Dans une base de données Spanner, Spanner crée automatiquement un index pour la clé primaire de chaque table. Par exemple, vous n'avez rien à faire pour indexer la clé primaire de Singers, car elle est indexée automatiquement pour vous.
Vous pouvez également créer des index secondaires pour d'autres colonnes. L'ajout d'un index secondaire sur une colonne facilite la recherche des données dans cette colonne. Par exemple, si vous devez rechercher rapidement un album par titre, créez un index secondaire sur AlbumTitle. Ainsi, Spanner n'a pas besoin d'analyser l'ensemble de la table.
Si la recherche de l'exemple précédent est effectuée au cours d'une transaction en lecture/écriture, pour plus d'efficacité, elle évite également de verrouiller la table entière, ce qui permet des insertions et des mises à jour simultanées dans la table pour les lignes en dehors de la plage de recherche AlbumTitle.
En plus des avantages qu'ils apportent aux recherches, les index secondaires peuvent également aider Spanner à exécuter des analyses plus efficacement, en permettant des analyses d'index plutôt que des analyses de table complète.
Spanner stocke les données suivantes dans chaque index secondaire :
- toutes les colonnes clés de la table de base ;
- toutes les colonnes incluses dans l'index ;
- Toutes les colonnes spécifiées dans la clause facultative
STORING(bases de données avec dialecte GoogleSQL) ouINCLUDE(bases de données avec dialecte PostgreSQL) de la définition de l'index.
Au fil du temps, Spanner analyse vos tables pour s'assurer que vos index secondaires sont utilisés pour les requêtes appropriées.
Ajouter un index secondaire
Le moment le plus efficace pour ajouter un index secondaire est lors de la création de la table. Pour créer une table et ses index en même temps, envoyez les instructions LDD pour la nouvelle table et les nouveaux index dans une seule requête à Spanner.
Dans Spanner, vous pouvez également ajouter un index secondaire à une table existante pendant que la base de données continue de diffuser du trafic. Comme toute autre modification de schéma dans Spanner, l'ajout d'un index à une base de données existante ne nécessite pas de mettre cette base de données hors connexion et n'entraîne pas le verrouillage de colonnes ou de tables entières.
Chaque fois qu'un nouvel index est ajouté à une table existante, Spanner remplit automatiquement ou renseigne l'index pour afficher une vue à jour des données indexées. Spanner gère ce processus de remplissage à votre place. Il s'exécute en arrière-plan à l'aide de ressources de nœud à faible priorité. La vitesse de remplissage de l'index s'adapte à l'évolution des ressources des nœuds lors de la création de l'index. Le remplissage n'a pas d'incidence significative sur les performances de la base de données.
La création d'un index peut prendre de quelques minutes à plusieurs heures. La création d'index étant une mise à jour du schéma, elle est soumise aux mêmes contraintes de performances que toute autre mise à jour de schéma. Le temps nécessaire à la création d'un index secondaire dépend de plusieurs facteurs :
- Taille de l'ensemble de données
- La capacité de calcul de l'instance
- La charge sur l'instance
Pour afficher la progression d'un processus de remplissage de l'index, consultez la section sur la progression.
Notez que l'utilisation de la colonne commit timestamp en tant que première partie de l'index secondaire peut créer des hotspots et réduire les performances en écriture.
Utilisez l'instruction CREATE INDEX pour définir un index secondaire dans votre schéma. Voici quelques exemples :
Pour indexer tous les chanteurs (Singers) de la base de données par leur prénom et leur nom :
GoogleSQL
CREATE INDEX SingersByFirstLastName ON Singers(FirstName, LastName);
PostgreSQL
CREATE INDEX SingersByFirstLastName ON Singers(FirstName, LastName);
Pour créer un index de tous les titres (Songs) de la base de données selon la valeur SongName :
GoogleSQL
CREATE INDEX SongsBySongName ON Songs(SongName);
PostgreSQL
CREATE INDEX SongsBySongName ON Songs(SongName);
Pour n'indexer que les titres d'un chanteur particulier, entrelacez l'index dans la table Singers à l'aide de la clause INTERLEAVE IN :
GoogleSQL
CREATE INDEX SongsBySingerSongName ON Songs(SingerId, SongName),
INTERLEAVE IN Singers;
PostgreSQL
CREATE INDEX SongsBySingerSongName ON Songs(SingerId, SongName)
INTERLEAVE IN Singers;
Pour n'indexer que les titres d'un album particulier :
GoogleSQL
CREATE INDEX SongsBySingerAlbumSongName ON Songs(SingerId, AlbumId, SongName),
INTERLEAVE IN Albums;
PostgreSQL
CREATE INDEX SongsBySingerAlbumSongName ON Songs(SingerId, AlbumId, SongName)
INTERLEAVE IN Albums;
Pour indexer par ordre décroissant de SongName :
GoogleSQL
CREATE INDEX SongsBySingerAlbumSongNameDesc ON Songs(SingerId, AlbumId, SongName DESC),
INTERLEAVE IN Albums;
PostgreSQL
CREATE INDEX SongsBySingerAlbumSongNameDesc ON Songs(SingerId, AlbumId, SongName DESC)
INTERLEAVE IN Albums;
Notez que l'annotation DESC précédente ne s'applique qu'à SongName. Pour indexer par ordre décroissant d'autres clés d'index, annotez-les avec DESC : SingerId DESC, AlbumId DESC.
Notez également que PRIMARY_KEY est un mot réservé ne pouvant pas être utilisé comme nom d'index. Il s'agit du nom donné à l'index pseudo-index établi lors de la création d'une table avec la spécification PRIMARY KEY.
Pour plus de détails et de bonnes pratiques concernant le choix des index non entrelacés et des index entrelacés, consultez les sections Options d'index et Utiliser un index entrelacé sur une colonne dont la valeur augmente ou diminue de façon linéaire.
Index et entrelacement
Les index Spanner peuvent être entrelacés avec d'autres tables afin de colocaliser les lignes d'index avec celles d'une autre table. Comme pour l'entrelacement de tables Spanner, les colonnes de clé primaire du parent de l'index doivent être un préfixe des colonnes indexées, avec le même type et le même ordre de tri. Contrairement aux tables entrelacées, la correspondance des noms de colonnes n'est pas requise. Chaque ligne d'un index entrelacé est stockée physiquement avec la ligne parente associée.
Par exemple, considérons le schéma suivant :
CREATE TABLE Singers (
SingerId INT64 NOT NULL,
FirstName STRING(1024),
LastName STRING(1024),
SingerInfo PROTO<Singer>(MAX)
) PRIMARY KEY (SingerId);
CREATE TABLE Albums (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
AlbumTitle STRING(MAX),
PublisherId INT64 NOT NULL
) PRIMARY KEY (SingerId, AlbumId),
INTERLEAVE IN PARENT Singers ON DELETE CASCADE;
CREATE TABLE Songs (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
TrackId INT64 NOT NULL,
PublisherId INT64 NOT NULL,
SongName STRING(MAX)
) PRIMARY KEY (SingerId, AlbumId, TrackId),
INTERLEAVE IN PARENT Albums ON DELETE CASCADE;
CREATE TABLE Publishers (
Id INT64 NOT NULL,
PublisherName STRING(MAX)
) PRIMARY KEY (Id);
Pour indexer tous les Singers de la base de données par leur prénom et leur nom, vous devez créer un index. Voici comment définir l'index SingersByFirstLastName :
CREATE INDEX SingersByFirstLastName ON Singers(FirstName, LastName);
Si vous souhaitez créer un index de Songs sur (SingerId, AlbumId, SongName), vous pouvez procéder comme suit :
CREATE INDEX SongsBySingerAlbumSongName
ON Songs(SingerId, AlbumId, SongName);
Vous pouvez également créer un index entrelacé avec un ancêtre de Songs, comme suit :
CREATE INDEX SongsBySingerAlbumSongName
ON Songs(SingerId, AlbumId, SongName),
INTERLEAVE IN Albums;
Vous pouvez également créer un index de Songs sur (PublisherId, SingerId, AlbumId, SongName) qui est entrelacé avec une table qui n'est pas un ancêtre de Songs, comme Publishers. Notez que la clé primaire de la table Publishers (id) n'est pas un préfixe des colonnes indexées dans l'exemple suivant. Cela reste autorisé, car Publishers.Id et Songs.PublisherId partagent le même type, le même ordre de tri et la même possibilité de valeur nulle.
CREATE INDEX SongsByPublisherSingerAlbumSongName
ON Songs(PublisherId, SingerId, AlbumId, SongName),
INTERLEAVE IN Publishers;
Vérifier la progression du remplissage de l'index
Console
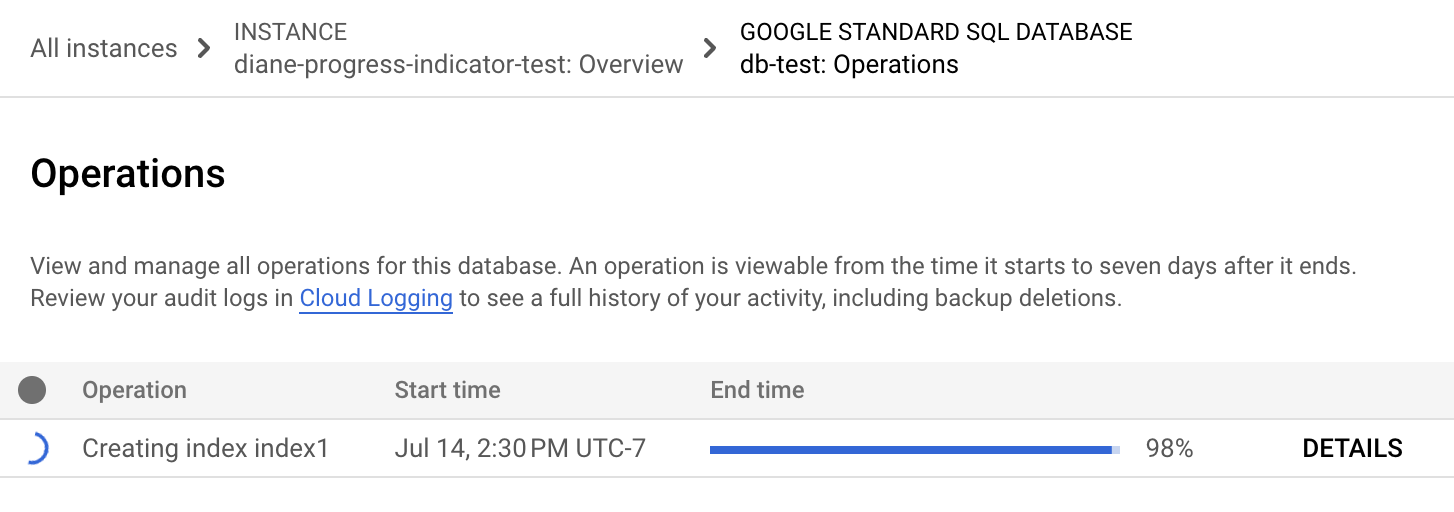
Dans le menu de navigation Spanner, cliquez sur l'onglet Opérations. La page Opérations affiche la liste des opérations en cours.
Recherchez l'opération de remplissage dans la liste. S'il est toujours en cours d'exécution, l'indicateur de progression dans la colonne Heure de fin indique le pourcentage de l'opération qui est terminé, comme illustré dans l'image suivante :
gcloud
Utilisez gcloud spanner operations describe pour vérifier la progression d'une opération.
Obtenez l'ID de l'opération :
gcloud spanner operations list --instance=INSTANCE-NAME \ --database=DATABASE-NAME --type=DATABASE_UPDATE_DDL
Remplacez les éléments suivants :
- INSTANCE-NAME par le nom de l'instance Spanner.
- DATABASE-NAME par le nom de la base de données.
Remarques concernant l'utilisation :
Pour limiter la liste, spécifiez l'option
--filter. Exemple :--filter="metadata.name:example-db"ne répertorie que les opérations sur une base de données spécifique.--filter="error:*"ne répertorie que les opérations de sauvegarde ayant échoué.
Pour en savoir plus sur la syntaxe des filtres, consultez la page gcloud topic filters. Pour en savoir plus sur le filtrage des opérations de sauvegarde, consultez le champ
filterdans ListBackupOperationsRequest.L'option
--typen'est pas sensible à la casse.
La sortie ressemble à ceci :
OPERATION_ID STATEMENTS DONE @TYPE _auto_op_123456 CREATE INDEX SingersByFirstLastName ON Singers(FirstName, LastName) False UpdateDatabaseDdlMetadata CREATE INDEX SongsBySingerAlbumSongName ON Songs(SingerId, AlbumId, SongName), INTERLEAVE IN Albums _auto_op_234567 True CreateDatabaseMetadataExécuter
gcloud spanner operations describegcloud spanner operations describe \ --instance=INSTANCE-NAME \ --database=DATABASE-NAME \ projects/PROJECT-NAME/instances/INSTANCE-NAME/databases/DATABASE-NAME/operations/OPERATION_ID
Remplacez les éléments suivants :
- INSTANCE-NAME : nom de l'instance Spanner.
- DATABASE-NAME : nom de la base de données Spanner.
- PROJECT-NAME : nom du projet.
- OPERATION-ID : ID de l'opération que vous souhaitez vérifier.
La section
progressde la sortie indique le pourcentage d'achèvement de l'opération. La sortie ressemble à ceci :done: true ... progress: - endTime: '2021-01-22T21:58:42.912540Z' progressPercent: 100 startTime: '2021-01-22T21:58:11.053996Z' - progressPercent: 67 startTime: '2021-01-22T21:58:11.053996Z' ...
REST v1
Obtenez l'ID de l'opération :
gcloud spanner operations list --instance=INSTANCE-NAME
--database=DATABASE-NAME --type=DATABASE_UPDATE_DDL
Remplacez les éléments suivants :
- INSTANCE-NAME par le nom de l'instance Spanner.
- DATABASE-NAME par le nom de la base de données.
Avant d'utiliser les données de requête ci-dessous, effectuez les remplacements suivants :
- PROJECT-ID : ID du projet.
- INSTANCE-ID : ID de l'instance.
- DATABASE-ID : ID de la base de données.
- OPERATION-ID : ID de l'opération.
Méthode HTTP et URL :
GET https://spanner.googleapis.com/v1/projects/PROJECT-ID/instances/INSTANCE-ID/databases/DATABASE-ID/operations/OPERATION-ID
Pour envoyer votre requête, développez l'une des options suivantes :
Vous devriez recevoir une réponse JSON de ce type :
{
...
"progress": [
{
"progressPercent": 100,
"startTime": "2023-05-27T00:52:27.366688Z",
"endTime": "2023-05-27T00:52:30.184845Z"
},
{
"progressPercent": 100,
"startTime": "2023-05-27T00:52:30.184845Z",
"endTime": "2023-05-27T00:52:40.750959Z"
}
],
...
"done": true,
"response": {
"@type": "type.googleapis.com/google.protobuf.Empty"
}
}
Pour gcloud et REST, vous pouvez suivre la progression de chaque instruction de remplissage de l'index dans la section progress. Pour chaque instruction du tableau d'instructions, il existe un champ correspondant dans le tableau de progression. L'ordre de ce tableau de progression correspond à l'ordre du tableau d'instructions. Une fois disponibles, les champs startTime, progressPercent et endTime sont renseignés en conséquence.
Notez que le résultat n'indique pas d'estimation du temps nécessaire pour que la progression du remplissage soit terminée.
Si l'opération prend trop de temps, vous pouvez l'annuler. Pour en savoir plus, consultez Annuler la création d'un index.
Scénarios d'affichage de la progression du remplissage de l'index
Différents scénarios peuvent se produire lorsque vous essayez de vérifier la progression d'un remplissage de l'index. Les instructions de création d'index qui nécessitent un remplissage d'index font partie des opérations de mise à jour du schéma. Une opération de mise à jour du schéma peut comporter plusieurs instructions.
Le premier scénario est le plus simple : l'instruction de création d'index est la première instruction de l'opération de mise à jour du schéma. Comme l'instruction de création d'index est la première instruction, elle est la première à être traitée et exécutée en raison de l'ordre d'exécution.
Le champ startTime de l'instruction de création d'index sera immédiatement renseigné avec l'heure de début de l'opération de mise à jour du schéma. Ensuite, le champ progressPercent de l'instruction de création d'index est renseigné lorsque la progression du remplissage de l'index est supérieure à 0 %. Enfin, le champ endTime est renseigné une fois l'instruction validée.
Le deuxième scénario se produit lorsque l'instruction de création d'index n'est pas la première instruction de l'opération de mise à jour du schéma. Aucun champ lié à l'instruction de création d'index ne sera renseigné tant que les instructions précédentes n'auront pas été validées en raison de l'ordre d'exécution.
Comme dans le scénario précédent, une fois les instructions précédentes validées, le champ startTime de l'instruction de création d'index est renseigné en premier, suivi du champ progressPercent. Enfin, le champ endTime est renseigné une fois que l'instruction a fini d'être validée.
Annuler la création de l'index
Vous pouvez utiliser Google Cloud CLI pour annuler la création de l'index. Pour extraire la liste des opérations de mise à jour du schéma d'une base de données Spanner, utilisez la commande gcloud spanner operations list et ajoutez l'option --filter :
gcloud spanner operations list \
--instance=INSTANCE \
--database=DATABASE \
--filter="@TYPE:UpdateDatabaseDdlMetadata"
Recherchez le OPERATION_ID pour l'opération que vous souhaitez annuler, puis utilisez la commande gcloud spanner operations cancel pour l'annuler :
gcloud spanner operations cancel OPERATION_ID \
--instance=INSTANCE \
--database=DATABASE
Afficher les index existants
Pour afficher des informations sur des index existants dans une base de données, vous pouvez utiliser la consoleGoogle Cloud ou Google Cloud CLI :
Console
Accédez à la page Instances de Spanner dans la console Google Cloud .
Cliquez sur le nom de l'instance que vous souhaitez afficher.
Dans le volet de gauche, cliquez sur la base de données à afficher, puis sur la table que vous souhaitez consulter.
Cliquez sur l'onglet Index. La console Google Cloud affiche une liste d'index.
Facultatif : Pour obtenir des détails sur un index, par exemple les colonnes qu'il contient, cliquez sur le nom de l'index.
gcloud
Exécutez la commande gcloud spanner databases ddl describe :
gcloud spanner databases ddl describe DATABASE \
--instance=INSTANCE
Gcloud CLI affiche les instructions DDL (LDD Definition Language) pour créer les tables et les index de la base de données. Les instructions CREATE
INDEX décrivent les index existants. Exemple :
--- |-
CREATE TABLE Singers (
SingerId INT64 NOT NULL,
FirstName STRING(1024),
LastName STRING(1024),
SingerInfo BYTES(MAX),
) PRIMARY KEY(SingerId)
---
CREATE INDEX SingersByFirstLastName ON Singers(FirstName, LastName)
Effectuer une requête avec un index spécifique
Les sections suivantes expliquent comment spécifier un index dans une instruction SQL et avec l'interface de lecture pour Spanner. Les exemples de ces sections supposent que vous avez ajouté une colonne MarketingBudget à la table Albums et que vous avez créé un index appelé AlbumsByAlbumTitle :
GoogleSQL
CREATE TABLE Albums (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
AlbumTitle STRING(MAX),
MarketingBudget INT64,
) PRIMARY KEY (SingerId, AlbumId),
INTERLEAVE IN PARENT Singers ON DELETE CASCADE;
CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle);
PostgreSQL
CREATE TABLE Albums (
SingerId BIGINT NOT NULL,
AlbumId BIGINT NOT NULL,
AlbumTitle VARCHAR,
MarketingBudget BIGINT,
PRIMARY KEY (SingerId, AlbumId)
) INTERLEAVE IN PARENT Singers ON DELETE CASCADE;
CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle);
Spécifier un index dans une instruction SQL
Lorsque vous utilisez SQL pour interroger une table Spanner, Spanner utilise automatiquement tous les index susceptibles d'améliorer l'efficacité de la requête. Par conséquent, vous n'avez pas besoin de spécifier un index pour les requêtes SQL. Toutefois, pour les requêtes critiques pour votre charge de travail, Google vous conseille d'utiliser des directives FORCE_INDEX dans vos instructions SQL afin d'obtenir des performances plus cohérentes.
Dans certains cas, Spanner peut choisir un index qui entraîne une augmentation de la latence des requêtes. Si vous avez suivi la procédure de dépannage des régressions de performances et vérifié qu'il est judicieux d'essayer un autre index pour la requête, vous pouvez spécifier l'index.
Pour spécifier un index dans une instruction SQL, utilisez l'indication FORCE_INDEX pour fournir une directive d'index. Les directives d'index utilisent la syntaxe suivante :
GoogleSQL
FROM MyTable@{FORCE_INDEX=MyTableIndex}
PostgreSQL
FROM MyTable /*@ FORCE_INDEX = MyTableIndex */
Vous pouvez également utiliser une directive d'index pour indiquer à Spanner d'analyser la table de base au lieu d'utiliser un index :
GoogleSQL
FROM MyTable@{FORCE_INDEX=_BASE_TABLE}
PostgreSQL
FROM MyTable /*@ FORCE_INDEX = _BASE_TABLE */
Vous pouvez utiliser une directive d'index pour indiquer à Spanner d'analyser un index dans une table avec des schémas nommés :
GoogleSQL
FROM MyNamedSchema.MyTable@{FORCE_INDEX="MyNamedSchema.MyTableIndex"}
PostgreSQL
FROM MyTable /*@ FORCE_INDEX = MyTableIndex */
L'exemple suivant illustre une requête SQL qui spécifie un index :
GoogleSQL
SELECT AlbumId, AlbumTitle, MarketingBudget
FROM Albums@{FORCE_INDEX=AlbumsByAlbumTitle}
WHERE AlbumTitle >= "Aardvark" AND AlbumTitle < "Goo";
PostgreSQL
SELECT AlbumId, AlbumTitle, MarketingBudget
FROM Albums /*@ FORCE_INDEX = AlbumsByAlbumTitle */
WHERE AlbumTitle >= 'Aardvark' AND AlbumTitle < 'Goo';
Une directive d'index peut obliger le processeur de requêtes de Spanner à lire des colonnes supplémentaires requises par la requête, mais qui ne sont pas stockées dans l'index.
Le processeur de requêtes récupère ces colonnes en joignant l'index et la table de base. Pour éviter cette jointure supplémentaire, utilisez une clause STORING (bases de données de dialecte GoogleSQL) ou INCLUDE (bases de données de dialecte PostgreSQL) pour stocker les colonnes supplémentaires dans l'index.
Dans l'exemple précédent, la colonne MarketingBudget n'est pas stockée dans l'index, mais la requête SQL sélectionne cette colonne. Par conséquent, Spanner doit rechercher la colonne MarketingBudget dans la table de base, puis la joindre aux données de l'index pour renvoyer les résultats de la requête.
Spanner génère une erreur si la directive d'index présente l'un des problèmes suivants :
- L'index n'existe pas.
- L'index se trouve dans une autre table de base.
- Il manque une expression de filtrage
NULLobligatoire dans la requête pour un indexNULL_FILTERED.
Les exemples suivants montrent comment écrire et exécuter des requêtes qui récupèrent les valeurs de AlbumId, AlbumTitle et MarketingBudget à l'aide de l'index AlbumsByAlbumTitle :
C++
C#
Go
Java
Node.js
PHP
Python
Ruby
Spécifier un index dans l'interface de lecture
Lorsque vous utilisez l'interface de lecture pour Spanner et que vous souhaitez que Spanner utilise un index, vous devez spécifier l'index. L'interface de lecture ne sélectionne pas automatiquement l'index.
En outre, votre index doit contenir toutes les données qui apparaissent dans les résultats de la requête, à l'exception des colonnes qui font partie de la clé primaire. Cette restriction existe, car l'interface de lecture ne prend pas en charge les jointures entre l'index et la table de base. Si vous devez inclure d'autres colonnes dans les résultats de la requête, vous disposez de plusieurs options :
- Utilisez une clause
STORINGouINCLUDEpour stocker les colonnes supplémentaires dans l'index. - Effectuez une requête sans inclure les colonnes supplémentaires, puis utilisez les clés primaires pour envoyer une autre requête qui lit les colonnes supplémentaires.
Spanner renvoie les valeurs de l'index par ordre de tri croissant par clé d'index. Pour récupérer les valeurs dans l'ordre décroissant, procédez comme suit :
Ajoutez à la clé d'index l'annotation
DESC: Exemple :CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle DESC);L'annotation
DESCs'applique à une seule clé d'index. Si l'index comprend plusieurs clés et si vous souhaitez que les résultats de la requête apparaissent dans l'ordre décroissant en fonction de toutes les clés, ajoutez une annotationDESCpour chaque clé.Si la lecture spécifie une plage de clés, assurez-vous que la plage de clés est également dans l'ordre décroissant. En d'autres termes, la valeur de la clé de début doit être supérieure à la valeur de la clé de fin.
L'exemple suivant montre comment extraire les valeurs de AlbumId et AlbumTitle à l'aide de l'index AlbumsByAlbumTitle :
C++
C#
Go
Java
Node.js
PHP
Python
Ruby
Créer un index pour les analyses indexées uniquement
Si vous le souhaitez, vous pouvez utiliser la clause STORING (pour les bases de données de dialecte GoogleSQL) ou INCLUDE (pour les bases de données de dialecte PostgreSQL) pour stocker une copie d'une colonne dans l'index. Ce type d'index offre des avantages pour les requêtes et les appels en lecture utilisant l'index, au prix d'un stockage supplémentaire :
- Les requêtes SQL qui utilisent l'index et sélectionnent les colonnes stockées dans la clause
STORINGouINCLUDEne nécessitent pas de jointure supplémentaire à la table de base. - Les appels
read()qui utilisent l'index peuvent lire les colonnes stockées par la clauseSTORING/INCLUDE.
Supposons, par exemple, que vous ayez créé une autre version de AlbumsByAlbumTitle qui stocke une copie de la colonne MarketingBudget dans l'index (notez la clause STORING ou INCLUDE en gras) :
GoogleSQL
CREATE INDEX AlbumsByAlbumTitle2 ON Albums(AlbumTitle) STORING (MarketingBudget);
PostgreSQL
CREATE INDEX AlbumsByAlbumTitle2 ON Albums(AlbumTitle) INCLUDE (MarketingBudget);
Avec l'ancien index AlbumsByAlbumTitle, Spanner doit joindre l'index à la table de base, puis récupérer la colonne à partir de la table de base. Avec le nouvel index AlbumsByAlbumTitle2, Spanner lit la colonne directement à partir de l'index, ce qui est plus efficace.
Si vous utilisez l'interface de lecture au lieu de SQL, le nouvel index AlbumsByAlbumTitle2 vous permet également de lire directement la colonne MarketingBudget :
C++
C#
Go
Java
Node.js
PHP
Python
Ruby
Modifier un index
Vous pouvez utiliser l'instruction ALTER INDEX pour ajouter des colonnes à un index existant ou en supprimer. Cela peut mettre à jour la liste des colonnes définies par la clause STORING (bases de données de dialecte GoogleSQL) ou la clause INCLUDE (bases de données de dialecte PostgreSQL) lorsque vous créez l'index. Vous ne pouvez pas utiliser cette instruction pour ajouter ou supprimer des colonnes de la clé d'index. Par exemple, au lieu de créer un index AlbumsByAlbumTitle2, vous pouvez utiliser ALTER INDEX pour ajouter une colonne à AlbumsByAlbumTitle, comme illustré dans l'exemple suivant :
GoogleSQL
ALTER INDEX AlbumsByAlbumTitle ADD STORED COLUMN MarketingBudget
PostgreSQL
ALTER INDEX AlbumsByAlbumTitle ADD INCLUDE COLUMN MarketingBudget
Lorsque vous ajoutez une colonne à un index existant, Spanner utilise un processus de remplissage en arrière-plan. Tant que le remplissage est en cours, la colonne de l'index n'est pas lisible. Vous risquez donc de ne pas obtenir l'amélioration des performances attendue. Vous pouvez utiliser la commande gcloud spanner operations pour lister l'opération de longue durée et afficher son état.
Pour en savoir plus, consultez describe operation.
Vous pouvez également utiliser cancel operation pour annuler une opération en cours.
Une fois le remplissage terminé, Spanner ajoute la colonne à l'index. À mesure que l'index augmente, les requêtes qui l'utilisent peuvent être ralenties.
L'exemple suivant montre comment supprimer une colonne d'un index :
GoogleSQL
ALTER INDEX AlbumsByAlbumTitle DROP STORED COLUMN MarketingBudget
PostgreSQL
ALTER INDEX AlbumsByAlbumTitle DROP INCLUDE COLUMN MarketingBudget
Index des valeurs NULL
Par défaut, Spanner indexe les valeurs NULL. Par exemple, reprenez la définition de l'index SingersByFirstLastName dans la table Singers :
CREATE INDEX SingersByFirstLastName ON Singers(FirstName, LastName);
Toutes les lignes de Singers sont indexées même si FirstName et/ou LastName sont NULL.

Lorsque des valeurs NULL sont indexées, vous pouvez effectuer des requêtes SQL efficaces et effectuer des lectures sur des données incluant des valeurs NULL. Par exemple, utilisez cette instruction de requête SQL pour trouver tous les Singers avec un FirstName NULL :
GoogleSQL
SELECT s.SingerId, s.FirstName, s.LastName
FROM Singers@{FORCE_INDEX=SingersByFirstLastName} AS s
WHERE s.FirstName IS NULL;
PostgreSQL
SELECT s.SingerId, s.FirstName, s.LastName
FROM Singers /* @ FORCE_INDEX = SingersByFirstLastName */ AS s
WHERE s.FirstName IS NULL;
Ordre de tri pour les valeurs NULL
Spanner trie NULL comme la plus petite valeur pour un type donné. Pour une colonne dans l'ordre croissant (ASC), les valeurs NULL sont triées en premier. Pour une colonne dans l'ordre décroissant (DESC), les valeurs NULL sont triées en dernier.
Désactiver l'indexation des valeurs NULL
GoogleSQL
Pour désactiver l'indexation des valeurs NULL, ajoutez le mot clé NULL_FILTERED à la définition de l'index. Les index NULL_FILTERED sont particulièrement utiles pour l'indexation des colonnes partiellement remplies, dont la plupart des lignes contiennent une valeur NULL. Dans ces cas, l'index NULL_FILTERED peut être considérablement plus petit et plus simple à maintenir qu'un index normal qui inclut des valeurs NULL.
Voici une autre définition de SingersByFirstLastName qui n'indexe pas les valeurs NULL :
CREATE NULL_FILTERED INDEX SingersByFirstLastNameNoNulls
ON Singers(FirstName, LastName);
Le mot clé NULL_FILTERED s'applique à toutes les colonnes de la clé d'index. Vous ne pouvez pas spécifier le filtrage des valeurs NULL par colonne.
PostgreSQL
Pour filtrer les lignes comportant des valeurs nulles dans une ou plusieurs colonnes indexées, utilisez le prédicat WHERE COLUMN IS NOT NULL.
Les index filtrés sur les valeurs nulles sont particulièrement utiles pour l'indexation des colonnes partiellement remplies, dont la plupart des lignes contiennent une valeur NULL. Dans ces cas, l'index filtré sur les valeurs nulles peut être considérablement plus petit et plus simple à maintenir qu'un index normal qui inclut des valeurs NULL.
Voici une autre définition de SingersByFirstLastName qui n'indexe pas les valeurs NULL :
CREATE INDEX SingersByFirstLastNameNoNulls
ON Singers(FirstName, LastName)
WHERE FirstName IS NOT NULL
AND LastName IS NOT NULL;
Le filtrage des valeurs NULL empêche Spanner de les utiliser pour certaines requêtes. Par exemple, Spanner n'utilise pas l'index pour cette requête, car il omet toutes les lignes Singers pour lesquelles LastName est NULL. Par conséquent, l'utilisation de l'index empêcherait la requête de renvoyer les lignes correctes :
GoogleSQL
FROM Singers@{FORCE_INDEX=SingersByFirstLastNameNoNulls}
WHERE FirstName = "John";
PostgreSQL
FROM Singers /*@ FORCE_INDEX = SingersByFirstLastNameNoNulls */
WHERE FirstName = 'John';
Pour permettre à Spanner d'utiliser l'index, vous devez réécrire la requête afin d'exclure les lignes qui sont également exclues de l'index :
GoogleSQL
SELECT FirstName, LastName
FROM Singers@{FORCE_INDEX=SingersByFirstLastNameNoNulls}
WHERE FirstName = 'John' AND LastName IS NOT NULL;
PostgreSQL
SELECT FirstName, LastName
FROM Singers /*@ FORCE_INDEX = SingersByFirstLastNameNoNulls */
WHERE FirstName = 'John' AND LastName IS NOT NULL;
Champs proto d'index
Utilisez des colonnes générées pour indexer les champs dans les protocol buffers stockés dans les colonnes PROTO, à condition que les champs indexés utilisent les types de données primitifs ou ENUM.
Si vous définissez un index sur un champ de message de protocole, vous ne pouvez pas modifier ni supprimer ce champ du schéma proto. Pour en savoir plus, consultez Mises à jour des schémas contenant un index sur les champs proto.
Voici un exemple de table Singers avec une colonne de message proto SingerInfo. Pour définir un index sur le champ nationality de PROTO, vous devez créer une colonne générée stockée :
GoogleSQL
CREATE PROTO BUNDLE (googlesql.example.SingerInfo, googlesql.example.SingerInfo.Residence);
CREATE TABLE Singers (
SingerId INT64 NOT NULL,
...
SingerInfo googlesql.example.SingerInfo,
SingerNationality STRING(MAX) AS (SingerInfo.nationality) STORED
) PRIMARY KEY (SingerId);
Il présente la définition suivante du type proto googlesql.example.SingerInfo :
GoogleSQL
package googlesql.example;
message SingerInfo {
optional string nationality = 1;
repeated Residence residence = 2;
message Residence {
required int64 start_year = 1;
optional int64 end_year = 2;
optional string city = 3;
optional string country = 4;
}
}
Définissez ensuite un index sur le champ nationality du fichier .proto :
GoogleSQL
CREATE INDEX SingersByNationality ON Singers(SingerNationality);
La requête SQL suivante lit les données à l'aide de l'index précédent :
GoogleSQL
SELECT s.SingerId, s.FirstName
FROM Singers AS s
WHERE s.SingerNationality = "English";
Remarques :
- Utilisez une directive d'index pour accéder aux index sur les champs des colonnes de tampon de protocole.
- Vous ne pouvez pas créer d'index sur les champs de tampon de protocole répétés.
Mises à jour des schémas contenant un index sur les champs proto
Si vous définissez un index sur un champ de message de protocole, vous ne pouvez pas modifier ni supprimer ce champ du schéma proto. En effet, une vérification du type est effectuée chaque fois que le schéma est mis à jour après la définition de l'index. Spanner capture les informations de type pour tous les champs du chemin d'accès utilisés dans la définition de l'index.
Index uniques
Les index peuvent être déclarés comme UNIQUE. Les index UNIQUE ajoutent une contrainte aux données indexées qui interdit les entrées en double pour une clé d'index donnée.
Spanner applique cette contrainte au moment du commit de transaction.
Plus précisément, toute transaction qui entraînerait l'existence de plusieurs entrées d'index pour une même clé verra son commit échouer.
Si une table contient des données violant la contrainte UNIQUE, la tentative de création d'un index UNIQUE échouera.
Remarque sur les index UNIQUE NULL_FILTERED
Un index UNIQUE NULL_FILTERED n'applique pas l'unicité des clés d'index lorsqu'au moins l'une des parties de la clé de l'index est NULL.
Par exemple, supposons que vous ayez créé la table et l'index suivants :
GoogleSQL
CREATE TABLE ExampleTable (
Key1 INT64 NOT NULL,
Key2 INT64,
Key3 INT64,
Col1 INT64,
) PRIMARY KEY (Key1, Key2, Key3);
CREATE UNIQUE NULL_FILTERED INDEX ExampleIndex ON ExampleTable (Key1, Key2, Col1);
PostgreSQL
CREATE TABLE ExampleTable (
Key1 BIGINT NOT NULL,
Key2 BIGINT,
Key3 BIGINT,
Col1 BIGINT,
PRIMARY KEY (Key1, Key2, Key3)
);
CREATE UNIQUE INDEX ExampleIndex ON ExampleTable (Key1, Key2, Col1)
WHERE Key1 IS NOT NULL
AND Key2 IS NOT NULL
AND Col1 IS NOT NULL;
Les deux lignes suivantes dans ExampleTable ont les mêmes valeurs pour les clés d'index secondaires Key1, Key2 et Col1 :
1, NULL, 1, 1
1, NULL, 2, 1
Comme Key2 est NULL et que l'index est filtré sur les valeurs nulles, les lignes ne seront pas présentes dans l'index ExampleIndex. Comme elles ne sont pas insérées dans l'index, celui-ci ne les rejettera pas pour cause de violation de la contrainte d'unicité sur (Key1, Key2,
Col1).
Si vous souhaitez que l'index applique la contrainte d'unicité pour les valeurs du tuple (Key1, Key2, Col1), vous devez annoter Key2 avec NOT NULL dans la définition de table ou créer un index sans filtrer les valeurs nulles.
Supprimer un index
Utilisez l'instruction DROP INDEX pour supprimer un index secondaire de votre schéma.
Pour supprimer l'index nommé SingersByFirstLastName :
DROP INDEX SingersByFirstLastName;
Index pour une analyse plus rapide
Lorsque Spanner doit effectuer une analyse de table (plutôt qu'une recherche indexée) pour extraire des valeurs d'une ou de plusieurs colonnes, vous pouvez obtenir des résultats plus rapidement si un index existe pour ces colonnes et dans l'ordre spécifié par la requête. Si vous effectuez fréquemment des requêtes nécessitant des analyses, envisagez de créer des index secondaires pour que ces analyses soient plus efficaces.
En particulier, si vous avez besoin que Spanner analyse fréquemment la clé primaire ou un autre index d'une table dans l'ordre inverse, vous pouvez améliorer son efficacité grâce à un index secondaire qui rend l'ordre choisi explicite.
Par exemple, la requête suivante renvoie toujours un résultat rapide, même si Spanner doit analyser Songs pour trouver la valeur la plus basse de SongId :
SELECT SongId FROM Songs LIMIT 1;
SongId est la clé primaire de la table, stockée (comme toutes les clés primaires) par ordre croissant. Spanner peut analyser l'index de cette clé et trouver rapidement le premier résultat.
Toutefois, sans l'aide d'un index secondaire, la requête suivante ne renverrait pas de résultat aussi rapidement, surtout si Songs contient beaucoup de données :
SELECT SongId FROM Songs ORDER BY SongId DESC LIMIT 1;
Même si SongId est la clé primaire de la table, Spanner n'a aucun moyen de récupérer la valeur la plus élevée de la colonne sans avoir recours à une analyse complète de la table.
L'ajout de l'index suivant permettrait à cette requête de renvoyer des résultats plus rapidement :
CREATE INDEX SongIdDesc On Songs(SongId DESC);
Avec cet index en place, Spanner l'utiliserait pour renvoyer un résultat pour la deuxième requête beaucoup plus rapidement.
Étapes suivantes
- Découvrez les bonnes pratiques SQL pour Spanner.
- Comprenez les plans d'exécution des requêtes pour Spanner.
- Découvrez comment résoudre les problèmes de régression des performances dans les requêtes SQL.