Nesta página, explicamos como migrar seu banco de dados NoSQL do Cassandra para o Spanner.
O Cassandra e o Spanner são bancos de dados distribuídos em grande escala criados para aplicativos que exigem alta escalonabilidade e baixa latência. Embora os dois bancos de dados possam oferecer suporte a cargas de trabalho NoSQL exigentes, o Spanner oferece recursos avançados para modelagem de dados, consultas e operações transacionais. O Spanner é compatível com a Cassandra Query Language (CQL).
Para mais informações sobre como o Spanner atende aos critérios de banco de dados NoSQL, consulte Spanner para cargas de trabalho não relacionais.
Restrições de migração
Para uma migração bem-sucedida do Cassandra para o endpoint do Cassandra no Spanner, consulte Spanner para usuários do Cassandra e saiba como a arquitetura, o modelo de dados e os tipos de dados do Spanner são diferentes do Cassandra. Considere cuidadosamente as diferenças funcionais entre o Spanner e o Cassandra antes de iniciar a migração.
Processo de migração
O processo de migração é dividido nas seguintes etapas:
- Converter o esquema e o modelo de dados.
- Configurar gravações duplas para dados recebidos.
- Exporte em massa seus dados históricos do Cassandra para o Spanner.
- Valide os dados para garantir a integridade deles durante todo o processo de migração.
- Aponte seu aplicativo para o Spanner em vez do Cassandra.
- Opcional. Faça a replicação inversa do Spanner para o Cassandra.
Converter o esquema e o modelo de dados
A primeira etapa da migração de dados do Cassandra para o Spanner é adaptar o esquema de dados do Cassandra ao esquema do Spanner, processando diferenças nos tipos de dados e na modelagem.
A sintaxe de declaração de tabela é bastante semelhante no Cassandra e no Spanner. Você especifica o nome da tabela, os nomes e tipos de colunas e a chave primária, que identifica exclusivamente uma linha. A principal diferença é que o Cassandra é particionado por hash e faz uma distinção entre as duas partes da chave primária: a chave de partição com hash e as colunas de clustering classificadas. Já o Spanner é particionado por intervalo. A chave primária do Spanner tem apenas colunas de clustering, com partições mantidas automaticamente em segundo plano. Assim como o Cassandra, o Spanner é compatível com chaves primárias compostas.
Recomendamos as seguintes etapas para converter seu esquema de dados do Cassandra para o Spanner:
- Leia a visão geral do Cassandra para entender as semelhanças e diferenças entre os esquemas de dados do Cassandra e do Spanner e aprender a mapear diferentes tipos de dados.
- Use a ferramenta de esquema do Cassandra para o Spanner para extrair e converter seu esquema de dados do Cassandra para o Spanner.
- Antes de iniciar a migração de dados, verifique se as tabelas do Spanner foram criadas com os esquemas de dados adequados.
Configurar a migração dinâmica para dados recebidos
Para realizar uma migração sem inatividade do Cassandra para o Spanner, configure a migração ativa para os dados recebidos. A migração em tempo real se concentra em minimizar o tempo de inatividade e garantir a disponibilidade contínua do aplicativo usando a replicação em tempo real.
Comece com o processo de migração em tempo real antes da migração em massa. O diagrama a seguir mostra a visão arquitetônica de uma migração ativa.
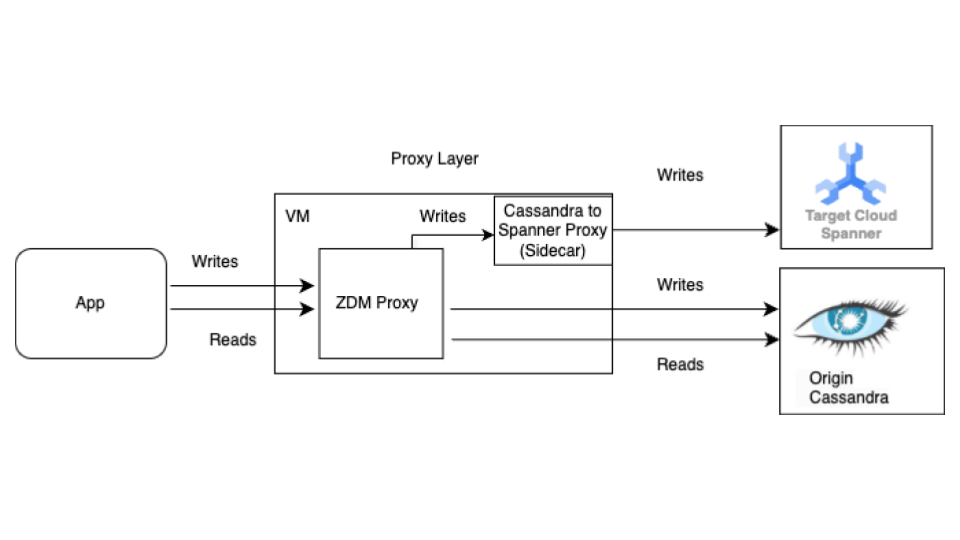
A arquitetura de migração em tempo real tem os seguintes componentes principais:
- Origem:seu banco de dados de origem do Cassandra.
- Destino:o banco de dados de destino do Spanner para onde você está migrando. Presumimos que você já provisionou sua instância do Spanner e o banco de dados com um esquema compatível com o do Cassandra (com as adaptações necessárias para o modelo de dados e os recursos do Spanner).
Proxy ZDM da Datastax:o proxy ZDM é um proxy de gravações duplas criado pela DataStax para migrações do Cassandra para o Cassandra. O proxy imita um cluster do Cassandra, permitindo que um aplicativo o use sem precisar de mudanças. Essa ferramenta é o que seu aplicativo usa para se comunicar e internamente para realizar gravações duplas nos bancos de dados de origem e de destino. Embora seja normalmente usado com clusters do Cassandra como origem e destino, nossa configuração o configura para usar o proxy Cassandra-Spanner (executado como um sidecar) como destino. Isso garante que cada leitura recebida seja encaminhada apenas para a origem e retorne a resposta da origem ao aplicativo. Além disso, cada gravação recebida é direcionada à origem e ao destino.
- Se as gravações na origem e no destino forem bem-sucedidas, o aplicativo vai receber uma mensagem de sucesso.
- Se as gravações na origem falharem e as gravações no destino forem bem-sucedidas, o aplicativo vai receber a mensagem de falha da origem.
- Se as gravações no destino falharem e as gravações na origem forem bem-sucedidas, o aplicativo vai receber a mensagem de falha do destino.
- Se as gravações na origem e no destino falharem, o aplicativo vai receber a mensagem de falha da origem.
Proxy do Cassandra-Spanner:um aplicativo sidecar que intercepta o tráfego da linguagem de consulta do Cassandra (CQL) destinado ao Cassandra e o traduz em chamadas da API Spanner. Ele permite que aplicativos e ferramentas interajam com o Spanner usando o cliente do Cassandra.
Aplicativo cliente:o aplicativo que lê e grava dados no cluster de origem do Cassandra.
Configuração de proxy
A primeira etapa para realizar uma migração dinâmica é implantar e configurar os proxies. O proxy do Cassandra-Spanner é executado como um arquivo secundário do proxy da ZDM. O proxy sidecar atua como o destino das operações de gravação do proxy ZDM no Spanner.
Teste de instância única usando o Docker
É possível executar uma única instância do proxy localmente ou em uma VM para testes iniciais usando o Docker.
Pré-requisitos
- Confirme se a VM em que o proxy é executado tem conectividade de rede com o aplicativo, o banco de dados Cassandra de origem e o banco de dados do Spanner.
- Instale o Docker.
- Confirme se há um arquivo de chave de conta de serviço com as permissões necessárias para gravar na instância e no banco de dados do Spanner.
- Configure a instância, o banco de dados e o esquema do Spanner.
- Verifique se o nome do banco de dados do Spanner é igual ao nome do keyspace do Cassandra de origem.
- Clone o repositório spanner-migration-tool.
Fazer o download e configurar o proxy do ZDM
- Acesse o diretório
sources/cassandra. - Verifique se os arquivos
entrypoint.sheDockerfileestão no mesmo diretório que o Dockerfile. Execute o comando a seguir para criar uma imagem local:
docker build -t zdm-proxy:latest .
Executar o proxy do ZDM
- Verifique se
zdm-config.yamlekeyfilesestão presentes localmente onde o comando a seguir é executado. - Abra o arquivo de amostra zdm-config yaml file.
- Confira a lista detalhada de flags aceitas pelo ZDM.
Use o seguinte comando para executar o contêiner:
sudo docker run --restart always -d -p 14002:14002 \ -v zdm-config-file-path:/zdm-config.yaml \ -v local_keyfile:/var/run/secret/keys.json \ -e SPANNER_PROJECT=SPANNER_PROJECT_ID \ -e SPANNER_INSTANCE=SPANNER_INSTANCE_ID \ -e SPANNER_DATABASE=SPANNER_DATABASE_ID \ -e GOOGLE_APPLICATION_CREDENTIALS="/var/run/secret/keys.json" \ -e ZDM_CONFIG=/zdm-config.yaml \ zdm-proxy:latest
Verificar a configuração do proxy
Use o comando
docker logspara verificar se há erros nos registros do proxy durante a inicialização:docker logs container-idExecute o comando
cqlshpara verificar se o proxy está configurado corretamente:cqlsh VM-IP 14002Substitua VM-IP pelo endereço IP da sua VM.
Configuração de Production usando o Terraform:
Para um ambiente de produção, recomendamos usar os modelos do Terraform fornecidos para orquestrar a implantação do proxy Cassandra-Spanner.
Pré-requisitos
- Instale o Terraform.
- Confirme se o aplicativo tem credenciais padrão com as permissões adequadas para criar recursos.
- Confirme se o arquivo de chave de serviço tem as permissões relevantes para gravar no Spanner. Esse arquivo é usado pelo proxy.
- Configure a instância, o banco de dados e o esquema do Spanner.
- Confirme se o Dockerfile,
entrypoint.she o arquivo de chave de serviço estão no mesmo diretório do arquivomain.tf.
Configurar variáveis do Terraform
- Verifique se você tem o modelo do Terraform para a implantação do proxy.
- Atualize o arquivo
terraform.tfvarscom as variáveis da sua configuração.
Implantação de modelo usando o Terraform
O script do Terraform faz o seguinte:
- Cria VMs otimizadas para contêineres com base em uma contagem especificada.
- Cria arquivos
zdm-config.yamlpara cada VM e aloca um índice de topologia a ela. O proxy da ZDM exige configurações de várias VMs para configurar a topologia usando os camposPROXY_TOPOLOGY_ADDRESSESePROXY_TOPOLOGY_INDEXno arquivo de configuraçãoyaml. - Transfere os arquivos relevantes para cada VM, executa o Docker Build remotamente e inicia os contêineres.
Para implantar o modelo, faça o seguinte:
Use o comando
terraform initpara inicializar o Terraform:terraform initExecute o comando
terraform planpara conferir as mudanças que o Terraform planeja fazer na sua infraestrutura:terraform plan -var-file="terraform.tfvars"Quando os recursos estiverem bons, execute o comando
terraform applyterraform apply -var-file="terraform.tfvars"Depois que o script do Terraform for interrompido, execute o comando
cqlshpara garantir que as VMs estejam acessíveis.cqlsh VM-IP 14002Substitua VM-IP pelo endereço IP da sua VM.
Direcione seus aplicativos cliente para o proxy do ZDM
Modifique a configuração do aplicativo cliente, definindo os pontos de contato como as VMs que executam os proxies em vez do cluster Cassandra de origem.
Teste o aplicativo completamente. Verifique se as operações de gravação estão sendo aplicadas ao cluster de origem do Cassandra e, ao verificar o banco de dados do Spanner, se elas também estão chegando ao Spanner usando o proxy do Cassandra-Spanner. As leituras são feitas no Cassandra de origem.
Exportar dados em massa para o Spanner
A migração de dados em massa envolve a transferência de grandes volumes de dados entre bancos de dados, geralmente exigindo planejamento e execução cuidadosos para minimizar o tempo de inatividade e garantir a integridade dos dados. As técnicas incluem processos de ETL (extração, transformação e carregamento), replicação direta de banco de dados e ferramentas de migração especializadas, todas com o objetivo de mover dados de maneira eficiente, preservando a estrutura e a precisão.
Recomendamos usar o modelo do Dataflow SourceDB para Spanner do Spanner para migrar em massa seus dados do Cassandra para o Spanner. O Dataflow é o serviço de extração, transformação e carregamento (ETL) distribuído do Google Cloud que oferece uma plataforma para executar canais de dados e ler e processar grandes quantidades de dados em paralelo em várias máquinas. O modelo do Dataflow do SourceDB para Spanner foi projetado para realizar leituras altamente paralelizadas do Cassandra, transformar os dados de origem conforme necessário e gravar no Spanner como um banco de dados de destino.
Siga as etapas nas instruções de Migração em massa do Cassandra para o Spanner usando o arquivo de configuração do Cassandra.
Validar dados para garantir a integridade
A validação de dados durante a migração de bancos de dados é crucial para garantir a precisão e a integridade dos dados. Isso envolve comparar dados entre os bancos de dados de origem do Cassandra e de destino do Spanner para identificar discrepâncias, como dados ausentes, corrompidos ou incompatíveis. As técnicas gerais de validação de dados incluem somas de verificação, contagens de linhas e comparações detalhadas de dados, todas destinadas a garantir que os dados migrados sejam uma representação precisa dos originais.
Depois que a migração de dados em massa for concluída e enquanto as gravações duplas ainda estiverem ativas, valide a consistência dos dados e corrija as discrepâncias. As diferenças entre o Cassandra e o Spanner podem ocorrer durante a fase de gravação dupla por vários motivos, incluindo:
- Falha nas gravações duplas. Uma operação de gravação pode ser concluída em um banco de dados, mas falhar no outro devido a problemas de rede temporários ou outros erros.
- Transações leves (LWT, na sigla em inglês). Se o aplicativo usar operações LWT (comparar e definir), elas poderão ser bem-sucedidas em um banco de dados, mas falhar no outro devido a diferenças nos conjuntos de dados.
- Alta consulta por segundo (QPS) em uma única chave primária. Em cargas de gravação muito altas para a mesma chave de partição, a ordem dos eventos pode ser diferente entre a origem e o destino devido a diferentes tempos de ida e volta da rede, o que pode levar a inconsistências.
Job em massa e gravações duplas em execução paralela:a migração em massa em execução paralela com gravações duplas pode causar divergência devido a várias condições de disputa, como as seguintes:
- Linhas extras no Spanner:se a migração em massa for executada enquanto as gravações duplas estiverem ativas, o aplicativo poderá excluir uma linha que já foi lida pelo job de migração em massa e gravada no destino.
- Condições de disputa entre gravações em massa e duplas:pode haver outras condições de disputa diversas em que o job em massa lê uma linha do Cassandra e os dados dela ficam desatualizados quando as gravações recebidas atualizam a linha no Spanner após a conclusão das gravações duplas.
- Atualizações parciais de colunas:atualizar um subconjunto de colunas em uma linha existente cria uma entrada no Spanner com outras colunas como nulas. Como as atualizações em massa não substituem as linhas atuais, isso faz com que as linhas divirjam entre o Cassandra e o Spanner.
Esta etapa se concentra na validação e conciliação de dados entre os bancos de dados de origem e de destino. A validação envolve a comparação da origem e do destino para identificar inconsistências, enquanto a conciliação se concentra em resolver essas inconsistências para alcançar a consistência dos dados.
Comparar dados entre o Cassandra e o Spanner
Recomendamos que você faça validações nas contagens de linhas e no conteúdo real delas.
A escolha de como comparar dados (correspondência de contagem e de linhas) depende da tolerância do aplicativo a inconsistências de dados e dos requisitos de validação exata.
Há duas maneiras de validar dados:
A validação ativa é realizada enquanto as gravações duplas estão ativas. Nesse cenário, os dados nos seus bancos de dados ainda estão sendo atualizados. Talvez não seja possível alcançar uma correspondência exata na contagem ou no conteúdo de linhas entre o Cassandra e o Spanner. O objetivo é garantir que as diferenças sejam apenas devido à carga ativa nos bancos de dados e não a outros erros. Se as discrepâncias estiverem dentro desses limites, você poderá continuar com a migração.
A validação estática exige um tempo de inatividade. Se os requisitos exigirem uma validação estática e forte com garantia de consistência exata dos dados, talvez seja necessário interromper temporariamente todas as gravações nos dois bancos de dados. Em seguida, valide os dados e reconcilie as diferenças no banco de dados do Spanner.
Escolha o momento da validação e as ferramentas adequadas com base nos seus requisitos específicos de consistência de dados e tempo de inatividade aceitável.
Comparar o número de linhas no Cassandra e no Spanner
Um método de validação de dados é comparar o número de linhas nas tabelas dos bancos de dados de origem e destino. Há algumas maneiras de fazer validações de contagem:
Ao migrar com conjuntos de dados pequenos (menos de 10 milhões de linhas por tabela), use este script de correspondência de contagem para contar linhas no Cassandra e no Spanner. Essa abordagem retorna contagens exatas em pouco tempo. O tempo limite padrão no Cassandra é de 10 segundos. Aumente o tempo limite da solicitação do driver e do lado do servidor se o script atingir o tempo limite antes de concluir a contagem.
Ao migrar grandes conjuntos de dados (mais de 10 milhões de linhas por tabela), lembre-se de que, embora as consultas de contagem do Spanner sejam bem dimensionadas, as consultas do Cassandra tendem a atingir o tempo limite. Nesses casos, recomendamos usar a ferramenta DataStax Bulk Loader para extrair linhas de contagem das tabelas do Cassandra. Para contagens do Spanner, usar a função SQL
count(*)é suficiente para a maioria das cargas em grande escala. Recomendamos que você execute o carregador em massa para cada tabela do Cassandra, busque as contagens da tabela do Spanner e compare as duas. Isso pode ser feito manualmente ou usando um script.
Validar uma incompatibilidade de linha
Recomendamos que você compare as linhas dos bancos de dados de origem e de destino para identificar incompatibilidades entre elas. Há duas maneiras de fazer validações de linha. A escolha depende dos requisitos do aplicativo:
- Validar um conjunto aleatório de linhas.
- Valide todo o conjunto de dados.
Validar uma amostra aleatória de linhas
Validar um conjunto de dados inteiro é caro e demorado para grandes cargas de trabalho. Nesses casos, use a amostragem para validar um subconjunto aleatório dos dados e verificar se há incompatibilidades nas linhas. Uma maneira de fazer isso é escolher linhas aleatórias no Cassandra e buscar as linhas correspondentes no Spanner. Depois, compare os valores (ou o hash da linha).
As vantagens desse método são que você termina mais rápido do que verificando um conjunto de dados inteiro e é simples de executar. A desvantagem é que, como é um subconjunto dos dados, ainda pode haver diferenças nos dados presentes para casos extremos.
Para fazer uma amostragem de linhas aleatórias do Cassandra, faça o seguinte:
- Gere números aleatórios no intervalo de tokens [
-2^63,2^63 - 1]. - Extrair linhas
WHERE token(PARTITION_KEY) > GENERATED_NUMBER.
O script de exemplo
validation.go
busca linhas aleatoriamente e as valida com linhas no banco de dados
do Spanner.
Validar todo o conjunto de dados
Para validar um conjunto de dados inteiro, busque todas as linhas no banco de dados Cassandra de origem. Use as chaves primárias para buscar todas as linhas correspondentes do banco de dados do Spanner. Em seguida, compare as linhas para identificar diferenças. Para conjuntos de dados grandes, use um framework baseado em MapReduce, como o Apache Spark ou o Apache Beam, para validar todo o conjunto de dados de maneira confiável e eficiente.
A vantagem é que a validação completa oferece mais confiança na consistência dos dados. As desvantagens são que ele adiciona carga de leitura no Cassandra e exige um investimento para criar ferramentas complexas para grandes conjuntos de dados. Também pode levar muito mais tempo para concluir a validação em um conjunto de dados grande.
Uma maneira de fazer isso é particionar os intervalos de tokens e consultar o anel do Cassandra em paralelo. Para cada linha do Cassandra, a linha equivalente do Spanner é buscada usando a chave de partição. Em seguida, essas duas linhas são comparadas para identificar discrepâncias. Para conferir dicas a seguir ao criar jobs de validação, consulte Dicas para validar o Cassandra usando a correspondência de linhas.
Reconciliar inconsistências na contagem de dados ou linhas
Dependendo do requisito de consistência de dados, é possível copiar linhas do Cassandra para o Spanner e conciliar as discrepâncias identificadas durante a fase de validação. Uma maneira de fazer a conciliação é estender a ferramenta usada para validação completa do conjunto de dados e copiar a linha correta do Cassandra para o banco de dados de destino do Spanner se uma incompatibilidade for encontrada. Para mais informações, consulte Considerações sobre a implementação.
Aponte seu aplicativo para o Spanner em vez do Cassandra
Depois de validar a acurácia e a integridade dos dados após a migração, escolha um horário para migrar o aplicativo para o Spanner em vez do Cassandra (ou para o adaptador de proxy usado na migração de dados ativos). Isso é chamado de migração.
Para fazer a transferência, siga estas etapas:
Crie uma mudança de configuração para o aplicativo cliente que permita que ele se conecte diretamente à instância do Spanner usando um dos seguintes métodos:
- Conecte o Cassandra ao Adaptador do Cassandra em execução como um sidecar.
- Mude o driver jar com o cliente de endpoint.
Aplique a mudança preparada na etapa anterior para apontar seu aplicativo para o Spanner.
Configure o monitoramento do aplicativo para detectar erros ou problemas de desempenho. Monitore as métricas do Spanner usando o Cloud Monitoring. Para mais informações, consulte Monitorar instâncias com o Cloud Monitoring.
Após uma transição bem-sucedida e uma operação estável, desative o proxy do ZDM e as instâncias do proxy do Cassandra-Spanner.
Realizar a replicação inversa do Spanner para o Cassandra
É possível realizar a replicação inversa usando o modelo do Dataflow Spanner to
SourceDB.
A replicação inversa é útil quando você encontra problemas imprevistos com o Spanner e precisa voltar ao banco de dados original do Cassandra com o mínimo de interrupção no serviço.
Dicas para validar o Cassandra usando a correspondência de linhas
É lento e ineficiente realizar verificações completas de tabelas no Cassandra (ou em qualquer outro banco de dados) usando SELECT *. Para resolver esse problema, divida o conjunto de dados do Cassandra em partições gerenciáveis e processe-as simultaneamente. Para isso, faça o seguinte:
- Dividir o conjunto de dados em intervalos de tokens
- Consultar partições em paralelo
- Ler dados em cada partição
- Buscar as linhas correspondentes do Spanner
- Ferramentas de validação de design para extensibilidade
- Denunciar e registrar incompatibilidades
Dividir o conjunto de dados em intervalos de tokens
O Cassandra distribui dados entre os nós com base em tokens de chave de partição.
O intervalo de tokens de um cluster do Cassandra vai de -2^63 a 2^63 -
1. É possível definir um número fixo de intervalos de tokens de tamanho igual para dividir todo o espaço de chaves em partições menores. Recomendamos dividir o intervalo de tokens com um parâmetro partition_size configurável que pode ser ajustado para processar rapidamente todo o intervalo.
Consultar partições em paralelo
Depois de definir os intervalos de token, é possível iniciar vários processos ou
threads paralelos, cada um responsável por validar dados em um intervalo específico. Para cada intervalo, é possível criar consultas CQL usando a função token() na chave de partição (pk).
Uma consulta de exemplo para um determinado intervalo de tokens seria assim:
SELECT *
FROM your_keyspace.your_table
WHERE token(pk) >= partition_min_token AND token(pk) <= partition_max_token;
Ao iterar pelos intervalos de tokens definidos e executar essas consultas em paralelo no cluster de origem do Cassandra (ou pelo proxy ZDM configurado para ler do Cassandra), você lê dados de maneira distribuída.
Ler dados em cada partição
Cada processo paralelo executa a consulta baseada em intervalo e recupera um subconjunto dos dados do Cassandra. Verifique a quantidade de dados recuperados por partição para garantir o equilíbrio entre paralelismo e uso de memória.
Extrair as linhas correspondentes do Spanner
Para cada linha buscada do Cassandra, recupere a linha correspondente do banco de dados de destino do Spanner usando a chave de linha de origem.
Comparar linhas para identificar incompatibilidades
Depois de ter a linha do Cassandra e a linha correspondente do Spanner (se ela existir), compare os campos para identificar incompatibilidades. Essa comparação precisa considerar possíveis diferenças de tipo de dados e transformações aplicadas durante a migração. Recomendamos que você defina critérios claros para o que constitui uma incompatibilidade com base nos requisitos do seu aplicativo.
Projetar ferramentas de validação para extensibilidade
Projete sua ferramenta de validação com a possibilidade de estendê-la para conciliação. Por exemplo, é possível adicionar recursos para gravar os dados corretos do Cassandra no Spanner em caso de incompatibilidades identificadas.
Informar e registrar incompatibilidades
Recomendamos que você registre todas as incompatibilidades identificadas com contexto suficiente para permitir investigação e conciliação. Isso pode incluir as chaves primárias, os campos específicos que diferem e os valores do Cassandra e do Spanner. Você também pode agregar estatísticas sobre o número e os tipos de incompatibilidades encontradas.
Ativar e desativar o TTL nos dados do Cassandra
Nesta seção, descrevemos como ativar e desativar o time to live (TTL) em dados do Cassandra em tabelas do Spanner. Para uma visão geral, consulte Time to live (TTL).
Ativar o TTL nos dados do Cassandra
Para os exemplos nesta seção, suponha que você tenha uma tabela com o seguinte esquema:
CREATE TABLE Singers (
SingerId INT64 OPTIONS (cassandra_type = 'bigint'),
AlbumId INT64 OPTIONS (cassandra_type = 'int'),
) PRIMARY KEY (SingerId);
Para ativar o TTL no nível da linha em uma tabela, faça o seguinte:
Adicione a coluna de carimbo de data/hora para armazenar o carimbo de data/hora de expiração de cada linha. Neste exemplo, a coluna é chamada de
ExpiredAt, mas você pode usar qualquer nome.ALTER TABLE Singers ADD COLUMN ExpiredAt TIMESTAMP;Adicione a política de exclusão de linha para excluir automaticamente as linhas mais antigas que o tempo de expiração.
INTERVAL 0 DAYsignifica que as linhas são excluídas imediatamente ao atingir o prazo de validade.ALTER TABLE Singers ADD ROW DELETION POLICY (OLDER_THAN(ExpiredAt, INTERVAL 0 DAY));Defina
cassandra_ttl_modecomorowpara ativar o TTL no nível da linha.ALTER TABLE Singers SET OPTIONS (cassandra_ttl_mode = 'row');Se quiser, defina
cassandra_default_ttlpara configurar o valor padrão de TTL. O valor está em segundos.ALTER TABLE Singers SET OPTIONS (cassandra_default_ttl = 10000);
Desativar o TTL nos dados do Cassandra
Para os exemplos nesta seção, suponha que você tenha uma tabela com o seguinte esquema:
CREATE TABLE Singers (
SingerId INT64 OPTIONS ( cassandra_type = 'bigint' ),
AlbumId INT64 OPTIONS ( cassandra_type = 'int' ),
ExpiredAt TIMESTAMP,
) PRIMARY KEY (SingerId),
ROW DELETION POLICY (OLDER_THAN(ExpiredAt, INTERVAL 0 DAY)), OPTIONS (cassandra_ttl_mode = 'row');
Para desativar o TTL no nível da linha em uma tabela, faça o seguinte:
Se quiser, defina
cassandra_default_ttlcomo zero para limpar o valor padrão de TTL.ALTER TABLE Singers SET OPTIONS (cassandra_default_ttl = 0);Defina
cassandra_ttl_modecomononepara desativar o TTL no nível da linha.ALTER TABLE Singers SET OPTIONS (cassandra_ttl_mode = 'none');Remova a política de exclusão de linha.
ALTER TABLE Singers DROP ROW DELETION POLICY;Remova a coluna de carimbo de data/hora de expiração.
ALTER TABLE Singers DROP COLUMN ExpiredAt;
Considerações de implementação
- Frameworks e bibliotecas:para validação personalizada escalonável, use frameworks baseados em MapReduce, como Apache Spark ou Dataflow (Beam). Escolha uma linguagem compatível (Python, Scala, Java) e use conectores para Cassandra e Spanner, por exemplo, usando um proxy. Essas estruturas permitem o processamento paralelo eficiente de grandes conjuntos de dados para validação abrangente.
- Tratamento de erros e novas tentativas:implemente um tratamento de erros robusto para gerenciar possíveis problemas, como problemas de conectividade de rede ou indisponibilidade temporária de qualquer um dos bancos de dados. Considere implementar mecanismos de repetição para falhas transitórias.
- Configuração:torne os intervalos de token, os detalhes de conexão para os dois bancos de dados e a lógica de comparação configuráveis.
- Ajuste de performance:teste o número de processos paralelos e o tamanho dos intervalos de tokens para otimizar o processo de validação no seu ambiente e volume de dados específicos. Monitore a carga nos clusters do Cassandra e do Spanner durante a validação.
A seguir
- Confira uma comparação entre o Spanner e o Cassandra na visão geral do Cassandra.
- Saiba como se conectar ao Spanner usando o adaptador do Cassandra.