Comme décrit dans la page Plans d'exécution de requêtes, le compilateur SQL transforme une instruction SQL en un plan d'exécution de requêtes, qui sert à obtenir les résultats d'une requête. Cette page décrit les bonnes pratiques pour la création d'instructions SQL qui aideront Spanner à trouver des plans d'exécution efficaces.
Les exemples d'instructions SQL présentés dans cette page suivent l'exemple de schéma suivant:
GoogleSQL
CREATE TABLE Singers (
SingerId INT64 NOT NULL,
FirstName STRING(1024),
LastName STRING(1024),
SingerInfo BYTES(MAX),
BirthDate DATE
) PRIMARY KEY (SingerId);
CREATE TABLE Albums (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
AlbumTitle STRING(MAX),
ReleaseDate DATE
) PRIMARY KEY (SingerId, AlbumId),
INTERLEAVE IN PARENT Singers ON DELETE CASCADE;
Pour obtenir une documentation de référence complète sur SQL, consultez les pages Syntaxe des requêtes, Fonctions et opérateurs et Structure lexicale et syntaxe.
PostgreSQL
CREATE TABLE Singers (
SingerId BIGINT PRIMARY KEY,
FirstName VARCHAR(1024),
LastName VARCHAR(1024),
SingerInfo BYTEA,
BirthDate TIMESTAMPTZ
);
CREATE TABLE Albums (
SingerId BIGINT NOT NULL,
AlbumId BIGINT NOT NULL,
AlbumTitle VARCHAR(1024),
ReleaseDate DATE,
PRIMARY KEY(SingerId, AlbumId),
FOREIGN KEY (SingerId) REFERENCES Singers(SingerId)
) INTERLEAVE IN PARENT Singers ON DELETE CASCADE;
Pour en savoir plus, consultez la section Le langage PostgreSQL dans Spanner.
Utiliser des paramètres de requête
Spanner accepte les paramètres de requête pour améliorer les performances et aider à éviter l'injection SQL lorsque les requêtes sont créées à l'aide d'entrées utilisateur. Vous pouvez utiliser des paramètres de requête pour remplacer des expressions arbitraires, mais pas pour remplacer des identifiants, des noms de colonnes, des noms de tables ou d'autres parties de la requête.
Les paramètres peuvent apparaître partout où une valeur littérale est attendue. Le même nom de paramètre peut être utilisé plusieurs fois dans une seule instruction SQL.
En résumé, les paramètres de requête favorisent l'exécution des requêtes de différentes manières:
- Plans préoptimisés: les requêtes utilisant des paramètres peuvent être exécutées plus rapidement à chaque appel, car le paramétrage facilite la mise en cache du plan d'exécution par Spanner.
- Composition de requête simplifiée: vous n'avez pas besoin d'échapper les valeurs de chaîne lorsque vous les fournissez dans les paramètres de requête. Les paramètres de requête réduisent également le risque d'erreurs de syntaxe.
- Sécurité: les paramètres de requête renforcent la sécurité de vos requêtes en vous protégeant contre diverses attaques par injection SQL. Cette protection est particulièrement importante pour les requêtes que vous créez à partir d'entrées utilisateur.
Comprendre comment Spanner exécute les requêtes
Spanner vous permet d'interroger des bases de données à l'aide d'instructions SQL déclaratives spécifiant les données que vous souhaitez récupérer. Si vous souhaitez comprendre comment Spanner obtient les résultats, examinez le plan d'exécution de la requête. Un plan d'exécution de requête affiche le coût de calcul associé à chaque étape de la requête. À l'aide de ces coûts, vous pouvez déboguer les problèmes de performance et optimiser votre requête. Pour en savoir plus, consultez la section Plans d'exécution de requêtes.
Vous pouvez récupérer les plans d'exécution de requêtes via la Google Cloud console ou en utilisant les bibliothèques clientes.
Pour obtenir un plan d'exécution de requêtes pour une requête spécifique à l'aide de la console Google Cloud , procédez comme suit:
Ouvrez la page "Instances Spanner".
Sélectionnez le nom de l'instance Spanner et de la base de données que vous souhaitez interroger.
Cliquez sur Spanner Studio dans le panneau de navigation de gauche.
Saisissez la requête dans le champ de texte, puis cliquez sur Exécuter la requête.
Cliquez sur Explication
. La console Google Cloud affiche un plan d'exécution visuel pour votre requête.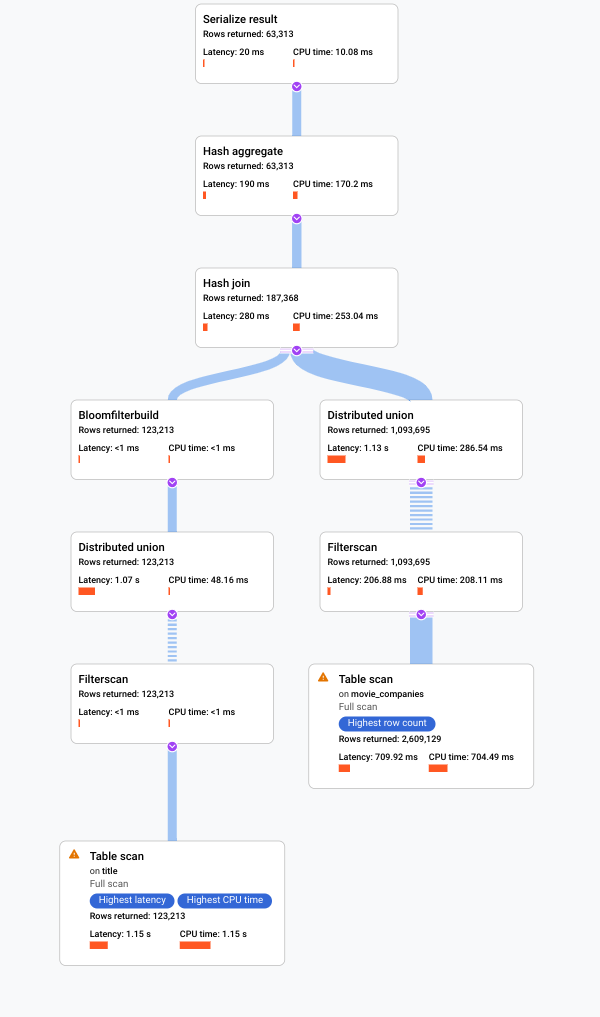
Pour en savoir plus sur la compréhension des plans visuels et leur utilisation pour déboguer vos requêtes, consultez la section Régler une requête à l'aide de l'outil de visualisation de plans de requête.
Vous pouvez également afficher des exemples d'historiques de plans de requêtes et comparer les performances d'une requête au fil du temps pour certaines requêtes. Pour en savoir plus, consultez la section Exemples de plans de requêtes.
Utiliser des index secondaires
Comme les autres bases de données relationnelles, Spanner propose des index secondaires que vous pouvez utiliser pour récupérer des données à l'aide d'une instruction SQL ou de l'interface de lecture de Spanner. Le moyen le plus courant d'extraire des données d'un index consiste à utiliser Spanner Studio. L'utilisation d'un index secondaire dans une requête SQL vous permet de spécifier comment vous souhaitez que Spanner obtienne les résultats. La spécification d'un index secondaire peut accélérer l'exécution des requêtes.
Par exemple, supposons que vous souhaitiez récupérer les identifiants de tous les chanteurs portant un nom de famille spécifique. La requête SQL pourrait être écrite de cette façon (par exemple) :
SELECT s.SingerId
FROM Singers AS s
WHERE s.LastName = 'Smith';
Cette requête renverrait les résultats attendus, mais son traitement pourrait prendre du temps. Le délai dépend du nombre de lignes de la table Singers et du nombre de lignes correspondant au prédicat WHERE s.LastName = 'Smith'. S'il n'y a pas d'index secondaire contenant la colonne LastName à lire, le plan de requête lira l'intégralité de la table Singers pour rechercher les lignes correspondant au prédicat. La lecture de la table entière s'appelle analyse complète de table. Une analyse complète de table est un moyen coûteux d'obtenir les résultats lorsque la table ne contient qu'un faible pourcentage de Singers portant ce nom de famille.
Pour améliorer les performances de cette requête, définissez un index secondaire sur la colonne du nom de famille, comme suit :
CREATE INDEX SingersByLastName ON Singers (LastName);
Comme l'index secondaire SingersByLastName contient la colonne LastName de la table indexée et la colonne de clé primaire SingerId, Spanner peut récupérer toutes les données de la table d'index qui est bien plus petite, sans avoir à effectuer une analyse complète de la table Singers.
Dans ce scénario, Spanner utilise automatiquement l'index secondaire SingersByLastName lors de l'exécution de la requête (du moment que trois jours se sont écoulés depuis la création de la base de données, voir la note concernant les nouvelles bases de données). Cependant, il est préférable de le lui demander explicitement en spécifiant une directive d'index dans la clause FROM:
GoogleSQL
SELECT s.SingerId
FROM Singers@{FORCE_INDEX=SingersByLastName} AS s
WHERE s.LastName = 'Smith';
PostgreSQL
SELECT s.SingerId
FROM Singers /*@ FORCE_INDEX=SingersByLastName */ AS s
WHERE s.LastName = 'Smith';
Supposons maintenant que vous souhaitiez également récupérer le prénom du chanteur en plus de son identifiant. Même si la colonne FirstName ne fait pas partie de l'index, vous devez toujours spécifier la directive d'index comme auparavant, de la manière suivante :
GoogleSQL
SELECT s.SingerId, s.FirstName
FROM Singers@{FORCE_INDEX=SingersByLastName} AS s
WHERE s.LastName = 'Smith';
PostgreSQL
SELECT s.SingerId, s.FirstName
FROM Singers /*@ FORCE_INDEX=SingersByLastName */ AS s
WHERE s.LastName = 'Smith';
Vous bénéficiez toujours d'un avantage en termes de performances grâce à l'utilisation de l'index, car Spanner n'a pas besoin d'effectuer une analyse complète de la table lors de l'exécution du plan de requête. Au lieu de cela, il sélectionne le sous-ensemble de lignes qui correspond au prédicat à partir de l'index SingersByLastName, puis effectue une recherche dans la table de base Singers pour n'extraire le prénom que pour ce sous-ensemble de lignes.
Si vous ne souhaitez pas que Spanner ait à récupérer des lignes de la table de base, vous pouvez stocker une copie de la colonne FirstName dans l'index même comme suit:
GoogleSQL
CREATE INDEX SingersByLastName ON Singers (LastName) STORING (FirstName);
PostgreSQL
CREATE INDEX SingersByLastName ON Singers (LastName) INCLUDE (FirstName);
L'utilisation d'une clause STORING (pour le dialecte GoogleSQL) ou d'une clause INCLUDE (pour le dialecte PostgreSQL) comme celle-ci consomme du stockage supplémentaire, mais elle offre les avantages suivants:
- Les requêtes SQL qui utilisent l'index et sélectionnent les colonnes stockées dans la clause
STORINGouINCLUDEne nécessitent pas de jointure supplémentaire à la table de base. - Les appels de lecture utilisant l'index peuvent lire les colonnes stockées dans la clause
STORINGouINCLUDE.
Les exemples ci-dessus illustrent comment les index secondaires peuvent accélérer les requêtes, en particulier lorsque ce type d'index permet d'identifier rapidement les lignes choisies par la clause WHERE d'une requête.
Un autre scénario dans lequel les index secondaires peuvent offrir des avantages en termes de performance concerne certaines requêtes qui renvoient des résultats ordonnés. Par exemple, supposons que vous souhaitiez extraire tous les titres d'album et leurs dates de sortie dans l'ordre croissant de la date de sortie et dans l'ordre décroissant des titres d'album. Vous pouvez écrire une requête SQL comme suit:
SELECT a.AlbumTitle, a.ReleaseDate
FROM Albums AS a
ORDER BY a.ReleaseDate, a.AlbumTitle DESC;
Sans index secondaire, cette requête nécessite une étape de tri potentiellement coûteuse dans le plan d'exécution. Vous pouvez accélérer l'exécution de la requête en définissant l'index secondaire suivant :
CREATE INDEX AlbumsByReleaseDateTitleDesc on Albums (ReleaseDate, AlbumTitle DESC);
Réécrivez ensuite la requête pour qu'elle utilise l'index secondaire:
GoogleSQL
SELECT a.AlbumTitle, a.ReleaseDate
FROM Albums@{FORCE_INDEX=AlbumsByReleaseDateTitleDesc} AS a
ORDER BY a.ReleaseDate, a.AlbumTitle DESC;
PostgreSQL
SELECT a.AlbumTitle, a.ReleaseDate
FROM Albums /*@ FORCE_INDEX=AlbumsByReleaseDateTitleDesc */ AS s
ORDER BY a.ReleaseDate, a.AlbumTitle DESC;
Cette requête et cette définition d'index répondent aux deux critères suivants:
- Pour supprimer l'étape de tri, assurez-vous que la liste des colonnes dans la clause
ORDER BYest un préfixe de la liste des clés d'index. - Pour éviter de joindre à nouveau la table de base afin de récupérer les colonnes manquantes, assurez-vous que l'index couvre toutes les colonnes de la table utilisée par la requête.
Bien que les index secondaires puissent accélérer les requêtes courantes, leur ajout peut rallonger la latence de vos opérations de validation, car chaque index secondaire nécessite généralement l'implication d'un nœud supplémentaire dans chaque validation. Pour la plupart des charges de travail, quelques index secondaires sont suffisants. Cependant, vous devez déterminer si vous êtes plus soucieux de la latence en lecture ou en écriture, ainsi que les opérations les plus critiques pour votre charge de travail. Analysez votre charge de travail pour vous assurer qu'elle correspond à vos attentes.
Pour obtenir une documentation de référence complète sur les index secondaires, consultez la page Index secondaires.
Optimiser les analyses
Certaines requêtes Spanner peuvent bénéficier d'une méthode de traitement orientée par lot lors de l'analyse des données plutôt que de la méthode de traitement orientée par ligne plus courante. Le traitement des analyses par lots est un moyen plus efficace de traiter de grands volumes de données en une seule fois. Il permet aux requêtes d'obtenir une utilisation et une latence du processeur plus faibles.
L'opération d'analyse Spanner démarre toujours l'exécution dans la méthode orientée ligne. Pendant ce temps, Spanner collecte plusieurs métriques d'exécution. Ensuite, Spanner applique un ensemble d'heuristiques basées sur le résultat de ces métriques pour déterminer la méthode d'analyse optimale. Le cas échéant, Spanner passe à une méthode de traitement orientée par lot pour améliorer le débit et les performances de l'analyse.
Cas d'utilisation courants
Les requêtes présentant les caractéristiques suivantes bénéficient généralement du traitement par lot:
- Analyse volumineuse de données rarement mises à jour.
- Analyse avec des prédicats sur des colonnes à largeur fixe.
- Analyses avec un grand nombre de recherches. (Une recherche utilise un indice pour récupérer des enregistrements.)
Cas d'utilisation sans gains de performances
Toutes les requêtes ne bénéficient pas du traitement par lot. Les types de requêtes suivants fonctionnent mieux avec le traitement de balayage orienté ligne:
- Requêtes de recherche de point: requêtes qui ne récupèrent qu'une seule ligne.
- Requêtes d'analyse de petite envergure: analyses de table qui n'analysent que quelques lignes, sauf si elles comportent un nombre élevé de recherches.
- Requêtes qui utilisent
LIMIT. - Requêtes qui lisent des données à forte attrition: requêtes dans lesquelles plus de 10% des données lues sont fréquemment mises à jour.
- Requêtes avec des lignes contenant de grandes valeurs: les lignes contenant de grandes valeurs sont celles contenant des valeurs supérieures à 32 000 octets (avant compression) dans une seule colonne.
Vérifier la méthode d'analyse utilisée par une requête
Pour vérifier si votre requête utilise un traitement par lot, un traitement par ligne ou si elle bascule automatiquement entre les deux méthodes d'exploration:
Accédez à la page Instances de Spanner dans la consoleGoogle Cloud .
Cliquez sur le nom de l'instance associée à la requête que vous souhaitez examiner.
Dans le tableau "Databases" (Bases de données), cliquez sur la base de données contenant la requête que vous souhaitez examiner.
Dans le menu de navigation, cliquez sur Spanner Studio.
Ouvrez un nouvel onglet en cliquant sur Nouvel onglet d'éditeur SQL ou Nouvel onglet.
Lorsque l'éditeur de requête s'affiche, rédigez votre requête.
Cliquez sur Exécuter.
Spanner exécute la requête et affiche les résultats.
Cliquez sur l'onglet Explanation (Explication) sous l'éditeur de requête.
Spanner affiche un outil de visualisation du plan d'exécution des requêtes. Chaque fiche du graphique représente un itérateur.
Cliquez sur la fiche de l'itérateur Analyse de la table pour ouvrir un panneau d'informations.
Le panneau d'informations affiche des informations contextuelles sur l'analyse sélectionnée. La méthode de numérisation est indiquée sur cette fiche. Automatic (Automatique) indique que Spanner détermine la méthode d'analyse. Les autres valeurs possibles sont Batch (Traitement par lot) pour le traitement orienté par lot et Row (Ligne) pour le traitement orienté par ligne.
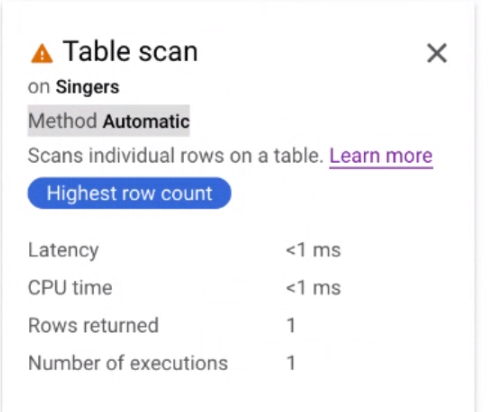
Appliquer la méthode d'analyse utilisée par une requête
Pour optimiser les performances des requêtes, Spanner choisit la méthode d'analyse optimale pour votre requête. Nous vous recommandons d'utiliser cette méthode d'analyse par défaut. Toutefois, il peut arriver que vous souhaitiez appliquer un type de méthode d'analyse spécifique.
Appliquer l'analyse par lot
Vous pouvez appliquer l'analyse orientée par lot au niveau de la table et de l'instruction.
Pour appliquer la méthode d'analyse orientée par lot au niveau de la table, utilisez un indice de table dans votre requête:
GoogleSQL
SELECT ...
FROM (t1@{SCAN_METHOD=BATCH} JOIN t2 ON ...)
WHERE ...
PostgreSQL
SELECT ...
FROM (t1/*@ scan_method=batch */ JOIN t2 on ...)
WHERE ...
Pour appliquer la méthode d'analyse orientée par lot au niveau de l'instruction, utilisez un indice d'instruction dans votre requête:
GoogleSQL
@{SCAN_METHOD=BATCH}
SELECT ...
FROM ...
WHERE ...
PostgreSQL
/*@ scan_method=batch */
SELECT ...
FROM ...
WHERE ...
Désactiver l'analyse automatique et appliquer l'analyse orientée lignes
Bien que nous ne recommandions pas de désactiver la méthode d'analyse automatique définie par Spanner, vous pouvez décider de la désactiver et d'utiliser la méthode d'analyse orientée ligne à des fins de dépannage, par exemple pour diagnostiquer la latence.
Pour désactiver la méthode d'analyse automatique et appliquer le traitement des lignes au niveau de la table, utilisez un indice de table dans votre requête:
GoogleSQL
SELECT ...
FROM (t1@{SCAN_METHOD=ROW} JOIN t2 ON ...)
WHERE ...
PostgreSQL
SELECT ...
FROM (t1/*@ scan_method=row */ JOIN t2 on ...)
WHERE ...
Pour désactiver la méthode d'analyse automatique et appliquer le traitement des lignes au niveau de l'instruction, utilisez un indice d'instruction dans votre requête:
GoogleSQL
@{SCAN_METHOD=ROW}
SELECT ...
FROM ...
WHERE ...
PostgreSQL
/*@ scan_method=row */
SELECT ...
FROM ...
WHERE ...
Optimiser l'exécution des requêtes
En plus d'optimiser les analyses, vous pouvez également optimiser l'exécution des requêtes en appliquant la méthode d'exécution au niveau de l'instruction. Cette méthode ne fonctionne que pour certains opérateurs et est indépendante de la méthode d'analyse, qui n'est utilisée que par l'opérateur d'analyse.
Par défaut, la plupart des opérateurs s'exécutent à l'aide de la méthode orientée ligne, qui traite les données une ligne à la fois. Les opérateurs vectorisés s'exécutent dans la méthode orientée par lot pour améliorer le débit et les performances d'exécution. Ces opérateurs traitent les données un bloc à la fois. Lorsqu'un opérateur doit traiter de nombreuses lignes, la méthode d'exécution orientée par lot est généralement plus efficace.
Méthode d'exécution par rapport à la méthode d'exploration
La méthode d'exécution des requêtes est indépendante de la méthode d'analyse des requêtes. Vous pouvez définir une ou les deux de ces méthodes, ou aucune d'entre elles dans votre indice de requête.
La méthode d'exécution des requêtes fait référence à la manière dont les opérateurs de requêtes traitent les résultats intermédiaires et à la manière dont les opérateurs interagissent les uns avec les autres, tandis que la méthode d'analyse fait référence à la manière dont l'opérateur d'analyse interagit avec la couche de stockage de Spanner.
Appliquer la méthode d'exécution utilisée par la requête
Pour optimiser les performances des requêtes, Spanner choisit la méthode d'exécution optimale pour votre requête en fonction de diverses heuristiques. Nous vous recommandons d'utiliser cette méthode d'exécution par défaut. Toutefois, il peut arriver que vous souhaitiez appliquer un type de méthode d'exécution spécifique.
Vous pouvez appliquer votre méthode d'exécution au niveau de l'instruction. EXECUTION_METHOD est un indice de requête plutôt qu'une directive. En fin de compte, l'optimiseur de requêtes décide de la méthode à utiliser pour chaque opérateur.
Pour appliquer la méthode d'exécution orientée par lot au niveau de l'instruction, utilisez un indice d'instruction dans votre requête:
GoogleSQL
@{EXECUTION_METHOD=BATCH}
SELECT ...
FROM ...
WHERE ...
PostgreSQL
/*@ execution_method=batch */
SELECT ...
FROM ...
WHERE ...
Bien que nous ne recommandions pas de désactiver la méthode d'exécution automatique définie par Spanner, vous pouvez décider de la désactiver et d'utiliser la méthode d'exécution orientée lignes à des fins de dépannage, par exemple pour diagnostiquer la latence.
Pour désactiver la méthode d'exécution automatique et appliquer la méthode d'exécution orientée lignes au niveau de l'instruction, utilisez un indice d'instruction dans votre requête:
GoogleSQL
@{EXECUTION_METHOD=ROW}
SELECT ...
FROM ...
WHERE ...
PostgreSQL
/*@ execution_method=row */
SELECT ...
FROM ...
WHERE ...
Vérifier quelle méthode d'exécution est activée
Tous les opérateurs Spanner ne sont pas compatibles avec les méthodes d'exécution orientées par lot et par ligne. Pour chaque opérateur, l'outil de visualisation du plan d'exécution de requête affiche la méthode d'exécution dans la fiche de l'itérateur. Si la méthode d'exécution est orientée par lots, l'option Batch (Lot) s'affiche. Si l'orientation est en ligne, l'option Ligne s'affiche.
Si les opérateurs de votre requête s'exécutent à l'aide de différentes méthodes d'exécution, les adaptateurs de méthode d'exécution DataBlockToRowAdapter et RowToDataBlockAdapter s'affichent entre les opérateurs pour indiquer le changement de méthode d'exécution.
Optimiser les recherches de clés de plage
Une requête SQL est couramment utilisée pour lire plusieurs lignes à partir de Spanner en fonction d'une liste de clés connues.
Les bonnes pratiques suivantes vous aident à écrire des requêtes efficaces lors de l'extraction de données à l'aide d'une plage de clés:
Si la liste de clés est fragmentée et non adjacente, utilisez les paramètres de requête et
UNNESTpour créer votre requête.Par exemple, si votre liste de clés correspond à
{1, 5, 1000}, écrivez la requête de la manière suivante :GoogleSQL
SELECT * FROM Table AS t WHERE t.Key IN UNNEST (@KeyList)
PostgreSQL
SELECT * FROM Table AS t WHERE t.Key IN UNNEST ($1)
Remarques :
L'opérateur de tableau UNNEST aplatit un tableau d'entrée sous la forme de lignes d'éléments.
Le paramètre de requête, qui est
@KeyListpour GoogleSQL et$1pour PostgreSQL, peut accélérer votre requête, comme indiqué dans la bonne pratique précédente.
Si la liste de clés est adjacente et comprise dans une plage, spécifiez les limites inférieure et supérieure de la plage de clés dans la clause
WHERE.Par exemple, si votre liste de clés correspond à
{1,2,3,4,5}, créez la requête comme suit:GoogleSQL
SELECT * FROM Table AS t WHERE t.Key BETWEEN @min AND @max
PostgreSQL
SELECT * FROM Table AS t WHERE t.Key BETWEEN $1 AND $2
Cette requête n'est plus efficace que si les clés de la plage de clés sont adjacentes. En d'autres termes, si votre liste de clés correspond à
{1, 5, 1000}, ne spécifiez pas les limites inférieure et supérieure comme dans la requête précédente, car la requête résultante risque d'analyser toutes les valeurs comprises entre 1 et 1 000.
Optimiser les jointures
Les opérations de jointure peuvent être coûteuses, car elles peuvent augmenter considérablement le nombre de lignes que votre requête doit analyser, ce qui la ralentit. Outre les techniques que vous êtes habitué à utiliser dans d'autres bases de données relationnelles pour optimiser les requêtes de jointure, voici quelques bonnes pratiques pour une opération JOIN plus efficace lors de l'utilisation de Spanner SQL:
Si possible, joignez des données dans des tables entrelacées par clé primaire. Exemple :
SELECT s.FirstName, a.ReleaseDate FROM Singers AS s JOIN Albums AS a ON s.SingerId = a.SingerId;
Vous avez la garantie que les lignes de la table entrelacée
Albumssont physiquement stockées dans les mêmes divisions que la ligne parente dansSingers, comme indiqué sur la page Schéma et modèle de données. Par conséquent, les jointures peuvent être effectuées localement sans envoyer énormément de données sur le réseau.Utilisez la directive de jointure si vous souhaitez définir un certain ordre pour la jointure. Exemple :
GoogleSQL
SELECT * FROM Singers AS s JOIN@{FORCE_JOIN_ORDER=TRUE} Albums AS a ON s.SingerId = a.Singerid WHERE s.LastName LIKE '%x%' AND a.AlbumTitle LIKE '%love%';
PostgreSQL
SELECT * FROM Singers AS s JOIN/*@ FORCE_JOIN_ORDER=TRUE */ Albums AS a ON s.SingerId = a.Singerid WHERE s.LastName LIKE '%x%' AND a.AlbumTitle LIKE '%love%';
La directive de jointure
FORCE_JOIN_ORDERindique à Spanner d'utiliser l'ordre de jointure spécifié dans la requête (c'est-à-direSingers JOIN Albums, pasAlbums JOIN Singers). Les résultats renvoyés sont les mêmes, quel que soit l'ordre choisi par Spanner. Toutefois, vous pouvez utiliser cette directive de jointure si vous remarquez dans le plan de requête que Spanner a modifié l'ordre de jointure et a entraîné des conséquences indésirables, telles que des résultats intermédiaires plus importants, ou des occasions manquées de recherche de lignes.Utilisez une directive de jointure pour choisir une mise en œuvre de jointure. Lorsque vous utilisez SQL pour interroger plusieurs tables, Spanner utilise automatiquement une méthode de jointure susceptible d'améliorer l'efficacité de la requête. Cependant, Google vous recommande de tester différents algorithmes de jointure. Le choix du bon algorithme de jointure peut améliorer la latence, la consommation de mémoire ou les deux. Cette requête illustre la syntaxe d'une directive JOIN avec l'indice
JOIN_METHODpour choisir uneHASH JOIN:GoogleSQL
SELECT * FROM Singers s JOIN@{JOIN_METHOD=HASH_JOIN} Albums AS a ON a.SingerId = a.SingerId
PostgreSQL
SELECT * FROM Singers s JOIN/*@ JOIN_METHOD=HASH_JOIN */ Albums AS a ON a.SingerId = a.SingerId
Si vous utilisez une
HASH JOINou uneAPPLY JOINet que vous avez une clauseWHEREtrès sélective d'un côté de votreJOIN, placez la table qui produit le plus petit nombre de lignes comme première table de la clauseFROMde la jointure. Cette structure est utile, car dansHASH JOIN, Spanner choisit toujours la table latérale gauche pour effectuer des compilations et la table latérale droite pour effectuer des vérifications. De même, pourAPPLY JOIN, Spanner choisit la table du côté gauche comme table externe et celle du côté droit comme table interne. Pour en savoir plus sur ces types de jointure, consultez les sections Jointure de hachage et Jointure d'application.Pour les requêtes critiques pour votre charge de travail, spécifiez la méthode de jointure et l'ordre de jointure les plus performants dans vos instructions SQL afin d'obtenir des performances plus cohérentes.
Optimiser les requêtes avec le pushdown de prédicat de code temporel
Le pushdown de prédicat de code temporel est une technique d'optimisation des requêtes utilisée dans Spanner pour améliorer l'efficacité des requêtes qui utilisent des codes temporels et des données avec une stratégie de stockage en niveaux basée sur l'âge. Lorsque vous activez cette optimisation, les opérations de filtrage sur les colonnes de code temporel sont effectuées dès que possible dans le plan d'exécution des requêtes. Cela peut réduire considérablement la quantité de données traitées et améliorer les performances globales des requêtes.
Avec le pushdown de prédicat de code temporel, le moteur de base de données analyse la requête et identifie le filtre de code temporel. Il "transfère" ensuite ce filtre vers la couche de stockage, de sorte que seules les données pertinentes en fonction des critères de code temporel soient lues à partir du SSD. Cela réduit la quantité de données traitées et transférées, ce qui accélère l'exécution des requêtes.
Pour optimiser les requêtes afin qu'elles n'accèdent qu'aux données stockées sur le SSD, les conditions suivantes doivent s'appliquer:
- Le pushdown du prédicat de code temporel doit être activé pour la requête. Pour en savoir plus, consultez les pages Indices d'instruction GoogleSQL et Indices d'instruction PostgreSQL.
- La requête doit utiliser une restriction basée sur l'âge égale ou inférieure à l'âge spécifié dans la stratégie de vidage des données (définie avec l'option
ssd_to_hdd_spill_timespandans l'instruction DDLCREATE LOCALITY GROUPouALTER LOCALITY GROUP). Pour en savoir plus, consultez les sections InstructionsLOCALITY GROUPGoogleSQL et InstructionsLOCALITY GROUPPostgreSQL. La colonne filtrée dans la requête doit être une colonne d'horodatage contenant l'horodatage de commit. Pour savoir comment créer une colonne de code temporel de commit, consultez les pages Code temporel de commit dans GoogleSQL et Code temporel de commit dans PostgreSQL. Ces colonnes doivent être mises à jour avec la colonne de code temporel et se trouver dans le même groupe de localité, qui dispose d'une stratégie de stockage en niveaux basée sur l'âge.
Si, pour une ligne donnée, certaines des colonnes interrogées se trouvent sur un SSD et d'autres sur un disque dur (en raison de la mise à jour des colonnes à des moments différents et de leur vieillissement sur le disque dur à des moments différents), les performances de la requête peuvent être moins bonnes lorsque vous utilisez l'indice. En effet, la requête doit renseigner les données des différentes couches de stockage. En raison de l'utilisation de l'indice, Spanner gère l'âge des données au niveau de chaque cellule (niveau de granularité de ligne et de colonne) en fonction du code temporel de validation de chaque cellule, ce qui ralentit la requête. Pour éviter ce problème, veillez à mettre à jour régulièrement toutes les colonnes interrogées à l'aide de cette technique d'optimisation dans la même transaction afin que toutes les colonnes partagent le même code temporel de validation et bénéficient de l'optimisation.
Pour activer le pushdown de prédicat de code temporel au niveau de l'instruction, utilisez un indice d'instruction dans votre requête. Exemple :
GoogleSQL
@{allow_timestamp_predicate_pushdown=TRUE}
SELECT s.SingerInfo
FROM Singers s
WHERE s.ModificationTime > TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 12 HOUR);
PostgreSQL
/*@allow_timestamp_predicate_pushdown=TRUE*/
SELECT s.SingerInfo
FROM Singers s
WHERE s.ModificationTime > CURRENT_TIMESTAMP - INTERVAL '12 hours';
Éviter les opérations de lecture de grande taille dans les transactions en lecture-écriture
Les transactions en lecture-écriture autorisent une séquence de zéro ou plusieurs lectures ou requêtes SQL et peuvent inclure un ensemble de mutations avant un appel à validation. Pour maintenir la cohérence de vos données, Spanner acquiert des verrous lors de la lecture et de l'écriture de lignes dans vos tables et index. Pour en savoir plus sur le verrouillage, consultez la section Déroulement des opérations de lecture et d'écriture.
En raison du fonctionnement du verrouillage dans Spanner, exécuter une requête de lecture ou une requête SQL lisant un grand nombre de lignes (par exemple, SELECT * FROM Singers) signifie qu'aucune autre transaction ne peut écrire sur les lignes que vous avez lues tant que votre transaction n'est pas validée ou abandonnée.
De plus, comme votre transaction traite un grand nombre de lignes, elle risque de prendre plus de temps qu'une transaction qui lit une plus petite plage de lignes (par exemple SELECT LastName FROM Singers WHERE SingerId = 7), ce qui accentue le problème et ralentit le débit du système.
Essayez donc d'éviter les opérations de lecture de grande taille (par exemple, les analyses de table complète ou les très grandes opérations de jointure) dans vos transactions, sauf si vous êtes prêt à accepter un débit d'écriture inférieur.
Dans certains cas, le modèle suivant peut donner de meilleurs résultats:
- Exécutez vos opérations de lecture de grande taille dans une transaction en lecture seule. Les transactions en lecture seule permettent un débit global plus élevé, car elles n'utilisent pas de verrous.
- Facultatif: effectuez le traitement requis sur les données que vous venez de lire.
- Démarrez une transaction en lecture-écriture.
- Vérifiez que les lignes critiques n'ont pas changé de valeur depuis que vous avez effectué la transaction en lecture seule à l'étape 1.
- Si les lignes ont changé, annulez votre transaction et recommencez à l'étape 1.
- Si tout se passe bien, validez vos mutations.
Pour éviter les opérations de lecture de grande taille dans les transactions en lecture-écriture, vous pouvez entre autres examiner les plans d'exécution générés par vos requêtes.
Utiliser ORDER BY pour garantir le classement de vos résultats SQL
Si vous souhaitez que les résultats d'une requête SELECT soient classés d'une certaine façon, incluez explicitement la clause ORDER BY. Par exemple, si vous voulez répertorier tous les chanteurs par ordre de clé primaire, utilisez la requête suivante:
SELECT * FROM Singers
ORDER BY SingerId;
Spanner ne garantit le classement des résultats que si la clause ORDER BY est présente dans la requête. En d'autres termes, considérez la requête suivante sans ORDER
BY :
SELECT * FROM Singers;
Spanner ne garantit pas que les résultats de cette requête seront renvoyés par ordre de clé primaire. De plus, l'ordre des résultats peut changer à tout moment et ce classement n'est pas garanti d'un appel à l'autre. Si une requête comporte une clause ORDER BY et que Spanner utilise un indice qui fournit l'ordre requis, Spanner ne trie pas explicitement les données. Par conséquent, ne vous souciez pas de l'impact sur les performances de l'inclusion de cette clause. Vous pouvez vérifier si une opération de tri explicite est incluse dans l'exécution en examinant le plan de requête.
Utiliser STARTS_WITH au lieu de LIKE
Comme Spanner n'évalue pas les modèles LIKE paramétrés avant l'exécution, il doit lire toutes les lignes et les évaluer par rapport à l'expression LIKE afin d'exclure celles qui ne correspondent pas.
Lorsqu'un modèle LIKE a la forme foo% (par exemple, il commence par une chaîne fixe et se termine par un seul caractère générique en pourcentage) et que la colonne est indexée, utilisez STARTS_WITH au lieu de LIKE. Cette option permet à Spanner d'optimiser plus efficacement le plan d'exécution des requêtes.
Option déconseillée :
GoogleSQL
SELECT a.AlbumTitle FROM Albums a WHERE a.AlbumTitle LIKE @like_clause;
PostgreSQL
SELECT a.AlbumTitle FROM Albums a WHERE a.AlbumTitle LIKE $1;
Recommandations:
GoogleSQL
SELECT a.AlbumTitle FROM Albums a WHERE STARTS_WITH(a.AlbumTitle, @prefix);
PostgreSQL
SELECT a.AlbumTitle FROM Albums a WHERE STARTS_WITH(a.AlbumTitle, $2);
Utiliser des horodatages de validation
Si votre application doit interroger les données écrites après un certain moment, ajoutez des colonnes d'horodatage de validation aux tables concernées. Les codes temporels de validation permettent une optimisation Spanner qui peut réduire les E/S des requêtes dont les clauses WHERE limitent les résultats aux lignes écrites plus récemment qu'une heure spécifique.
En savoir plus sur cette optimisation avec des bases de données au format GoogleSQL ou avec des bases de données au format PostgreSQL