在 Spanner 数据库中,Spanner 会自动为每个表的主键创建索引。例如,您无需执行任何操作即可为 Singers 的主键编制索引,因为系统会自动为您编制索引。
除此之外,您可以针对非主键列创建“二级索引”。针对非主键列添加二级索引有助于更高效地查找此类列中的数据。例如,如果您需要按标题快速查找专辑,则应对 AlbumTitle 创建二级索引,这样 Spanner 便无需扫描整个表。
如果上述示例中的查找在读写事务中完成,则更高效的查找还可以避免对整个表保持锁定,从而允许针对 AlbumTitle 查找范围以外的行对表进行并发插入和更新。
除了为查询带来的优势之外,二级索引还可以帮助 Spanner 更高效地执行扫描,从而启用索引扫描而不是全表扫描。
Spanner 会将以下数据存储在各个二级索引中:
- 基表中的所有键列
- 索引中包含的所有列
- 索引定义的可选
STORING子句(GoogleSQL 方言数据库)或INCLUDE子句(PostgreSQL 方言数据库)中指定的所有列。
随着时间的推移,Spanner 会逐步分析您的表,以确保为适合的查询使用二级索引。
添加二级索引
在创建表时添加二级索引最为高效。要同时创建表及其索引,请在一个请求中将添加新表和添加新索引的 DDL 语句一并发送到 Spanner。
在 Spanner 中,您还可以向现有表添加新的二级索引,添加过程中数据库可继续处理流量。与 Spanner 中的其他所有架构更改一样,向现有数据库添加索引不需要使数据库离线,也不会锁定整个列或表。
每当新索引添加到现有表时,Spanner 就会自动回填或填充索引,以反映被编入索引的数据的最新视图。Spanner 会为您管理此回填过程,该过程会以低优先级使用节点资源在后台运行。索引回填速度会适应在创建索引期间不断变化的节点资源,并且回填不会显著影响数据库的性能。
创建索引可能需要几分钟到数小时才能完成。由于创建索引属于架构更新,因此须遵循与其他架构更新一样的性能限制。创建二级索引所需的时间取决于以下几个因素:
- 数据集的大小
- 实例的计算容量
- 实例上的负载
如需查看索引回填流程的进度,请参阅进度部分。
请注意,将提交时间戳列用作二级索引的第一部分可能会引发热点,并降低写入性能。
使用 CREATE INDEX 语句在您的架构中定义二级索引。下面是一些示例:
要按名字和姓氏将数据库中的所有 Singers 编入索引,请使用以下语句:
GoogleSQL
CREATE INDEX SingersByFirstLastName ON Singers(FirstName, LastName);
PostgreSQL
CREATE INDEX SingersByFirstLastName ON Singers(FirstName, LastName);
要按照 SongName 的值为数据库中的所有 Songs 创建索引,请使用以下语句:
GoogleSQL
CREATE INDEX SongsBySongName ON Songs(SongName);
PostgreSQL
CREATE INDEX SongsBySongName ON Songs(SongName);
要仅将特定歌手的歌曲编入索引,请使用 INTERLEAVE IN 子句在表 Singers 中交错索引:
GoogleSQL
CREATE INDEX SongsBySingerSongName ON Songs(SingerId, SongName),
INTERLEAVE IN Singers;
PostgreSQL
CREATE INDEX SongsBySingerSongName ON Songs(SingerId, SongName)
INTERLEAVE IN Singers;
要仅将特定专辑中的歌曲编入索引,请使用以下语句:
GoogleSQL
CREATE INDEX SongsBySingerAlbumSongName ON Songs(SingerId, AlbumId, SongName),
INTERLEAVE IN Albums;
PostgreSQL
CREATE INDEX SongsBySingerAlbumSongName ON Songs(SingerId, AlbumId, SongName)
INTERLEAVE IN Albums;
要按照 SongName 的降序顺序编制索引,请使用以下语句:
GoogleSQL
CREATE INDEX SongsBySingerAlbumSongNameDesc ON Songs(SingerId, AlbumId, SongName DESC),
INTERLEAVE IN Albums;
PostgreSQL
CREATE INDEX SongsBySingerAlbumSongNameDesc ON Songs(SingerId, AlbumId, SongName DESC)
INTERLEAVE IN Albums;
请注意,上面的 DESC 注解仅适用于 SongName。要按其他索引键的降序顺序编制索引,请同样为这些索引键添加注释 DESC,例如:SingerId DESC, AlbumId DESC。
另请注意,PRIMARY_KEY 是保留字,不能用作索引的名称。它是伪索引的名称,是在创建具有 PRIMARY KEY 规范的表时创建的
有关选择非交错索引和交错索引的详细信息和最佳做法,请参阅索引选项和在其值单调递增或递减的列上使用交错索引。
索引和交织
Spanner 索引可以与其他表交织,以便将索引行与其他表中的行放置在一起。与 Spanner 表交织类似,索引父项的主键列必须是索引列的前缀,并且在类型和排序顺序上相匹配。与交织表不同,列名称匹配不是必需的。交织索引的每一行都会与关联的父行一起存储。
例如,请考虑以下架构:
CREATE TABLE Singers (
SingerId INT64 NOT NULL,
FirstName STRING(1024),
LastName STRING(1024),
SingerInfo PROTO<Singer>(MAX)
) PRIMARY KEY (SingerId);
CREATE TABLE Albums (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
AlbumTitle STRING(MAX),
PublisherId INT64 NOT NULL
) PRIMARY KEY (SingerId, AlbumId),
INTERLEAVE IN PARENT Singers ON DELETE CASCADE;
CREATE TABLE Songs (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
TrackId INT64 NOT NULL,
PublisherId INT64 NOT NULL,
SongName STRING(MAX)
) PRIMARY KEY (SingerId, AlbumId, TrackId),
INTERLEAVE IN PARENT Albums ON DELETE CASCADE;
CREATE TABLE Publishers (
Id INT64 NOT NULL,
PublisherName STRING(MAX)
) PRIMARY KEY (Id);
如需按名字和姓氏将数据库中的所有 Singers 编入索引,您必须创建索引。以下演示了如何定义索引 SingersByFirstLastName:
CREATE INDEX SingersByFirstLastName ON Singers(FirstName, LastName);
如果您想对 (SingerId, AlbumId, SongName) 创建 Songs 索引,可以执行以下操作:
CREATE INDEX SongsBySingerAlbumSongName
ON Songs(SingerId, AlbumId, SongName);
或者,您可以创建一个与 Songs 的祖先交织的索引,如下所示:
CREATE INDEX SongsBySingerAlbumSongName
ON Songs(SingerId, AlbumId, SongName),
INTERLEAVE IN Albums;
此外,您还可以在 (PublisherId, SingerId, AlbumId, SongName) 上创建 Songs 索引,该索引与非 Songs 祖先的表(如 Publishers)交织。请注意,Publishers 表的主键 (id) 不是以下示例中编入索引的列的前缀。这种情况仍然是允许的,因为 Publishers.Id 和 Songs.PublisherId 具有相同的类型、排序顺序以及可为 null 性。
CREATE INDEX SongsByPublisherSingerAlbumSongName
ON Songs(PublisherId, SingerId, AlbumId, SongName),
INTERLEAVE IN Publishers;
检查索引回填进度
控制台
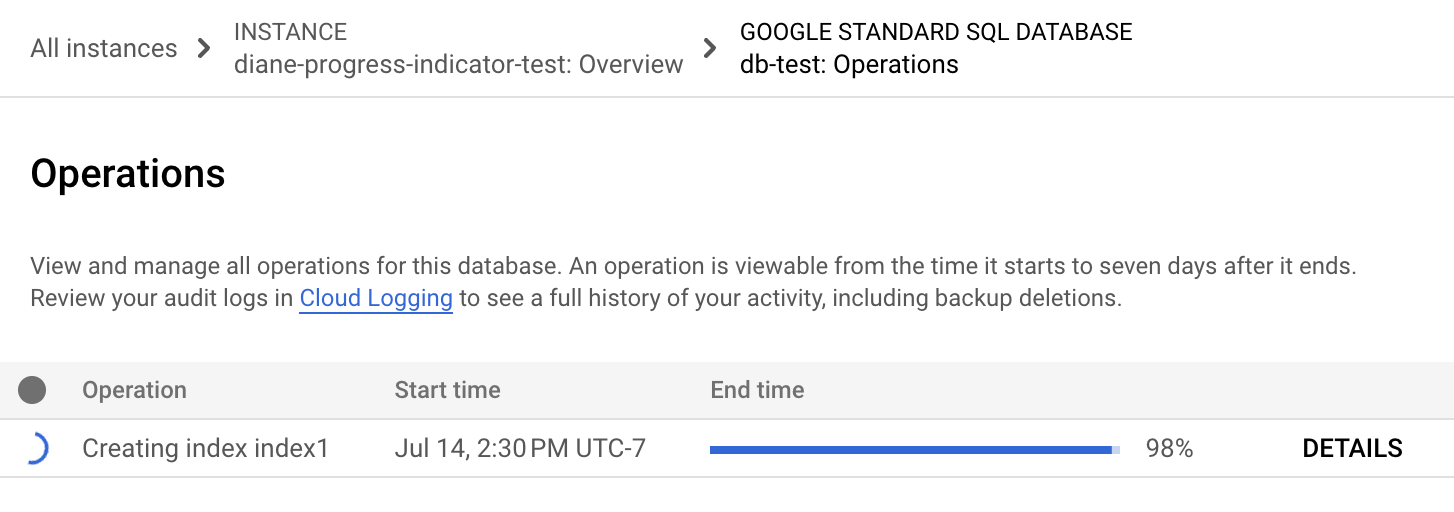
在 Spanner 导航菜单中,点击操作标签页。操作页面会显示正在运行的操作的列表。
在列表中找到回填操作。如果任务仍在运行,结束时间列中的进度指示器会显示操作已完成的百分比,如下图所示:
gcloud
使用 gcloud spanner operations describe 检查操作的进度。
获取操作 ID:
gcloud spanner operations list --instance=INSTANCE-NAME \ --database=DATABASE-NAME --type=DATABASE_UPDATE_DDL
替换以下内容:
- 将 INSTANCE-NAME 替换为 Spanner 实例名称。
- 将 DATABASE-NAME 替换为数据库的名称。
使用说明:
要限制列表,请指定
--filter标志。例如:--filter="metadata.name:example-db"仅列出对特定数据库的操作。--filter="error:*"仅列出失败的备份操作。
如需了解过滤条件语法,请参阅 gcloud topic filters。如需了解如何过滤备份操作,请参阅 ListBackupOperationsRequest 中的
filter字段。--type标志不区分大小写。
输出类似于以下内容:
OPERATION_ID STATEMENTS DONE @TYPE _auto_op_123456 CREATE INDEX SingersByFirstLastName ON Singers(FirstName, LastName) False UpdateDatabaseDdlMetadata CREATE INDEX SongsBySingerAlbumSongName ON Songs(SingerId, AlbumId, SongName), INTERLEAVE IN Albums _auto_op_234567 True CreateDatabaseMetadata运行
gcloud spanner operations describe:gcloud spanner operations describe \ --instance=INSTANCE-NAME \ --database=DATABASE-NAME \ projects/PROJECT-NAME/instances/INSTANCE-NAME/databases/DATABASE-NAME/operations/OPERATION_ID
替换以下内容:
- INSTANCE-NAME:Spanner 实例名称。
- DATABASE-NAME:Spanner 数据库名称。
- PROJECT-NAME:项目名称。
- OPERATION-ID:要检查的操作的 ID。
输出中的
progress部分显示操作的完成百分比。输出类似于以下内容:done: true ... progress: - endTime: '2021-01-22T21:58:42.912540Z' progressPercent: 100 startTime: '2021-01-22T21:58:11.053996Z' - progressPercent: 67 startTime: '2021-01-22T21:58:11.053996Z' ...
REST v1
获取操作 ID:
gcloud spanner operations list --instance=INSTANCE-NAME
--database=DATABASE-NAME --type=DATABASE_UPDATE_DDL
替换以下内容:
- 将 INSTANCE-NAME 替换为 Spanner 实例名称。
- 将 DATABASE-NAME 替换为数据库的名称。
在使用任何请求数据之前,请先进行以下替换:
- PROJECT-ID:项目 ID。
- INSTANCE-ID:实例 ID。
- DATABASE-ID:数据库 ID。
- OPERATION-ID:操作 ID。
HTTP 方法和网址:
GET https://spanner.googleapis.com/v1/projects/PROJECT-ID/instances/INSTANCE-ID/databases/DATABASE-ID/operations/OPERATION-ID
如需发送您的请求,请展开以下选项之一:
您应该收到类似以下内容的 JSON 响应:
{
...
"progress": [
{
"progressPercent": 100,
"startTime": "2023-05-27T00:52:27.366688Z",
"endTime": "2023-05-27T00:52:30.184845Z"
},
{
"progressPercent": 100,
"startTime": "2023-05-27T00:52:30.184845Z",
"endTime": "2023-05-27T00:52:40.750959Z"
}
],
...
"done": true,
"response": {
"@type": "type.googleapis.com/google.protobuf.Empty"
}
}
对于 gcloud 和 REST,您可以在 progress 部分中找到每个索引回填语句的进度。对于语句数组中的每个语句,进度数组都有一个对应的字段。此进度数组顺序与语句数组的顺序对应。成为可用状态后,系统会相应地填充 startTime、progressPercent 和 endTime 字段。请注意,输出内容不会显示回填进度完成的预计时间。
如果操作花费的时间过长,您可以取消它。如需了解详情,请参阅取消索引创建。
查看索引回填进度时的场景
在尝试检查索引回填的进度时,您可能会遇到不同的场景。需要索引回填的索引创建语句是架构更新操作的一部分,并且架构更新操作中可能有多个语句。
第一个场景最简单,即索引创建语句是架构更新操作中的第一个语句。因为索引创建语句是第一个语句,所以根据执行顺序,它是第一个处理和执行的语句。索引创建语句的 startTime 字段将立即使用架构更新操作的开始时间进行填充。接下来,当索引回填的进度超过 0% 时,系统会填充索引创建语句的 progressPercent 字段。最后,在提交语句后,系统会填充 endTime 字段。
第二个场景是,索引创建语句不是架构更新操作中的第一个语句。由于执行顺序,在提交上一个语句之前,不会填充与索引创建语句相关的字段。与上一个场景类似,提交前面的语句后,系统会先填充索引创建语句的 startTime 字段,然后填充 progressPercent 字段。最后,一旦语句提交完成,系统会填充 endTime 字段。
取消索引创建
您可以使用 Google Cloud CLI 取消索引创建操作。要检索 Spanner 数据库的一系列架构更新操作,请使用 gcloud spanner operations list 命令,并添加 --filter 选项:
gcloud spanner operations list \
--instance=INSTANCE \
--database=DATABASE \
--filter="@TYPE:UpdateDatabaseDdlMetadata"
找到要取消操作的 OPERATION_ID,然后使用 gcloud spanner operations cancel 命令将其取消:
gcloud spanner operations cancel OPERATION_ID \
--instance=INSTANCE \
--database=DATABASE
查看现有索引
如需查看数据库中现有索引的相关信息,您可以使用Google Cloud 控制台或 Google Cloud CLI:
控制台
前往 Google Cloud 控制台中的 Spanner 实例页面。
点击要查看的实例的名称。
在左侧窗格中,点击要查看的数据库,然后点击要查看的表。
点击索引标签页。 Google Cloud 控制台会显示索引列表。
可选:要获取有关索引的详细信息(例如其中包含的列),请点击相应索引的名称。
gcloud
使用 gcloud spanner databases ddl describe 命令:
gcloud spanner databases ddl describe DATABASE \
--instance=INSTANCE
gcloud CLI 可输出数据定义语言 (DDL) 语句来创建数据库的表和索引。CREATE
INDEX 语句描述了现有索引。例如:
--- |-
CREATE TABLE Singers (
SingerId INT64 NOT NULL,
FirstName STRING(1024),
LastName STRING(1024),
SingerInfo BYTES(MAX),
) PRIMARY KEY(SingerId)
---
CREATE INDEX SingersByFirstLastName ON Singers(FirstName, LastName)
使用特定索引进行查询
以下部分介绍了如何在 SQL 语句中指定索引以及如何使用 Spanner 的读取接口指定索引。这些部分中的示例假定您向 Albums 表添加了 MarketingBudget 列并创建了名为 AlbumsByAlbumTitle 的索引:
GoogleSQL
CREATE TABLE Albums (
SingerId INT64 NOT NULL,
AlbumId INT64 NOT NULL,
AlbumTitle STRING(MAX),
MarketingBudget INT64,
) PRIMARY KEY (SingerId, AlbumId),
INTERLEAVE IN PARENT Singers ON DELETE CASCADE;
CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle);
PostgreSQL
CREATE TABLE Albums (
SingerId BIGINT NOT NULL,
AlbumId BIGINT NOT NULL,
AlbumTitle VARCHAR,
MarketingBudget BIGINT,
PRIMARY KEY (SingerId, AlbumId)
) INTERLEAVE IN PARENT Singers ON DELETE CASCADE;
CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle);
在 SQL 语句中指定索引
在您使用 SQL 来查询 Spanner 表时,Spanner 会自动使用任何有可能提高查询效率的索引。因此,您不需要为 SQL 查询指定索引。但是,对于工作负载至关重要的查询,Google 建议您在 SQL 语句中使用 FORCE_INDEX 指令以实现更一致的性能。
在少数情况下,Spanner 可能会选择让查询延迟时间增加的索引。如果您已按照性能回归问题排查步骤进行操作,并确认有必要为查询尝试其他索引,则可以在查询中指定索引。
如需在 SQL 语句中指定索引,请使用 FORCE_INDEX 提示来提供“索引指令”。索引指令使用以下语法:
GoogleSQL
FROM MyTable@{FORCE_INDEX=MyTableIndex}
PostgreSQL
FROM MyTable /*@ FORCE_INDEX = MyTableIndex */
您还可以使用索引指令来指示 Spanner 扫描基表(而不是使用索引):
GoogleSQL
FROM MyTable@{FORCE_INDEX=_BASE_TABLE}
PostgreSQL
FROM MyTable /*@ FORCE_INDEX = _BASE_TABLE */
您可以使用索引指令来指示 Spanner 扫描具有命名架构的表中的索引:
GoogleSQL
FROM MyNamedSchema.MyTable@{FORCE_INDEX="MyNamedSchema.MyTableIndex"}
PostgreSQL
FROM MyTable /*@ FORCE_INDEX = MyTableIndex */
以下示例演示了指定索引的 SQL 查询:
GoogleSQL
SELECT AlbumId, AlbumTitle, MarketingBudget
FROM Albums@{FORCE_INDEX=AlbumsByAlbumTitle}
WHERE AlbumTitle >= "Aardvark" AND AlbumTitle < "Goo";
PostgreSQL
SELECT AlbumId, AlbumTitle, MarketingBudget
FROM Albums /*@ FORCE_INDEX = AlbumsByAlbumTitle */
WHERE AlbumTitle >= 'Aardvark' AND AlbumTitle < 'Goo';
索引指令可能会强制 Spanner 的查询处理器读取查询需要但未存储在索引中的其他列。查询处理器通过联接索引和基表来检索这些列。如需避免这种额外的联接,请使用 STORING 子句(GoogleSQL 方言数据库)或 INCLUDE 子句(PostgreSQL 方言数据库)将其他列存储在索引中。
在上面的示例中,MarketingBudget 列未存储在索引中,但 SQL 查询会选择此列。因此,Spanner 必须在基表中查找 MarketingBudget 列,然后将其与索引中的数据联接,以返回查询结果。
如果索引指令存在以下任何问题,则 Spanner 将发生错误:
- 索引不存在。
- 索引位于不同的基表上。
- 查询缺少
NULL_FILTERED索引必需的NULL过滤表达式。
下面的示例演示了如何编写和执行查询,以使用索引 AlbumsByAlbumTitle 提取 AlbumId、AlbumTitle 和 MarketingBudget 的值:
C++
C#
Go
Java
Node.js
PHP
Python
Ruby
在读取接口中指定索引
如果您使用了 Spanner 的读取接口,并且希望 Spanner 使用索引,则必须指定索引。读取接口不会自动选择索引。
此外,您的索引必须包含查询结果中显示的所有数据,属于主键的列除外。存在此限制是因为读取接口不支持索引和基表之间的联接。如果您需要在查询结果中包含其他列,可以使用以下几种方法:
- 使用
STORING或INCLUDE子句将其他列存储在索引中。 - 执行不包含其他列的查询,然后再使用主键发送另一个读取其他列的查询。
Spanner 按索引键的升序顺序返回索引中的值。要按降序顺序检索值,请完成以下步骤:
为索引键添加注释
DESC。例如:CREATE INDEX AlbumsByAlbumTitle ON Albums(AlbumTitle DESC);DESC注释适用于单个索引键。如果索引包含多个键,并且您希望按照所有键的降序顺序显示查询结果,请为每个键添加DESC注释。如果读取接口指定了键范围,请确保该键范围也按降序顺序排列。换句话说,也就是起始键的值必须大于结束键的值。
以下示例演示了如何使用索引 AlbumsByAlbumTitle 检索 AlbumId 和 AlbumTitle 的值:
C++
C#
Go
Java
Node.js
PHP
Python
Ruby
为纯索引扫描创建索引
您可以选择使用 STORING 子句(对于 GoogleSQL 方言数据库)或 INCLUDE 子句(对于 PostgreSQL 方言数据库)将列的副本存储在索引中。此类索引为使用索引的查询和读取调用提供了便利,但会占用额外存储空间:
- 如果 SQL 查询使用索引且选择存储在
STORING或INCLUDE子句中的列,则不需要与基表建立额外联接。 - 使用索引的
read()调用可以读取由STORING/INCLUDE子句存储的列。
例如,假设您创建了 AlbumsByAlbumTitle 的替代版本,将 MarketingBudget 列的副本存储在索引中(请注意,STORING 或 INCLUDE 子句以粗体显示):
GoogleSQL
CREATE INDEX AlbumsByAlbumTitle2 ON Albums(AlbumTitle) STORING (MarketingBudget);
PostgreSQL
CREATE INDEX AlbumsByAlbumTitle2 ON Albums(AlbumTitle) INCLUDE (MarketingBudget);
使用旧的 AlbumsByAlbumTitle 索引时,Spanner 必须将索引与基表联接,然后从基表检索该列。借助新的 AlbumsByAlbumTitle2 索引,Spanner 可直接从索引中读取该列,效率更高。
如果您使用读取接口(而非 SQL),新的 AlbumsByAlbumTitle2 索引也可让您直接读取 MarketingBudget 列:
C++
C#
Go
Java
Node.js
PHP
Python
Ruby
更改索引
您可以使用 ALTER INDEX 语句向现有索引中添加其他列或删除列。这可以更新您在创建索引时由 STORING 子句(GoogleSQL 方言数据库)或 INCLUDE 子句(PostgreSQL 方言数据库)定义的列列表。您无法使用此语句对索引键添加列或删除列。例如,您可以使用 ALTER INDEX 将列添加到 AlbumsByAlbumTitle 中,而不是创建新索引 AlbumsByAlbumTitle2,如以下示例所示:
GoogleSQL
ALTER INDEX AlbumsByAlbumTitle ADD STORED COLUMN MarketingBudget
PostgreSQL
ALTER INDEX AlbumsByAlbumTitle ADD INCLUDE COLUMN MarketingBudget
当您向现有索引添加新列时,Spanner 会使用后台回填过程。在回填正在进行期间,索引中的列不可读,因此您可能无法获得预期的性能提升。您可以使用 gcloud spanner operations 命令列出长时间运行的操作并查看其状态。如需了解详情,请参阅描述操作。
您还可以使用取消操作来取消正在运行的操作。
回填完成后,Spanner 会将相应列添加到索引中。随着索引变得越来越大,这可能会降低使用该索引的查询的速度。
以下示例展示了如何从索引中删除列:
GoogleSQL
ALTER INDEX AlbumsByAlbumTitle DROP STORED COLUMN MarketingBudget
PostgreSQL
ALTER INDEX AlbumsByAlbumTitle DROP INCLUDE COLUMN MarketingBudget
NULL 值的索引
默认情况下,Spanner 会将 NULL 值编入索引。例如,回顾一下表 Singers 上的索引 SingersByFirstLastName 的定义:
CREATE INDEX SingersByFirstLastName ON Singers(FirstName, LastName);
即使 FirstName 和/或 LastName 为 NULL,系统仍会将 Singers 的所有行编入索引。

将 NULL 值编入索引后,您便可以针对包含 NULL 值的数据执行有效的 SQL 查询和读取。例如,使用以下 SQL 查询语句可查找 FirstName 为 NULL 的所有 Singers:
GoogleSQL
SELECT s.SingerId, s.FirstName, s.LastName
FROM Singers@{FORCE_INDEX=SingersByFirstLastName} AS s
WHERE s.FirstName IS NULL;
PostgreSQL
SELECT s.SingerId, s.FirstName, s.LastName
FROM Singers /* @ FORCE_INDEX = SingersByFirstLastName */ AS s
WHERE s.FirstName IS NULL;
NULL 值的排列顺序
Spanner 将 NULL 作为任何给定类型的最小值进行排序。也就是说,如果列按升序 (ASC) 顺序排列,则 NULL 值排在最前。如果列按降序 (DESC) 顺序排列,则 NULL 值排在最后。
禁止将 NULL 值编入索引
GoogleSQL
要禁止将 NULL 值编入索引,请在索引定义中添加 NULL_FILTERED 关键字。NULL_FILTERED 索引特别适用于将大部分行都包含 NULL 值的稀疏列编入索引。在这些情况下,与包含 NULL 的一般索引相比,NULL_FILTERED 索引非常小,维护起来也更为高效。
下面是不将 NULL 编入索引的 SingersByFirstLastName 的一个替代定义:
CREATE NULL_FILTERED INDEX SingersByFirstLastNameNoNulls
ON Singers(FirstName, LastName);
NULL_FILTERED 关键字适用于所有索引键列。您无法针对每个列指定 NULL 过滤。
PostgreSQL
如需过滤掉在一个或多个编入索引的列中包含 null 值的行,请使用 WHERE COLUMN IS NOT NULL 谓词。过滤掉 null 值的索引特别适用于将大部分行包含 NULL 值的稀疏列编入索引。在这些情况下,与包含 NULL 的一般索引相比,过滤掉 NULL 值的索引非常小,维护起来也更为高效。
下面是不将 NULL 编入索引的 SingersByFirstLastName 的一个替代定义:
CREATE INDEX SingersByFirstLastNameNoNulls
ON Singers(FirstName, LastName)
WHERE FirstName IS NOT NULL
AND LastName IS NOT NULL;
过滤掉 NULL 值会使 Spanner 无法对部分查询使用该值。例如,Spanner 不会为此查询使用索引,因为索引会忽略所有 LastName 为 NULL 的 Singers 行;因此,使用索引会导致查询无法返回正确的行:
GoogleSQL
FROM Singers@{FORCE_INDEX=SingersByFirstLastNameNoNulls}
WHERE FirstName = "John";
PostgreSQL
FROM Singers /*@ FORCE_INDEX = SingersByFirstLastNameNoNulls */
WHERE FirstName = 'John';
要让 Spanner 正常使用索引,您必须重新撰写查询,另行排除索引中已排除的行:
GoogleSQL
SELECT FirstName, LastName
FROM Singers@{FORCE_INDEX=SingersByFirstLastNameNoNulls}
WHERE FirstName = 'John' AND LastName IS NOT NULL;
PostgreSQL
SELECT FirstName, LastName
FROM Singers /*@ FORCE_INDEX = SingersByFirstLastNameNoNulls */
WHERE FirstName = 'John' AND LastName IS NOT NULL;
将 proto 字段编入索引
使用生成的列可将存储在 PROTO 列中的协议缓冲区中的字段编入索引,只要被编入索引的字段使用的是原始数据类型或 ENUM 数据类型即可。
如果您为某个协议消息字段定义了索引,则无法修改该字段或从 proto 架构中移除该字段。如需了解详情,请参阅包含 proto 字段索引的架构的更新。
下面是包含 SingerInfo proto 消息列的 Singers 表的示例。如需为 PROTO 的 nationality 字段定义索引,您需要创建存储的生成列:
GoogleSQL
CREATE PROTO BUNDLE (googlesql.example.SingerInfo, googlesql.example.SingerInfo.Residence);
CREATE TABLE Singers (
SingerId INT64 NOT NULL,
...
SingerInfo googlesql.example.SingerInfo,
SingerNationality STRING(MAX) AS (SingerInfo.nationality) STORED
) PRIMARY KEY (SingerId);
它对 googlesql.example.SingerInfo proto 类型有以下定义:
GoogleSQL
package googlesql.example;
message SingerInfo {
optional string nationality = 1;
repeated Residence residence = 2;
message Residence {
required int64 start_year = 1;
optional int64 end_year = 2;
optional string city = 3;
optional string country = 4;
}
}
然后对 proto 的 nationality 字段定义索引:
GoogleSQL
CREATE INDEX SingersByNationality ON Singers(SingerNationality);
以下 SQL 查询使用前面的索引读取数据:
GoogleSQL
SELECT s.SingerId, s.FirstName
FROM Singers AS s
WHERE s.SingerNationality = "English";
注意:
- 使用索引指令访问协议缓冲区列字段的索引。
- 您无法为重复的协议缓冲区字段创建索引。
包含 proto 字段索引的架构的更新
如果您为某个协议消息字段定义了索引,则无法修改该字段或从 proto 架构中移除该字段。这是因为在您定义索引后,系统会在每次更新架构时执行类型检查。Spanner 会捕获相应路径中在索引定义中使用的所有字段的类型信息。
唯一索引
索引可声明为是 UNIQUE 的。UNIQUE 索引会对要编入索引的数据施加一项限制,禁止给定索引键有重复条目。在提交事务时,Spanner 会强制执行此限制。具体而言,任何会导致同一个键出现多个索引条目的事务都将提交失败。
如果某个表的开头包含非 UNIQUE 数据,那么尝试为其创建 UNIQUE 索引将失败。
有关 UNIQUE NULL_FILTERED 索引的注意事项
当 UNIQUE NULL_FILTERED 索引至少有一个键包含 NULL 值时,系统便不会强制施加索引键唯一性限制。
例如,假设您创建了以下表和索引:
GoogleSQL
CREATE TABLE ExampleTable (
Key1 INT64 NOT NULL,
Key2 INT64,
Key3 INT64,
Col1 INT64,
) PRIMARY KEY (Key1, Key2, Key3);
CREATE UNIQUE NULL_FILTERED INDEX ExampleIndex ON ExampleTable (Key1, Key2, Col1);
PostgreSQL
CREATE TABLE ExampleTable (
Key1 BIGINT NOT NULL,
Key2 BIGINT,
Key3 BIGINT,
Col1 BIGINT,
PRIMARY KEY (Key1, Key2, Key3)
);
CREATE UNIQUE INDEX ExampleIndex ON ExampleTable (Key1, Key2, Col1)
WHERE Key1 IS NOT NULL
AND Key2 IS NOT NULL
AND Col1 IS NOT NULL;
ExampleTable 中的以下两行的二级索引键 Key1、Key2 和 Col1 具有相同的值:
1, NULL, 1, 1
1, NULL, 2, 1
由于 Key2 为 NULL 且索引已过滤掉 null 值,因此这些行不会出现在索引 ExampleIndex 中。而由于这些行没有插入到索引中,索引不会因为 (Key1, Key2,
Col1) 违反唯一性而拒绝它们。
如果希望索引强制对元组(Key1、Key2 和 Col1)的值施加唯一性限制,那么您必须在表定义中为 Key2 添加注解 NOT NULL,或者创建未过滤掉 NULL 值的索引。
删除索引
可使用 DROP INDEX 语句从架构中删除二级索引。
要删除名为 SingersByFirstLastName 的索引,请使用以下语句:
DROP INDEX SingersByFirstLastName;
编入索引以加快扫描速度
当 Spanner 需要执行表扫描(而不是索引查找)以从一个或多个列中获取值时,如果这些列存在索引并且按照查询指定的顺序,您可以获得更快的结果。如果您经常执行需要扫描的查询,请考虑创建二级索引,以帮助更高效地执行这些扫描。
具体来说,如果您需要 Spanner 以反向顺序频繁扫描表的主键或其他索引,则可以通过使所选顺序明确显示的二级索引来提高其效率。
例如,以下查询会始终快速返回结果,即使 Spanner 需要扫描 Songs 以查找最低的 SongId 值:
SELECT SongId FROM Songs LIMIT 1;
SongId 是表的主键(与所有主键一样),按升序存储。Spanner 可以扫描该键的索引并快速查找第一个结果。
但是,如果没有二级索引的帮助,以下查询不会快速返回,尤其是在 Songs 包含大量数据的情况下:
SELECT SongId FROM Songs ORDER BY SongId DESC LIMIT 1;
尽管 SongId 是表的主键,但如果没有进行全表扫描,Spanner 也无法提取列的最高值。
添加以下索引可让此查询更快地返回:
CREATE INDEX SongIdDesc On Songs(SongId DESC);
有了此索引,Spanner 将会以更快的速度返回第二个查询的结果。
后续步骤
- 了解 Spanner 的 SQL 最佳做法。
- 了解 Spanner 的查询执行计划。
- 了解如何排查 SQL 查询中的性能回归问题。