當您使用 SQL 查詢查詢資料時,Spanner 會自動使用任何可能有助於更有效率地擷取資料的次要索引。然而,在少數情況下,Spanner 可能會選擇造成查詢速度變慢的索引。因此,您可能會發現某些查詢的執行速度比以往慢。
本頁面說明如何偵測查詢執行速度的變化、檢查這些查詢的查詢執行計畫,以及視需要為日後的查詢指定不同的索引。
偵測查詢執行速度的變化
在下列情況下,查詢執行速度很可能會有所變化:
- 大幅變更含有次要索引的大量現有資料。
- 新增、變更或刪除次要索引。
您可以使用多種工具,找出 Spanner 執行速度比平常慢的特定查詢:
- 查詢洞察和查詢統計資料。
延遲指標。
您透過 Cloud Monitoring 擷取及分析的特定應用程式指標。舉例來說,您可以監控「查詢數量」指標,判斷執行個例中查詢的數量,並找出執行查詢時使用的查詢最佳化器版本。
用於評估應用程式效能的用戶端監控工具。
關於新資料庫的注意事項
當您使用新插入或匯入的資料查詢新建的資料庫時,Spanner 可能不會選取最適當的索引,因為查詢最佳化工具最多需要三天才能自動收集最佳化工具統計資料。如要提早最佳化新 Spanner 資料庫的索引用量,您可以手動建構新的統計資料套件。
查看結構定義
找出導致速度變慢的查詢後,請查看該查詢的 SQL 陳述式,並找出陳述式使用的資料表,以及從這些資料表擷取的資料欄。
接著,找出這些資料表的次要索引。判斷是否有任何索引包含您要查詢的資料欄,這表示 Spanner 可能會使用其中一個索引來處理查詢。
- 如果有適用的索引,下一個步驟就是找出 Spanner 用於查詢的索引。
如果沒有適用的索引,請使用
gcloud spanner operations list指令檢查您是否最近刪除適用的索引:gcloud spanner operations list \ --instance=INSTANCE \ --database=DATABASE \ --filter="@TYPE:UpdateDatabaseDdlMetadata"如果您刪除適用的索引,該變更可能會影響查詢效能。將次要索引加回資料表。Spanner 新增索引後,請再次執行查詢並查看其效能。如果效能未改善,下一個步驟是找出 Spanner 用於查詢的索引。
如果您並未刪除適用的索引,則索引選取作業並不會導致查詢效能下降。查看資料或使用模式是否有其他變更,可能會影響成效。
找出用於查詢的索引
如要瞭解 Spanner 用來處理查詢的索引,請在 Google Cloud 控制台中查看查詢執行計劃:
前往 Google Cloud 控制台的 Spanner「Instances」(執行個體) 頁面。
按一下要查詢的執行個體名稱。
在左側窗格中,按一下要查詢的資料庫,然後按一下 「Spanner Studio」。
輸入要測試的查詢。
在「執行查詢」下拉式清單中,選取「僅顯示說明」。Spanner 會顯示查詢計畫。
在查詢計劃中找出至少下列任一運算子:
- 資料表掃描
- 索引掃描
- Cross apply 或 distributed cross apply
以下各節將說明各運算子的含義。
資料表掃描運算子
「資料表掃描」運算子表示 Spanner 並未使用次要索引:
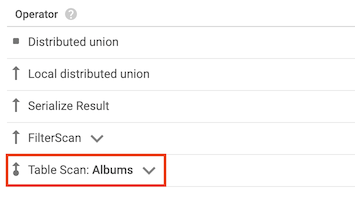
舉例來說,假設 Albums 資料表沒有任何次要索引,且您執行下列查詢:
SELECT AlbumTitle FROM Albums WHERE STARTS_WITH(AlbumTitle, "Now");
由於沒有可用的索引,因此查詢計畫包含資料表掃描運算子。
索引掃描運算子
索引掃描運算子表示 Spanner 在處理查詢時使用了次要索引:
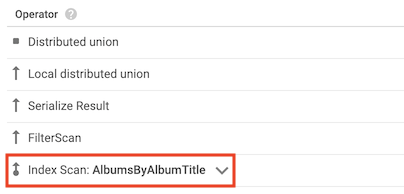
舉例來說,假設您在 Albums 資料表中新增索引:
CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle);
然後執行下列查詢:
SELECT AlbumTitle FROM Albums WHERE STARTS_WITH(AlbumTitle, "Now");
AlbumsByAlbumTitle 索引包含 AlbumTitle,這是查詢選取的唯一資料欄。因此,查詢計畫會包含索引掃描運算子。
Cross apply 運算子
在某些情況下,Spanner 會使用只包含查詢所選部分資料欄的索引。因此,Spanner 必須將索引與基礎資料表彙整。
發生這類彙整時,查詢計劃會包含 cross apply 或 distributed cross apply 運算子,其中包含下列輸入內容:
- 資料表索引的索引掃描運算子
- 擁有索引的資料表的資料表掃描運算子
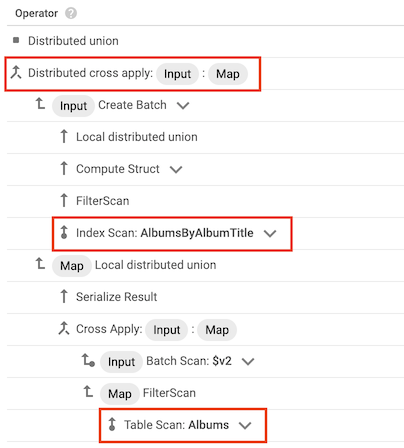
舉例來說,假設您在 Albums 資料表中新增索引:
CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle);
然後執行下列查詢:
SELECT * FROM Albums WHERE STARTS_WITH(AlbumTitle, "Now");
AlbumsByAlbumTitle 索引包含 AlbumTitle,但查詢會選取資料表中的所有資料欄,而非只選取 AlbumTitle。因此,查詢計畫包含分散式 cross apply 運算子,其中 AlbumsByAlbumTitle 的索引掃描和 Albums 的資料表掃描做為輸入。
選擇其他索引
找出 Spanner 用於查詢的索引後,請嘗試使用其他索引執行查詢,或掃描主資料表,而非使用索引。如要指定索引,請在查詢中加入 FORCE_INDEX 指令。
如果您發現更快的查詢版本,請更新應用程式以便使用更快的版本。
選擇索引的指南
請根據下列規範,決定要為查詢測試哪個索引:
如果查詢符合下列任一條件,請改用主資料表,不要使用次要索引:
- 查詢會檢查是否與基礎資料表的主鍵前置字串相等 (例如
SELECT * FROM Albums WHERE SingerId = 1)。 - 大量資料列符合查詢述詞 (例如
SELECT * FROM Albums WHERE AlbumTitle != "There Is No Album With This Title")。 - 查詢使用只包含幾百列的基礎資料表。
- 查詢會檢查是否與基礎資料表的主鍵前置字串相等 (例如
如果查詢包含非常精確的述詞 (例如
REGEXP_CONTAINS、STARTS_WITH、<、<=、>、>=或!=),請嘗試使用包含述詞中所用相同欄位的索引。
測試更新後的查詢
使用 Google Cloud 控制台測試更新後的查詢,找出處理查詢所需的時間。
如果查詢包含查詢參數,且某個查詢參數與某些值繫結的頻率遠高於其他值,請在測試中將查詢參數與其中一個值繫結。舉例來說,如果查詢包含 WHERE country = @countryId 等述詞,且幾乎所有查詢都將 @countryId 繫結至 US 值,請將 @countryId 繫結至 US 以進行效能測試。這有助於針對您最常執行的查詢進行最佳化。
如要在 Google Cloud 控制台中測試更新後的查詢,請按照下列步驟操作:
前往 Google Cloud 控制台的 Spanner「Instances」(執行個體) 頁面。
按一下要查詢的執行個體名稱。
在左側窗格中,按一下要查詢的資料庫,然後按一下 「Spanner Studio」。
輸入要測試的查詢 (包括
FORCE_INDEX指令),然後按一下「Run query」(執行查詢)。Google Cloud 控制台會開啟「結果表格」分頁,然後顯示查詢結果,包括 Spanner 服務處理查詢所需的時間。
這項指標不包含其他延遲來源,例如 Google Cloud 主控台解讀及顯示查詢結果所需的時間。
使用 REST API 以 JSON 格式取得查詢的詳細設定檔
根據預設,執行查詢時只會傳回陳述式結果。這是因為 QueryMode 已設為 NORMAL。如要在查詢結果中加入詳細的執行統計資料,請將 QueryMode 設為 PROFILE。
建立工作階段
更新查詢模式前,請先建立工作階段,代表與 Spanner 資料庫服務的通訊管道。
- 按一下 [
projects.instances.databases.sessions.create]。 請在下列表單中提供專案、執行個體和資料庫 ID:
projects/[\PROJECT_ID\]/instances/[\INSTANCE_ID\]/databases/[\DATABASE_ID\]按一下 [Execute] (執行)。回應會顯示您在這個表單中建立的工作階段:
projects/[\PROJECT_ID\]/instances/[\INSTANCE_ID\]/databases/[\DATABASE_ID\]/sessions/[\SESSION\]您將在下一個步驟中使用此檔案執行查詢設定檔。建立的工作階段在連續使用之間最多會維持一小時,之後就會遭到資料庫刪除。
剖析查詢
為查詢啟用 PROFILE 模式。
- 按一下 [
projects.instances.databases.sessions.executeSql]。 在「工作階段」中,輸入您在上一個步驟中建立的工作階段 ID:
projects/[PROJECT_ID]/instances/[INSTANCE_ID]/databases/[DATABASE_ID]/sessions/[SESSION]針對「Request body」,請使用以下內容:
{ "sql": "[YOUR_SQL_QUERY]", "queryMode": "PROFILE" }按一下 [Execute] (執行)。傳回的回應會包含查詢結果、查詢計畫,以及查詢的執行統計資料。