In diesem Dokument wird beschrieben, wie Sie das Systemstatistik-Dashboard verwenden, um Spanner-Instanzen und -Datenbanken zu überwachen.
Systemstatistiken
Im Dashboard für Systemstatistiken werden Kurzübersichten und Diagramme für eine ausgewählte Instanz oder Datenbank angezeigt. Es enthält Messwerte für Latenzen, CPU-Auslastung, Speicher, Durchsatz und andere Leistungsstatistiken. Sie können Diagramme für verschiedene Zeiträume abrufen, die von der letzten Stunde bis zu den letzten 30 Tagen reichen.
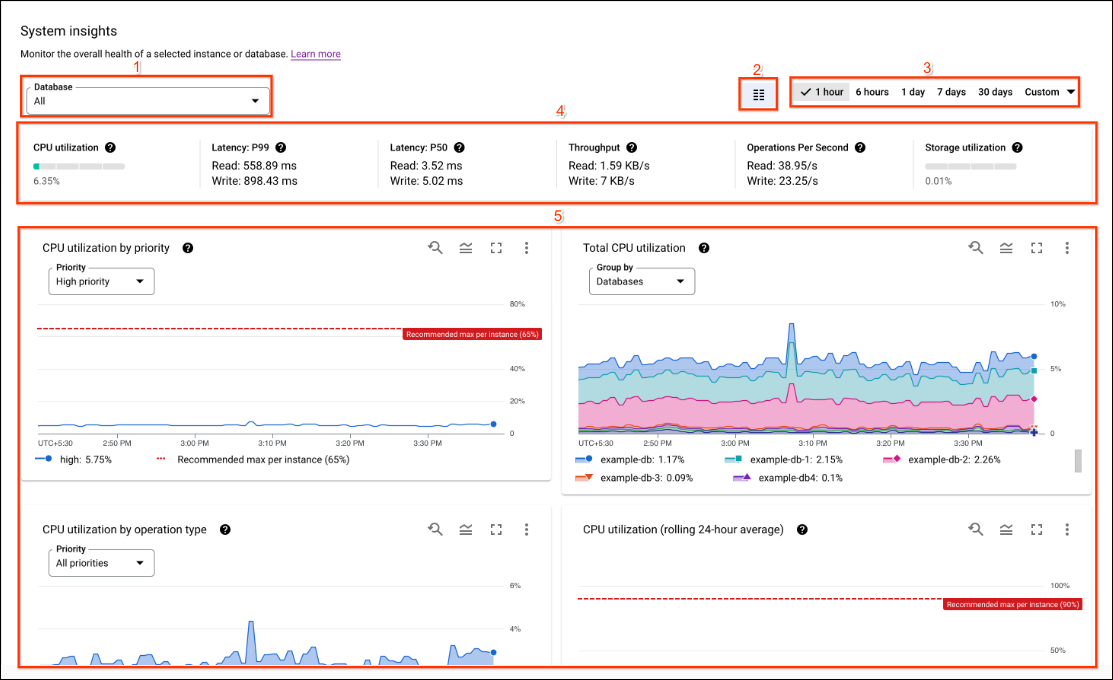
Das Systemstatistik-Dashboard enthält die folgenden Abschnitte. Die Nummern entsprechen dem folgenden Screenshot der Benutzeroberfläche:
- Auswahlfelder für Statistiken:Wählen Sie die Datenbanken, Instanzpartitionen und Regionen aus, die im Dashboard angezeigt werden sollen. In System-Insights werden Instanzpartitionen und Regionsauswahlen angezeigt, wenn mehrere Instanzpartitionen oder Regionen in der Instanz verfügbar sind.
- Zeitraumfilter:Statistiken nach einem Zeitraum filtern, z. B. Stunden, Tage oder ein benutzerdefinierter Zeitraum.
- Dashboard-Auswahl:Hier können Sie benutzerdefinierte Ansichten auswählen oder Systemstatistiken auf die standardmäßige vordefinierte Ansicht zurücksetzen.
- Anmerkungen:Wählen Sie Ereignistypen für Benachrichtigungen zu Statistiken aus, um Diagramme damit zu annotieren.
- Dashboards anpassen:Sie können das Aussehen, die Platzierung und den Inhalt von Dashboard-Widgets und des System-Insights-Dashboards anpassen. In diesem Dokument wird die vordefinierte Dashboard-Präsentation beschrieben.
- Kurzübersichten:Hier werden Statistiken für einen bestimmten Zeitpunkt im ausgewählten Zeitraum angezeigt.
- Diagramme:Hier werden Diagramme zur CPU-Auslastung, zum Durchsatz, zu Latenzen, zur Speichernutzung und mehr angezeigt. Statistikbenachrichtigungen, die über Anmerkungen festgelegt wurden, werden in Diagrammen mit Glockensymbolen angezeigt.
Erforderliche Rollen
Bitten Sie Ihren Administrator, Ihnen die folgenden IAM-Rollen für das Projekt zuzuweisen, um die Berechtigungen zu erhalten, die Sie zum Aufrufen oder Ändern von Statistiken-Dashboards, einschließlich benutzerdefinierter Dashboards, benötigen:
-
So erstellen und bearbeiten Sie benutzerdefinierte Dashboards:
Bearbeiter der Monitoring-Dashboard-Konfiguration (
roles/monitoring.dashboardEditor) -
So öffnen und sehen Sie sich Metrics Explorer-Diagramme an:
Betrachter von Monitoring-Dashboard-Konfigurationen (
roles/monitoring.dashboardViewer) -
So erstellen und bearbeiten Sie Alerts im Metrics Explorer:
Monitoring-Editor (
roles/monitoring.editor)
Weitere Informationen zum Zuweisen von Rollen finden Sie unter Zugriff auf Projekte, Ordner und Organisationen verwalten.
Diese vordefinierten Rollen enthalten die Berechtigungen, die zum Aufrufen oder Ändern von Statistiken-Dashboards, einschließlich benutzerdefinierter Dashboards, erforderlich sind. Erweitern Sie den Abschnitt Erforderliche Berechtigungen, um die erforderlichen Berechtigungen anzuzeigen:
Erforderliche Berechtigungen
Die folgenden Berechtigungen sind erforderlich, um Insights-Dashboards, einschließlich benutzerdefinierter Dashboards, aufzurufen oder zu ändern:
-
So erstellen Sie benutzerdefinierte Dashboards:
monitoring.dashboards.create -
So bearbeiten Sie benutzerdefinierte Dashboards:
monitoring.dashboards.update -
So rufen Sie benutzerdefinierte Dashboards auf:
monitoring.dashboards.get, monitoring.dashboards.list
Sie können diese Berechtigungen auch mit benutzerdefinierten Rollen oder anderen vordefinierten Rollen erhalten.
Systemstatistik-Dashboard anpassen
Das Dashboard „Systemstatistiken“ ist ein vordefiniertes Dashboard, das Sie anpassen können, um die für Sie wichtigsten Informationen anzuzeigen. Sie können neue Diagramme hinzufügen, das Layout ändern und die Daten filtern, um sich auf bestimmte Ressourcen zu konzentrieren.
Änderungen am Dashboard mit Systemstatistiken sind nicht irreversibel und können zurückgesetzt werden, indem Sie die Dashboard-Auswahl auf Vordefiniert festlegen.
Dashboard ändern
Wenn Sie das Dashboard ändern möchten, klicken Sie auf Dashboards anpassen. Folgende Optionen stehen zur Verfügung:
- Widget hinzufügen:Klicken Sie in der Dashboard-Symbolleiste auf Widget hinzufügen, wählen Sie das gewünschte Widget aus und konfigurieren Sie es.
- Widget bearbeiten:Bewegen Sie den Mauszeiger auf ein Widget, um die Symbolleiste aufzurufen, und klicken Sie dann auf Bearbeiten. Sie können den Typ des Widgets ändern und die darin angezeigten Daten anpassen.
- Widget klonen:Bewegen Sie den Mauszeiger auf ein Widget, um die Symbolleiste aufzurufen, klicken Sie auf Weitere Diagrammoptionen und dann auf Widget klonen.
- Widget löschen:Bewegen Sie den Mauszeiger auf ein Widget, um die Symbolleiste aufzurufen, klicken Sie auf Weitere Diagrammoptionen und dann auf Widget löschen.
- Layout ändern:Sie können Widgets verschieben, um sie neu zu positionieren, und an den Ecken ziehen, um ihre Größe zu ändern.
- Benutzerdefinierte Ansicht benennen:Sie können den Namen der benutzerdefinierten Ansicht im Feld Name der benutzerdefinierten Ansicht festlegen.
- Dashboard speichern:Sie können die benutzerdefinierte Ansicht speichern, indem Sie auf Speichern klicken. Sie können den Vorgang auch beenden, ohne zu speichern, indem Sie auf Bearbeitungsmodus beenden klicken.
Übersichtsdiagramme, Diagramme und Messwerte für Systemstatistiken
Das Dashboard „System-Insights“ bietet die folgenden Diagramme und Messwerte, um den aktuellen Status und den Verlaufsstatus einer Instanz anzuzeigen. Die meisten Diagramme und Messwerte sind auf Instanzebene verfügbar. Sie können sich auch viele Diagramme und Messwerte für eine einzelne Datenbank in einer Instanz anzeigen lassen.
Verfügbare Kurzübersichten
| Name | Beschreibung |
|---|---|
| CPU-Auslastung | Gesamte CPU-Nutzung in einer Instanz oder ausgewählten Datenbank. In einer Dual-Region- oder multiregionalen Instanz stellt dieser Messwert den regionsübergreifenden Mittelwert der CPU-Auslastung dar. |
| Latenz (P99) | Die P99-Latenz (99. Perzentil) für Lese- und Schreibvorgänge in einer Instanz oder ausgewählten Datenbank. Sie gibt die Zeit an, innerhalb derer 99% dieser Vorgänge abgeschlossen werden. |
| Latenz (P50) | Die P50-Latenz (50. Perzentil) für Lese- und Schreibvorgänge in einer Instanz oder ausgewählten Datenbank. Sie gibt die Zeit an, innerhalb derer 50% dieser Vorgänge abgeschlossen werden. |
| Durchsatz | Die Menge an unkomprimierten Daten, die pro Sekunde aus der Instanz oder Datenbank gelesen oder in diese geschrieben wurden. Dieser Wert wird in binären Byte-Einheiten wie KiB, MiB oder GiB gemessen. |
| Vorgänge pro Sekunde | Anzahl der Vorgänge pro Sekunde (Rate) bei Lese- und Schreibvorgängen in einer Instanz oder ausgewählten Datenbank. |
| Speicherauslastung | Auf Instanzebene ist es die gesamte Speicherauslastung in Prozent innerhalb einer Instanz. Auf Datenbankebene ist dies der Gesamtspeicherplatz, der für die ausgewählte Datenbank verwendet wird. |
Verfügbare Diagramme und Messwerte
Das folgende Diagramm zeigt einen Beispielmesswert, die CPU-Auslastung nach Vorgangstyp:
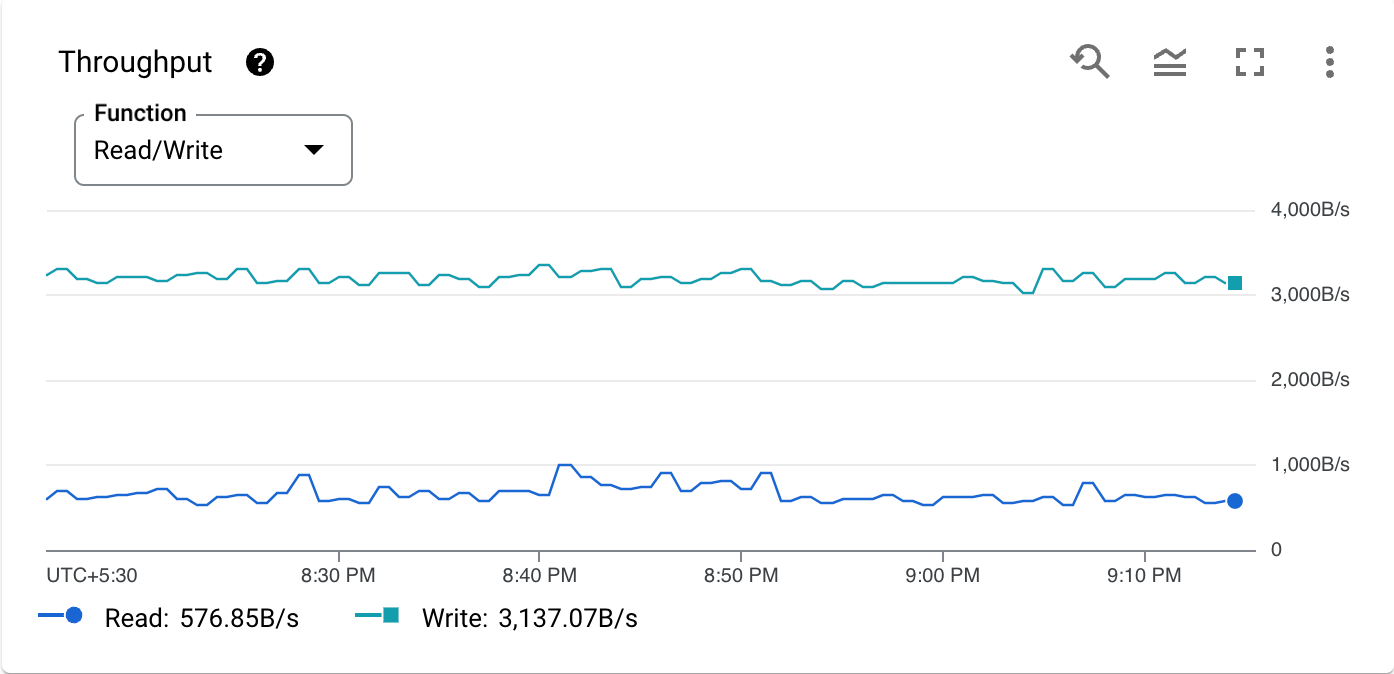
Die Symbolleiste jedes Diagramms enthält die folgenden Standardoptionen. Einige Elemente sind ausgeblendet, bis Sie den Mauszeiger über das Diagramm bewegen.
Wenn Sie einen bestimmten Bereich eines Diagramms vergrößern möchten, ziehen Sie den Mauszeiger über den gewünschten Bereich. Mit dieser Aktion wird ein benutzerdefinierter Zeitraum festgelegt, den Sie mit dem Zeitbereichsfilter anpassen oder rückgängig machen können.
Wenn Sie eine Beschreibung des Diagramms und der zugehörigen Daten aufrufen möchten, klicken Sie auf help.
Wenn Sie die auf das Diagramm angewendeten Filter und Gruppierungen sehen möchten, klicken Sie auf info.
Wenn Sie einen Alert auf Grundlage der Daten des Diagramms erstellen möchten, klicken Sie auf add_alert.
Wenn Sie die Daten im Diagramm genauer ansehen möchten, klicken Sie auf query_stats.
Klicken Sie auf more_vert Weitere Diagrammoptionen, um zusätzliche Diagrammoptionen aufzurufen.
Klicken Sie auf Im Vollbildmodus ansehen, um ein Diagramm im Vollbildmodus anzuzeigen. Sie können den Vollbildmodus beenden, indem Sie auf Abbrechen klicken oder die Esc-Taste drücken.
Wenn Sie die Diagrammlegende maximieren oder minimieren möchten, klicken Sie auf Diagrammlegende maximieren/minimieren.
Wenn Sie das Diagramm herunterladen möchten, klicken Sie auf Herunterladen und wählen Sie ein Downloadformat aus.
Wenn Sie das visuelle Format des Diagramms ändern möchten, klicken Sie auf Modus und wählen Sie einen Ansichtsmodus aus.
Wenn Sie sich den Messwert im Metrics Explorer ansehen möchten, klicken Sie auf Im Metrics Explorer ansehen. Sie können sich weitere Spanner-Messwerte im Metrics Explorer ansehen, nachdem Sie den Ressourcentyp Spanner-Datenbank ausgewählt haben.
In der folgenden Tabelle werden die Diagramme beschrieben, die standardmäßig im Systemstatistik-Dashboard angezeigt werden. Der Messwerttyp für jedes Diagramm ist aufgeführt. Die Messwerttyp-Strings folgen diesem Präfix: spanner.googleapis.com/. Ein Messwerttyp beschreibt Messungen, die von einer überwachten Ressource erfasst werden können.
| Diagrammname und Messwerttyp |
Beschreibung | Für Instanzen verfügbar | Für Datenbanken verfügbar |
|---|---|---|---|
|
Biregionale Zeitachse zur Quorumintegrität instance/dual_region_quorum_availability |
Dieses Diagramm wird nur für Konfigurationen mit biregionalen Instanzen angezeigt. Sie zeigt den Zustand von drei Quoren: dem biregionalen Quorum ( Global) und dem Einzelregionsquorum in jeder Region (z. B. Sydney und Melbourne).
In der Zeitachse wird ein orangefarbener Balken angezeigt, wenn es zu einer Dienstunterbrechung kommt. Wenn Sie den Mauszeiger auf den Balken bewegen, sehen Sie die Start- und Endzeit der Unterbrechung. Verwenden Sie dieses Diagramm zusammen mit den Fehlerraten und Latenzmesswerten, um im Falle regionaler Fehler selbstverwaltete Entscheidungen zum Failover zu treffen. Weitere Informationen finden Sie unter Failover und Failback. Informationen zum manuellen Failover und Failback finden Sie unter Dual-Region-Quorum ändern. |
done |
done |
CPU-Auslastung nach Priorität instance/cpu/utilization_by_priority |
Der Prozentsatz der CPU-Ressourcen der Instanz für Aufgaben mit hoher, mittlerer, niedriger oder beliebiger Priorität. Diese Aufgaben umfassen von Ihnen initiierte Anfragen und Wartungsaufgaben, die Spanner umgehend ausführen muss. Bei Instanzen mit zwei oder mehreren Regionen werden die Messwerte nach Region und Priorität gruppiert. Weitere Informationen zu Aufgaben mit hoher Priorität Weitere Informationen zur CPU-Auslastung. |
done |
close |
|
CPU-Auslastung nach Region instance/cpu/utilization_by_priority |
Die CPU-Auslastung in der ausgewählten Instanz oder Datenbank, gruppiert nach Region. | done |
done |
|
CPU-Auslastung nach Datenbank instance/cpu/utilization_by_priority |
Die CPU-Auslastung in der ausgewählten Instanz, gruppiert nach Datenbank und Region. | done |
close |
|
CPU-Auslastung nach Nutzer/System instance/cpu/utilization_by_priority |
Die CPU-Auslastung in der ausgewählten Instanz oder Datenbank, gruppiert nach Nutzer- und Systemaufgaben sowie nach Priorität. | done |
done |
CPU-Auslastung nach Vorgangstyp instance/cpu/utilization_by_operation_type |
Ein gestapeltes Diagramm der CPU-Auslastung als Prozentsatz der CPU-Ressourcen der Instanz, gruppiert nach vom Nutzer initiierten Vorgängen wie Lese-, Schreib- und Commit-Vorgängen. Verwenden Sie diesen Messwert, um eine detaillierte Aufschlüsselung der CPU-Auslastung zu erhalten und weitere Fehlerbehebungen durchzuführen, wie unter Hohe CPU-Auslastung untersuchen beschrieben. Sie können die Aufgabenliste auch nach Priorität filtern. Bei Instanzen mit zwei oder mehr Regionen zeigen die Messwerte im Liniendiagramm den durchschnittlichen Prozentsatz zwischen den Regionen. |
done |
done |
CPU-Auslastung (gleitender Durchschnitt über 24 Stunden) instance/cpu/smoothed_utilization |
Ein gleitender Durchschnitt der gesamten CPU-Auslastung von Spanner als Prozentsatz der CPU-Ressourcen der Instanz für jede Datenbank. Jeder Datenpunkt ist ein Durchschnittswert für die letzten 24 Stunden. |
done |
close |
Latenz api/request_latencies |
Die Zeit, die Spanner für die Bearbeitung einer Lese- oder Schreibanfrage benötigt hat. Diese Messung beginnt, wenn Spanner eine Anfrage empfängt, und endet, wenn Spanner mit dem Senden einer Antwort beginnt. Sie können sich Latenzmesswerte für die Latenz des 50. und 99. Perzentils über die Optionsliste ansehen. |
close |
done |
Latenz nach Datenbank api/request_latencies |
Die Zeit, die Spanner für die Bearbeitung einer Lese- oder Schreibanfrage benötigt hat, gruppiert nach Datenbank. Diese Messung beginnt, wenn Spanner eine Anfrage empfängt, und endet, wenn Spanner mit dem Senden einer Antwort beginnt. Sie können sich Messwerte für die Latenz des 50. und 99. Perzentils ansehen, indem Sie die Ansichtsliste in diesem Diagramm verwenden. |
done |
close |
Latenz nach API-Methode api/request_latencies |
Die Zeit, die Spanner für die Bearbeitung einer Anfrage benötigt hat, gruppiert nach Spanner API-Methoden. Diese Messung beginnt, wenn Spanner eine Anfrage empfängt, und sie endet, wenn Spanner mit dem Senden einer Antwort beginnt. Sie können sich Messwerte für die Latenz des 50. und 99. Perzentils ansehen, indem Sie die Ansichtsliste in diesem Diagramm verwenden. |
close |
done |
Transaktionslatenz api/request_latencies_by_transaction_type |
Die Zeit, die Spanner für die Verarbeitung einer Transaktion benötigt hat. Sie können auswählen, ob Sie Messwerte für Lese-/Schreib- und schreibgeschützte Transaktionen sehen möchten. Der Hauptunterschied zwischen dem Latenzdiagramm und dem Transaktionslatenzdiagramm besteht darin, dass Sie im Transaktionslatenzdiagramm die Leader-Beteiligung für den schreibgeschützten Typ sehen können. Lesevorgänge, an denen der Leader beteiligt ist, können eine höhere Latenz aufweisen. Anhand dieses Diagramms können Sie entscheiden, ob Sie veraltete Lesevorgänge verwenden sollten, ohne mit dem Leader zu kommunizieren, vorausgesetzt, die Zeitstempelgrenze beträgt mindestens 15 Sekunden. Bei Lese-/Schreibtransaktionen ist der Leader immer an der Transaktion beteiligt. Die im Diagramm angezeigten Daten enthalten daher immer die Zeit, die benötigt wurde, bis die Anfrage den Leader erreicht und eine Antwort empfangen wurde. Der Standort entspricht der Region des Cloud Spanner API-Frontends. Sie können sich Messwerte für die Latenz des 50. und 99. Perzentils ansehen, indem Sie die Ansichtsliste in diesem Diagramm verwenden. |
close |
done |
Transaktionslatenz nach Datenbank api/request_latencies_by_transaction_type |
Die Zeit, die Spanner für die Verarbeitung einer Transaktion benötigt hat. Der Hauptunterschied zwischen dem Latenzdiagramm und dem Diagramm „Transaktionslatenz nach Datenbank“ besteht darin, dass Sie im Diagramm „Transaktionslatenz nach Datenbank“ die Leader-Beteiligung für den schreibgeschützten Typ sehen können. Lesevorgänge, an denen der Leader beteiligt ist, können eine höhere Latenz aufweisen. Anhand dieses Diagramms können Sie beurteilen, ob Sie veraltete Lesevorgänge verwenden sollten, ohne mit dem Leader zu kommunizieren, vorausgesetzt, die Zeitstempelgrenze beträgt mindestens 15 Sekunden. Bei Lese-/Schreibtransaktionen ist der Leader immer an der Transaktion beteiligt. Die im Diagramm angezeigten Daten enthalten daher immer die Zeit, die benötigt wurde, bis die Anfrage den Leader erreicht und eine Antwort empfangen wurde. Der Standort entspricht der Region des Cloud Spanner API-Frontends. Sie können sich Messwerte für die Latenz des 50. und 99. Perzentils ansehen, indem Sie die Ansichtsliste in diesem Diagramm verwenden. |
done |
close |
Transaktionslatenz nach API-Methode api/request_latencies_by_transaction_type |
Die Zeit, die Spanner für die Verarbeitung einer Transaktion benötigt hat. Der Hauptunterschied zwischen dem Latenzdiagramm und dem Diagramm „Transaktionslatenz nach API-Methode“ besteht darin, dass Sie im Diagramm „Transaktionslatenz nach API-Methode“ die Leader-Beteiligung für den schreibgeschützten Typ sehen können. Lesevorgänge, an denen der Leader beteiligt ist, können eine höhere Latenz aufweisen. Anhand dieses Diagramms können Sie beurteilen, ob Sie veraltete Lesevorgänge verwenden sollten, ohne mit dem Leader zu kommunizieren, vorausgesetzt, die Zeitstempelgrenze beträgt mindestens 15 Sekunden. Bei Lese-/Schreibtransaktionen ist der Leader immer an der Transaktion beteiligt. Die im Diagramm angezeigten Daten enthalten daher immer die Zeit, die benötigt wurde, bis die Anfrage den Leader erreicht und eine Antwort empfangen wurde. Der Standort entspricht der Region des Cloud Spanner API-Frontends. |
close |
done |
Vorgänge pro Sekunde api/api_request_count |
Die Anzahl der Lese- und Schreibvorgänge, die Spanner pro Sekunde ausführt, oder die Anzahl der Spanner-Serverfehler pro Sekunde. Sie können auswählen, welche Vorgänge in diesem Diagramm angezeigt werden sollen:
|
close |
done |
Vorgänge pro Sekunde nach Datenbank api/api_request_count |
Die Anzahl der Lese- und Schreibvorgänge, die Spanner pro Sekunde ausführt, oder die Anzahl der Spanner-Serverfehler pro Sekunde. Dieses Diagramm ist nach Datenbank gruppiert. Sie können auswählen, welche Vorgänge in diesem Diagramm angezeigt werden sollen:
|
done |
close |
Vorgänge pro Sekunde nach API-Methode api/api_request_count |
Die Anzahl der Vorgänge, die Spanner pro Sekunde ausgeführt hat, gruppiert nach Spanner-API-Methode |
close |
done |
Durchsatz api/sent_bytes_count (Lesen) api/received_bytes_count (Schreiben) |
Die Menge an unkomprimierten Daten, die pro Sekunde aus der Datenbank gelesen und in die Datenbank geschrieben wurden. Dieser Wert wird in binären Byte-Einheiten wie KiB, MiB oder GiB gemessen. Der Durchsatz für Lesevorgänge umfasst Anfragen und Antworten für Methoden in der Lese-API und für SQL-Abfragen. Auch Anfragen und Antworten für DML-Anweisungen sind darin enthalten. Der Durchsatz für Schreibvorgänge umfasst Anfragen und Antworten zum Aktualisieren von Daten über die Mutation API. Anfragen und Antworten für DML-Anweisungen sind darin enthalten. |
close |
done |
Durchsatz nach Datenbank api/sent_bytes_count (Lesen) api/received_bytes_count (Schreiben) |
Die Menge an unkomprimierten Daten, die pro Sekunde aus der Instanz gelesen und in die Instanz geschrieben wurden, gruppiert nach Datenbank. Dieser Wert wird in binären Byte-Einheiten wie KiB, MiB oder GiB gemessen. Der Durchsatz für Lesevorgänge umfasst Anfragen und Antworten für Methoden in der Lese-API und für SQL-Abfragen. Auch Anfragen und Antworten für DML-Anweisungen sind darin enthalten. Der Durchsatz für Schreibvorgänge umfasst Anfragen und Antworten zum Aktualisieren von Daten über die Mutation API. Anfragen und Antworten für DML-Anweisungen sind darin enthalten. |
done |
close |
Durchsatz nach API-Methode api/sent_bytes_count (Lesen) api/received_bytes_count (Schreiben) |
Die Menge an unkomprimierten Daten, die pro Sekunde aus der Instanz oder Datenbank gelesen oder in diese geschrieben wurden, gruppiert nach API-Methode. Dieser Wert wird in binären Byte-Einheiten wie KiB, MiB oder GiB gemessen. Der Durchsatz für Lesevorgänge umfasst Anfragen und Antworten für Methoden in der Lese-API und für SQL-Abfragen. Auch Anfragen und Antworten für DML-Anweisungen sind darin enthalten. Der Durchsatz für Schreibvorgänge umfasst Anfragen und Antworten zum Aktualisieren von Daten über die Mutation API. Anfragen und Antworten für DML-Anweisungen sind darin enthalten. |
close |
done |
Gesamtspeicherplatz instance/storage/used_bytes |
Die Menge der in der Datenbank gespeicherten Daten. Dieser Wert wird in binären Byte-Einheiten wie KiB, MiB oder GiB gemessen. |
close |
done |
Gesamtdatenbankspeicher nach Datenbank instance/storage/used_bytes |
Die Datenmenge, die in der Instanz gespeichert ist, gruppiert nach Datenbank. Dieser Wert wird in binären Byte-Einheiten wie KiB, MiB oder GiB gemessen. |
done |
close |
Gesamtspeicherplatz für Sicherungen instance/backup/used_bytes |
Die Datenmenge, die in den Sicherungen gespeichert ist, die der Datenbank zugeordnet sind. Dieser Wert wird in binären Byte-Einheiten wie KiB, MiB oder GiB gemessen. |
close |
done |
Wartezeit für Sperren lock_stat/total/lock_wait_time |
Die Sperrwartezeit für eine Transaktion ist die Zeit, die benötigt wird, um eine Sperre für eine Ressource zu erhalten, die von einer anderen Transaktion gehalten wird. Die Gesamtwartezeit für Sperrungen für Sperrkonflikte wird für die gesamte Datenbank aufgezeichnet. |
close |
done |
Wartezeit bei Sperren nach Datenbank lock_stat/total/lock_wait_time |
Die Wartezeit bei Sperren für eine Transaktion ist die Zeit, die benötigt wird, um eine Sperre für eine Ressource zu erhalten, die von einer anderen Transaktion gehalten wird, gruppiert nach Datenbank. Die Gesamtwartezeit für Sperrungen für Sperrkonflikte wird für die gesamte Instanz aufgezeichnet. |
done |
close |
Gesamtspeicherplatz für Sicherungen nach Datenbank instance/backup/used_bytes |
Die Datenmenge, die in den Sicherungen gespeichert ist, die der Instanz zugeordnet sind, gruppiert nach Datenbank. Dieser Wert wird in binären Byte-Einheiten wie KiB, MiB oder GiB gemessen. |
done |
close |
Rechenkapazität instance/processing_units instance/nodes |
Die Rechenkapazität ist die Anzahl der in einer Instanz verfügbaren Verarbeitungseinheiten oder Knoten. Sie können die Kapazität in Verarbeitungseinheiten oder in Knoten anzeigen. |
done |
close |
Leader-Verteilung instance/leader_percentage_by_region |
Bei biregionalen oder multiregionalen Instanzen können Sie die Anzahl der Datenbanken mit der Mehrheit der Leader (>= 50%) in einer bestimmten Region aufrufen. Wenn Sie im Listenmenü Regionen eine bestimmte Region auswählen, wird im Diagramm die Gesamtzahl der Datenbanken in dieser Instanz angezeigt, für die die ausgewählte Region die Leader-Region ist. Wenn Sie im Listenmenü Regionen die Option Alle Regionen auswählen, enthält das Diagramm eine Zeile für jede Region. Jede Zeile zeigt die Gesamtzahl der Datenbanken in der Instanz, für die diese Region als Leader-Region festgelegt ist. Bei Datenbanken in einer biregionalen oder multiregionalen Instanz können Sie den Prozentsatz der nach Region gruppierten Leader sehen. Wenn eine Datenbank beispielsweise fünf Leader hat, einen in us-west1 und vier in us-east1, zeigt das Diagramm „Alle Regionen“ zwei Linien (eine pro Region). Eine Linie für us-west1 liegt bei 20 % und die andere Linie für us-east1 bei 80%. Das Diagramm für „us-west1“ zeigt eine einzelne Linie bei 20 % und das Diagramm für „us-east1“ eine einzelne Linie bei 80%.Wenn eine Datenbank vor Kurzem erstellt oder eine führende Region vor Kurzem geändert wurde, stabilisieren sich die Diagramme möglicherweise nicht sofort. Dieses Diagramm ist nur für Instanzen mit zwei Regionen und multiregionale Instanzen verfügbar. |
done |
done |
CPU-Nutzungswert des Spitzen-Splits instance/peak_split_peak |
Die maximale CPU-Nutzung des Spitzen-Splits, die in allen Splits einer Datenbank beobachtet wurde. Dieser Messwert gibt den Prozentsatz der Ressourcen der Verarbeitungseinheit an, die für einen Split verwendet werden. Ein Prozentsatz von über 50% bedeutet, dass der Split die Hälfte der Verarbeitungseinheiten des Hostservers verwendet. Ein Prozentsatz von 100% bedeutet, dass der Split stark genutzt wird und die meisten Ressourcen der Verarbeitungseinheit des Hostservers verwendet. Spanner verwendet die lastbasierte Aufteilung, um Hotspots zu beheben und die Last auszugleichen. Aufgrund problematischer Muster in der Anwendung kann Spanner die Last jedoch möglicherweise auch nach mehreren Versuchen, die Daten aufzuteilen, nicht ausgleichen. Hotspots, die mindestens 10 Minuten lang anhalten, müssen daher möglicherweise weiter untersucht werden und erfordern unter Umständen Änderungen an der Anwendung. Weitere Informationen finden Sie unter Hotspots in Splits finden. | done |
done |
|
Remote-Dienstaufrufe query_stat/total/remote_service_calls_count |
Anzahl der Remote-Dienstaufrufe, gruppiert nach Dienst und Antwortcodes. Antwortet mit einem HTTP-Antwortcode, z. B. 200 oder 500. |
done |
done |
|
Latenz: Aufrufe von Remote-Diensten query_stat/total/remote_service_calls_latencies |
Die Latenz der Remote-Dienstaufrufe, gruppiert nach Dienst. Sie können sich Latenzmesswerte für die Latenz des 50. und 99. Perzentils über die Optionsliste ansehen. |
done |
done |
|
Vom Remote-Dienst verarbeitete Zeilen query_stat/total/remote_service_processed_rows_count |
Anzahl der Zeilen, die von einem Remote-Dienst verarbeitet wurden, gruppiert nach Dienst und Antwortcodes. Antwortet mit einem HTTP-Antwortcode, z. B. 200 oder 500. |
done |
done |
|
Latenz: Zeilen von Remote-Diensten query_stat/total/remote_service_processed_rows_latencies |
Anzahl der Zeilen, die von einem Remote-Dienst verarbeitet wurden, gruppiert nach Dienst und Antwortcodes. Sie können sich Latenzmesswerte für die Latenz des 50. und 99. Perzentils über die Optionsliste ansehen. |
done |
done |
|
Netzwerkbytes von Remote-Diensten query_stat/total/remote_service_network_bytes_sizes |
Mit dem Remote-Dienst ausgetauschte Netzwerkbyte, gruppiert nach Dienst und Richtung. Dieser Wert wird in binären Byte-Einheiten wie KiB, MiB oder GiB gemessen. „Richtung“ bezieht sich auf gesendeten oder empfangenen Traffic. In der Optionsliste können Sie sich Messwerte für das 50. und 99. Perzentil des Netzwerk-Byte-Austauschs ansehen. |
done |
done |
|
Aufrufe von Mikrodiensten query_stat/total/remote_service_calls_count |
Anzahl der Aufrufe von Mikrodiensten, gruppiert nach Mikrodienst und Antwortcode. | done |
done |
|
Latenz: Aufrufe von Mikrodiensten query_stat/total/remote_service_calls_latencies |
Latenzen der Aufrufe von Mikrodiensten, gruppiert nach Mikrodienst. | done |
done |
Datenbankspeicher nach Tabelle (none) |
Die Datenmenge, die in der Instanz oder Datenbank gespeichert ist, gruppiert nach Tabellen in der ausgewählten Datenbank. Dieser Wert wird in binären Byte-Einheiten wie KiB, MiB oder GiB gemessen. Die Daten für dieses Diagramm werden durch Abfragen von SPANNER_SYS.TABLE_SIZES_STATS_1HOUR abgerufen. Weitere Informationen finden Sie unter
Statistiken zur Tabellengröße. |
close |
done |
Am häufigsten verwendete Tabellen nach Vorgängen (keine) |
Die 15 am häufigsten verwendeten Tabellen und Indexe in der Instanz oder Datenbank, bestimmt durch die Anzahl der Lese-, Schreib- oder Löschvorgänge. Die Daten für dieses Diagramm werden durch Abfragen der Statistiktabellen für Tabellenvorgänge abgerufen. Weitere Informationen finden Sie unter Statistiken zu Tabellenvorgängen. |
close |
done |
Am seltensten verwendete Tabellen nach Vorgängen (none) |
Die 15 am wenigsten verwendeten Tabellen und Indexe in der Instanz oder Datenbank, bestimmt durch die Anzahl der Lese-, Schreib- oder Löschvorgänge. Die Daten für dieses Diagramm werden durch Abfragen der Statistiktabellen für Tabellenvorgänge abgerufen. Weitere Informationen finden Sie unter Statistiken zu Tabellenvorgängen. |
close |
done |
Diagramme und Messwerte für verwaltetes Autoscaling
Zusätzlich zu den Optionen im vorherigen Abschnitt enthält das Diagramm zur Rechenkapazität die Schaltfläche Logs ansehen, wenn für eine Instanz der verwaltete Autoscaler aktiviert ist. Wenn Sie auf diese Schaltfläche klicken, werden Logs aus dem verwalteten Autoscaler angezeigt.
Die folgenden Messwerte sind für Instanzen verfügbar, für die die verwaltete automatische Skalierung aktiviert ist.
| Name und Typ des Messwerts | Beschreibung |
|---|---|
| Rechenkapazität | Mit ausgewählten Knoten. |
|
instance/autoscaling/min_node_count |
Die Mindestanzahl von Knoten, die das Autoscaling für die Instanz zuweisen soll. |
|
instance/autoscaling/max_node_count |
Maximale Anzahl von Knoten, die vom Autoscaler für die Instanz zugewiesen werden. |
|
instance/autoscaling/recommended_node_count_for_cpu |
Empfohlene Anzahl von Knoten basierend auf der CPU-Nutzung der Instanz. |
|
instance/autoscaling/recommended_node_count_for_storage |
Empfohlene Anzahl von Knoten basierend auf der Speichernutzung der Instanz. |
| Rechenkapazität | Verarbeitungseinheiten sind ausgewählt. |
|
instance/autoscaling/min_processing_units |
Mindestanzahl der Verarbeitungseinheiten, die das Autoscaling für die Instanz zuweisen soll. |
|
instance/autoscaling/max_processing_units |
Maximale Anzahl von Verarbeitungseinheiten, die der Autoscaler für die Instanz zuweisen kann. |
|
instance/autoscaling/recommended_processing_units_for_cpu |
Empfohlene Anzahl von Verarbeitungseinheiten. Diese Empfehlung basiert auf der bisherigen CPU-Auslastung der Instanz. |
|
instance/autoscaling/recommended_processing_units_for_storage |
Empfohlene Anzahl der zu verwendenden Verarbeitungseinheiten. Diese Empfehlung basiert auf der bisherigen Speichernutzung der Instanz. |
| CPU-Auslastung nach Priorität | |
|
instance/autoscaling/high_priority_cpu_utilization_target |
CPU-Auslastungsziel mit hoher Priorität, das für das Autoscaling verwendet werden soll. |
| Gesamtspeicherplatz | Verarbeitungseinheiten sind ausgewählt. |
|
instance/storage/limit_bytes |
Speicherlimit für die Instanz in Byte. |
|
instance/autoscaling/storage_utilization_target |
Speicherauslastungsziel für das Autoscaling. |
Diagramme und Messwerte für mehrstufigen Speicher
Die folgenden Messwerte sind für Instanzen verfügbar, die Tiered Storage verwenden.
| Name und Typ des Messwerts | Beschreibung |
|---|---|
| instance/storage/used_bytes | Gesamtzahl der Byte an Daten, die auf SSD- und HDD-Speicher gespeichert sind. |
| instance/storage/combined/limit_bytes | Kombinierte Speicherlimits für SSD und HDD. |
| instance/storage/combined/limit_per_processing_unit | Kombiniertes SSD- und HDD-Speicherlimit für jede Verarbeitungseinheit. |
| instance/storage/combined/utilization | Verwendeter kombinierter SSD- und HDD-Speicher im Vergleich zum kombinierten Speicherlimit. |
| instance/disk_load | HDD-Last verwenden. |
Datenaufbewahrung
Die maximale Datenaufbewahrung für die meisten Messwerte im Dashboard „Systemstatistiken“ beträgt 6 Wochen. Für das Diagramm Datenbankspeicher nach Tabelle werden die Daten jedoch aus der Tabelle SPANNER_SYS.TABLE_SIZES_STATS_1HOUR (anstelle von Spanner) abgerufen, die eine maximale Aufbewahrungsdauer von 30 Tagen hat.
Weitere Informationen
Systemstatistik-Dashboard aufrufen
Zum Aufrufen der Seite „Systemstatistiken“ benötigen Sie zusätzlich zu den Spanner-Berechtigungen und Spanner-Berechtigungen auf Instanz- und Datenbankebene die folgenden IAM-Berechtigungen (Identity and Access Management):
spanner.databases.beginReadOnlyTransactionspanner.databases.selectspanner.sessions.create
Weitere Informationen zu Spanner-IAM-Berechtigungen finden Sie unter Zugriffssteuerung mit IAM.
Wenn Sie den verwalteten Autoscaler für Ihre Instanz aktivieren, benötigen Sie auch die Berechtigungen logging.logEntries.list, logging.logs.list und logging.logServices.list, um die Logs des verwalteten Autoscalers aufzurufen.
Weitere Informationen zu dieser Berechtigung finden Sie unter Vordefinierte Rollen.
So rufen Sie das Systemstatistik-Dashboard auf:
Öffnen Sie in der Google Cloud Console die Liste der Spanner-Instanzen.
Führen Sie einen der folgenden Schritte aus:
Wenn Sie Messwerte für eine Instanz aufrufen möchten, klicken Sie auf den Namen der Instanz und dann im Navigationsmenü auf Systemstatistiken.
Wenn Sie Messwerte für eine Datenbank aufrufen möchten, klicken Sie auf den Namen der Instanz, wählen Sie eine Datenbank aus und klicken Sie dann im Navigationsmenü auf Systemstatistiken.
Optional: Wenn Sie sich Verlaufsdaten für einen anderen Zeitraum ansehen möchten, suchen Sie die Schaltflächen oben rechts auf der Seite und klicken Sie dann auf den gewünschten Zeitraum.
Optional: Wenn Sie andere Daten im Diagramm darstellen möchten, klicken Sie auf eine der Listen im Diagramm und stellen ein, welche Daten im Diagramm angezeigt werden sollen. Wenn die Instanz beispielsweise eine Dual-Region- oder Multiregionenkonfiguration verwendet, bieten einige Diagramme eine Liste an, um sich Daten für eine bestimmte Region anzeigen zu lassen. Nicht alle Diagramme haben Ansichtslisten.
Nächste Schritte
- Informationen zur CPU-Auslastung und zum Latenzmesswert für Spanner.
- Benutzerdefinierte Diagramme und Benachrichtigungen mit Monitoring einrichten
- Informationen zu Arten von Spanner-Instanzen.