本文档介绍了如何使用系统分析洞见信息中心来监控 Spanner 实例和数据库。
系统分析洞见简介
系统分析洞见信息中心会显示与所选实例或数据库相关的统计信息摘要和图表,并提供延迟时间、CPU 利用率、存储空间、吞吐量和其他性能统计数据的衡量值。您可以查看过去 1 小时到过去 30 天内可选时间段的图表。
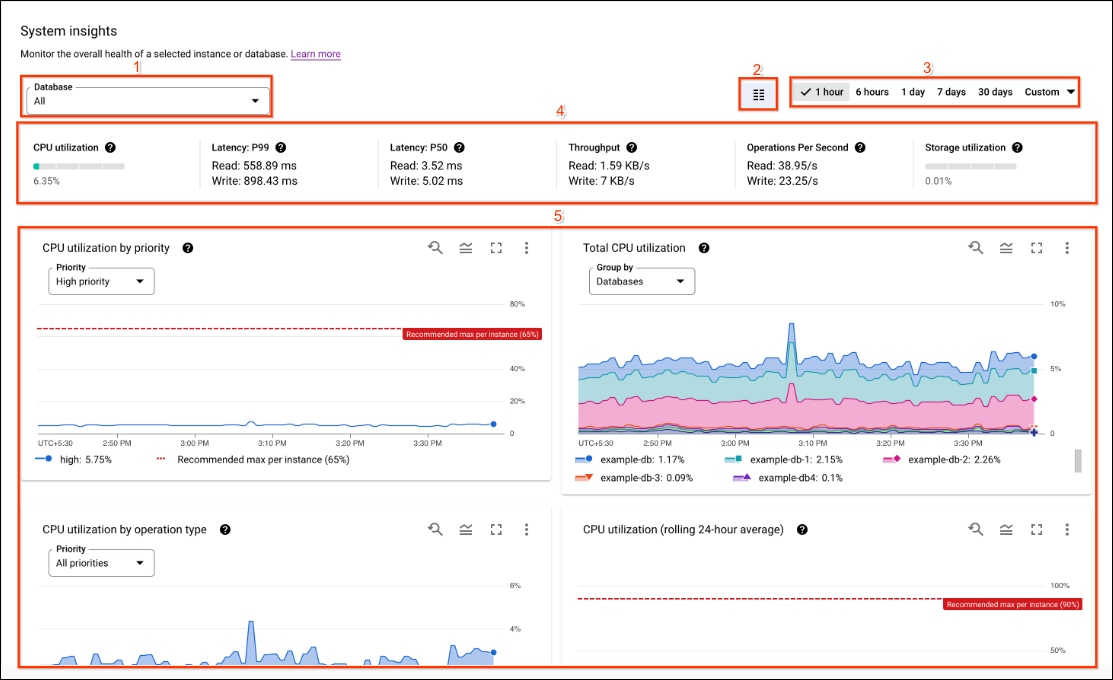
系统分析洞见信息中心包含以下部分,编号与以下界面屏幕截图相对应:
- 数据洞察选择器:选择用于填充信息中心的数据库、实例分区和区域。当实例中存在多个实例分区或区域时,系统洞见会显示实例分区和区域选择。
- 时间范围过滤条件:按时间范围(如小时、天或自定义范围)过滤统计信息。
- 信息中心选择器:选择用户自定义视图,或将系统数据洞见重置为默认的预定义视图。
- 注释:选择要在图表中添加注释的数据洞见提醒事件类型。
- 自定义信息中心:自定义信息中心 widget 和系统洞见信息中心的外观、位置和内容。本文档介绍了预定义的信息中心演示。
- 统计信息摘要:显示所选时间段内某个时间点的统计信息。
- 图表:显示 CPU 利用率、吞吐量、延迟时间、存储空间使用情况等的图表。通过注释设置的数据分析提醒会显示在图表中,并带有铃铛图标。
所需的角色
如需获得查看或修改数据分析信息中心(包括自定义信息中心)所需的权限,请让您的管理员向您授予项目的以下 IAM 角色:
-
如需创建和修改自定义信息中心,请使用:Monitoring Dashboard Configuration Editor (
roles/monitoring.dashboardEditor) -
如需打开并查看 Metrics Explorer 图表,请执行以下操作:Monitoring Dashboard Configuration Viewer (
roles/monitoring.dashboardViewer) -
如需创建和修改 Metrics Explorer 提醒,您需要具备以下权限:Monitoring Editor (
roles/monitoring.editor)
如需详细了解如何授予角色,请参阅管理对项目、文件夹和组织的访问权限。
这些预定义角色包含查看或修改数据分析信息中心(包括自定义信息中心)所需的权限。如需查看所需的确切权限,请展开所需权限部分:
所需权限
您需要具备以下权限才能查看或修改数据分析信息中心(包括自定义信息中心):
-
如需创建自定义信息中心,请执行以下操作:
monitoring.dashboards.create -
如需修改自定义信息中心,请执行以下操作:
monitoring.dashboards.update -
如需查看自定义信息中心,请执行以下操作:
monitoring.dashboards.get, monitoring.dashboards.list
自定义系统分析洞见信息中心
系统数据分析信息中心是一个预定义的信息中心,您可以对其进行自定义,以显示对您来说最重要的信息。您可以添加新图表、更改布局和过滤数据,以便专注于特定资源。
对系统洞见信息中心所做的更改不会造成破坏,并且可以通过将“信息中心选择器”设置为预定义来重置。
修改信息中心
如需修改信息中心,请点击 自定义信息中心。您可以选择以下选项:
- 添加 widget:在信息中心工具栏中,点击 添加 widget,选择要添加的 widget,然后对其进行配置。
- 修改 widget:将鼠标悬停在某个 widget 上以显示其工具栏,然后点击 修改。您可以更改 widget 的类型,并自定义其显示的数据。
- 复制 widget:将光标悬停在 widget 上以显示其工具栏,点击 更多图表选项,然后点击复制 widget。
- 删除 widget:将光标悬停在 widget 上以显示其工具栏,点击 更多图表选项,然后点击删除 widget。
- 更改布局:您可以拖动 widget 来重新放置它们,也可以拖动 widget 的边角来调整它们的大小。
- 为自定义视图命名:您可以在自定义视图名称框中设置自定义视图名称。
- 保存信息中心:您可以点击 保存来保存自定义视图。您也可以点击退出修改模式,退出而不保存。
系统分析洞见统计信息摘要、图表和指标
系统分析洞见信息中心提供以下图表和指标,用于展示实例的当前状态和历史状态。大多数图表和指标均适用于实例级层。您还可以查看实例中单个数据库的许多图表和指标。
可用的统计信息摘要
| 名称 | 说明 |
|---|---|
| CPU 利用率 | 实例或所选数据库中 CPU 的总体使用情况。在双区域实例或多区域实例中,该指标表示区域间的平均 CPU 利用率。 |
| 延迟时间 (p99) | 实例或所选数据库中读取和写入操作的第 99 百分位延迟时间,表示 99% 的此类操作完成所需的时间。 |
| 延迟时间 (p50) | 实例或所选数据库中读取和写入操作的第 50 百分位延迟时间,表示 50% 的这些操作完成所需的时间。 |
| 吞吐量 | 每秒从实例或数据库读取或向其写入的未压缩数据量。此值以二进制字节为单位进行计量,例如 KiB、MiB 或 GiB。 |
| 每秒操作数 | 实例或所选数据库中读取和写入操作的每秒操作次数(速率)。 |
| 存储空间利用率 | 在实例级别,它是实例中的总存储空间利用率百分比。在数据库级别,这是所选数据库使用的总存储空间。 |
可用图表和指标
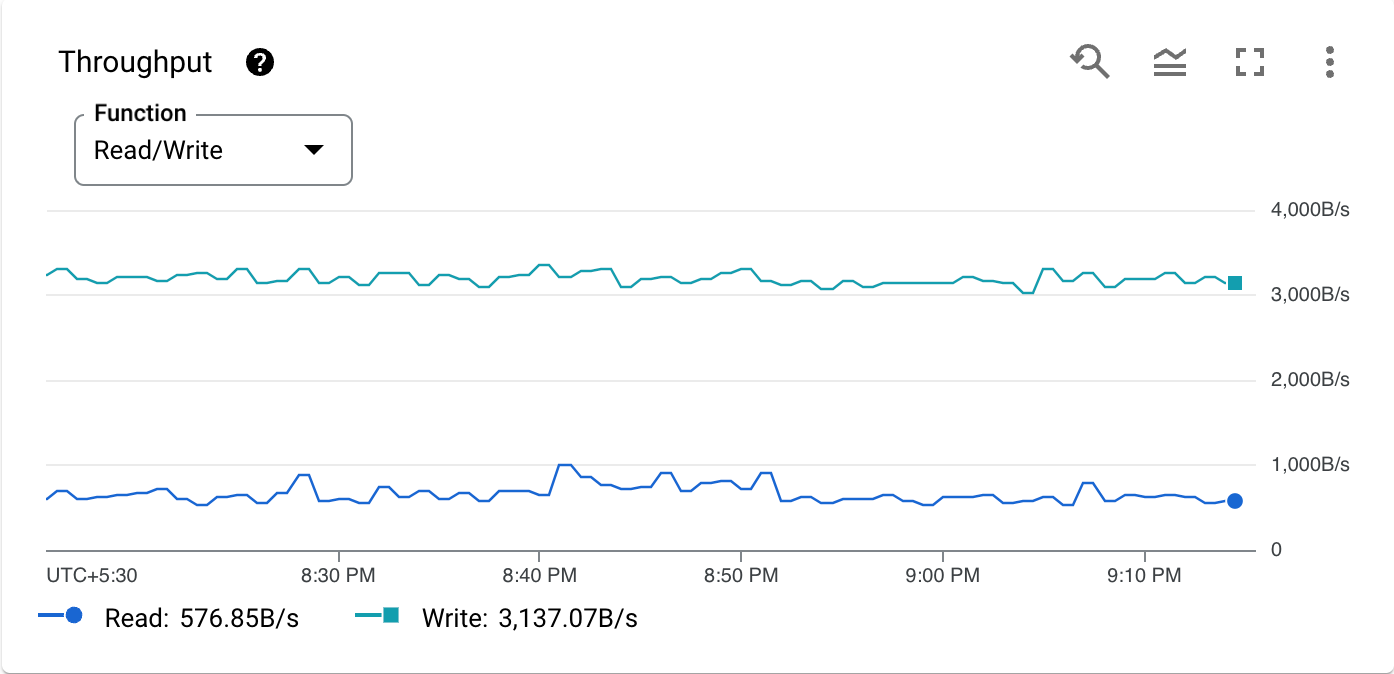
下图显示了一个示例指标,即按操作类型分类的 CPU 利用率:
每个图表上的工具栏都提供以下标准选项。除非您将指针悬停在图表上,否则某些元素会处于隐藏状态。
如需放大图表的特定部分,请将指针拖动到您要查看的部分。此操作会设置自定义时间范围,您可以使用时间范围过滤条件调整或恢复此范围。
如需查看图表及其数据的说明,请点击 help。
如需查看应用于图表的过滤条件和分组,请点击 info。
如需根据图表的数据创建提醒,请点击 add_alert。
如需探索图表中的数据,请点击 query_stats。
如需查看其他图表选项,请点击 more_vert 更多图表选项。
如需以全屏模式查看图表,请点击全屏查看。 您可以点击取消或按 Esc 键退出全屏模式。
如需展开或收起图表图例,请点击展开/收起图表图例。
如需下载图表,请点击下载,然后选择下载格式。
如需更改图表的视觉格式,请点击模式,然后选择一种查看模式。
如需在 Metrics Explorer 中查看相应指标,请点击在 Metrics Explorer 中查看。选择 Spanner 数据库资源类型后,您可以在 Metrics Explorer 中查看其他 Spanner 指标。
下表说明了系统分析洞见信息中心默认显示的图表。列出了每个图表的指标类型。指标类型字符串具有此前缀:spanner.googleapis.com/。指标类型描述了可以从受监控的资源中收集的测量结果。
| 图表名称和指标类型 |
说明 | 适用于实例 | 适用于数据库 |
|---|---|---|---|
|
双区域仲裁健康状况时间轴 instance/dual_region_quorum_availability |
此图表仅针对双区域实例配置显示。它会显示三个仲裁的健康状况:双区域仲裁 ( Global) 以及每个区域中的单区域仲裁(例如 Sydney 和 Melbourne)。
当服务中断时,时间轴中会显示一个橙色条。您可以将鼠标悬停在相应柱形上,查看中断的开始时间和结束时间。您可以将此图表与错误率和延迟时间指标结合使用,以便在发生区域故障时做出自管理的故障切换决策。如需了解详情,请参阅故障切换和故障恢复。 如需手动执行故障切换和故障恢复,请参阅更改双区域仲裁。 |
done |
done |
按优先级划分的 CPU 利用率 instance/cpu/utilization_by_priority |
高优先级、中优先级、低优先级或所有任务的 CPU 资源百分比(按优先级划分)。这些任务包括由您发起的请求,以及 Spanner 必须立即完成的维护任务。 对于双区域或多区域实例,指标按区域和优先级分组。 详细了解高优先级任务。 详细了解 CPU 利用率。 |
done |
close |
|
各区域的 CPU 利用率 instance/cpu/utilization_by_priority |
所选实例或数据库中的 CPU 利用率,按区域分组。 | done |
done |
|
各数据库的 CPU 利用率 instance/cpu/utilization_by_priority |
所选实例中的 CPU 利用率,按数据库和区域分组。 | done |
close |
|
各用户/系统的 CPU 利用率 instance/cpu/utilization_by_priority |
所选实例或数据库中的 CPU 利用率,按用户和系统任务以及优先级分组。 | done |
done |
按操作类型列出的 CPU 利用率 instance/cpu/utilization_by_operation_type |
堆叠图,显示以实例占用的 CPU 资源的百分比表示的 CPU 利用率,按用户启动的操作(例如读取、写入和提交)进行分组。使用此指标可以获取详细的 CPU 使用量明细并进一步进行问题排查,如调查高 CPU 利用率中所述。 您还可以使用选项列表按任务优先级进一步过滤。 对于双区域或多区域实例,折线图中的指标显示的是各区域的平均百分比。 |
done |
done |
CPU 利用率(24 小时的滚动平均值) instance/cpu/smoothed_utilization |
每个数据库的总 CPU Spanner利用率的滚动平均值,以实例占用 CPU 资源的百分比表示。每个数据点代表过去 24 小时的平均值。 |
done |
close |
延迟时间 api/request_latencies |
Spanner 处理读取或写入请求所用的时间。此测量在 Spanner 收到请求时开始,并在 Spanner 开始发送响应时结束。 您可以使用选项列表查看第 50 百分位和第 99 百分位延迟时间的延迟时间指标。 |
close |
done |
延迟时间(按数据库) api/request_latencies |
Spanner 处理读取或写入请求所用的时间(按数据库分组)。此测量在 Spanner 收到请求时开始,并在 Spanner 开始发送响应时结束。 您可以使用此图表上的视图列表查看第 50 百分位和第 99 百分位延迟时间的指标。 |
done |
close |
延迟时间(按 API 方法) api/request_latencies |
Spanner 处理请求所用的时间(按 Spanner API 方法分组)。此测量在 Spanner 收到请求时开始,并在 Spanner 开始发送响应时结束。 您可以使用此图表上的查看列表来查看第 50 百分位和第 99 百分位延迟时间的指标。 |
close |
done |
事务延迟时间 api/request_latencies_by_transaction_type |
Spanner 处理事务所用的时间。您可以选择查看读写型和只读型事务的指标。 “延迟时间”图表与“事务延迟时间”图表之间的主要区别在于,您可以通过“事务延迟时间”图表为只读类型查看主要区域参与方式。涉及主要区域的读取操作可能会出现较长的延迟时间。假设时间戳绑定至少为 15 秒,您可以使用此图表来评估是否应在不与主要区域通信的情况下使用过时数据读取。对于读写事务,主要区域始终参与事务,因此图表中显示的数据始终包含请求到达主要区域并收到响应所用的时间。 相应位置对应于 Cloud Spanner API 前端的区域。 您可以使用此图表上的查看列表来查看第 50 百分位和第 99 百分位延迟时间的指标。 |
close |
done |
事务延迟时间(按数据库) api/request_latencies_by_transaction_type |
Spanner 处理事务所用的时间。 “延迟时间”图表与“按数据库划分的事务延迟时间”图表之间的主要区别在于,您可以通过“按数据库划分的事务延迟时间”图表查看只读类型的主要区域参与方式。涉及主要区域的读取操作可能会出现较长的延迟时间。 假设时间戳绑定至少为 15 秒,您可以使用此图表来评估是否应在不与主要区域通信的情况下使用过时数据读取。对于读写事务,主要区域始终参与事务,因此图表中显示的数据始终包含请求到达主要区域并收到响应所用的时间。 相应位置对应于 Cloud Spanner API 前端的区域。 您可以使用此图表上的查看列表来查看第 50 百分位和第 99 百分位延迟时间的指标。 |
done |
close |
事务延迟时间(按 API 方法) api/request_latencies_by_transaction_type |
Spanner 处理事务所用的时间。 “延迟时间”图表与“事务延迟时间(按 API 方法)”图表之间的主要区别在于,“事务延迟时间(按 API 方法)”图表可让您为只读类型查看主要区域参与方式。涉及主要区域的读取操作可能会出现较长的延迟时间。您可以使用此图表来评估是否应在不与主要区域通信的情况下使用过时数据读取,假设时间戳绑定至少为 15 秒。对于读写事务,主要区域始终参与事务,因此图表中显示的数据始终包含请求到达主要区域并收到响应所用的时间。 相应位置对应于 Cloud Spanner API 前端的区域。 |
close |
done |
每秒操作数 api/api_request_count |
Spanner 每秒执行的读取和写入操作数,或每秒发生的 Spanner 服务器错误数。 您可以选择要在此图表中查看的操作:
|
close |
done |
每秒操作次数(按数据库) api/api_request_count |
Spanner 每秒执行的读取和写入操作数,或每秒发生的 Spanner 服务器错误数。 此图表按数据库分组。 您可以选择要在此图表中查看的操作:
|
done |
close |
每秒操作次数(按 API 方法) api/api_request_count |
Spanner 每秒执行的操作数,按 Spanner API 方法分组 |
close |
done |
吞吐量 api/sent_bytes_count (读取) api/received_bytes_count (写入) |
每秒从数据库读取和写入数据库的未压缩数据量。此值以二进制字节为单位进行计量,例如 KiB、MiB 或 GiB。 读取吞吐量包括读取 API中的方法以及 SQL 查询的请求和响应,还包括 DML 语句的请求和响应。 写入吞吐量包括通过变更 API 发出的提交数据的请求以及获得的响应。它排除了 DML 语句的请求和响应。 |
close |
done |
吞吐量(按数据库) api/sent_bytes_count (读取) api/received_bytes_count (写入) |
每秒从实例读取和写入到实例的未压缩数据量,按数据库分组。此值以二进制字节为单位进行计量,例如 KiB、MiB 或 GiB。 读取吞吐量包括读取 API中的方法以及 SQL 查询的请求和响应,还包括 DML 语句的请求和响应。 写入吞吐量包括通过变更 API 发出的提交数据的请求以及获得的响应。它排除了 DML 语句的请求和响应。 |
done |
close |
吞吐量(按 API 方法) api/sent_bytes_count (读取) api/received_bytes_count (写入) |
每秒从实例或数据库读取或向其写入的未压缩数据量,按 API 方法分组。此值以二进制字节为单位进行计量,例如 KiB、MiB 或 GiB。 读取吞吐量包括读取 API中的方法以及 SQL 查询的请求和响应,还包括 DML 语句的请求和响应。 写入吞吐量包括通过变更 API 发出的提交数据的请求以及获得的响应。它排除了 DML 语句的请求和响应。 |
close |
done |
总存储空间 instance/storage/used_bytes |
存储在数据库中的数据量。此值以二进制字节为单位进行计量,例如 KiB、MiB 或 GiB。 |
close |
done |
总数据库存储空间(按数据库) instance/storage/used_bytes |
存储在实例中的数据量,按数据库分组。此值以二进制字节为单位进行计量,例如 KiB、MiB 或 GiB。 |
done |
close |
备份总存储空间 instance/backup/used_bytes |
与数据库关联的备份中存储的数据量。此值以二进制字节为单位进行计量,例如 KiB、MiB 或 GiB。 |
close |
done |
锁定等待时间 lock_stat/total/lock_wait_time |
事务的锁等待时间是指获取另一事务持有的资源锁所需的时间。 对整个数据库记录的锁定冲突的总锁定等待时间。 |
close |
done |
锁定等待时间(按数据库) lock_stat/total/lock_wait_time |
事务的锁定等待时间是指获取另一事务持有的资源锁所需的时间,按数据库分组。 针对整个实例记录的锁定冲突的总锁定等待时间。 |
done |
close |
总备份存储空间(按数据库) instance/backup/used_bytes |
与实例关联的备份中存储的数据量,按数据库分组。此值以二进制字节为单位进行计量,例如 KiB、MiB 或 GiB。 |
done |
close |
计算容量 实例/处理单元 实例/节点 |
计算容量是指实例中可用的处理单元或节点的数量。您可以选择以处理单元或节点为单位显示容量。 |
done |
close |
主要区域分布 instance/leader_percentage_by_region |
对于双区域或多区域实例,您可以查看大部分主要区域 (>=50%) 位于指定区域的数据库的数量。在区域列表菜单中,如果您选择特定区域,图表会显示该实例中以所选区域作为主要区域的数据库总数。如果您在区域列表菜单中选择所有区域,图表会针对每个区域显示一条线,每条线会显示以该区域为主要区域的实例中数据库的总数。 对于双区域或多区域实例中的数据库,您可以查看按区域分组的主要区域百分比。例如,如果某个数据库在某个时间点有 5 个主要区域,其中 1 个位于 us-west1,4 个位于 us-east1,那么“所有区域”图表会显示两条线(每个区域一个)。us-west1 的一条线为 20%,us-east1 的另一条线为 80%。us-west1 图表显示一条位于 20% 的线,而 us-east1 图表显示一条位于 80% 的线。请注意,如果数据库是最近创建的,或者主要区域是最近修改的,图表可能不会立即稳定下来。 此图表仅适用于双区域和多区域实例。 |
done |
done |
分块 CPU 使用率最高分数 instance/peak_split_peak |
在数据库的所有分块中观察到的峰值分块 CPU 使用率上限。此指标显示了在分块中使用的处理单元资源的百分比。超过 50% 的百分比表示热分块,这意味着该分块使用了主机服务器的一半处理单元资源。百分比为 100% 表示热分块,即使用主机服务器处理单元资源的大部分的分块。Spanner 使用基于负载的拆分来解决热点问题并均衡负载。但是,由于应用中存在有问题的模式,即使在多次尝试拆分后,Spanner 也可能无法均衡负载。因此,如果热点持续时间至少为 10 分钟,则可能需要进一步排查问题,并且可能需要更改应用。如需了解详情,请参阅在分块中查找热点。 | done |
done |
|
远程服务调用次数 query_stat/total/remote_service_calls_count |
远程服务调用次数(按服务和响应代码分组)。 使用 HTTP 响应代码(例如 200 或 500)进行响应。 |
done |
done |
|
延迟时间:远程服务调用 query_stat/total/remote_service_calls_latencies |
远程服务调用的延迟时间(按服务分组)。 您可以使用选项列表查看第 50 百分位和第 99 百分位延迟时间的延迟时间指标。 |
done |
done |
|
远程服务处理的行数 query_stat/total/remote_service_processed_rows_count |
远程服务处理的行数(按服务提供方和响应代码分组)。 使用 HTTP 响应代码(例如 200 或 500)进行响应。 |
done |
done |
|
延迟时间:远程服务行数 query_stat/total/remote_service_processed_rows_latencies |
远程服务处理的行数(按服务和响应代码分组)。 您可以使用选项列表查看第 50 百分位和第 99 百分位延迟时间的延迟时间指标。 |
done |
done |
|
远程服务网络字节数 query_stat/total/remote_service_network_bytes_sizes |
与远程服务交换的网络字节数(按服务和方向分组)。 此值以二进制字节为单位进行计量,例如 KiB、MiB 或 GiB。 “方向”是指流量是发送还是接收。 您可以使用选项列表查看网络字节交换的第 50 百分位和第 99 百分位的指标。 |
done |
done |
|
微服务调用次数 query_stat/total/remote_service_calls_count |
微服务调用次数(按微服务和响应代码分组)。 | done |
done |
|
延迟时间:微服务调用 query_stat/total/remote_service_calls_latencies |
微服务调用的延迟时间(按微服务分组)。 | done |
done |
数据库存储空间(按表) (无) |
存储在实例或数据库中的数据量,按所选数据库中的表分组。此值以二进制字节为单位进行计量,例如 KiB、MiB 或 GiB。 此图表通过查询 SPANNER_SYS.TABLE_SIZES_STATS_1HOUR 获取数据。如需了解详情,请参阅表大小统计信息。 |
close |
done |
操作最多的表 (无) |
实例或数据库中最常用的 15 个表和索引,由读取、写入或删除操作的数量决定。 此图表通过查询表操作统计信息表来获取数据。如需了解详情,请参阅 表操作统计信息。 |
close |
done |
操作最少的表 (无) |
实例或数据库中读取、写入或删除操作次数最少的 15 个表和索引。 此图表通过查询表操作统计信息表来获取数据。如需了解详情,请参阅 表操作统计信息。 |
close |
done |
托管式自动扩缩器图表和指标
除了上一部分中显示的选项之外,当实例启用了受管理的自动扩缩器时,计算容量图表中会显示查看日志按钮。点击此按钮后,系统会显示受管自动扩缩器的日志。
对于启用托管式自动扩缩器的实例,可以使用以下指标。
| 指标名称和类型 | 说明 |
|---|---|
| 计算容量 | 已选择节点。 |
|
instance/autoscaling/min_node_count |
实例的自动扩缩器配置要分配的节点数下限。 |
|
instance/autoscaling/max_node_count |
自动扩缩器配置可分配给实例的节点数上限。 |
|
instance/autoscaling/recommended_node_count_for_cpu |
根据实例的 CPU 使用情况推荐的节点数。 |
|
instance/autoscaling/recommended_node_count_for_storage |
根据实例的存储空间用量建议的节点数。 |
| 计算容量 | 已选择处理单元。 |
|
instance/autoscaling/min_processing_units |
自动扩缩器配置为向实例分配的最小处理单元数量。 |
|
instance/autoscaling/max_processing_units |
自动扩缩器配置为向实例分配的处理单元数上限。 |
|
instance/autoscaling/recommended_processing_units_for_cpu |
建议的处理单元数。此建议基于实例之前的 CPU 用量。 |
|
instance/autoscaling/recommended_processing_units_for_storage |
建议使用的处理单元数。此建议基于实例的之前存储用量。 |
| 按优先级划分的 CPU 利用率 | |
|
instance/autoscaling/high_priority_cpu_utilization_target |
用于自动扩缩的高优先级 CPU 利用率目标。 |
| 总存储空间 | 已选择处理单元。 |
|
instance/storage/limit_bytes |
实例的存储空间限制(以字节为单位)。 |
|
instance/autoscaling/storage_utilization_target |
用于自动扩缩的存储空间利用率目标。 |
分层存储空间图表和指标
对于使用分层存储的实例,您可以查看以下指标。
| 指标名称和类型 | 说明 |
|---|---|
| instance/storage/used_bytes | 在 SSD 和 HDD 存储空间中存储的数据总字节数。 |
| instance/storage/combined/limit_bytes | SSD 和 HDD 存储空间限制总计。 |
| instance/storage/combined/limit_per_processing_unit | 每个处理单元的 SSD 和 HDD 存储空间限制总计。 |
| instance/storage/combined/utilization | 已用 SSD 和 HDD 存储空间的总计,与存储空间限制总计进行比较。 |
| instance/disk_load | HDD 加载用量。 |
数据保留
系统分析洞见信息中心的大多数指标的数据保留期最长为六周。不过,对于按表划分的数据库存储空间图表,数据是从 SPANNER_SYS.TABLE_SIZES_STATS_1HOUR 表(而不是 Spanner)中提取的,该表的最长保留期限为 30 天。如需了解详情,请参阅数据保留。
查看系统分析洞见信息中心
如需查看系统分析洞见页面,您需要在实例和数据库级别拥有 Spanner 权限和 Spanner 权限,以及以下 Identity and Access Management (IAM) 权限:
spanner.databases.beginReadOnlyTransactionspanner.databases.selectspanner.sessions.create
如需详细了解 Spanner IAM 权限,请参阅使用 IAM 进行访问权限控制。
如果您在实例上启用托管式自动扩缩器,还需要 logging.logEntries.list、logging.logs.list 和 logging.logServices.list 权限才能查看托管式自动扩缩器日志。
如需详细了解此权限,请参阅预定义角色。
如需查看系统分析洞见信息中心,请按以下步骤操作:
在 Google Cloud 控制台中,打开 Spanner 实例列表。
执行下列其中一项操作:
如需查看实例的指标,请点击要了解的实例的名称,然后点击导航菜单中的系统分析洞见。
如需查看数据库的指标,请点击实例的名称,选择数据库,然后点击导航菜单中的系统分析洞见。
可选:如需查看不同时间段的历史数据,请找到页面右上角的按钮,然后点击要查看的时间段。
可选:如需控制图表中显示的数据,请点击图表中的列表之一。例如,如果实例采用双区域或多区域配置,则某些图表会提供一个列表以查看特定区域的数据。并非所有图表都有查看列表。
后续步骤
- 了解 Spanner 的 CPU 利用率和延迟时间指标。
- 使用 Monitoring 设置自定义图表和提醒。
- 详细了解 Spanner 实例的类型。