Este documento descreve como usar o painel de controlo de estatísticas do sistema para monitorizar instâncias e bases de dados do Spanner.
Acerca das estatísticas do sistema
O painel de controlo de estatísticas do sistema apresenta tabelas de dados e gráficos relativamente a uma instância ou uma base de dados selecionada e fornece medidas de latências, utilização da CPU, armazenamento, taxa de transferência e outras estatísticas de desempenho. Pode ver gráficos para períodos selecionáveis, que variam da última hora aos últimos 30 dias.
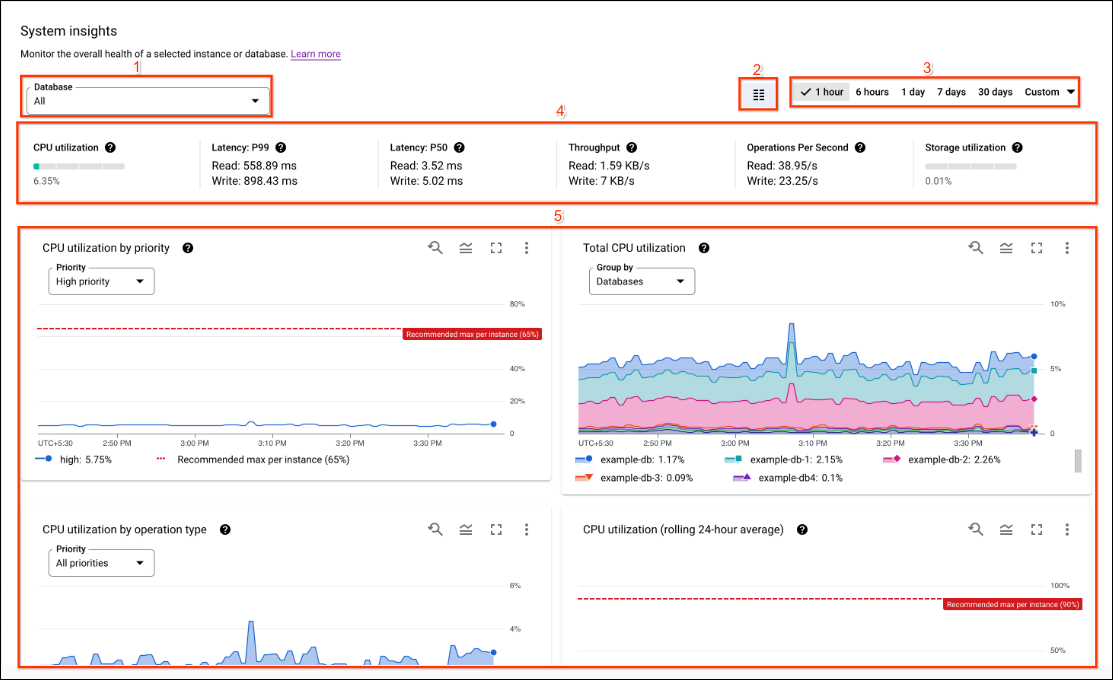
O painel de controlo de estatísticas do sistema inclui as seguintes secções, com números correspondentes à seguinte captura de ecrã da IU:
- Seletores de estatísticas: selecione as bases de dados, as partições de instâncias e as regiões que preenchem o painel de controlo. As estatísticas do sistema mostram partições de instâncias e seleções de regiões quando existem várias partições de instâncias ou regiões disponíveis na instância.
- Filtro do intervalo de tempo: filtre as estatísticas por um intervalo de tempo, como horas, dias ou um intervalo personalizado.
- Seletor do painel de controlo: selecione vistas personalizadas pelo utilizador ou reponha as estatísticas do sistema para a vista predefinida.
- Anotações: selecione tipos de eventos de alertas de estatísticas para anotar gráficos.
- Personalize painéis de controlo: personalize o aspeto, o posicionamento e o conteúdo dos widgets do painel de controlo e do painel de controlo de estatísticas do sistema. Este documento descreve a apresentação do painel de controlo predefinido.
- Tabelas de dados: apresentam estatísticas num ponto específico do tempo, durante o período selecionado.
- Gráficos: apresentam gráficos de utilização da CPU, débito, latências, utilização de armazenamento e muito mais. Os alertas de estatísticas definidos por anotações aparecem em gráficos com ícones de sino.
Funções necessárias
Para receber as autorizações de que precisa para ver ou modificar painéis de controlo de estatísticas, incluindo painéis de controlo personalizados, peça ao seu administrador para lhe conceder as seguintes funções de IAM no projeto:
-
Para criar e editar painéis de controlo personalizados:
Editor de configuração do painel de controlo de monitorização (
roles/monitoring.dashboardEditor) -
Para abrir e ver os gráficos do Metrics Explorer:
Visualizador de configuração do painel de controlo de monitorização (
roles/monitoring.dashboardViewer) -
Para criar e editar alertas do Metrics Explorer:
Editor de monitorização (
roles/monitoring.editor)
Para mais informações sobre a atribuição de funções, consulte o artigo Faça a gestão do acesso a projetos, pastas e organizações.
Estas funções predefinidas contêm as autorizações necessárias para ver ou modificar painéis de controlo de estatísticas, incluindo painéis de controlo personalizados. Para ver as autorizações exatas que são necessárias, expanda a secção Autorizações necessárias:
Autorizações necessárias
São necessárias as seguintes autorizações para ver ou modificar painéis de controlo de estatísticas, incluindo painéis de controlo personalizados:
-
Para criar painéis de controlo personalizados:
monitoring.dashboards.create -
Para editar painéis de controlo personalizados:
monitoring.dashboards.update -
Para ver painéis de controlo personalizados:
monitoring.dashboards.get, monitoring.dashboards.list
Também pode conseguir estas autorizações com funções personalizadas ou outras funções predefinidas.
Personalize o painel de controlo de estatísticas do sistema
O painel de controlo de estatísticas do sistema é um painel de controlo predefinido que pode personalizar para apresentar as informações mais importantes para si. Pode adicionar novos gráficos, alterar o esquema e filtrar os dados para se concentrar em recursos específicos.
As alterações ao painel de controlo de estatísticas do sistema não são destrutivas e podem ser repostas definindo o seletor do painel de controlo como Predefinido.
Modifique o painel de controlo
Para modificar o painel de controlo, clique em Personalizar painéis de controlo. Estão disponíveis as seguintes opções:
- Adicione um widget: na barra de ferramentas do painel de controlo, clique em Adicionar widget, selecione o widget que quer adicionar e, de seguida, configure-o.
- Editar um widget: passe o cursor do rato sobre um widget para mostrar a respetiva barra de ferramentas e, de seguida, clique em Editar. Pode alterar o tipo de widget e personalizar os dados que apresenta.
- Clonar um widget: passe o cursor do rato sobre um widget para mostrar a respetiva barra de ferramentas, clique em Mais opções de gráficos, e, de seguida, em Clonar widget.
- Eliminar um widget: passe o cursor do rato sobre um widget para mostrar a respetiva barra de ferramentas, clique em Mais opções de gráficos, e, de seguida, em Eliminar widget.
- Alterar o esquema: pode arrastar os widgets para os reposicionar e arrastar os cantos para os redimensionar.
- Dê um nome à vista personalizada: pode definir o nome da vista personalizada na caixa Nome da vista personalizada.
- Guarde o painel de controlo: pode guardar a vista personalizada clicando em Guardar. Também pode sair sem guardar clicando em Sair do modo de edição.
Tabelas de dados, gráficos e métricas de estatísticas do sistema
O painel de controlo de estatísticas do sistema apresenta os seguintes gráficos e métricas para mostrar o estado atual e histórico de uma instância. A maioria dos gráficos e métricas está disponível ao nível da instância. Também pode ver muitos gráficos e métricas para uma única base de dados numa instância.
Visões gerais disponíveis
| Nome | Descrição |
|---|---|
| Utilização da CPU | Utilização total da CPU numa instância ou numa base de dados selecionada. Numa instância de região dupla ou de várias regiões, esta métrica representa a média da utilização da CPU em várias regiões. |
| Latência (p99) | Latência P99 (percentil 99) para operações de leitura e escrita numa instância ou numa base de dados selecionada, que representa o tempo no qual 99% destas operações são concluídas. |
| Latência (p50) | Latência P50 (percentil 50) para operações de leitura e escrita numa instância ou numa base de dados selecionada, que representa o tempo no qual 50% destas operações são concluídas. |
| Débito | Quantidade de dados não comprimidos que foram lidos ou escritos na instância ou na base de dados a cada segundo. Este valor é medido em bytes binários, como KiB, MiB ou GiB. |
| Operações por segundo | Número de operações por segundo (taxa) de leitura e escritas numa instância ou numa base de dados selecionada. |
| Utilização do armazenamento | Ao nível da instância, é a percentagem total de utilização do armazenamento numa instância. Ao nível da base de dados, este é o armazenamento total usado para a base de dados selecionada. |
Gráficos e métricas disponíveis
Segue-se um gráfico de uma métrica de exemplo, a utilização da CPU por tipo de operação:
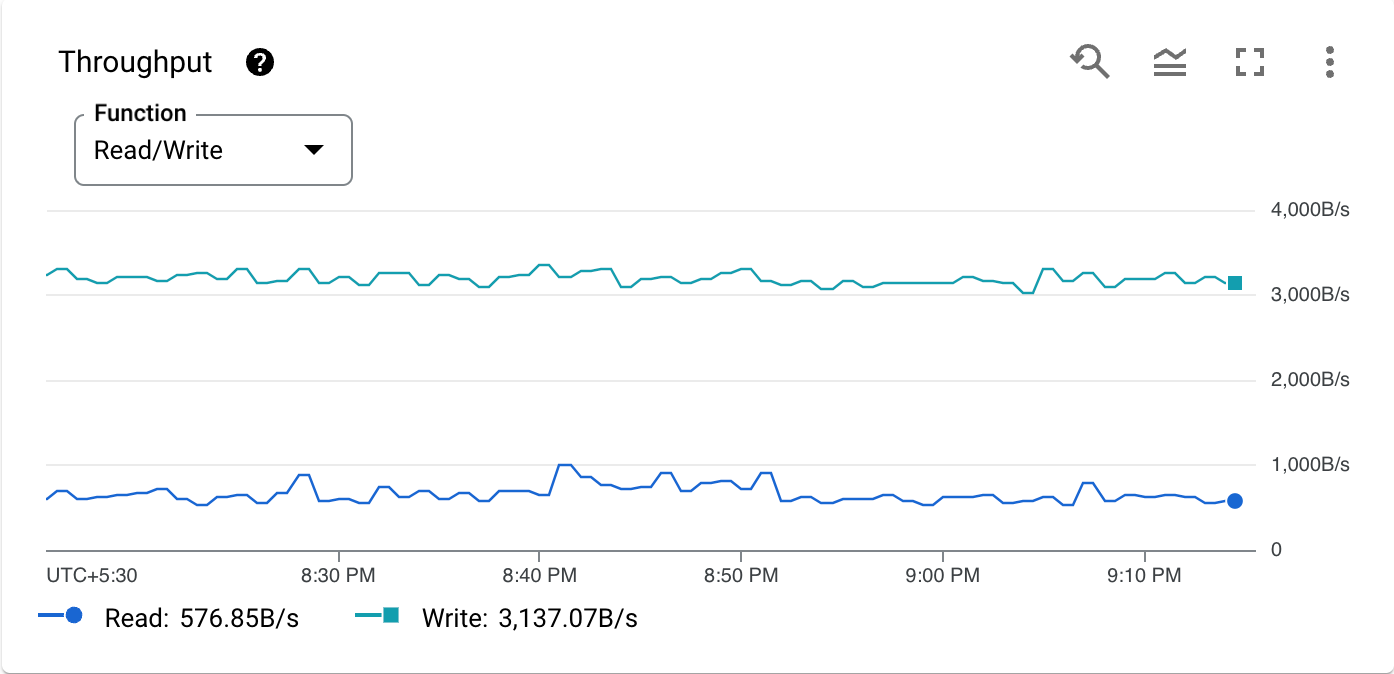
A barra de ferramentas em cada gráfico oferece as seguintes opções padrão. Alguns elementos estão ocultos, a menos que passe o cursor do rato sobre o gráfico.
Para aumentar o zoom numa secção específica de um gráfico, arraste o ponteiro pela secção que quer ver. Esta ação define um intervalo de tempo personalizado que pode ajustar ou reverter com o filtro de intervalo de tempo.
Para ver uma descrição do gráfico e dos respetivos dados, clique em help.
Para ver os filtros e os agrupamentos aplicados ao gráfico, clique em info.
Para criar um alerta com base nos dados do gráfico, clique em add_alert.
Para explorar os dados no gráfico, clique em query_stats.
Para ver opções de gráficos adicionais, clique em more_vert Mais opções de gráficos.
Para ver um gráfico no modo de ecrã inteiro, clique em Ver em ecrã inteiro. Pode sair do modo de ecrã inteiro clicando em Cancelar ou premindo Esc.
Para expandir ou reduzir a legenda do gráfico, clique em Expandir/Reduzir legenda do gráfico.
Para transferir o gráfico, clique em Transferir e, de seguida, selecione um formato de transferência.
Para alterar o formato visual do gráfico, clique em Modo e, de seguida, selecione um modo de visualização.
Para ver a métrica no Explorador de métricas, clique em Ver no Explorador de métricas. Pode ver outras métricas do Spanner no explorador de métricas depois de selecionar o tipo de recurso Base de dados do Spanner.
A tabela seguinte descreve os gráficos apresentados por predefinição no painel de controlo
Estatísticas do sistema. O tipo de métrica para cada gráfico é apresentado. As strings do tipo de métrica seguem este prefixo: spanner.googleapis.com/. O tipo
de métrica
descreve as medições que podem ser recolhidas de um recurso monitorizado.
| Nome do gráfico e tipo de métrica |
Descrição | Disponível para instâncias | Disponível para bases de dados |
|---|---|---|---|
|
Linha cronológica do estado de funcionamento do quórum de duas regiões instance/dual_region_quorum_availability |
Este gráfico só é apresentado para configurações de instâncias de duas regiões. Mostra o estado de três quóruns: o quórum de dupla região ( Global) e o quórum de região única em cada região
(por exemplo, Sydney e Melbourne).
Mostra uma barra laranja na cronologia quando existe uma interrupção do serviço. Pode passar o cursor do rato sobre a barra para ver as horas de início e fim da interrupção. Use este gráfico juntamente com as taxas de erro e as métricas de latência para ajudar a tomar decisões de gestão autónoma sobre quando fazer failover em caso de falhas regionais. Para mais informações, consulte Comutação por falha e recuperação de falhas. Para fazer failover e failback manualmente, consulte o artigo Alterar o quórum de duas regiões. |
done |
done |
Utilização da CPU por prioridade instance/cpu/utilization_by_priority |
A percentagem dos recursos da CPU da instância para tarefas de prioridade alta, média, baixa ou todas. Estas tarefas incluem pedidos que inicia e tarefas de manutenção que o Spanner tem de concluir imediatamente. Para instâncias de duas regiões ou multirregionais, as métricas são agrupadas por região e prioridade. Saiba mais sobre as tarefas de alta prioridade. Saiba mais sobre a utilização da CPU. |
done |
close |
|
Utilização da CPU por região instance/cpu/utilization_by_priority |
Utilização da CPU na instância ou base de dados selecionada, agrupada por região. | done |
done |
|
Utilização da CPU por base de dados instance/cpu/utilization_by_priority |
Utilização da CPU na instância selecionada, agrupada por base de dados e região. | done |
close |
|
Utilização da CPU por utilizador/sistema instance/cpu/utilization_by_priority |
Utilização da CPU na instância ou base de dados selecionada, agrupada por tarefas do utilizador e do sistema, e por prioridade. | done |
done |
Utilização da CPU por tipo de operação instance/cpu/utilization_by_operation_type |
Um gráfico de barras empilhadas da utilização da CPU como uma percentagem dos recursos da CPU da instância, agrupados por operações iniciadas pelo utilizador, como leituras, escritas e commits. Use esta métrica para obter uma discriminação detalhada da utilização da CPU e para resolver problemas adicionais, conforme explicado no artigo Investigue a utilização elevada da CPU. Pode filtrar ainda mais por prioridade das tarefas através da lista de opções. Para instâncias de duas ou várias regiões, as métricas no gráfico de linhas mostram a percentagem média entre regiões. |
done |
done |
Utilização da CPU (média móvel de 24 horas) instance/cpu/smoothed_utilization |
Uma média contínua da utilização da CPU do Spanner, como uma percentagem dos recursos de CPU da instância, para cada base de dados. Cada ponto de dados é uma média das 24 horas anteriores. |
done |
close |
Latência api/request_latencies |
O tempo que o Spanner demorou a processar um pedido de leitura ou escrita. Esta medição começa quando o Spanner recebe um pedido e termina quando o Spanner começa a enviar uma resposta. Pode ver as métricas de latência para as latências do 50.º e 99.º percentil através da lista de opções. |
close |
done |
Latência por base de dados api/request_latencies |
O tempo que o Spanner demorou a processar um pedido de leitura ou escrita, agrupado por base de dados. Esta medição começa quando o Spanner recebe um pedido e termina quando o Spanner começa a enviar uma resposta. Pode ver as métricas de latência do 50.º e 99.º percentil usando a lista de visualização neste gráfico. |
done |
close |
Latência por método da API api/request_latencies |
O tempo que o Spanner demorou a processar um pedido, agrupado por métodos da API Spanner. Esta medição começa quando o Spanner recebe um pedido e termina quando o Spanner começa a enviar uma resposta. Pode ver as métricas para as latências do 50.º e 99.º percentil usando a lista de visualização neste gráfico. |
close |
done |
Latência da transação api/request_latencies_by_transaction_type |
O tempo que o Spanner demorou a processar uma transação. Pode optar por ver métricas para transações do tipo de leitura/escrita e só de leitura. A principal diferença entre o gráfico de latência e o gráfico de latência das transações é que o gráfico de latência das transações permite ver o envolvimento do líder para o tipo só de leitura. As leituras que envolvem o líder podem ter uma latência mais elevada. Pode usar este gráfico para avaliar se deve usar leituras desatualizadas sem comunicar com o líder, partindo do princípio de que o limite de tempo é de, pelo menos, 15 segundos. Para transações de leitura/escrita, o líder está sempre envolvido na transação, pelo que os dados apresentados no gráfico incluem sempre o tempo que o pedido demorou a chegar ao líder e a receber uma resposta. A localização corresponde à região do front-end da API Cloud Spanner. Pode ver as métricas para as latências do 50.º e 99.º percentil usando a lista de visualização neste gráfico. |
close |
done |
Latência das transações por base de dados api/request_latencies_by_transaction_type |
O tempo que o Spanner demorou a processar uma transação. A principal diferença entre o gráfico de latência e o gráfico de latência de transação por base de dados é que o gráfico de latência de transação por base de dados permite ver o envolvimento do líder para o tipo só de leitura. As leituras que envolvem o líder podem ter uma latência mais elevada. Pode usar este gráfico para avaliar se deve usar leituras desatualizadas sem comunicar com o líder, partindo do princípio de que o limite de tempo é de, pelo menos, 15 segundos. Para transações de leitura/escrita, o líder está sempre envolvido na transação, pelo que os dados apresentados no gráfico incluem sempre o tempo que o pedido demorou a chegar ao líder e a receber uma resposta. A localização corresponde à região do front-end da API Cloud Spanner. Pode ver as métricas para as latências do 50.º e 99.º percentil usando a lista de visualização neste gráfico. |
done |
close |
Latência das transações por método da API api/request_latencies_by_transaction_type |
O tempo que o Spanner demorou a processar uma transação. A principal diferença entre o gráfico de latência e o gráfico de latência das transações por método da API é que o gráfico de latência das transações por método da API permite ver o envolvimento do líder para o tipo só de leitura. As leituras que envolvem o líder podem ter uma latência mais elevada. Pode usar este gráfico para avaliar se deve usar leituras desatualizadas sem comunicar com o líder, partindo do princípio de que o limite de tempo é de, pelo menos, 15 segundos. Para transações de leitura/escrita, o líder está sempre envolvido na transação, pelo que os dados apresentados no gráfico incluem sempre o tempo que o pedido demorou a chegar ao líder e a receber uma resposta. A localização corresponde à região do front-end da API Cloud Spanner. |
close |
done |
Operações por segundo api/api_request_count |
O número de operações de leitura e escrita que o Spanner realiza por segundo ou o número de erros do servidor do Spanner por segundo. Pode escolher as operações a ver neste gráfico:
|
close |
done |
Operações por segundo por base de dados api/api_request_count |
O número de operações de leitura e escrita que o Spanner realiza por segundo ou o número de erros do servidor do Spanner por segundo. Este gráfico está agrupado por base de dados. Pode escolher as operações a ver neste gráfico:
|
done |
close |
Operações por segundo por método da API api/api_request_count |
O número de operações que o Spanner realizou por segundo, agrupadas por método da API Spanner |
close |
done |
Débito api/sent_bytes_count (leitura) api/received_bytes_count (escrita) |
A quantidade de dados não comprimidos lidos e escritos na base de dados a cada segundo. Este valor é medido em bytes binários, como KiB, MiB ou GiB. A taxa de transferência de leitura inclui pedidos e respostas para métodos na API read e para consultas SQL. Também inclui pedidos e respostas para declarações DML. A taxa de transferência de gravação inclui pedidos e respostas para confirmar dados através da API de mutação. Exclui pedidos e respostas para declarações DML. |
close |
done |
Débito por base de dados api/sent_bytes_count (leitura) api/received_bytes_count (escrita) |
A quantidade de dados não comprimidos lidos e escritos na instância a cada segundo, agrupados por base de dados. Este valor é medido em bytes binários, como KiB, MiB ou GiB. A taxa de transferência de leitura inclui pedidos e respostas para métodos na API read e para consultas SQL. Também inclui pedidos e respostas para declarações DML. A taxa de transferência de gravação inclui pedidos e respostas para confirmar dados através da API de mutação. Exclui pedidos e respostas para declarações DML. |
done |
close |
Débito por método da API api/sent_bytes_count (leitura) api/received_bytes_count (escrita) |
A quantidade de dados não comprimidos que foram lidos ou escritos na instância ou na base de dados a cada segundo, agrupados por método da API. Este valor é medido em bytes binários, como KiB, MiB ou GiB. A taxa de transferência de leitura inclui pedidos e respostas para métodos na API read e para consultas SQL. Também inclui pedidos e respostas para declarações DML. A taxa de transferência de gravação inclui pedidos e respostas para confirmar dados através da API de mutação. Exclui pedidos e respostas para declarações DML. |
close |
done |
Armazenamento total instance/storage/used_bytes |
A quantidade de dados armazenados na base de dados. Este valor é medido em bytes binários, como KiB, MiB ou GiB. |
close |
done |
Armazenamento total da base de dados por base de dados instance/storage/used_bytes |
A quantidade de dados armazenados na instância, agrupados por base de dados. Este valor é medido em bytes binários, como KiB, MiB ou GiB. |
done |
close |
Armazenamento total da cópia de segurança instance/backup/used_bytes |
A quantidade de dados armazenados nas cópias de segurança associadas à base de dados. Este valor é medido em bytes binários, como KiB, MiB ou GiB. |
close |
done |
Tempo de espera do bloqueio lock_stat/total/lock_wait_time |
O tempo de espera de bloqueio de uma transação é o tempo necessário para adquirir um bloqueio num recurso detido por outra transação. O tempo total de espera de bloqueio para conflitos de bloqueio é registado para toda a base de dados. |
close |
done |
Tempo de espera de bloqueio por base de dados lock_stat/total/lock_wait_time |
O tempo de espera de bloqueio de uma transação é o tempo necessário para adquirir um bloqueio num recurso detido por outra transação, agrupado por base de dados. O tempo total de espera de bloqueio para conflitos de bloqueio é registado para toda a instância. |
done |
close |
Armazenamento total de cópias de segurança por base de dados instance/backup/used_bytes |
A quantidade de dados armazenados nas cópias de segurança associadas à instância, agrupados por base de dados. Este valor é medido em bytes binários, como KiB, MiB ou GiB. |
done |
close |
Capacidade de computação instance/processing_units instance/nodes |
A capacidade de computação é a quantidade de unidades de processamento ou nós disponíveis numa instância. Pode optar por apresentar a capacidade em unidades de processamento ou em nós. |
done |
close |
Distribuição de líderes instance/leader_percentage_by_region |
Para instâncias de região dupla ou multirregião, pode ver o número de bases de dados com a maioria dos líderes (>=50%) numa determinada região. No menu de lista Regiões, se selecionar uma região específica, o gráfico mostra o número total de bases de dados nessa instância que têm a região selecionada como região principal. Se selecionar Todas as regiões no menu de lista Regiões, o gráfico mostra uma linha para cada região, e cada linha mostra o número total de bases de dados na instância que tem essa região como região principal. Para bases de dados numa instância de duas regiões ou multirregional, pode ver a percentagem de líderes agrupados por região. Por exemplo, se uma base de dados tiver cinco líderes, um em us-west1 e quatro em us-east1 num determinado momento, o gráfico "Todas as regiões" mostra duas linhas (uma por região). Uma linha para us-west1 está a 20% e a outra linha para us-east1 está a 80%. O gráfico us-west1 mostra uma única linha a 20% e o gráfico us-east1 mostra uma única linha a 80%.Tenha em atenção que, se uma base de dados foi criada recentemente ou uma região principal foi modificada recentemente, os gráficos podem não estabilizar imediatamente. Este gráfico só está disponível para instâncias de duas regiões e várias regiões. |
done |
done |
Pontuação de utilização da CPU dividida no pico instance/peak_split_peak |
A utilização máxima da CPU dividida de pico observada em todas as divisões numa base de dados. Esta métrica mostra a percentagem dos recursos da unidade de processamento que estão a ser usados numa divisão. Uma percentagem superior a 50% é uma divisão parcial, o que significa que a divisão está a usar metade dos recursos da unidade de processamento do servidor anfitrião. Uma percentagem de 100% é uma divisão frequente, que é uma divisão que está a usar a maioria dos recursos da unidade de processamento do servidor anfitrião. O Spanner usa a divisão baseada na carga para resolver pontos críticos e equilibrar a carga. No entanto, o Spanner pode não conseguir equilibrar a carga, mesmo após várias tentativas de divisão, devido a padrões problemáticos na aplicação. Assim, os pontos críticos que duram, pelo menos, 10 minutos podem exigir uma resolução de problemas adicional e podem exigir alterações à aplicação. Para mais informações, consulte o artigo Encontre pontos críticos em divisões. | done |
done |
|
Chamadas de serviço remoto query_stat/total/remote_service_calls_count |
Contagem de chamadas de serviços remotos, agrupadas por serviço e códigos de resposta. Responde com um código de resposta HTTP, como 200 ou 500. |
done |
done |
|
Latência: chamadas de serviços remotos query_stat/total/remote_service_calls_latencies |
A latência das chamadas de serviços remotos, agrupadas por serviço. Pode ver as métricas de latência para as latências do 50.º e 99.º percentil através da lista de opções. |
done |
done |
|
Linhas processadas pelo serviço remoto query_stat/total/remote_service_processed_rows_count |
Contagem de linhas processadas por um serviço remoto, agrupadas pelo fornecedor de serviços e pelos códigos de resposta. Responde com um código de resposta HTTP, como 200 ou 500. |
done |
done |
|
Latência: linhas de serviço remoto query_stat/total/remote_service_processed_rows_latencies |
Contagem de linhas processadas por um serviço remoto, agrupadas pelo serviço e códigos de resposta. Pode ver as métricas de latência para as latências do 50.º e 99.º percentil através da lista de opções. |
done |
done |
|
Bytes de rede do serviço remoto query_stat/total/remote_service_network_bytes_sizes |
Bytes de rede trocados com o serviço remoto, agrupados por serviço e direção. Este valor é medido em bytes binários, como KiB, MiB ou GiB. A direção refere-se ao tráfego que está a ser enviado ou recebido. Pode ver as métricas para o 50.º e o 99.º percentil de bytes de rede trocados através da lista de opções. |
done |
done |
|
Chamadas de microsserviços query_stat/total/remote_service_calls_count |
Número de chamadas de microsserviços, agrupadas por microsserviço e código de resposta. | done |
done |
|
Latência: chamadas de microsserviços query_stat/total/remote_service_calls_latencies |
Latências de chamadas de microserviços, agrupadas por microserviço. | done |
done |
Armazenamento da base de dados por tabela (nenhum) |
A quantidade de dados armazenados na instância ou na base de dados, agrupados por tabelas na base de dados selecionada. Este valor é medido em bytes binários, como KiB, MiB ou GiB. Este gráfico obtém os respetivos dados consultando SPANNER_SYS.TABLE_SIZES_STATS_1HOUR. Para mais informações, consulte o artigo
Estatísticas de tamanhos das tabelas. |
close |
done |
Tabelas mais usadas por operações (nenhuma) |
As 15 tabelas e índices mais usados na instância ou na base de dados, determinados pelo número de operações de leitura, escrita ou eliminação. Este gráfico obtém os respetivos dados consultando as tabelas de estatísticas de operações de tabelas. Para mais informações, consulte o artigo Estatísticas de operações de tabelas. |
close |
done |
Tabelas menos usadas por operações (nenhuma) |
As 15 tabelas e índices menos usados na instância ou na base de dados, determinados pelo número de operações de leitura, escrita ou eliminação. Este gráfico obtém os respetivos dados consultando as tabelas de estatísticas de operações de tabelas. Para mais informações, consulte o artigo Estatísticas de operações de tabelas. |
close |
done |
Gráficos e métricas do escalador automático gerido
Além das opções apresentadas na secção anterior, quando uma instância tem o escalador automático gerido ativado, o gráfico de capacidade de computação tem o botão Ver registos. Quando clica neste botão, são apresentados registos do escalador automático gerido.
As seguintes métricas estão disponíveis para instâncias com o escalador automático gerido ativado.
| Nome e tipo da métrica | Descrição |
|---|---|
| Capacidade de computação | Com nós selecionados. |
|
instance/autoscaling/min_node_count |
Número mínimo de nós que o dimensionamento automático está configurado para atribuir à instância. |
|
instance/autoscaling/max_node_count |
Número máximo de nós que o dimensionador automático está configurado para atribuir à instância. |
|
instance/autoscaling/recommended_node_count_for_cpu |
Número recomendado de nós com base na utilização da CPU da instância. |
|
instance/autoscaling/recommended_node_count_for_storage |
Número recomendado de nós com base na utilização de armazenamento da instância. |
| Capacidade de computação | Com unidades de processamento selecionadas. |
|
instance/autoscaling/min_processing_units |
Número mínimo de unidades de processamento que o escalador automático está configurado para atribuir à instância. |
|
instance/autoscaling/max_processing_units |
O número máximo de unidades de processamento que o dimensionamento automático está configurado para atribuir à instância. |
|
instance/autoscaling/recommended_processing_units_for_cpu |
Número recomendado de unidades de processamento. Esta recomendação baseia-se na utilização anterior da CPU da instância. |
|
instance/autoscaling/recommended_processing_units_for_storage |
Número recomendado de unidades de processamento a usar. Esta recomendação baseia-se na utilização de armazenamento anterior da instância. |
| Utilização da CPU por prioridade | |
|
instance/autoscaling/high_priority_cpu_utilization_target |
Alvo de utilização da CPU de prioridade elevada a usar para a escala automática. |
| Armazenamento total | Com unidades de processamento selecionadas. |
|
instance/storage/limit_bytes |
Limite de armazenamento da instância em bytes. |
|
instance/autoscaling/storage_utilization_target |
Objetivo de utilização do armazenamento a usar para o dimensionamento automático. |
Gráficos e métricas de armazenamento hierarquizado
As seguintes métricas estão disponíveis para instâncias que usam o armazenamento hierárquico.
| Nome e tipo da métrica | Descrição |
|---|---|
| instance/storage/used_bytes | Total de bytes de dados armazenados no armazenamento SSD e HDD. |
| instance/storage/combined/limit_bytes | Limites de armazenamento combinados de SSD e HDD. |
| instance/storage/combined/limit_per_processing_unit | Limite de armazenamento combinado de SSD e HDD para cada unidade de processamento. |
| instance/storage/combined/utilization | Armazenamento de SSD e HDD combinado usado, em comparação com o limite de armazenamento combinado. |
| instance/disk_load | Utilização de carga do HDD. |
Retenção de dados
A retenção máxima de dados para a maioria das métricas no painel de controlo de estatísticas do sistema é de 6 semanas. No entanto, para o gráfico Armazenamento de base de dados por tabela, os dados são consumidos a partir da tabela SPANNER_SYS.TABLE_SIZES_STATS_1HOUR (em vez do Spanner), que tem uma retenção máxima de 30 dias.
Consulte o artigo
Retenção de dados
para saber mais.
Veja o painel de controlo de estatísticas do sistema
Para ver a página Estatísticas do sistema, precisa das seguintes autorizações de gestão de identidade e acesso (IAM), além das autorizações do Spanner e das autorizações do Spanner ao nível da instância e da base de dados:
spanner.databases.beginReadOnlyTransactionspanner.databases.selectspanner.sessions.create
Para mais informações sobre as autorizações da IAM do Spanner, consulte o artigo Controlo de acesso com a IAM.
Se ativar o redimensionador automático gerido na instância, também precisa das autorizações logging.logEntries.list, logging.logs.list e logging.logServices.list para ver os registos do redimensionador automático gerido.
Para mais informações acerca desta autorização, consulte o artigo Funções predefinidas.
Para ver o painel de controlo Estatísticas do sistema, siga estes passos:
Na Google Cloud consola, abra a lista de instâncias do Spanner.
Efetue um dos seguintes passos:
Para ver as métricas de uma instância, clique no nome da instância sobre a qual quer saber mais e, de seguida, clique em Estatísticas do sistema no menu de navegação.
Para ver as métricas de uma base de dados, clique no nome da instância, selecione uma base de dados e, de seguida, clique em Estatísticas do sistema no menu de navegação.
Opcional: para ver dados do histórico relativos a um período diferente, encontre os botões na parte superior direita da página e, de seguida, clique no período que quer ver.
Opcional: para controlar que dados são apresentados no gráfico, clique numa das listas no gráfico. Por exemplo, se a instância usar uma configuração de região dupla ou de várias regiões, alguns gráficos fornecem uma lista para ver dados de uma região específica. Nem todos os gráficos têm listas de visualização.
O que se segue?
- Compreenda as métricas de utilização da CPU e latência para o Spanner.
- Configure gráficos e alertas personalizados com a funcionalidade de monitorização.
- Obtenha detalhes sobre os tipos de instâncias do Spanner.