Halaman ini menjelaskan cara memigrasikan database NoSQL dari Cassandra ke Spanner.
Cassandra dan Spanner adalah database terdistribusi berskala besar yang dibuat untuk aplikasi yang memerlukan skalabilitas tinggi dan latensi rendah. Meskipun kedua database dapat mendukung workload NoSQL yang berat, Spanner menyediakan fitur canggih untuk pemodelan data, kueri, dan operasi transaksional. Spanner mendukung Cassandra Query Language (CQL).
Untuk mengetahui informasi selengkapnya tentang cara Spanner memenuhi kriteria database NoSQL, lihat Spanner untuk beban kerja non-relasional.
Batasan migrasi
Agar migrasi dari Cassandra ke endpoint Cassandra di Spanner berhasil, tinjau Spanner untuk pengguna Cassandra untuk mempelajari perbedaan arsitektur, model data, dan jenis data Spanner dengan Cassandra. Pertimbangkan dengan cermat perbedaan fungsional antara Spanner dan Cassandra sebelum Anda memulai migrasi.
Proses migrasi
Proses migrasi dibagi menjadi langkah-langkah berikut:
- Konversi skema dan model data Anda.
- Siapkan penulisan ganda untuk data yang masuk.
- Mengekspor data historis Anda secara massal dari Cassandra ke Spanner.
- Validasi data untuk memastikan integritas data selama proses migrasi.
- Arahkan aplikasi Anda ke Spanner, bukan Cassandra.
- Opsional. Lakukan replikasi terbalik dari Spanner ke Cassandra.
Mengonversi skema dan model data Anda
Langkah pertama dalam memigrasikan data dari Cassandra ke Spanner adalah menyesuaikan skema data Cassandra dengan skema Spanner, sekaligus menangani perbedaan jenis data dan pemodelan.
Sintaks deklarasi tabel cukup mirip di Cassandra dan Spanner. Anda menentukan nama tabel, nama dan jenis kolom, serta kunci primer yang secara unik mengidentifikasi baris. Perbedaan utamanya adalah Cassandra dipartisi hash dan membedakan antara dua bagian kunci primer: kunci partisi hashed dan kolom pengelompokan sorted, sedangkan Spanner dipartisi rentang. Anda dapat menganggap kunci utama Spanner hanya memiliki kolom pengelompokan, dengan partisi yang otomatis dikelola di balik layar. Seperti Cassandra, Spanner mendukung kunci utama gabungan.
Sebaiknya lakukan langkah-langkah berikut untuk mengonversi skema data Cassandra Anda ke Spanner:
- Tinjau Ringkasan Cassandra untuk memahami persamaan dan perbedaan antara skema data Cassandra dan Spanner serta mempelajari cara memetakan berbagai jenis data.
- Gunakan alat skema Cassandra ke Spanner untuk mengekstrak dan mengonversi skema data Cassandra Anda ke Spanner.
- Sebelum memulai migrasi data, pastikan tabel Spanner Anda telah dibuat dengan skema data yang sesuai.
Menyiapkan migrasi langsung untuk data masuk
Untuk melakukan migrasi dengan periode nonaktif nol dari Cassandra ke Spanner, siapkan migrasi langsung untuk data yang masuk. Migrasi langsung berfokus pada meminimalkan waktu non-operasional dan memastikan ketersediaan aplikasi berkelanjutan dengan menggunakan replikasi real-time.
Mulai dengan proses migrasi langsung sebelum migrasi massal. Diagram berikut menunjukkan tampilan arsitektur migrasi langsung.
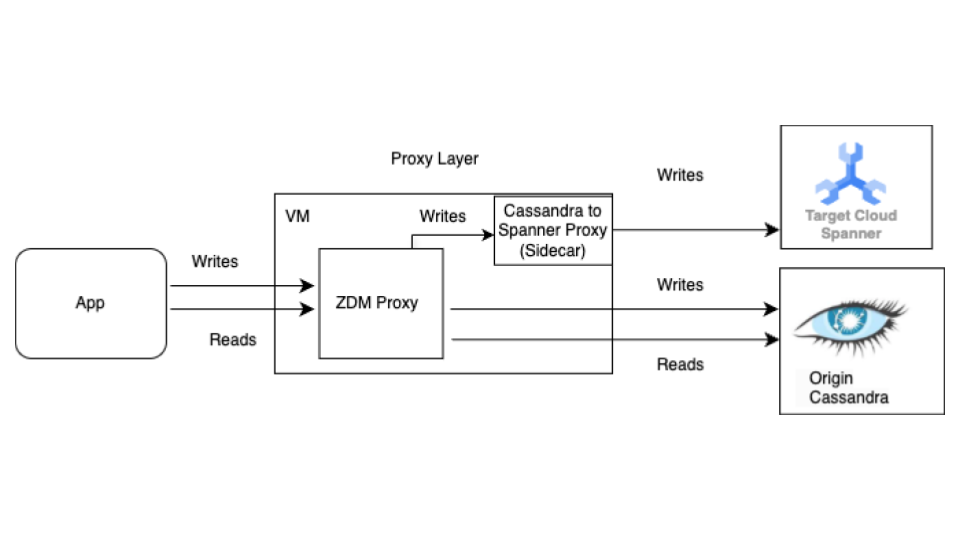
Arsitektur migrasi langsung memiliki komponen utama berikut:
- Asal: Database Cassandra sumber Anda.
- Target: Database Spanner tujuan tempat Anda melakukan migrasi. Diasumsikan bahwa Anda telah menyediakan instance Spanner dan database dengan skema yang kompatibel dengan skema Cassandra Anda (dengan adaptasi yang diperlukan untuk model dan fitur data Spanner).
Datastax ZDM Proxy: ZDM Proxy adalah proxy penulisan ganda yang dibuat oleh DataStax untuk migrasi Cassandra ke Cassandra. Proxy meniru cluster Cassandra sehingga aplikasi dapat menggunakan proxy tanpa perlu mengubah aplikasi. Alat ini adalah alat yang digunakan aplikasi Anda untuk berkomunikasi dan secara internal digunakan untuk melakukan penulisan ganda ke database sumber dan target. Meskipun biasanya digunakan dengan cluster Cassandra sebagai origin dan target, penyiapan kami mengonfigurasinya untuk menggunakan Cassandra- Spanner Proxy (berjalan sebagai sidecar) sebagai target. Hal ini memastikan bahwa setiap pembacaan masuk hanya diteruskan ke asal dan menampilkan respons asal kembali ke aplikasi. Selain itu, setiap operasi tulis masuk diarahkan ke asal dan target.
- Jika penulisan ke asal dan target berhasil, aplikasi akan menerima pesan keberhasilan.
- Jika penulisan ke origin gagal dan penulisan ke target berhasil, aplikasi akan menerima pesan kegagalan origin.
- Jika penulisan ke target gagal dan penulisan ke asal berhasil, aplikasi akan menerima pesan kegagalan target.
- Jika penulisan ke asal dan target gagal, aplikasi akan menerima pesan kegagalan asal.
Cassandra-Spanner Proxy: Aplikasi sidecar yang mencegat traffic Cassandra Query Language (CQL) yang ditujukan untuk Cassandra dan menerjemahkannya menjadi panggilan Spanner API. Driver ini memungkinkan aplikasi dan alat berinteraksi dengan Spanner menggunakan klien Cassandra.
Aplikasi klien: Aplikasi yang membaca dan menulis data ke cluster Cassandra sumber.
Penyiapan proxy
Langkah pertama untuk melakukan migrasi langsung adalah men-deploy dan mengonfigurasi proxy. Cassandra-Spanner Proxy berjalan sebagai sidecar ke ZDM Proxy. Proxy sidecar bertindak sebagai target untuk operasi penulisan ZDM Proxy ke Spanner.
Pengujian instance tunggal menggunakan Docker
Anda dapat menjalankan satu instance proxy secara lokal atau di VM untuk pengujian awal menggunakan Docker.
Prasyarat
- Pastikan VM tempat proxy berjalan memiliki konektivitas jaringan ke aplikasi, database Cassandra asal, dan database Spanner.
- Instal Docker.
- Pastikan ada file kunci akun layanan dengan izin yang diperlukan untuk menulis ke instance dan database Spanner Anda.
- Siapkan instance, database, dan skema Spanner Anda.
- Pastikan nama Database Spanner sama dengan nama keyspace Origin Cassandra.
- Clone repositori spanner-migration-tool.
Mendownload dan mengonfigurasi Proxy ZDM
- Buka direktori
sources/cassandra. - Pastikan file
entrypoint.shdanDockerfileberada di direktori yang sama dengan Dockerfile. Jalankan perintah berikut untuk membangun image lokal:
docker build -t zdm-proxy:latest .
Menjalankan Proxy ZDM
- Pastikan
zdm-config.yamldankeyfilesada secara lokal di tempat perintah berikut dijalankan. - Buka file contoh zdm-config yaml.
- Tinjau daftar lengkap flag yang diterima ZDM.
Gunakan perintah berikut untuk menjalankan container:
sudo docker run --restart always -d -p 14002:14002 \ -v zdm-config-file-path:/zdm-config.yaml \ -v local_keyfile:/var/run/secret/keys.json \ -e SPANNER_PROJECT=SPANNER_PROJECT_ID \ -e SPANNER_INSTANCE=SPANNER_INSTANCE_ID \ -e SPANNER_DATABASE=SPANNER_DATABASE_ID \ -e GOOGLE_APPLICATION_CREDENTIALS="/var/run/secret/keys.json" \ -e ZDM_CONFIG=/zdm-config.yaml \ zdm-proxy:latest
Memverifikasi penyiapan proxy
Gunakan perintah
docker logsuntuk memeriksa apakah ada error dalam log proxy selama startup:docker logs container-idJalankan perintah
cqlshuntuk memverifikasi bahwa proxy telah disiapkan dengan benar:cqlsh VM-IP 14002Ganti VM-IP dengan alamat IP untuk VM Anda.
Penyiapan produksi menggunakan Terraform:
Untuk lingkungan produksi, sebaiknya gunakan template Terraform yang disediakan untuk mengatur deployment proxy Cassandra-Spanner.
Prasyarat
- Menginstal Terraform
- Pastikan aplikasi memiliki kredensial default dengan izin yang sesuai untuk membuat resource.
- Pastikan file kunci layanan memiliki izin yang relevan untuk menulis ke Spanner. File ini digunakan oleh proxy.
- Siapkan instance, database, dan skema Spanner Anda.
- Pastikan Dockerfile,
entrypoint.sh, dan file kunci layanan berada di direktori yang sama dengan filemain.tf.
Mengonfigurasi variabel Terraform
- Pastikan Anda memiliki template Terraform untuk deployment proxy.
- Perbarui file
terraform.tfvarsdengan variabel untuk penyiapan Anda.
Deployment template menggunakan Terraform
Skrip Terraform akan melakukan hal berikut:
- Membuat VM yang dioptimalkan untuk container berdasarkan jumlah yang ditentukan.
- Membuat file
zdm-config.yamluntuk setiap VM, dan mengalokasikan indeks topologi untuk VM tersebut. Proxy ZDM memerlukan penyiapan multi-VM untuk mengonfigurasi topologi menggunakan kolomPROXY_TOPOLOGY_ADDRESSESdanPROXY_TOPOLOGY_INDEXdalam fileyamlkonfigurasi. - Mentransfer file yang relevan ke setiap VM, menjalankan Docker Build dari jarak jauh, dan meluncurkan container.
Untuk men-deploy template, lakukan hal berikut:
Gunakan perintah
terraform inituntuk menginisialisasi Terraform:terraform initJalankan perintah
terraform planuntuk melihat perubahan yang direncanakan Terraform pada infrastruktur Anda:terraform plan -var-file="terraform.tfvars"Jika resource terlihat baik, jalankan perintah
terraform apply:terraform apply -var-file="terraform.tfvars"Setelah skrip Terraform berhenti, jalankan perintah
cqlshuntuk memastikan VM dapat diakses.cqlsh VM-IP 14002Ganti VM-IP dengan alamat IP untuk VM Anda.
Arahkan aplikasi klien Anda ke Proxy ZDM
Ubah konfigurasi aplikasi klien Anda, dengan menetapkan titik kontak sebagai VM yang menjalankan proxy, bukan cluster Cassandra asal Anda.
Uji aplikasi Anda secara menyeluruh. Verifikasi bahwa operasi tulis diterapkan ke cluster Cassandra asal dan, dengan memeriksa database Spanner, bahwa operasi tersebut juga mencapai Spanner menggunakan Proxy Cassandra-Spanner. Operasi baca ditayangkan dari Cassandra asal.
Mengekspor data Anda secara massal ke Spanner
Migrasi data massal melibatkan transfer data dalam volume besar antar-database, yang sering kali memerlukan perencanaan dan eksekusi yang cermat untuk meminimalkan periode nonaktif dan memastikan integritas data. Teknik ini mencakup proses ETL (Ekstrak, Transformasi, Muat), replikasi database langsung, dan alat migrasi khusus, yang semuanya bertujuan untuk memindahkan data secara efisien sekaligus mempertahankan struktur dan akurasinya.
Sebaiknya gunakan template Dataflow SourceDB To Spanner untuk memigrasikan data Anda secara massal dari Cassandra ke Spanner. Dataflow adalah layanan ETL (ekstraksi, transformasi, dan pemuatan) terdistribusi Google Cloud yang menyediakan platform untuk menjalankan pipeline data guna membaca dan memproses data dalam jumlah besar secara paralel di beberapa mesin. Template Dataflow SourceDB To Spanner dirancang untuk melakukan pembacaan yang sangat paralel dari Cassandra, mengubah data sumber sesuai kebutuhan, dan menulis ke Spanner sebagai database target.
Lakukan langkah-langkah dalam petunjuk Migrasi Massal Cassandra ke Spanner menggunakan file konfigurasi Cassandra.
Memvalidasi data untuk memastikan integritas
Validasi data selama migrasi database sangat penting untuk memastikan akurasi dan integritas data. Proses ini melibatkan perbandingan data antara database Cassandra sumber dan Spanner target untuk mengidentifikasi perbedaan, seperti data yang hilang, rusak, atau tidak cocok. Teknik validasi data umum mencakup checksum, jumlah baris, dan perbandingan data mendetail, yang semuanya bertujuan untuk menjamin bahwa data yang dimigrasikan adalah representasi yang akurat dari data asli.
Setelah migrasi data massal selesai, dan saat penulisan ganda masih aktif, Anda perlu memvalidasi konsistensi data dan memperbaiki perbedaan. Perbedaan antara Cassandra dan Spanner dapat terjadi selama fase penulisan ganda karena berbagai alasan, termasuk:
- Penulisan ganda gagal. Operasi tulis mungkin berhasil di satu database, tetapi gagal di database lainnya karena masalah jaringan sementara atau error lainnya.
- Transaksi ringan (LWT). Jika aplikasi Anda menggunakan operasi LWT (bandingkan dan tetapkan), operasi ini mungkin berhasil di satu database, tetapi gagal di database lainnya karena perbedaan dalam set data.
- Kueri per detik (QPS) tinggi pada satu kunci utama. Dengan beban tulis yang sangat tinggi ke kunci partisi yang sama, urutan peristiwa mungkin berbeda antara asal dan target karena perbedaan waktu perjalanan pulang pergi jaringan, yang berpotensi menyebabkan inkonsistensi.
Tugas massal dan penulisan ganda berjalan secara paralel: Migrasi massal yang berjalan secara paralel dengan penulisan ganda dapat menyebabkan perbedaan karena berbagai kondisi persaingan, seperti berikut:
- Baris tambahan di Spanner: jika migrasi massal berjalan saat penulisan ganda aktif, aplikasi dapat menghapus baris yang telah dibaca oleh tugas migrasi massal dan ditulis ke target.
- Kondisi persaingan antara penulisan massal dan ganda: mungkin ada kondisi persaingan lain-lain di mana tugas massal membaca baris dari Cassandra dan data dari baris tersebut menjadi tidak valid saat penulisan masuk memperbarui baris di Spanner setelah penulisan ganda selesai.
- Update kolom parsial: mengupdate subset kolom pada baris yang ada akan membuat entri di Spanner dengan kolom lain sebagai null. Karena update massal tidak menimpa baris yang ada, hal ini menyebabkan baris berbeda antara Cassandra dan Spanner.
Langkah ini berfokus pada validasi dan rekonsiliasi data antara database asal dan target. Validasi melibatkan perbandingan asal dan target untuk mengidentifikasi inkonsistensi, sedangkan rekonsiliasi berfokus pada penyelesaian inkonsistensi ini untuk mencapai konsistensi data.
Membandingkan data antara Cassandra dan Spanner
Sebaiknya lakukan validasi pada jumlah baris dan konten baris yang sebenarnya.
Memilih cara membandingkan data (pencocokan jumlah dan baris) bergantung pada toleransi aplikasi Anda terhadap inkonsistensi data dan persyaratan Anda untuk validasi yang tepat.
Ada dua cara untuk memvalidasi data:
Validasi aktif dilakukan saat penulisan ganda aktif. Dalam skenario ini, data di database Anda masih diperbarui. Mungkin tidak mungkin untuk mencapai kecocokan persis dalam jumlah baris atau konten baris antara Cassandra dan Spanner. Tujuannya adalah untuk memastikan bahwa perbedaan apa pun hanya disebabkan oleh beban aktif pada database dan bukan karena error lainnya. Jika perbedaan berada dalam batas ini, Anda dapat melanjutkan peralihan.
Validasi statis memerlukan periode nonaktif. Jika persyaratan Anda memerlukan validasi statis yang kuat dengan jaminan konsistensi data yang tepat, Anda mungkin perlu menghentikan semua penulisan ke kedua database untuk sementara. Kemudian, Anda dapat memvalidasi data dan menyelaraskan perbedaan pada database Spanner.
Pilih waktu validasi dan alat yang sesuai berdasarkan persyaratan spesifik Anda untuk konsistensi data dan waktu nonaktif yang dapat diterima.
Membandingkan jumlah baris di Cassandra dan Spanner
Salah satu metode validasi data adalah dengan membandingkan jumlah baris dalam tabel di database sumber dan target. Ada beberapa cara untuk melakukan validasi jumlah:
Saat melakukan migrasi dengan set data kecil (kurang dari 10 juta baris per tabel), Anda dapat menggunakan skrip pencocokan jumlah ini untuk menghitung baris di Cassandra dan Spanner. Pendekatan ini menampilkan jumlah yang tepat dalam waktu singkat. Waktu tunggu default di Cassandra adalah 10 detik. Pertimbangkan untuk menaikkan waktu tunggu permintaan driver dan waktu tunggu sisi server jika skrip mengalami waktu tunggu habis sebelum menyelesaikan penghitungan.
Saat memigrasikan set data besar (lebih dari 10 juta baris per tabel), perlu diingat bahwa meskipun kueri penghitungan Spanner dapat diskalakan dengan baik, kueri Cassandra cenderung mengalami waktu tunggu habis. Dalam kasus tersebut, sebaiknya gunakan alat DataStax Bulk Loader untuk mendapatkan baris jumlah dari tabel Cassandra. Untuk jumlah Spanner, penggunaan fungsi SQL
count(*)sudah cukup untuk sebagian besar beban skala besar. Sebaiknya jalankan Pemuat Massal untuk setiap tabel Cassandra dan ambil jumlah dari tabel Spanner, lalu bandingkan keduanya. Hal ini dapat dilakukan secara manual atau menggunakan skrip.
Validasi untuk ketidakcocokan baris
Sebaiknya Anda membandingkan baris dari database asal dan target untuk mengidentifikasi ketidakcocokan antar-baris. Ada dua cara untuk melakukan validasi baris. Yang Anda gunakan bergantung pada persyaratan aplikasi Anda:
- Memvalidasi sekumpulan baris acak.
- Validasi seluruh set data.
Memvalidasi sampel baris acak
Memvalidasi seluruh set data memerlukan biaya dan waktu yang besar untuk workload yang besar. Dalam kasus ini, Anda dapat menggunakan pengambilan sampel untuk memvalidasi subkumpulan data acak guna memeriksa ketidakcocokan dalam baris. Salah satu cara untuk melakukannya adalah dengan memilih baris acak di Cassandra dan mengambil baris yang sesuai di Spanner, lalu membandingkan nilai (atau hash baris).
Keuntungan dari metode ini adalah Anda dapat menyelesaikan pemeriksaan lebih cepat daripada memeriksa seluruh set data, dan cara menjalankannya pun mudah. Kekurangannya adalah karena merupakan subset data, mungkin masih ada perbedaan dalam data yang ada untuk kasus ekstrem.
Untuk mengambil sampel baris acak dari Cassandra, Anda harus melakukan hal berikut:
- Buat angka acak dalam rentang token [
-2^63,2^63 - 1]. - Ambil baris
WHERE token(PARTITION_KEY) > GENERATED_NUMBER.
Skrip sampel validation.go
mengambil baris secara acak dan memvalidasinya dengan baris di database Spanner.
Memvalidasi seluruh set data
Untuk memvalidasi seluruh set data, ambil semua baris di database Cassandra asal. Gunakan kunci utama untuk mengambil semua baris database Spanner yang sesuai. Kemudian, Anda dapat membandingkan baris untuk melihat perbedaannya. Untuk set data besar, Anda dapat menggunakan framework berbasis MapReduce, seperti Apache Spark atau Apache Beam, untuk memvalidasi seluruh set data secara andal dan efisien.
Keuntungannya adalah validasi penuh memberikan keyakinan yang lebih tinggi terhadap konsistensi data. Kekurangannya adalah menambahkan beban baca di Cassandra dan memerlukan investasi untuk membuat alat yang kompleks untuk set data besar. Validasi pada set data besar juga memerlukan waktu yang lebih lama untuk diselesaikan.
Salah satu cara untuk melakukannya adalah dengan mempartisi rentang token dan membuat kueri ring Cassandra secara paralel. Untuk setiap baris Cassandra, baris Spanner yang setara diambil menggunakan kunci partisi. Kedua baris ini kemudian dibandingkan untuk mengetahui perbedaannya. Untuk mengetahui petunjuk yang harus diikuti saat membuat tugas validator, lihat Tips untuk memvalidasi Cassandra menggunakan pencocokan baris.
Menyelesaikan perbedaan data atau jumlah baris
Bergantung pada persyaratan konsistensi data, Anda dapat menyalin baris dari Cassandra ke Spanner untuk menyelesaikan perbedaan yang teridentifikasi selama fase validasi. Salah satu cara untuk melakukan rekonsiliasi adalah memperluas alat yang digunakan untuk validasi set data lengkap, dan menyalin baris yang benar dari Cassandra ke database Spanner target jika ketidakcocokan ditemukan. Untuk mengetahui informasi selengkapnya, lihat Pertimbangan penerapan.
Arahkan aplikasi Anda ke Spanner, bukan Cassandra
Setelah Anda memvalidasi akurasi dan integritas data setelah migrasi, pilih waktu untuk memigrasikan aplikasi agar mengarah ke Spanner, bukan Cassandra (atau ke adaptor proxy yang digunakan untuk migrasi data langsung). Proses ini disebut peralihan.
Untuk melakukan peralihan, ikuti langkah-langkah berikut:
Buat perubahan konfigurasi untuk aplikasi klien yang memungkinkannya terhubung langsung ke instance Spanner menggunakan salah satu metode berikut:
- Hubungkan Cassandra ke Cassandra Adapter yang berjalan sebagai sidecar.
- Ubah file JAR driver dengan klien endpoint.
Terapkan perubahan yang Anda siapkan pada langkah sebelumnya untuk mengarahkan aplikasi Anda ke Spanner.
Siapkan pemantauan untuk aplikasi Anda guna memantau error atau masalah performa. Pantau metrik Spanner menggunakan Cloud Monitoring. Untuk mengetahui informasi selengkapnya, lihat Memantau instance dengan Cloud Monitoring.
Setelah pengalihan berhasil dan operasi stabil, nonaktifkan instance ZDM Proxy dan Cassandra-Spanner Proxy.
Melakukan replikasi terbalik dari Spanner ke Cassandra
Anda dapat melakukan replikasi terbalik menggunakan template Dataflow Spanner to
SourceDB.
Replikasi terbalik berguna saat Anda mengalami masalah tak terduga dengan
Spanner dan perlu melakukan failover ke database Cassandra
asli dengan gangguan minimal pada layanan.
Tips untuk memvalidasi Cassandra menggunakan pencocokan baris
Melakukan pemindaian tabel penuh di Cassandra (atau
database lainnya) menggunakan SELECT * akan lambat dan tidak efisien. Untuk mengatasi masalah ini, bagi set data Cassandra menjadi partisi yang mudah dikelola dan proses partisi secara bersamaan. Untuk melakukannya, Anda harus melakukan hal berikut:
- Membagi set data menjadi rentang token
- Membuat kueri partisi secara paralel
- Membaca data dalam setiap partisi
- Mengambil baris yang sesuai dari Spanner
- Alat validasi desain untuk ekstensibilitas
- Melaporkan dan mencatat ketidakcocokan
Membagi set data menjadi rentang token
Cassandra mendistribusikan data di seluruh node berdasarkan token kunci partisi.
Rentang token untuk cluster Cassandra mencakup dari -2^63 hingga 2^63 -
1. Anda dapat menentukan jumlah tetap rentang token berukuran sama untuk membagi
seluruh ruang kunci menjadi partisi yang lebih kecil. Sebaiknya Anda membagi rentang token dengan parameter partition_size yang dapat dikonfigurasi dan dapat disesuaikan untuk memproses seluruh rentang dengan cepat.
Mengkueri partisi secara paralel
Setelah menentukan rentang token, Anda dapat meluncurkan beberapa proses atau
thread paralel, yang masing-masing bertanggung jawab untuk memvalidasi data dalam rentang tertentu. Untuk setiap rentang, Anda dapat membuat kueri CQL menggunakan
fungsi token()
pada kunci partisi (pk).
Contoh kueri untuk rentang token tertentu akan terlihat seperti berikut:
SELECT *
FROM your_keyspace.your_table
WHERE token(pk) >= partition_min_token AND token(pk) <= partition_max_token;
Dengan melakukan iterasi melalui rentang token yang ditentukan dan menjalankan kueri ini secara paralel terhadap cluster Cassandra asal (atau melalui proxy ZDM yang dikonfigurasi untuk membaca dari Cassandra), Anda dapat membaca data secara efisien dengan cara terdistribusi.
Membaca data dalam setiap partisi
Setiap proses paralel menjalankan kueri berbasis rentang dan mengambil subset data dari Cassandra. Periksa jumlah partisi data yang diambil untuk memastikan keseimbangan antara paralelisme dan penggunaan memori.
Mengambil baris yang sesuai dari Spanner
Untuk setiap baris yang diambil dari Cassandra, ambil baris yang sesuai dari database Spanner target Anda menggunakan kunci baris sumber.
Membandingkan baris untuk mengidentifikasi ketidakcocokan
Setelah memiliki baris Cassandra dan baris Spanner yang sesuai (jika ada), Anda perlu membandingkan kolomnya untuk mengidentifikasi ketidakcocokan. Perbandingan ini harus mempertimbangkan potensi perbedaan jenis data dan transformasi apa pun yang diterapkan selama migrasi. Sebaiknya tentukan kriteria yang jelas untuk apa yang dianggap sebagai ketidakcocokan berdasarkan persyaratan aplikasi Anda.
Alat validasi desain untuk ekstensibilitas
Rancang alat validasi Anda dengan kemungkinan memperluasnya untuk rekonsiliasi. Misalnya, Anda dapat menambahkan kemampuan untuk menulis data yang benar dari Cassandra ke Spanner untuk ketidakcocokan yang teridentifikasi.
Melaporkan dan mencatat ketidakcocokan
Sebaiknya Anda mencatat setiap ketidakcocokan yang teridentifikasi dengan konteks yang memadai untuk memungkinkan penyelidikan dan rekonsiliasi. Hal ini dapat mencakup kunci utama, kolom tertentu yang berbeda, dan nilai dari Cassandra dan Spanner. Anda mungkin juga ingin menggabungkan statistik tentang jumlah dan jenis ketidakcocokan yang ditemukan.
Mengaktifkan dan menonaktifkan TTL pada data Cassandra
Bagian ini menjelaskan cara mengaktifkan dan menonaktifkan time to live (TTL) pada data Cassandra di tabel Spanner. Untuk ringkasan, lihat Time to live (TTL).
Mengaktifkan TTL pada data Cassandra
Untuk contoh di bagian ini, asumsikan Anda memiliki tabel dengan skema berikut:
CREATE TABLE Singers (
SingerId INT64 OPTIONS (cassandra_type = 'bigint'),
AlbumId INT64 OPTIONS (cassandra_type = 'int'),
) PRIMARY KEY (SingerId);
Untuk mengaktifkan TTL tingkat baris pada tabel yang ada, lakukan hal berikut:
Tambahkan kolom stempel waktu untuk menyimpan stempel waktu habis masa berlaku untuk setiap baris. Dalam contoh ini, kolom diberi nama
ExpiredAt, tetapi Anda dapat menggunakan nama apa pun.ALTER TABLE Singers ADD COLUMN ExpiredAt TIMESTAMP;Tambahkan kebijakan penghapusan baris untuk menghapus baris yang lebih lama dari waktu habis masa berlaku secara otomatis.
INTERVAL 0 DAYberarti baris akan segera dihapus setelah mencapai waktu habis masa berlaku.ALTER TABLE Singers ADD ROW DELETION POLICY (OLDER_THAN(ExpiredAt, INTERVAL 0 DAY));Setel
cassandra_ttl_modekerowuntuk mengaktifkan TTL tingkat baris.ALTER TABLE Singers SET OPTIONS (cassandra_ttl_mode = 'row');Secara opsional, tetapkan
cassandra_default_ttluntuk mengonfigurasi nilai TTL default. Nilainya dalam hitungan detik.ALTER TABLE Singers SET OPTIONS (cassandra_default_ttl = 10000);
Menonaktifkan TTL pada data Cassandra
Untuk contoh di bagian ini, asumsikan Anda memiliki tabel dengan skema berikut:
CREATE TABLE Singers (
SingerId INT64 OPTIONS ( cassandra_type = 'bigint' ),
AlbumId INT64 OPTIONS ( cassandra_type = 'int' ),
ExpiredAt TIMESTAMP,
) PRIMARY KEY (SingerId),
ROW DELETION POLICY (OLDER_THAN(ExpiredAt, INTERVAL 0 DAY)), OPTIONS (cassandra_ttl_mode = 'row');
Untuk menonaktifkan TTL tingkat baris pada tabel yang ada, lakukan hal berikut:
Secara opsional, setel
cassandra_default_ttlke nol untuk menghapus nilai TTL default.ALTER TABLE Singers SET OPTIONS (cassandra_default_ttl = 0);Setel
cassandra_ttl_modekenoneuntuk menonaktifkan TTL tingkat baris.ALTER TABLE Singers SET OPTIONS (cassandra_ttl_mode = 'none');Hapus kebijakan penghapusan baris.
ALTER TABLE Singers DROP ROW DELETION POLICY;Hapus kolom stempel waktu masa berlaku.
ALTER TABLE Singers DROP COLUMN ExpiredAt;
Pertimbangan penerapan
- Framework dan library: Untuk validasi kustom yang skalabel, gunakan framework berbasis MapReduce seperti Apache Spark atau Dataflow (Beam). Pilih bahasa yang didukung (Python, Scala, Java) dan gunakan konektor untuk Cassandra dan Spanner, misalnya, menggunakan proxy. Framework ini memungkinkan pemrosesan paralel yang efisien untuk set data besar guna validasi yang komprehensif.
- Penanganan error dan percobaan ulang: Terapkan penanganan error yang andal untuk mengelola potensi masalah seperti masalah konektivitas jaringan atau ketidaktersediaan sementara salah satu database. Pertimbangkan untuk menerapkan mekanisme percobaan ulang untuk kegagalan sementara.
- Konfigurasi: Buat rentang token, detail koneksi untuk kedua database, dan logika perbandingan yang dapat dikonfigurasi.
- Penyesuaian performa: Bereksperimenlah dengan jumlah proses paralel dan ukuran rentang token untuk mengoptimalkan proses validasi untuk lingkungan dan volume data tertentu. Pantau beban di cluster Cassandra dan Spanner Anda selama validasi.
Langkah Berikutnya
- Lihat perbandingan antara Spanner dan Cassandra di ringkasan Cassandra.
- Pelajari cara Menghubungkan ke Spanner menggunakan Cassandra Adapter.