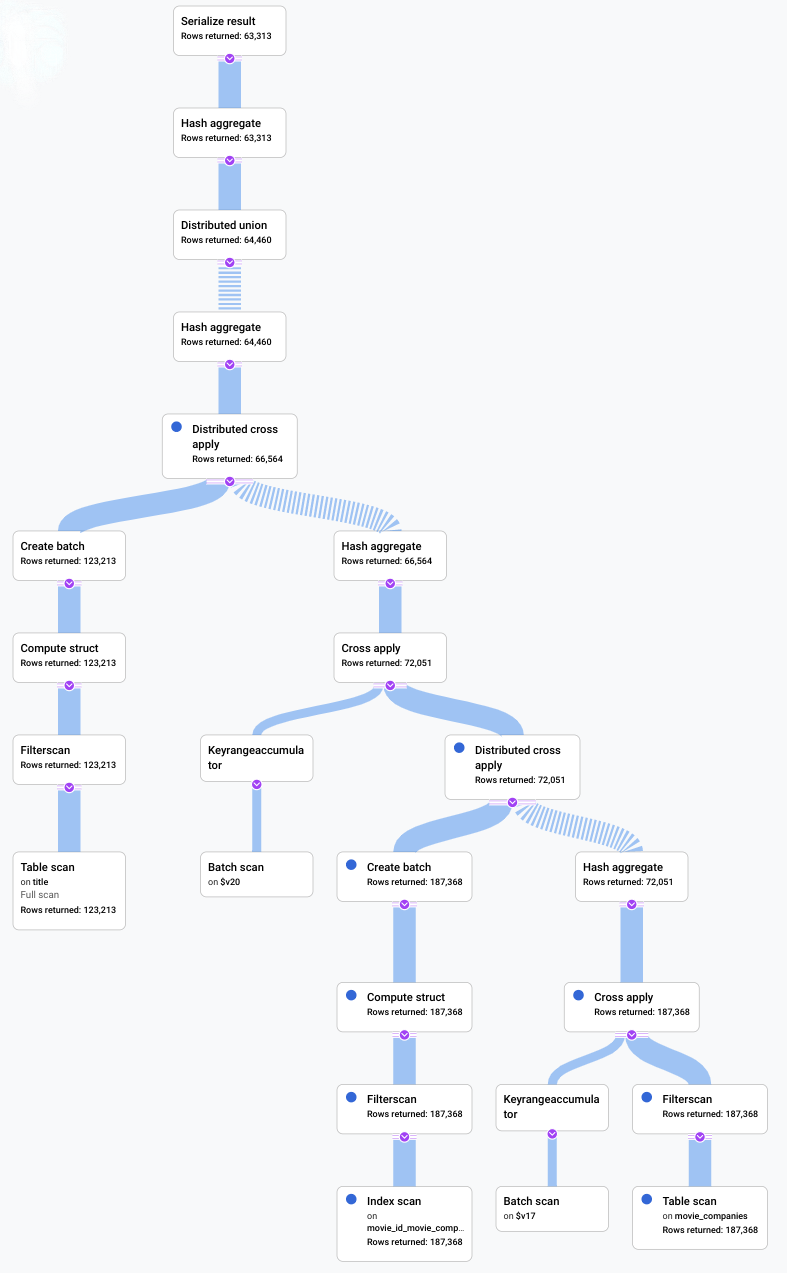
Analizza le query lente con il visualizzatore del piano di query
A questo punto, sappiamo che la query nel passaggio precedente richiede più di due minuti, ma non sappiamo se la query è la più efficiente possibile e, pertanto, se questa durata è prevista.
Seleziona la scheda SPIEGAZIONE appena sotto l'editor di query per visualizzare una rappresentazione visiva del piano di esecuzione creato da Spanner per eseguire la query e restituire i risultati.
Il piano mostrato nello screenshot seguente è relativamente grande, ma anche a questo livello di zoom puoi fare le seguenti osservazioni.
In base al Riepilogo query nel riquadro delle informazioni a destra, scopriamo che sono state analizzate quasi 3 milioni di righe e ne sono state restituite meno di 64.000.
Dal riquadro Cronologia di esecuzione delle query possiamo anche vedere che nella query sono stati coinvolti 4 gruppi di macchine. Un gruppo di macchine è responsabile dell'esecuzione di una parte della query. L'esecuzione degli operatori può avvenire su una o più macchine. Se selezioni un gruppo di macchine nella cronologia, nel piano visivo viene evidenziata la parte della query eseguita su quel gruppo.
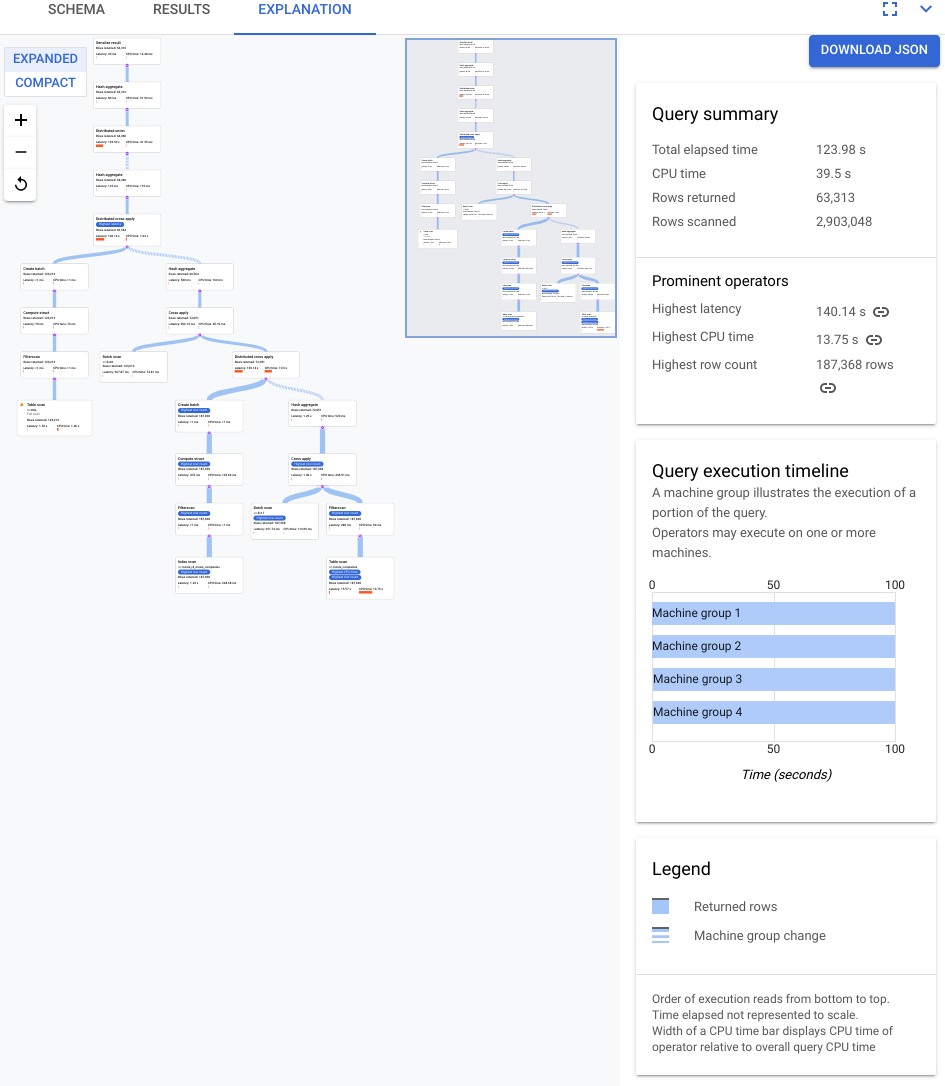
A causa di questi fattori, decidi che un miglioramento del rendimento potrebbe essere possibile modificando il join da un apply join, che Spanner ha scelto per impostazione predefinita, a un hash join.
Migliorare la query
Per migliorare il rendimento della query, utilizza un suggerimento di join per modificare il metodo di join in un hash join. Questa implementazione del join esegue l'elaborazione basata su set.
Ecco la query aggiornata:
SELECT
t.title,
MIN(t.production_year) AS year,
ANY_VALUE(mc.note HAVING MIN t.production_year) AS note
FROM
title AS t
JOIN
@{join_method=hash_join} movie_companies AS mc
ON
t.id = mc.movie_id
WHERE
t.title LIKE '% the %'
GROUP BY
title;
Lo screenshot seguente illustra la query aggiornata. Come mostrato nello screenshot, la query è stata completata in meno di 5 secondi, un miglioramento significativo rispetto ai 120 secondi di runtime prima di questa modifica.
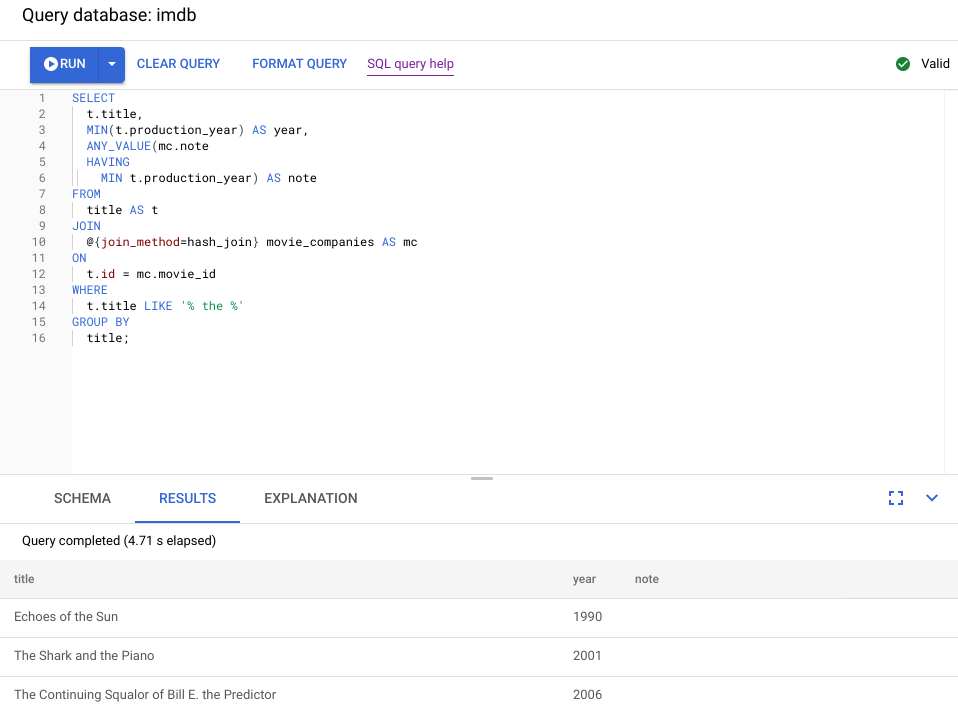
Esamina il nuovo piano visivo, mostrato nel seguente diagramma, per vedere cosa ci dice di questo miglioramento.
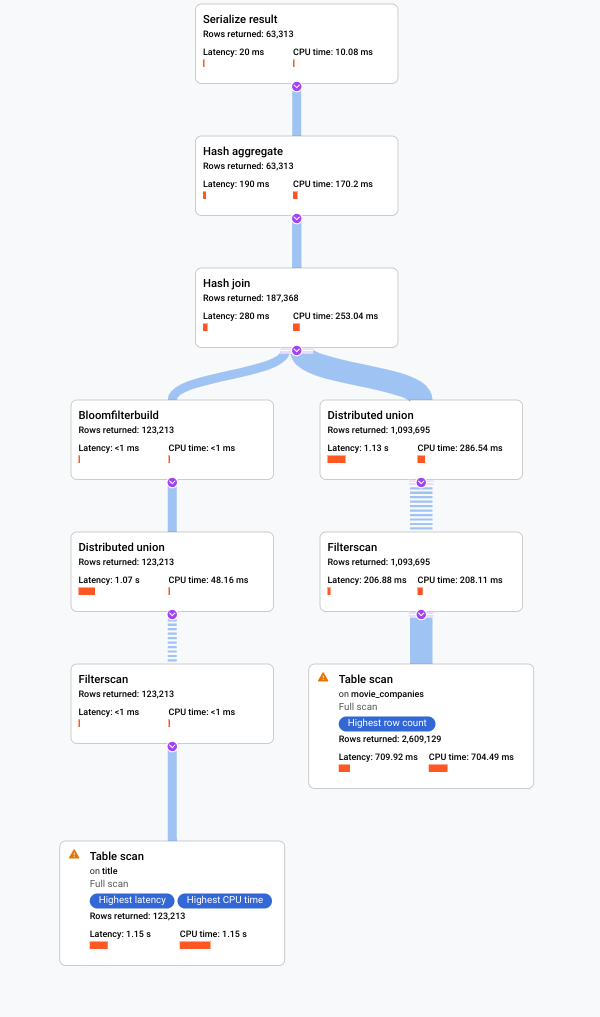
Noterai subito alcune differenze:
In questa esecuzione della query è stato coinvolto un solo gruppo di macchine.
Il numero di aggregazioni è stato ridotto drasticamente.
Conclusione
In questo scenario, abbiamo eseguito una query lenta e abbiamo esaminato il relativo piano visivo per cercare inefficienze. Di seguito è riportato un riepilogo delle query e dei piani prima e dopo l'apporto di eventuali modifiche. Ogni scheda mostra la query eseguita e una visualizzazione compatta del piano di esecuzione della query completo.
Prima
SELECT
t.title,
MIN(t.production_year) AS year,
ANY_VALUE(mc.note
HAVING
MIN t.production_year) AS note
FROM
title AS t
JOIN
movie_companies AS mc
ON
t.id = mc.movie_id
WHERE
t.title LIKE '% the %'
GROUP BY
title;
Dopo
SELECT
t.title,
MIN(t.production_year) AS year,
ANY_VALUE(mc.note
HAVING
MIN t.production_year) AS note
FROM
title AS t
JOIN
@{join_method=hash_join} movie_companies AS mc
ON
t.id = mc.movie_id
WHERE
t.title LIKE '% the %'
GROUP BY
title;
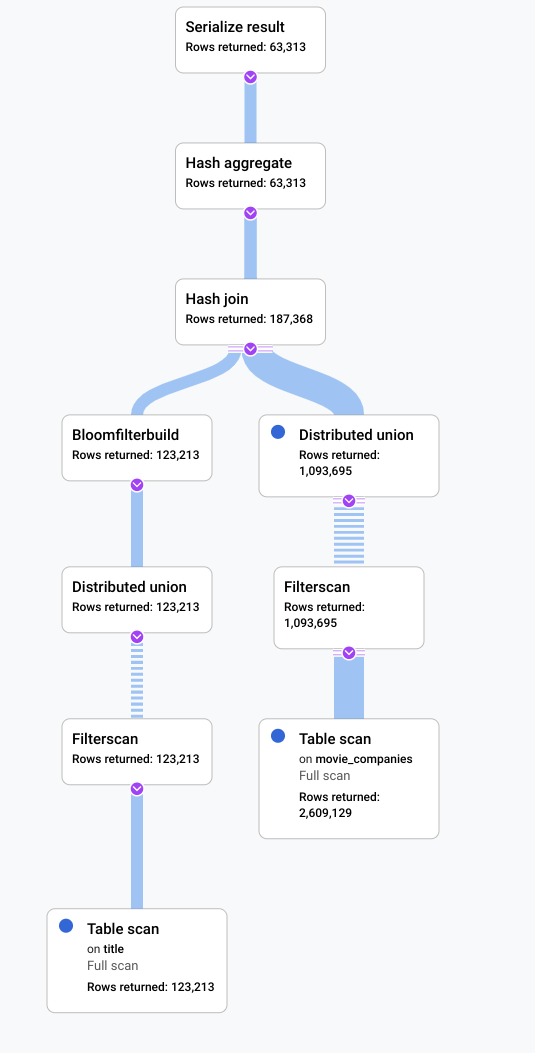
Un indicatore che suggerisce la possibilità di migliorare questo scenario è che una grande
proporzione di righe della tabella title soddisfaceva il filtro LIKE
'% the %'. La ricerca in un'altra tabella con così tante righe è probabilmente
costosa. La modifica dell'implementazione del join in un hash join ha migliorato
significativamente le prestazioni.
Passaggi successivi
Per il riferimento completo al piano di query, consulta Piani di esecuzione delle query.
Per il riferimento completo agli operatori, consulta Operatori di esecuzione delle query.