이 페이지에서는 PGAdapter를 간략하게 설명합니다. PGAdapter를 시작하는 방법은 PGAdapter 시작을 참조하세요.
PGAdapter는 Spanner용 PostgreSQL 인터페이스와 Spanner 간의 통신을 지원하기 위해 기본 애플리케이션과 함께 실행되는 소형 애플리케이션인 사이드카 프록시입니다.
Java 애플리케이션의 경우 PGAdapter를 별도의 프로세스에서 실행하지 않고도 애플리케이션에 직접 연결할 수 있습니다. PGAdapter는 애플리케이션과 동일한 머신에서 실행되도록 설계되었으며 PostgreSQL 유선 프로토콜을 지원하는 localhost에 엔드포인트를 노출합니다. 이는 PostgreSQL 유선 프로토콜을 Spanner 유선 프로토콜인 gRPC로 변환합니다. 이 프록시가 로컬로 실행되면 psql과 같은 PostgreSQL 클라이언트를 PostgreSQL 언어 Spanner 데이터베이스에 연결할 수 있습니다.
PGAdapter는 최대 0.2ms의 지연 시간 오버헤드를 추가합니다. PostgreSQL 인터페이스의 지연 시간 수준은 GoogleSQL과 동일합니다.
다음 다이어그램은 psql이 PGAdapter를 통해 Spanner에 연결되는 방식을 보여줍니다.
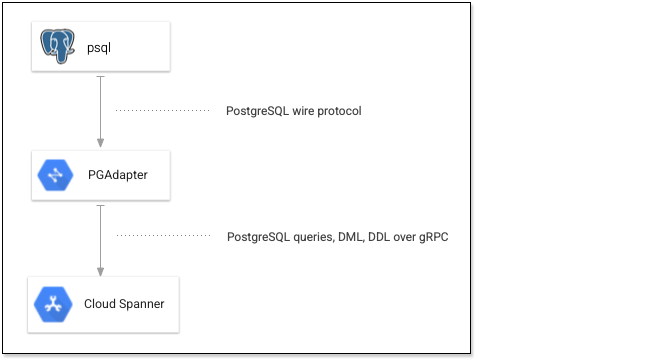
PGAdapter는 기본 및 확장 쿼리 모드를 지원하며 Spanner용 PostgreSQL 인터페이스에서 지원하는 모든 데이터 형식을 지원합니다.
PGAdapter 실행 환경
다음 방법 중 하나를 사용하여 PGAdapter를 실행할 수 있습니다.
- 독립형: PGAdapter는 JAR 파일로 제공되며 JVM에서 독립형으로 실행됩니다.
- Docker: PGAdapter는 Docker 이미지로 패키징됩니다.
- Cloud Run: PGAdapter는 Cloud Run에서 사이드카 프록시로 배포할 수 있습니다.
- 사이드카 프록시: 사이드카 프록시로의 일반적인 용도는 Kubernetes 클러스터입니다.
- 프로세스 내: Java 애플리케이션 코드는 제공된 JAR 파일을 사용하여 PGAdapter 인스턴스를 만들고 시작할 수 있습니다.
이러한 메서드에 대한 자세한 내용은 PGAdapter 시작을 참조하세요.
PGAdapter에 인증
PGAdapter는 시작할 때 지정한 사용자 인증 정보를 검사하여 연결에 사용할 서비스 계정 또는 기타 Identity and Access Management(IAM) 주 구성원을 결정합니다. 이 주 구성원에게 부여된 IAM 권한에 따라 연결 애플리케이션에 데이터베이스에 대한 권한이 부여됩니다.
세분화된 액세스 제어가 사용 중인 경우 PGAdapter를 시작할 때 선택적으로 데이터베이스 역할을 지정할 수도 있습니다. 데이터베이스 역할을 지정하면 PGAdapter에서 쿼리 및 DML 문에 대한 요청을 보낼 때 세분화된 액세스 제어를 사용합니다. 그러려면 IAM 권한 spanner.databases.useRoleBasedAccess가 필요하며 public 이외의 데이터베이스 역할의 경우 spanner.databaseRoles.use 권한이 필요합니다. 데이터베이스 역할에 부여된 권한에 따라 연결 애플리케이션에서 실행할 수 있는 작업이 결정됩니다. 데이터베이스 역할을 지정하지 않으면 IAM 주 구성원에게 부여된 데이터베이스 수준 권한이 사용됩니다. DDL 문을 실행하려면 주 구성원에게 spanner.databases.updateDdl 권한이 있어야 합니다.
자세한 내용은 세분화된 액세스 제어 정보 및 IAM으로 액세스 제어를 참조하세요.
다음 단계
- PGAdapter 시작
- PGAdapter GitHub 저장소 자세히 알아보기
- PGAdapter에서 지원하는 PostgreSQL 드라이버 및 ORM 테이블에 대한 PostgreSQL 드라이버 및 ORM 자세히 알아보기