En esta página se explica cómo migrar tu base de datos NoSQL de Cassandra a Spanner.
Cassandra y Spanner son bases de datos distribuidas a gran escala creadas para aplicaciones que requieren alta escalabilidad y baja latencia. Aunque ambas bases de datos pueden admitir cargas de trabajo NoSQL exigentes, Spanner ofrece funciones avanzadas para el modelado, las consultas y las operaciones transaccionales de datos. Spanner admite el lenguaje de consulta de Cassandra (CQL).
Para obtener más información sobre cómo cumple Spanner los criterios de las bases de datos NoSQL, consulta Spanner para cargas de trabajo no relacionales.
Restricciones de migración
Para que la migración de Cassandra al endpoint de Cassandra en Spanner se realice correctamente, consulta Spanner para usuarios de Cassandra para saber cómo se diferencian la arquitectura, el modelo de datos y los tipos de datos de Spanner de los de Cassandra. Ten en cuenta las diferencias funcionales entre Spanner y Cassandra antes de empezar la migración.
Proceso de migración
El proceso de migración se divide en los siguientes pasos:
- Convierte tu esquema y tu modelo de datos.
- Configura la escritura dual para los datos entrantes.
- Exporta en bloque tu historial de datos de Cassandra a Spanner.
- Valida los datos para asegurarte de que se mantienen íntegros durante todo el proceso de migración.
- Dirige tu aplicación a Spanner en lugar de a Cassandra.
- Opcional. Realiza la replicación inversa de Spanner a Cassandra.
Convertir el esquema y el modelo de datos
El primer paso para migrar los datos de Cassandra a Spanner es adaptar el esquema de datos de Cassandra al de Spanner, al tiempo que se gestionan las diferencias en los tipos de datos y el modelado.
La sintaxis de declaración de tablas es bastante similar en Cassandra y Spanner. Usted especifica el nombre de la tabla, los nombres y tipos de las columnas, y la clave principal que identifica de forma exclusiva una fila. La diferencia principal es que Cassandra se particiona por hash y distingue entre las dos partes de la clave principal: la clave de partición con hash y las columnas de clustering ordenadas, mientras que Spanner se particiona por intervalo. Puedes considerar que la clave principal de Spanner solo tiene columnas de clustering, con particiones que se mantienen automáticamente en segundo plano. Al igual que Cassandra, Spanner admite claves primarias compuestas.
Te recomendamos que sigas estos pasos para convertir tu esquema de datos de Cassandra a Spanner:
- Consulta la descripción general de Cassandra para conocer las similitudes y diferencias entre los esquemas de datos de Cassandra y Spanner, así como para saber cómo asignar diferentes tipos de datos.
- Usa la herramienta de esquema de Cassandra a Spanner para extraer y convertir tu esquema de datos de Cassandra a Spanner.
- Antes de iniciar la migración de datos, asegúrese de que las tablas de Spanner se han creado con los esquemas de datos adecuados.
Configurar la migración activa de los datos entrantes
Para realizar una migración sin tiempo de inactividad de Cassandra a Spanner, configura la migración activa de los datos entrantes. La migración activa se centra en minimizar los periodos de inactividad y garantizar la disponibilidad continua de las aplicaciones mediante la replicación en tiempo real.
Empieza con el proceso de migración en directo antes de la migración masiva. En el siguiente diagrama se muestra la vista de arquitectura de una migración en directo.
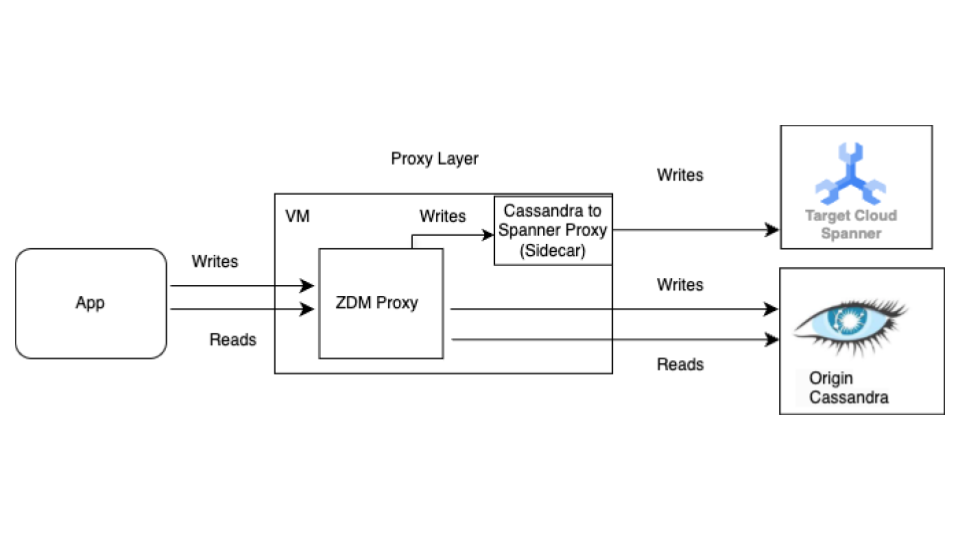
La arquitectura de migración en directo tiene los siguientes componentes clave:
- Origen: tu base de datos Cassandra de origen.
- Destino: la base de datos de Spanner a la que vas a migrar. Se presupone que ya has aprovisionado tu instancia de Spanner y tu base de datos con un esquema compatible con tu esquema de Cassandra (con las adaptaciones necesarias para el modelo de datos y las funciones de Spanner).
Proxy de ZDM de DataStax: El proxy de ZDM es un proxy de escritura dual creado por DataStax para migraciones de Cassandra a Cassandra. El proxy imita un clúster de Cassandra, lo que permite que una aplicación use el proxy sin tener que modificarla. Esta herramienta es con la que se comunica tu aplicación y que usa internamente para realizar escrituras duales en las bases de datos de origen y de destino. Aunque normalmente se usa con clústeres de Cassandra como origen y destino, nuestra configuración lo configura para que use el proxy de Cassandra a Spanner (que se ejecuta como un sidecar) como destino. De esta forma, cada lectura entrante solo se reenvía al origen y devuelve la respuesta del origen a la aplicación. Además, cada escritura entrante se dirige tanto al origen como al destino.
- Si las escrituras en el origen y el destino se realizan correctamente, la aplicación recibe un mensaje de éxito.
- Si las operaciones de escritura en el origen fallan y las operaciones de escritura en el destino se completan correctamente, la aplicación recibe el mensaje de error del origen.
- Si las operaciones de escritura en el destino fallan y las operaciones de escritura en el origen se realizan correctamente, la aplicación recibe el mensaje de error del destino.
- Si se produce un error al escribir en el origen y en el destino, la aplicación recibe el mensaje de error del origen.
Proxy de Cassandra a Spanner: una aplicación sidecar que intercepta el tráfico de Cassandra Query Language (CQL) destinado a Cassandra y lo traduce a llamadas a la API de Spanner. Permite que las aplicaciones y las herramientas interactúen con Spanner mediante el cliente de Cassandra.
Aplicación cliente: la aplicación que lee y escribe datos en el clúster de Cassandra de origen.
Configuración del proxy
El primer paso para realizar una migración en directo es implementar y configurar los proxies. El proxy de Cassandra-Spanner se ejecuta como un contenedor auxiliar junto al proxy de ZDM. El proxy sidecar actúa como destino de las operaciones de escritura del proxy de ZDM en Spanner.
Pruebas de una sola instancia con Docker
Puedes ejecutar una sola instancia del proxy de forma local o en una VM para realizar pruebas iniciales con Docker.
Requisitos previos
- Confirma que la VM en la que se ejecuta el proxy tiene conectividad de red con la aplicación, la base de datos de Cassandra de origen y la base de datos de Spanner.
- Instala Docker.
- Confirma que hay un archivo de clave de cuenta de servicio con los permisos necesarios para escribir en tu instancia y base de datos de Spanner.
- Configura tu instancia, base de datos y esquema de Spanner.
- Asegúrate de que el nombre de la base de datos de Spanner sea el mismo que el del espacio de claves de Origin Cassandra.
- Clona el repositorio spanner-migration-tool.
Descargar y configurar el proxy de ZDM
- Ve al directorio
sources/cassandra. - Asegúrate de que los archivos
entrypoint.shyDockerfileestén en el mismo directorio que el archivo Dockerfile. Ejecuta el siguiente comando para compilar una imagen local:
docker build -t zdm-proxy:latest .
Ejecutar el proxy de ZDM
- Asegúrate de que
zdm-config.yamlykeyfilesestén presentes de forma local donde se ejecute el siguiente comando. - Abre el archivo de ejemplo zdm-config yaml.
- Consulta la lista detallada de las marcas que acepta ZDM.
Usa el siguiente comando para ejecutar el contenedor:
sudo docker run --restart always -d -p 14002:14002 \ -v zdm-config-file-path:/zdm-config.yaml \ -v local_keyfile:/var/run/secret/keys.json \ -e SPANNER_PROJECT=SPANNER_PROJECT_ID \ -e SPANNER_INSTANCE=SPANNER_INSTANCE_ID \ -e SPANNER_DATABASE=SPANNER_DATABASE_ID \ -e GOOGLE_APPLICATION_CREDENTIALS="/var/run/secret/keys.json" \ -e ZDM_CONFIG=/zdm-config.yaml \ zdm-proxy:latest
Verificar la configuración del proxy
Usa el comando
docker logspara comprobar si hay errores en los registros del proxy durante el inicio:docker logs container-idEjecuta el comando
cqlshpara comprobar que el proxy se ha configurado correctamente:cqlsh VM-IP 14002Sustituye VM-IP por la dirección IP de tu máquina virtual.
Configuración de producción con Terraform:
En un entorno de producción, te recomendamos que uses las plantillas de Terraform proporcionadas para orquestar la implementación del proxy de Cassandra-Spanner.
Requisitos previos
- Instala Terraform.
- Confirma que la aplicación tiene credenciales predeterminadas con los permisos adecuados para crear recursos.
- Confirma que el archivo de clave de servicio tiene los permisos pertinentes para escribir en Spanner. El proxy usa este archivo.
- Configura tu instancia, base de datos y esquema de Spanner.
- Confirma que el archivo Dockerfile,
entrypoint.shy el archivo de clave de servicio se encuentran en el mismo directorio que el archivomain.tf.
Configurar variables de Terraform
- Asegúrate de tener la plantilla de Terraform para la implementación del proxy.
- Actualiza el archivo
terraform.tfvarscon las variables de tu configuración.
Despliegue de plantillas con Terraform
La secuencia de comandos de Terraform hace lo siguiente:
- Crea VMs optimizadas para contenedores en función de un recuento especificado.
- Crea archivos
zdm-config.yamlpara cada máquina virtual y le asigna un índice de topología. El proxy de ZDM requiere configuraciones de varias VMs para configurar la topología mediante los camposPROXY_TOPOLOGY_ADDRESSESyPROXY_TOPOLOGY_INDEXdel archivo de configuraciónyaml. - Transfiere los archivos pertinentes a cada VM, ejecuta Docker Build de forma remota e inicia los contenedores.
Para implementar la plantilla, siga estos pasos:
Usa el comando
terraform initpara inicializar Terraform:terraform initEjecuta el comando
terraform planpara ver qué cambios tiene previsto hacer Terraform en tu infraestructura:terraform plan -var-file="terraform.tfvars"Cuando los recursos tengan un aspecto adecuado, ejecuta el comando
terraform apply:terraform apply -var-file="terraform.tfvars"Cuando se detenga la secuencia de comandos de Terraform, ejecuta el comando
cqlshpara asegurarte de que se puede acceder a las VMs.cqlsh VM-IP 14002Sustituye VM-IP por la dirección IP de tu máquina virtual.
Dirige tus aplicaciones cliente al proxy de ZDM
Modifica la configuración de tu aplicación cliente y define los puntos de contacto como las VMs que ejecutan los proxies en lugar de tu clúster de Cassandra de origen.
Prueba tu aplicación a fondo. Verifica que las operaciones de escritura se apliquen tanto al clúster de Cassandra de origen como a tu base de datos de Spanner. Para ello, comprueba que también llegan a Spanner mediante el proxy de Cassandra-Spanner. Las lecturas se sirven desde el origen de Cassandra.
Exportar datos en bloque a Spanner
La migración de datos en bloque implica transferir grandes volúmenes de datos entre bases de datos, lo que suele requerir una planificación y una ejecución cuidadosas para minimizar el tiempo de inactividad y garantizar la integridad de los datos. Entre las técnicas se incluyen los procesos de ETL (extracción, transformación y carga), la replicación directa de bases de datos y las herramientas de migración especializadas. Todas ellas tienen como objetivo mover los datos de forma eficiente y, al mismo tiempo, conservar su estructura y precisión.
Te recomendamos que uses la plantilla de Dataflow SourceDB To Spanner para migrar tus datos de Cassandra a Spanner de forma masiva. Dataflow es el servicio de extracción, transformación y carga (ETL) distribuido que proporciona una plataforma para ejecutar flujos de procesamiento de datos con el fin de leer y procesar grandes cantidades de datos en paralelo en varias máquinas. Google Cloud La plantilla de Dataflow SourceDB To Spanner se ha diseñado para realizar lecturas altamente paralelizadas de Cassandra, transformar los datos de origen según sea necesario y escribir en Spanner como base de datos de destino.
Sigue los pasos que se indican en las instrucciones de migración masiva de Cassandra a Spanner con el archivo de configuración de Cassandra.
Validar los datos para asegurar su integridad
La validación de datos durante la migración de bases de datos es fundamental para asegurar la precisión y la integridad de los datos. Consiste en comparar los datos de las bases de datos de Cassandra de origen y de Spanner de destino para identificar discrepancias, como datos que faltan, están dañados o no coinciden. Las técnicas generales de validación de datos incluyen sumas de comprobación, recuentos de filas y comparaciones detalladas de datos, todo ello con el objetivo de garantizar que los datos migrados sean una representación precisa de los originales.
Una vez completada la migración masiva de datos y mientras la escritura dual siga activa, debe validar la coherencia de los datos y corregir las discrepancias. Las diferencias entre Cassandra y Spanner pueden producirse durante la fase de escritura dual por varios motivos, entre los que se incluyen los siguientes:
- Escrituras duales fallidas. Una operación de escritura puede completarse correctamente en una base de datos, pero fallar en la otra debido a problemas de red transitorios u otros errores.
- Transacciones ligeras (LWT). Si tu aplicación usa operaciones LWT (comparar y definir), es posible que se completen en una base de datos, pero no en otra, debido a las diferencias en los conjuntos de datos.
- Un número elevado de consultas por segundo (CPS) en una sola clave principal. Si se producen cargas de escritura muy altas en la misma clave de partición, el orden de los eventos puede ser diferente entre el origen y el destino debido a los diferentes tiempos de ida y vuelta de la red, lo que puede provocar incoherencias.
Trabajo en bloque y escritura dual que se ejecutan en paralelo: la migración en bloque que se ejecuta en paralelo con la escritura dual puede provocar divergencias debido a varias condiciones de carrera, como las siguientes:
- Filas adicionales en Spanner: si la migración masiva se ejecuta mientras las escrituras duales están activas, la aplicación podría eliminar una fila que ya ha leído el trabajo de migración masiva y que se ha escrito en el destino.
- Condiciones de carrera entre escrituras masivas y duales: puede haber otras condiciones de carrera varias en las que el trabajo masivo lea una fila de Cassandra y los datos de la fila se queden obsoletos cuando las escrituras entrantes actualicen la fila en Spanner después de que finalicen las escrituras duales.
- Actualizaciones parciales de columnas: al actualizar un subconjunto de columnas de una fila, se crea una entrada en Spanner con otras columnas como nulas. Como las actualizaciones masivas no sobrescriben las filas, esto provoca que las filas difieran entre Cassandra y Spanner.
En este paso, se valida y concilia la información entre las bases de datos de origen y de destino. La validación consiste en comparar el origen y el destino para identificar incoherencias, mientras que la conciliación se centra en resolver estas incoherencias para lograr la coherencia de los datos.
Comparar datos entre Cassandra y Spanner
Te recomendamos que realices validaciones tanto en el número de filas como en el contenido real de las filas.
La forma de comparar los datos (tanto el recuento como la coincidencia de filas) depende de la tolerancia de tu aplicación a las incoherencias de los datos y de tus requisitos de validación exacta.
Hay dos formas de validar los datos:
La validación activa se lleva a cabo mientras la escritura dual está activa. En este caso, los datos de tus bases de datos se siguen actualizando. Es posible que no se pueda conseguir una coincidencia exacta en el número de filas o en el contenido de las filas entre Cassandra y Spanner. El objetivo es asegurarse de que las diferencias se deban únicamente a la carga activa de las bases de datos y no a otros errores. Si las discrepancias están dentro de estos límites, puede continuar con el cambio.
La validación estática requiere un tiempo de inactividad. Si necesitas una validación estática y sólida con una garantía de coherencia de datos exacta, puede que tengas que detener temporalmente todas las escrituras en ambas bases de datos. Después, puede validar los datos y conciliar las diferencias en su base de datos de Spanner.
Elige el momento de validación y las herramientas adecuadas en función de tus requisitos específicos de coherencia de los datos y del tiempo de inactividad aceptable.
Comparar el número de filas de Cassandra y Spanner
Un método de validación de datos consiste en comparar el número de filas de las tablas de las bases de datos de origen y de destino. Hay varias formas de realizar validaciones de recuento:
Cuando migres conjuntos de datos pequeños (menos de 10 millones de filas por tabla), puedes usar esta secuencia de comandos de recuento coincidente para contar las filas de Cassandra y Spanner. Este enfoque devuelve recuentos exactos en poco tiempo. El tiempo de espera predeterminado en Cassandra es de 10 segundos. Si el script agota el tiempo de espera antes de terminar el recuento, te recomendamos que aumentes el tiempo de espera de la solicitud del controlador y el tiempo de espera del lado del servidor.
Cuando migres conjuntos de datos grandes (más de 10 millones de filas por tabla), ten en cuenta que, aunque las consultas de recuento de Spanner se escalan bien, las consultas de Cassandra suelen agotar el tiempo de espera. En estos casos, recomendamos usar la herramienta DataStax Bulk Loader para obtener el número de filas de las tablas de Cassandra. Para los recuentos de Spanner, usar la función SQL
count(*)es suficiente para la mayoría de las cargas a gran escala. Te recomendamos que ejecutes Bulk Loader en cada tabla de Cassandra, obtengas los recuentos de la tabla de Spanner y compares ambos. Puedes hacerlo manualmente o con una secuencia de comandos.
Validar si hay un error en las filas
Te recomendamos que compares las filas de las bases de datos de origen y de destino para identificar las diferencias entre ellas. Hay dos formas de realizar validaciones de filas. La que uses dependerá de los requisitos de tu aplicación:
- Valida un conjunto aleatorio de filas.
- Valida todo el conjunto de datos.
Validar una muestra aleatoria de filas
Validar un conjunto de datos completo es caro y lleva mucho tiempo en cargas de trabajo grandes. En estos casos, puedes usar el muestreo para validar un subconjunto aleatorio de los datos y comprobar si hay discrepancias en las filas. Una forma de hacerlo es elegir filas aleatorias en Cassandra y obtener las filas correspondientes en Spanner. Después, compara los valores (o el hash de la fila).
Las ventajas de este método son que terminas más rápido que si revisaras todo el conjunto de datos y que es fácil de ejecutar. La desventaja es que, como se trata de un subconjunto de los datos, puede que siga habiendo diferencias en los datos de los casos límite.
Para muestrear filas aleatorias de Cassandra, debes hacer lo siguiente:
- Genera números aleatorios en el intervalo de tokens [
-2^63,2^63 - 1]. - Obtener filas
WHERE token(PARTITION_KEY) > GENERATED_NUMBER.
La muestra validation.go
script
obtiene filas aleatoriamente y las valida con las filas de la base de datos de Spanner.
Validar todo el conjunto de datos
Para validar un conjunto de datos completo, obtén todas las filas de la base de datos de Cassandra de origen. Usa las claves principales para obtener todas las filas de la base de datos de Spanner correspondientes. Después, puede comparar las filas para ver las diferencias. En el caso de los conjuntos de datos de gran tamaño, puedes usar un framework basado en MapReduce, como Apache Spark o Apache Beam, para validar todo el conjunto de datos de forma fiable y eficiente.
La ventaja de este método es que la validación completa ofrece una mayor confianza en la coherencia de los datos. Las desventajas son que añade carga de lectura en Cassandra y requiere una inversión para crear herramientas complejas para conjuntos de datos grandes. También puede tardar mucho más en completar la validación en un conjunto de datos grande.
Una forma de hacerlo es particionar los intervalos de tokens y consultar el anillo de Cassandra en paralelo. Por cada fila de Cassandra, se obtiene la fila de Spanner equivalente mediante la clave de partición. Después, se comparan estas dos filas para detectar discrepancias. Para obtener consejos sobre cómo crear trabajos de validación, consulta Consejos para validar Cassandra mediante la coincidencia de filas.
Conciliar las incoherencias en los datos o en el recuento de filas
En función del requisito de coherencia de los datos, puede copiar filas de Cassandra a Spanner para conciliar las discrepancias identificadas durante la fase de validación. Una forma de hacer la conciliación es ampliar la herramienta usada para la validación del conjunto de datos completo y copiar la fila correcta de Cassandra a la base de datos de Spanner de destino si se encuentra alguna discrepancia. Para obtener más información, consulta las consideraciones sobre la implementación.
Dirige tu aplicación a Spanner en lugar de a Cassandra
Después de validar la precisión y la integridad de los datos tras la migración, elige un momento para migrar tu aplicación de forma que apunte a Spanner en lugar de a Cassandra (o al adaptador de proxy usado para la migración de datos activos). Esto se denomina "cambio".
Para llevar a cabo el cambio, sigue estos pasos:
Crea un cambio de configuración para tu aplicación cliente que le permita conectarse directamente a tu instancia de Spanner mediante uno de los siguientes métodos:
- Conecta Cassandra al adaptador de Cassandra que se ejecuta como sidecar.
- Cambia el archivo JAR del controlador por el cliente del endpoint.
Aplica el cambio que has preparado en el paso anterior para dirigir tu aplicación a Spanner.
Configura la monitorización de tu aplicación para detectar errores o problemas de rendimiento. Monitoriza las métricas de Spanner con Cloud Monitoring. Para obtener más información, consulta Monitorizar instancias con Cloud Monitoring.
Una vez que se haya completado el cambio y el funcionamiento sea estable, retira las instancias del proxy de ZDM y del proxy de Cassandra-Spanner.
Realizar la replicación inversa de Spanner a Cassandra
Puedes realizar la replicación inversa con la plantilla de Dataflow Spanner to
SourceDB.
La replicación inversa es útil cuando se producen problemas imprevistos con Spanner y necesitas volver a la base de datos de Cassandra original con la mínima interrupción posible del servicio.
Consejos para validar Cassandra mediante la coincidencia de filas
Es lento e ineficiente realizar análisis completos de tablas en Cassandra (o en cualquier otra base de datos) con SELECT *. Para solucionar este problema, divide el conjunto de datos de Cassandra en particiones gestionables y procesa las particiones simultáneamente. Para ello, debes hacer lo siguiente:
- Dividir el conjunto de datos en intervalos de tokens
- Consultar particiones en paralelo
- Leer datos de cada partición
- Obtener las filas correspondientes de Spanner
- Herramientas de validación de diseño para la extensibilidad
- Informar y registrar las discrepancias
Dividir el conjunto de datos en intervalos de tokens
Cassandra distribuye los datos entre los nodos en función de los tokens de la clave de partición.
El intervalo de tokens de un clúster de Cassandra va de -2^63 a 2^63 -
1. Puedes definir un número fijo de intervalos de tokens de igual tamaño para dividir todo el espacio de claves en particiones más pequeñas. Te recomendamos que dividas el intervalo de tokens con un parámetro partition_size configurable que puedas ajustar para procesar rápidamente todo el intervalo.
Consultar particiones en paralelo
Una vez que hayas definido los intervalos de tokens, podrás iniciar varios procesos o
hilos paralelos, cada uno de los cuales se encargará de validar los datos de un intervalo específico. Para cada intervalo, puede crear consultas de CQL con la tokenfunción
en su clave de partición (pk).
Una consulta de ejemplo para un intervalo de tokens determinado sería la siguiente:
SELECT *
FROM your_keyspace.your_table
WHERE token(pk) >= partition_min_token AND token(pk) <= partition_max_token;
Al iterar en los intervalos de tokens definidos y ejecutar estas consultas en paralelo en tu clúster de Cassandra de origen (o a través del proxy de ZDM configurado para leer de Cassandra), puedes leer datos de forma distribuida de manera eficiente.
Leer datos de cada partición
Cada proceso paralelo ejecuta la consulta basada en el intervalo y recupera un subconjunto de los datos de Cassandra. Comprueba la cantidad de datos recuperados de la partición para asegurarte de que haya un equilibrio entre el paralelismo y el uso de memoria.
Obtener las filas correspondientes de Spanner
Por cada fila obtenida de Cassandra, recupera la fila correspondiente de tu base de datos de Spanner de destino mediante la clave de fila de origen.
Comparar filas para identificar las discrepancias
Una vez que tengas la fila de Cassandra y la fila de Spanner correspondiente (si existe), debes comparar sus campos para identificar cualquier discrepancia. En esta comparación se deben tener en cuenta las posibles diferencias en los tipos de datos y las transformaciones que se hayan aplicado durante la migración. Te recomendamos que definas criterios claros sobre lo que constituye una falta de coincidencia en función de los requisitos de tu aplicación.
Diseñar herramientas de validación para la extensibilidad
Diseña tu herramienta de validación con la posibilidad de ampliarla para la conciliación. Por ejemplo, puede añadir funciones para escribir los datos correctos de Cassandra en Spanner en caso de que se detecten discrepancias.
Informar y registrar las discrepancias
Te recomendamos que registres cualquier discrepancia que detectes con suficiente contexto para que podamos investigar y conciliar los datos. Esto puede incluir las claves principales, los campos específicos que difieren y los valores de Cassandra y Spanner. También puede que quieras agregar estadísticas sobre el número y los tipos de errores encontrados.
Habilitar e inhabilitar el TTL en los datos de Cassandra
En esta sección se describe cómo habilitar e inhabilitar el tiempo de vida (TTL) en los datos de Cassandra de las tablas de Spanner. Para obtener una descripción general, consulta Tiempo de vida (TTL).
Habilitar el TTL en los datos de Cassandra
En los ejemplos de esta sección, supongamos que tiene una tabla con el siguiente esquema:
CREATE TABLE Singers (
SingerId INT64 OPTIONS (cassandra_type = 'bigint'),
AlbumId INT64 OPTIONS (cassandra_type = 'int'),
) PRIMARY KEY (SingerId);
Para habilitar el TTL a nivel de fila en una tabla, sigue estos pasos:
Añade la columna de marca de tiempo para almacenar la marca de tiempo de caducidad de cada fila. En este ejemplo, la columna se llama
ExpiredAt, pero puedes usar el nombre que quieras.ALTER TABLE Singers ADD COLUMN ExpiredAt TIMESTAMP;Añade la política de eliminación de filas para eliminar automáticamente las filas anteriores a la hora de vencimiento.
INTERVAL 0 DAYsignifica que las filas se eliminan inmediatamente al alcanzar la hora de vencimiento.ALTER TABLE Singers ADD ROW DELETION POLICY (OLDER_THAN(ExpiredAt, INTERVAL 0 DAY));Asigna el valor
cassandra_ttl_modearowpara habilitar el TTL a nivel de fila.ALTER TABLE Singers SET OPTIONS (cassandra_ttl_mode = 'row');También puedes definir
cassandra_default_ttlpara configurar el valor de TTL predeterminado. El valor se expresa en segundos.ALTER TABLE Singers SET OPTIONS (cassandra_default_ttl = 10000);
Inhabilitar el TTL en los datos de Cassandra
En los ejemplos de esta sección, supongamos que tiene una tabla con el siguiente esquema:
CREATE TABLE Singers (
SingerId INT64 OPTIONS ( cassandra_type = 'bigint' ),
AlbumId INT64 OPTIONS ( cassandra_type = 'int' ),
ExpiredAt TIMESTAMP,
) PRIMARY KEY (SingerId),
ROW DELETION POLICY (OLDER_THAN(ExpiredAt, INTERVAL 0 DAY)), OPTIONS (cassandra_ttl_mode = 'row');
Para inhabilitar el TTL a nivel de fila en una tabla, sigue estos pasos:
También puedes asignar el valor
cassandra_default_ttla cero para limpiar el valor predeterminado de TTL.ALTER TABLE Singers SET OPTIONS (cassandra_default_ttl = 0);Asigna el valor
noneacassandra_ttl_modepara inhabilitar el TTL a nivel de fila.ALTER TABLE Singers SET OPTIONS (cassandra_ttl_mode = 'none');Elimina la política de eliminación de filas.
ALTER TABLE Singers DROP ROW DELETION POLICY;Elimina la columna de marca de tiempo de caducidad.
ALTER TABLE Singers DROP COLUMN ExpiredAt;
Consideraciones de implementación
- Frameworks y bibliotecas: para la validación personalizada escalable, usa frameworks basados en MapReduce, como Apache Spark o Dataflow (Beam). Elige un lenguaje admitido (Python, Scala o Java) y usa conectores para Cassandra y Spanner, por ejemplo, mediante un proxy. Estos frameworks permiten procesar en paralelo de forma eficiente grandes conjuntos de datos para realizar validaciones completas.
- Gestión de errores y reintentos: implementa una gestión de errores sólida para gestionar posibles problemas, como problemas de conectividad de red o la falta de disponibilidad temporal de cualquiera de las bases de datos. Implementa mecanismos de reintento para los errores transitorios.
- Configuración: haz que los intervalos de tokens, los detalles de conexión de ambas bases de datos y la lógica de comparación se puedan configurar.
- Ajuste del rendimiento: experimenta con el número de procesos paralelos y el tamaño de los intervalos de tokens para optimizar el proceso de validación de tu entorno y volumen de datos específicos. Monitoriza la carga de los clústeres de Cassandra y Spanner durante la validación.
Siguientes pasos
- Consulta una comparación entre Spanner y Cassandra en la descripción general de Cassandra.
- Consulta cómo conectarte a Spanner mediante el adaptador de Cassandra.